Amazon Web Services ブログ
AWS でコンソーシアムサイエンスを活用し科学的発見を促進
同僚の Mia Champion は科学者 (彼女が発表した記事) であり、AWS 認定ソリューションアーキテクト そして AWS 認定開発者でもあります。今回は、彼女が大量なデータのデータセットリサーチを行っている際に、バイオインフォマティクスにおけるクラウドコンピューティングの価値に気付いた時のことについてブログを投稿いただきました。
— Jeff;
科学研究における技術の進歩は、そのコンテンツにおいても複雑性を増し、日々急増しているデータセットのコレクションに可能性を与えています。世界中で加速化するイノベーションは、最近のクラウドコンピューティング革命によっても活気付けられ、一見したところ無限でスケーラブルそして迅速なインフラストラクチャを研究者に提供しています。現在では、研究者が独自のシーケンサー、マイクロスコープ、コンピューティングクラスターなどを所有するための障害を排除しています。クラウドを使用することで、科学者はギガバイトにも及ぶ何百万人という患者のサンプルのデータセットや各患者のその他の情報を簡単に保存、管理、処理そして共有することができます。アメリカの物理学者である John Bardeen はこのように言っています。「科学というものは協同して取り組むものです。数人の科学者が共に努力し出し合った結果を組み合わせることで、1 人の科学者が行うよりも効率よく研究を進めることができるのです (Science is a collaborative effort. The combined results of several people working together is much more effective than could be that of an individual scientist working alone)」
再現性のイノベーション、一般化、データ保護の優先
これまでにないスケールで、安全性を備えたクラウドを有効にしたデータ共有を活用する研究者や組織は日々増え、AWS クラウドを使用して革新的でカスタマイズした分析ソリューションを作り出しています。しかし、そうしたスケールの共同作業環境において、対象分野そして科学における従来の方法を根本的に変え、安全なデータ共有と分析を行うことは可能でしょうか?クラウドを有効にしたリソースの共同体を構築することで、研究結果の説明やその影響において問題となり、再現性の下落に繋げた分析変動性を排除することはできるのでしょうか? こうした疑問への答えは「イエス」です。Neuro Cloud Consortium、The Global Alliance for Genomics and Health (GA4GH)、The Sage Bionetworks Synapse プラットフォームのようなイニシアティブは (これは、いくつものリサーチコンソーシアムをサポートしています)、DREAM challenges も含み、プラクティスモデルのクラウドイニシアティブを取り入れ始めています。そして、これらは神経科学、感染病、癌などにおいても大きな発見を提供しているだけでなく、科学研究の在り方についても根本的な変化をみせています。
クラウドで開発するモデル、アルゴリズム、機能をデータに取り入れる
従来、共同プロジェクトでは研究者が相対的な配列分析や医用画像データでディープラーニングアルゴリズムのトレーニングにて使用されるデータセットをダウンロードするようになっていました。そしてダウンロード後に、研究者は組織のクラスター、ローカルワークステーション、ノートパソコンを使用して独自の分析を開発し実行することができます。
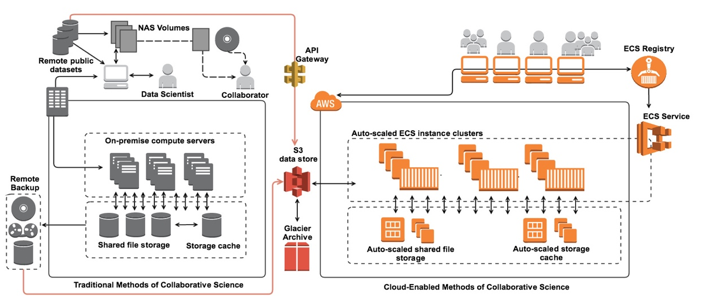
この方法で行う共同作業は問題となるいくつもの理由があります。まず、データセキュリティが最初の懸念です。データセットをダウンロードする方法では、その情報が何人もの受信者に渡り「連鎖したデータ共有」を許可してしまうことになるからです。そして次に、何らかの段階でテンプレートを使用せずにコンピューティング環境で行った分析は変数解析のリスクを伴い、それ自体を別の研究者が再現することはできません。また、同じ研究者が別のコンピューティング環境を使用した場合も同様です。さらに、必須とされるデータのダンプ、プロセスそして共同作業のグループへの再アップロードやディストリビューションは効率的とは言えず、各個人のネットワーキングやコンピューティング能力に依存することになります。全体的に見て、従来の科学的な共同作業を行う方法にはセキュリティ問題や科学的発見に費やす時間において障害を伴います。AWS クラウドを使用することで、共同作業を行う研究者達は Identity and Access Management (IAM) ポリシー制限をユーザーのバケットアクセスや、S3 バケットポリシー、アクセスコントロールリスト (ACL) で利用することにより、簡単かつ安全にデータセットを共有することができます。データソースに分析を移動するリソースを使用したり、リモート API リクエストを利用して共有データベースやデータレイクにアクセスする方法を取り入れることで、多くの研究者達はデータセットをダウンロードする必要性を排除し、分析を効率化してデータセキュリティを確保しています。この達成方法の 1 つとして、当社のお客様は共同作業を行うユーザー達にアルゴリズムを送信または共有したデータセットをホストするシステムで実行するモデルを提供することで、コンテナベースの Docker テクノロジーを利用しています。
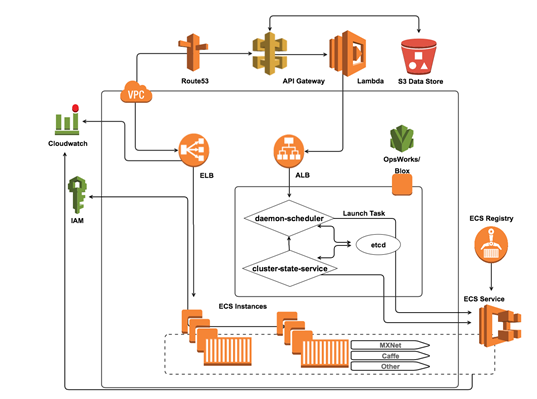
Docker コンテナイメージにはアプリケーションへの依存関係すべてが含まれています。そのため、レベルの高い多彩性や可搬性を提供することができ、これは他の実行可能ベースのアプローチの使用に比べ、大きなメリットになっています。機械学習の共同プロジェクトにおいては、各 Docker コンテナにアプリケーション、言語ランタイム、パッケージとライブラリ、その他にも MXNet、Caffe、TensorFlow、Theano など、研究者達が一般的に使用している人気のディープラーニングフレームワークが含まれています。こうしたフレームワークで一般的に見られる機能は、機械学習の計算に関与するマトリックスやベクトルオペレーションホストマシンのグラフィック処理ユニット (GPU) があります。こうした目的を持つ研究者達は EC2 の新しい P2 インスタンスタイプを利用して、送信された機械学習モデルを実行しています。さらに NVIDIA Docker ツールを使用して、GPU を追加デバイスとしてシステムレベルに見せてコンテナに直接マウントすることができます。Amazon EC2 Container Service と EC2 コンテナレジストリを利用することで、共同作業を行っている研究者達は同僚が再現可能な方法でプロジェクトリポジトリに送信した分析ソリューションを実行することができます。また、既存の環境で引き続き構築することも可能です。研究者は継続的なデプロイパイプラインを設計することで、Docker を有効にしたワークフローを実行することもできます。つまり、クラウドを有効にしたコンソーシアムイニシアティブは、幅広いリサーチコミュニティで精密医療分野における科学的発見を促進させながら、プロジェクトを実施する上でデータセキュリティや再現性を持つ、科学的発見が自然に必要とするプラットフォームをサポートすることも可能にしたモデルの役割を担っているのです。
— Mia D. Champion, Ph.D.