Amazon Web Services ブログ
マネージドサービスを活用した機械学習のためのCI/CDパイプラインの構築
この投稿は株式会社ブレインパッドのエンジニアである 小杉 知己 氏に、自社で取り組まれた機械学習のための CI/CD パイプライン構築についてご紹介頂き、AWS 社員と共著したものとなります。
はじめに
機械学習 (ML) のビジネスにおける活用はますます加速しています。しかし、MLプロジェクトの初期段階における概念実証 (PoC) フェーズを乗り越え、MLを本番環境において運用するには多くの課題があることが知られています。例えば、運用中のデータの質の変化に対応するためにMLモデルの再訓練を行う必要が出てきたとき、さまざまなモデルのバージョンをいかに管理するかが課題となります。また、作ったモデルの本番適用可否の判断を効率的に行うためにはライフサイクルの管理が必要となります。
AWSは、機械学習プロジェクトを効率化するフルマネージドなプラットフォームであるAmazon SageMakerを提供しています。本記事では、株式会社ブレインパッドがお客様の機械学習プロジェクトをご支援される際に、いわゆるMLOpsのプラクティスを導入し、Amazon SageMakerを中心としたAWSサービスを複数組み合わせて機械学習パイプラインを構築した事例をご紹介します。
今回の事例では、AWS Step Functionsを用いて機械学習パイプラインを構築しています。AWS Step Functions Data Science SDKを使用すると、データサイエンティストの方々が慣れ親しんでいるPythonを利用して、一連の処理のワークフローを定義するための有向非巡回グラフ(DAG)を記述することができます。データの前処理や学習、評価のためにはAmazon SageMakerを、CI/CD パイプライン構築にはAWS CodePipelineなどのCodeシリーズを、機械学習モデルの監視のためにAmazon QuickSightを活用してダッシュボードを構築されました。以下では、機械学習プロジェクトを加速させるために、いかにして要件定義や今回のアーキテクチャーの検討を進めたのか、そしてそれにより得られた価値はどのようなものだったのかご紹介頂きます。
背景
今回ブレインパッドが開発を担当したプロジェクトでは、日本たばこ産業株式会社(以下、JT)が運営するWebサイトにおける会員ユーザの属性(購買実績など)を元にユーザをいくつかのセグメントに分類し、マーケティング施策に活かすことを目的としています。
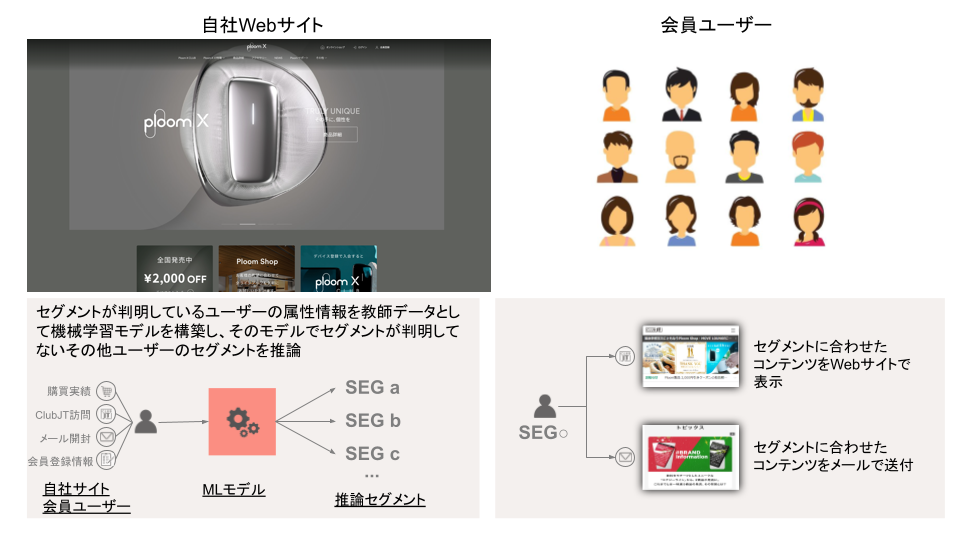
この内容自体は一般的なMLのタスクではありますが、このようなプロジェクトを真に有益なものにするためには企業ごとに抱える特有の課題を克服し、迅速に開発とフィードバックを繰り返す必要があります。これを達成するため、本プロジェクトでは下図のような開発プロセスを導入しています。
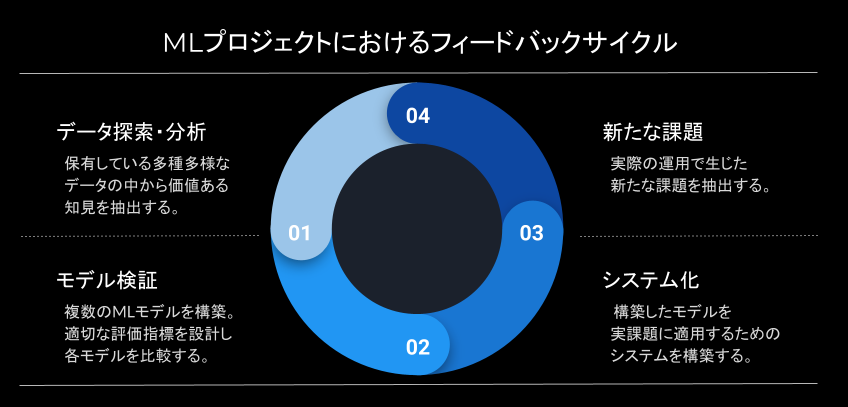
MLプロジェクトにおいて、初期のPoCフェーズで得られたモデルを更新せずに使い続けられることは滅多にありません。データの変化に追従し、実際の運用で得た知見を反映するため、MLを用いたシステムには高いアジリティが求められます。このようなMLの開発プロセスを実現するためには、データサイエンスに対する高いリテラシーと、それを速やかにシステムに落とし込むエンジニアリングが必要になります。
本プロジェクトでは、AWSのフルマネージドなサービスを活用することで、MLの効果を最大限に高めることに集中し開発を進めることができました。また、JTの自社データに対する深い造詣により素早く密度の高い検証が行えたことも、プロジェクトをスムーズに遂行できた大きな要因でした。JTのようにMLプロジェクトを単なるモデル検証だけで終わらせるのではなく、実際のビジネスに活用する開発を含めた部分まで意識することが、プロジェクトを成功させるうえでは必要不可欠になります。
本記事では、本MLプロジェクトにおけるAWSの活用方法にフォーカスを当て記載します。
データ探索・分析・モデル検証
データ探索・分析・モデル検証のフェーズでは、検証を実施する環境としてSageMakerノートブックインスタンスを活用しました。SageMakerノートブックインスタンスはAWSマネジメントコンソール上から簡単な操作でJupyter NotebookやJupyter Labを利用する環境を起動・停止することができます。また、データ量が多いときなどに一時的にハイスペックなインスタンスが必要になった場合も柔軟に変更が可能です。

さらにSageMaker Python SDKを利用することで、重い前処理やモデル学習のプロセスをSageMaker ProcessingやTrainingジョブとしてノートブックから切り出して実行することが可能です。これによりノートブックインスタンスのスペックは低く抑えつつ、必要な時間だけ稼働するジョブとして実行することができ検証中のコスト削減につながります。
また、ジョブとして実行することで実際に稼働したマシンリソース等をAWSマネジメントコンソール上で確認でき、システム化するときに必要なインスタンススペックの見積もりにも繋がります。
SageMakerノートブックインスタンスの便利さについては既に色々なところで話されていると思うので詳細は割愛します。ここでは細かいTipsとしてノートブックインスタンスの停止忘れを防止する方法を紹介します。
Jupyter Notebookではインスタンス内のコンソールで下記のようにAPIを実行すると、各ノートブックの稼働状態(kernel.execution_stateの値)が取得できます。これを利用して定期的にidle状態を監視し、自動停止や通知を送るスクリプトをSageMakerノートブックインスタンスのLifecycle Configurationsに設定すれば、インスタンスの停止忘れを防止することに役立ちます。(aws-samplesリポジトリにサンプルがあります)
sh-4.2$ curl -s -k https://localhost:8443/api/sessions | jq .
[
{
"id": "63878653-9220-425e-90d1-bdbd21260bf2",
"path": "Untitled.ipynb",
"name": "Untitled.ipynb",
"type": "notebook",
"kernel": {
"id": "56f46140-bc18-42c9-a7a0-da597f1202a3",
"name": "conda_python3",
"last_activity": "2021-07-06T15:21:23.367742Z",
"execution_state": "idle",
"connections": 7
},
"notebook": {
"path": "Untitled.ipynb",
"name": "Untitled.ipynb"
}
}
]一口に検証と言ってもデータ探索、仮説検証、適切な評価指標の設計など必要なタスクは数多くあります。それら主要タスク以外の環境構築等に要するコストや労力を最小限に抑えつつ、本来すべきタスクに集中できることが理想です。細かいところにも手が届き、かつ簡単な操作で検証環境が手に入るSageMakerノートブックインスタンスを活用することで検証時のコスト削減や期間短縮につながりました。
システム化
先述の検証フェーズで得られたモデルを自動的に再構築・評価するためのMLパイプラインを構築しました。
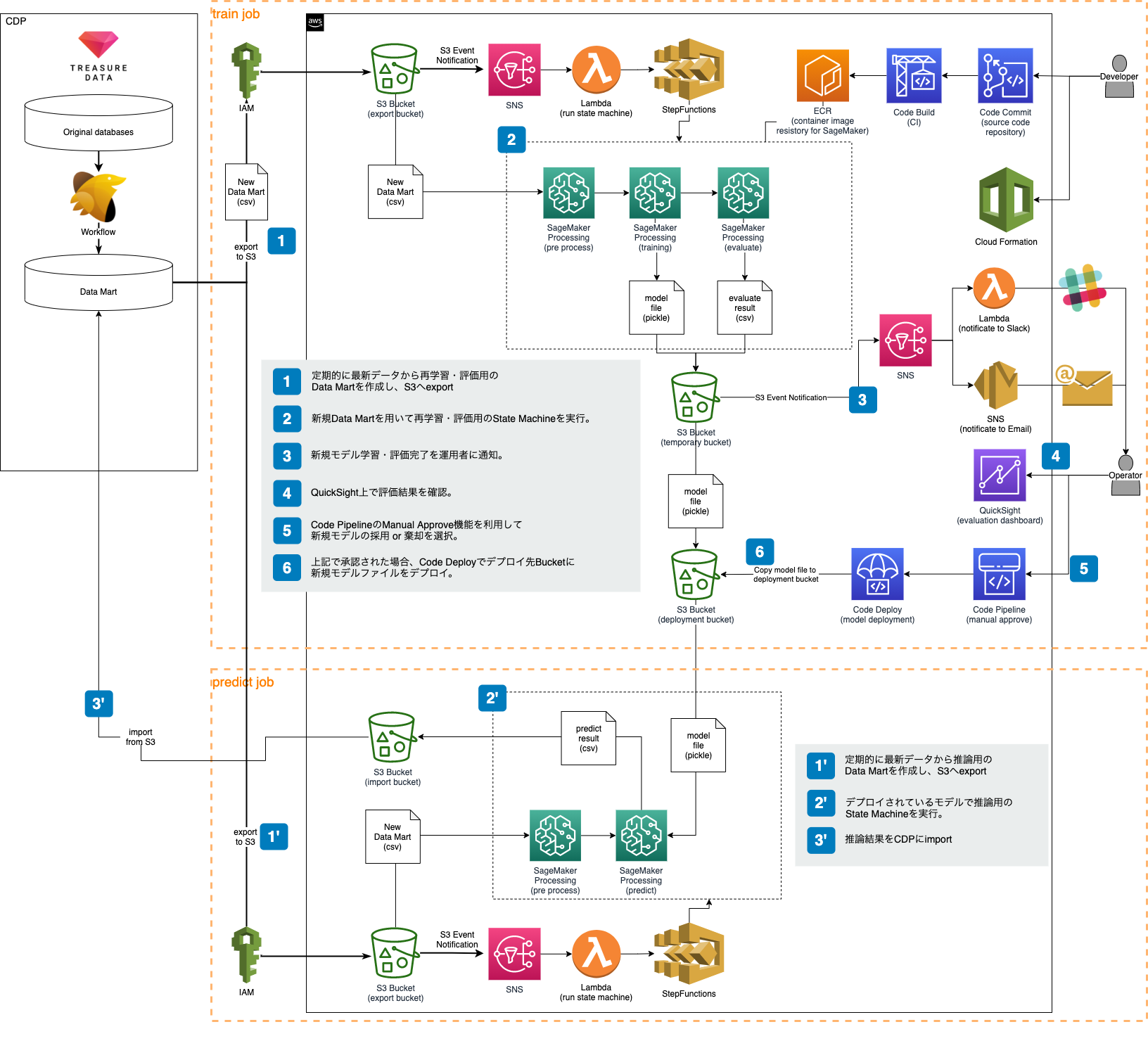
様々なAWSサービスを活用していますが、主要なポイントとしては以下になります。
- フルマネージドサービスを活用することで開発コストを削減
- サーバレスなバッチジョブを実行することでランニングコストを削減
- 運用者が新規モデルについて解釈しやすいUIを提供
本プロジェクトではバッチジョブのみが必要であるため、常時稼働する推論API等は構築していませんが、今後推論APIを構築する場合にもSageMakerエンドポイントをはじめとしたAWSのマネージドサービスを活用して拡張することが選択肢として考えれると思います。
以下にいくつか今回の構築例をピックアップして紹介します。
Step Functions + SageMaker Processing + SAMによるサーバレスなMLパイプライン
MLパイプラインの主要ワークフローはStep FunctionsとSageMaker Processingを用いて構築しました。また、図示はしていませんがStep Functionsのステートマシンにはファイル移動や細かい操作をするためにLambdaも用いています。
今回はこれらをSAM(Serverless Application Model)を用いてデプロイする方法を採用しました。SAMを用いた理由としては以下があげられます。
- LambdaやStep Functionsなどサーバレス系のリソースを簡易な記述で定義可能
- SAMがサポートしていないリソースもCloudFormationの記述で拡張可能
SageMakerのジョブリソースを用いる方法としてはProcessingジョブの他にTrainingジョブやBatch Transformジョブなどがありますが、本プロジェクトでは各アーティファクトをAmazon S3で管理するシンプルな構成であることや、分散処理も不要であったためProcessingにまとめることでコードの記述方法を統一することを選択しました。これによりコードの修正や追加が容易になったと感じます。

CodePipeline + CodeDeploy + QuickSightによるMLモデルのCI/CD
AWS CodePipeline、AWS CodeBuild、AWS CodeDeployはソースコードのCI/CDだけではなく、MLモデルのデプロイにも活用できます。
CDにはContinuous DeliveryとContinuous Deploymentの2種類の方法があります。一般的に、前者は本番環境へのデプロイ前に人手の確認・承認をはさみ、後者は人手を介さない完全な自動デプロイを指すと思います。
MLOpsにも同様の考え方が適用できると思います。つまり、新しいモデルの各評価値や傾向を可視化したうえで人間が確認したうえでデプロイを決定する(Continuous Delivery)を選択するか、機械的に判断し自動デプロイをする(Continuous Deployment)か、ということです。
本プロジェクトでは、CodePipeline、CodeDeploy、QuickSightを利用することでMLモデルのContinuous Deliveryを実現しました。
CodePipelineにはデプロイの前に人手の承認ステージを設ける機能が標準で提供されています。これを利用することにより、簡単にContinuous Deliveryを実現することができます。また、将来Continuous Deploymentに移行したい場合にも同様にCodePipelineとCodeDeployを用いて自動デプロイの仕組みを構築可能です。

また、CodePipelineの承認アクションにはレビュー用のURLを記載可能になっています。
本プロジェクトでは、このレビュー用URLを新しいモデルに対する評価値を可視化したQuickSightのDashboardに設定しました。これによって運用者は、新しいデータでモデルが新規構築された際に整備されたDashboard上でその精度や傾向を簡単に把握することが可能になります。

上図はサンプルですが、QuickSightではこのようなDashboardをGUI上で簡単に作成することができます。今回はMLモデルの各メトリクスを可視化するだけなので本来のBIツールとしての使い方としてはやや邪道かもしれませんが、今後他のデータソースから集計したインサイトも併せて可視化するといった方法も考えられます。MLのメトリクスをQuickSight Dashboardで提供する利点としては以下があげられます。
- 少ない開発コストで充実した可視化が行える
- 要望に応じて柔軟に可視化内容を変更可能
- インフラの管理が不要
- ユーザ管理もQuickSight側で提供されているため開発不要
- 従量課金で小さな規模から使い始めることができるため、今回のように簡単な可視化だけの用途だとしても気軽に利用可能
これらのメリットを享受し、少ない開発コストでMLのCI/CDパイプラインを構築することができました。
まとめ
本記事では株式会社ブレインパッドが機械学習モデルの開発から行い、そのビジネス適用を実現して継続的に運用するためのアーキテクチャーをご紹介いただきました。AWS サービスをご活用頂くことで、開発コストを抑えることができると評価頂けました。
他にも、AWS上のワークロードを設計および実行するための原則をまとめたAWS Well-Architected Frameworkは、MLワークロードの設計や運用手法に焦点を当てた機械学習レンズというベストプラクティス集を提供します。MLモデルデプロイ用のワークフローの参照アーキテクチャーであるAWS MLOpsフレームワークもすぐに利用可能な形で提供されています。こういったリソースを活用いただくことで素早くMLワークロードを構築し、評価することができます。
著者について
 |
株式会社ブレインパッド 小杉 知己 (Tomoki Kosugi) 株式会社ブレインパッドで機械学習・データ活用案件にてデータエンジニアリングやプロトタイプ開発を担当。 データサイエンティストが開発したアルゴリズムを、ユーザーが実際に活用できるような形にして提供します。 |
 |
アマゾン ウェブ サービス ジャパン 機械学習パートナーソリューションアーキテクト 本橋和貴(Kazuki Motohashi) 主に、AWS上で機械学習関連のソリューションを開発しているISV/SaaSパートナー様に対する技術支援をしています。 |
 |
アマゾン ウェブ サービス ジャパン 機械学習 プロトタイプ ソリューションアーキテクト 上総 虎智 (Taketoshi Kazusa) 機械学習 プロトタイプ ソリューション アーキテクトで、機械学習基盤の構築支援を行っています。 |