Amazon Web Services ブログ
AWSとパートナーソリューションによるセキュアなデータメッシュの構築
この記事は Build Secure Data Mesh with AWS and Partner Solutions を翻訳した記事になります。翻訳は Solutions Architect 深見が担当しました。
はじめに
データメッシュは、組織がドメイン間でデータを管理・共有する方法に革命をもたらす変革的なアーキテクチャパラダイムとして登場しています。
データを製品として扱い、ドメインチームに所有権を分散させることで、データメッシュはドメインの自律性を維持しながら、スケーラブルで安全かつ効率的なデータ共有を可能にします。
このブログは、最新のデータメッシュアーキテクチャを実装中または計画中のデータアーキテクトや技術リーダー向けです。
主に AWS とそのパートナーと協力している世界的な金融サービス組織による革新的な実装から着想を得ていますが、ここで議論される原則とソリューションは業界全体に広く適用できます。
金融機関は、ドメイン固有のガバナンスを維持しながら多様な製品にわたる包括的な顧客ビューを作成するために、データメッシュアーキテクチャの採用を増やしています。
これらの組織は、データが伝統的にサイロ化されていた規制環境において独自の課題に直面しています。
今日のソリューションは、Apache Icebergのようなオープンテーブルフォーマット、エンジン間のストレージとコンピュートの分離、クラウドスケールの機能を活用しており、従来のクエリフェデレーションアプローチからの進化を表しています。
最新のデータメッシュアプローチは、エンティティ認証、一貫したアクセス制御、包括的な監査証跡、データ系統追跡を通じて厳格な管理を維持しながら、ストレージレベルでの安全なデータ共有を可能にします。
これにより、チームはセキュリティやコンプライアンス要件を損なうことなく、特定のニーズに最適な専門エンジンを選択できます。
このブログでは、AWS ネイティブの分析サービスとサードパーティエンジンを同時に活用することを目的としたデータメッシュアーキテクチャを実装するための 3 つの重要な要件を探ります:(1)クロスカタログメタデータフェデレーション、(2)クロスアカウント&クロスエンジンでの認証と認可、(3)分散ポリシーの反映
AWS をデータプロデューサーとコンシューマーの両方として実用的な実装パターンを検討し、Databricks や Snowflake などのパートナーとの統合アプローチを代表例として紹介します。
これらのパターンは、組織が企業全体のガバナンスを維持しながら、データメッシュの中核原則をサポートする柔軟で安全かつスケーラブルなデータアーキテクチャをどのように構築するかを示しています。
主な要素
データメッシュ
データメッシュは、中央集権型のデータプラットフォームから分散型のドメイン指向の所有モデルへと移行するアーキテクチャおよび組織的なデータ管理アプローチです。
データを製品として扱い、ドメインチームが生成するデータに責任を持たせます。
例えば、金融機関では、クレジットカード部門が顧客取引データを製品として所有・管理し、明確に定義されたインターフェースとアクセス制御を通じて、不正検出やマーケティング分析などの他部門が安全にアクセスできるようにします。
データメッシュの中核原則には、(1)ドメイン指向の所有権、(2)製品としてのデータ、(3)セルフサービスデータインフラストラクチャ、(4)連合型ガバナンスが含まれます。
詳細については、データメッシュとはおよび Let’s Architect! Architecting a data mesh をご覧ください。
データメッシュでは、データプロデューサーがデータコンシューマーが消費できるようにデータを公開します。
フェデレーテッドガバナンス層 (Federated Governance) がデータへのアクセスを規制します。
コンシューマーとプロデューサーは、AWS ネイティブサービスと AWS パートナープラットフォーム間でデータを共有する必要があります。
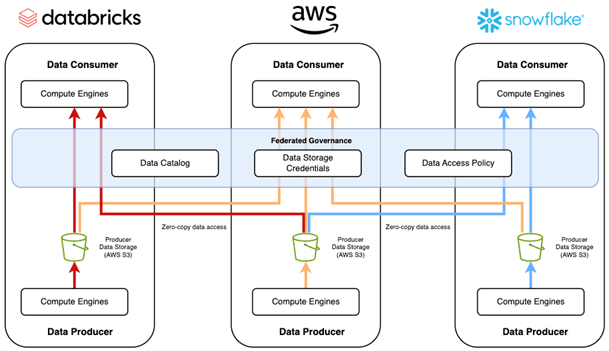
図1. Databricks や Snowflake などの AWS ネイティブサービスと AWS パートナーによるデータメッシュ設計のコンセプトを示しています。AWS と AWS パートナーの両方がデータコンシューマーとデータプロデューサーの役割を果たしています。
Iceberg オープンテーブルフォーマット
Apache Iceberg は、データメッシュアーキテクチャにとって重要なオープンテーブルフォーマットです。
その主な理由は、異なるデータメッシュ環境に不可欠なAmazon Athena、Snowflake、Databricks などの多様なクエリエンジン間で一貫したデータアクセスを可能にするクロスプラットフォーム互換性にあります。
また、コンシューマーに影響を与えることなくスキーマ進化をサポートし、ガバナンスと監査のためのタイムトラベル機能を提供し、ACID トランザクションによるデータ一貫性を維持、プラットフォーム間でのきめ細やかなアクセス制御を可能にします。
これらの機能により、データの整合性とガバナンスを維持しながらドメイン間の相互運用性を確保できます。
Lake Formation
AWS Lake Formation は、分析と機械学習のためのデータを一元的に管理、保護、共有するのに役立ちます。
Amazon Simple Storage Service (Amazon S3) や Amazon Redshift などの様々なデータストアに保存されたデータと AWS Glue Data Catalog 内のメタデータに対するきめ細やかなアクセス制御を提供します。
次世代の Amazon SageMaker
Amazon SageMaker のレイクハウスアーキテクチャは、Apache Iceberg を使用してデータレイクとウェアハウスを 1 つのオープンプラットフォームに統合します。
このレイクハウスは、複数のソースからのデータへの接続、カタログ化、権限管理をスムーズに行います。
AWS Glue Data Catalog と AWS Lake Formation を基盤として構築され、オープンな Apache Iceberg REST API を通じてアクセス可能なカタログを通じてデータを整理し、一貫したきめ細やかなアクセス制御による安全なデータアクセスを提供します。
Amazon SageMaker Unified Studio は、Amazon レイクハウスアーキテクチャの開発環境とオーケストレーション層として機能します。
レイクハウスが Apache Iceberg ベースのデータ基盤を提供する場所であるのに対して、SageMaker Unified Studio は、データサイエンティスト、アナリスト、開発者が AWS サービスと外部パートナープラットフォームの両方のデータをやり取りし操作する場所です。
詳細については、Connect, share, and query where your data sits using Amazon SageMaker Unified Studio ブログを参照してください。
アイデンティティとアクセス制御の管理
金融サービス組織はサイロ化されたデータから、オープンテーブルフォーマット、ストレージとコンピュートの分離、クラウド機能によって可能になったデータメッシュアーキテクチャへと進化してきました。
この変化により、エンティティ認証、一貫したクロスエンジンアクセス制御、包括的な監査、コンプライアンスモニタリング、データ系統追跡を通じて厳格な管理を維持しながら、クエリフェデレーションではなくストレージレベルでの安全なデータ共有が可能になりました。
このアプローチにより、チームは組織のセキュリティとコンプライアンス要件を維持しながら、ケースに適したエンジンを選択できるようになります。
クロスエンジンデータ共有のためのデータメッシュアーキテクチャが進化するにつれて、2 つの重要なセキュリティ要件が浮上します:
- プラットフォーム間で一貫したエンティティ ID
- プラットフォーム間で統一されたアクセス制御
ユーザーとエンジンのアイデンティティ
マルチクエリエンジン環境では、ユーザーとエンジンの両方の ID が不可欠です。
ユーザーはサービス間で一貫した ID(フェデレーション ID プロバイダー、IDP サーバーを通じて管理)が必要である一方、エンジンはユーザーに代わってフェデレーションデータソースに接続する際にシステム ID を必要とします。
エンジンは、シームレスなクロスエンジン操作を可能にしながらセキュリティを維持するために、互いに信頼関係を確立する必要があります。
アクセス制御
ID の確認後、アクセス制御には 2 つの重要な側面が関わります:ポリシー定義(AWS および非 AWS エンジン間で許可されるアクションの指定)とポリシーの反映(定期的な同期を伴うエンジンレベルでの実装)です。
このアプローチにより、データが AWS またはパートナーエンジンのどちらを通じてアクセスされるかに関わらず、一貫したセキュリティが維持されます。
マルチエンジンデータメッシュは、2 つの補完的なアクセス制御モデルを活用します:
- IAM/S3 ポリシーを使用した粗い粒度のアクセス (Coarse-grained access )
- Lake Formation を使用したきめ細やかなアクセス制御(Fine-grained access control: FGAC)
Lake Formation は、データフィルターを持つ名前付きリソースを使用したロールベースのアクセス制御を含む、きめ細やかなアクセス制御での権限管理を行うための様々な権限モデルをサポートしています:
- タグベースのアクセス制御(TBAC):LF-Tags は、類似したリソースをグループ化し、そのリソースグループに対する権限をプリンシパルに付与できるメカニズムで、権限のスケーリングを可能にします。
- 属性ベースのアクセス制御(ABAC):ユーザー属性に基づいてリソースに対する権限を付与できるようになり、コンテキスト駆動型で、特定の属性値に基づく行レベルのフィルタリングなどの精密なセキュリティ対策が可能になります。
実装の成功のためには、ユーザーがデータメッシュとやり取りするためにどのアクセスポイントを使用するかに関わらず、一貫したセキュリティ実施を維持するために、エンジン間で慎重なポリシーの変換が必要です。
データメッシュアーキテクチャにおける相互運用性の要件
データ相互運用性とは、システムが共通ストレージレイヤーからデータを重複なく安全にアクセス、解釈、処理する能力です。
このブログでは、特に AWS が管理するストレージを使用する AWS ネイティブサービスとパートナープラットフォーム間のデータコンシューマーとプロデューサー間の相互運用性に焦点を当てています。
データメッシュ実装のための主要なデータ相互運用性要件:
1. クロスカタログメタデータフェデレーション – フェデレーションメタデータカタログを通じて、組織の境界を越えてドメインデータ製品を発見可能にする
2. クロスアカウント認証と認可 – コンシューマークエリエンジンが適切な権限でプロデューサーデータにアクセスできる安全な認証情報管理の実装
3. 分散ポリシーの反映 – プロデューサー定義のアクセスポリシーをデータコンシューマーポイント全体に適用する一貫したガバナンスメカニズムの確立
図 2 は、データメッシュアーキテクチャにおける権限の粒度の適用を示しています。
これは、データフェデレーションプロセス中にシステムがユーザー ID またはエンジン ID を想定するかどうかに基づいて、粗い粒度ときめ細やかな権限の違いを示しています。
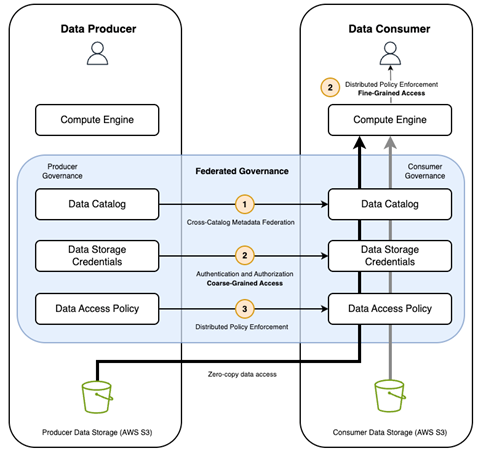 図 2. この図は、データ相互運用性要件がデータメッシュ内のプロデューサーとコンシューマープラットフォーム間の安全な共有をどのように可能にするかを示しています。クロスカタログアクセスはアプリケーション/システム ID を使用して行われ、ユーザー ID のためのエンジンは、コンシューマーカタログで定義されているとおりに FGAC 制御を実施します。
図 2. この図は、データ相互運用性要件がデータメッシュ内のプロデューサーとコンシューマープラットフォーム間の安全な共有をどのように可能にするかを示しています。クロスカタログアクセスはアプリケーション/システム ID を使用して行われ、ユーザー ID のためのエンジンは、コンシューマーカタログで定義されているとおりに FGAC 制御を実施します。
AWS とそのパートナーがどのようにデータメッシュアーキテクチャを構築し、2 つの主要なパターンを通じてデータ相互運用性要件を実装しているかを探ってみましょう:データプロデューサーとしての AWS プラットフォームとデータコンシューマーとしての AWS プラットフォームです。
データメッシュの実装: AWS をデータプロデューサーとして利用する
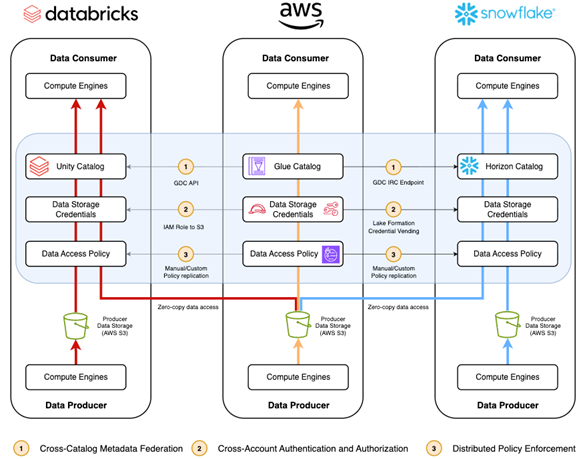
図 3. この図は、データメッシュアーキテクチャにおいてデータプロデューサーとして機能する AWS を示し、AWS ネイティブサービスを使用するプロデューサーから AWS パートナーと AWS ネイティブサービスの両方を使用したコンシューマーへのデータフローを示しています。AWS ネイティブコンピュートエンジンとパートナーコンピュートエンジンの両方が、AWS 管理のデータレイクから直接データを利用しています。
1. クロスカタログメタデータフェデレーション
サードパーティのクエリエンジンは、Lake Formation によって管理される AWS データレイク内のデータを検出・理解するために AWS Glue Data Catalog(GDC)を使用します。
GDC は、スキーマ定義、データ型、場所、その他のメタデータを一貫した方法で維持するための手段を提供します。
Glue Data Catalog へのカタログフェデレーションは、AWS Glue API または AWS Glue Iceberg REST エンドポイント(Glue IRC)のいずれかを介して確立できます。
両方のアプローチが Apache Iceberg テーブルをサポートしていますが、Glue IRC API は統合のための標準的な REST API セットを有効にし、認証と認可のサポートを提供してフレームワークを簡素化します。
2. クロスアカウント認証と認可
サードパーティのクエリエンジンは、Lake Formation 管理の認証情報または S3 への直接アクセス用の IAM プリンシパルロールのいずれかを使用して、GDC カタログで検出されたデータにアクセスします。
Lake Formation 管理の認証情報を利用した提供方法が推奨されるアプローチです。
3. 分散ポリシーの反映
AWS Lake Formation との統合により、サードパーティサービスは Amazon S3 ベースのデータレイク内のデータに完全なテーブルアクセス権限で安全にアクセスできます。
組織は、サードパーティのクエリエンジンがきめ細やかなアクセス制御ポリシーを実施できるように、手動のポリシー共有や追加のメカニズムでこれを補完する必要があります。
| 機能 | Lake Formation 認証情報 | S3 用の IAM プリンシパル |
| 目的 | データレイクアクセス管理 | AWS リソースのアクセス制御 |
| 粒度 | きめ細やかな粒度(テーブル/列/行) | 粗い粒度(バケット/プレフィックス/オブジェクト) |
| 管理 | Lake Formation で一元化 | IAM と S3 バケットポリシー |
| IAM/S3 ポリシー | Lake Formation の制御が適用される | アクセスを直接制御 |
| ユーザーエクスペリエンス | S3 権限の直接管理が不要 | 明示的な S3 権限が必要 |
| 統合 | AWS とサードパーティのアプリケーション | アプリケーション/ユーザーの直接アクセス |
表 1. この表は、S3 ロケーションにアクセスするための Lake Formation による認証情報の提供(推奨アプローチ)と IAM プリンシパルロール方式を比較しています。
データコンシューマーとして利用する際のパートナー製品特有のデータ相互運用性機能
Databricks をコンシューマとして利用する場合
1. クロスカタログメタデータフェデレーション
Databricks Lakehouse Federation を使用すると、組織は外部データシステムを Lakehouse 拡張としてクエリおよび統制管理ができます。
GDC に接続する際、Databricks は Iceberg REST カタログエンドポイントではなく、メタデータの検出とフェデレーションのために GDC API を使用します。
詳細については、Unity Catalog における Hive Metastore と AWS Glue フェデレーションの一般提供開始のお知らせを参照してください。
2. クロスアカウント認証と認可
データアクセス権限については、Databricks は Lake Formation の認証情報提供メカニズムではなく、従来のクロスアカウント IAM ロールベースのアクセスパターンを使用して S3 データにアクセスします。
顧客は、フェデレーションする各テーブルについて、Unity Catalog に S3 バケットストレージを明示的に登録する必要があります。
3. 分散ポリシーの反映
Databricks で Lake Formation のきめ細やかなアクセス制御を複製するには、Lake Formation からアクセスポリシーを抽出し、それらを同等の Databricks Unity Catalog の権限に変換する同期メカニズムが必要です。
これらのきめ細やかなアクセスポリシーは、手動で複製するか、両システムを同期させるカスタムビルドソリューションを介して複製することができます。
Snowflake をコンシューマとして利用する場合
1. クロスカタログメタデータフェデレーション
AWS Glue Data Catalog から Snowflake Horizon カタログへのクロスカタログメタデータフェデレーションを実装するために、Snowflake はカタログ統合を使用します。
AWS Glue と統合するために、Snowflake はカタログ提供の認証情報などの追加の Iceberg テーブル機能をサポートする AWS Glue Iceberg REST エンドポイントのカタログ統合を作成することを推奨しています。
詳細については、Apache Iceberg Rest Catalog (IRC) のカタログ統合に関する追加情報を参照してください。
2. クロスアカウント認証と認可
Snowflake Horizon カタログと AWS GlueのIceberg REST エンドポイントの統合は、Lake Formation による認証情報の提供機能(現在は粗い粒度のみ)をサポートしています。詳細については、Apache Iceberg™テーブルのカタログ提供の認証情報を使用するを参照してください。
3. 分散ポリシーの反映
Snowflake で Lake Formation のきめ細やかなアクセス制御を複製するには、Lake Formation からアクセスポリシーを抽出し、それらを同等の Snowflake Horizon カタログの権限に変換する同期メカニズムが必要です。これらのきめ細やかなアクセスポリシーは、手動で複製するか、両システムを同期させるカスタムビルドソリューションを介して複製することができます。
| パターン | 要件 | 統合機能 |
| コンシューマーとしての Databricks(プロデューサーとしてのAWS) | 1. カタログフェデレーション | UC から GDC へのフェデレーション |
| 2. データストレージ権限 | S3 への IAM ロールアクセス
(L F認証情報のサポートなし) |
|
| 3. データポリシーの反映 | カスタムプロセスを介して複製され、Databricks によって実施されるきめ細やかなポリシー | |
| コンシューマーとしての Snowflake(プロデューサーとしてのAWS) | 1. メタデータフェデレーション | CREATE CATALOG INTEGRATION(Apache Iceberg™ REST) |
| 2. データストレージ権限 | Apache Iceberg™ のカタログ提供の認証情報を使用する(テーブル全体へのアクセス権を持つ Lake Formation 認証情報を使用) | |
| 3. データポリシーの反映 | カスタムプロセスを介して複製され、Snowflake によって反映される FGACポリシー |
表2. この表は、AWSをデータプロデューサーパターンとして実装する際に、AWS 管理のデータレイクとのデータ相互運用性を可能にする Databricks と Snowflake が提供する統合機能をまとめたものです。
データメッシュの実装: AWS をデータコンシューマーとして利用する
図4は、データプロデューサーとしてAWS パートナープラットフォームを使用する際に AWS ネイティブ分析サービスを使用たデータコンシューマーへのデータの流れを示しています。
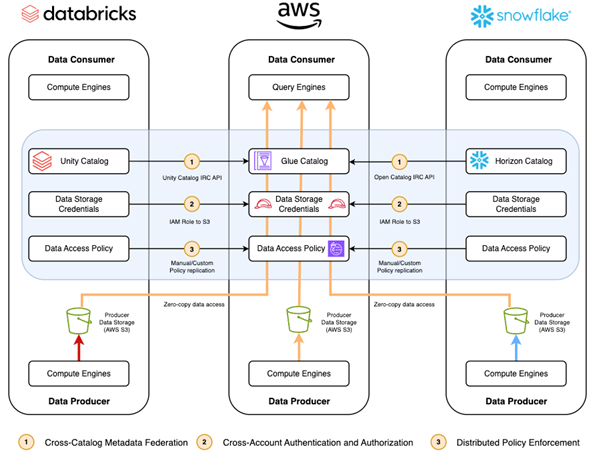
図4. この図は、データメッシュアーキテクチャにおいてデータコンシューマーとして機能するAWSプラットフォームを示しています。AWS ネイティブコンピュートは、AWS 管理のデータレイクとパートナーが管理するストレージからデータを消費します。
データコンシューマーとしての AWS ネイティブデータ相互運用性機能
1. クロスカタログメタデータフェデレーション
AWS Glue は現在、リモート Iceberg へのカタログフェデレーションをサポートしています。この機能により、AWS Glue Data Catalog を Databricks Unity Catalog、Snowflake Polaris カタログ、Horizon カタログ、およびカスタム Iceberg REST カタログ実装とフェデレーションを設定することができます。統合後、AWS Glue はバックグラウンドでメタデータの同期を自動的に管理し、クエリ結果にリモートカタログからの最新のテーブル変更が反映されるようにはたらきます。フェデレーションされたテーブルは、Amazon Redshift、Amazon EMR、Amazon Athena、AWS Glue などの AWS 分析エンジンを使用して検出およびクエリが可能です。
2. クロスアカウント認証と認可
Lake Formation は、AWS ネイティブサービスがデータレイクアクセスに使用するのと同じアプリケーション統合プロセスを使用して、フェデレーションソースにデータガバナンスを拡張します。カタログフェデレーションは、フェデレーションデータソースに対して Lake Formation のきめ細やかなアクセス制御を使用します。
ユーザーが Athena などの AWS コンピュートサービスにクエリを送信すると、AWS ネイティブサービスはアクセス権限を確認して認証情報を取得するためにリクエストを Lake Formation に転送します。認可されると、Lake Formation はこれらの認証情報を AWS ネイティブサービスに提供し、Amazon S3 で要求されたデータにアクセスできるようにします。フェデレーションテーブルにクエリを実行する際、AWS Glue はクエリ時にリモートカタログから現在のメタデータを検出し、Lake Formation は S3 バケットに格納されたテーブルデータへのスコープ付き認証情報を提供してアクセスを管理します。その後、AWS ネイティブサービスは取得したデータにポリシーベースのフィルタリングを適用してから、結果をユーザーに返します。
3. 分散ポリシーの反映
Lake Formation は、フェデレーション 対象のIceberg カタログに対する包括的アクセス制御を提供し、データ所有者が AWS アカウント間でフェデレーションテーブルを共有する際に列、行、セルレベルの権限を付与できるようにします。Lake Formation は、フェデレーションカタログのデータベース/テーブル/列に対するタグベースのアクセス制御(TBAC)もサポートしており、組織は個々のリソースポリシーを管理するのではなく、リモートカタログオブジェクトにタグを適用することでガバナンスを効率化できます。ただし、組織はサードパーティプラットフォームから Lake Formation へのきめ細やかなアクセス制御を同期するための補完的なポリシー共有または追加のメカニズムを実装する必要があります。
データプロデューサーとしてのパートナー固有のデータ相互運用性機能
Databricks
1. クロスカタログメタデータフェデレーション
Unity Catalog は OpenAPI 仕様に従って構築され、Apache 2.0 ライセンスで、複数の API 標準を通じて幅広い互換性を提供しています。製品の詳細についてはUnity Catalog のオープンソース化をご覧ください。
Databricks は Unity REST API と Apache Iceberg REST カタログを使用して Unity Catalog テーブルへのアクセスを提供しています。具体的な手順については、Apache Iceberg クライアントから Databricks テーブルにアクセスするとUnity Catalog への外部データアクセスを有効にするを参照してください。
2. クロスアカウント認証と認可
Unity Catalog の認証情報提供メカニズムにより、ユーザーは外部クライアントが Databricks によって管理されるデータ上の権限を継承するように構成できます。Iceberg と Delta の両方のクライアントが認証情報提供メカニズムの利用をサポートしています。AWS 固有の手順については、外部システムアクセスのための Unity Catalog 認証情報提供、外部システムを使用した Databricks データへのアクセスおよびサービス認証情報の作成方法を参照してください。
データアクセス権限については、Glue Data Catalog は Unity 認証情報提供メカニズムではなく、従来のクロスアカウント IAM ロールベースのアクセスパターンを使用して S3 データにアクセスします。顧客は、Lake Formation が一時的な認証情報提供を管理できるように、フェデレーションの一部として S3 バケットストレージへの権限を明示的に設定する必要があります。
3. 分散ポリシーの反映
Databricks Unity Catalog のきめ細やかな制御を Lake Formation で複製するには、Unity Catalog ポリシーを抽出し、同等の Lake Formation 権限に変換する同期メカニズムが必要です。組織はこれを手動でのポリシー複製または両方のガバナンスシステム間で継続的な同期を維持するカスタムソリューションの開発のいずれかを通じて実装します。
Snowflake
1. クロスカタログメタデータフェデレーション
Snowflake Open Catalog は、オープン API を通じてあらゆる Iceberg テーブルメタデータを公開することで、サードパーティのクエリエンジンとの相互運用性をサポートするように設計されています。これにより、外部エンジンがメタデータにアクセスして Snowflake Open Catalog に格納されているデータをクエリでき、フェデレーションデータアクセスアプローチをサポートします。さらに、Horizon カタログは、外部クエリエンジンを使用して Iceberg テーブルを読み取ることができる Apache Iceberg™ REST API を公開しています。Snowflake Open Catalog は Apache Polaris の管理バージョンですが、顧客はApache Polaris を直接セルフホストすることもできます。詳細については、Snowflake Open Catalog の使用開始を参照してください。
2. クロスアカウント認証と認可
Snowflake Open Catalog 認証情報提供メカニズムは、Open Catalog メタデータと Apache Iceberg テーブルストレージロケーションの両方のアクセス管理を一元化します。有効にすると、Open Catalog はクエリエンジンにテーブルデータにアクセスするための一時的なストレージ認証情報を提供し、ストレージアクセスを個別に管理する必要性を排除します。具体的な手順については、Snowflake Open Catalog 認証情報提供と外部カタログの認証情報提供を有効にするを参照してください。
単一の Horizon カタログエンドポイントを使用して新規または既存の Snowflake アカウントで Snowflake の Iceberg テーブルにクエリを実行し、クエリエンジンにテーブルデータにアクセスするための一時的なストレージ認証情報を提供します。Snowflake Horizon カタログを通じて外部エンジンで Apache Iceberg™ テーブルにクエリを実行するを参照してください。
データアクセス権限については、GDC は Snowflake 認証情報提供メカニズムではなく、クロスアカウント IAM ロールベースのアクセスパターンを使用して S3 データにアクセスします。顧客は、Lake Formation が一時的な認証情報提供を管理できるように、フェデレーションの一部として S3 バケットストレージへの権限を明示的に設定する必要があります。
3. 分散ポリシーの反映
Snowflake のきめ細やかなアクセス制御を Lake Formation へ複製するには、Snowflake からアクセスポリシーを抽出し、同等の Lake Formation 権限に変換する同期メカニズムが必要です。これらのきめ細やかなアクセスポリシーは、手動で複製するか、両システムを同期させるカスタムビルドソリューションを介して複製することができます。
| パターン | 要件 | 統合機能 |
| プロデューサーとしての Databricks (コンシューマーとしての AWS) | 1. カタログフェデレーション | AWS Glue カタログフェデレーションから Unity Catalogへ |
| 2. データストレージ権限 | S3 アクセス用の IAM ロール | |
| 3. データポリシーの反映 | FGAC ポリシーは手動またはカスタムロジックを介して Lake Formation に複製され、実施される | |
| プロデューサーとしての Snowflake (コンシューマーとしての AWS) | 1. メタデータフェデレーション | AWS Glue カタログフェデレーションで Open Catalog または Horizon Catalog IRC API を使用 |
| 2. データストレージ権限 | S3 アクセス用の IAM ロール | |
| 3. データアクセスポリシー | FGAC ポリシーは手動またはカスタムロジックを介して Lake Formation に複製され、実施される |
表3. この表は、AWSをデータコンシューマーパターンとして実装する際に、Databricks とSnowflake とのデータ相互運用性を可能にする AWS が提供する統合機能をまとめたものです。
結論
データメッシュアーキテクチャを成功させるには、3つの重要な相互運用性要件に対応する必要があります:クロスカタログメタデータフェデレーション、クロスアカウント認証と認可、そして分散ポリシーの反映です。Apache Iceberg のようなオープンテーブルフォーマットをサポートするパートナーは組織が柔軟で安全かつスケーラブルなデータアーキテクチャを構築できるような補完的な機能を提供しますが、さらに AWS Lake Formation を利用することでデータメッシュ実装のための堅牢な基盤を構築することが可能です。これらのパターンを、Databricks と Snowflake を代表例として使用して実証ました。
Apache Iceberg は、データメッシュアーキテクチャを検討している組織にとって、テーブルフォーマットとして説得力のある利点を提供します。そのクロスプラットフォーム互換性により、異なるクエリエンジン間で一貫したデータアクセスが可能になり、簡素化された認証/認可による効率的な統合オプションを提供します。また、このフォーマットは、スキーマ進化、タイムトラベル機能、ACID トランザクションなどの価値ある機能をサポートしており、分散所有権シナリオでデータの整合性を維持するのに役立ちます。これらの特性により、データメッシュアプローチの実装を検討しているチームにとって、Iceberg は評価する価値があります。
クロスカタログメタデータフェデレーションを実装するために、AWS とパートナーの機能を活用して分散データ資産の統合ビューを作成し、ドメイン所有権を維持しながらデータ発見をシームレスにします。この重要なバランスにより、金融サービス組織は従来のデータサイロを解消しながら、革新のスピードと規制遵守の両方を維持することができます。
最後に、チームはデータメッシュを実装する前に組織全体で標準化されたポリシー定義を確立するべきです。プラットフォーム間(AWS Lake Formation、Databricks、Snowflakeなど)で変換できるセキュリティポリシーの共通フレームワークを作成することで、ドメインチームが自分たちのデータ製品を管理する自律性を許容しながら、一貫したガバナンスを維持します。ポリシー標準化は重要な焦点領域であり、共通ポリシー定義フォーマットの確立とクロスエンジンポリシー変換の改善に向けた取り組みが進められています。これらの技術が成熟するにつれて、組織は安全でスケーラブルなデータメッシュアーキテクチャを自信を持って構築し、ドメインチームがデータプロダクトを所有しながら、データエコシステム全体にわたる企業全体のガバナンスと相互運用性を維持することができます。