Amazon Web Services ブログ
知的なフィジカル AI 構築: Strands Agents、Bedrock AgentCore、Claude4.5、NVIDIA GR00T、および Hugging Face LeRobot によるエッジからクラウドへ
エージェンティック AI システムは急速にデジタル世界を超えて物理世界へと拡大しており、AI エージェントは実際の物理環境で知覚、推論、および行動をとります。AI システムがロボティクス、自律走行車、およびスマートインフラストラクチャを通じて物理世界とますます相互作用するにつれて、根本的な疑問が浮かび上がります:複雑な推論のために大規模なクラウドコンピューティングを活用しながら、物理的な感知と作動に対してミリ秒レベルの応答性を維持するエージェントをどのように構築するのでしょうか?
2025年は、AWS におけるエージェンティック AI にとって変革的な年でした。私たちは2025 年 5 月に Strands Agents を立ち上げ、シンプルな開発者エクスペリエンスとモデル駆動型アプローチをエージェント開発にもたらしました。7 月には、マルチエージェントオーケストレーション機能を備えたバージョン 1.0 をリリースし、Amazon Bedrock AgentCore を導入して、あらゆる規模で AI エージェントを本番環境に迅速に展開できるようにしました。re:Invent 2025 では、TypeScript SDK、評価、音声エージェント用の双方向ストリーミング、およびルール内にエージェントを誘導するためのステアリングを追加して Strands を拡張しました。今日、私たちはこれらの機能がエッジやフィジカル AI にどのように拡張されるかを探っています。そこでは、エージェントは単に情報を処理するだけでなく、物理的な世界で私たちと共に働きます。

デモンストレーションの完全なコードは以下で見つけることができます:
これらのデモンストレーションでは、フィジカル AI エージェントが統一された Strands Agents インターフェースを通じて 2 つの非常に異なるロボットを制御します。このインターフェースは AI エージェントを物理的なセンサーやハードウェアに接続します。3D プリントの SO-101ロボットアームは、NVIDIA GR00T ビジョン言語アクションモデル(VLA)を使用して操作を処理します。「果物を拾ってバスケットに入れる」というコマンドにより、リンゴを識別し、それを把持してタスクを完了します。一方、Boston Dynamics Spot 四足歩行ロボットは、移動と全身制御を扱います。「センサーを点検する」というコマンドにより、Spot はセンサーが下側にあることを理解し、自律的に座って側面に転がってセンサーにアクセスします。両方のデモンストレーションは NVIDIA Jetson エッジハードウェア上で実行され、組み込みシステム上で直接実行できる高度な AI 機能を示しています。
エッジとクラウドの連続性
フィジカル AI アプリケーションは、インテリジェントシステムを構築する方法に影響を与えるトレードオフを明らかにします。ボールをキャッチするロボットアームを考えてみましょう。ボールを見てグリッパーの位置を調整する瞬間は、ミリ秒単位で行われなければなりません。最速の接続であっても、クラウドサービスへのネットワーク遅延はこれを不可能にします。推論は、物理的な現実が要求するほぼ瞬時の応答時間で、デバイス自体のエッジで行われなければなりません。しかし、同じロボットシステムはクラウドの機能から非常に大きな恩恵を受けます。複数のステップからなる組立作業の計画、他のロボットとの連携、または何千もの類似ロボットの集合的な経験から学ぶことは、クラウドのみが提供する計算規模を必要とします。Anthropic Claude Sonnet 4.5 のようなモデルは、ロボットが複雑なタスクを理解し実行する方法を変革する推論能力をもたらしますが、エッジハードウェアで実行するには大きすぎます。これは Daniel Kahneman の System 1 and System 2 thinking を反映しています – エッジは速い本能的な反応を提供し、クラウドは慎重な推論、長期的な計画、そして継続的な学習を可能にします。最も有能なフィジカル AI システムは、両者をシームレスに連携させて使用します。
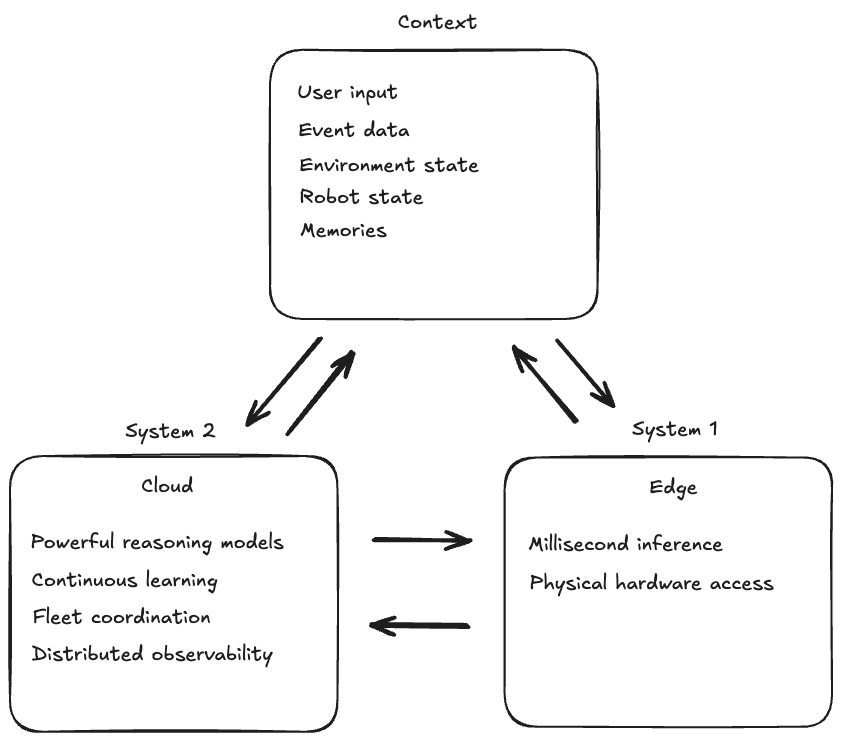
クラウドは、エッジでは実現不可能な追加機能を可能にします。AgentCore Memory は、何が起こったかだけでなく、どこでいつ起こったかを覚えておく、時間的および空間的コンテキストを数時間または数日間維持できます。学習は個々のデバイスにサイロ化されるのではなく、全デバイスにわたって収集され適用できます – 1 つのロボットがより良いアプローチを発見すると、その知識は共有メモリを通じてすべてのロボットが利用できるようになります。Distributed observability は全デバイスにわたって提供され、AI エージェントとロボットが大規模に展開されたときに何をしているかを理解する能力を提供し、単一のデバイスでは生成できない洞察を提供します。Amazon SageMaker は、モデルの大規模な並列シミュレーションとトレーニングを可能にし、組織が実世界およびシミュレーションされた展開からの学習を改善されたモデルに適用して、全デバイスに利益をもたらすことを可能にします。
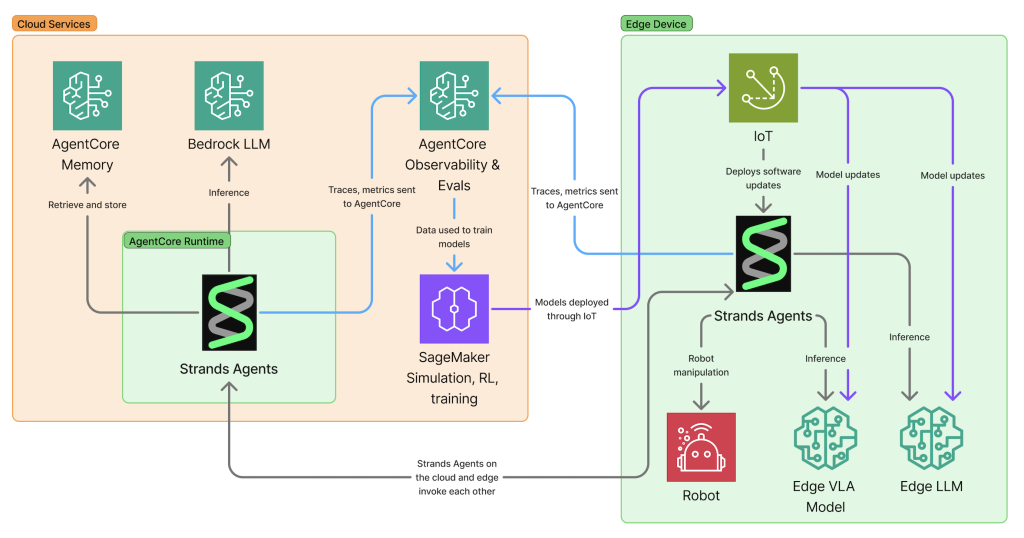
このハイブリッドアーキテクチャは、まったく新しいカテゴリーのインテリジェントシステムを可能にします。ヒューマノイドロボットは、クラウドベースの推論を使用して複数のステップからなるタスクを計画し、エッジベースのビジョン-言語-アクションモデルで正確な物理的な動きを実行します。クラウドエージェントは「朝食を準備する」ことを計画し、それをステップに分解し、あなたが好むものを覚えているかもしれませんが、エッジ VLA モデルはイチゴをつぶさずにつかむためのミリ秒レベルの制御を処理します。自律走行車は、ルート最適化と交通予測にクラウドインテリジェンスを活用しながら、エッジでリアルタイムの障害物回避を維持します。車両は歩行者を避けるためにクラウドの応答を待つことはできませんが、都市全体の交通パターンのクラウドベースの分析から恩恵を受けます。
コードを通じた進歩的なジャーニー
エッジおよびフィジカル AI システムの構築には、エッジとクラウドのオーケストレーションの完全な複雑さから始める必要はありません。前進の道は、シンプルに始めて、ニーズが成長するにつれて洗練度を高めていく進歩的な反復です。
エッジから始める
まず、エッジデバイスに Strands Agents Python SDK を Ollama と共にインストールし、Qwen3-VL モデルをプルします。Ollama をインストールし、これらのコマンドを実行します:
ollama pull qwen3-vl:2b
pip install 'strands-agents[ollama]'シンプルな出発点は、エッジデバイス上でモデルをローカルに実行することです。Strands の Ollama プロバイダーを使用すると、Qwen3-VL のようなオープンソースモデルをエッジハードウェア上で直接実行できます。Strands はまた、量子化モデルを使用した高パフォーマンス推論のための llama.cpp と、Apple Silicon 上でモデルを実行するための MLX をサポートしています:
from strands import Agent
from strands.models.ollama import OllamaModel
edge_model = OllamaModel(
host="http://localhost:11434",
model_id="qwen3-vl:2b"
)
agent = Agent(
model=edge_model,
system_prompt="You are a helpful assistant running on edge hardware."
)
result = agent("Hello!")フィジカル AI は、テキストの処理だけでなく、物理的な世界を理解する必要があることがよくあります。カメラ入力を介して視覚的理解を追加するのは簡単です – テキストを処理する同じエージェントが今や画像を処理でき、物理的な環境を見ることができます:
def get_camera_frame() -> bytes:
# Example function that returns the current camera frame
with open("camera_frame.jpg", "rb") as f:
return f.read()
result = agent([
{"text": "What objects do you see?"},
{"image": {"source": {"bytes": get_camera_frame()}}}
])
視覚を超えて、エージェントは他のセンサーにアクセスして状態を理解できます。センサー読み取りをツールとしてラップすることで、エージェントは情報に基づいた決定を行うために必要に応じてそれらを動的に呼び出すことができます。バッテリーレベルの読み取りは、エージェントがタスクを続行するか充電に戻るかを決定するのに役立ちます:
@tool
def get_battery_level() -> str:
"""Get current battery level percentage and remaining duration."""
# Example function that returns battery metrics
percentage = robot.get_battery_percentage()
duration = robot.get_battery_duration_minutes()
return f"Battery level: {percentage}%, approximately {duration} minutes remaining"
agent = Agent(
model=edge_model,
tools=[get_battery_level],
system_prompt="You are a robot assistant. Use available tools to answer questions."
)
result = agent("How long until you need to recharge?")
物理的な世界で行動する
フィジカル AI システムは、環境を感知し、何をすべきかを推論し、目標を達成するために物理世界を変えるために行動するという連続的なサイクルに従います。カメラとセンサーを通じた感知については説明しました。今、エージェントが決定を物理的な行動に変換する方法を探ってみましょう。
物理世界で行動するということは、ハードウェアを制御することを意味します。ロボットの関節を回転させるモーター、開閉するグリッパー、移動プラットフォームを駆動する車輪などです。ロボットアームには 6 つの関節があり、それぞれが特定の角度に回転できるモーターで制御されています。オブジェクトを拾うには、ロボットは 6 つの関節を同時に調整し、現在の位置からオブジェクトに到達し、グリッパーの角度を調整し、グリッパーを閉じて持ち上げる必要があります。この調整は、ターゲット関節位置をモーターに送信することで行われ、モーターがロボットの物理構造を動かします。これには 2 つの方法があります:ロボットアクションを直接出力するビジョン-言語-アクションモデルを使用するか、AI が高レベルのコマンドを提供する従来のロボット SDK を使用することです。
NVIDIA GR00T のようなビジョン-言語-アクションモデルは、視覚的知覚、言語理解、行動予測を 1 つのモデルに組み合わせます。カメラ画像、ロボット関節位置、言語指示を入力として取り、新しいターゲット関節位置を直接出力します。
「あなたと同じ色の果物を拾ってバスケットに入れてください」という指示を考えてみましょう。VLA モデルのビジョン-言語バックボーンがまず指示とカメラ画像で見るものを推論し、どのオブジェクトがリンゴで、どれがバスケットかを識別します。ロボットの現在の状態(関節位置)を含めることで、モデルはロボットをリンゴに移動し、その周りでグリッパーを閉じ、バスケットに移動し、放出する新しい関節位置のシーケンスを生成します。モデルはこれをアクションチャンクとして実行します – ロボットがシーンを継続的に観察しながら実行する小さな関節移動のシーケンスです。タスク中に誰かがリンゴを動かした場合、VLA モデルは次のカメラフレームでこれを認識し、リンゴの新しい位置に到達するための修正された関節移動を生成します。
Hugging Face の LeRobot は、ロボットハードウェアの操作を容易にするデータとハードウェアインターフェースを提供します。テレオペレーションまたはシミュレーションを使用してデモンストレーションを記録し、データでモデルをトレーニングし、ロボットにデプロイします。LeRobot のようなハードウェア抽象化と NVIDIA GR00T のような VLA モデルを組み合わせることで、物理世界で知覚し、推論し、行動するエッジ AI アプリケーションを作成します:
@tool
def execute_manipulation(instruction: str) -> str:
"""Execute a manipulation task using your robotics hardware."""
# Example function that runs inference on a VLA model and actuates a robot
while not task_complete:
observation = robot.get_observation() # Camera + joint positions
action = vla.get_action(observation, instruction) # Inference from the VLA model
robot.apply_action(action) # Execute joint movements
return f"Completed: {instruction}"
robot_agent = Agent(
model=edge_model,
tools=[execute_manipulation],
system_prompt="You control a robotic arm. Use the manipulation tool to complete physical tasks."
)
result = robot_agent("place the apple in the basket.")
これにより、自然な役割分担が生まれます。Strands が高レベルのタスク分解を処理し、GR00T がミリ秒レベルの感覚運動制御とリアルタイムの自己修正を処理します。
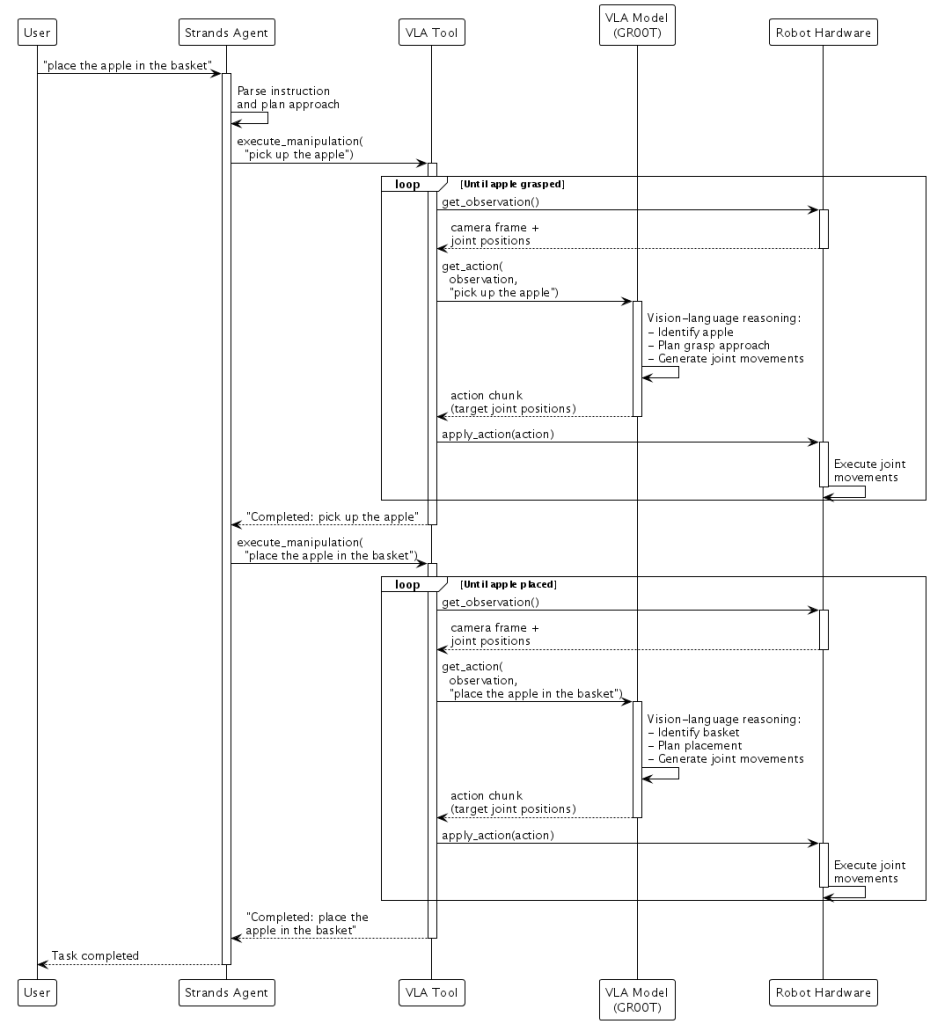
ビルダーにとってこれをより簡単にするために、私たちは NVIDIA GR00T のような VLA モデルとハードウェアを接続するためのシンプルなインターフェースを備えた 実験的なロボットクラス をリリースしました。
from strands import Agent
from strands_robots import Robot
# Create robot with cameras
robot = Robot(
tool_name="my_arm",
robot="so101_follower",
cameras={
"front": {"type": "opencv", "index_or_path": "/dev/video0", "fps": 30},
"wrist": {"type": "opencv", "index_or_path": "/dev/video2", "fps": 30}
},
port="/dev/ttyACM0",
data_config="so100_dualcam"
)
# Create agent with robot tool
agent = Agent(tools=[robot])
agent("place the apple in the basket")
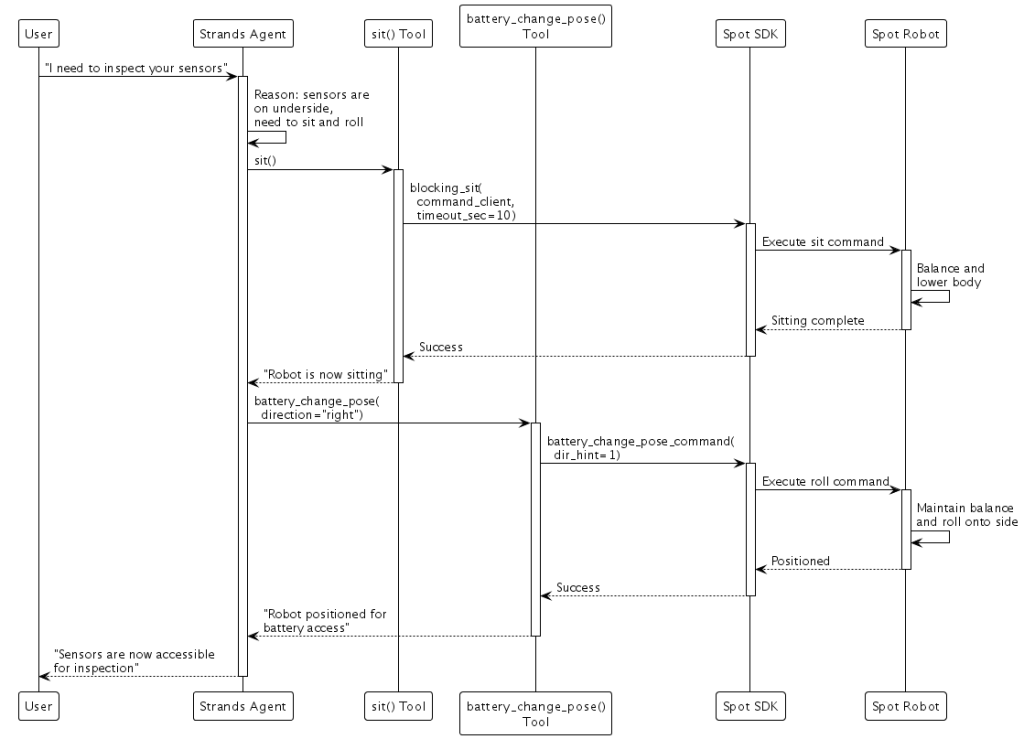
SDK ベースの制御は、ロボットメーカーが堅牢なモーションプリミティブを提供し、テスト済みの制御システムを活用したい場合に適しています。Boston Dynamics Spot では、SDK コマンドを Strands ツールとしてラップします:
from bosdyn.client.robot_command import RobotCommandBuilder, blocking_command, blocking_stand, blocking_sit
@tool
def stand() -> str:
"""Command the robot to stand up."""
blocking_stand(command_client, timeout_sec=10)
return "Robot is now standing"
@tool
def sit() -> str:
"""Command the robot to sit down."""
blocking_sit(command_client, timeout_sec=10)
return "Robot is now sitting"
@tool
def battery_change_pose(direction: str = "right") -> str:
"""Position robot for battery access by rolling onto its side."""
cmd = RobotCommandBuilder.battery_change_pose_command(
dir_hint=1 if direction == "right" else 2
)
blocking_command(command_client, cmd, timeout_sec=20)
return f"Robot positioned for battery access"
spot_agent = Agent(
model=edge_model,
tools=[stand, sit, battery_change_pose],
system_prompt="You control a Boston Dynamics Spot robot."
)
result = spot_agent("I need to inspect your sensors")
「センサーを点検する必要があります」と要求されたとき、エージェントはセンサーがロボットの下側にあると判断し、Spot に座るコマンドとバッテリー交換ポーズを実行するよう指示します。SDK は、ロボットを安全に横向きにするのに必要な複雑なバランスとモーター制御を処理します。
エッジとクラウドの架け橋
エッジエージェントは、必要に応じて複雑な推論をクラウドに委任できます。VLA モデルは物理的なアクションに対してミリ秒レベルの制御を提供しますが、システムがより深い推論を必要とする状況(複数ステップのタスクの計画や過去のパターンに基づく決定など)に遭遇した場合、agents-as-tools パターンを使用して、より強力なクラウドベースのエージェントに相談できます:
from strands import Agent, tool
from strands.models import BedrockModel
from strands.models.ollama import OllamaModel
# Cloud agent with powerful reasoning
cloud_agent = Agent(
model=BedrockModel(model_id="global.anthropic.claude-sonnet-4-5-20250929-v1:0"),
system_prompt="Plan tasks step-by-step for edge robots."
)
# Expose cloud agent as a tool so that it can be delegated to
# using the agents-as-tools pattern
@tool
def plan_task(task: str) -> str:
"""Delegate complex planning to cloud-based reasoning."""
return str(cloud_agent(task))
# Edge agent with local model
edge_agent = Agent(
model=OllamaModel(
host="http://localhost:11434",
model_id="qwen3-vl:2b"
),
tools=[plan_task],
system_prompt="Complete tasks. Consult cloud for complex planning."
)
result = edge_agent("Fetch me a drink")
逆のパターンも同様に強力です。クラウドベースのオーケストレーターは、各エッジデバイスが独自のリアルタイム制御を処理する間、クラウドエージェントが全体的なワークフローを管理することで、複数のエッジデバイスを調整できます:
@tool
def control_robot_arm(command: str) -> str:
"""Control robotic arm for manipulation tasks."""
# Example function that invokes a remote robot arm agent
return str(robot_arm_agent(command))
@tool
def control_mobile_robot(command: str) -> str:
"""Control mobile robot for navigation and transport."""
# Example function that invokes a remote mobile agent
return str(mobile_robot_agent(command))
warehouse_orchestrator = Agent(
model=BedrockModel(model_id="global.anthropic.claude-sonnet-4-5-20250929-v1:0"),
tools=[control_robot_arm, control_mobile_robot],
system_prompt="You coordinate multiple robots in a warehouse environment."
)
result = warehouse_orchestrator(
"Coordinate inventory check: scan shelves, retrieve items, and sort"
)
倉庫では、これはロボットアーム、モバイルロボット、検査ドローンを調整して複雑な在庫タスクを完了することを意味するかもしれません。各デバイスは即時の応答のために独自のエッジインテリジェンスを維持しますが、クラウドオーケストレーションの下で一緒に働きます。
フリート全体での学習と改善
クラウドエージェントが複数のエッジデバイスを調整できることを見てきたように、フィジカル AI システムは、集合的な経験から学び、観察とフィードバックを通じて継続的に改善できるようになるとさらに能力が向上します。
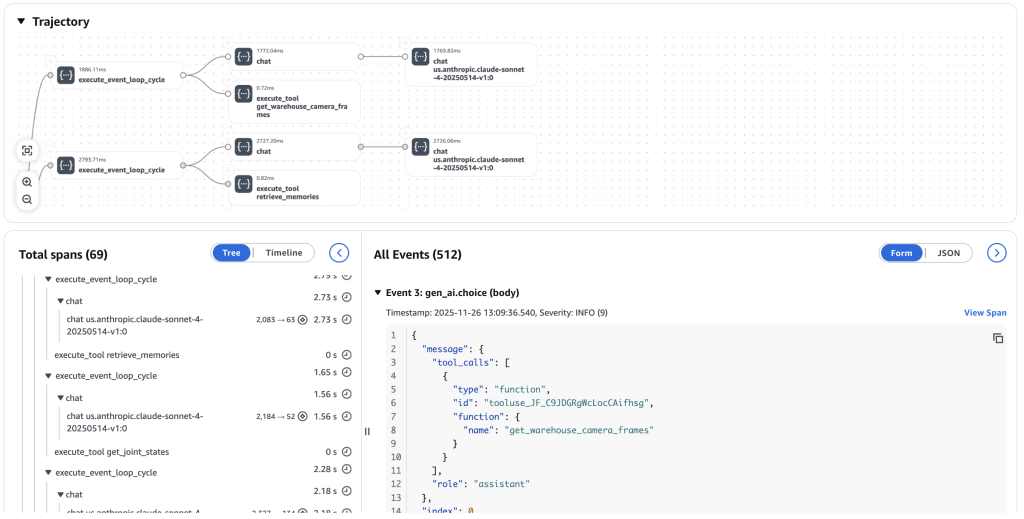
多数のモバイルロボットを持つ倉庫を考えてみましょう。複数のロボットが同じ問題に遭遇すると、単一のロボットでは検出できないパターンが現れます。 AgentCore Memory により、この集合的知性が可能になります – 各ロボットは動作中に観察を共有メモリに保存します:
from bedrock_agentcore.memory import MemoryClient
memory_client = MemoryClient(region_name="us-east-1")
# Robot stores observation after navigation issue
memory_client.create_event(
memory_id=FLEET_MEMORY_ID,
actor_id=robot_id,
session_id=f"robot-{robot_id}",
messages=[
("Navigation failure in north corridor - low confidence in visual localization. "
"Location: north_corridor, light_level: high_contrast", "ASSISTANT")
]
)
フリートコーディネーターは、この共有メモリを照会して、北側の通路における87%のナビゲーション失敗が午後2時から4時の間に発生し、そのときの天窓からの日光がビジョンシステムを混乱させていることを発見することができます。この洞察により、即座に運用変更が行われ、モデル改善につながります。
AgentCore Observability は、推論 → シミュレート/実行 → 観察 → 評価 → 最適化の完全なフィードバックループを通じて継続的な改善の基盤を提供します。CloudWatch の GenAI Observability ダッシュボードは、エッジデバイスからのエンドツーエンドのトレースをキャプチャし、エージェントの実行パス、メモリの取得操作、およびシステム全体のレイテンシーの内訳を明らかにします。この観察データは強化学習のトレーニングシグナルとなり、成功した行動は強化され、失敗は修正に役立ちます。
Amazon SageMaker は、これらの学習を適用するための大規模な並列シミュレーションとトレーニングを可能にします。NVIDIA Isaac Sim や MuJoCo などの物理シミュレーターは、ロボットがデプロイ前に何百万ものシナリオを安全に練習できる現実的な物理環境を提供します。LLM ベースのユーザーシミュレーターを含むデジタルシミュレーターは、エージェントがエッジケースを処理するのに役立つ多様な相互作用パターンを生成します。サイクルは繰り返されます:実際のロボットにデプロイし、行動を観察し、大規模に改善をシミュレートし、更新されたモデルをトレーニングし、フリートに再デプロイします。各反復により、フリート全体がより有能になります。AWS で Isaac GR00T のファインチューニングを使用したスケーラブルなロボット学習パイプラインの設定に関する詳細なウォークスルーについては、embodied AI ブログ投稿シリーズ をご覧ください。
次世代のインテリジェントシステムの構築
この瞬間を興味深いものにしているのは、いくつかの分野で見られる収束です。強力なマルチモーダル推論モデルは物理的なタスクを理解し計画することができ、エッジハードウェアは VLA モデルが物理システムが要求する低レイテンシーでローカルで実行することを可能にし、オープンソースのロボティクスハードウェアはより広いビルダーコミュニティにフィジカル AI 開発を可能にしています。VLA モデルは、ロボットがミリ秒レベルの制御で動的環境を感知し行動することを可能にし、エージェントがシミュレーションと実際の物理的なデプロイメントの両方を通じて改善する継続的な学習ループがクラウド上で実用的になりました。
AWS の目標の一つは、AI エージェント開発を容易なものにすることです。この取り組みは、その目標を物理的な世界にまで拡張します。David Silver と Richard S. Sutton が Welcome to the Era of Experience で説明しているように、AI エージェントは環境での経験から学習し、モデルのトレーニング、チューニング、長期記憶、およびコンテキスト最適化を通じて改善しています。これらのシステムが物理的な世界についてより深く推論する能力を開発するにつれ、行動を起こす前に将来の世界状態をシミュレートし、決定の結果を予測し、より大きなシステムの一部として確実に連携できるようになります。
この急速に成長する分野で、今後数ヶ月間で皆さんが何を作るか楽しみにしています。
今日から始めましょう:
- Strands Agents
- Amazon Bedrock AgentCore
- Amazon SageMaker
- NVIDIA Isaac GR00T
- Hugging Face LeRobot
- SO-101 robot arm
- Boston Dynamics Spot
- Experimental Strands Robot Class
このブログは、Building intelligent physical AI: From edge to cloud with Strands Agents, Bedrock AgentCore, Claude 4.5, NVIDIA GR00T, and Hugging Face LeRobot を、AWSジャパンのソリューションアーキテクト、岩根義忠が翻訳しました。
 |
Arron Bailiss Arron Bailiss はAWSの主任エンジニアで、人工知能、機械学習、ロボット工学の間で働く Agent AI に焦点を当てています。彼は、ビルダーが高度なAI駆動のアプリケーションを作成できるようにする開発者ツールの未来を形作る手助けをしています。 |
 |
Cagatay Cali Cagatay Cali はAWSのリサーチエンジニアで、エージェントAIとロボティクスに注力しています。彼は、AI エージェントを実際のロボットに接続するインターフェースを設計し、開発者が自然言語でロボットシステムを制御できるようにしています。また、エージェントとロボット開発を、あらゆるスキルレベルの構築者が使えるようにしています。 |
 |
Rachita Chandra Rachita Chandra はプロトタイピングソリューションアーキテクトであり、AWS上のワークロードにおいて生成AIおよび機械学習ソリューションの実装に特化しています。彼女の専門知識には、エンタープライズグレードのセキュリティとコンプライアンスを確保しながら、スケーラブルなAIパイプラインを設計することが含まれます。 |
 |
Aaron Su Aaron Su はアマゾン ウェブ サービスのソリューションアーキテクトであり、スタートアップが概念から実際の運用まで AI ソリューションを構築して拡張することを支援しています。彼はフィジカル AI とエージェントシステムに深い情熱を注ぎ、オープンソースプロジェクト、視点のガイダンス、リファレンスアーキテクチャを通じて技術コミュニティに積極的に貢献しています。アーロンは世界中の何百もの起業家を支援し、世界の会議で技術セッションを行っています。彼は起業家およびロボット工学の研究者としての経験を持っています。 |