Amazon Web Services ブログ
Amazon Managed Service for Apache Flink でよく使われるストリーミングデータエンリッチメントパターン
本記事は 2026 年 2 月 13 日 に公開された「Common streaming data enrichment patterns in Amazon Kinesis Data Analytics for Apache Flink」を翻訳したものです。
ストリームデータ処理を使うと、リアルタイムでデータに対してアクションを実行できます。リアルタイムデータ分析により、迅速かつ的確な対応が可能になり、カスタマーエクスペリエンスの向上につながります。
Apache Flink は、ステートフルなリアルタイムデータ処理に対応した分散計算フレームワークです。バッチとストリーミングの両方に対応した統一 API セットを提供しており、有限データと無限データを容易に扱えます。Apache Flink はさまざまなイベント処理ユースケースに対応できるよう、複数の抽象化レベルを提供しています。
Amazon Managed Service for Apache Flink (Amazon MSF) は、Apache Flink アプリケーションを実行するためのサーバーレスインフラストラクチャを提供する AWS サービスです。Apache Flink クラスターの構築・設定・保守の知識がなくても、高可用性でフォールトトレラント、スケーラブルな Apache Flink アプリケーションを容易に構築できます。
データストリーミングワークロードでは、ストリーム内のデータを外部ソース (データベースや他のデータストリームなど) でエンリッチする必要がよくあります。たとえば、GPS デバイスから座標データを受信し、座標を地理的位置に変換したい場合、ジオロケーションデータでエンリッチする必要があります。Amazon MSF では、ユースケースや Apache Flink の抽象化レベルに応じて、リアルタイムデータをエンリッチするためのさまざまなアプローチを利用できます。各手法はスループット、ネットワークトラフィック、CPU (またはメモリ) 使用率に異なる影響を与えます。本記事では、各アプローチの利点と欠点を解説します。
データエンリッチメントパターン
データエンリッチメントとは、収集したデータにコンテキストを追加して強化するプロセスです。追加データはさまざまなソースから収集されることが多く、データの形式や更新頻度は月 1 回から秒単位まで幅広く異なります。以下の表に、さまざまなソース、形式、更新頻度の例を示します。
| データ | 形式 | 更新頻度 |
| 国別 IP アドレス範囲 | CSV | 月 1 回 |
| 企業の組織図 | JSON | 年 2 回 |
| ID 別マシン名 | CSV | 1 日 1 回 |
| 従業員情報 | テーブル (リレーショナルデータベース) | 1 日数回 |
| 顧客情報 | テーブル (非リレーショナルデータベース) | 1 時間に数回 |
| 顧客注文 | テーブル (リレーショナルデータベース) | 毎秒複数回 |
ユースケースに応じて、データエンリッチメントアプリケーションにはレイテンシー、スループットなどの要件が異なります。以降では、Amazon MSF でのデータエンリッチメントパターンを詳しく解説します。以下の表に各パターンの主な特性をまとめています。各特性のトレードオフに基づいて、最適なパターンを選択できます。
| エンリッチメントパターン | レイテンシー | スループット | 参照データ変更時の正確性 | メモリ使用率 | 複雑さ |
| Apache Flink Task Manager メモリへの参照データの事前ロード | 低 | 高 | 低 | 高 | 低 |
| Apache Flink ステートへの参照データのパーティション別事前ロード | 低 | 高 | 低 | 低 | 低 |
| Apache Flink ステートへの参照データの定期パーティション別事前ロード | 低 | 高 | 中 | 低 | 中 |
| レコード単位の非同期ルックアップ (unordered map) | 中 | 中 | 高 | 低 | 低 |
| 外部キャッシュシステムからのレコード単位の非同期ルックアップ | 低〜中 (キャッシュストレージと実装に依存) | 中 | 高 | 低 | 中 |
| Table API を使用したストリームエンリッチメント | 低 | 高 | 高 | 低〜中 (選択した結合演算子に依存) | 低 |
参照データの事前ロードによるストリーミングデータのエンリッチメント
参照データのサイズが小さく静的な場合 (国コードと国名を含む国データなど)、参照データを事前ロードしてストリーミングデータをエンリッチする方法が推奨されます。事前ロードにはいくつかの方法があります。
参照データを事前ロードする各方法のコード実装については、GitHub リポジトリを参照してください。リポジトリの手順に従ってコードを実行し、データモデルを理解してください。
Apache Flink Task Manager メモリへの参照データの事前ロード
最もシンプルかつ高速なエンリッチメント手法は、エンリッチメントデータを各 Apache Flink Task Manager のオンヒープメモリにロードする方法です。この手法を実装するには、RichFlatMapFunction 抽象クラスを拡張した新しいクラスを作成します。クラス定義にグローバルな static 変数を定義します。変数の型は java.io.Serializable を拡張していれば何でもよく、たとえば java.util.HashMap が使えます。open() メソッド内で、定義した変数に静的データをロードするロジックを記述します。open() メソッドは Apache Flink の Task Manager で各タスクの初期化時に必ず最初に呼び出されるため、処理開始前に参照データ全体がロードされることが保証されます。processElement() メソッドをオーバーライドして処理ロジックを実装し、定義したグローバル変数からキーで参照データにアクセスします。
以下のアーキテクチャ図は、Task Manager の各タスクスロットに参照データが完全ロードされる様子を示しています。
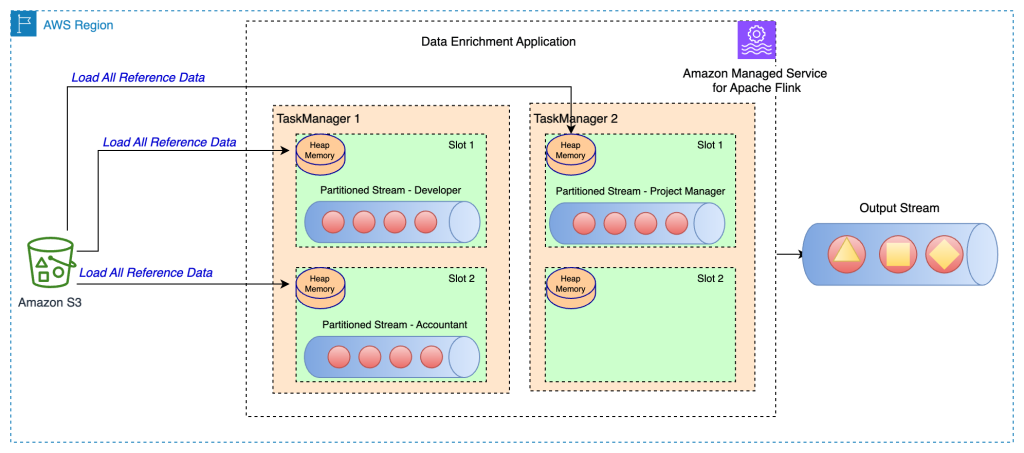
この手法の利点は以下のとおりです。
- 実装が容易
- 低レイテンシー
- 高スループットに対応可能
一方、以下の欠点があります。
- 参照データのサイズが大きい場合、Apache Flink Task Manager がメモリ不足になる可能性がある
- 時間の経過とともに参照データが古くなる可能性がある
- Task Manager の各タスクスロットに同じ参照データの複数コピーがロードされる
- 参照データは単一のタスクスロットに割り当てられたメモリに収まるサイズである必要がある。Amazon MSF では、各 Kinesis Processing Unit (KPU) に 4 GB のメモリがあり、そのうち 3 GB をヒープメモリとして使用できる。Amazon MSF で
ParallelismPerKPUを 1 に設定すると、各 Task Manager で 1 つのタスクスロットが実行され、3 GB のヒープメモリ全体を使用できる。ParallelismPerKPUを 1 より大きい値に設定すると、3 GB のヒープメモリが Task Manager 内の複数のタスクスロットに分散される。Apache Flink を Amazon EMR またはセルフマネージドモードでデプロイしている場合は、taskmanager.memory.task.heap.sizeを調整して Task Manager のヒープメモリを増やせる
Apache Flink ステートへの参照データのパーティション別事前ロード
このアプローチでは、Apache Flink アプリケーションの起動時に参照データを Apache Flink のステートストアにロードして保持します。メモリ使用率を最適化するため、まずメインデータストリームを keyBy() 演算子で指定フィールドに基づいて全タスクスロットに分割します。さらに、各タスクスロットに対応する参照データの部分のみをステートストアにロードします。Apache Flink では、RichFlatMapFunction 抽象クラスを拡張した PartitionPreLoadEnrichmentData クラスを作成して実現します。open メソッド内で ValueStateDescriptor メソッドをオーバーライドしてステートハンドルを作成します。参照例では、ディスクリプタの名前は locationRefData、ステートキーの型は String、値の型は Location です。各パーティションが特定のキーに対する位置参照データのみを保持するため、MapState ではなく ValueState を使用しています。たとえば、Amazon S3 に位置参照データを問い合わせる際、特定のロールで問い合わせて特定の位置を値として取得します。
Apache Flink では、ValueState はキーに対する特定の値を保持するために使用し、MapState はキーと値のペアの組み合わせを保持するために使用します。この手法は、大規模な静的データセットを各パーティションのメモリに全体として収めるのが難しい場合に有効です。
以下のアーキテクチャ図は、ストリームの各パーティションの特定キーに対する参照データのロードを示しています。
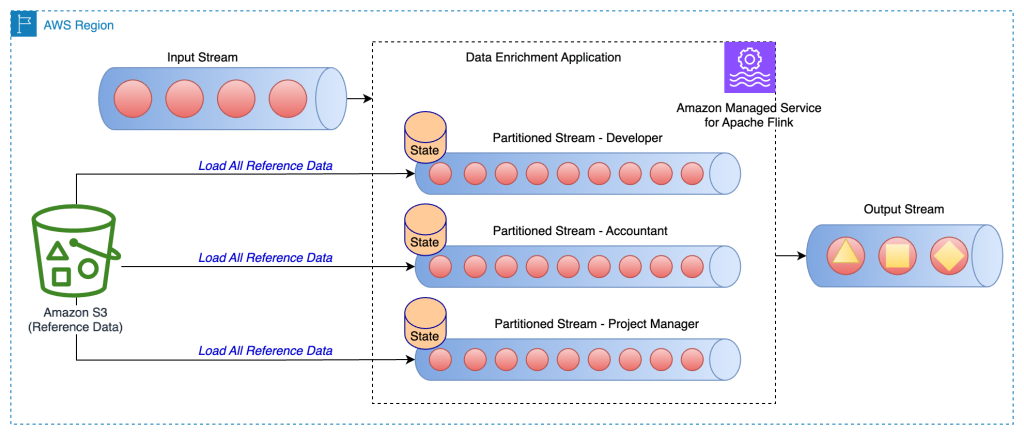
たとえば、サンプル GitHub コードの参照データには、各ビルディングにマッピングされたロールがあります。ストリームはロールでパーティション分割されているため、各パーティションの参照データとして、ロールに対応するビルディング情報のみをロードすれば十分です。この手法の利点は以下のとおりです。
- 低レイテンシー
- 高スループットに対応可能
- 特定パーティションの参照データがキー付きステートにロードされる
- Amazon MSF では、デフォルトのステートストアとして RocksDB が設定されている。RocksDB は各 KPU が提供する 1 GB のマネージドメモリと 50 GB のディスクスペースの大部分を活用できるため、参照データの増大に十分な余裕がある
一方、以下の欠点があります。
- 時間の経過とともに参照データが古くなる可能性がある
Apache Flink ステートへの参照データの定期パーティション別事前ロード
このアプローチは前述の手法を改良したもので、パーティション分割された参照データを定期的にリロードして更新します。参照データがときどき変更される場合に有効です。
以下のアーキテクチャ図は、ストリームの各パーティションの特定キーに対する参照データの定期ロードを示しています。
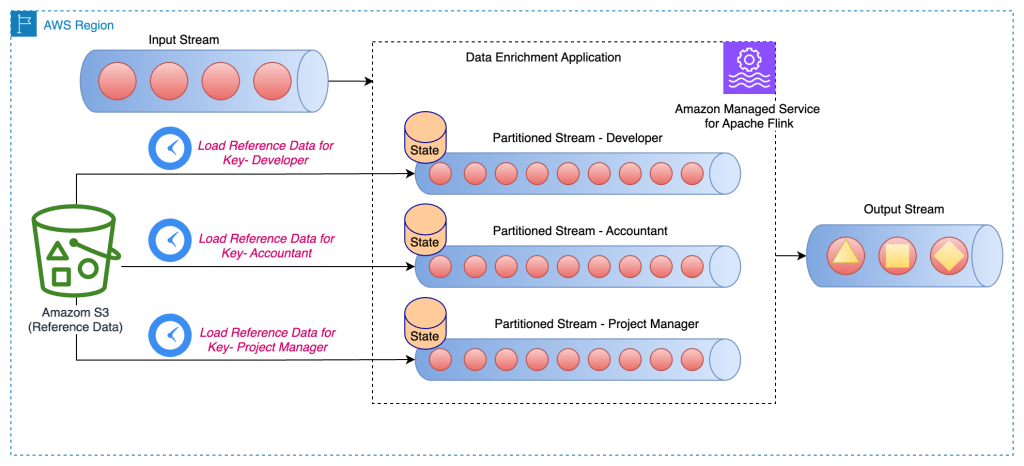
このアプローチでは、KeyedProcessFunction クラスを拡張した PeriodicPerPartitionLoadEnrichmentData クラスを作成します。前述のパターンと同様に、GitHub の例では各パーティションがキーに対する単一の値のみをロードするため、ValueState が推奨されます。前述と同じく、open メソッドで ValueStateDescriptor を定義してバリューステートを管理し、ステートにアクセスするためのランタイムコンテキストを定義します。
processElement メソッド内で、バリューステートをロードし、参照データを付加します (GitHub の例では、buildingNo を顧客データに付加しています)。また、処理時間が指定時間を過ぎたときに呼び出されるタイマーサービスを登録します。サンプルコードでは、タイマーサービスは定期的に (たとえば 60 秒ごとに) 呼び出されるようスケジュールされています。onTimer メソッドで、特定のロールの参照データをリロードしてステートを更新します。
この手法の利点は以下のとおりです。
- 低レイテンシー
- 高スループットに対応可能
- 特定パーティションの参照データがキー付きステートにロードされる
- 参照データが定期的に更新される
- Amazon MSF では、デフォルトのステートストアとして RocksDB が設定されている。また、各 KPU が 50 GB のディスクスペースを提供するため、参照データの増大に十分な余裕がある
一方、以下の欠点があります。
- 参照データが頻繁に変更される場合、ステートのリロード頻度によっては古いデータが残る可能性がある
- 参照データのリロード時に負荷スパイクが発生する可能性がある
レコード単位のルックアップによるストリーミングデータのエンリッチメント
参照データの事前ロードは低レイテンシーと高スループットを実現しますが、以下のようなワークロードには適さない場合があります。
- 参照データが高頻度で更新される
- Apache Flink がビジネスロジックの計算のために外部呼び出しを行う必要がある
- 出力の正確性が重要で、古いデータを使用すべきでない
通常、こうしたユースケースではデータの正確性のために高スループットと低レイテンシーをトレードオフします。以降では、レコード単位のデータエンリッチメントの実装方法と利点・欠点を解説します。
レコード単位の非同期ルックアップ (unordered map)
同期的なレコード単位のルックアップ実装では、Apache Flink アプリケーションはリクエスト送信後にレスポンスを受信するまで待機する必要があります。そのため、プロセッサは処理時間の大部分をアイドル状態で過ごすことになります。代わりに、最初の要素のレスポンスを待つ間にストリーム内の他の要素に対するリクエストを送信できます。待機時間が複数のリクエストに分散されるため、処理スループットが向上します。Apache Flink は外部データアクセスのための非同期 I/O を提供しています。このパターンを使用する際は、unorderedWait (ストリーム上の要素の順序に関係なく、レスポンスを受信次第すぐに次の演算子に結果を出力する) と orderedWait (すべてのインフライト I/O 操作が完了するまで待機し、元の要素がストリームに配置された順序と同じ順序で次の演算子に結果を送信する) のどちらを使用するか決める必要があります。通常、ダウンストリームのコンシューマーがストリーム内の要素の順序を考慮しない場合、unorderedWait の方がスループットが高くアイドル時間が短くなります。このパターンの詳細については、Managed Service for Apache Flink を使用したデータストリームの非同期エンリッチメントを参照してください。
以下のアーキテクチャ図は、Amazon MSF 上の Apache Flink アプリケーションがメインストリームの各イベントに対して外部データベースエンジン (Amazon DynamoDB など) に非同期呼び出しを行う様子を示しています。
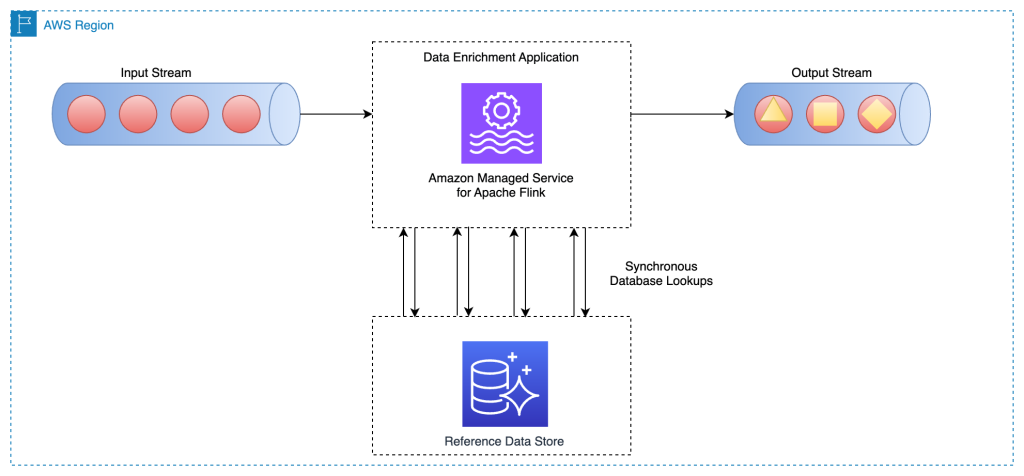
この手法の利点は以下のとおりです。
- 比較的シンプルで実装が容易
- 最新の参照データを読み取れる
一方、以下の欠点があります。
- 参照データをホストする外部システム (データベースエンジンや外部 API など) に大量の読み取り負荷が発生する
- 全体として、低レイテンシーで高スループットが求められるシステムには適さない可能性がある
外部キャッシュシステムからのレコード単位の非同期ルックアップ
前述のパターンを改善する方法として、キャッシュシステムを使用してルックアップ I/O 呼び出しごとの読み取り時間を短縮できます。Amazon ElastiCache をキャッシュに使用すると、アプリケーションとデータベースのパフォーマンスが向上します。また、セッションストア、ゲームのリーダーボード、ストリーミング、分析など、永続性を必要としないユースケースのプライマリデータストアとしても使用できます。ElastiCache は Redis と Memcached に対応しています。
このパターンでは、キャッシュストレージにデータを投入するキャッシュパターンの実装が必要です。アプリケーションの目的とレイテンシー要件に応じて、プロアクティブまたはリアクティブなアプローチを選択できます。詳細については、キャッシュパターンを参照してください。
以下のアーキテクチャ図は、Apache Flink アプリケーションが外部キャッシュストレージ (Amazon ElastiCache for Redis など) から参照データを読み取る様子を示しています。データの変更は、キャッシュパターンのいずれかを実装して、メインデータベース (Amazon Aurora など) からキャッシュストレージにレプリケートする必要があります。
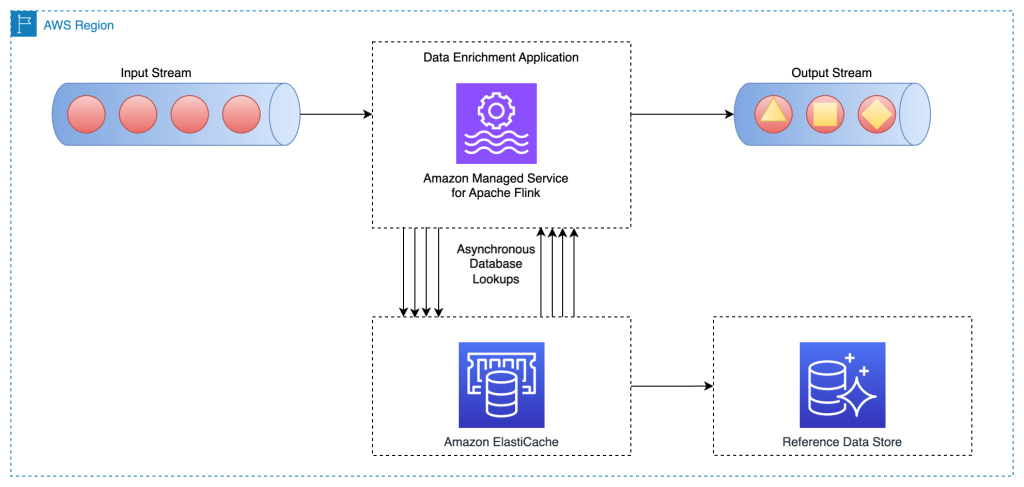
このデータエンリッチメントパターンの実装は、レコード単位の非同期ルックアップパターンと類似しています。唯一の違いは、Apache Flink アプリケーションがプライマリデータベースではなくキャッシュストレージに接続する点です。
この手法の利点は以下のとおりです。
- キャッシュによりアプリケーションとデータベースのパフォーマンスが向上するため、スループットが改善される
- ストリーム処理アプリケーションが生成する読み取りトラフィックからプライマリデータソースを保護できる
- ルックアップ呼び出しごとの読み取りレイテンシーを低減できる
一方、以下の欠点があります。
- 全体として、データの鮮度を向上させたい中〜高スループットシステムには適さない可能性がある
- プライマリデータベースとキャッシュストレージ間でデータを投入・同期するキャッシュパターン実装が複雑になる
- 実装されたキャッシュパターンによっては、Apache Flink ストリーム処理アプリケーションが古い参照データを読み取る可能性がある
- 選択したキャッシュパターン (プロアクティブまたはリアクティブ) によって各エンリッチメント I/O のレスポンス時間が異なるため、ストリーム全体の処理時間が予測しにくくなる可能性がある
あるいは、Flink SQL API 向けの Apache Flink JDBC コネクタを使用すると、キャッシュ実装の複雑さを回避できます。Flink SQL API によるストリームデータのエンリッチメントについては、後述で詳しく解説します。
別のストリームによるストリームデータのエンリッチメント
このパターンでは、メインストリームのデータを別のデータストリームの参照データでエンリッチします。参照データが頻繁に更新され、変更データキャプチャ (CDC) を実行して Apache Kafka や Amazon Kinesis Data Streams などのデータストリーミングサービスにイベントを発行できる場合に適しています。たとえば、以下のようなユースケースで有効です。
- 顧客の購入注文が Kinesis データストリームに発行され、DynamoDB ストリームの顧客請求情報と結合する
- IoT デバイスからキャプチャされたデータイベントを Amazon Relational Database Service (Amazon RDS) のテーブルの参照データでエンリッチする
- ネットワークログイベントを送信元 (および宛先) IP アドレスのマシン名でエンリッチする
以下のアーキテクチャ図は、Amazon MSF 上の Apache Flink アプリケーションがメインストリームのデータと DynamoDB ストリームの CDC データを結合する様子を示しています。
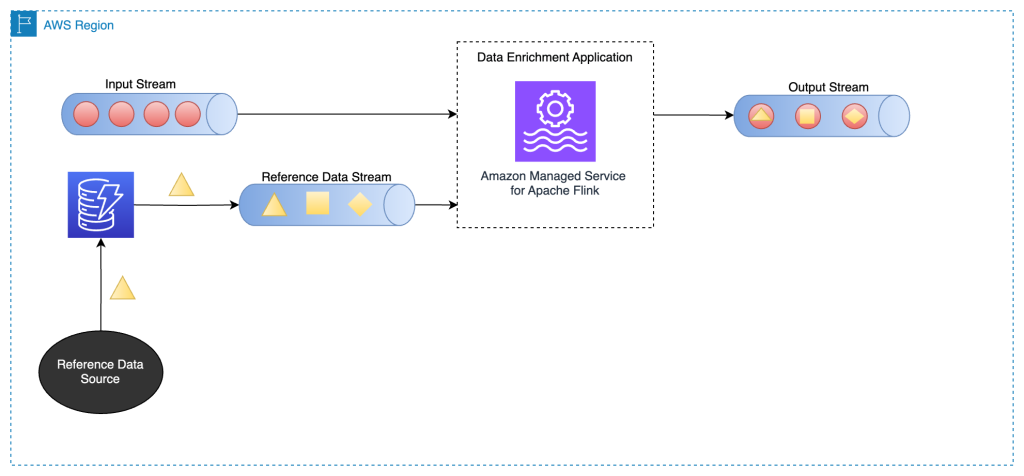
別のストリームからストリーミングデータをエンリッチするには、一般的なストリーム間結合パターンを使用します。以降のセクションで解説します。
Table API を使用したストリームエンリッチメント
Apache Flink Table API は、データイベントを扱うためのより高い抽象化を提供します。Table API を使うと、データストリームをテーブルとして定義し、データスキーマを付与できます。
このパターンでは、各データストリームのテーブルを定義し、それらを結合してデータエンリッチメントを実現します。Apache Flink Table API は内部結合や外部結合などさまざまな結合条件をサポートしていますが、無限ストリームを扱う場合はリソース消費が大きいため避けるべきです。リソース使用率を制限して効率的に結合を実行するには、インターバル結合またはテンポラル結合を使用してください。インターバル結合には、1 つの等結合述語と両側の時間を制限する結合条件が必要です。インターバル結合の実装方法の詳細については、Amazon Managed Service for Apache Flink の開始方法 (Table API) を参照してください。
インターバル結合と比較して、テンポラルテーブル結合はレコードの異なるバージョンが保持される時間期間では動作しません。メインストリームのレコードは、ウォーターマークで指定された時点の参照データの対応するバージョンと常に結合されます。そのため、ステートに残る参照データのバージョンが少なくなります。参照データに時間要素が関連付けられている場合とそうでない場合があります。関連付けられていない場合は、時間ベースのストリームとの結合のために処理時間要素を追加する必要があるかもしれません。
以下のコードスニペットの例では、currency_rates 参照テーブルに Debezium などの変更データキャプチャメタデータから update_time 列を追加しています。さらに、テーブルのウォーターマーク戦略の定義に使用しています。
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL,
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(currency) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'value.format' = 'debezium-json',
/* ... */
);
この手法の利点は以下のとおりです。
- 実装が容易
- 低レイテンシー
- 参照データがデータストリームの場合、高スループットに対応可能
SQL API はデータの処理方法についてより高い抽象化を提供します。結合処理でより複雑なロジックが必要な場合も、まず SQL API から始めて、必要な場合にのみ DataStream API を使用することを推奨します。
まとめ
本記事では、Amazon MSF でのさまざまなデータエンリッチメントパターンを紹介しました。各パターンを活用して、ニーズに合ったものを見つけ、ストリーム処理アプリケーションを迅速に開発してください。
Amazon MSF の詳細については、公式製品ページをご覧ください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。