AWS Big Data Blog
Enrich your data stream asynchronously using Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
Streaming data into or out of a data system must be fast. One of the most expensive pieces of any streaming system is the I/O of the system: reading from the streaming layer using Apache Kafka or Amazon Kinesis, reading a file, writing to an Amazon Simple Storage Service (Amazon S3) data lake, or communicating with an external system. The use cases for this could be anything from enriching a streaming payload with additional elements, to passing data elements to an API for a machine learning (ML) prediction, or loading data streams into a data lake for near-real-time analytics. This interaction with an external data source must be performant so as not to impact the real-time nature of streaming.
In this post, we discuss the method by which Apache Flink allows for the asynchronous enrichment of a data stream through its API for asynchronous I/O with external data sources. You can use this within any Apache Flink workload, including Amazon Kinesis Data Analytics for Apache Flink. This post showcases the async I/O feature set.
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Setting up a Flink cluster can be quite complicated. There are many moving pieces when it comes to scaling, checkpointing, taking snapshots, and monitoring.
Amazon Kinesis Data Analytics for Apache Flink is a fully managed Apache Flink environment with no servers or clusters to manage. It allows for the building of sophisticated Apache Flink applications with sub-second latencies and automatic scaling built in. The service offers pay-as-you-go pricing for cost savings and efficiency. Amazon Kinesis Data Analytics for Apache Flink allows developers to focus on application development rather than Flink Infrastructure management, and enables monitoring of Flink applications with powerful integrations with other AWS Services.
Why is enriching a data stream necessary?
When designing a streaming workload, it can sometimes be necessary to enrich the incoming data with external information. Think of a financial transaction containing the following data:
As this data comes in, it might be saved into a raw datastore, but downstream consumers of this data want to use it to compute things like transactional fraud, application usage trends, stock purchase trends, and more. To calculate these important metrics, the stream must be enriched with external data:
You might retrieve this data from an external relational or non-relational database. It could also come from a key-value data store like Amazon DynamoDB, or an API that contains this querying logic within it. The stream processing application reads the data off of the stream, queries the database with the necessary parameters, and adds the result to the existing payload to send it on its way.

Because this interaction happens outside of the streaming layer, a network call to the external data source is required to handle the request as well as the response. When performing this external call, ensuring that it doesn’t impact upstream data flow is of the highest importance. You can make this call either synchronously or asynchronously from Apache Flink.
The synchronous version of this call from Apache Flink uses a .map() function to the external data source for every message that comes in:
With this interaction, an important consideration is that each individual request is sent synchronously, meaning that any upstream data waits for the current request to complete before moving to the next request. This is detrimental to the performance and throughput of your data stream; it accumulates backpressure in the upstream operator and doesn’t use the Apache Flink distributed machines efficiently. You can improve the throughput of the application by scaling the parallelism of your Flink application, but this results in a higher resource cost, adding more machines and more overhead for the job manager to manage between tasks, threads, and network connections of the running job.

In asynchronous requests, data flowing into an operator can be handled concurrently, making requests and receiving responses in parallel, amortizing the amount of time waiting for any individual request to the max duration of the batch of requests. This can greatly increase throughput of your application without increasing cost or overhead. It also allows you to avoid backpressure by accepting and running concurrent requests.
To learn more about the internal architecture of the asynchronous I/O operations of Apache Flink, see Asynchronous I/O for External Data Access.
Ordered wait vs. unordered wait
When designing a data stream to call AsyncWaitOperator, you have a choice between orderedWait and unorderedWait modes when results are emitted to the next operator.
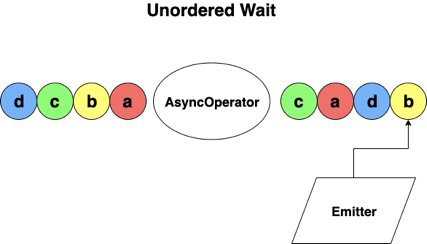
Unordered wait mode is set up so that records are emitted as soon as the asynchronous request finishes (see the following diagram). This means that data might be sent to the next operator out of order, but you ultimately experience lower latency and lower overhead when used with ProcessingTime as the time characteristic.
Ordered wait mode is set up so that records are emitted in the order in which they’re received, and stream order is preserved (see the following diagram). The way this is achieved within the AsyncWaitOperator is through the operator buffer, which waits for all records in the queue to complete, then emits them in the same order as they were enqueued. This introduces extra latency and overhead when checkpointing because records and results are maintained for a longer period of time compared to unordered wait mode.
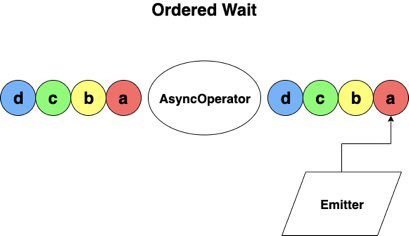
The choice between these two is entirely based on use case. If order of the requests doesn’t matter, or if you can afford to sort the results in downstream operators, use unordered wait. Otherwise, use ordered wait.
Apache Flink asynchronous I/O configuration and tuning
In addition to ordered and unordered wait, you can tune several parameters when calling the asynchronous function. Depending on your workload, these parameters can be critical to have a stable application:
- Capacity — Defines the maximum number of inputs that the asynchronous operator holds in-flight during this asynchronous operation. Keep in mind that this number should only be as high as the external datasource can handle. Setting a capacity of 10 means 10 requests are made to that external datasource asynchronously per parallelism—a capacity of 10 with a parallelism of 8 means 80 concurrent requests to the external datasource is possible.
- Timeout — Defines the duration of the in-flight requests before they’re considered timed out or failed. Set this to a reasonable time based on responses from an external data source (for concurrent requests). You can override the AsyncFunction’s timeout function to handle these timeouts rather than throwing an exception and restarting the job.
- Operator parallelism — It can be useful to limit the operator parallelism of asynchronous operators so you don’t take in too many concurrent requests (for example,
orderedWait(...).setParallelism(1)). Keep in mind that this parallelism will multiply the capacity of requests going to the external data source. - Checkpoint interval — When writing asynchronous functions, the in-flight requests are included within checkpoints, and this can increase the overall checkpoint size or duration. Monitor the checkpoint size and duration to ensure that checkpointing these in-flight requests doesn’t cause backpressure.
Synchronous calls vs. asynchronous calls using Kinesis Data Analytics for Apache Flink
In an experiment to highlight the benefits of using asynchronous I/O, we created an Apache Flink application that calls an Amazon API Gateway endpoint to an AWS Lambda function and returns a result. The function sleeps for 1.5 seconds to illustrate the benefits with a poorly performing API. The application calls the API in both a .map() function and an AsyncFunction to call the API asynchronously.
The following diagram shows our I/O metrics in Amazon CloudWatch.
Within the experiment, when setting a capacity of 1, both the .map() function and AsyncFunction produce the same throughput. This is because a capacity of 1 can only have one request in flight at any given time, which is exactly how a synchronous map function behaves. When increasing the capacity to 2, the experiment shows a doubled throughput for the asynchronous function compared to the map function. This increases dramatically as we increase capacity.
The purple line in the metric visualization shows the capacity set for the asyncronous function. The red line is the .map() version of the call, and the orange line is the asynchronous version of the call using asynchronous I/O.
This functionality helps you enrich your streams performantly by doing so asynchronously. You can use this functionality many different ways, such as the following use cases:
- Sinking your data to Lambda using asynchronous I/O to trigger notifications and external actions upon data in real time
- Accessing and writing files to Amazon S3 that will influence the stream process
- Calling an API with calculated ML Features for real-time complex predictions on models hosted in Amazon Elastic Container Service (Amazon ECS).
Summary
Kinesis Data Analytics for Apache Flink takes away the complexity of running Apache Flink workloads on your own by managing the infrastructure, monitoring, and operational overhead of an Apache Flink cluster. This eliminates the undifferentiated heavy lifting of managing your own checkpoints and snapshots, version upgrades, alerting, and automatic scaling. When you use asynchronous I/O within Kinesis Data Analytics for Apache Flink, you can improve the overall throughput of your application. In this post, we showed some use cases for using Asynchronous I/O for Apache Flink, along with ways to configure your external communications to ensure efficient throughput.
If you have questions or concerns, please share them in the comments. For more information about Kinesis Data Analytics for Apache Flink, see the Github repo with the source code for testing and the workshop Amazon Flink on Amazon Kinesis Data Analytics.
About the Authors
Hari Rajaram is a Principal Data Architect at AWS with a proven record of designing and developing complex steaming and analytics applications. His primary role is to help customers find meaningful insights from data in real time. He has authored a book on Apache Flink (early stages in 2016). Before joining AWS, he played an instrumental role in designing analytic applications that could scale petabytes, apart from researching data privacy.
Jeremy Ber has been working in the telemetry data space for the past 5 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Solutions Architect Streaming Specialist supporting both Managed Streaming for Kafka (Amazon MSK) and Amazon Kinesis.