Amazon Web Services ブログ
Operating Lambda: イベント駆動型アーキテクチャにおけるアンチパターン – Part 3
Operating Lambda シリーズでは、AWS Lambda ベースのアプリケーションを管理している開発者、アーキテクト、システム管理者向けの重要なトピックについて説明します。3 部構成のこのセクションでは、イベント駆動型アーキテクチャと、それが Lambdaベースのアプリケーションとどのように関連しているかについてディスカッションします。
Part 1 では、イベント駆動型パラダイムの利点と、スループット、スケーリング、拡張性をどのように改善できるかについてカバーしています。Part 2 では、開発者が Lambda ベースのアプリケーションを構築するメリットを享受するのに役立つ設計原則とベストプラクティスについて説明しています。この記事では、イベント駆動型アーキテクチャの一般的なアンチパターンについて説明します。
Lambda は決まりきったサービスではなく、必要に応じてアプリケーションを構築するための幅広い機能を提供します。この柔軟性はお客様にとって重要ですが、技術的には動作するものの時には最適ではない設計となることもあります。
Lambdaのモノリス
Amazon EC2 インスタンスまたは AWS Elastic Beanstalk アプリケーションのような、従来のサーバーから移行された多くのアプリケーションでは開発者は既存のコードを「リフト&シフト」します。多くの場合、これによりすべてのイベントでトリガーされるすべてのアプリケーションロジックを含む 1 つの Lambda 関数が生成されます。たとえば、基本的なウェブアプリケーションの場合、モノリシックな Lambda 関数は、すべての Amazon API Gateway ルートを処理し、必要なすべてのダウンストリームリソースと統合します。
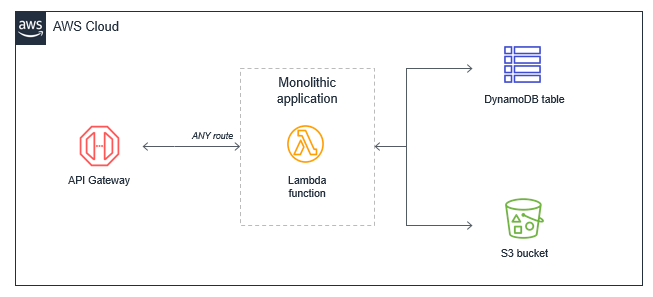
このアプローチには、いくつかの欠点があります。
- パッケージサイズ: Lambda関数のサイズは、すべてのパスに対して取り得るすべてのコードが含まれているため、より大きくなる可能性があります。そのためLambdaサービスが関数をダウンロードし実行する速度が遅くなります。
- 最小権限を適用するのが難しい: 関数の IAM ロールは、すべてのパスに必要なすべてのリソースに対するアクセス許可を付与するのでアクセス許可は非常に広範になります。関数モノリス内の多くのパスは、付与されたすべての権限を必要としません。
- アップグレードが困難: 本番システムでは、どのようなものでも単一機能のアップグレードはリスクが高くなり、アプリケーション全体が動作しなくなる可能性があります。Lambda 関数内で1 つのパスをアップグレードするだけでも関数全体をアップグレードすることになります。
- 保守が困難: モノリシックなコードのリポジトリでは、複数の開発者がそのサービスに取り組むことはより困難です。また開発者が知る必要がある領域が増加し、コードに対する適切なカバレッジのテストを作成することも難しくなります。
- コードの再利用が難しい: 通常、ライブラリをモノリスから分離することは難しくコードの再利用はより困難になります。より多くのプロジェクトを開発して保守するようになると、コードを保守しながらチームの速度を上げることが難しくなります。
- テストが難しい: コードの行が増えるにつれて、コードベースに対して可能な入力とエントリポイントのすべての組み合わせを作成することが難しくなります。一般に、より少ないコードの小さなサービスに対して単体テストを実装する方が簡単です。
これに代わる案は、モノリシックな Lambda 関数を個々のマイクロサービスに分解し、単一の Lambda 関数を正しく定義された単一のタスクにマッピングします。この例の少数の API エンドポイントを持つWebアプリケーションでは、結果として構築されるマイクロサービスベースのアーキテクチャはAPI のルートに基づいています。

モノリスを分解するプロセスは、ワークロードの複雑さに依存します。Strangler パターンのような戦略を使用して、より大きなコードベースからマイクロサービスへコードを移行します。Lambda ベースのアプリケーションをこの方法で実行すると多くの潜在的な利点が生まれます。
- パッケージサイズが最適化されます。1 つのタスクに必要なコードにのみに最適化できるため関数のパフォーマンスが向上します。また実行コストを削減できます。
- IAM ロールは、マイクロサービスが必要とするアクセス権限に正確に範囲を設定できるため、最小権限の原則をより簡単に適用できます。ブラストラディウス(訳注:影響範囲)を制御する際に、この方法で IAM ロールを使用するとアプリケーションのセキュリティをより強化できます。
- アップグレードが容易: ワークロード全体に影響を与えることなく、マイクロサービス レベルでアップグレードを適用できます。アップグレードはアプリケーションレベルではなく関数のレベルで行われます。またアップデートの展開を制御するためにカナリアリリースを実装できます。
- メンテナンスが簡単: 新しい機能を追加することは、通常は多くの結合を持つモノリスよりも単一の小さなサービスに行うほうが容易です。多くの場合、既存のコードを変更せずに新しい Lambda 関数を追加することで機能を実装できます。
- コードの再利用が容易: 単一のタスクを実行する特定の関数がある場合、複数のプロジェクト間でより容易にそれらをコピーすることができます。汎用的で特定機能のライブラリを構築することで、将来のプロジェクトでの開発を加速することができます。
- テストが容易: コードが数行で関数の潜在的な入力の範囲が小さい場合、ユニットテストはより容易になります。
- 開発者にとってより低い負担: 各開発チームにとってアプリケーションを理解するための領域が小さいため開発者が内容を理解するための負担が低くなります。これによって新しい開発者がチームメンバーとして活躍するまでの時間を加速できます。
詳細については「Decomposing the Monolith with Event Storming」をお読みください。
オーケストレーターとしてのLambda
多くのビジネスワークフローは、複数の要因に依存するオペレーションのフローによって複雑なワークフローロジックになります。eコマースを例に上げると支払サービスは複雑なワークフローの例になります。
- 支払タイプは、現金、小切手、またはクレジットカードのいずれかであり、そのすべてが異なるプロセスです。
- クレジットカードでの支払いには、成功から拒否までのさまざまな状態があります。
- サービスは、クレジットの一部または全額払い戻し、または返金を発行する必要がある場合があります。
- クレジットカードを処理するサードパーティーサービスは、システム停止により利用できない場合があります。
- 支払い処理によっては処理に数日かかる場合があります。
Lambda 関数でこのロジックを実装すると結果的に、読む、理解する、保守することに苦労する「スパゲッティコード」になる可能性があります。また本番システムは壊れやすくなる可能性があります。エラー処理、リトライロジック、入出力処理を自分のコードで扱わなければならない場合、複雑性を組み込むことになります。これらのタイプのオーケストレーション関数は、Lambda ベースのアプリケーションではアンチパターンになります。
代わりに、AWS Step Functionsを使用して、バージョニング可能な JSON 定義のステートマシンを使用してこれらのワークフローをオーケストレーションします。ステートマシンは、ネストされたワークフローのロジック、エラー、およびリトライを処理できます。標準ワークフローは最大 1 年間実行でき、サービスは異なるバージョンのワークフローを維持できるため、本番システムをインプレースでアップグレードできます。この方法を使用すると、カスタムコードが少なくなり、アプリケーションのテストと保守が容易になります。
Step Functionsは、一般的に境界内のコンテキストまたはマイクロサービスのワークフローに最適ですが、複数のサービス間で状態の変更を調停するには、代わりに Amazon EventBridge を使用します。これはルールに基づいてイベントをルーティングし、マイクロサービス間のオーケストレーションを簡素化するサーバーレスのイベントバスです。
呼び出しループを引き起こす再帰パターン
AWS サービスはLambda 関数を呼び出すイベントを生成し、Lambda 関数は AWS サービスにメッセージを送信できます。一般にLambda 関数を呼び出すサービスまたはリソースは、関数が出力するサービスまたはリソースとは異なる必要があります。この管理に失敗すると呼び出しループが発生する可能性があります。
例えばLambda 関数が Amazon S3 オブジェクトにオブジェクトを書き込み、次にそのオブジェクトのPUT イベントによって同じ Lambda 関数を呼び出すとします。この呼び出しにより、2 番目のオブジェクトがバケットに書き込まれ、同じ Lambda 関数を呼び出します。

無限ループの可能性はほとんどのプログラミング言語に存在しますが、このアンチパターンはサーバーレスアプリケーションのリソースをより消費する可能性があります。Lambda と S3 はどちらもトラフィックに基づいて自動的にスケールするため、ループによって Lambda は利用可能なすべての同時実行インスタンスを消費するようにスケールし、S3 はオブジェクトを書き続けLambda のイベントを生成し続けます。このような場合はLambda コンソールで「スロットリング」ボタンを押して関数の同時実行をゼロにスケールダウンし再帰サイクルを停止します。
この例では S3 を使用していますが、再帰ループのリスクはAmazon SNS、Amazon SQS、Amazon DynamoDB、およびその他のサービスにも存在します。ほとんどの場合、イベントを生成したり消費したりするリソースを Lambda から分離した方がより安全です。ただし関数を呼び出したリソースにデータを書き戻すために Lambda 関数が必要な場合は、次のことを確認してください。
- ポジティブトリガーの使用: 例えばS3 オブジェクトトリガーは最初の呼び出しでのみトリガーされる命名規則またはメタタグを使用できます。これによりLambda 関数から書き込まれたオブジェクトが同じ Lambda 関数を再び呼び出すのを防ぐことができます。このメカニズムの例については、S3-to-Translate – Language Translation at Scaleを参照してください。
- 同時実行の予約を使用: 関数の同時実行の予約を低く設定すると、関数がその制限を超えて同時にスケーリングされなくなります。これで再帰を防ぐことはありませんが、安全なメカニズムとしてリソースの消費を制限できます。これは開発とテストの段階で役立ちます。
- Amazon CloudWatch モニタリングとアラームの使用: 関数の同時実行メトリックスにアラームを設定すると、同時実行が突然スパイクした場合にアラートを受け取り、適切なアクションを実行できます。
Lambda関数を呼び出す Lambda 関数
関数はカプセル化とコードの再利用を可能にします。ほとんどのプログラミング言語は、コードベース内の関数を同期的に呼び出すコードの概念をサポートしています。この場合、呼び出し元は関数が応答を返すまで待機します。多くの場合、このモデルはサーバーレスの開発には適していません。
例えば注文を処理する 3 つの Lambda 関数で構成されるシンプルな e コマースアプリケーションを考えてみましょう。

この場合、「注文の作成」関数は「支払処理」関数を呼び出し、次に「請求書の作成」関数を呼び出します。この同期フローは、一台のサーバー上の 1 つのアプリケーション内では動作しますが、分散サーバーレスアーキテクチャでは、いくつかの避けられる問題を持ち込むことになります。
コスト: Lambda は呼び出した関数の実行時間に対して課金します。この例では、[請求書の作成] 関数の実行中に、他の 2 つの関数も待機状態で実行されています。これは、図上で赤で示されています。
エラー処理: ネストされた呼び出しでは、エラー処理がより複雑になる可能性があります。最上位関数で処理するために親関数にエラーをスローするか、または関数でカスタムの処理が必要です。たとえば、[請求書の作成] のエラーでは、請求金額を取り消すために [支払の処理] 機能を要求したり、代わりに [請求書の作成] 処理を再試行するかもしれません。
密結合: 支払処理は通常、請求書を作成するよりも時間がかかります。このモデルではワークフロー全体の可用性は最も遅い関数によって制限されます。
スケール: 3 つの関数すべての同時実行数は等しくなければなりません。負荷の高いシステムでは、これはより多くの同時実行数を使用します。
サーバーレスアプリケーションでは、このパターンを回避するための一般的なアプローチが 2 つあります。まずこれらのLambda 関数の間にSQS キューを使用します。ダウンストリームプロセスがアップストリームプロセスよりも遅い場合、キューは高い耐久性でメッセージを保存し2 つの関数を分離します。この例では、[注文の作成] 関数は SQS キューにメッセージを発行し、[支払の処理] 関数はキューからメッセージを消費します。
2 番目のアプローチはAWS Step Functionsの利用です。複数のタイプのエラーとリトライロジックを持つ複雑なプロセスの場合、Step Functionsを使用すると、ワークフローをオーケストレーションするために必要なカスタムコードの量を減らすことができます。その結果、Step Functionsによって作業が調整されることでエラーとリトライが確実に処理され、Lambda 関数にはビジネスロジックのみが含まれることになります。
単一の Lambda 関数内で同期的な待機
単一の Lambda 内で、同時実行可能なアクティビティが同期的にスケジュールされていないことを確認します。例えば、あるLambda 関数が S3 バケットに書き込み、次に DynamoDB テーブルに書き込むとします。
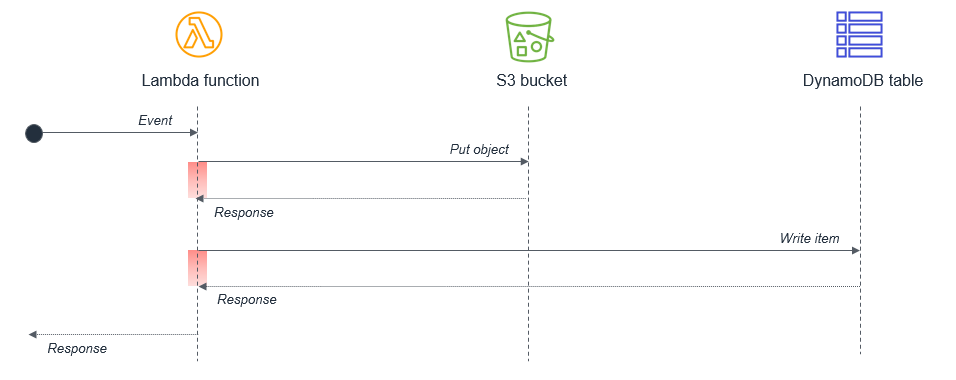
図に赤で示されている待機状態は、アクティビティがシーケンシャルであるため合計の時間がかかっています。これらのタスクが独立している場合は並列に実行でき、その結果としてより実行時間が長いタスクによって合計待機時間が設定されます。
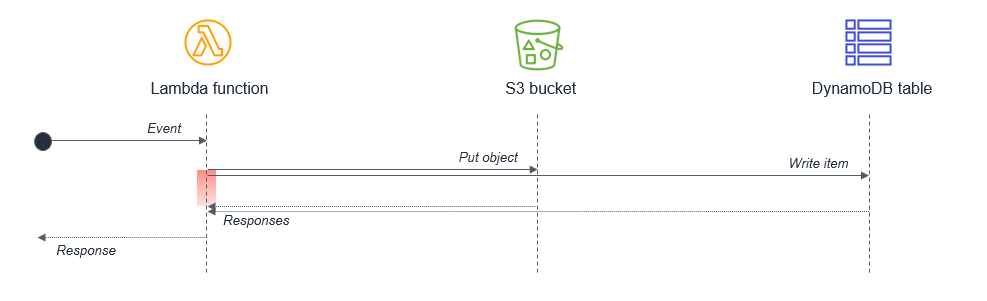
2 番目のタスクが最初のタスクの完了に依存する場合、Lambda 関数を分割することで合計待機時間と実行コストを削減できます。

この設計では、最初の Lambda 関数はオブジェクトを S3 バケットに配書き込んですぐにレスポンスを返します。S3 サービスは2 番目の Lambda 関数を呼び出し、DynamoDB テーブルにデータを書き込みます。この方法はLambda 関数の実行の合計待機時間を最小限に抑えます。
詳細については、AWS の優れたアーキテクチャフレームワークの「Serverless Applications Lens」を参照してください。
結論
この記事では、Lambda を使用するイベント駆動型アーキテクチャの一般的なアンチパターンについて議論しました。モノリシックな Lambda 関数やカスタムコードを使用してワークフローをオーケストレーションするときのいくつかの問題を示しました。呼び出しループを引き起こす可能性のある再帰的なアーキテクチャを避ける方法と、関数から関数を呼び出すことを避けるべき理由を説明しました。またコストを最小限に抑えるための関数での待機処理に対する異なるアプローチについても説明しました。
サーバーレスラーニングリソースの詳細については、Serverless Landをご覧ください。
日本語訳はSA福井 厚が担当しました。原文はこちらです。