Amazon Web Services ブログ
Amazon Managed Service for Apache Flink アプリケーションライフサイクルの詳細 – パート 1
本記事は 2025 年 9 月 3 日 に公開された「Deep dive into the Amazon Managed Service for Apache Flink application lifecycle – Part 1」を翻訳したものです。
Apache Flink は、ストリームおよびバッチ処理アプリケーション向けのオープンソースフレームワークです。リアルタイム分析、イベント駆動型アプリケーション、複雑なデータ処理を低レイテンシーかつ高スループットで処理することに優れています。Flink は、アプリケーション状態に対して exactly-once の一貫性を保証するステートフルな計算向けに設計されています。
Amazon Managed Service for Apache Flink は、クラスターの管理やリソースのプロビジョニングを気にすることなく、Apache Flink ジョブをスケールで実行できるフルマネージドのストリーム処理サービスです。お好みの統合開発環境 (IDE) を使用してアプリケーションの実装に集中し、標準的なビルドおよび継続的インテグレーション/継続的デリバリー (CI/CD) ツールを使用してアプリケーションをビルドおよびパッケージ化できます。
Managed Service for Apache Flink では、シンプルな AWS API アクションを通じてアプリケーションのライフサイクルを制御できます。API を使用してアプリケーションの開始と停止、コード、ランタイム設定、スケールの変更を適用できます。サービスが基盤となる Flink クラスターの管理を行うため、サーバーレスな体験が得られます。AWS API または AWS Command Line Interface (AWS CLI) と連携できるツールを使用して、CI/CD パイプラインなどの自動化を実装できます。
AWS マネジメントコンソール、AWS CLI、AWS SDK、および AWS API を使用するツール (AWS CloudFormation や Terraform など) を使用してアプリケーションを制御できます。サービスは、アプリケーションのデプロイとオーケストレーションに使用する自動化ツールを規定しません。
有名なレーシングドライバーである Jackie Stewart の言葉を借りれば、Managed Service for Apache Flink を使用するために Flink クラスターの操作方法を理解する必要はありませんが、ある程度の Mechanical Sympathy (機械への共感) があれば、堅牢で信頼性の高い自動化を実装するのに役立ちます。
この 2 部構成のシリーズでは、アプリケーションのライフサイクル中に何が起こるかを探ります。この記事では、コアコンセプトと通常運用時のアプリケーションワークフローについて説明します。パート 2 では、潜在的な障害、モニタリングによる検出方法、問題発生時の迅速な解決方法について説明します。
定義
アプリケーションライフサイクルのステップを調べる前に、Managed Service for Apache Flink のコンテキストにおける特定の用語の使用法を明確にする必要があります。
- アプリケーション – Managed Service for Apache Flink で作成、制御、実行する主要なリソースはアプリケーションです。
- アプリケーションコードパッケージ – 各 Managed Service for Apache Flink アプリケーションに対して、実行したい Flink アプリケーションコードのアプリケーションコードパッケージ (アプリケーションアーティファクト) を実装します。このコードは依存関係とともにコンパイルされ、JAR または ZIP ファイルにパッケージ化され、Amazon Simple Storage Service (Amazon S3) バケットにアップロードします。
- 設定 – 各アプリケーションには、実行するための情報を含む設定があります。設定は S3 バケット内のアプリケーションコードパッケージを指し、並列度を定義します。これにより、KPU の観点からアプリケーションリソースも決定されます。また、セキュリティ、ネットワーキング、およびランタイム時にアプリケーションコードに渡されるランタイムプロパティも定義します。
- ジョブ – アプリケーションを開始すると、Managed Service for Apache Flink は専用のクラスターを作成し、アプリケーションコードを Flink ジョブとして実行します。
次の図は、これらの概念間の関係を示しています。
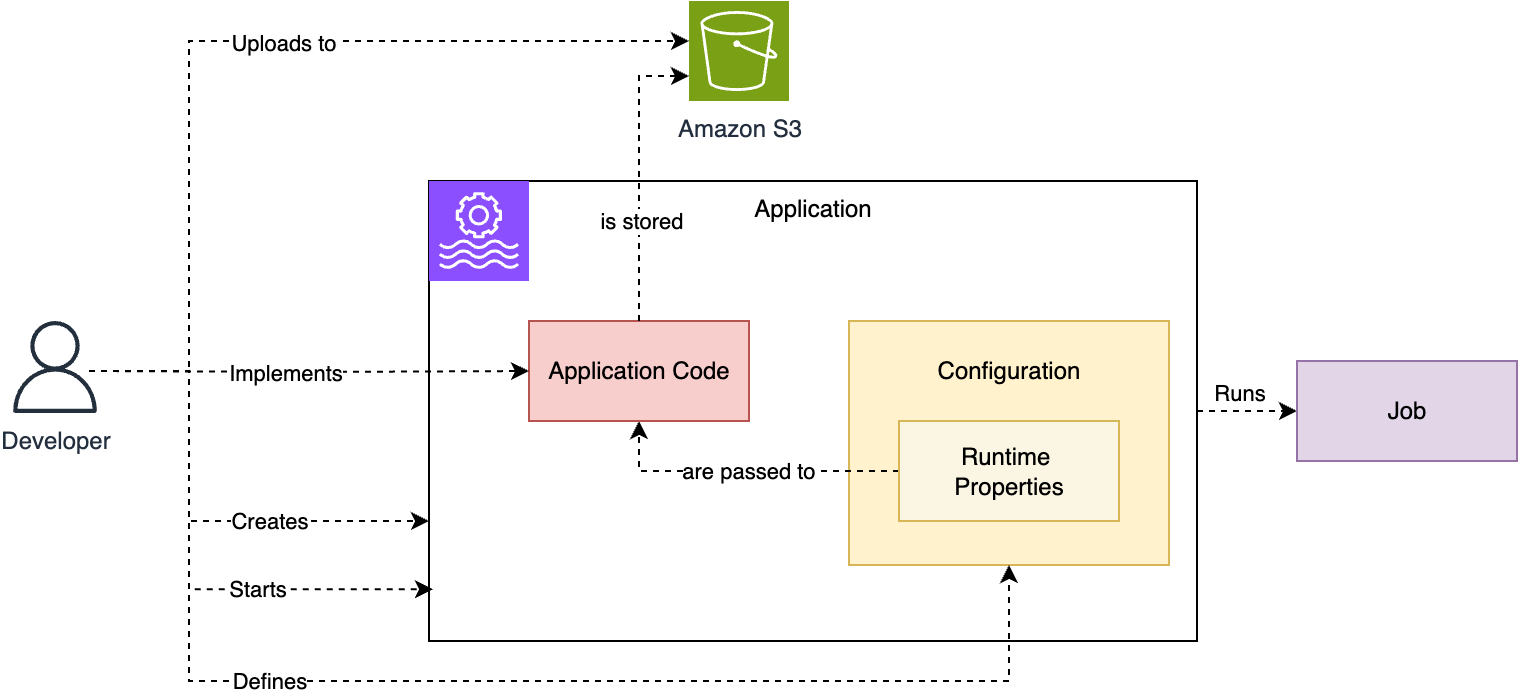
さらに 2 つの重要な概念があります。チェックポイントとセーブポイントは、Flink が障害や操作全体で状態の一貫性を保証するために使用するメカニズムです。Managed Service for Apache Flink では、チェックポイントとセーブポイントの両方がフルマネージドです。
- チェックポイント – アプリケーション設定によって制御され、デフォルトで 1 分間隔で有効になっています。Managed Service for Apache Flink では、ランタイム障害後にジョブが自動的に再起動するときにチェックポイントが使用されます。チェックポイントは永続的ではなく、アプリケーションが停止または更新されたとき、およびアプリケーションが自動スケーリングしたときに削除されます。
- セーブポイント – Managed Service for Apache Flink ではスナップショットと呼ばれ、更新や自動スケーリングイベントによってユーザーが意図的にアプリケーションを再起動するときにアプリケーション状態を永続化するために使用されます。スナップショットはユーザーがトリガーできます。スナップショット (有効な場合) は、変更のデプロイや自動スケーリングなど、アプリケーションが停止して再起動されるときにアプリケーション状態を保存および復元するためにも自動的に使用されます。スナップショットの自動使用はアプリケーション設定で有効になっています (コンソールを使用してアプリケーションを作成するとデフォルトで有効)。
Managed Service for Apache Flink におけるアプリケーションのライフサイクル
ハッピーパスから始めると、Managed Service for Apache Flink アプリケーションの典型的なライフサイクルは以下のステップで構成されます。
- 新しいアプリケーションを作成して設定する。
- アプリケーションを開始する。
- 変更をデプロイする (ランタイム設定の更新、アプリケーションコードの更新、スケールアップまたはスケールダウンのための並列度の変更)。
- アプリケーションを停止する。
アプリケーションの開始、停止、更新では、操作全体でアプリケーション状態の一貫性を維持するためにスナップショット (有効な場合) を使用します。本番環境およびステージング環境のすべてのアプリケーションでスナップショットを有効にして、操作全体でアプリケーション状態の永続性をサポートすることをお勧めします。
Managed Service for Apache Flink では、アプリケーションライフサイクルはコンソール、kinesisanalyticsv2 API の API アクション、または AWS CLI と SDK の同等のアクションを通じて制御されます。これらの基本的な操作の上に、低レベルのアクションを直接使用するか、AWS CloudFormation や Terraform などの高レベルの Infrastructure as Code (IaC) ツールを使用して、さまざまなツールで独自の自動化を構築できます。
この記事では、各ステップで使用される低レベルの API アクションを参照します。高レベルの IaC ツールは、これらの操作の組み合わせを使用します。これらの操作を理解することは、堅牢な自動化を設計するために不可欠です。
次の図は、アプリケーションライフサイクルをまとめたもので、典型的な操作とアプリケーションステータスを示しています。
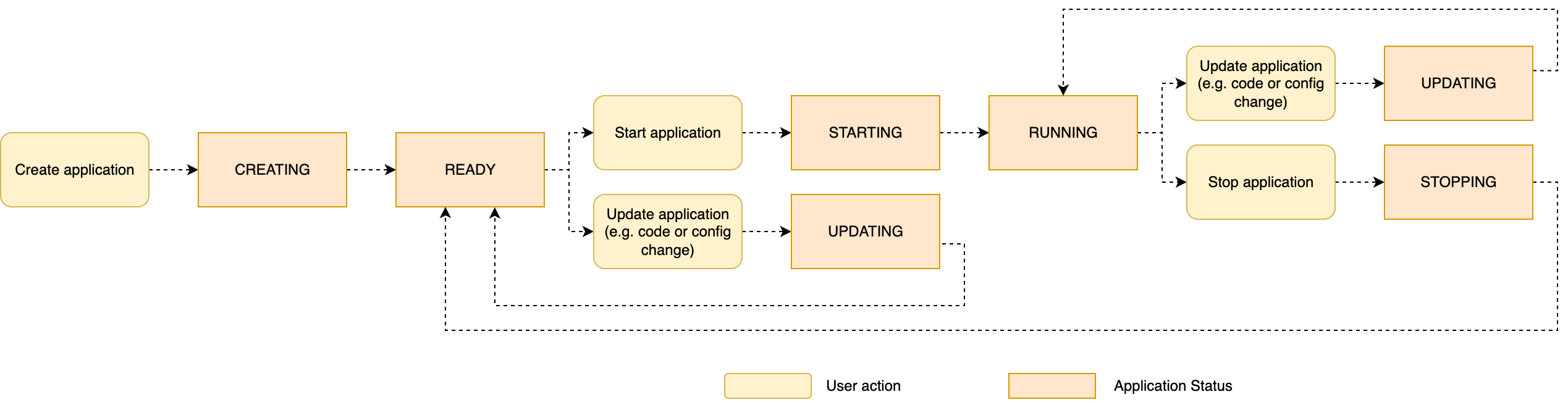
アプリケーションのステータス (READY、STARTING、RUNNING、UPDATING など) は、コンソールおよび DescribeApplication API アクションを使用して確認できます。
以下のセクションでは、各ライフサイクル操作をより詳細に分析します。
アプリケーションの作成と設定
最初のステップは、アプリケーション設定の定義を含む新しい Managed Service for Apache Flink アプリケーションの作成です。CreateApplication アクションを使用して 1 つのステップで行うか、基本的なアプリケーション設定を作成してから UpdateApplication を使用して開始前に設定を更新できます。後者のアプローチは、コンソールからアプリケーションを作成するときに行う方法です。
このフェーズでは、開発者は実装したアプリケーションを JAR ファイル (Java の場合) または ZIP ファイル (Python の場合) にパッケージ化し、事前に作成した S3 バケットにアップロードします。バケット名とアプリケーションコードパッケージへのパスは、定義する設定の一部です。
UpdateApplication または CreateApplication が呼び出されると、Managed Service for Apache Flink は設定で参照されているアプリケーションコードパッケージ (JAR または ZIP ファイル) のコピーを取得します。設定で指定されたファイルが存在しない場合、設定は拒否されます。
次の図は、このワークフローを示しています。
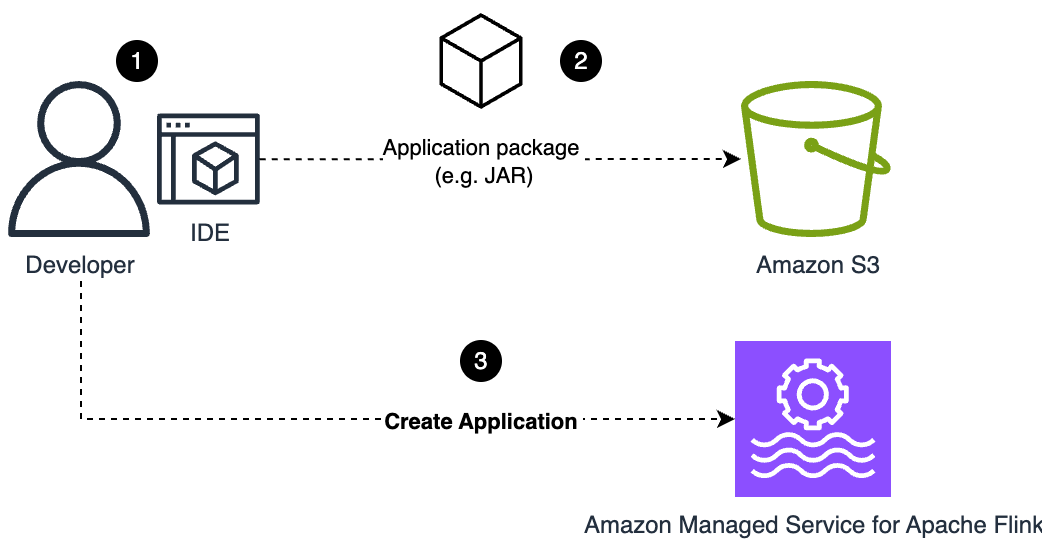
S3 バケット内のアプリケーションコードパッケージを単に更新しても、更新はトリガーされません。同じ名前でコードパッケージを上書きした場合でも、新しいファイルをサービスに認識させて更新をトリガーするには、UpdateApplication を実行する必要があります。
アプリケーションの開始
Managed Service for Apache Flink は、アプリケーションが実際に実行されているときにリソースをプロビジョニングし、実行中のアプリケーションのリソースに対してのみ課金されます。StartApplication を発行することで、アプリケーションをいつ開始するかを明示的に制御します。
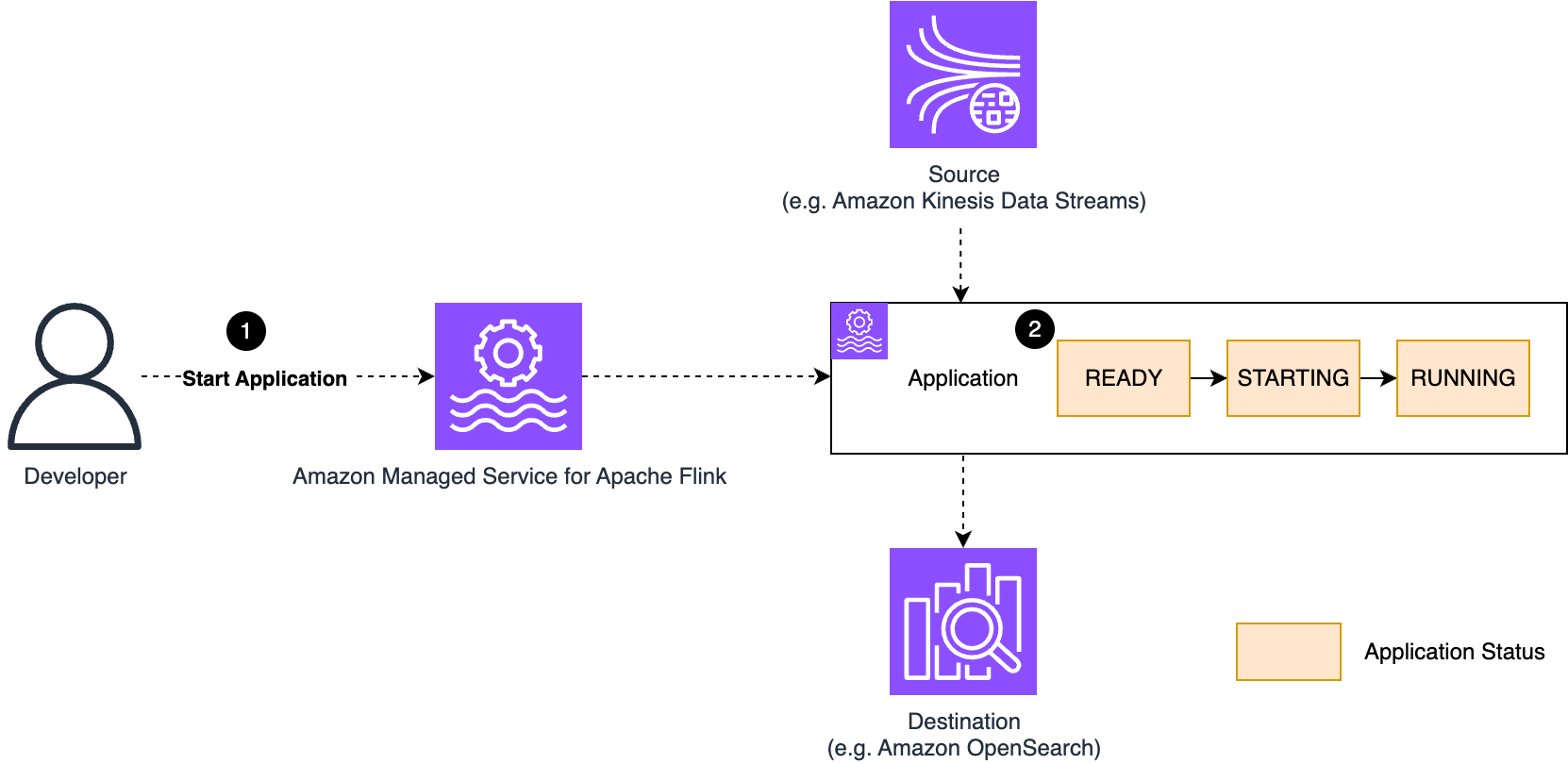
Managed Service for Apache Flink は高可用性を重視し、専用の Flink クラスターでアプリケーションを実行します。アプリケーションを開始すると、Managed Service for Apache Flink は専用のクラスターをデプロイし、定義した設定に基づいて Flink ジョブをデプロイして実行します。
アプリケーションを開始すると、アプリケーションのステータスは READY から STARTING、そして RUNNING に移行します。
次の図は、このワークフローを示しています。
Managed Service for Apache Flink は、Apache Flink のデフォルトであるストリーミングモードとバッチモードの両方をサポートしています。
- ストリーミングモード – ストリーミングモードでは、アプリケーションが正常に開始されて
RUNNINGステータスになると、明示的に停止するまで実行し続けます。この時点から、障害時の動作は最新のチェックポイントからジョブを自動的に再起動することであり、データ損失はありません。この障害シナリオの詳細については、この記事の後半で説明します。 - バッチモード – バッチモードで実行される Flink アプリケーションは異なる動作をします。開始後、
RUNNINGステータスになり、処理が完了するまでジョブは実行し続けます。その時点でジョブは正常に停止し、Managed Service for Apache Flink アプリケーションはREADYステータスに戻ります。
この記事では、ストリーミングアプリケーションのみに焦点を当てています。
アプリケーションの更新
Managed Service for Apache Flink では、コンソールまたは UpdateApplication API アクションを使用してアプリケーション設定を更新することで、以下の変更を処理します。
- アプリケーションコードの変更 (新しいバージョンを含むパッケージ (JAR または ZIP ファイル) の置き換え)
- ランタイムプロパティの変更
- スケーリング (並列度とリソース (KPU) の変更を伴う)
- チェックポイント、ログレベル、モニタリング設定などの運用パラメータの変更
- ネットワーク設定の変更
アプリケーション設定を変更すると、Managed Service for Apache Flink は新しい設定バージョンを作成します。これは、変更のたびに自動的にインクリメントされるバージョン ID 番号で識別されます。
コードパッケージの更新
アプリケーション設定を更新するときに、サービスがコードパッケージ (JAR または ZIP ファイル) のコピーを取得することを説明しました。コピーは、作成された新しいアプリケーション設定バージョンに関連付けられます。サービスは、アプリケーションを開始するために独自のコードパッケージのコピーを使用します。設定を更新した後、コードパッケージを安全に置き換えたり削除したりできます。新しいパッケージは、アプリケーション設定を再度更新するまで考慮されません。
READY (実行していない) アプリケーションの更新
READY ステータスのアプリケーションを更新しても、次回アプリケーションを開始するときに使用される新しい設定バージョンの作成以外に特別なことは起こりません。ただし、本番環境では、変更を適用するために RUNNING ステータスのアプリケーションの設定を更新するのが通常です。Managed Service for Apache Flink は、データ損失なしでアプリケーションを更新するために必要な操作を自動的に処理します。
RUNNING アプリケーションの更新
実行中のアプリケーションを更新するときに何が起こるかを理解するには、Flink が強力な一貫性と exactly-once の状態一貫性のために設計されていることを覚えておく必要があります。変更が適用されるときにこれらの機能を維持するために、Flink はデータ処理を停止し、アプリケーション状態のコピーを取得し、変更を加えてジョブを再起動し、処理を再開する前に状態を復元する必要があります。
これは標準的な Flink の動作であり、コードの変更、ランタイム設定の変更、スケールアップおよびスケールダウンのための新しい並列度など、あらゆる変更に適用されます。Managed Service for Apache Flink は、このプロセスを自動的にオーケストレーションします。スナップショットが有効な場合、サービスは処理を停止する前にスナップショットを取得し、変更がデプロイされたときにスナップショットから再起動します。これにより、データ損失なしで変更をデプロイできます。
スナップショットが無効な場合、サービスは変更を加えてジョブを再起動しますが、状態は空になり、アプリケーションを最初に開始したときと同じになります。これによりデータ損失が発生する可能性があります。特に本番アプリケーションでは、通常これは望ましくありません。
実際の例を見てみましょう。次の図で示されています。例えば、コードの変更をデプロイする場合、通常以下のステップが発生します (この例では、本番アプリケーションで有効にすべきスナップショットが有効であると仮定しています)。
- アプリケーションコードを変更する。
- ビルドプロセスがアプリケーションパッケージ (JAR または ZIP ファイル) を作成する (手動または CI/CD 自動化を使用)。
- 新しいアプリケーションパッケージを S3 バケットにアップロードする。
- 新しいアプリケーションパッケージを指すようにアプリケーション設定を更新する。
- 設定の更新が成功するとすぐに、Managed Service for Apache Flink はアプリケーションを更新する操作を開始します。アプリケーションステータスは
UPDATINGに変わります。Flink ジョブは停止し、アプリケーション状態のスナップショットを取得します。 - 変更が適用された後、アプリケーションは新しい設定 (この場合は新しいアプリケーションコードを含む) を使用して再起動され、ジョブはスナップショットから状態を復元します。プロセスが完了すると、アプリケーションステータスは
RUNNINGに戻ります。
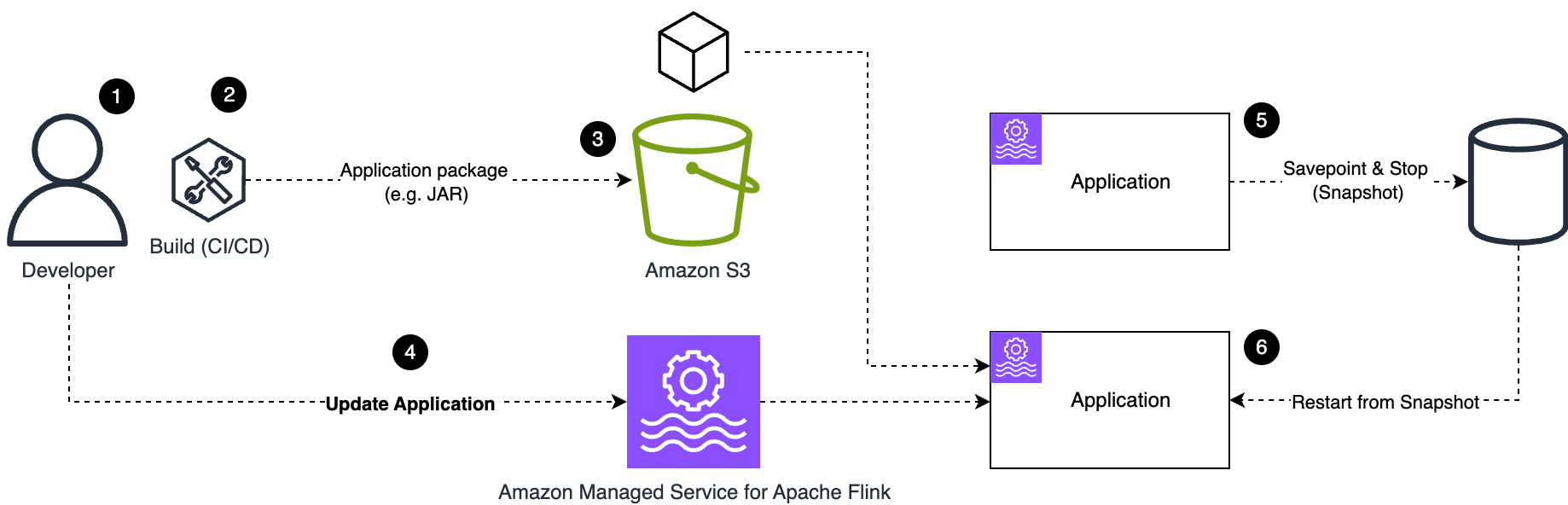
アプリケーション設定の変更についても同様のプロセスです。例えば、アプリケーション設定を更新して並列度を変更することでアプリケーションをスケーリングでき、新しい並列度と新しい KPU 数に基づくリソース量 (CPU、メモリ、ローカルストレージ) でアプリケーションが再デプロイされます。
アプリケーションの IAM ロールの更新
アプリケーション設定には、AWS Identity and Access Management (IAM) ロールへの参照が含まれています。別のロールを使用したい場合 (まれなケースですが)、UpdateApplication を使用してアプリケーション設定を更新できます。プロセスは前述と同じです。
ただし、通常は権限を追加または削除するために IAM ロールを変更したいと思うでしょう。この操作は Managed Service for Apache Flink アプリケーションライフサイクルを使用せず、いつでも実行できます。アプリケーションの停止と再起動は必要ありません。IAM の変更は即座に有効になり、例えば必要な権限を誤って削除した場合、障害を引き起こす可能性があります。この場合、Flink ジョブの応答動作は、影響を受けるコンポーネントによって異なる場合があります。
アプリケーションの停止
StopApplication アクションまたはコンソールを使用して、実行中の Managed Service for Apache Flink アプリケーションを停止できます。サービスはアプリケーションを正常に停止します。ステータスは RUNNING から STOPPING、最終的に READY に変わります。
スナップショットが有効な場合、次の図に示すように、サービスは停止時にアプリケーション状態のスナップショットを取得します。
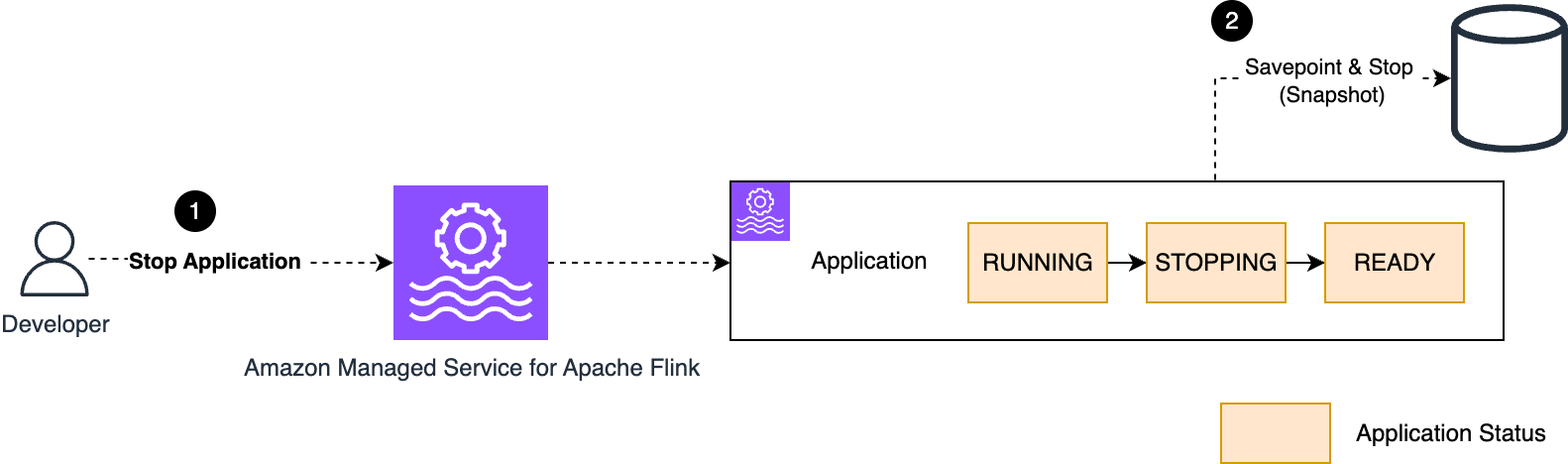
アプリケーションを停止すると、アプリケーションを実行するために以前プロビジョニングされたリソースは回収されます。アプリケーションが実行されていない (READY) 間は、コストは発生しません。
スナップショットからのアプリケーションの開始
本番アプリケーションを停止し、停止した時点から処理を再開して後で再起動したい場合があります。Managed Service for Apache Flink は、スナップショットからのアプリケーションの開始をサポートしています。スナップショットは、アプリケーション状態だけでなく、アプリケーションが消費を停止したソース内のポイント (例えば Kafka トピックのオフセット) も保存します。
スナップショットが有効な場合、Managed Service for Apache Flink はアプリケーションを停止するときに自動的にスナップショットを取得します。このスナップショットは、アプリケーションを再起動するときに使用できます。
StartApplication API コマンドには 3 つの復元オプションがあります。
RESTORE_FROM_LATEST_SNAPSHOT: 最新のスナップショットから復元します。RESTORE_FROM_CUSTOM_SNAPSHOT: カスタムスナップショットから復元します (どれを使用するか指定する必要があります)。SKIP_RESTORE_FROM_SNAPSHOT: スナップショットからの復元をスキップします。アプリケーションは、最初に実行したときと同様に状態なしで開始されます。
アプリケーションを初めて開始するとき、スナップショットはまだ利用できません。選択した復元オプションに関係なく、アプリケーションはスナップショットなしで開始されます。
スナップショットからアプリケーションを開始するプロセスは、次の図で視覚化されています。
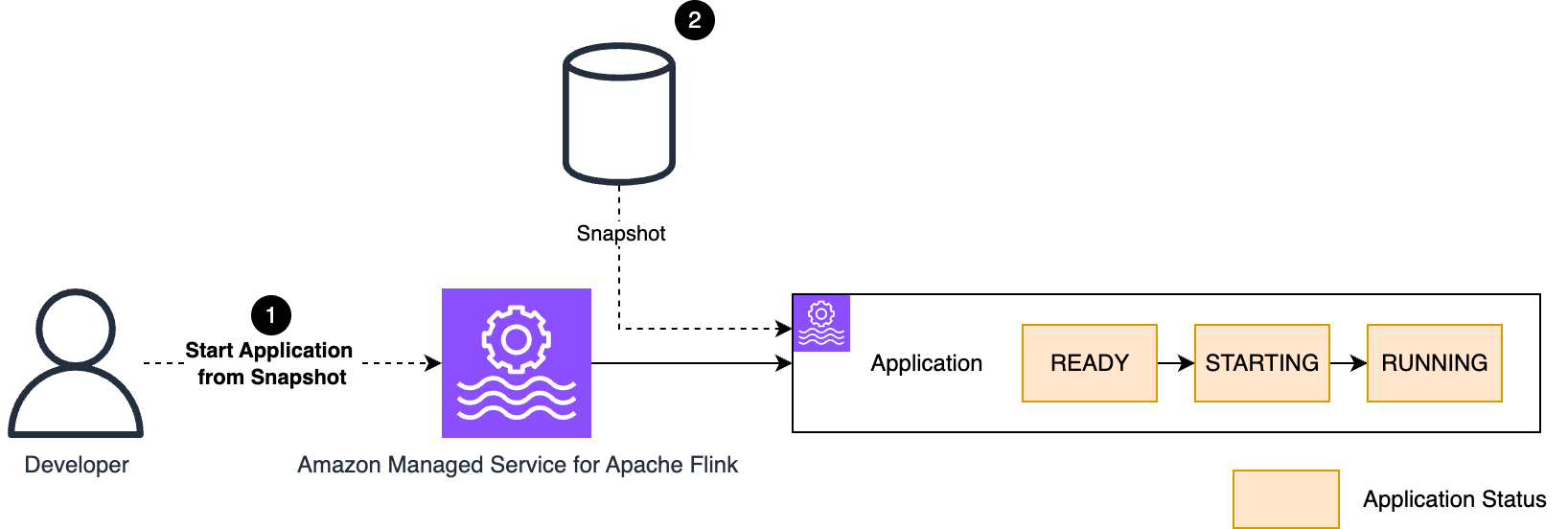
本番環境では、通常、最新のスナップショットから復元したいと思うでしょう (RESTORE_FROM_LATEST_SNAPSHOT)。これにより、最後にアプリケーションを停止したときにサービスが作成したスナップショットが自動的に使用されます。
スナップショットは Flink のセーブポイントメカニズムに基づいており、内部状態の exactly-once の一貫性を維持します。また、スナップショットは Flink ジョブが停止している間に同期的に取得されるため、ソースから重複レコードを再処理するリスクが最小限に抑えられます。
古いスナップショットからのアプリケーションの開始
Managed Service for Apache Flink では、例えば Snapshot Manager を使用して、実行中の本番アプリケーションの定期的なスナップショットの取得をスケジュールできます。実行中のアプリケーションからスナップショットを取得しても処理は停止せず、最小限のオーバーヘッド (チェックポイントと同程度) のみが発生します。2 番目のオプション RESTORE_FROM_CUSTOM_SNAPSHOT を使用すると、最後の StopApplication で取得されたスナップショットよりも古いスナップショットを使用して、アプリケーションを過去の時点に戻すことができます。
ソースの位置 (例えば Kafka トピックのオフセット) もスナップショットとともに復元されるため、アプリケーションはスナップショットが取得されたときに処理していたポイントに戻ります。これにより、その正確なポイントで状態も復元され、一貫性が提供されます。
古いスナップショットからアプリケーションを開始する場合、2 つの重要な考慮事項があります。
- ソースシステムの保持期間内に取得されたスナップショットのみを復元する – ソースの保持期間よりも古いスナップショットを復元すると、データ損失が発生する可能性があり、アプリケーションの動作は予測できません。
- 古いスナップショットからの再起動は重複出力を生成する可能性が高い – エンドツーエンドのシステムが冪等になるように設計されている場合、これは問題にならないことが多いです。ただし、File System sink や exactly-once 保証が有効な Kafka sink などの Flink トランザクションコネクタを使用している場合、問題が発生する可能性があります。これらのシンクは重複を保証しないように設計されている (いかなる犠牲を払っても防止する) ため、古いスナップショットからのアプリケーションの再起動を妨げる可能性があります。この運用上の問題には回避策がありますが、特定のユースケースに依存するため、この記事の範囲外です。
アプリケーション開始時に何が起こるかを理解する
アプリケーションのライフサイクルにおける基本的な操作を学びました。Managed Service for Apache Flink では、これらの操作は StartApplication、UpdateApplication、StopApplication などのいくつかの API アクションによって制御されます。サービスがすべての操作を制御します。Flink クラスターをプロビジョニングまたは管理する必要はありません。ただし、ライフサイクル中に何が起こるかをより深く理解することで、潜在的な障害モードを認識し、より堅牢な自動化を実装するための十分な Mechanical Sympathy が得られます。
READY (実行していない) アプリケーションに対して StartApplication コマンドを発行したときに何が起こるかを詳しく見てみましょう。RUNNING アプリケーションに対して UpdateApplication コマンドを発行すると、アプリケーションは最初にスナップショットとともに停止され、その後、これから見るプロセスと同じプロセスで新しい設定で再起動されます。
Flink クラスターの構成
アプリケーションを開始するときに何が起こるかを理解するには、いくつかの追加の概念を紹介する必要があります。Flink クラスターは 2 種類のノードで構成されています。
- コーディネーターとして機能する単一の Job Manager
- 実際のデータ処理を行う 1 つ以上の Task Manager
Managed Service for Apache Flink では、コンソールからアクセスできる Flink Dashboard でクラスターノードを確認できます。
Flink は、アプリケーションコードで定義されたデータ処理を 1 つ以上のサブタスクに分解し、次の図に示すように Task Manager ノード全体に分散します。
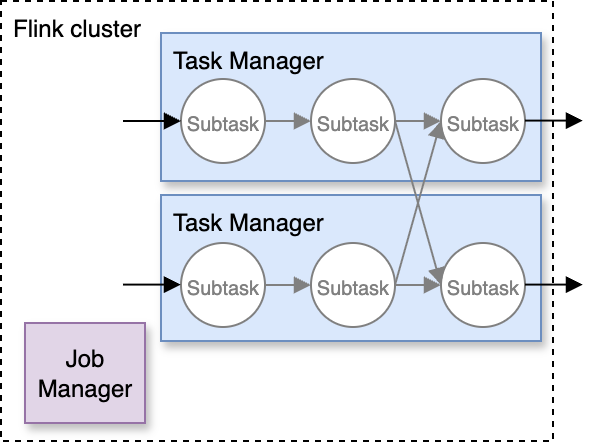
Managed Service for Apache Flink では、クラスターのプロビジョニングと設定について心配する必要はありません。サービスがアプリケーション専用のクラスターを提供します。Task Manager の vCPU、メモリ、ローカルストレージの合計量は、設定した KPU の数と一致します。
Managed Service for Apache Flink アプリケーションの開始
Flink クラスターの構成について説明したので、StartApplication コマンドを発行したとき、または UpdateApplication コマンドで変更がデプロイされた後にアプリケーションが再起動するときに何が起こるかを見てみましょう。
次の図はプロセスを示しています。すべてが自動的に実行されます。
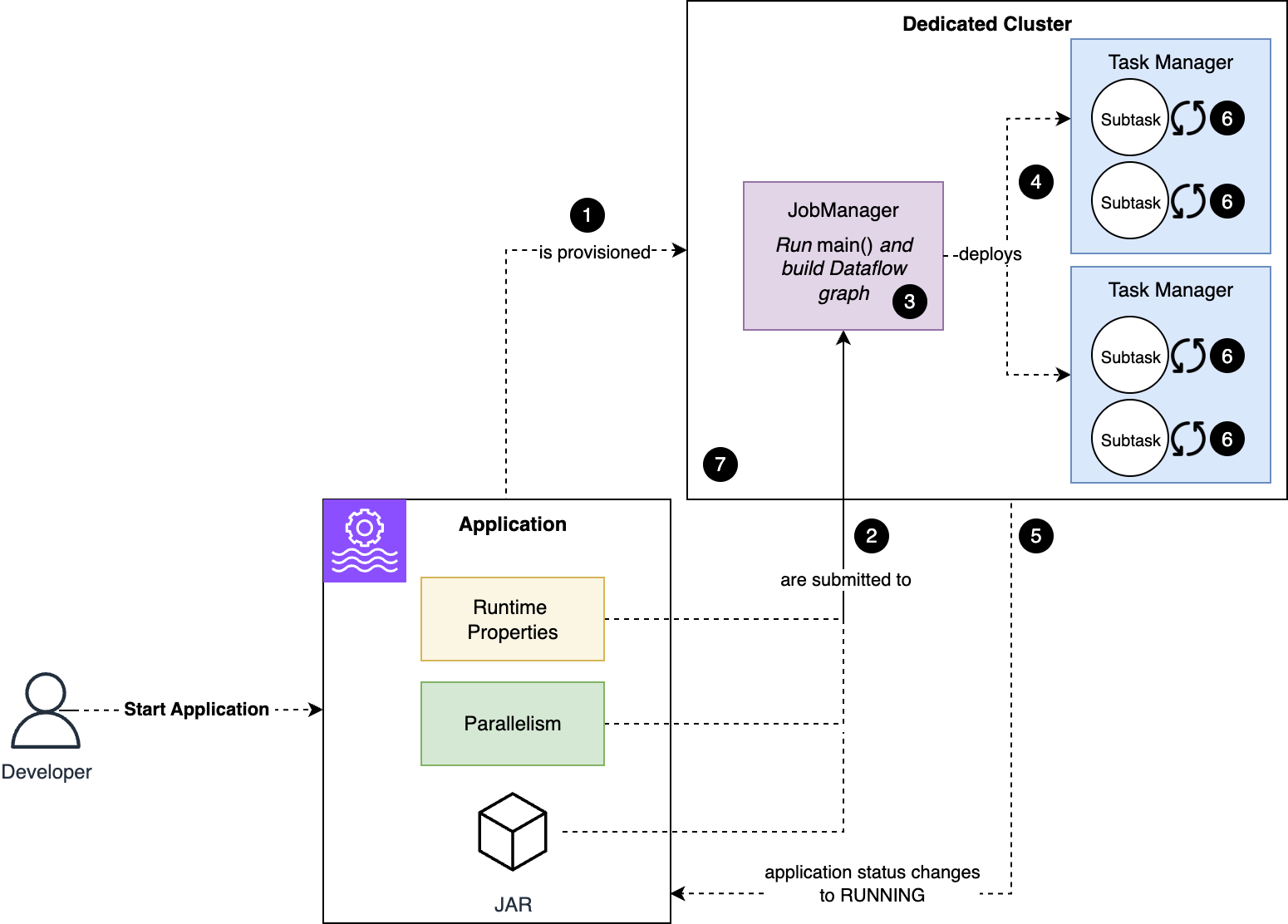
ワークフローは以下のステップで構成されています。
- KPU の数に基づいて要求したリソース量を持つ専用クラスターがアプリケーション用にプロビジョニングされます。
- アプリケーションコード、ランタイムプロパティ、およびアプリケーションの並列度などのその他の設定が、クラスターのコーディネーターである Job Manager ノードに渡されます。
- アプリケーションの
main()メソッド内の Java または Python コードが実行されます。これにより、アプリケーションの演算子の論理グラフ (dataflow と呼ばれる) が生成されます。定義した dataflow とアプリケーションの並列度に基づいて、Flink はサブタスク (データを処理するために Flink が実行する実際のノード) を生成します。 - 次に、Flink はジョブのサブタスクを Task Manager (クラスターの実際のワーカーノード) 全体に分散します。
- 前のステップが成功すると、Flink ジョブのステータスと Managed Service for Apache Flink アプリケーションのステータスが
RUNNINGに変わります。ただし、ジョブはまだ完全に実行されておらず、データを処理していません。すべてのサブタスクを初期化する必要があります。 - 各サブタスクは、スナップショットから開始する場合は状態を独立して復元し、ランタイムリソースを初期化します。例えば、Flink の Kafka ソースコネクタは、セーブポイント (スナップショット) からパーティションの割り当てとオフセットを復元し、Kafka クラスターへの接続を確立し、Kafka トピックをサブスクライブします。このステップ以降、Flink ジョブは未処理のエラーが発生すると停止し、最後のチェックポイントから再起動します。エラーの原因となる問題が一時的でない場合、ジョブは同じチェックポイントからの停止と再起動をループで繰り返します。
- すべてのサブタスクが正常に初期化され、
RUNNINGステータスに変わると、Flink ジョブはデータの処理を開始し、適切に実行されるようになります。
まとめ
この記事では、Managed Service for Apache Flink アプリケーションのライフサイクルが、シンプルな AWS API コマンド、または AWS SDK や AWS CLI を使用した同等のコマンドによってどのように制御されるかについて説明しました。AWS CloudFormation や Terraform などの高レベルの自動化ツールを使用している場合、低レベルのアクションも抽象化されます。サービスは、Flink クラスターの運用と Flink ジョブライフサイクルのオーケストレーションの複雑さを処理します。
ただし、Flink の仕組みとサービスが何をしてくれるかをより深く理解することで、より堅牢な自動化を実装し、障害のトラブルシューティングを行うことができます。
パート 2 では、通常の運用中や変更のデプロイまたはアプリケーションのスケーリング時に発生する可能性のある障害シナリオ、および問題が発生したときに検出して回復するための操作のモニタリング方法について引き続き説明します。
著者について
 Lorenzo Nicora AWS のシニアストリーミングソリューションアーキテクトとして、EMEA 全域のお客様を支援しています。25 年以上にわたり、コンサルティング会社やプロダクト企業を通じて、さまざまな業界でクラウド中心のデータ集約型システムを構築してきました。オープンソース技術を幅広く活用し、Apache Flink を含む複数のプロジェクトに貢献しており、Flink Prometheus コネクタのメンテナーでもあります。
Lorenzo Nicora AWS のシニアストリーミングソリューションアーキテクトとして、EMEA 全域のお客様を支援しています。25 年以上にわたり、コンサルティング会社やプロダクト企業を通じて、さまざまな業界でクラウド中心のデータ集約型システムを構築してきました。オープンソース技術を幅広く活用し、Apache Flink を含む複数のプロジェクトに貢献しており、Flink Prometheus コネクタのメンテナーでもあります。
 Felix John ドイツを拠点とする AWS のグローバルソリューションアーキテクトであり、データストリーミングのエキスパートです。グローバルな自動車・製造業のお客様のクラウドジャーニーをサポートすることに注力しています。仕事以外では、フロアボールやハイキングを楽しんでいます。
Felix John ドイツを拠点とする AWS のグローバルソリューションアーキテクトであり、データストリーミングのエキスパートです。グローバルな自動車・製造業のお客様のクラウドジャーニーをサポートすることに注力しています。仕事以外では、フロアボールやハイキングを楽しんでいます。
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。