Amazon Web Services ブログ
Amazon Managed Service for Apache Flink アプリケーションのライフサイクルの詳細 – パート 2
本記事は 2025 年 9 月 3 日 に公開された「Deep dive into the Amazon Managed Service for Apache Flink application lifecycle – Part 2」を翻訳したものです。
このシリーズのパート 1 では、Amazon Managed Service for Apache Flink アプリケーションのライフサイクルを制御するための基本的な操作について説明しました。AWS CloudFormation や Terraform などの高レベルツールを使用している場合、ツールがこれらの操作を実行してくれます。しかし、基本的な操作とサービスが自動的に行うことを理解することで、ある程度のメカニカルシンパシーを得て、より堅牢な自動化を自信を持って実装できます。
このシリーズの最初のパートでは、ハッピーパスに焦点を当てました。理想的な世界では、障害は発生せず、デプロイするすべての変更は完璧に動作します。しかし、現実の世界はそれほど予測可能ではありません。Amazon の CTO である Werner Vogels の言葉を引用すると、「すべてのものは常に故障する」のです。
この記事では、通常の運用中や変更のデプロイ、アプリケーションのスケーリング時に発生する可能性のある障害シナリオと、問題が発生したときに検出して回復するための操作の監視方法について説明します。
ハッピーパスではない場合
堅牢な自動化は、特に操作中の障害シナリオを処理するように設計する必要があります。そのためには、Apache Flink がハッピーパスからどのように逸脱する可能性があるかを理解する必要があります。ステートフルなストリーム処理エンジンとしての Flink の性質上、障害シナリオの検出と解決には、マイクロサービスや短命なサーバーレス関数 (AWS Lambda など) などの他の長時間実行アプリケーションとは異なる手法が必要です。
ランタイムエラー時の Flink の動作: 失敗と再起動のループ
Flink ジョブがランタイムで予期しないエラー (未処理の例外) に遭遇した場合、通常の動作は失敗し、処理を停止し、最新のチェックポイントから再起動することです。チェックポイントにより、Flink は障害発生時のデータ整合性とデータ損失なしをサポートできます。また、Flink は継続的に実行されるストリーム処理アプリケーション向けに設計されているため、エラーが再び発生した場合、デフォルトの動作は再起動を続け、問題が一時的であり、アプリケーションが最終的に通常の処理を回復することを期待することです。ただし、問題が一時的でない場合もあります。たとえば、ジョブがデータの処理を開始するとすぐに失敗するバグを含むコード変更をデプロイした場合や、予期されるスキーマがソース内のレコードと一致せず、デシリアライゼーションまたは処理エラーが発生する場合です。コネクタが外部システムに到達できないように設定を誤って変更した場合も、同じシナリオが発生する可能性があります。これらの場合、ジョブは無期限に、またはアクティブに強制停止するまで、失敗と再起動のループに陥ります。
これが発生すると、Managed Service for Apache Flink アプリケーションのステータスは RUNNING かもしれませんが、基盤となる Flink ジョブは実際には失敗と再起動を繰り返しています。AWS マネジメントコンソールは、アプリケーションに注意が必要である可能性があることを示すヒントを表示します (次のスクリーンショットを参照)。
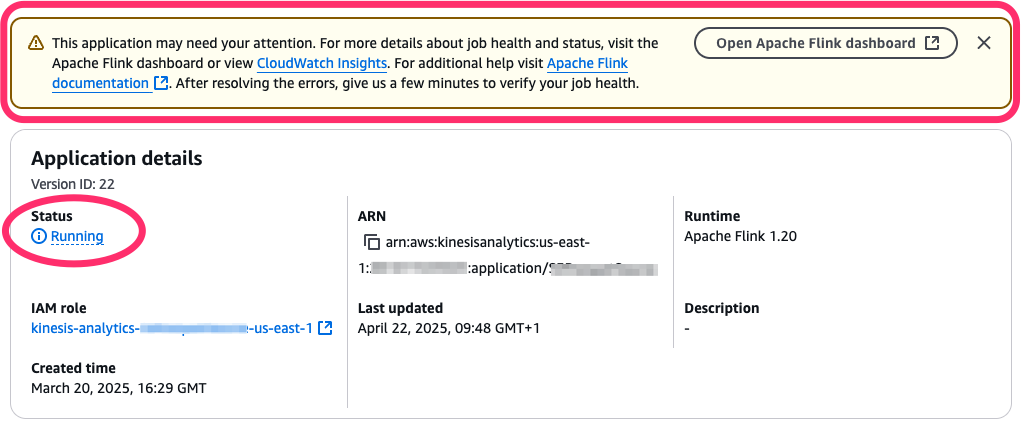
以降のセクションでは、この状況に自動的に対応するために、アプリケーションとジョブのステータスを監視する方法を学びます。
アプリケーションの起動または更新がうまくいかない場合
障害モードを理解するために、アプリケーションを起動したとき、またはこのシリーズのパート 1 で説明したように UpdateApplication コマンドを発行した後にアプリケーションが再起動したときに自動的に何が起こるかを確認しましょう。次の図は、アプリケーションが起動するときに何が起こるかを示しています。
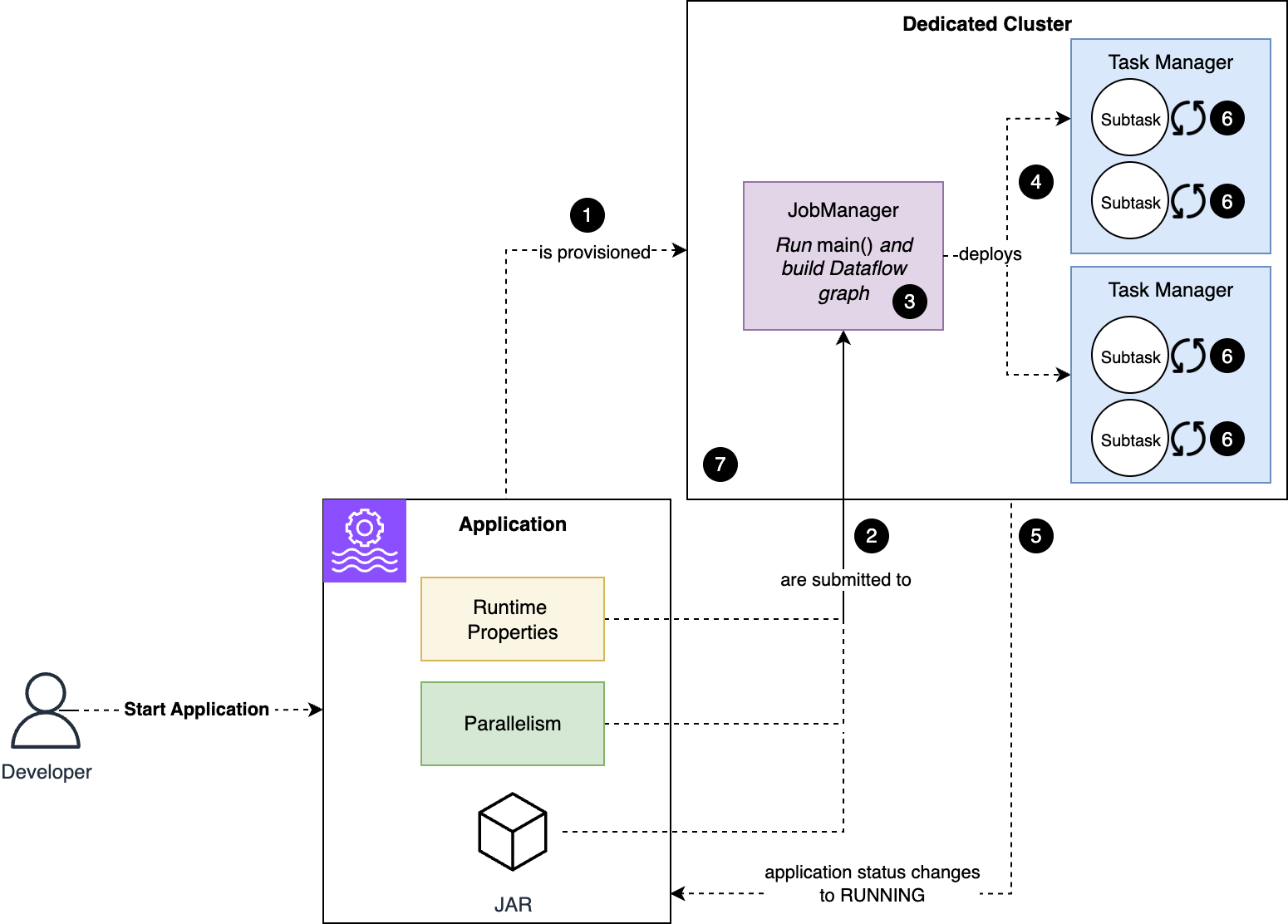
ワークフローは次のステップで構成されます。
- Managed Service for Apache Flink がアプリケーション専用のクラスターをプロビジョニングします。
- コードと設定が Job Manager ノードに送信されます。
- アプリケーションの
main()メソッドのコードが実行され、アプリケーションのデータフローが定義されます。 - Flink がジョブを構成するサブタスクを Task Manager ノードにデプロイします。
- ジョブとアプリケーションのステータスが
RUNNINGに変わります。ただし、サブタスクの初期化はここから始まります。 - サブタスクは状態を復元し (該当する場合)、リソースを初期化します。たとえば、Kafka コネクタのサブタスクは Kafka クライアントを初期化し、トピックをサブスクライブします。
- すべてのサブタスクが正常に初期化されると、
RUNNINGステータスに変わり、ジョブがデータの処理を開始します。
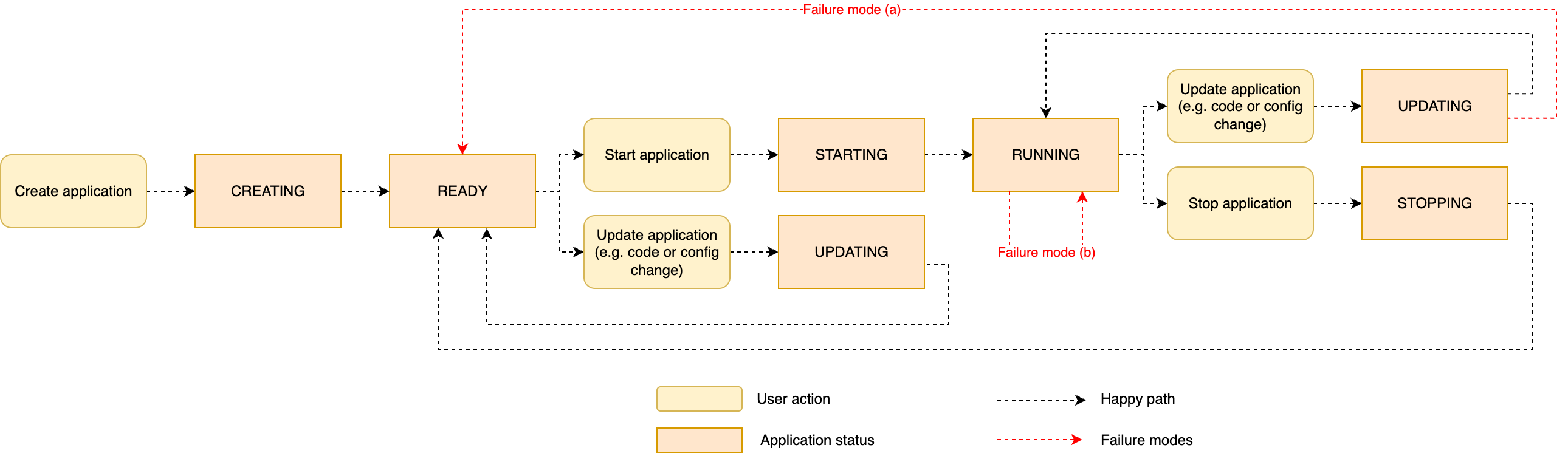
Flink の新規ユーザーにとって、RUNNING ステータスが必ずしもジョブが正常でデータを処理していることを意味しないことは混乱を招く可能性があります。アプリケーションの起動 (または再起動) プロセス中に何か問題が発生した場合、問題が発生したフェーズによって、2 つの異なるタイプの障害モードが観察される可能性があります。
- (a) 問題によりアプリケーションコードのデプロイが妨げられる – コードと設定が Job Manager に渡されるとすぐにデプロイが失敗した場合 (プロセスのステップ 2)、アプリケーションはこの障害シナリオに遭遇する可能性があります。たとえば、アプリケーションコードパッケージが不正な形式の場合です。典型的なエラーは、JAR に
mainClassがない場合、またはmainClassが存在しないクラスを指している場合です。この障害モードは、main()メソッドのコードが未処理の例外をスローした場合 (ステップ 3) にも発生する可能性があります。これらの場合、アプリケーションはRUNNINGに変更できず、試行後にREADYに戻ります。 - (b) アプリケーションは起動したが、ジョブが失敗と再起動のループに陥る – アプリケーションのステータスが
RUNNINGに変更された後、プロセスの後半で問題が発生する可能性があります。たとえば、Flink ジョブがクラスターにデプロイされた後 (プロセスのステップ 4)、コンポーネントの初期化に失敗する可能性があります (ステップ 6)。これは、コネクタの設定が間違っている場合や、問題により外部システムへの接続が妨げられている場合に発生する可能性があります。たとえば、Kafka コネクタは、コネクタの設定ミスやネットワークの問題により、Kafka クラスターへの接続に失敗する可能性があります。もう 1 つの可能なシナリオは、Flink ジョブが正常に初期化されたが、データの処理を開始するとすぐに例外をスローする場合です (ステップ 7)。これが発生すると、Flink はランタイムエラーに反応し、失敗と再起動のループに陥る可能性があります。
次の図は、先ほど説明した 2 つの障害シナリオを含む、アプリケーションステータスのシーケンスを示しています。
トラブルシューティング
操作中、特に RUNNING アプリケーションを更新したり、設定を変更した後にアプリケーションを再起動したりするときに何が問題になる可能性があるかを調べました。このセクションでは、これらの障害シナリオにどのように対処できるかを説明します。
変更のロールバック
変更をデプロイして何かがうまくいっていないことに気づいた場合、通常は変更をロールバックして、問題を調査して修正するまでアプリケーションを正常な状態に戻したいと思います。Managed Service for Apache Flink は、変更を元に戻す (ロールバックする) 優雅な方法を提供し、障害のある変更を適用する前に停止した時点から処理を再開し、整合性とデータ損失なしを提供します。Managed Service for Apache Flink には、2 種類のロールバックがあります。
- 自動 – 自動ロールバック (システムロールバックとも呼ばれる) 中、有効になっている場合、サービスは変更後にアプリケーションの再起動に失敗したとき、またはジョブが開始したがすぐに失敗と再起動のループに陥ったときを自動的に検出します。これらの状況では、ロールバックプロセスは最後の変更が適用される前のアプリケーション設定バージョンを自動的に復元し、変更がデプロイされたときに取得されたスナップショットからアプリケーションを再起動します。詳細については、Improve the resilience of Amazon Managed Service for Apache Flink application with system-rollback feature を参照してください。この機能はデフォルトで無効になっています。アプリケーション設定の一部として有効にできます。
- 手動 – 手動ロールバック API 操作はシステムロールバックに似ていますが、ユーザーによって開始されます。アプリケーションが実行中で、変更を適用した後に何かが期待どおりに動作していないことを観察した場合、RollbackApplication API アクションまたはコンソールを使用してロールバック操作をトリガーできます。手動ロールバックは、アプリケーションが
RUNNINGまたはUPDATINGのときに可能です。
両方のロールバックは同様に機能し、変更前の設定バージョンを復元し、変更前に取得されたスナップショットで再起動します。これにより、データ損失が防止され、動作していたアプリケーションのバージョンに戻ります。また、これは以前の設定バージョン (ロールバック先のバージョン) を作成したときに保存されたコードパッケージを使用するため、その間にコードパッケージを Amazon Simple Storage Service (Amazon S3) バケットから置き換えたり削除したりしても、コード、設定、スナップショット間に不整合はありません。
暗黙的なロールバック: 古い設定での更新
変更をロールバックする 3 番目の方法は、設定を更新して、最後の変更前の状態に戻すことです。これにより新しい設定バージョンが作成され、UpdateApplication コマンドを発行するときに、正しいバージョンのコードパッケージが S3 バケットで利用可能である必要があります。
サービスがシステムロールバックとマネージド RollbackApplication アクションを提供しているのに、なぜ 3 番目のオプションがあるのでしょうか?Terraform などのほとんどの高レベルの Infrastructure as Code (IaC) フレームワークがこの戦略を使用し、設定を明示的に上書きするためです。低レベルのアクションに基づいて自動化を実装する場合はおそらくマネージドロールバックを使用しますが、この可能性を理解することは重要です。
この暗黙的なロールバックについて考慮すべき 2 つの重要な注意点があります。
- 通常、障害のある変更がデプロイされる前に取得されたスナップショットからアプリケーションを再起動したいと思います。アプリケーションが現在
RUNNINGで正常な場合、これは最新のスナップショット (RESTORE_FROM_LATEST_SNAPSHOT) ではなく、その前のスナップショットです。RESTORE_FROM_CUSTOM_SNAPSHOTからの再起動を設定し、正しいスナップショットを選択する必要があります。 - UpdateApplication は、アプリケーションが
RUNNINGで正常であり、ジョブをスナップショットで正常に停止できる場合にのみ機能します。逆に、アプリケーションが失敗と再起動のループに陥っている場合は、まず強制停止し、アプリケーションがREADYの間に設定を変更し、その後、障害のある変更がデプロイされる前に取得されたスナップショットからアプリケーションを起動する必要があります。
アプリケーションの強制停止
通常のシナリオでは、自動スナップショット作成でアプリケーションを正常に停止します。ただし、Flink ジョブが失敗と再起動のループに陥っている場合など、一部のシナリオではこれが不可能な場合があります。これは、たとえば、ジョブが使用する外部システムが動作を停止した場合や、AWS Identity and Access Management (IAM) 設定が誤って変更され、ジョブに必要な権限が削除された場合に発生する可能性があります。
障害のある変更後に Flink ジョブが失敗と再起動のループに陥った場合、最初のオプションは RollbackApplication を使用することです。これにより、以前の設定が自動的に復元され、正しいスナップショットから開始されます。アプリケーションを正常に停止できない、または RollbackApplication を使用できないまれなケースでは、最後の手段はアプリケーションの強制停止です。強制停止は、Force=true を指定した StopApplication コマンドを使用します。コンソールからアプリケーションを強制停止することもできます。
アプリケーションを強制停止すると、スナップショットは取得されません (それが可能であれば、正常に停止できたはずです)。アプリケーションを再起動するときは、スナップショットからの復元をスキップする (SKIP_RESTORE_FROM_SNAPSHOT) か、Snapshot Manager を使用してスケジュールされた、またはコンソールや CreateApplicationSnapshot API アクションを使用して手動で以前に取得されたスナップショットを使用できます。
状態なしで再起動する余裕がないすべての本番アプリケーションに対して、スケジュールされたスナップショットを設定することを強くお勧めします。
Apache Flink アプリケーション操作の監視
操作中および操作後の Apache Flink アプリケーションの効果的な監視は、操作の結果を検証し、何か問題が発生した場合にライフサイクル自動化がアラームを発生させたり対応したりできるようにするために重要です。
操作中に使用できる主な指標には、FullRestarts メトリクス (Amazon CloudWatch で利用可能) と、アプリケーション、ジョブ、タスクのステータスがあります。
操作の結果の監視
StartApplication や UpdateApplication などの操作の結果を検出する最も簡単な方法は、ListApplicationOperations API コマンドを使用することです。このコマンドは、アプリケーションの再起動を強制するメンテナンスイベントを含む、特定のアプリケーションの最新の操作のリストを返します。
たとえば、最新の操作のステータスを取得するには、次のコマンドを使用できます。
出力は次のコードのようになります。
OperationStatus は、コンソールと DescribeApplication によって報告されるアプリケーションステータスと同じロジックに従います。これは、オペレーターの初期化中やジョブがデータの処理を開始している間の障害を検出できない可能性があることを意味します。学んだように、これらの障害はアプリケーションを失敗と再起動のループに陥らせる可能性があります。自動化を使用してこれらのシナリオを検出するには、このセクションの残りで説明する他の手法を使用する必要があります。
FullRestarts メトリクスを使用した失敗と再起動のループの検出
アプリケーションが失敗と再起動のループに陥っているかどうかを検出する最も簡単な方法は、CloudWatch Metrics で利用可能な fullRestarts メトリクスを使用することです。このメトリクスは、StartApplication コマンドでアプリケーションを起動した後、または UpdateApplication で再起動した後の Flink ジョブの再起動回数をカウントします。
正常なアプリケーションでは、完全な再起動の回数は理想的にはゼロであるべきです。デプロイまたは計画されたメンテナンス中に 1 回の完全な再起動は許容される場合があります。複数回の再起動は通常、何らかの問題を示しています。1 回の再起動、または連続する数回の再起動でアラームをトリガーしないことをお勧めします。
アラームは、アプリケーションが失敗と再起動のループに陥っている場合にのみトリガーされるべきです。これは、比較的短い期間に複数回の再起動が発生したかどうかを確認することを意味します。期間を決定することは簡単ではありません。Flink ジョブがチェックポイントから再起動するのにかかる時間は、アプリケーション状態のサイズに依存するためです。ただし、アプリケーションの状態が KPU あたり数 GB 未満の場合、アプリケーションは 1 分未満で起動すると安全に想定できます。
目標は、fullRestarts が複数回の再起動に十分な期間にわたって増加し続けるときにトリガーされる CloudWatch アラームを作成することです。たとえば、アプリケーションが 1 分未満で再起動すると仮定すると、fullRestarts メトリクスの DIFF 数式に依存する CloudWatch アラームを作成できます。次のスクリーンショットは、アラームの詳細の例を示しています。

この例は保守的なアラームで、アプリケーションが 5 分以上再起動し続けた場合にのみトリガーされます。これは、少なくとも 5 分後に問題を検出することを意味します。障害をより早く検出するために時間を短縮することを検討できます。ただし、1 回または 2 回の再起動だけでアラームをトリガーしないように注意してください。サービスによって管理される通常のメンテナンス (パッチ適用) 中や、外部システムの一時的なエラーなど、時折再起動が発生する可能性があります。Flink は、最小限のダウンタイムとデータ損失なしでこれらの状態から回復するように設計されています。
ジョブが稼働しているかどうかの検出: アプリケーション、ジョブ、タスクのステータスの監視
アプリケーション、ジョブ、サブタスクのステータスが異なることについて説明しました。Managed Service for Apache Flink では、サブタスクがクラスターに正常にデプロイされると、アプリケーションとジョブのステータスが RUNNING に変わります。ただし、すべてのサブタスクが RUNNING になるまで、ジョブは実際には実行されておらず、データを処理していません。
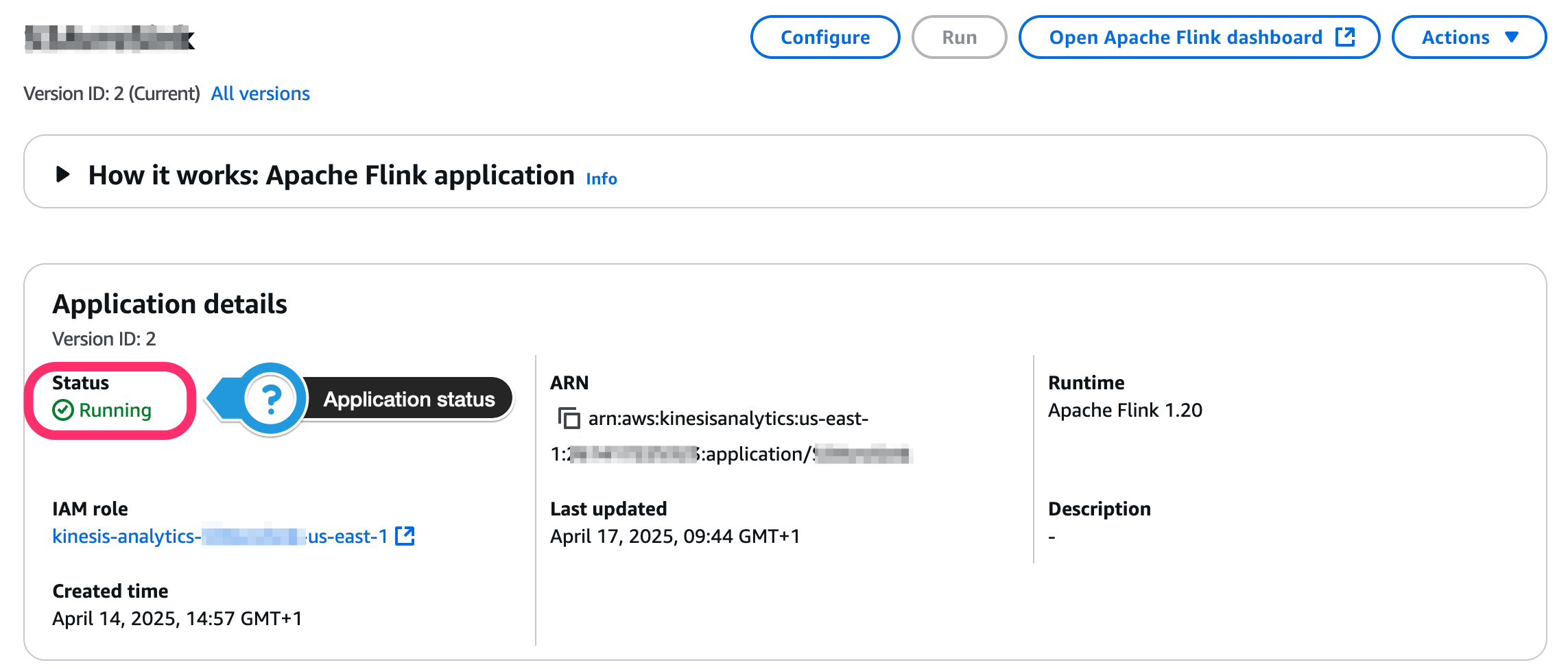
操作中のアプリケーションステータスの観察
アプリケーションのステータスは、次のスクリーンショットに示すように、コンソールに表示されます。
自動化では、DescribeApplication API アクションをポーリングしてアプリケーションのステータスを観察できます。次のコマンドは、AWS Command Line Interface (AWS CLI) と jq コマンドを使用してアプリケーションのステータス文字列を抽出する方法を示しています。
ジョブとサブタスクのステータスの観察
Managed Service for Apache Flink は、すべてのサブタスクのステータスを含むトラブルシューティングに役立つ情報を提供する Flink Dashboard へのアクセスを提供します。たとえば、次のスクリーンショットは、すべてのサブタスクが RUNNING である正常なジョブを示しています。
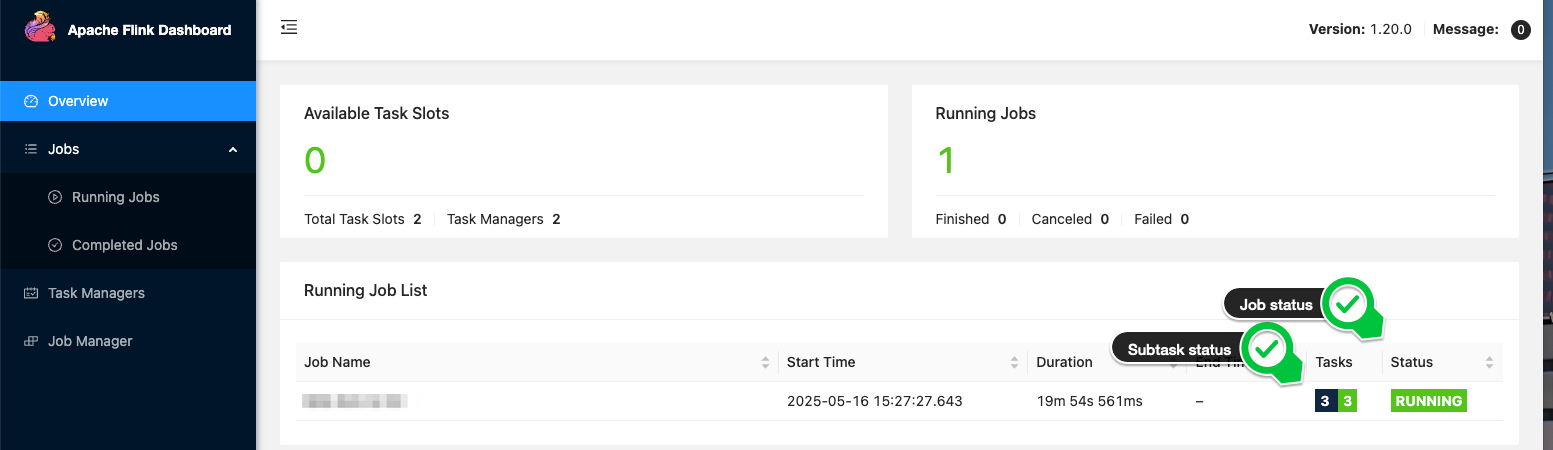
次のスクリーンショットでは、サブタスクが失敗して再起動しているジョブを確認できます。

自動化では、アプリケーションを起動したり変更をデプロイしたりするときに、ジョブが最終的に稼働してデータを処理していることを確認したいと思います。これは、すべてのサブタスクが RUNNING のときに発生します。操作後にジョブのステータスが RUNNING になるのを待つことは完全に安全ではないことに注意してください。サブタスクは、RUNNING として報告された後でも失敗し、ジョブが再起動する可能性があります。
ライフサイクル操作を実行した後、自動化は 2 つのイベントのいずれかを待ってサブタスクのステータスをポーリングできます。
- すべてのサブタスクが
RUNNINGを報告 – これは操作が成功し、Flink ジョブが稼働していることを示します。 - いずれかのサブタスクが
FAILINGまたはCANCELEDを報告 – これは何か問題が発生し、アプリケーションが失敗と再起動のループに陥っている可能性があることを示します。たとえば、アプリケーションを強制停止してから変更をロールバックするなど、介入が必要です。
スナップショットから再起動していて、アプリケーションの状態がかなり大きい場合、サブタスクが INITIALIZING ステータスをより長く報告することがあります。初期化中、Flink は RUNNING に変更する前にオペレーターの状態を復元します。
Flink REST API はサブタスクの状態を公開し、自動化で使用できます。Managed Service for Apache Flink では、これには 3 つのステップが必要です。
- CreateApplicationPresignedUrl API アクションを使用して、Flink REST API にアクセスするための署名付き URL を生成します。
- Flink REST API の
/jobsエンドポイントに GET リクエストを行い、ジョブ ID を取得します。 /jobs/<job-id>エンドポイントに GET リクエストを行い、サブタスクのステータスを取得します。
次の GitHub リポジトリには、指定された Managed Service for Apache Flink アプリケーションのタスクのステータスを取得するシェルスクリプトが用意されています。
ジョブ実行中のサブタスク障害の監視
Flink REST API をポーリングするアプローチは、操作の直後に自動化で使用して、操作が最終的に成功したかどうかを観察できます。
ジョブの実行中に障害を検出するために Flink REST API を継続的にポーリングしないことを強くお勧めします。この操作はリソースを消費し、パフォーマンスを低下させたりエラーを引き起こしたりする可能性があります。
通常の操作中に疑わしいサブタスクのステータス変更を監視するには、代わりに CloudWatch Logs を使用することをお勧めします。次の CloudWatch Logs Insights クエリは、すべてのサブタスクの状態遷移を抽出します。
Managed Service for Apache Flink が処理のダウンタイムを最小化する方法
Flink が強力な整合性のために設計されていることを見てきました。exactly-once の状態整合性を保証するために、Flink はスケーリングを含むあらゆる変更をデプロイするために処理を一時的に停止します。このダウンタイムは、Flink がアプリケーション状態の整合性のあるコピーを取得し、セーブポイントに保存するために必要です。変更がデプロイされた後、ジョブはセーブポイントから再起動され、データ損失はありません。Managed Service for Apache Flink では、更新は完全にマネージドです。スナップショットが有効になっている場合、UpdateApplication は自動的にジョブを停止し、スナップショット (Flink のセーブポイントに基づく) を使用して状態を保持します。
Flink はデータ損失がないことを保証します。ただし、ビジネス要件やサービスレベル目標 (SLO) によって、ダウンストリームシステムが受信するデータの最大遅延、またはエンドツーエンドのレイテンシーが課される場合もあります。この遅延は、処理のダウンタイム、つまり Flink が変更をデプロイできるようにするためにジョブがデータを処理しない時間の影響を受けます。Flink では、ある程度の処理ダウンタイムは避けられません。ただし、Managed Service for Apache Flink は、変更をデプロイするときの処理ダウンタイムを最小化するように設計されています。
サービスが完全な分離のためにアプリケーションを専用クラスターで実行することを見てきました。RUNNING アプリケーションで UpdateApplication を発行すると、サービスは必要な量のリソースを持つ新しいクラスターを準備します。この操作には時間がかかる場合があります。ただし、サービスは新しいクラスターの準備ができるまで、元のクラスターでジョブを実行してデータを処理し続けるため、処理のダウンタイムには影響しません。この時点で、サービスはセーブポイントでジョブを停止し、新しいクラスターで再起動します。
この操作中、単一クラスターの KPU 数に対してのみ課金されます。
次の図は、更新操作の期間 (アプリケーションのステータスが UPDATING である時間) と、Flink Dashboard に表示されるジョブのステータスから観察できる処理のダウンタイムの違いを示しています。
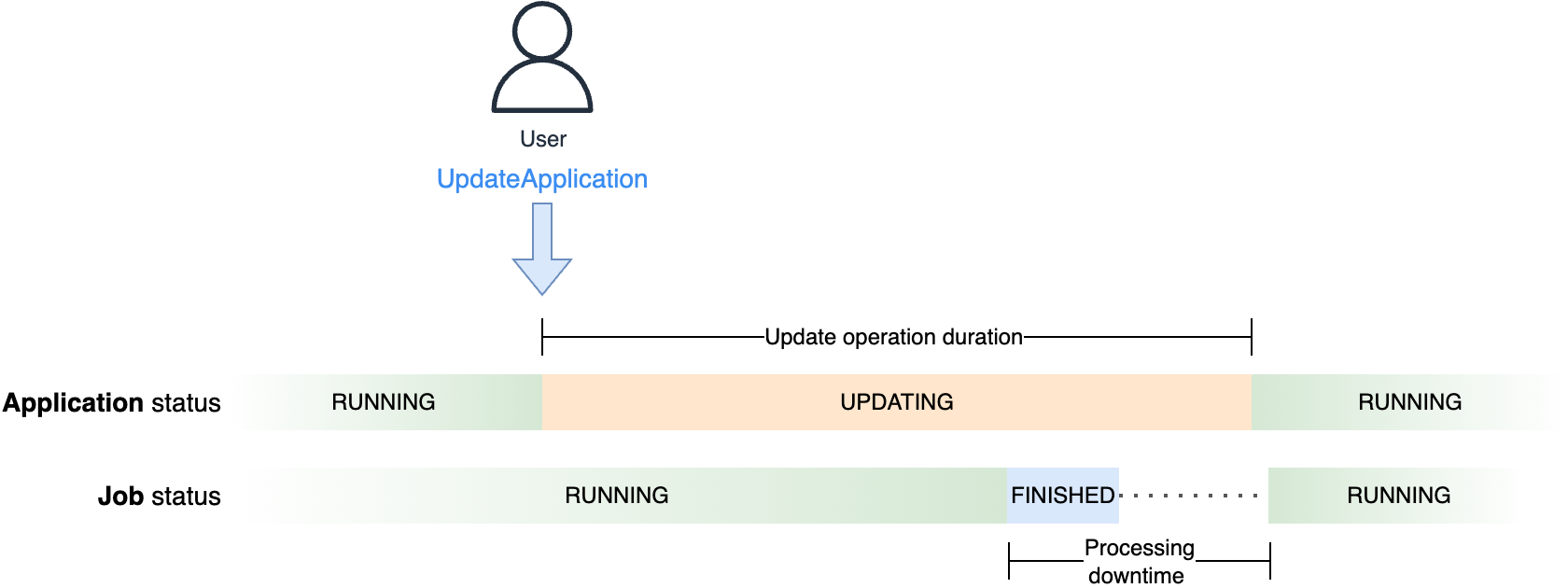
実行中のアプリケーションの設定を更新するとき (変更がなくても)、アプリケーションコンソールと Flink Dashboard の両方を開いたままにしておくと、このプロセスを観察できます。サービスが新しいクラスターに切り替わると、Flink Dashboard は一時的に利用できなくなります。さらに、このスコープでジョブのステータスを確認するために提供したスクリプトを使用することはできません。クラスターは破棄されるまで Flink Dashboard を提供し続けますが、アプリケーションが UPDATING の間は CreateApplicationPresignedUrl アクションは機能しません。
処理時間 (ジョブがどちらのクラスターでも実行されていない時間) は、ジョブがセーブポイント (スナップショット) で停止し、新しいクラスターで状態を復元するのにかかる時間に依存します。この時間は主にアプリケーション状態のサイズに依存します。データスキューも、バリアアライメントメカニズムによりセーブポイント時間に影響を与える可能性があります。Flink のバリアアライメントメカニズムの詳細については、Optimize checkpointing in your Amazon Managed Service for Apache Flink applications with buffer debloating and unaligned checkpoints を参照してください。セーブポイントは常にアライメントされることに注意してください。
自動化のスコープでは、通常、ジョブが稼働してデータを処理するまで待ちたいと思います。通常、タイムアウトを設定したいと思います。アプリケーションとジョブの両方がこのタイムアウト内に RUNNING に戻らない場合、おそらく何か問題が発生しており、アラームを発生させるか、ロールバックを強制したい場合があります。このタイムアウトは、更新操作全体の期間を考慮する必要があります。
まとめ
この記事では、変更をデプロイしたりアプリケーションをスケーリングしたりするときに発生する可能性のある障害シナリオについて説明しました。Managed Service for Apache Flink のロールバック機能が、変更がうまくいかなかった後に安全な場所にシームレスに戻す方法を示しました。また、アプリケーション、ジョブ、サブタスクのステータスを観察するための操作の監視を自動化する方法と、fullRestarts メトリクスを使用してジョブが失敗と再起動のループに陥っているときを検出する方法についても説明しました。
詳細については、Run a Managed Service for Apache Flink application、Implement fault tolerance in Managed Service for Apache Flink、Manage application backups using Snapshots を参照してください。
著者について
 Lorenzo Nicora AWS の Senior Streaming Solution Architect として、EMEA 全域のお客様を支援しています。25 年以上にわたり、コンサルティング会社やプロダクト企業を通じて、クラウド中心のデータ集約型システムを構築してきました。オープンソース技術を幅広く活用し、Apache Flink を含む複数のプロジェクトに貢献しており、Flink Prometheus コネクタのメンテナーでもあります。
Lorenzo Nicora AWS の Senior Streaming Solution Architect として、EMEA 全域のお客様を支援しています。25 年以上にわたり、コンサルティング会社やプロダクト企業を通じて、クラウド中心のデータ集約型システムを構築してきました。オープンソース技術を幅広く活用し、Apache Flink を含む複数のプロジェクトに貢献しており、Flink Prometheus コネクタのメンテナーでもあります。
 Felix John ドイツを拠点とする AWS の Global Solutions Architect であり、データストリーミングのエキスパートです。グローバルな自動車・製造業のお客様のクラウドジャーニーをサポートすることに注力しています。仕事以外では、フロアボールや山でのハイキングを楽しんでいます。
Felix John ドイツを拠点とする AWS の Global Solutions Architect であり、データストリーミングのエキスパートです。グローバルな自動車・製造業のお客様のクラウドジャーニーをサポートすることに注力しています。仕事以外では、フロアボールや山でのハイキングを楽しんでいます。
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。