Amazon Web Services ブログ
大規模モデル推論コンテナを使って AWS Inferentia2 に大規模言語モデルをデプロイ
本稿は、2023年4月10日に公開された “Deploy large language models on AWS Inferentia2 using large model inference containers” を翻訳したものです。
機械学習 (ML) の専門家でなくても、大規模言語モデル (LLM) の恩恵を受けることができます。検索結果の改善、視覚障碍者のための画像認識、テキストからの斬新なデザインの作成、インテリジェントなチャットボットなどは、これらのモデルがさまざまなアプリケーションやタスクを実現しているうちのほんの一例です。
ML の専門家たちは、これらのモデルの精度と能力を絶えず向上させ続けています。その結果、トランスフォーマーモデルの進化の流れに見られるように、これらのモデルはサイズが大きくなり、より良く汎化されるようになりました。以前の記事では、Amazon SageMaker のディープラーニングコンテナ (DLC) を活用し、GPU ベースのインスタンスを用いてこの種の大規模モデルをデプロイする方法について説明しました。
本稿では、前回と同様のアプローチをとりますが、AWS Inferentia2 上でモデルをホストします。ここでは、AWS Neuron ソフトウェア開発キット (SDK) を使って Inferentia デバイスにアクセスし、その高いパフォーマンスの恩恵を受けます。そして、モデルサービングのソリューションとして、Deep Java Library (DJLServing) を搭載した大規模モデル推論コンテナを使用します。Amazon Elastic Compute Cloud (Amazon EC2) の inf2.48xlarge インスタンスに OPT-13B モデルをデプロイし、これら3つのレイヤーがどのように連携しているかをデモンストレーションします。
三本の柱
以下の図は、大規模言語モデルの最高のコストパフォーマンスを引き出すために働くハードウェアとソフトウェアのレイヤーを表しています。AWS Neuron と tranformer-neuronx は、AWS Inferentia 上で深層学習ワークロードを実行するために使用される SDK です。そして、DJLServing は、コンテナに統合されたサービングソリューションです。
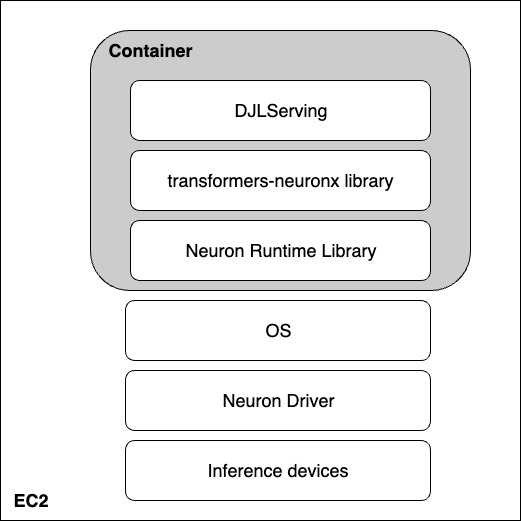
ハードウェア: Inferentia
AWS によって推論用途向けに設計された AWS Inferentia は、高性能かつ低コストの ML 推論アクセラレータです。本稿では、第二世代の ML 推論特化型アクセラレータである AWS Inferentia2 (Inf2 インスタンスで利用可能) を使用します。
それぞれの EC2 Inf2 インスタンスは、最大12台の Inferentia2 デバイスを搭載し、4つのインスタンスサイズから選択することが可能です。
Amazon EC2 Inf2 は、低レイテンシーかつ高帯域幅のチップ間の内部接続である NeuronLink v2 をサポートしており、AllReduce や AllGather などの高性能な集合通信操作 (collective communication operation) を可能にします。これにより、AWS Inferentia2 のデバイス間で (テンソル並列化などにより) 効率的にモデルをシャードし、レイテンシーとスループットが最適化されます。これは、大規模言語モデルで特に有効です。ベンチマーク性能の数値については、AWS Neuron Performance を参照してください。

Amazon EC2 Inf2 インスタンスの心臓部には AWS Inferentia2 デバイスがあり、それぞれふたつの NeuronCore-v2 が搭載されています。各 NeuronCore-v2 は、独立した異種計算ユニットであり、テンソル、ベクトル、スカラー、GPSIMD の4つのメインエンジンを備えています。また、データの局所性 (data locality) を最大化するために、オンチップのソフトウェアマネージド SRAM メモリが搭載されています。以下の図は、AWS Inferentia2 デバイスアーキテクチャーの内部構造を示しています。

Neuron と transformers-neuronx
ハードウェアレイヤーの上には、AWS Inferentia と対話するためのソフトウェアレイヤーがあります。AWS Neuron は、AWS Inferentia と AWS Trainium ベースのインスタンス上で深層学習ワークロードを実行するために使用される SDK です。これにより、新しいモデルの構築、学習、最適化、本番環境へのデプロイなど、エンドツーエンドの ML 開発ライフサイクルを実現することができます。AWS Neuron には、TensorFlow や PyTorch のような一般的なフレームワークとネイティブに統合された深層学習コンパイラ、ランタイム、およびツールが含まれています。
transformers-neuronx は、AWS Neuron チームが構築したオープンソースのライブラリであり、AWS Neuron SDK を使用してトランスフォーマーのデコーダーによる推論ワークフローを実行するのを支援します。現在、サンプルとして、GPT2、GPT-J、OPT の各モデルタイプ、および異なるモデルサイズに対して、フォワード関数の広範なコード解析と最適化を行い、コンパイル言語で再実装したものを公開しています。お客様は、同じライブラリをベースにして、他のモデルアーキテクチャーを実装することもできます。AWS Neuron に最適化されたトランスフォーマーのデコーダークラスは、PyHLO と呼ばれる構文を使用して XLA HLO (High Level Operation) に再実装されています。また、このライブラリは、複数の Neuron コアにまたがってモデルの重みをシャードするためのテンソル並列化 (tensor parallelism) を実装しています。
なぜテンソル並列化が必要かというと、モデルが非常に大きく、ひとつのアクセラレータの HBM メモリに収まらないからです。transformers-neuronx の AWS Neuron ランタイムによるテンソル並列化のサポートは、AllReduce などの集合操作を多用します。AWS Neuron に最適化されたトランスフォーマーのデコーダーモデルのテンソル並列度 (シャード化された行列乗算演算に参加する Neuron コアの数) を設定する際の原則は次の通りです。
- アテンションヘッドの数は、テンソル並列度によって割り切れる必要がある。
- モデルの重みとキーバリューキャッシュの合計データサイズは、16 GB × [テンソル並列度] より小さくする必要がある。
- 現在、Neuron ランタイムは、Trn1 ではテンソル並列度1、2、8、32をサポートし、Inf2 ではテンソル並列度1、2、4、8、24をサポートしている。
DJLServing
DJLServing は、2023年3月に AWS Inferentia2 のサポートを追加した高性能なモデルサーバーです。AWS Model Server チームは、LLM/AIGC (訳注: AI Generated Content の略) のユースケースを支援するコンテナイメージを提供しています。DJL は Neuron に対応した大規模推論エンジンの一部でもあり、DJLServing と transformers-neuronx の間の統合を含みます。DJLServing モデルサーバーと transformers-neuronx ライブラリは、transformers ライブラリでサポートされる LLM をサービングするために構築されたコンテナのコアコンポーネントです。このコンテナと後続の DLC では、AWS Inferentia ドライバーとツールキットがインストールされた Amazon EC2 Inf2 ホスト上の AWS Inferentia チップにモデルをロードすることができます。本稿では、コンテナを実行するふたつの方法について説明します。
ひとつ目の方法では、追加のコードを書かずにコンテナを実行します。シームレスなユーザー体験のためにデフォルトのハンドラーを使用し、サポートされているモデル名のひとつと読み込み時に設定可能なパラメータを渡すことができます。これにより、Inf2 インスタンス上で LLM がコンパイルされ、サービングされます。以下のコードに一例を示します。
engine=Python
option.entryPoint=djl_python.transformers_neuronx
option.task=text-generation
option.model_id=facebook/opt-1.3b
option.tensor_parallel_degree=2また、独自の model.py ファイルを書くこともできますが、その場合、DJLServing API と、今回の例では transformers-neuronx API の間の橋渡しとなるモデル読み込みと推論のメソッドを実装する必要があります。また、serving.properties ファイルに設定可能なパラメータを記述して、モデル読み込み時にピックアップすることもできます。設定可能なパラメーターの全リストは「すべての DJL 設定オプション」のページを参照してください。
次のコードは、model.py ファイルのサンプルです。serving.properties ファイルは、先に示したものと同様です。
def load_model(properties):
"""
フレームワークが提供する API をベースにモデルを読み込む
:param: serving.properties で指定されたモデル読み込み用の設定可能なプロパティ
:return: モデル、および推論に必要なその他のアーティファクト
"""
batch_size = int(properties.get("batch_size", 2))
tp_degree = int(properties.get("tensor_parallel_degree", 2))
amp = properties.get("dtype", "f16")
model_id = "facebook/opt-13b"
model = OPTForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True)
...
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OPTForSampling.from_pretrained(load_path,
batch_size=batch_size,
amp=amp,
tp_degree=tp_degree)
model.to_neuron()
return model, tokenizer, batch_sizeそれでは、実際に Inf2 インスタンスを利用するとどうなるか見てみましょう。
Inferentia ハードウェアを起動
まず、OPT-13b モデルをホストするために inf2.48xlarge インスタンスを起動していきます。Amazon Machine Image (AMI) には「Deep Learning AMI Neuron PyTorch 1.13.0 (Ubuntu 20.04) 20230315」を使用します。これには、AWS Neuron ランタイム用の Docker イメージと必要なドライバーがすでに含まれています。

なお、大規模言語モデルに対応するため、インスタンスのストレージを512 GB に増設しています。

必要な依存関係のインストールとモデルの作成
次に、AMI 内で Jupyter ノートブックサーバーをセットアップし、ディレクトリやファイルを容易に表示したり管理できるようにします。作業用のディレクトリに入ったら、logs と models というサブディレクトリを作成し、serving.properties ファイルを作成します。

ここでは、DJL Serving コンテナが提供するスタンドアロンのモデルを使用することができます。つまり、モデルを定義する必要はありませんが、serving.properties ファイルは提供する必要があります。以下のコードを参照してください。
option.model_id=facebook/opt-1.3b
option.batch_size=2
option.tensor_parallel_degree=2
option.n_positions=256
option.dtype=fp16
option.model_loading_timeout=600
engine=Python
option.entryPoint=djl_python.transformers-neuronx
#option.s3url=s3://djl-llm/opt-1.3b/
#can also specify which device to load on.
#engine=Python ---because the handles are implement in python.こちらのファイルでは、DJL モデルサーバーに OPT-13B モデルを使用するよう指示しています。バッチサイズを2に設定し、モデルが Neuron デバイスに適合するように dtype=f16 としています。DJL は動的なバッチをサポートしており、tensor_parallel_degree を同様に設定することで、複数の Neuron コアに推論を分散させ、推論リクエストのスループットを向上することができます。また、n_positions=256 を設定したのは、モデルが持つべき最大トークン長を知らせるためです。
今回起動したインスタンスには12個の AWS Neuron デバイス、つまり24個の Neuron コアがあり、OPT-13B モデルには40個のアテンションヘッドがあります。例えば、tensor_parallel_degree=8 に設定すると、8個の Neuron コアごとにひとつのモデルインスタンスをホストすることになります。必要なアテンションヘッドの数 (40個) を Neuron コアの数 (8個) で割ると、各 Neuron コアに5個のアテンションヘッドが割り当てられます。言い換えると、それぞれの AWS Neuron デバイスに10個のアテンションヘッドが割り当てられます。
以下のサンプル model.py ファイルでは、モデルを定義し、ハンドラ関数を作成します。みなさまのニーズに合わせて書き換えて利用できますが、やりたいことが transformers-neuronx でサポートされているか気をつけてください。
cat serving.propertiesoption.tensor_parallel_degree=2
option.batch_size=2
option.dtype=f16
engine=Pythoncat model.pyimport torch
import tempfile
import os
from transformers.models.opt import OPTForCausalLM
from transformers import AutoTokenizer
from transformers_neuronx import dtypes
from transformers_neuronx.module import save_pretrained_split
from transformers_neuronx.opt.model import OPTForSampling
from djl_python import Input, Output
model = None
def load_model(properties):
batch_size = int(properties.get("batch_size", 2))
tp_degree = int(properties.get("tensor_parallel_degree", 2))
amp = properties.get("dtype", "f16")
model_id = "facebook/opt-13b"
load_path = os.path.join(tempfile.gettempdir(), model_id)
model = OPTForCausalLM.from_pretrained(model_id,
low_cpu_mem_usage=True)
dtype = dtypes.to_torch_dtype(amp)
for block in model.model.decoder.layers:
block.self_attn.to(dtype)
block.fc1.to(dtype)
block.fc2.to(dtype)
model.lm_head.to(dtype)
save_pretrained_split(model, load_path)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OPTForSampling.from_pretrained(load_path,
batch_size=batch_size,
amp=amp,
tp_degree=tp_degree)
model.to_neuron()
return model, tokenizer, batch_size
def infer(seq_length, prompt):
with torch.inference_mode():
input_ids = torch.as_tensor([tokenizer.encode(text) for text in prompt])
generated_sequence = model.sample(input_ids,
sequence_length=seq_length)
outputs = [tokenizer.decode(gen_seq) for gen_seq in generated_sequence]
return outputs
def handle(inputs: Input):
global model, tokenizer, batch_size
if not model:
model, tokenizer, batch_size = load_model(inputs.get_properties())
if inputs.is_empty():
# モデルサーバーは、起動時にモデルをウォームアップするための空の呼び出しを実行
return None
data = inputs.get_as_json()
seq_length = data["seq_length"]
prompt = data["text"]
outputs = infer(seq_length, prompt)
result = {"outputs": outputs}
return Output().add_as_json(result)mkdir -p models/opt13b logs
mv serving.properties model.py models/opt13bサービングコンテナを実行
推論前の最後のステップでは、DJL サービングコンテナの Docker イメージをプルし、起動したインスタンスで実行します。
docker pull deepjavalibrary/djl-serving:0.21.0-pytorch-inf2コンテナイメージをプルしたら、以下のコマンドを実行してモデルをデプロイします。ただし、logs と models サブディレクトリを含んでいるディレクトリにいることを確認してください。以下のコマンドでは、これらのサブディレクトリをコンテナ内の /opt/ ディレクトリにマッピングします。
docker run -it --rm --network=host \
-v `pwd`/models:/opt/ml/model \
-v `pwd`/logs:/opt/djl/logs \
-u djl --device /dev/neuron0 --device /dev/neuron10 --device /dev/neuron2 --device /dev/neuron4 --device /dev/neuron6 --device /dev/neuron8 --device /dev/neuron1 --device /dev/neuron11 \
-e MODEL_LOADING_TIMEOUT=7200 \
-e PREDICT_TIMEOUT=360 \
deepjavalibrary/djl-serving:0.21.0-pytorch-inf2 serve
推論の実行
これでモデルをデプロイできたので、簡単な CURL コマンドでエンドポイントに JSON データを渡してテストしてみましょう。先ほどバッチサイズを2に設定したので、それに対応する数の入力を渡します。
curl -X POST "http://127.0.0.1:8080/predictions/opt13b" \
-H 'Content-Type: application/json' \
-d '{"seq_length":2048,
"text":[
"Hello, I am a language model,",
"Welcome to Amazon Elastic Compute Cloud,"
]
}'
こちらのコマンドを実行すると、コマンドラインにレスポンスを生成します。このモデルはかなりおしゃべりですが、そのレスポンスはモデルが正常に動いていることを証明しています。Inferentia のおかげで、LLM による推論を実行することができました!
後片付け
無駄なコストを防ぐため、EC2 インスタンスを削除しておくことを忘れないようにしましょう。
まとめ
本稿では、LLM をホストするために Amazon EC2 Inf2 インスタンスをデプロイし、大規模モデル推論コンテナを使用して推論を実行しました。AWS Inferentia と AWS Neuron SDK がどのように相互作用して、最適なコストパフォーマンスで推論用の LLM を簡単にデプロイできるかを学びました。Inferentia のさらなる機能と新しいイノベーションに関するアップデートにご期待ください。Neuron のその他のサンプルについて知りたい場合は、aws-neuron-samples をご覧ください。
翻訳は機械学習パートナーソリューションアーキテクトの本橋が担当しました。
著者について
 Qingwei Li は、Amazon Web Services の機械学習スペシャリストです。オペレーションズ・リサーチの領域で博士号を取得しましたが、約束したノーベル賞の受賞を果たさないまま、指導教官の研究助成金を使い切ってしまいました。現在は、金融サービスや保険業界のお客様が AWS 上で機械学習ソリューションを構築するのを支援しています。読書と教えることが趣味。
Qingwei Li は、Amazon Web Services の機械学習スペシャリストです。オペレーションズ・リサーチの領域で博士号を取得しましたが、約束したノーベル賞の受賞を果たさないまま、指導教官の研究助成金を使い切ってしまいました。現在は、金融サービスや保険業界のお客様が AWS 上で機械学習ソリューションを構築するのを支援しています。読書と教えることが趣味。
 Peter Chung は AWS のソリューションアーキテクトであり、お客様がデータからインサイトを得るための支援に情熱を注いでいます。公共と民間の両方のセクターで、組織がデータ駆動型の意思決定を行うのを支援するソリューションを構築してきました。AWS の全認定資格とふたつの GCP 認定資格を保有しています。趣味はコーヒー、料理、アクティブに過ごすこと、家族と過ごすこと。
Peter Chung は AWS のソリューションアーキテクトであり、お客様がデータからインサイトを得るための支援に情熱を注いでいます。公共と民間の両方のセクターで、組織がデータ駆動型の意思決定を行うのを支援するソリューションを構築してきました。AWS の全認定資格とふたつの GCP 認定資格を保有しています。趣味はコーヒー、料理、アクティブに過ごすこと、家族と過ごすこと。
 Aaqib Ansari は、Amazon SageMaker Inference チームのソフトウェア開発エンジニアです。SageMaker のお客様がモデルの推論とデプロイを加速させるための支援に注力しています。余暇には、ハイキング、ランニング、写真撮影、スケッチを楽しんでいます。
Aaqib Ansari は、Amazon SageMaker Inference チームのソフトウェア開発エンジニアです。SageMaker のお客様がモデルの推論とデプロイを加速させるための支援に注力しています。余暇には、ハイキング、ランニング、写真撮影、スケッチを楽しんでいます。
 Qing Lan は、AWS のソフトウェア開発エンジニアです。高性能な ML 推論ソリューションや高性能なロギングシステムなど、Amazon におけるいくつかの挑戦的な製品に携わってきました。Qing のチームは、非常に低いレイテンシーを要求される Amazon Advertising において、数十億規模のパラメータを持つモデルの初めての立ち上げに成功しました。インフラストラクチャーの最適化と深層学習の高速化に関する深い知識を持っています。
Qing Lan は、AWS のソフトウェア開発エンジニアです。高性能な ML 推論ソリューションや高性能なロギングシステムなど、Amazon におけるいくつかの挑戦的な製品に携わってきました。Qing のチームは、非常に低いレイテンシーを要求される Amazon Advertising において、数十億規模のパラメータを持つモデルの初めての立ち上げに成功しました。インフラストラクチャーの最適化と深層学習の高速化に関する深い知識を持っています。
 Frank Liu は、AWS Deep Learning のソフトウェアエンジニアです。ソフトウェアエンジニアやサイエンティストのための革新的なディープラーニングツールを構築することに重点を置いています。余暇には、友人や家族とハイキングを楽しんでいます。
Frank Liu は、AWS Deep Learning のソフトウェアエンジニアです。ソフトウェアエンジニアやサイエンティストのための革新的なディープラーニングツールを構築することに重点を置いています。余暇には、友人や家族とハイキングを楽しんでいます。