Artificial Intelligence
Deploy large language models on AWS Inferentia2 using large model inference containers
You don’t have to be an expert in machine learning (ML) to appreciate the value of large language models (LLMs). Better search results, image recognition for the visually impaired, creating novel designs from text, and intelligent chatbots are just some examples of how these models are facilitating various applications and tasks.
ML practitioners keep improving the accuracy and capabilities of these models. As a result, these models grow in size and generalize better, such as in the evolution of transformer models. We explained in a previous post how you can use Amazon SageMaker deep learning containers (DLCs) to deploy these kinds of large models using a GPU-based instance.
In this post, we take the same approach but host the model on AWS Inferentia2. We use the AWS Neuron software development kit (SDK) to access the Inferentia device and benefit from its high performance. We then use a large model inference container powered by Deep Java Library (DJLServing) as our model serving solution. We demonstrate how these three layers work together by deploying an OPT-13B model on an Amazon Elastic Compute Cloud (Amazon EC2) inf2.48xlarge instance.
The three pillars
The following image represents the layers of hardware and software working to help you unlock the best price and performance of your large language models. AWS Neuron and tranformers-neuronx are the SDKs used to run deep learning workloads on AWS Inferentia. Lastly, DJLServing is the serving solution that is integrated in the container.
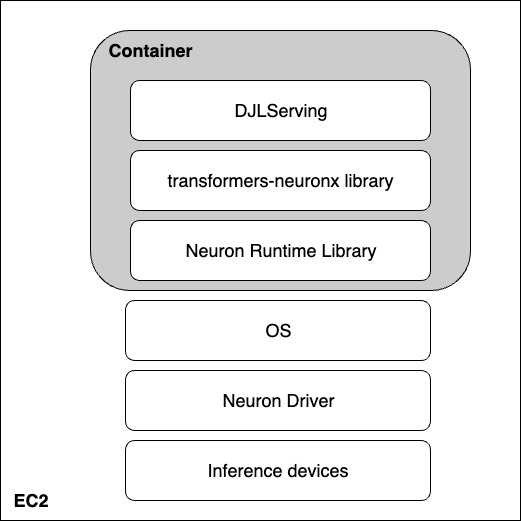
Hardware: Inferentia
AWS Inferentia, specifically designed for inference by AWS, is a high-performance and low-cost ML inference accelerator. In this post, we use AWS Inferentia2 (available via Inf2 instances), the second generation purpose-built ML inference accelerator.
Each EC2 Inf2 instance is powered by up to 12 Inferentia2 devices, and allows you to choose between four instance sizes.
Amazon EC2 Inf2 supports NeuronLink v2, a low-latency and high-bandwidth chip-to-chip interconnect, which enables high performance collective communication operations such as AllReduce and AllGather. This efficiently shards models across AWS Inferentia2 devices (such as via Tensor Parallelism), and therefore optimizes latency and throughput. This is particularly useful for large language models. For benchmark performance figures, refer to AWS Neuron Performance.

At the heart of the Amazon EC2 Inf2 instance are AWS Inferentia2 devices, each containing two NeuronCores-v2. Each NeuronCore-v2 is an independent, heterogenous compute-unit, with four main engines: Tensor, Vector, Scalar, and GPSIMD engines. It includes an on-chip software-managed SRAM memory for maximizing data locality. The following diagram shows the internal workings of the AWS Inferentia2 device architecture.

Neuron and transformers-neuronx
Above the hardware layer are the software layers used to interact with AWS Inferentia. AWS Neuron is the SDK used to run deep learning workloads on AWS Inferentia and AWS Trainium based instances. It enables end-to-end ML development lifecycle to build new models, train and optimize these models, and deploy them for production. AWS Neuron includes a deep learning compiler, runtime, and tools that are natively integrated with popular frameworks like TensorFlow and PyTorch.
transformers-neuronx is an open-source library built by the AWS Neuron team that helps run transformer decoder inference workflows using the AWS Neuron SDK. Currently, it has examples for the GPT2, GPT-J, and OPT model types, and different model sizes that have their forward functions re-implemented in a compiled language for extensive code analysis and optimizations. Customers can implement other model architecture based on the same library. AWS Neuron-optimized transformer decoder classes have been re-implemented in XLA HLO (High Level Operations) using a syntax called PyHLO. The library also implements tensor parallelism to shard the model weights across multiple NeuronCores.
Tensor parallelism is needed because the models are so large, they don’t fit into a single accelerator HBM memory. The support for tensor parallelism by the AWS Neuron runtime in transformers-neuronx makes heavy use of collective operations such as AllReduce. The following are some principles for setting the tensor parallelism degree (number of NeuronCores participating in sharded matrix multiply operations) for AWS Neuron-optimized transformer decoder models:
- The number of attention heads needs to be divisible by the tensor parallelism degree
- The total data size of model weights and key-value caches needs to be smaller than 16 GB times the tensor parallelism degree
- Currently, the Neuron runtime supports tensor parallelism degrees 1, 2, 8, and 32 on Trn1 and supports tensor parallelism degrees 1, 2, 4, 8, and 24 on Inf2
DJLServing
DJLServing is a high-performance model server that added support for AWS Inferentia2 in March 2023. The AWS Model Server team offers a container image that can help LLM/AIGC use cases. DJL is also part of Rubikon support for Neuron that includes the integration between DJLServing and transformers-neuronx. The DJLServing model server and transformers-neuronx library are the core components of the container built to serve the LLMs supported through the transformers library. This container and the subsequent DLCs will be able to load the models on the AWS Inferentia chips on an Amazon EC2 Inf2 host along with the installed AWSInferentia drivers and toolkit. In this post, we explain two ways of running the container.
The first way is to run the container without writing any additional code. You can use the default handler for a seamless user experience and pass in one of the supported model names and any load time configurable parameters. This will compile and serve an LLM on an Inf2 instance. The following code shows an example:
engine=Python
option.entryPoint=djl_python.transformers_neuronx
option.task=text-generation
option.model_id=facebook/opt-1.3b
option.tensor_parallel_degree=2
Alternatively, you can write your own model.py file, but that requires implementing the model loading and inference methods to serve as a bridge between the DJLServing APIs and, in this case, the transformers-neuronx APIs. You can also provide configurable parameters in a serving.properties file to be picked up during model loading. For the full list of configurable parameters, refer to All DJL configuration options.
The following code is a sample model.py file. The serving.properties file is similar to the one shown earlier.
def load_model(properties):
"""
Load a model based from the framework provided APIs
:param: properties configurable properties for model loading
specified in serving.properties
:return: model and other artifacts required for inference
"""
batch_size = int(properties.get("batch_size", 2))
tp_degree = int(properties.get("tensor_parallel_degree", 2))
amp = properties.get("dtype", "f16")
model_id = "facebook/opt-13b"
model = OPTForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True)
...
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OPTForSampling.from_pretrained(load_path,
batch_size=batch_size,
amp=amp,
tp_degree=tp_degree)
model.to_neuron()
return model, tokenizer, batch_size
Let’s see what this all looks like on an Inf2 instance.
Launch the Inferentia hardware
We first need to launch an inf.42xlarge instance to host our OPT-13b model. We use the Deep Learning AMI Neuron PyTorch 1.13.0 (Ubuntu 20.04) 20230226 Amazon Machine Image (AMI) because it already includes the Docker image and necessary drivers for the AWS Neuron runtime.

We increase the storage of the instance to 512 GB to accommodate for large language models.

Install necessary dependencies and create the model
We set up a Jupyter notebook server with our AMI to make it easier to view and manage our directories and files. When we’re in the desired directory, we set subdirectories for logs and models and create a serving.properties file.

We can use the standalone model provided by the DJL Serving container. This means we don’t have to define a model, but we do need to provide a serving.properties file. See the following code:
option.model_id=facebook/opt-1.3b
option.batch_size=2
option.tensor_parallel_degree=2
option.n_positions=256
option.dtype=fp16
option.model_loading_timeout=600
engine=Python
option.entryPoint=djl_python.transformers-neuronx
#option.s3url=s3://djl-llm/opt-1.3b/
#can also specify which device to load on.
#engine=Python ---because the handles are implement in python.This instructs the DJL model server to use the OPT-13B model. We set the batch size to 2 and dtype=f16 for the model to fit on the neuron device. DJL serving supports dynamic batching and by setting a similar tensor_parallel_degree value, we can increase throughput of inference requests because we distribute inference across multiple NeuronCores. We also set n_positions=256 because this informs the maximum length we expect the model to have.
Our instance has 12 AWS Neuron devices, or 24 NeuronCores, while our OPT-13B model requires 40 attention heads. For example, setting tensor_parallel_degree=8 means every 8 NeuronCores will host one model instance. If you divide the required attention heads (40) by the number of NeuronCores (8), then you get 5 attention heads allocated to each NeuronCore, or 10 on each AWS Neuron device.
You can use the following sample model.py file, which defines the model and creates the handler function. You can edit it to meet your needs, but be sure it can be supported on transformers-neuronx.
cat serving.propertiesoption.tensor_parallel_degree=2
option.batch_size=2
option.dtype=f16
engine=Pythoncat model.pyimport torch
import tempfile
import os
from transformers.models.opt import OPTForCausalLM
from transformers import AutoTokenizer
from transformers_neuronx import dtypes
from transformers_neuronx.module import save_pretrained_split
from transformers_neuronx.opt.model import OPTForSampling
from djl_python import Input, Output
model = None
def load_model(properties):
batch_size = int(properties.get("batch_size", 2))
tp_degree = int(properties.get("tensor_parallel_degree", 2))
amp = properties.get("dtype", "f16")
model_id = "facebook/opt-13b"
load_path = os.path.join(tempfile.gettempdir(), model_id)
model = OPTForCausalLM.from_pretrained(model_id,
low_cpu_mem_usage=True)
dtype = dtypes.to_torch_dtype(amp)
for block in model.model.decoder.layers:
block.self_attn.to(dtype)
block.fc1.to(dtype)
block.fc2.to(dtype)
model.lm_head.to(dtype)
save_pretrained_split(model, load_path)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OPTForSampling.from_pretrained(load_path,
batch_size=batch_size,
amp=amp,
tp_degree=tp_degree)
model.to_neuron()
return model, tokenizer, batch_size
def infer(seq_length, prompt):
with torch.inference_mode():
input_ids = torch.as_tensor([tokenizer.encode(text) for text in prompt])
generated_sequence = model.sample(input_ids,
sequence_length=seq_length)
outputs = [tokenizer.decode(gen_seq) for gen_seq in generated_sequence]
return outputs
def handle(inputs: Input):
global model, tokenizer, batch_size
if not model:
model, tokenizer, batch_size = load_model(inputs.get_properties())
if inputs.is_empty():
# Model server makes an empty call to warmup the model on startup
return None
data = inputs.get_as_json()
seq_length = data["seq_length"]
prompt = data["text"]
outputs = infer(seq_length, prompt)
result = {"outputs": outputs}
return Output().add_as_json(result)
mkdir -p models/opt13b logs
mv serving.properties model.py models/opt13b
Run the serving container
The last steps before inference are to pull the Docker image for the DJL serving container and run it on our instance:
docker pull deepjavalibrary/djl-serving:0.22.0-pytorch-inf2After you pull the container image, run the following command to deploy your model. Make sure you’re in the right directory that contains the logs and models subdirectory because the command will map these to the container’s /opt/directories.
docker run -it --rm --network=host \
-v `pwd`/models:/opt/ml/model \
-v `pwd`/logs:/opt/djl/logs \
-u djl --device /dev/neuron0 --device /dev/neuron10 --device /dev/neuron2 --device /dev/neuron4 --device /dev/neuron6 --device /dev/neuron8 --device /dev/neuron1 --device /dev/neuron11 \
-e MODEL_LOADING_TIMEOUT=7200 \
-e PREDICT_TIMEOUT=360 \
deepjavalibrary/djl-serving:0.21.0-pytorch-inf2 serve
Run inference
Now that we’ve deployed the model, let’s test it out with a simple CURL command to pass some JSON data to our endpoint. Because we set a batch size of 2, we pass along the corresponding number of inputs:
curl -X POST "http://127.0.0.1:8080/predictions/opt13b" \
-H 'Content-Type: application/json' \
-d '{"seq_length":2048,
"text":[
"Hello, I am a language model,",
"Welcome to Amazon Elastic Compute Cloud,"
]
}'
The preceding command generates a response in the command line. The model is quite chatty but its response validates our model. We were able to run inference on our LLM thanks to Inferentia!
Clean up
Don’t forget to delete your EC2 instance once you are done to save cost.
Conclusion
In this post, we deployed an Amazon EC2 Inf2 instance to host an LLM and ran inference using a large model inference container. You learned how AWS Inferentia and the AWS Neuron SDK interact to allow you to easily deploy LLMs for inference at an optimal price-to-performance ratio. Stay tuned for updates on more capabilities and new innovations with Inferentia. For more examples about Neuron, see aws-neuron-samples.
About the Authors
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
 Aaqib Ansari is a Software Development Engineer with the Amazon SageMaker Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys hiking, running, photography and sketching.
Aaqib Ansari is a Software Development Engineer with the Amazon SageMaker Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys hiking, running, photography and sketching.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
 Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.
Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.