Amazon Web Services ブログ
FMOps/LLMOps:生成系 AI の運用と MLOps との違い
最近、多くのお客様は大規模言語モデル (Large Language Model: LLM) に高い期待を示しており、生成系 AI がビジネスをどのように変革できるか考えています。しかし、そのようなソリューションやモデルをビジネスの日常業務に持ち込むことは簡単な作業ではありません。この投稿では、MLOps の原則を利用して生成系 AI アプリケーションを運用化する方法について説明します。これにより、基盤モデル運用 (FMOps) の基盤が築かれます。さらに、Text to Text のアプリケーションや LLM 運用 (LLMOps) について深掘りします。LLMOps は FMOps のサブセットです。以下の図は、議論するトピックを示しています。
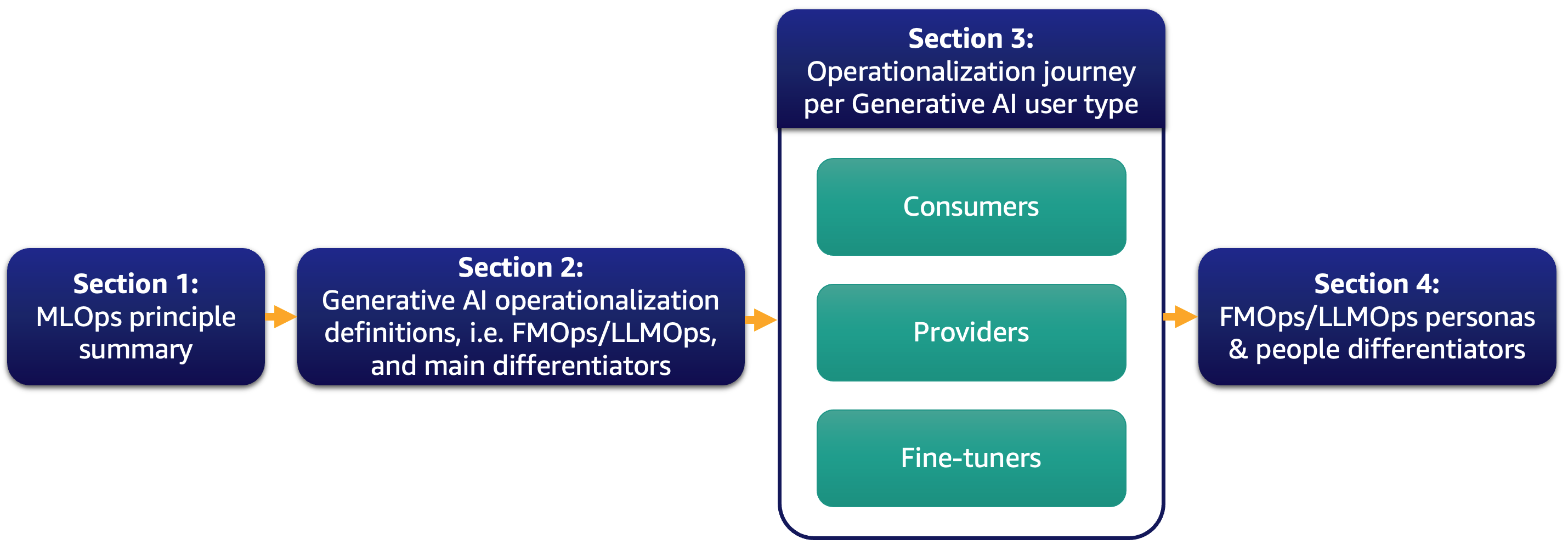 具体的には、MLOps の原則を簡単に紹介し、FMOps および LLMOps との主な違いに焦点を当てます。これは、プロセス、人材、モデル選択と評価、データプライバシー、モデルのデプロイメントなどに関連します。そのまま利用する場合、スクラッチから基盤モデルを作成する場合、ファインチューニングする場合の全てに当てはまります。本アプローチは、オープンソースとプロプライエタリモデルの両方に同様に適用できます。
具体的には、MLOps の原則を簡単に紹介し、FMOps および LLMOps との主な違いに焦点を当てます。これは、プロセス、人材、モデル選択と評価、データプライバシー、モデルのデプロイメントなどに関連します。そのまま利用する場合、スクラッチから基盤モデルを作成する場合、ファインチューニングする場合の全てに当てはまります。本アプローチは、オープンソースとプロプライエタリモデルの両方に同様に適用できます。
機械学習の運用サマリー
Amazon SageMaker を利用したエンタープライズのための MLOps 基盤ロードマップで定義されているように、機械学習と運用 (MLOps) は、機械学習 (ML) ソリューションを効率的に実運用するために、人材、プロセス、テクノロジーを組み合わせたものです。これを達成するには、以下に示すチームとペルソナが協力する必要があります。
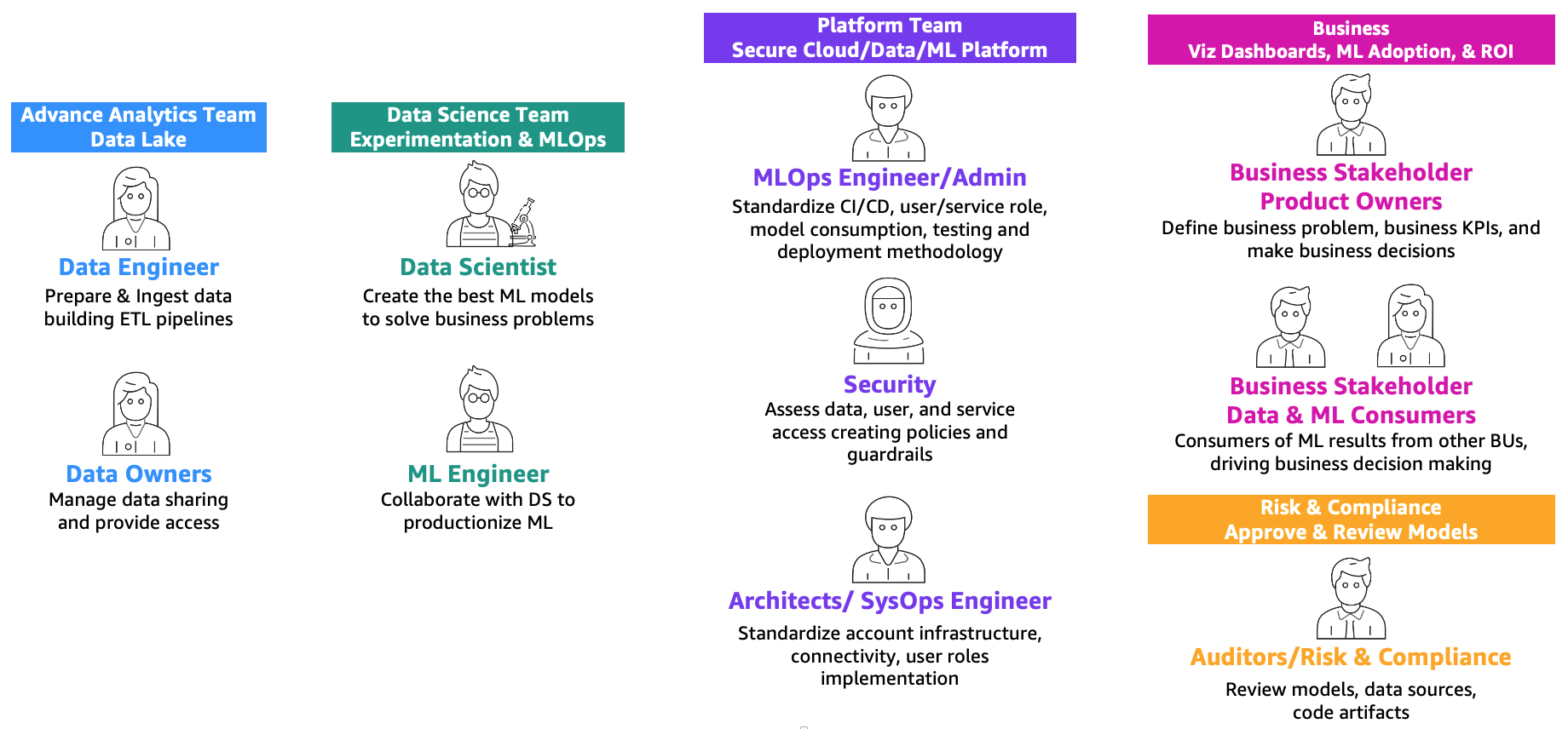
これらのチームは以下の通りです。
- アドバンスド・アナリティクス・チーム(データレイクとデータメッシュ) – データエンジニアは、複数のソースからデータを準備および取り込み、ETL (抽出、変換、ロード) パイプラインを構築してデータを策定およびカタログ化し、ML ユースケースに必要な履歴データを準備する責任があります。これらのデータ所有者は、複数のビジネスユニットまたはチームへのデータアクセスの提供に焦点を当てています。
- データサイエンティスト・チーム – データサイエンティストは、予め定義された主要業績評価指標 (KPI) に基づいて、ノートブックでベストモデルを作成することに集中する必要があります。研究フェーズの完了後、データサイエンティストは ML エンジニアと協力して、CI/CD パイプラインを使用してモデルのビルド (ML パイプライン) と実稼働環境へのモデルのデプロイメントの自動化を作成する必要があります。
- ビジネスチーム – プロダクトオーナーは、ビジネスケース、要件、およびモデルパフォーマンスを評価するために使用される KPI を定義する責任があります。ML コンシューマーは、意思決定を左右するために推論結果 (予測) を利用するその他のビジネスステークホルダーです。
- プラットフォームチーム – アーキテクトは、ビジネスの全体的なクラウドアーキテクチャと、異なるサービスがどのように接続されているかの責任があります。セキュリティ SME は、ビジネスのセキュリティポリシーとニーズに基づいてアーキテクチャをレビューします。MLOps エンジニアは、データサイエンティストと ML エンジニアが ML ユースケースを実運用化できるように、安全な環境を提供する責任があります。具体的には、ビジネスとセキュリティの要件に基づいて、CI/CD パイプライン、ユーザーとサービスの役割とコンテナの作成、モデル利用、テスト、およびデプロイメントの方法論を標準化する責任があります。
- リスクとコンプライアンス・チーム – より制限的な環境の場合、監査人はデータ、コード、モデルアーティファクトを評価し、ビジネスが規制 (データプライバシーなど) に準拠していることを確認する責任があります。
ビジネスのスケーリングと MLOps の成熟度に応じて複数のペルソナを同一人物が担当する場合があることに注意してください。
これらのペルソナは、以下の図に示すように、さまざまなプロセスを実行するための専用の環境を必要とします。
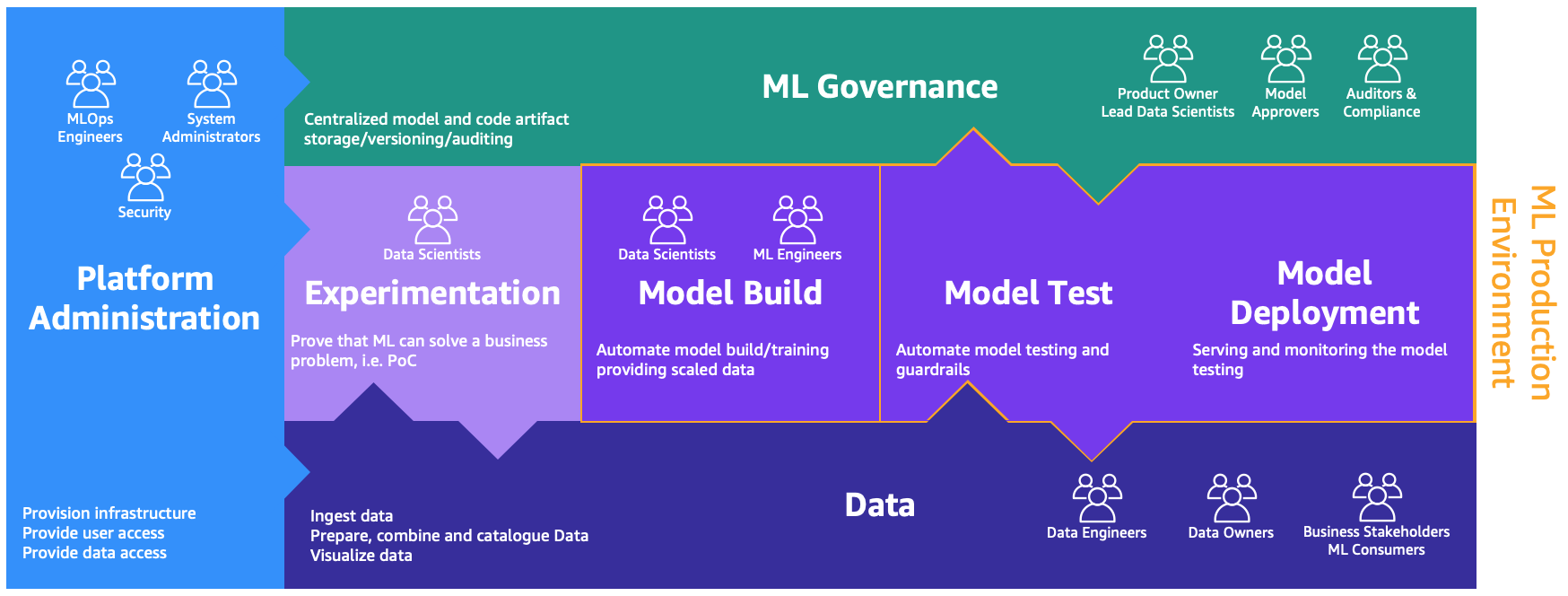
環境は以下の通りです。
- プラットフォーム管理 – プラットフォームチームが AWS アカウントを作成し、適切なユーザーとデータをリンクできるプラットフォーム管理環境です。
- データ – データレイヤーは、データエンジニアまたは所有者とビジネスステークホルダーがデータを準備、操作、および可視化するために使用するデータレイクまたはデータメッシュと呼ばれる環境です。
- 実験 – データサイエンティストは、概念実証 (Proof of Concept: PoC) がビジネスの問題を解決できることを証明するために、新しいライブラリと機械学習技術をテストするためのサンドボックスまたは実験環境を使用します。
- モデル構築、モデルテスト、モデルデプロイメント – モデルの構築、テスト、およびデプロイメント環境は、研究を実運用に移行するためにデータサイエンティストと ML エンジニアが協力して研究を自動化する MLOps のレイヤーです。
- ML ガバナンス – パズルの最後のピースは、モデルとコードの成果物が保存、レビュー、および対応するペルソナによる監査対象となる ML ガバナンス環境です。
以下の図は、Amazon SageMaker を利用したエンタープライズのための MLOps 基盤ロードマップで既に説明されているリファレンスアーキテクチャを示しています。
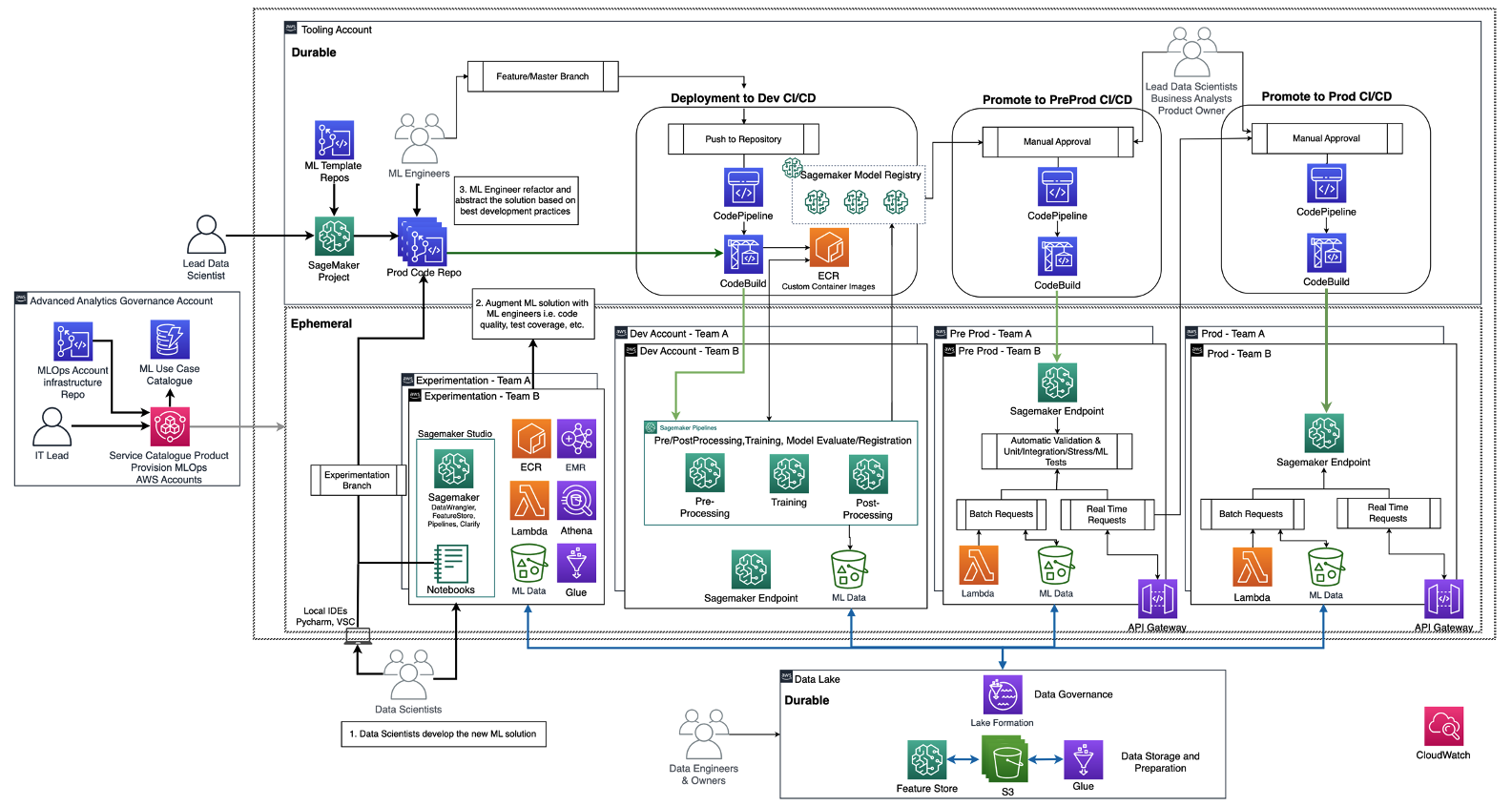
各ビジネスユニットには、ML ユースケースを実運用化するための独自セットの Dev (自動化されたモデルトレーニングとビルド)、Pre Prod (自動テスト)、Prod (モデルのデプロイとサービング) アカウントがあります。これらは、中心化されたデータレイクまたは分散データメッシュからデータを取得します。生成されたすべてのモデルとコードの自動化は、モデルレジストリの機能を使用して Tooling アカウントに集約されます。これらすべてのアカウントのインフラストラクチャコードは、プラットフォームチームが抽象化、テンプレート化、保守、および各新規チームの MLOps プラットフォームへのオンボーディングで再利用できる共有サービスアカウント (advanced analytics governance account) でバージョン管理されます。
生成系 AI の定義と MLOps との違い
クラシックな機械学習では、人材、プロセス、テクノロジーの前述の組み合わせにより、ML ユースケースを製品化できます。ただし、生成系 AI では、ユースケースの性質により、これらの機能の拡張または新機能が必要になります。これらの新しい概念の 1 つは、基盤モデル (Foundation Model: FM) です。これらは以下の図に示すように、広範囲の他の AI モデルを作成するために使用できるため、そのように呼ばれています。
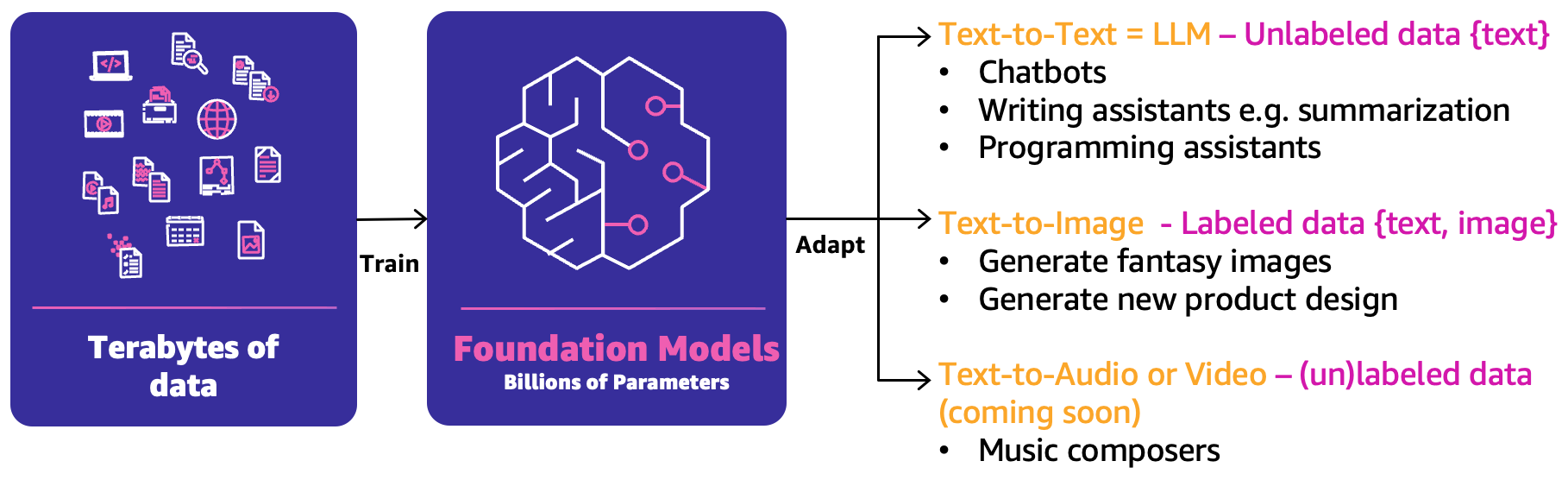
FM はテラバイト単位のデータでトレーニングされており、3 つの主なカテゴリの生成系 AI ユースケースにおいて、最良の回答を予測するための数百億のパラメータを持っています。
- Text to Text – FM (LLM) は、ラベルなしデータ(フリーテキストなど)でトレーニングされており、次の最適な単語または一連の単語 (段落または長文) を予測できます。主なユースケースは、人間らしいチャットボット、要約、プログラミングコードなど、その他のコンテンツ作成などです。
- Text to Image – <テキスト、画像> のペアなどのラベル付きデータを使用して、最適なピクセルの組み合わせを予測できる FM をトレーニングすることができます。使用例としては、服のデザイン生成や想像上のパーソナライズされた画像があります。
- Text-to-Audio or Video – トレーニングされた FM のために、ラベル付きデータとラベルなしデータの両方を使用できます。主な生成系 AI のユースケースの例は音楽の作曲です。
これらの生成系AIユースケースを実運用化するには、MLOps ドメインを借用および拡張して、以下を含める必要があります。
- FM 運用 (FMOps) – これにより、使用例のタイプを問わず、生成系 AI ソリューションを実運用化できます。
- LLM 運用 (LLMOps) – これは FMOps のサブセットであり、LLM ベースのソリューション (Text to Text など)の実運用化に焦点を当てています。
以下の図は、これらのユースケースの重複を示しています。
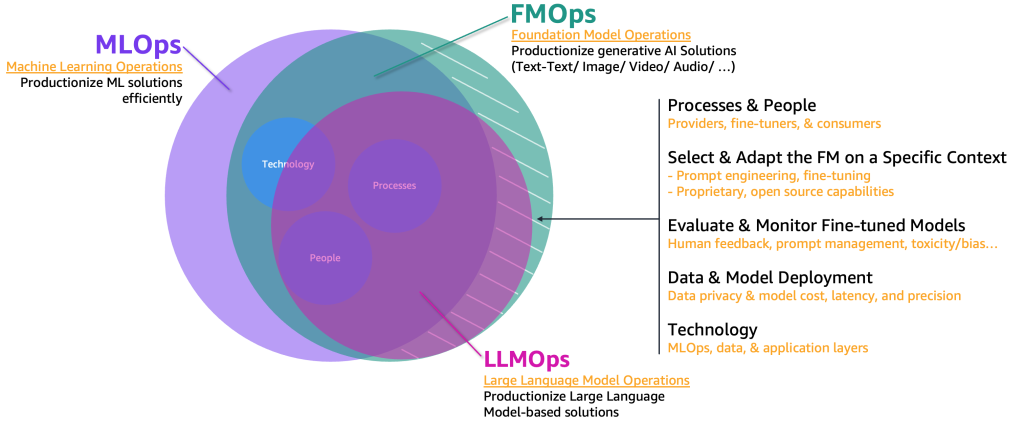
従来の機械学習や MLOps と比較すると、FMOps と LLMOps は、以下の 4 つの主なカテゴリーに基づいて異なります。これらは、以下のセクションで取り上げます: プロセス、人材、FM の選択と適応、FM の評価と監視、データプライバシーとモデルのデプロイメント、技術ニーズ。監視については、別の投稿で取り上げます。
生成系 AI ユーザータイプごとの運用化の旅
プロセスの説明を簡単にするために、以下の図に示すように主な生成系 AI ユーザータイプを分類する必要があります。
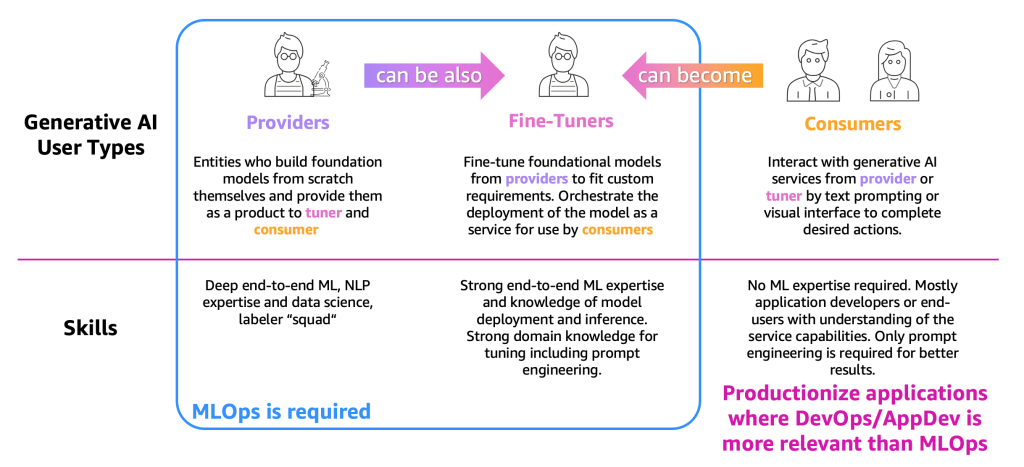
ユーザータイプは以下の通りです。
- プロバイダー – スクラッチから FM を構築し、製品として他のユーザー (ファインチューナーとコンシューマー) に提供するユーザー。彼らはエンドツーエンドの ML と自然言語処理 (NLP) の専門知識、および膨大なデータラベラーとエディタのチームを持っています。
- ファインチューナー – プロバイダーから FM を再トレーニング (ファインチューニング) して、カスタム要件に合わせるユーザー。彼らはモデルのサービスとしてのデプロイをオーケストレーションします。これは、コンシューマーが使用するためのものです。これらのユーザーは、エンドツーエンドの ML とデータサイエンスの専門知識、モデルのデプロイと推論の知識が必要です。チューニングのためのプロンプトエンジニアリングを含むドメイン知識も必要です。
- コンシューマー – テキストのプロンプトまたはビジュアルインターフェースによって、プロバイダーまたはファインチューナーの生成系 AI サービスと対話し、所望のアクションを完了するユーザー。ML の専門知識は必要ありませんが、主にアプリケーション開発者またはエンドユーザーで、サービスの機能についての理解が必要です。良い結果のために必要なのはプロンプトエンジニアリングのみです。
定義と必要な ML の専門知識に従って、MLOps は主にプロバイダーとファインチューナーに必要です。一方、コンシューマーは DevOps や AppDev の原則を使用して、生成系 AI アプリケーションを作成できます。さらに、次のようなユーザータイプの変遷が観察されています。プロバイダーは、垂直セクター (金融セクターなど) に基づくユースケースをサポートするためにファインチューナーになる可能性があります。または、コンシューマーは、より正確な結果を得るためにファインチューナーになる可能性があります。しかしながら、以降ではユーザータイプごとの主要なプロセスを観察しましょう。
コンシューマーの旅
以下の図は、コンシューマーの旅を示しています。
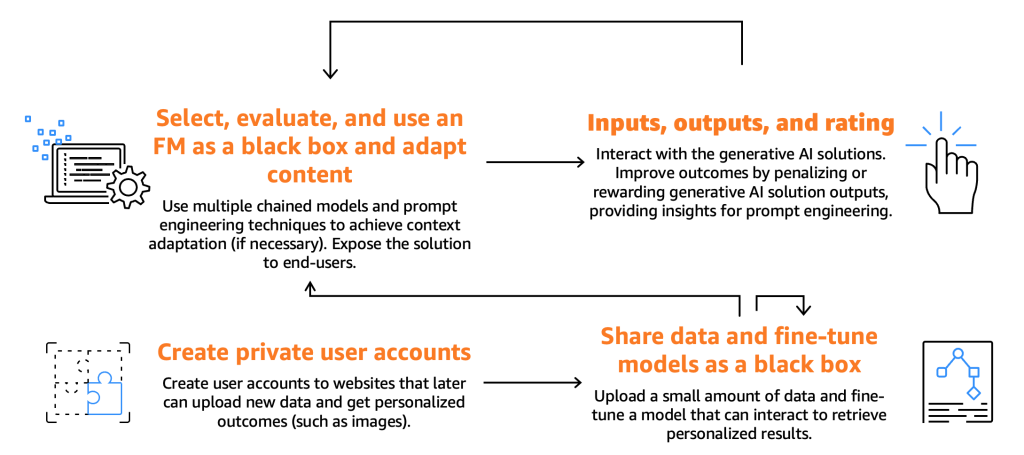
前述のとおり、コンシューマーは、特定の入力、つまりプロンプトを提供することによって、FM を選択、テスト、使用する必要があります。プロンプトとは、コンピュータプログラミングや AI のコンテキストで、モデルまたはシステムに対して与えられる入力を指します。これは、テキスト、コマンド、質問の形式をとることができ、システムはこれを使用して出力を処理および生成します。FM によって生成された出力は、エンドユーザーが使用できます。エンドユーザーは、これらの出力を評価して、モデルの将来の応答を強化する必要があります。
これらの基本プロセスに加えて、ファインチューナーが提供する機能を活用してモデルをファインチューニングすることをコンシューマーが望んでいることに私たちは気づきました。たとえば、画像を生成する Web サイトを考えてみましょう。ここでは、エンドユーザーはプライベートアカウントを設定し、個人写真をアップロードし、その後、それらの画像に関連するコンテンツを生成できます (たとえば、バイクに乗って剣を振り回しているエンドユーザー、またはエキゾチックな場所にいるエンドユーザーを描いた画像)。このシナリオでは、コンシューマーが設計した生成系 AI アプリケーションは、API を介してファインチューナーのバックエンドと対話して、この機能をエンドユーザーに提供する必要があります。
しかし、その前に以下の図に示すような、モデルの選択、テスト、使用、入力と出力の対話、および評価のプロセスに注力しましょう。
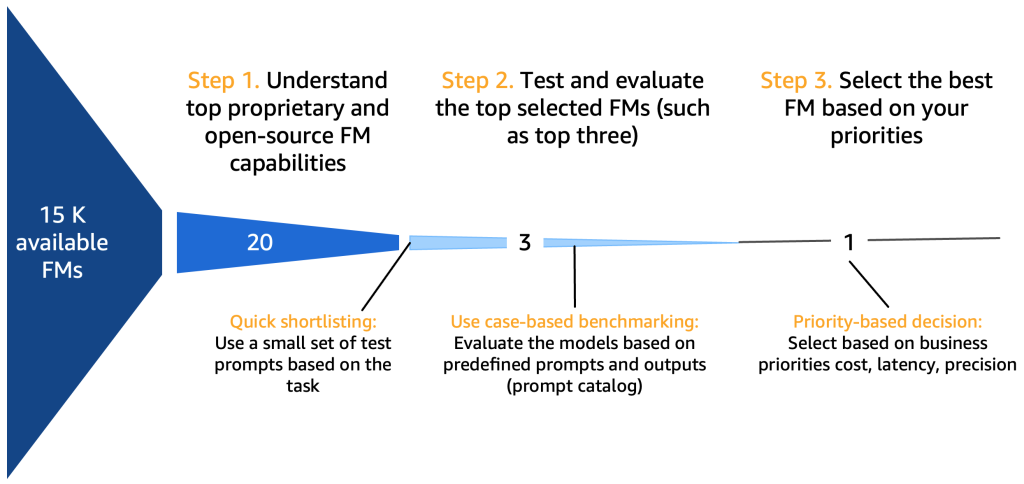
ステップ1. トップ FM 機能を理解する
基盤モデルを選択する際には、ユースケース、利用可能なデータ、規制などに応じて、考慮すべき多くの観点があります。包括的ではないが、次のような優良チェックリストが考えられます。
- プロプライエタリまたはオープンソースの FM – プロプライエタリモデルは金銭的コストがかかりますが、通常、生成されたテキストまたは画像の品質の点で優れたパフォーマンスを発揮します。これは、最適なパフォーマンスと信頼性を確保する専任のモデルプロバイダーチームによって開発・維持管理されることが多いためです。一方、オープンソースモデルの採用も増加しており、無料である以外に、アクセスしやすく柔軟性があるという追加のメリットがあります (例えば、すべてのオープンソースモデルはファインチューニング可能です)。プロプライエタリモデルの例として Anthropic の Claude モデルが、高性能なオープンソースモデルの例として 2023 年 7 月時点の Falcon-40B があります。
- 商用ライセンス – FM を決定する際、ライセンスの考慮事項が重要です。一部のモデルはオープンソースですが、ライセンスの制限または条件により、商業目的で使用できないことに注意することが重要です。違いは微妙な場合があります。たとえば、新しくリリースされた xgen-7b-8k-base モデルはオープンソースで商用可能 (Apache-2.0ライセンス) ですが、Instruction Fine-Tuning バージョンのモデル xgen-7b-8k-inst は研究目的でのみリリースされています。商用アプリケーションの FM を選択する場合、ライセンス契約を確認し、その制限を理解し、プロジェクトの意図された使用目的と整合していることを確認することが重要です。
- パラメータ – パラメータの数は、ニューラルネットワークの重みとバイアスで構成されます。これはもう 1 つの重要な要因です。パラメータが多いほど、モデルはより複雑で可能性のある強力なモデルになります。これは、データ内のより精妙なパターンと相関関係を捉えることができるためです。ただし、トレードオフはより多くのコンピューティングリソースが必要になり、実行コストが高くなることです。また、オープンソースでは小規模モデル (70 億 ~ 400 億のパラメータ)のファインチューニング時に良好なパフォーマンスを発揮する傾向が特に見られます。
- 速度 – モデルの速度は、そのサイズの影響を受けます。大規模モデルは、計算の複雑さが増すため、データ処理が遅くなりがちです (レイテンシが高くなる)。したがって、高い予測力を持つモデル (多くの場合、大規模モデル) の必要性と、特にチャットボットなどのリアルタイムまたはニアリアルタイム応答を必要とするアプリケーションの速度に関する実際の要件のバランスを取ることが重要です。
- コンテキストウィンドウサイズ (トークン数) – プロンプトごとに入力または出力できる最大トークン数によって定義されるコンテキストウィンドウは、モデルが一度に考慮できるコンテキスト量を決定するのに重要です (トークンは英語では約 0.75 語に相当します)。コンテキストウィンドウが大きいモデルは、長い会話やドキュメントに関わるタスクに役立つ、より長いテキストシーケンスを理解および生成できます。
- トレーニングデータセット – FM がどのような種類のデータでトレーニングされたかを理解することも重要です。一部のモデルは、インターネットデータ、コーディングスクリプト、インストラクション、人間のフィードバックなど、さまざまなテキストデータセットでトレーニングされている場合があります。テキストと画像データの組み合わせなど、マルチモーダルデータセットでトレーニングされている場合もあります。これは、異なるタスクに対するモデルの適合性に影響を与える可能性があります。また、組織にはモデルが正確にどのソースでトレーニングされたかに応じて、著作権の問題が発生する可能性があるため、トレーニングデータセットを注意深く検証することが必須です。
- 品質 – FM の品質は、そのタイプ (プロプライエタリかオープンソース)、サイズ、トレーニング内容に基づいて異なる場合があります。品質はコンテキスト依存であり、あるアプリケーションで高品質と見なされるものが、別のアプリケーションではそうでない可能性があります。たとえば、インターネットデータでトレーニングされたモデルは、会話型テキストの生成には高品質だと考えられる可能性がありますが、技術的または専門的なタスクにはそうでない可能性があります。
- ファインチューニング可能 – モデルの重みやレイヤーを調整することによって FM をファインチューニングできる機能は、重要な要因となり得ます。ファインチューニングにより、モデルをアプリケーションの具体的なコンテキストにより適合させ、特定のタスクでのパフォーマンスを向上させることができます。ただし、ファインチューニングには追加のコンピューティングリソースと技術専門知識が必要であり、すべてのモデルがこの機能をサポートしているわけではありません。オープンソースモデルは、モデルアーティファクトをダウンロードでき、ユーザーはそれらを自由に拡張および使用できるため、(一般に) 常にファインチューニングが可能です。プロプライエタリモデルの場合、ファインチューニングのオプションを提供していることがあります。
- 顧客または開発チームの既存スキル – FM の選択は、顧客または開発チームのスキルと習熟度の影響も受けます。組織のチームに AI/ML の専門家がいない場合、API サービスの方が適している可能性があります。また、チームが特定の FM に広範な経験を持っている場合、新しいものを学習および適応するために時間とリソースを投資するよりも、それを使用し続ける方が効率的な場合があります。
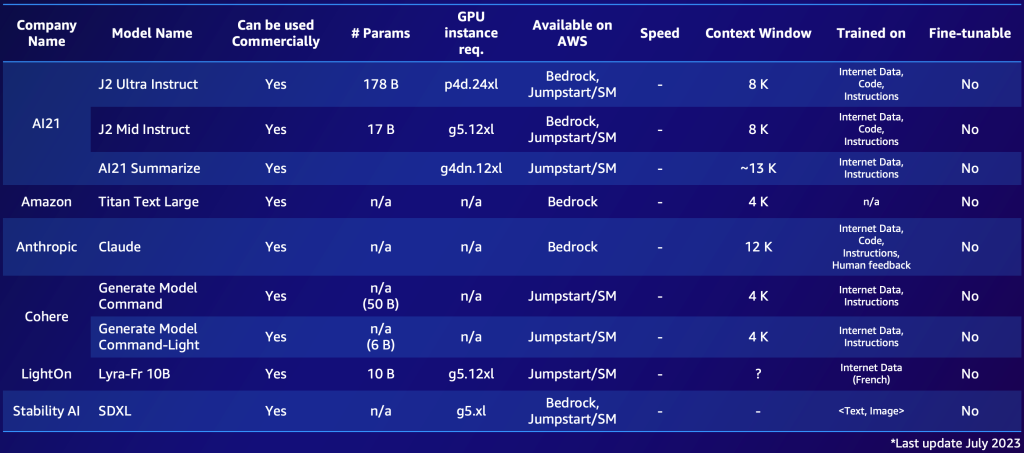
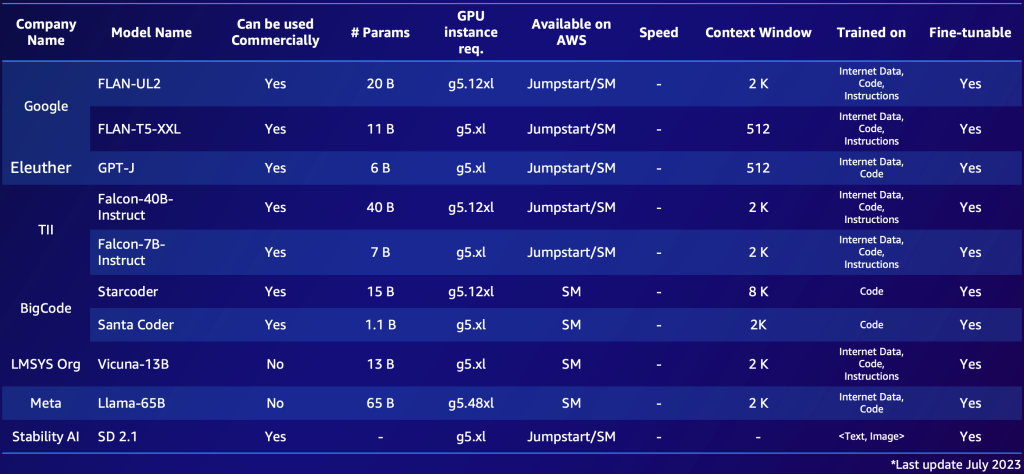
プロプライエタリモデルとオープンソースモデルの 2 つの短いリストの例を以下に示します。ニーズに基づいて同様の表を作成し、利用可能なオプションの概要を迅速に把握できます。これらのモデルのパフォーマンスとパラメータは急速に変化し、本ブログを読まれているタイミングでは古い情報になっている可能性がある一方で、サポート言語など、特定の顧客にとって重要な他の機能があることに注意してください。
以下は、AWS で利用可能な注目すべきプロプライエタリ FM の例です (2023 年 7 月時点)。
以下は、AWS で利用可能な注目すべきオープンソース FM の例です (2023 年 7 月時点)。
10 – 20 の潜在的な候補モデルの概要を作成した後、この短いリストをさらに絞り込む必要があります。このセクションでは、次のラウンドの候補として実行可能な 2、3 の最終モデルを迅速に生成するメカニズムを提案します。
次の図は、初期の短いリスト作成プロセスを示しています。
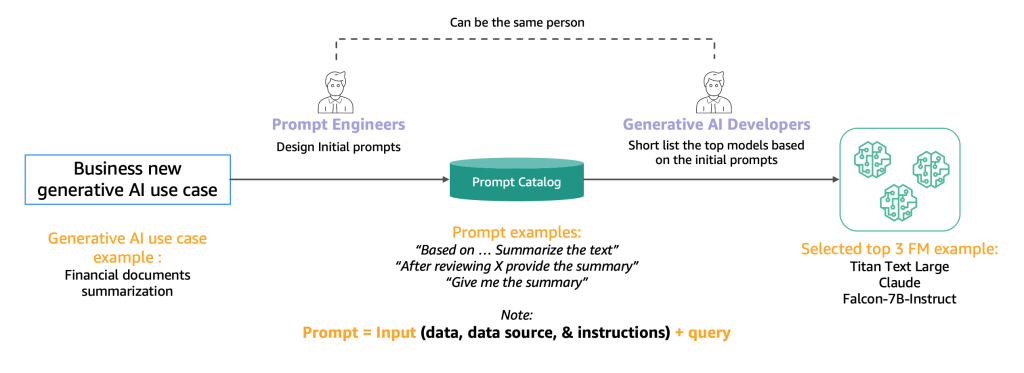
通常、高品質なプロンプトを作成して AI モデルがユーザー入力を理解および処理できるようにする専門家であるプロンプトエンジニアは、要約など同じタスクをモデルで実行するさまざまな方法を試します。これらのプロンプトはその場で作成されるのではなく、プロンプトカタログから体系的に抽出されることをお勧めします。プロンプトカタログは、プロンプトの複製を避け、バージョン管理を可能にし、次のセクションで紹介するさまざまな開発段階の異なるプロンプトテスター間の一貫性を確保するためにプロンプトをチーム内で共有するための中心的な場所です。このプロンプトカタログは、特徴量ストアの Git リポジトリに似ています。潜在的にはプロンプトエンジニアと同じ人物である可能性のある生成系 AI 開発者は、開発を目指している生成系 AI アプリケーションに適しているかどうかを判断するために、出力を評価する必要があります。
ステップ2. トップ FM をテストおよび評価する
短いリストが約 3 つの FM に絞り込まれた後、ユースケースに対する FM の機能と適合性をさらにテストするための評価ステップを推奨します。評価データの可用性と性質に応じて、以下の図に示すように、異なる方法を提案します。
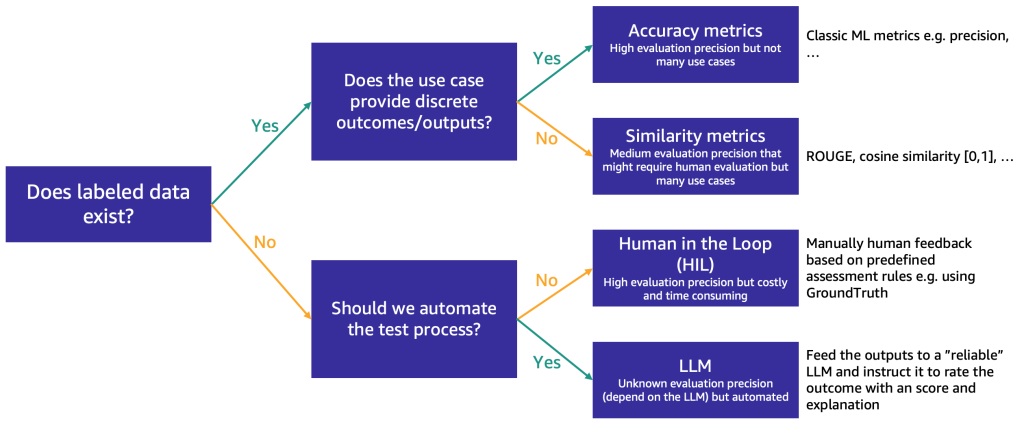
最初に使用する方法は、ラベル付きのテストデータがあるかどうかによって異なります。
ラベル付きデータがある場合は、従来の ML モデルと同様に、モデル評価を実行できます (一部のサンプルを入力し、出力をラベルと比較します)。テストデータに離散ラベル (肯定的、否定的、中立的な感情分析など) があるか、非構造化テキスト (要約など) であるかによって、評価のための異なる方法を提案します。
- 精度指標 – 離散出力 (感情分析など) の場合は、精度、再現率、F1 スコアなどの標準的な精度指標を使用できます。
- 類似性指標 – 出力が非構造化(要約など)の場合は、ROUGE やコサイン類似度などの類似性指標を提案します。
一部のユースケースは、唯一の正解を持たない場合があります (例:「5 歳の娘のための短い子供向けの物語を作成する」)。このような場合、ラベル付きのテストデータがないため、モデルを評価することがより困難になります。モデルの自動評価と人のレビューの重要性に応じて、次の 2 つのアプローチを提案します。
- Human-in-the-Loop (HIL) – この場合、プロンプトテスターのチームがモデルからの応答をレビューします。アプリケーションの重要性に応じて、プロンプトテスターはモデル出力の 100 % をレビューするか、サンプルのみをレビューする可能性があります。
- LLM 駆動型評価 – このシナリオでは、プロンプトテスターは、テスト対象のものよりも強力な (おそらく遅く、コストもかかる) LLM に置き換えられます。LLM は、モデルが生成する全ての応答をレビューしてスコア付けします。この方法では品質が低下する可能性がありますが、モデルパフォーマンスの初期の目安を提供できる、より安価で高速な評価オプションです。
たとえば、入力クエリ、LLM 応答、インストラクションが含まれる次のサンプルプロンプトを LLM に使用できます: 「上記に表示されているユーザーの質問に対する AI アシスタントのパフォーマンスについてフィードバックをお願いします。助手の応答の有用性、関連性、正確性、詳細のレベルを評価してください。アシスタントは、高いスコアほど全体的なパフォーマンスが向上する 1-10 の尺度で全体的なスコアを受け取る必要があります。」
このプロンプトは、別の LLM (EvalLLM) に送信されて評価されます。次は、Falcon-40B モデルの応答が EvalLLM (このケースでは Claude) によって評価された例です。「スエズ運河が建設されなければどうなっていたか」という質問を使用します。応答は次のとおりです。
質問: スエズ運河が建設されなければどうなっていたか?
falcon-40b-instruct
スエズ運河が建設されなければ、船は地中海と紅海の間を航行するためにアフリカを迂回しなければなりませんでした。 これにより、航海時間と距離が大幅に増加し、効率性が低下し、コストがかかるようになります。 また、スエズ運河がなければ、中東と北アフリカの多くの国々は世界の他の地域との接続が非常に薄れ、経済発展と文化発展が阻害されていたでしょう。
レビュー(スコア: 9/10)
アシスタントの応答は非常に適切で、正確で、詳細です。 これは、スエズ運河の非存在に関するユーザーの仮想の質問に対して優れた回答を提供しています。 アシスタントは、海上交通と中東・北アフリカの経済的・文化的影響について的確に指摘しています。 ただし、地政学的含意や世界的な貿易パターンへの影響についてさらに詳述すれば、より包括的な回答になったでしょう。
次の図は、エンドツーエンドの評価プロセスの例を示しています。
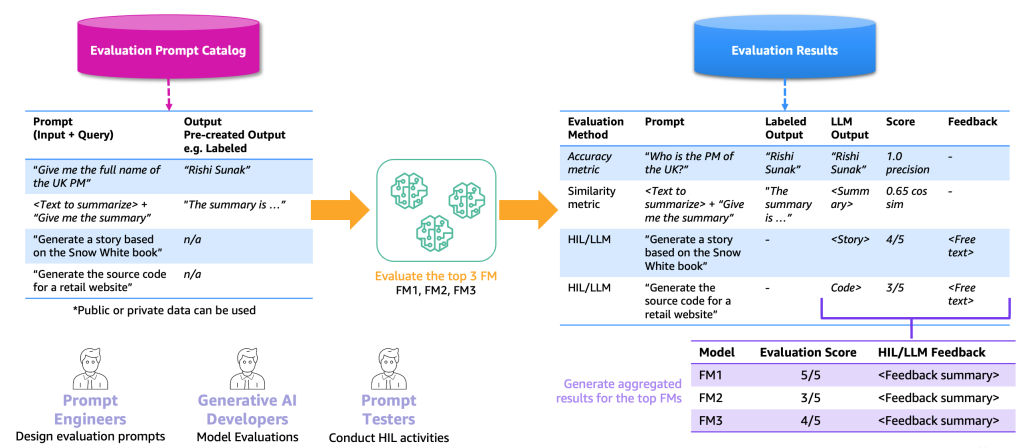
この例に基づき、評価を実行するには、プロンプトカタログに格納されているサンプルプロンプトと、特定のアプリケーションに基づくラベル付けされたまたはラベルなしの評価データセットを提供する必要があります。 たとえば、ラベル付きの評価データセットであれば、「2023年の英国首相の氏名を教えてください」というプロンプト(入力とクエリ)や「Rishi Sunak」といった出力と回答を提供できます。 ラベルなしのデータセットの場合は、「小売りウェブサイトのソースコードを生成する」などの質問や指示のみを提供します。 プロンプトカタログと評価データセットの組み合わせを、評価プロンプトカタログと呼びます。 プロンプトカタログと評価プロンプトカタログを区別する理由は、後者は特定のユースケースを対象としているのに対し、プロンプトカタログには質問応答などの汎用のプロンプトとインストラクションが含まれるためです。
この評価プロンプトカタログを使用すると、次のステップは、トップ FM に評価プロンプトを入力することです。 結果は、プロンプト、各 FM の出力、スコアとともにラベル付き出力が含まれる評価結果データセットになります(存在する場合)。 ラベルなしの評価プロンプトカタログの場合、結果をレビューしてスコアやフィードバックを提供する HIL または LLM の追加ステップがあります(前述)。 最終的な結果は、すべての出力のスコアを結合した集計結果(平均精度や人間の評価を計算)で、ユーザーはモデルの品質をベンチマークできます。
評価結果が収集されたら、いくつかの次元に基づいてモデルを選択することを提案します。 これらは通常、精度、速度、コストなどの要因に関係します。 次の図は、例を示しています。
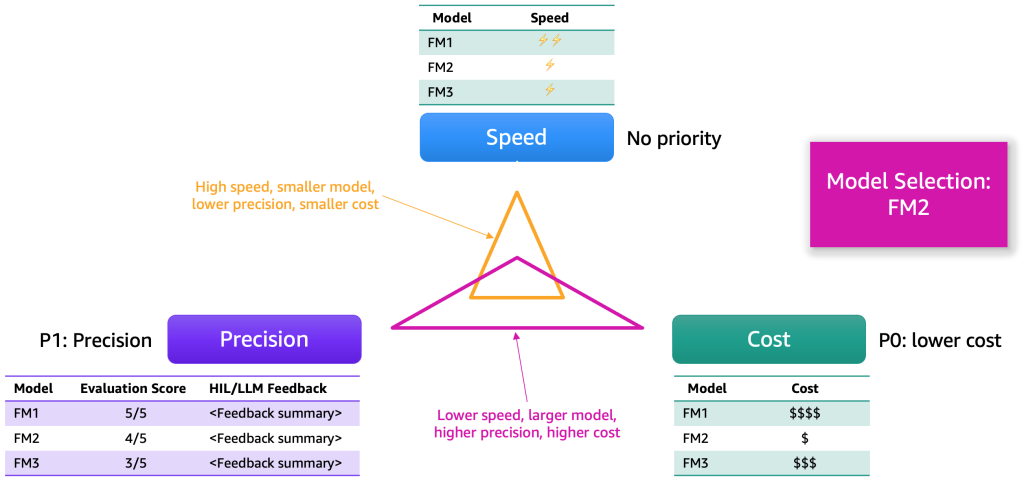
各モデルは、これらの次元に沿って強みと特定のトレードオフを持っています。 ユースケースに応じて、これらの次元に異なる優先順位を割り当てる必要があります。 前の例では、最も重要な要因としてコストを優先し、次に精度、そしてスピードとしました。 FM1 ほど効率的ではなく、遅いものの、十分に効果的で、ホスティングコストも大幅に安価です。 したがって、FM2 をトップ選択として選択する可能性があります。
ステップ3. 生成系 AI アプリケーションのバックエンドとフロントエンドを開発する
この時点で、生成系 AI 開発者は、プロンプトエンジニアとテスターの助けを借りて、特定のアプリケーションに適した正しい FM を選択しました。 次のステップは、生成系 AI アプリケーションの開発を開始することです。 生成系 AI アプリケーションの開発をバックエンドとフロントエンドの2つのレイヤーに分けています。以下の図の通りです。
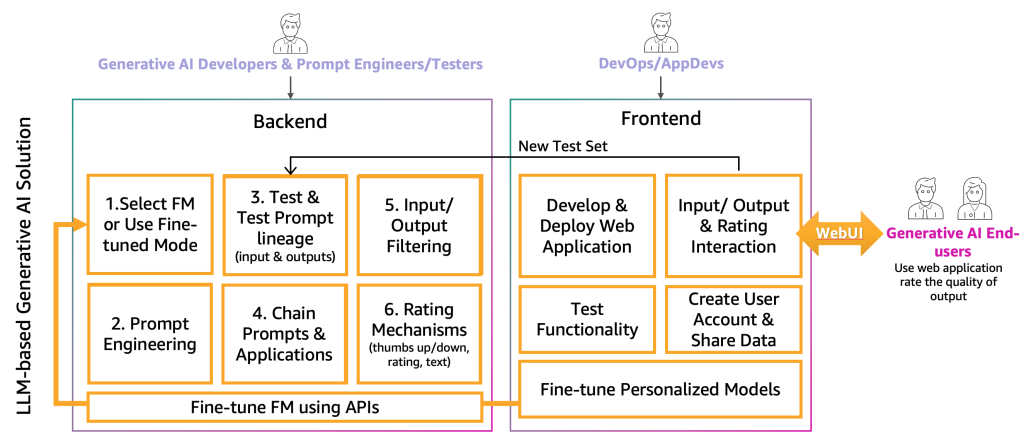
バックエンドでは、生成系 AI 開発者は、選択した FM をソリューションに組み込み、プロンプトエンジニアと協力して、エンドユーザーの入力を適切な FM プロンプトに変換するための自動化を作成します。 プロンプトテスターは、自動または手動 (HIL または LLM) のテストのために、プロンプトカタログに必要なエントリを作成します。 次に、生成系 AI 開発者は、最終出力を提供するためのプロンプトチェーンとアプリケーションメカニズムを作成します。 このコンテキストでは、プロンプトチェーンは、より動的でコンテキスト認識のある LLM アプリケーションを作成するテクニックです。 これは、複雑なタスクを一連の小さな、管理可能なサブタスクに分解することによって機能します。 たとえば、LLM に「イギリスの首相はどこで生まれ、その場所はロンドンからどのくらい離れているか」と尋ねた場合、タスクは、「イギリスの首相は誰ですか」、「出生地はどこですか」、「その場所はロンドンからどのくらい離れていますか」などの個々のプロンプトに分解できます。以前のプロンプトの評価に基づいてプロンプトが構築される場合があります。 一定の入力と出力の品質を確保するために、生成系 AI 開発者は、エンドユーザーの入力とアプリケーション出力を監視およびフィルタリングするメカニズムも作成する必要があります。 たとえば、LLM アプリケーションが有害なリクエストと応答を回避することを目的としている場合、入力と出力の両方に有害性検出を適用し、それらを除外できます。 最後に、良好例と悪例で評価プロンプトカタログを拡張するのに役立つ、評価メカニズムを提供する必要があります。 これらのメカニズムのより詳細な表現は、今後の投稿で提示されます。
この機能を生成系 AI エンドユーザーに提供するには、バックエンドと対話するフロントエンドウェブサイトの開発が必要です。 したがって、DevOps および AppDevs (クラウド上のアプリケーション開発者)のペルソナは、入力/出力および評価の機能を実装するために、ベストプラクティスに従う必要があります。
この基本的な機能に加えて、フロントエンドとバックエンドには、パーソナルユーザーアカウントの作成、データのアップロード、ブラックボックスとしてのファインチューニングの開始、基本 FM の代わりにパーソナライズされたモデルの使用などの機能を組み込む必要があります。 生成系 AI アプリケーションのプロダクション化は、通常のアプリケーションと同様です。 次の図は、サンプルアーキテクチャを示しています。
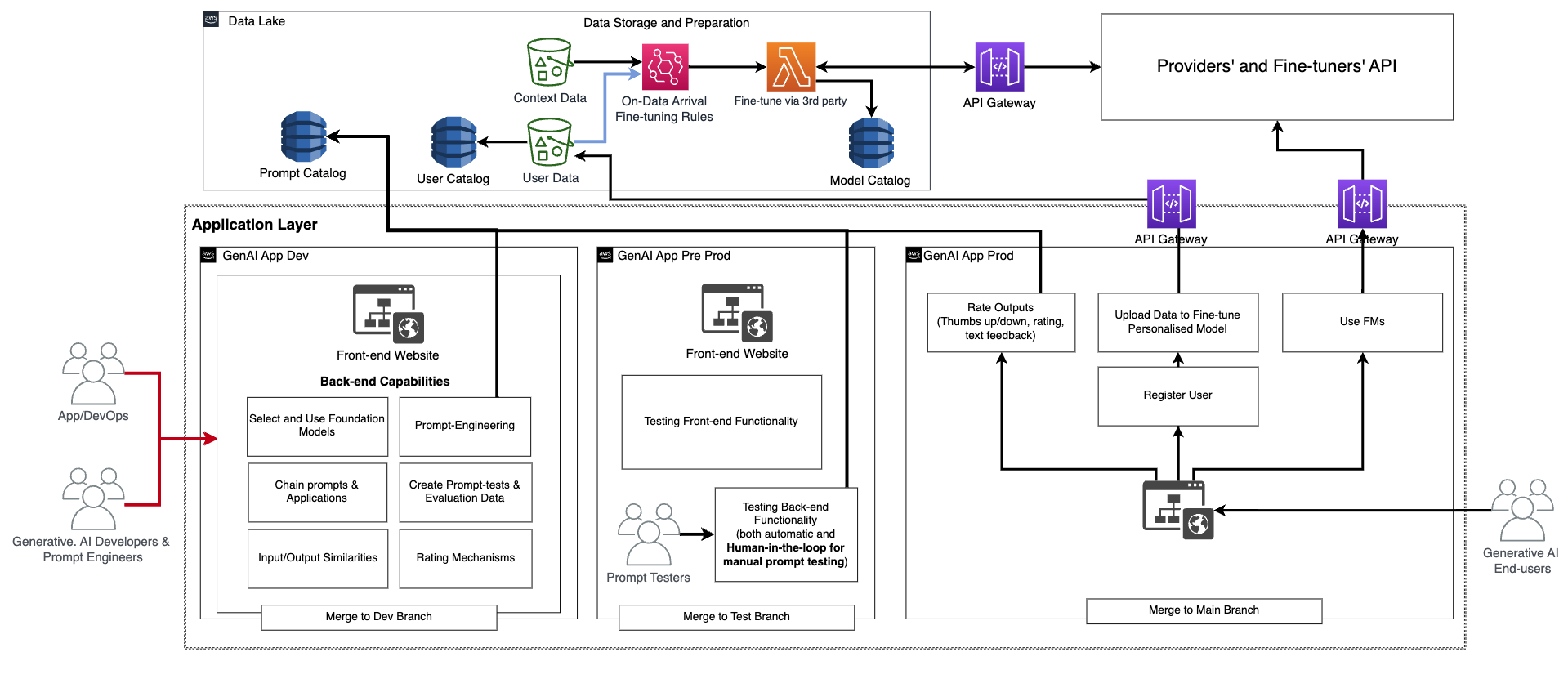
このアーキテクチャでは、生成系 AI 開発者、プロンプトエンジニア、DevOps または AppDev がアプリケーションを手動で作成およびテストし、専用のコードリポジトリを介して CI/CD 経由で開発環境(前の図の GenAI App Dev) にデプロイし、dev ブランチとマージします。 この段階で、生成系 AI 開発者は、FM プロバイダーによって提供された API を呼び出すことにより、対応する FM を使用します。 次に、アプリケーションを広範にテストするには、コードをテストブランチにプロモートする必要があります。これにより、CI/CD を介してプリプロダクション環境 (GenAI App Pre Prod) へのデプロイがトリガーされます。 この環境で、プロンプトテスターは大量のプロンプトの組み合わせを試し、結果を確認する必要があります。 プロンプト、出力、レビューの組み合わせは、評価プロンプトカタログに移動し、今後のテストプロセスを自動化する必要があります。 この広範なテストの後、最後のステップは、メインブランチとのマージにより、生成系 AI アプリケーションを CI/CD 経由で本番にプロモートすることです (GenAI App Prod)。 プロンプトカタログ、評価データと結果、エンドユーザーデータとメタデータ、ファインチューニングされたモデルのメタデータなど、すべてのデータをデータレイクまたはデータメッシュレイヤに格納する必要があることに注意してください。 CI/CD パイプラインとリポジトリは、別のツールアカウント( MLOps に記載のものと同様)に格納する必要があります。
プロバイダーの旅
FM プロバイダーは、ディープラーニングモデルなどの FM をトレーニングする必要があります。 彼らにとって、エンドツーエンドの MLOps ライフサイクルとインフラストラクチャが必要です。 履歴データの準備、モデル評価、および監視に追加が必要です。 以下の図は、そのプロセスを示しています。
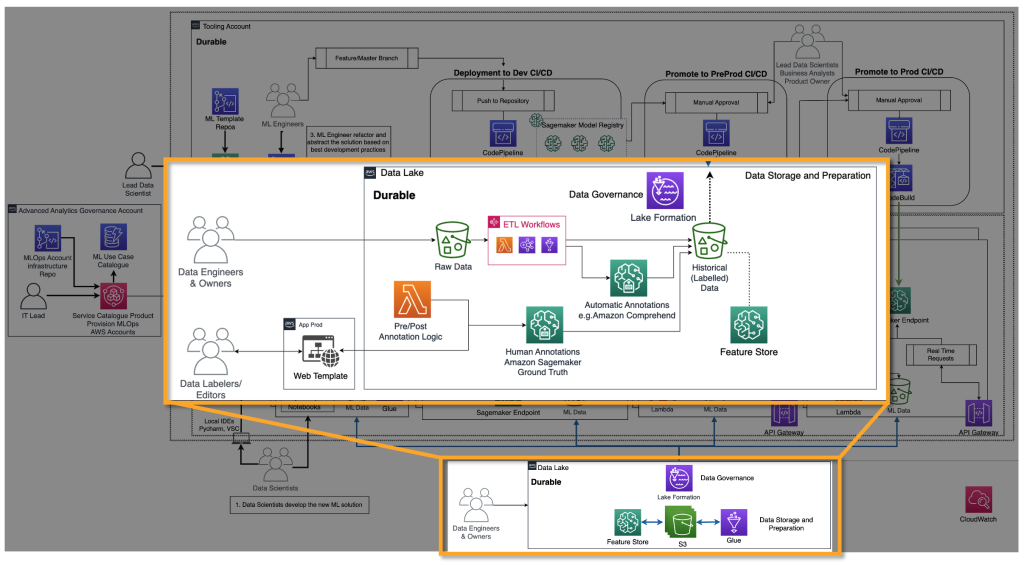
従来の ML では、真値を ETL パイプライン経由でフィードすることにより、履歴データが作成されます。 例えば、顧客離反予測のユースケースでは、自動化によりデータベーステーブルが顧客の離反/非離反ステータスに基づいて自動的に更新されます。 FM の場合、ラベル付きまたはラベルなしのデータポイントの10億~100億が必要です。 テキスト対画像のユースケースでは、データラベラーチームが手動で<テキスト、画像>のペアにラベルを付ける必要があります。 これは、多くの人的リソースを必要とする高価な作業です。 Amazon SageMaker Ground Truth Plus は、このアクティビティを実行するためのラベラーチームを提供できます。 LLM の場合などのラベルなしデータのユースケースの場合、データはラベルが付いていません。 ただし、既存の未ラベルの履歴データのフォーマットに従う必要があるため、データエディターが必要なデータ準備を行い、一貫性を確保する必要があります。
履歴データの準備が整ったら、次のステップはモデルのトレーニングと運用化です。 消費者のシナリオに記載されているのと同じ評価手法を使用できることに注意してください。
ファインチューナーの旅
ファインチューナーの目的は、既存の FM を特定のコンテキストに適合させることです。 たとえば、FM モデルは一般目的のテキストを要約できますが、金融報告書を正確に要約できないかもしれません。または、一般的ではないプログラミング言語のソースコードを生成できない可能性があります。 このような場合、ファインチューナーはデータにラベルを付け、トレーニングジョブを実行してモデルをファインチューニングし、モデルをデプロイし、コンシューマーのプロセスに基づいてモデルをテストし、モデルを監視する必要があります。 次の図は、このプロセスを示しています。
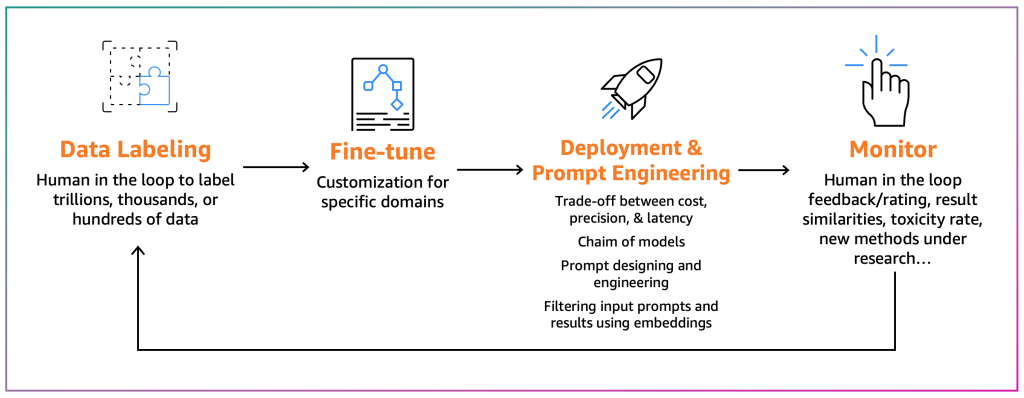
現時点では、ファインチューニングのメカニズムが2つあります。
- ファインチューニング – FM とラベル付きデータを使用することにより、トレーニングジョブはディープラーニングモデルのレイヤの重みとバイアスを再計算します。 このプロセスは計算資源を大量に必要とする可能性があり、代表的な量のデータが必要ですが、正確な結果を生成できます。
- パラメータ効率的ファインチューニング (PEFT) – すべての重みとバイアスを再計算する代わりに、研究者はディープラーニングモデルに追加の小さなレイヤーを追加することにより、満足のいく結果を達成できることを示してきました (LoRA など)。 PEFT は、ディープファインチューニングよりも計算リソースが少なくて済み、トレーニングジョブに必要な入力データが少なくて済みます。 欠点は、精度が低下する可能性があることです。
次の図は、これらのメカニズムを示しています。
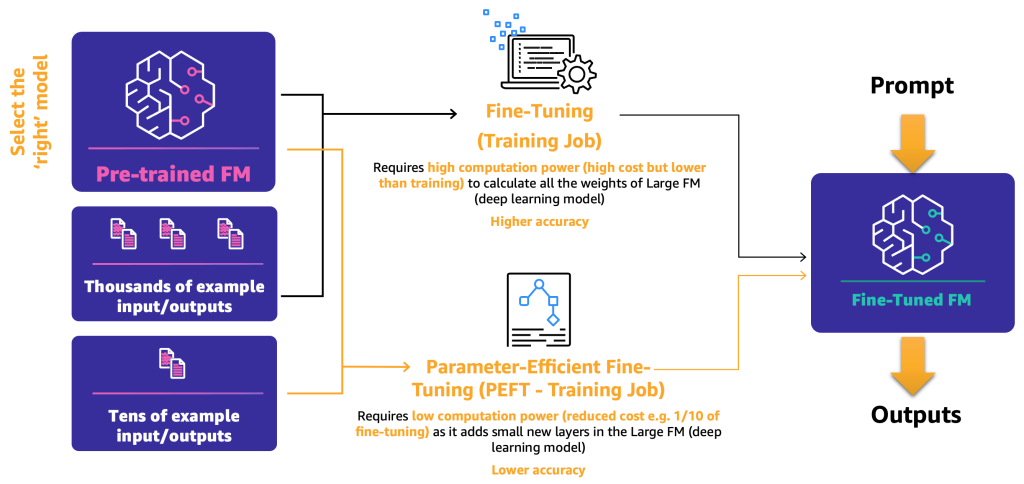
2つの主要なファインチューニング方法を定義したので、次のステップは、オープンソースおよびプロプライエタリの FM をどのようにデプロイおよび使用するかを決定することです。
オープンソースの FM の場合、ファインチューナーはウェブからモデルアーティファクトとソースコードをダウンロードできます。たとえば、Hugging Face Model Hub を使用できます。 これにより、モデルを深くファインチューニングし、ローカルのモデルレジストリに格納し、Amazon SageMaker エンドポイントにデプロイする柔軟性が得られます。 このプロセスにはインターネット接続が必要です。 よりセキュアな環境(金融セクターの顧客など)をサポートするには、モデルをオンプレミスでダウンロードし、すべての必要なセキュリティチェックを実行し、AWS アカウントのローカルバケットにアップロードできます。 次に、ファインチューナーは、インターネット接続なしでローカルバケットから FM を使用できます。 これにより、データプライバシーが確保され、データがインターネット経由で移動しないようになります。 次の図は、この方法を示しています。
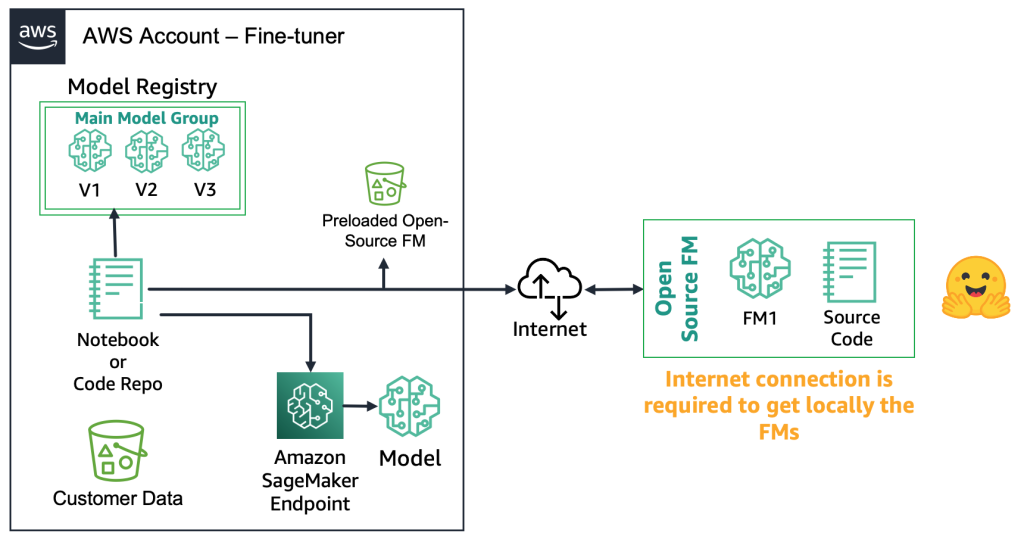
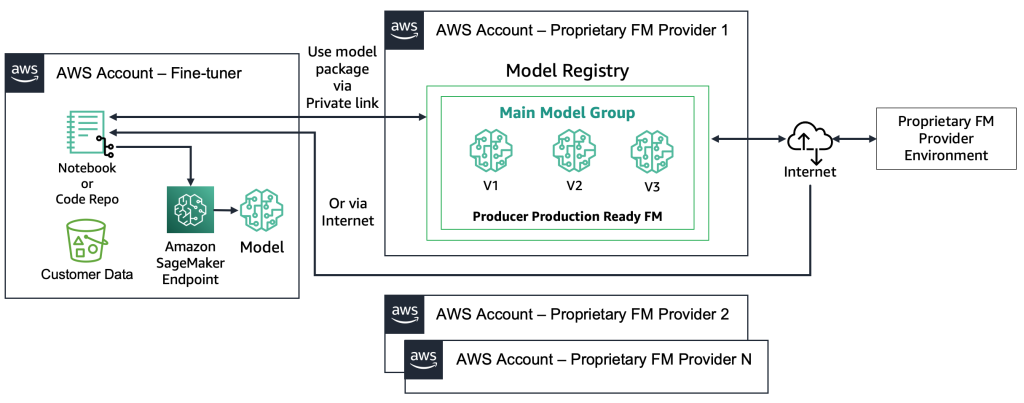
プロプライエタリ FM の場合、ファインチューナーがモデルアーティファクトやソースコードにアクセスできないため、デプロイプロセスは異なります。 モデルは、プロプライエタリ FM プロバイダーの AWS アカウントとモデルレジストリに格納されています。 SageMaker エンドポイントにこのようなモデルをデプロイするには、ファインチューナーは直接エンドポイントにデプロイされるモデルパッケージのみをリクエストできます。 このプロセスでは、プロプライエタリ FM プロバイダーのアカウントで顧客データを使用してファインチューニングを実行する必要があるため、リモートアカウントで顧客機密データが使用されてファインチューニングが実行されることや、複数の顧客間で共有されるモデルレジストリでモデルがホストされることに関する疑問が生じます。 これにより、プロプライエタリ FM プロバイダーがこれらのモデルを提供する必要がある場合、マルチテナントの問題がより困難になります。 ファインチューナーが Amazon Bedrock を使用する場合、これらの課題が解決されます。データはインターネット経由では移動せず、FM プロバイダーはファインチューナーのデータにアクセスできません。 前述の例で説明したように、ウェブサイトが数千人の顧客がパーソナライズされた画像をアップロードすることを可能にする場合と同じ課題が、オープンソースモデルにもあります。 ただし、これらのシナリオは、ファインチューナーのみが関与しているため、制御可能であると見なすことができます。 次の図は、この方法を示しています。
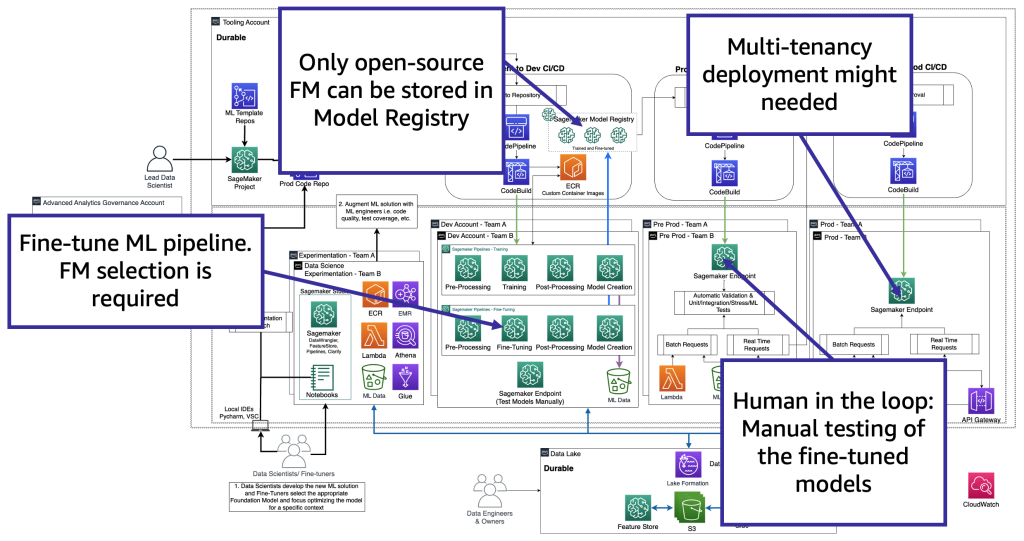
技術的な観点から、ファインチューナーがサポートする必要のあるアーキテクチャは、MLOps と同様です(次の図を参照)。 ファインチューニングは、Amazon SageMaker Pipelines などを使用した ML パイプラインを作成することにより、開発で行う必要があります。前処理、ファインチューニング(トレーニングジョブ)、および後処理を実行し、ファインチューニングされたモデルをオープンソース FM の場合はローカルのモデルレジストリに送信し(そうでない場合、新しいモデルはプロプライエタリ FM プロバイダー環境に格納されます)。 次に、本番前にモデルをテストする必要があります。最後に、モデルがサービスとして提供され、監視されます。 現在(ファインチューニングされた) FM には、GPU インスタンスエンドポイントが必要です。 各ファインチューニングモデルを個別のエンドポイントにデプロイする必要がある場合、数百ものモデルがあるとコストが増加する可能性があります。 したがって、マルチモデルエンドポイントを使用し、マルチテナンシーの課題を解決する必要があります。
ファインチューナーは、特定のコンテキストに基づいて FM モデルを適合させ、ビジネス目的で使用します。 つまり、ファインチューナーはほとんどの場合、前のセクションで説明したすべてのレイヤーをサポートするコンシューマーでも必要です。これには、生成系AIアプリケーションの開発、データレイクとデータメッシュ、MLOps が含まれます。
以下の図は、生成系 AI エンドユーザーに提供するための完全な FM ファインチューニングライフサイクルを示しています。
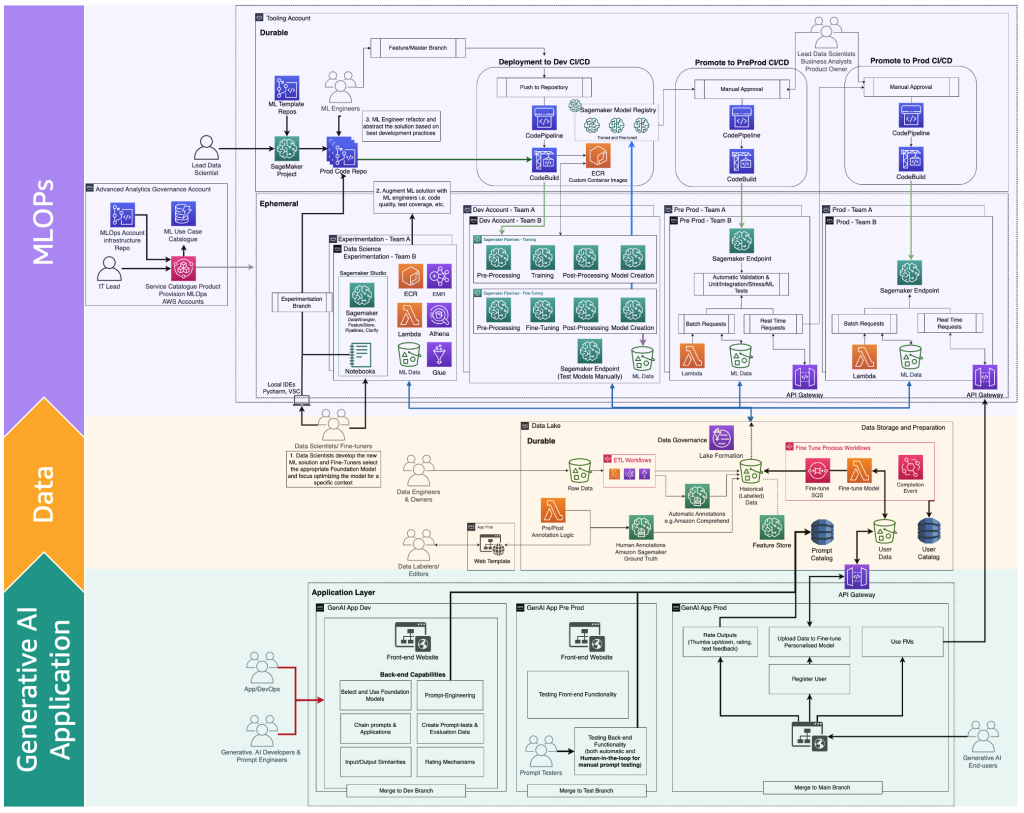
次の図は、重要なステップを示しています。
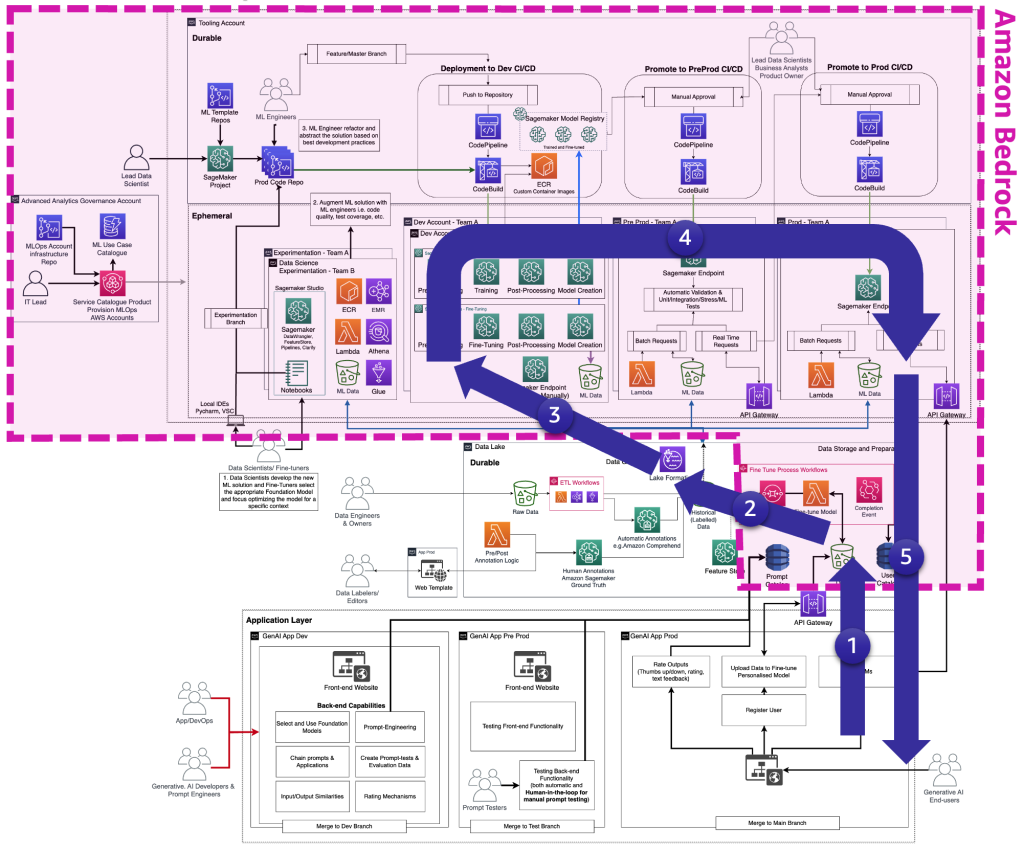
主なステップは以下のとおりです。
- エンドユーザーがパーソナルアカウントを作成し、プライベートデータをアップロードします。
- データはデータレイクに格納され、FM が期待するフォーマットに前処理されます。
- これにより、モデルをモデルレジストリに追加するファインチューニング ML パイプラインがトリガーされます。
- そこから、モデルは最小限のテストで本番にデプロイされるか、手動の承認ゲートを備えた広範なテストを経てプッシュされます。
- ファインチューニングされたモデルは、エンドユーザーが利用できるようになります。
このインフラストラクチャはエンタープライズ顧客以外には複雑なため、AWS はこのようなアーキテクチャの作成の労力を軽減し、ファインチューニングされた FM をより製品に近づけるために Amazon Bedrock をリリースしました。
FMOps および LLMOps のペルソナとプロセスの差別化点
前述のユーザータイプ(コンシューマー、プロデューサー、ファインチューナー)のジャーニーに基づいて、特定のスキルを持つ新しいペルソナが必要です。以下の図に示されています。
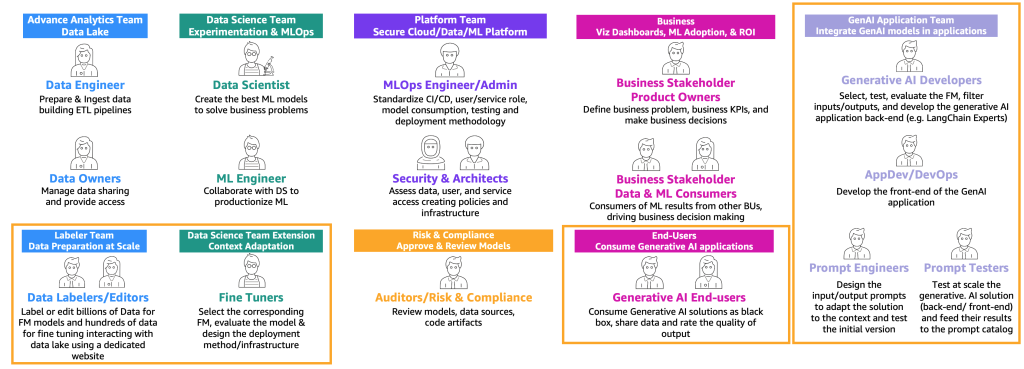
新しいペルソナは以下の通りです。
- データラベラーとエディター – これらのユーザーは、<テキスト、画像>のペアなどのデータにラベルを付けたり、フリーテキストなどのラベルなしデータを準備したりして、アドバンスドアナリティクスチームとデータレイク環境を拡張します。
- ファインチューナー – これらのユーザーは FM に関する深い知識を持ち、それらを調整する方法を知っており、クラシック ML に焦点を当てるデータサイエンティストチームを拡張します。
- 生成系 AI 開発者 – FM の選択、プロンプトチェーン、アプリケーション、入力と出力のフィルタリングに関する深い知識を持っています。 彼らは新しいチームである生成系 AI アプリケーションチームに属します。
- プロンプトエンジニア – これらのユーザーは、コンテキストにソリューションを適合させ、テストし、プロンプトカタログの初期バージョンを作成する入力と出力のプロンプトを設計します。 彼らのチームは生成系 AI アプリケーションチームです。
- プロンプトテスター – これらのユーザーは生成系 AI ソリューション(バックエンドとフロントエンド)を大規模にテストし、結果をプロンプトカタログと評価データセットの拡張にフィードします。 彼らのチームは生成系 AI アプリケーションチームです。
- AppDev と DevOps – これらのユーザーは、生成系 AI アプリケーションのフロントエンド(ウェブサイトなど)を開発します。 彼らのチームは生成系 AI アプリケーションチームです。
- 生成系 AI エンドユーザー – これらのユーザーは、ブラックボックスとしての生成系 AI アプリケーションを消費し、データを共有し、出力の品質を評価します。
生成系 AI を組み込むために MLOps プロセスマップの拡張バージョンは、次の図のように示すことができます。
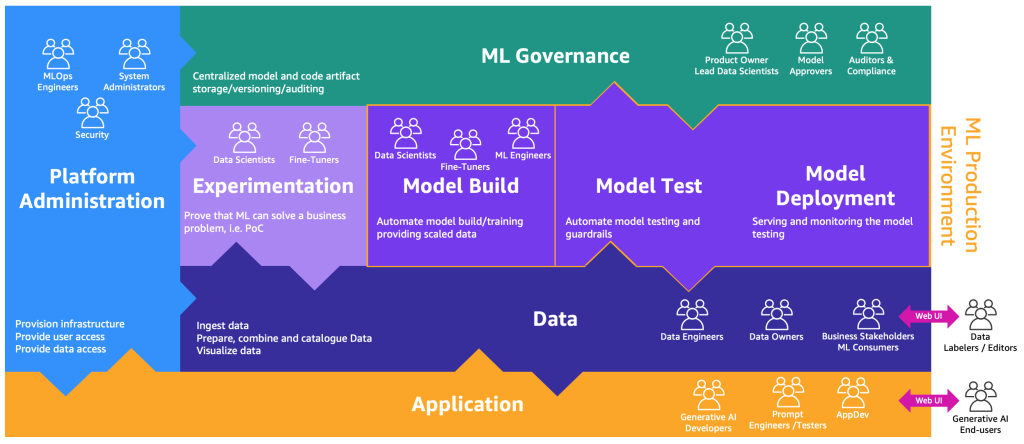
新しいアプリケーションレイヤーは、生成系 AI 開発者、プロンプトエンジニア、テスター、AppDev が生成系 AI アプリケーションのバックエンドとフロントエンドを作成する環境です。 生成系 AI エンドユーザーは、インターネット (Web UI など)を介して生成系 AI アプリケーションのフロントエンドと対話します。 一方、データラベラーとエディターは、バックエンドにアクセスすることなくデータを前処理する必要があります。 したがって、データと安全に対話するためのエディター付きの Web UI (Web サイト)が必要です。 SageMaker Ground Truth はこれらの機能をすぐに利用できるように提供します。
まとめ
MLOps は、ML モデルを効率的に本番化するのに役立ちます。 ただし、生成系 AI アプリケーションを運用化するには、追加のスキル、プロセス、テクノロジーが必要で、FMOps と LLMOps につながります。 この投稿では、FMOps と LLMOps の主な概念を定義し、人材、プロセス、テクノロジーの観点から MLOps 機能との主な違いについて説明しました。 FM モデルの選択と評価、および生成系 AI アプリケーションの開発ライフサイクルについて説明しました。
今後、議論したドメインごとのソリューションの提供に焦点を当て、FM 監視(有害性、バイアス、幻覚など)やサードパーティまたはプライベートデータソースアーキテクチャパターン(検索拡張生成など) の FMOps/LLMOps への統合に関する詳細を提供する予定です。
詳細については、Amazon SageMakerを利用したエンタープライズのためのMLOps基盤ロードマップを参照し、Amazon SageMaker JumpStart 事前トレーニングモデルでの MLOps プラクティスの実装でエンドツーエンドのソリューションを試してください。
ご意見やご質問があれば、コメント欄にお寄せください。
著者について
 Dr. Sokratis Kartakis は、Amazon Web Services のシニア機械学習および運用専門ソリューションアーキテクトです。 Sokratis は、AWS サービスを活用し、運用モデル、つまり MLOps の基盤と変革ロードマップを形作ることにより、エンタープライズ顧客が機械学習 (ML) ソリューションを産業化するのを支援に集中しています。 彼は、エネルギー、小売、ヘルスケア、ファイナンス/銀行、モータースポーツなどの領域で、革新的なエンドツーエンドの ML および IoT ソリューションの発明、設計、リーダーシップ、実装に15年以上携わってきました。 Sokratis は、家族や友人と過ごしたり、バイクに乗ったりすることで余暇を過ごすのが好きです。
Dr. Sokratis Kartakis は、Amazon Web Services のシニア機械学習および運用専門ソリューションアーキテクトです。 Sokratis は、AWS サービスを活用し、運用モデル、つまり MLOps の基盤と変革ロードマップを形作ることにより、エンタープライズ顧客が機械学習 (ML) ソリューションを産業化するのを支援に集中しています。 彼は、エネルギー、小売、ヘルスケア、ファイナンス/銀行、モータースポーツなどの領域で、革新的なエンドツーエンドの ML および IoT ソリューションの発明、設計、リーダーシップ、実装に15年以上携わってきました。 Sokratis は、家族や友人と過ごしたり、バイクに乗ったりすることで余暇を過ごすのが好きです。
 Heiko Hotz は、自然言語処理、大規模言語モデル、生成系 AI に特化した AI および機械学習のシニアソリューションアーキテクトです。 この役割に就く前は、Amazon の欧州顧客サービスのデータサイエンス部門の責任者を務めていました。 Heiko は、AWS で AI/ML の旅を成功させるお客様を支援しており、保険、金融サービス、メディア&エンターテイメント、ヘルスケア、ユーティリティ、製造など、多くの業界の組織と協力してきました。 Heiko は、できる限り旅行するのが趣味です。
Heiko Hotz は、自然言語処理、大規模言語モデル、生成系 AI に特化した AI および機械学習のシニアソリューションアーキテクトです。 この役割に就く前は、Amazon の欧州顧客サービスのデータサイエンス部門の責任者を務めていました。 Heiko は、AWS で AI/ML の旅を成功させるお客様を支援しており、保険、金融サービス、メディア&エンターテイメント、ヘルスケア、ユーティリティ、製造など、多くの業界の組織と協力してきました。 Heiko は、できる限り旅行するのが趣味です。
翻訳はソリューションアーキテクトの中島佑樹、伊藤芳幸が担当しました。原文はこちらです。