Amazon Web Services ブログ
さようなら Microsoft SQL Server、こんにちは Babelfish
多くのお客様は、高額なコストと負担のかかるライセンス条項を避けるために、商用データベースベンダーから離れることを望んでいると私たちに言っています。ただし、商用データベースやレガシーデータベースからの移行は、時間がかかり、リソースを大量に消費する可能性があります。データベースを移行する場合、AWS スキーマ変換ツールと AWS Database Migration Service を使用して、データベーススキーマとデータの移行を自動化できます。
ただし、データベースとやり取りするアプリケーションコードを書き直すなど、アプリケーション自体を移行するには、常に多くの作業が必要です。モチベーションはそこにありますが、コストやリスクがしばしば制限要因となります。
2021 年 10 月 28 日、Babelfish for Aurora PostgreSQL の一般利用を開始します。Babelfish は、Amazon Aurora PostgreSQL 互換エディションが SQL Server のワイヤプロトコルを理解できるようにします。これにより、SQL Server アプリケーションを PostgreSQL に安価かつ迅速に移行でき、そのような変更に伴うリスクも低減できます。
従来の移行で必要とされる時間のほんの一部で、アプリケーションを移行できます。現在アプリケーションが使用している既存のクエリとドライバーを引き続き使用できます。アプリケーションを Babelfish がアクティブ化された Amazon Aurora PostgreSQL データベースに向けるだけです。 Babelfish は、Amazon Aurora PostgreSQL に SQL Server ワイヤプロトコル Tabular Data Stream (TDS) を理解する機能を追加し、PostgreSQL が SQL Server で一般的に使用される T-SQL コマンドを理解できるように拡張します。T-SQL のサポートには、SQL ダイアレクト、静的カーソル、データ型、トリガー、ストアドプロシージャ、関数などの要素が含まれます。Babelfish は、アプリケーションに必要な変更の数を大幅に減らすことで、データベース移行プロジェクトに関連するリスクを軽減します。Babelfish を採用すると、SQL Server を使用する際のライセンスコストを節約できます。Amazon Aurora は、商用データベースのセキュリティ、可用性、および信頼性を 10 分の 1 のコストで提供します。
SQL Server は 30 年以上にわたって進化しており、すべての機能をすぐにサポートすることは期待できません。代わりに、最も一般的な T-SQL コマンドに焦点を当て、正しい応答またはエラーメッセージを返します。例えば、MONEY データ型は SQL Server (小数点以下 4 桁の精度) と PostgreSQL (小数点以下 2 桁の精度) で異なる特性を持っています。このような微妙な違いが、丸め誤差につながり、財務報告などの下流プロセスに大きな影響を与える可能性があります。この場合、および他の多くの場合、Babelfish は、SQL Server データ型のセマンティクスと T-SQL 機能が保持されることを保証します。SQL Serverアプリが期待するように動作する MONEY データ型を作成しました。Babelfish 接続を介してこのデータ型を持つテーブルを作成すると、SQL Server アプリが期待するこの互換性のあるデータ型と動作が得られます。
コンソールを使用して Babelfish クラスターを作成する
Babelfish の仕組みを説明するために、まずコンソールに接続し、新しい Amazon Aurora PostgreSQL クラスターを作成しましょう。この手順は、通常の Amazon Aurora データベースの場合と変わりません。RDS 起動ウィザードで、まず PostgreSQL 13.4 またはそれより新しいバージョンと互換性がある Aurora バージョンを選択します。更新されたコンソールには、Babelfish と互換性のあるバージョンを選択するのに役立つ追加のフィルターがあります。
 次に、ページの下部で、[Babelfish をオンにする] オプションを選択します。
次に、ページの下部で、[Babelfish をオンにする] オプションを選択します。
[モニタリング] セクションで、[拡張モニタリングを有効にする] をオフにします。このオプションには、このデモには関係のない追加の IAM 許可と準備が必要です。
 数分後、クラスターが作成され、1 つのライターと 1 つのリーダーの 2 つのインスタンスがあります。
数分後、クラスターが作成され、1 つのライターと 1 つのリーダーの 2 つのインスタンスがあります。
CLI を使用した Babelfish クラスターの作成
または、 を使用してクラスターを作成することもできます。まず、Babelfish をアクティブにするパラメータグループを作成します (コンソールが自動的に実行します)。
aws rds create-db-cluster-parameter-group \
--db-cluster-parameter-group-name myapp-babelfish \
--db-parameter-group-family aurora-postgresql13 \
--description "babelfish APG 13"
aws rds modify-db-cluster-parameter-group \
--db-cluster-parameter-group-name myapp-babelfish \
--parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" \次に、データベースクラスターを作成します (以下のコマンドを使用する場合は、セキュリティグループ ID とサブネットグループ名を調整します)。
aws rds create-db-cluster \
--db-cluster-identifier awsnewblog-cli-demo \
--master-username postgres \
--master-user-password Passw0rd \
--engine aurora-postgresql \
--engine-version 13.4 \
--vpc-security-group-ids sg-abcd1234 \
--db-subnet-group-name default-vpc-1234abcd \
--db-cluster-parameter-group-name myapp-babelfish
{
"DBCluster": {
"AllocatedStorage": 1,
"AvailabilityZones": [
"us-east-1c",
"us-east-1d",
"us-east-1a"
],
"BackupRetentionPeriod": 1,
"DBClusterIdentifier": "awsnewblog-cli-demo",
"Status": "creating",
... <redacted for brevity> ...
}
}クラスターが作成されたら、以下を使用してインスタンスを作成します。
aws rds create-db-instance \
--db-instance-identifier myapp-db1 \
--db-instance-class db.r5.4xlarge \
--db-subnet-group-name default-vpc-1234abcd \
--db-cluster-identifier awsnewblog-cli-demo \
--engine aurora-postgresql
{
"DBInstance": {
"DBInstanceIdentifier": "myapp-db1",
"DBInstanceClass": "db.r5.4xlarge",
"Engine": "aurora-postgresql",
"DBInstanceStatus": "creating",
... <redacted for brevity> ...Babelfish クラスターに接続する
クラスターとインスタンスの準備が整ったら、ライターインスタンスに接続してデータベース自体を作成します。SQL Server Management Studio (SSMS) または sqlcmd などの他の SQL クライアントを使用してインスタンスに接続できます。Windows クライアントは Babelfish クラスターに接続できる必要があります。RDS セキュリティグループが Windows ホストからの接続を許可することを確認しました。
Windows で SSMS を使用して、ツールバーの [新しいクエリ] を選択し、データベースの DNS 名をサーバー名として入力します。 [SQL Server 認証] を選択し、データベースのログインとパスワードを入力します。[接続] をクリックします。
重要: SSMS オブジェクトエクスプローラでは接続しないでください。必ず、[新しいクエリ] ボタンでクエリエディタを使用して接続してください。現時点では、Babelfish はクエリエディタをサポートしていますが、オブジェクトエクスプローラはサポートしていません。
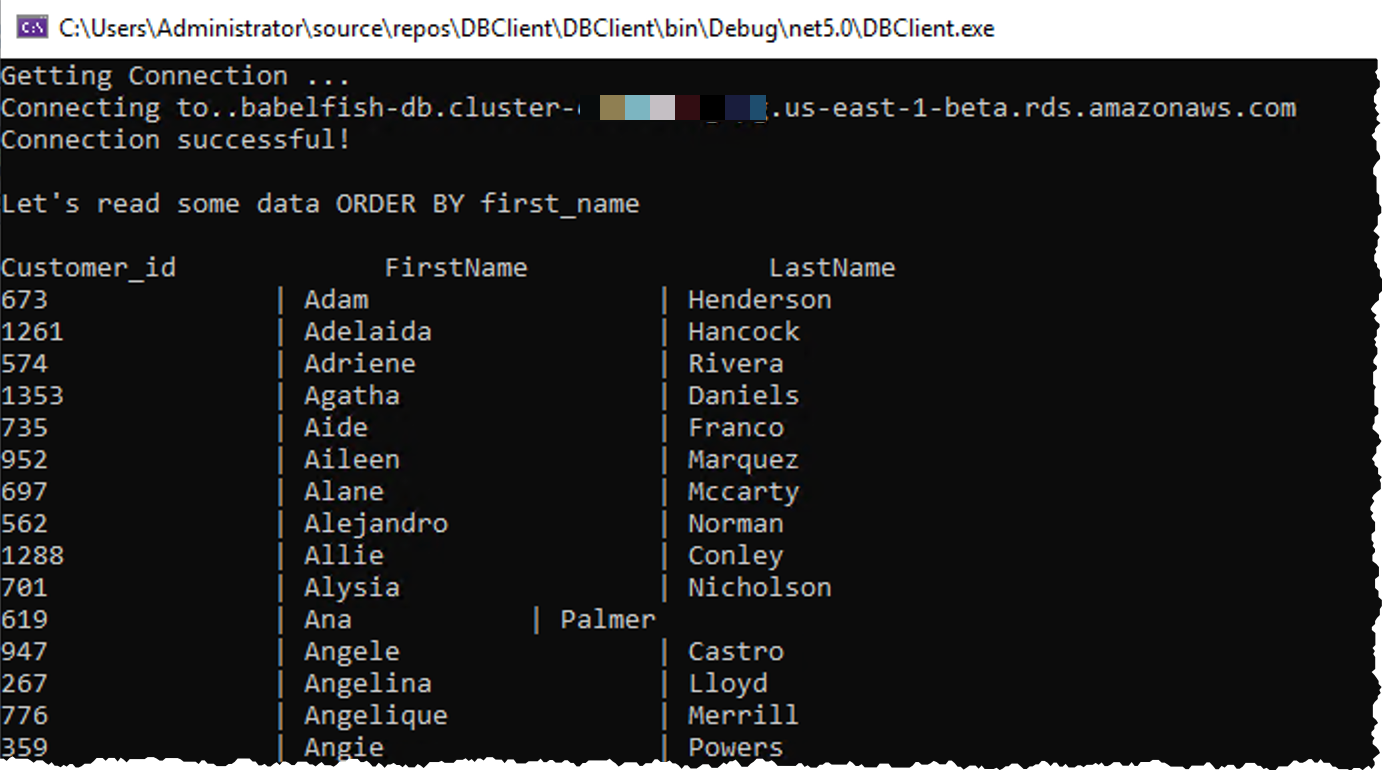
接続したら、select @@version ステートメントでバージョンを確認し、ツールバーにある緑色の [Execute] ボタンをクリックします。画面の下部にあるステートメントの結果を読むことができます。

最後に、create database demo ステートメントを使用して、インスタンスでデータベースを作成します。

デフォルトでは、Babelfish はシングルデータベースモードで動作します。このモードを使用すると、インスタンスごとに最大 1 つのユーザーデータベースを持つことができます。これにより、SQL Server と PostgreSQL の間のスキーマ名の密接なマッピングが可能になります。または、クラスター作成時にマルチデータベースモードをオンにすることもできます。これにより、インスタンスごとに複数のユーザーデータベースを作成できます。PostgreSQL では、ユーザデータベースは、データベース名をプレフィックスとして持つ複数のスキーマにマップされます。
アプリケーションを実行する
このデモの目的から、SQL Server チュートリアルの一部として SQLServerTutorial.net が提供するデータベーススキーマを使用して、スキーマを作成し、データを入力します。このデモで使用している SQL スクリプトとアプリケーション C# コードは、GitHub リポジトリで入手できます。C# デモアプリケーションを提供してくれた同僚の Anuja に心から感謝します。
SQL Server Management Studio でcreate_objects.sql スクリプトを開き、上部のツールバーにある緑色の [実行] アイコンを選択します。データベーススキーマが作成されたことを示す確認メッセージが表示されます。

load_data.sql スクリプトでこのオペレーションを繰り返し、新しく作成されるテーブルにデータをロードします。データのロードには数分かかります。
データベースがロードされたら、 Anuja の SQL Server データベースにアクセスするために開発された C# アプリケーションを開きましょう。2 行のコードを修正します。
- 12 行目: 先ほど作成した Babelfish クラスターの DNS 名を入力します。クラスターの「書き込み」ノードの DNS 名を使用することに注意してください。
- 15 行目: データベースクラスターの作成時に入力したパスワードを入力します。

これで完成です。 このアプリでは、その他の変更は必要ありません。SQL Server とのクエリとやり取りのために書かれたこのコードは、Babelfishと Aurora PostgreSQL で「そのままで」動作します。
オープンソースの透明性
Babelfish の背後にある技術をオープンソース化して、Babelfish for PostgreSQL オープンソースプロジェクトを作成することにしました。寛容な Apache 2.0 と PostgreSQL のライセンスを使用します。つまり、Babelfish を変更したり、調整したり、配布したりすることができます。時間の経過とともに、Babelfish を GitHub での開発に完全にオープンにするようにシフトしているため、最初から透明性があります。今では、AWS のお客様であるかないかに関わらず、誰でも Babelfish を使用して SQL Server から離れ、迅速かつ簡単、そして費用対効果の高い方法でアプリケーションをオープンソースの PostgreSQL に移行することができます。Babelfish は PostgreSQL を、これまでになく幅広いお客様やデベロッパーのグループ、特に SQL Server 向けに作成された複雑なアプリケーションが多数あるユーザーやデベロッパーがアクセスできるようにすると確信しています。
利用状況
Babelfish for Aurora PostgreSQL は、現在、パブリックに利用可能なすべての AWS リージョンで追加料金なしでご利用いただけます。アプリケーションの移行を今すぐ始めましょう。
PS: Babelfish という名前がどこから来ているのか疑問に思ったら、答えは 42 であることを覚えておいてください。(または、この少し長い答えを読むこともできます。)
原文はこちらです。