Amazon Web Services ブログ
Annalect が Amazon Redshift を使ってイベントログデータ分析ソリューションを構築した方法
ほぼリアルタイムでイベントログデータをデータウェアハウスに取り込み、分析することは困難な作業です。データインジェストは、高速かつ効率的である必要があります。データウェアハウスは、受信データボリュームを処理するために迅速にスケールできなければなりません。アクセス頻度の低い大量の履歴データをデータウェアハウスに保存するためのコストは、とてつもなく高額です。データウェアハウス外にアクセス頻度の低いデータを保存する場合、ロード時間が許容できない長さになります。
Annalect では、これらの課題を克服する方法を見いだしました。この記事では、Annalect が、広告テクノロジーパートナーからのイベントログデータを管理、強化、そして分析するために、どのように AWS でソリューションを構築したかについて説明します。Annalect では、ストレージ用に Amazon S3、コンピューティング用に Amazon EC2 と AWS Batch、データのカタログ化に AWS Glue、そして分析用に Amazon Redshift と Amazon Redshift Spectrum を使用しています。このスケーラブルなオンデマンドのアーキテクチャは、Annalect の分析ユーザーに対する高パフォーマンスソリューションであり、かつコスト効率性が極めて高いことが明らかになりました。
アーキテクチャの概要
2016 年のなかばごろ、私たちは、アナリストとモデラーが広告購入戦略を向上させることができるように、イベントレベルのアドテクノロジーデータセットに対する SQL アクセスを提供するローカルテーブルに Amazon Redshift を使用していました。Annalect では、厳選されたデータソースの履歴データを最高 6 ヵ月保持しており、これは約 2,300 億件のイベントに相当する量でした。2017 年初頭には、同じデータフットプリントが 3,850 億イベントに膨れ上がり、それに対応するために Amazon Redshift の容量を増加しました。将来を見据えて、履歴とデータソースのカバレッジの両方の観点から、より多くのデータをサポートしたいと考えてはいましたが、それと同時に、クエリパフォーマンスを、理想的にはコストを増加させることなく、維持または向上させたいとも考えていました。
Amazon Redshift はすでにデータウェアハウスとして使用していたため、私たちは Redshift Spectrum に着目しました。Redshift Spectrum は、Amazon S3 に保存されたデータをクエリする Amazon Redshift の機能です。これは、Amazon Redshift と同じ SQL 機能を使用しますが、Amazon Redshift クラスター内のディスクに保存されている Amazon Redshift テーブルにデータをロードすることを必要としません。
Redshift Spectrum では、テーブルのストレージがクラスターのコンピューティングリソースから分離されているため、それぞれを他方に依存することなくスケールすることが可能です。大規模データテーブルを、ローカルの Amazon Redshift ストレージではなく S3 に保存することができるため、Amazon Redshift クラスターのサイズが縮小され、コストが低減されます。外部の Redshift Spectrum テーブルを使用するクエリは、Redshift Spectrum のコンピューティングリソース (Amazon Redshift クラスターとは切り離されているもの) を使って S3 のデータをスキャンします。クエリ料金は、スキャンしたデータの量に基づいた従量制で AWS から請求されます。クエリの効率性のため、私たちは AWS Batch を使って S3 に保存されたデータを Parquet ファイルに変換しました。
結果として、Redshift Spectrum でのクエリのためにいつでもデータを利用できる、効率的で、ほとんどサーバーレスの分析環境が生まれました。常時オンの Amazon Redshift クラスターもいくつか管理していますが、私たちは、この環境を「ほぼサーバーレス」と見なしています。 分析のために Redshift Spectrum を通じて使用し、データの準備のために AWS Batch を通じて使用するサーバーレスコンピューティングパワーと比較して、クラスターフットプリントが非常に小さいからです。
Amazon Redshift クラスターは、ジョブのロード専用としてその時間の一部を費やすかわりに、アナリストによる分析の実行だけに使われます。これは、Amazon Redshift クラスター内のローカルテーブルへのデータのコピーに費やす時間がまったくなく、データの準備作業を Amazon Redshift 外で行っているためです。
Redshift Spectrum への進化と、S3 でのデータの保存によって、2018 年初頭には、アナリストに配信するデータの量を大幅に増加させました。それと同時に、コストも 2017 年と同じレベルに抑えることができました。Redshift Spectrum の使用は、私たちにとって優れたコスト節減になっています。Annalect では現在、はるかに多くのデータソース用に使用できる履歴データを最大 36 ヵ月維持しており、これは何 10 兆ものイベントに相当します。
私たちのデータ管理インフラストラクチャである Enhanced Event-Level Data Environment (EELDE) は、以下のように構成されています。
EELDE は 4 つの主な機能を提供します。
- データインジェスト
- データ変換
- コンピューティング集約型のエンリッチメント
- アナリストのアドホッククエリ環境
これら 4 つの機能については、以下でより詳しく説明します。
データインジェスト
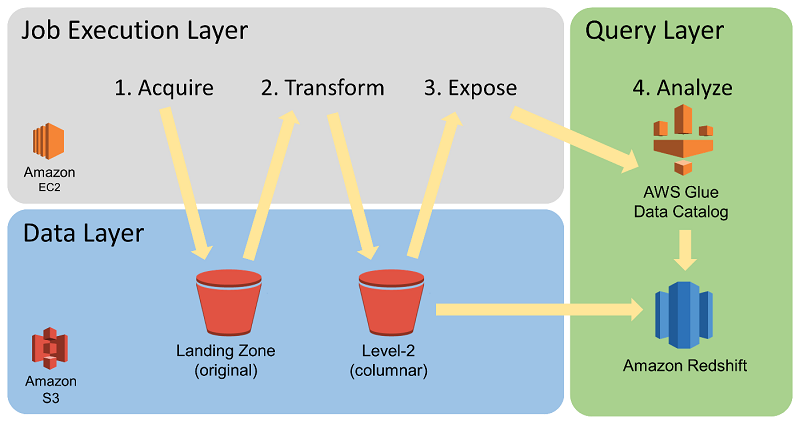
私たちのインジェストシステムは、スムーズで高速なダウンストリームデータの可用性を確保するために設計したものです。ベンダーデータフィード自体のコンテンツと、異なるベンダーのデータのプッシュ規則の両方で、ベンダーデータフィードに固有の不整合性を考慮しました。また、ベンダーが所定の時間に配信する可能性がある大容量ボリュームのデータファイルも考慮しました。以下の図は、Annalect のデータインジェストプロセスを示しています。

ベンダーからのデータを当面保持するため、Amazon S3 に 2 箇所のストレージエリアをセットアップします。ランディングゾーンは、履歴的な変更されていない raw ログファイルの長期ストレージのためのリポジトリとして機能します。私たちがベンダーから直接プルしたログファイルは、直ちにランディングゾーンに保存されます。データフィードストレージは、ベンダーがプッシュするログファイルのための一時的な保存場所として機能します。私たちは、ベンダーによってデータフィードストレージに配信されるデータファイルを、ランディングゾーンにプルするときにキュレーションし、整理します。
このプルプロセスは、自動でスケールし、多くのデータファイルを並行して処理できる EELDE のジョブ実行レイヤーで行われます。これは、データの処理と可用性において、データボリュームの突然のスパイクによる遅延が生じないことを確実にします。スパイクには、新しいベンダーからの大規模データセットをバックフィルする必要から生じるものもあれば、ベンダーが、ベンダー側の遅延後に蓄積された大量のログを配信するときに生じる場合もあります。
私たちは、ベンダーのログがプッシュされるかプルされるかにかかわらず、ランディングゾーンを監視して、ダウンストリーム分析に影響する可能性があるファイルフォーマットにおける変化、またはデータ内のギャップを検知すると、アラートを送信します。Annalect は、このアーキテクチャとプロセスが、あらゆるボリュームのデータ、そしてデータ内のあらゆる変化に素早く対応するために必要なコントロール、柔軟性、および機敏性を提供してくれると考えています。
データ変換
EELDE は、コンピューティングおよびコストの効率性に優れた方法で大容量ボリュームのイベントデータをプロセス、強化、および分析できます。この能力における重要点は、ランディングゾーンにおけるファイルの初期変換です。EELDE のジョブ実行レイヤーは、オリジナルソースデータからのコンピューティング集約型のデータ変換を並列化するために AWS Batch を使用します。このデータは通常、コンマ区切り値 (CSV) または JSON フォーマットです。AWS Batch は、データを列指向の圧縮されたストレージフォーマットである Apache Parquet に並列化します。この図では、Parquet のストレージ場所が「Level 2 (columnar)」バケットになっています。
Parquet 変換ジョブについては、AWS Batch を使用して、ローカルモードの Apache Spark で多くのコンテナを実行することで良い結果を生んできました。私たちの目標は、各ファイルのサイズが数メガバイトから数ギガバイトの範囲のファイル変換における高スループットをサポートすることです。所定の Parquet 変換には、数秒から 30 分かかる場合があります。
AWS Batch が提供するリソースの分離とジョブ管理は、何百もの独立したデータ変換ジョブの実行を容易にしてくれます。それと同時に、Amazon EMR 内で多くのタスクを同時に実行する時の課題もいくつか取り除いてくれます。一方、大規模データセットの変換には、EMR が提供できるジョブごとの並行コンピューティングが魅力的です。
以下の図は、データの変換とカタログ化を示しています。

私たちは、大規模な Parquet ベースのイベントデータテーブルを日付ごとにパーティション分割します。データのパーティション分割は、所定の分析プロセスのために必要なデータへの効率的なパスを提供することによって、クエリコストとクエリパフォーマンスの両方を最適化するために戦略的に実装されています。Parquet に変換された後、ファイルは AWS Glue Data Catalog でテーブルパーティションとして公開されます。データストレージフォーマットは変換されていますが、データはその元のフィールドを引き続き維持します。これはアドホック分析のサポートに重要です。
Parquet 変換と AWS Glue Data Catalog 管理プロセスが実行されたら、データには Redshift Spectrum を使った SQL クエリでアクセスできるようになります。Redshift Spectrum は、AWS Glue Data Catalog を使って S3 に保存された外部テーブルを参照するため、Amazon Redshift クラスターを通じてそれらをクエリできます。Parquet などのカラムナフォーマットの使用は、Redshift Spectrum を使ったクエリ実行の速度とコスト効率性を向上させます。
コンピューティング集約型のエンリッチメント
分析作業の前に、ジョブ実行レイヤーがログを強化するために他のコンピューティング集約型データ変換を行って、ログがより高度なタイプの分析をサポートできるようにする場合もあります。イベントレベルのログの組み合わせとイベント属性の拡張が 2 つの例です。
これらのエンリッチメントタスクには異なるコンピューティング要件がある場合もありますが、これらはすべて関連データセットの収集に Redshift Spectrum を使用することが可能で、収集後、ジョブ実行レイヤーで処理されます。その結果は、今回も Redshift Spectrum 経由で利用可能になります。これは、許容可能な時間枠内、かつ低コストでの大規模データセットの複雑なエンリッチメントを実現します。
アナリストのアドホッククエリ環境
Annalect の環境は、アナリストにミッションクリティカルな分析のためのデータランドスケープと SQL クエリ環境を提供します。データは EELDE 内で、アドテクノロジーベンダー、およびシステムのシートまたはアカウントごとに、個別の外部スキーマに編成されます。エージェンシーベースのアナリストとデータ科学者は、プロジェクトの必要に応じて特定のスキーマへのアクセス権が付与されます。
単一のプラットフォーム内にある様々なデータセットに対するアクセス権を持つことによって、アナリストは別個のサイロでのデータの分析では得られないユニークな洞察を得ることができます。アナリストは、データ分離要件に従いながら、特定の分析プロジェクトに使用するための新しいデータセットを、ソースベンダーの組み合わせから作成することができます。これは、予測モデリング、チャネル計画、およびマルチソース帰属などのユースケースをサポートするために役立ちます。
コストを低く保つためのベストプラクティス
この過程において、私たちは Redshift Spectrum に対するベストプラクティスをいくつか確立しました。
- 圧縮されたコラムナフォーマットを使用する。 私たちは、大規模なイベントレベルのテーブルのために Apache Parquet を使用しました。これによって、クエリの実行時間、データスキャンコスト、およびストレージコストが削減されます。私たちの大規模テーブルには通常 40~200 の列がありますが、クエリの多くは一度に 4~8 列しか使用しません。Parquet の使用は一般的に、コラムナフォーマット以外の代替手段と比較してスキャンコストを 90 パーセント以上削減します。
- テーブルをパーティション分割する。 Annalect では、イベントレベルの大規模テーブルを日付でパーティション分割し、WHERE 句にパーティション列を使用するようユーザーを訓練します。そうすることによって、クエリによって使用される日付の範囲に比例するコスト節減が提供されます。例えば、私たちが 6 ヵ月分のデータを公開し、クエリが 1 ヵ月分のデータだけを調べるとします。この場合、クエリのコストは、適切な WHERE 句を使用することによって 6 分の 1 に削減されます。
- テーブルパーティションを積極的に管理する。 私たちは、最大 36 ヵ月の履歴データを Parquet ファイルとして利用できるようにしてはいますが、デフォルトで、直近 6 ヵ月分のデータのみを外部テーブルパーティションとして公開しています。この慣行により、ユーザーがパーティション列をフィルターしないときのクエリのコストが削減されます。リクエストに応じて、6 ヵ月を超えるデータが必要となるクエリをサポートするために、必要なテーブルに古いデータパーティションを一時的に追加します。こうすることによって、必要に応じてより長い期間をサポートします。同時に、私たちは通常、一般的に必要とされる量を超えるデータを公開しないことによって、低いコスト上限を維持しています。
- 必要に応じて外部テーブルを Amazon Redshift に移動させる。 多数のクエリが同じ外部テーブルを繰り返しヒットする場合、Annalect では、クエリを行うための一時的なローカルテーブルを Amazon Redshift に作成することがよくあります。クエリの数とそれらのスコープに応じて、適切な分散キーとソートキーを使ってローカル Amazon Redshift テーブルにデータをロードすることが役立つ場合があります。この慣行は、反復的な Redshift Spectrum スキャンコストを排除するために役立ちます。
- WLM ルール「spectrum_scan_size_mb」を使用する。 Annalect のユーザーとジョブのほとんどは、デフォルト WLM キューに WLM ルール「spectrum_scan_size_mb」を設定することによって、1 テラバイトの有効な Redshift Spectrum データスキャン上限で作業を行います。単一の分析またはモデリングのクエリでは、この上限を超える必要が生じることはめったにありません。
- 必要に応じてクラスターを追加して同時実行性を向上させる。S3 内の同じテーブルには、複数の Amazon Redshift クラスターがアクセスできます。多数のユーザーが外部テーブルに対して同時にクエリを実行している場合、より多くのクラスターの追加を選択することがあります。Redshift Spectrum と、Annalect が独自の環境用に作成した管理ツールは、このタスクを容易にしてくれます。
- 短期間の Amazon Redshift クラスター を使用する。 スケジュールされた本番ジョブの一部には、外部スキーマを通じて必要なデータを利用できる、短期間の Amazon Redshift クラスターを使用します。Redshift Spectrum は長時間にわたるデータのロードを回避できるようにしてくれるため、毎日作業する数時間 Amazon Redshift クラスターを起動して、その後終了することが実用的です。こうすることによって、プロジェクトのために常時オンのクラスターを用意することに比べて、80~90 パーセントのコスト節約が可能になります。また、短期間のクラスターはプロジェクト専用になるため、他のクエリアクティビティとの競合も避けることができます。
まとめ
Annalect では、ストレージ用の Amazon S3と、分析用の Redshift Spectrum を使用したデータウェアハウス戦略を確立することによって、サポートするデータセットのサイズを大幅に増加させました。それに加えて、コストを増加させることなく、大容量ボリュームのデータを素早く取り込み、高速パフォーマンスを維持する能力も向上させました。私たちのアナリストとモデラーは、広告購入戦略と成果を向上させるために、より掘り下げた分析を行うことができるようになりました。
その他の参考資料
この記事が役に立つと思われる場合は、Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production と How I built a data warehouse using Amazon Redshift and AWS services in record time も併せてお読みください。
今回のブログ投稿者について
 Eric Kamm 氏は Annalect 社のシニアエンジニア/アーキテクトです。Eric は、20 年以上にわたって大規模な ETL ワークフローを管理し、アナリストとモデラーのチームのためにデータとコンピューティング環境を提供してきており、信頼性と運用効率性を高めながら、プロジェクトの計画と実装を迅速化することができるクラウドテクノロジーを使った仕事を楽しんでいます。
Eric Kamm 氏は Annalect 社のシニアエンジニア/アーキテクトです。Eric は、20 年以上にわたって大規模な ETL ワークフローを管理し、アナリストとモデラーのチームのためにデータとコンピューティング環境を提供してきており、信頼性と運用効率性を高めながら、プロジェクトの計画と実装を迅速化することができるクラウドテクノロジーを使った仕事を楽しんでいます。