Amazon Web Services ブログ
Amazon OpenSearch Service のセマンティック検索で注文履歴検索を改善する
本記事は 2026 年 2 月 26 日 に公開された「Improving order history search using semantic search with Amazon OpenSearch Service」を翻訳したものです。
Amazon で買い物をしたことがあれば、注文履歴を使ったことがあるでしょう。この機能は 1995 年まで遡る注文履歴を保持しており、すべての購入を追跡・管理できます。注文履歴の検索機能では、検索バーにキーワードを入力して過去の購入品を見つけられます。商品を見つけるだけでなく、同じ商品や類似商品を簡単に再購入でき、時間と手間を節約できます。
Rufus や Alexa など、Amazon のショッピング体験を支えるさまざまな機能が注文履歴検索を活用し、過去の購入品を見つける手助けをしています。そのため、注文履歴検索には過去の購入品をできるだけ正確かつ迅速に見つける能力が求められます。
本記事では、Your Orders チームが Amazon OpenSearch Service と Amazon SageMaker を使い、既存のレキシカル検索システムにセマンティック検索機能を導入して注文履歴検索を改善した方法を紹介します。
レキシカル検索の限界
注文履歴検索では、レキシカルマッチングを使って、検索キーワードの少なくとも 1 つの単語に一致する商品を顧客の注文履歴全体から取得しています。たとえば「orange juice」と検索すると、オレンジジュースだけでなく、過去に注文した生のオレンジや他のフルーツジュースも取得されます。レキシカルマッチングは検索キーワードに正確に一致する商品の再現率は高いものの、この例の「health drinks」のような関連キーワードや汎用的なキーワードではうまく機能しません。
Amazon の AI ショッピングアシスタント Rufus の登場以来、効率的で充実したショッピング体験を求める顧客が増え、Rufus で過去の購入品を検索するケースも増えています。「Show me healthy drinks」のように、「kombucha」「green tea」「protein shakes」といった長く正確な用語を気にせず検索できるようになりました。検索体験が会話的で意図ベースになり、商品をより直感的に見つけられるようになっています。Rufus が「Show me the healthy drinks I bought last year」のような注文履歴検索に同じ直感的な体験で応えるには、基盤となる注文履歴データストア (Your Orders) に、従来のレキシカルマッチングを超えて検索キーワードの意味を理解するセマンティック検索機能が必要です。
セマンティック検索の実装における課題
この規模でセマンティック検索を実装するにあたり、次の技術的課題がありました。
- スケール – 世界中の顧客の注文履歴に対応する数十億件のレコードでセマンティック検索を有効にする必要がありました。
- ゼロダウンタイム – バックエンドでセマンティック検索を導入する変更を行う間も、システムの可用性を 100% 維持する必要がありました。
- 検索品質の低下防止 – セマンティック検索は検索品質の向上が目的ですが、逆効果になるケースもあります。たとえば、顧客が商品名を正確に覚えていてその名前に一致する商品だけを見つけたい場合、類似商品も表示すると結果が混雑し、目的の商品を見つけにくくなります。同様に、注文 ID のように固有の意味を持たない識別子で検索する場合、セマンティック検索は機能しません。このようなシナリオではレキシカル検索のみを使用します。
ソリューション概要
セマンティック検索は大規模言語モデル (LLM) を基盤としています。LLM は主に人間の言語で学習されており、学習済みの言語のテキストを受け取り、入力テキストの長さに関係なく固定長のエンベディングベクトルを出力するように適応できます。エンベディングベクトルは入力テキストの意味を捉えるよう設計されており、意味的に類似した 2 つのテキストは、それぞれのエンベディングベクトルのコサイン類似度が高くなります。注文履歴のセマンティック検索では、エンベディング生成と類似度計算の対象となる入力テキストは、顧客の検索フレーズと購入済み商品の商品テキストです。
ソリューションは 2 つのパートに分かれます。
- 大規模リクエスト処理に向けたスケーラビリティとレジリエンシーの向上 – セマンティック検索を実装する前に、増加する計算負荷に対応できるインフラストラクチャを確保する必要があり、セルベースアーキテクチャを採用しました。すべてのユースケースで必要ではありませんが、リクエスト量やデータ量が非常に大きいシステムでは、セマンティック検索のようなリソース集約型機能の実装前に大きな効果を発揮します。
- セマンティック検索の実装 – まず利用可能なエンベディングモデルを評価し、Amazon Bedrock のオフライン評価機能でさまざまなモデルをテストしました。モデルを選定した後、エンベディングベクトル生成のインフラストラクチャを構築しました。
システムのスケーラビリティとレジリエンシーの向上
スケーラビリティとレジリエンシーの向上には、セルベースアーキテクチャの設計パターンを採用しました。セルベースの設計では、システムを同一の小さな自己完結型のチャンク (セル) に分割し、各セルがシステム全体のトラフィックの一部のみを処理します。次の図は、注文履歴検索のセルベース設計の概要を示しています。
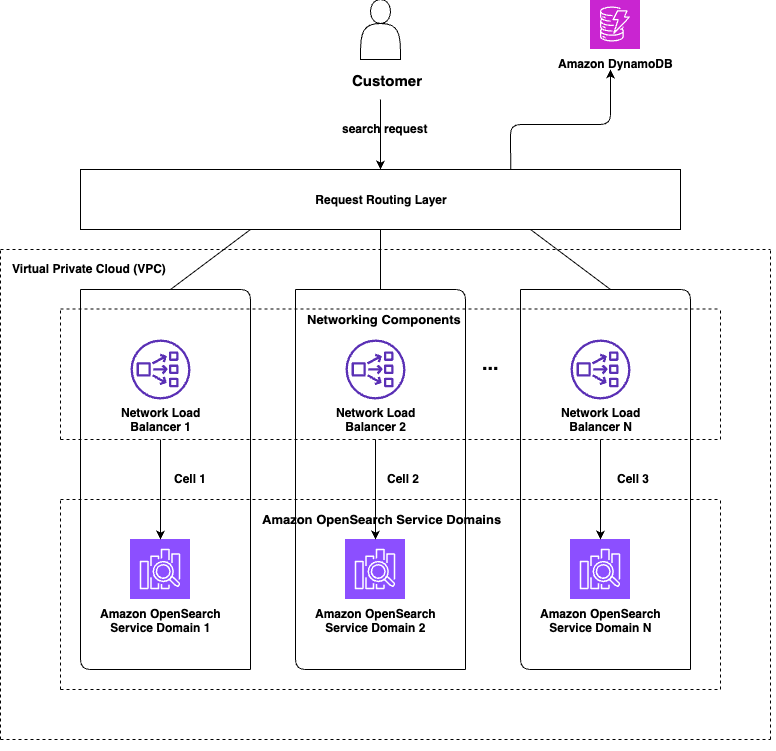
各セルは定義された顧客のサブセットを担当します。セル間で顧客リクエストを処理するための通信は不要です。各顧客はセルに割り当てられ、その顧客からのリクエストはすべて該当セルにルーティングされます。各セルの OpenSearch Service ドメインは、担当する顧客のサブセットのデータのみを保持します。セル数 (N) とセル間のデータ分散はビジネスユースケースに依存しますが、データとトラフィックをできるだけ均等に分散させることが目標です。
ルーティングロジックはユースケースに応じてシンプルにも高度にもできます。セル割り当て値はリクエストごとにランタイムで計算するか、一度計算して Amazon DynamoDB などのキャッシュや永続データストアに書き込み、以降のリクエストで参照する方法があります。注文履歴検索では、ロジックがシンプルで高速だったため、リクエストごとにランタイムで実行しました。永続データストアからセル割り当てを参照する方法は、一部のセルが時間とともに「重く」なるリスクがある場合に特に有効です。その場合、パーティショニングロジックを変更する代わりに、データストア内の特定キーのセル割り当て値を上書きするだけで、重いセルのデータを再分散できます。パーティショニングロジックの変更はすべてのセルのデータ分散に影響する可能性があります。
システムの負荷が増加した場合、セル数を増やして追加トラフィックに対応できます。セル数を増やさなくても、負荷の高いセルから軽いセルにキーを再割り当てすることで、既存の N セル間でデータを再分散し、負荷をより均等に分散させてインフラストラクチャをより効率的に活用できます。
セルベースアーキテクチャはシステムのレジリエンシー向上にも役立ちます。たとえば、1 つのセルが失われた場合、キャパシティの低下は 100% ではなく 1/N にとどまります。さらに、パーティショニングキーを 2 つ以上のセルに割り当てて複数のセルに書き込むことで、キャパシティ低下をさらに抑えられます。この場合、単一セルの喪失がデータ損失につながることはありません。
セマンティック検索の実装
注文履歴検索にセマンティック検索を実装するには、いくつかの重要な判断と技術的ステップが必要でした。まず利用可能なエンベディングモデルを評価し、Amazon Bedrock のオフライン評価機能でさまざまなモデルをビジネスドメインの要件に照らしてテストしました。この評価でユースケースに最適なモデルを特定し、選定後にエンベディングベクトル生成のインフラストラクチャを構築しました。エンベディングモデルをコンテナ化して Amazon Elastic Container Registry (Amazon ECR) に登録し、SageMaker 推論エンドポイントにデプロイして大規模なベクトル計算を処理しました。
検索インフラストラクチャには、セマンティック検索機能の実装に OpenSearch Service を選択しました。OpenSearch Service は、必要なベクトルストレージと、ユーザーに関連性の高い結果を提供する検索アルゴリズムの両方を備えていました。
最大の課題の 1 つは、既存の注文でセマンティック検索をサポートするために過去のデータを更新することでした。AWS Step Functions でワークフローをオーケストレーションし、AWS Lambda 関数でレガシーデータのベクトル生成を処理するデータ処理パイプラインを構築し、対象のすべてのレコードでセマンティック検索を提供できるようにしました。
次の図は、アーキテクチャの概要を示しています。
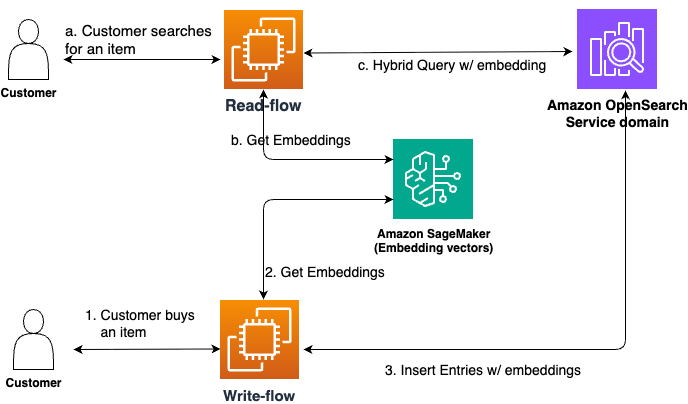
モデルの評価と選定
注文履歴検索では、Amazon 固有のデータで学習されたエンベディングモデルを使用しています。ドメイン固有の学習は、生成されるエンベディングベクトルがビジネスコンテキストで適切に機能し、質の高い結果を返すために不可欠です。
候補モデルの評価には、Amazon Bedrock 上の Anthropic Claude を使った LLM-as-a-judge 手法を採用しました。Anthropic Claude に、顧客の注文履歴から匿名化された商品テキストと検索フレーズを含むプロンプトを与え、関連性に基づいて商品をフィルタリングおよびランク付けしました。この結果を比較用のグラウンドトゥルースとして使用しました。
モデルの評価には標準的なランキング指標を使用しました。
- Normalized Discounted Cumulative Gain (NDCG) – 理想的な順序に対するランキング品質を測定
- Mean Reciprocal Rank (MRR) – 最初の関連アイテムの位置を考慮
- Precision – 取得結果の精度を評価
- Recall – すべての関連アイテムを取得する能力を評価
このプロセスにより最適なモデルを決定しました。
検索戦略: 顧客スコープの包括的検索
注文履歴検索には 2 つの重要な要件があります。
- リクエスト元の顧客の注文履歴のみを検索する – ある顧客の注文履歴の商品が別の顧客の検索結果に表示されてはなりません。
- その顧客の履歴をすべて検索する – 検索アルゴリズムが何らかの理由で評価しなかったために、顧客の検索フレーズに関連する商品が表示されないことがあってはなりません。
このアプローチでは、OpenSearch Service を使って検索クエリを発行した顧客のすべての商品を取得し、検索フレーズに対する各商品の関連性スコアを計算し、スコア順にソートして上位 K 件の結果を返します。各顧客に対して包括的な結果カバレッジを提供します。
OpenSearch Service によるベクトルストレージ
効率的なベクトルストレージと検索のために、OpenSearch Service の 2 つの機能を使用しました。
- knn_vector データ型 – エンベディングベクトルを格納するための組み込みサポート。既存のドメインでもインデックスの再作成なしにこのフィールド型を追加でき、すべてのレコードに対する正確な kNN 検索が可能です。ほとんどの顧客のレコード数は正確な kNN でスケールできる範囲だったため、近似 kNN は不要でした。
- スクリプトスコアリング – Painless スクリプトがサーバーサイドでベクトル類似度を計算し、クライアントの複雑さを軽減しつつ低レイテンシーを維持します。
ハイブリッド検索
ハイブリッド検索とは、レキシカル検索とセマンティック検索の結果を組み合わせ、それぞれの強みを活かすことです。OpenSearch Service のハイブリッドクエリ機能により、クライアントは単一のリクエストで両方のクエリタイプを指定でき、ハイブリッド検索の実装が簡素化されます。OpenSearch Service は両方のクエリを並列実行し、結果をマージし、サブクエリの関連性スコアを正規化し、指定されたソート順 (デフォルトは関連性スコア) で結果をソートしてからクライアントに返します。
両方の検索タイプの利点を活用できます。たとえば、顧客が orderId で検索する場合のように、検索フレーズに意味的な意味があまりないシナリオがあります。セマンティック検索はこのようなケースには適しておらず、キーワードマッチングが最適です。
ハイブリッド検索機能により、注文履歴検索の実装工数と潜在的なレイテンシー増加を抑えられました。
過去のデータの更新
インフラストラクチャのセットアップ後、新しく取り込まれるレコードは関連するエンベディングベクトルとともに永続化され、セマンティック検索をサポートします。しかし、顧客が検索する際は通常、以前に購入した商品を検索します。そのため、古いレコードにエンベディングがなければ、顧客体験の改善にはつながりません。バックフィルの方法はデータ規模に依存します。
潜在的な顧客影響を最小化するリリース
最後のステップは、問題発生時の影響を最小限に抑えながらクライアントに変更をリリースすることでした。具体的には以下の方法を採用しました。
- セマンティック検索フローで一時的な問題が発生した場合、リクエスト全体を失敗させるのではなく、レキシカルのみの検索にフォールバックするよう実装する。セマンティック検索が実行されなくても、空の結果ではなくレキシカル検索の結果をクライアントに返せるようにする。
- デフォルトの動作をレキシカルのみの検索とし、セマンティック検索機能が必要なクライアントはリクエストに追加フラグを渡す必要があるようにゲーティングする。これにより、該当リクエストのみでセマンティックまたはハイブリッドフローが実行される。
- 初期期間中は新しいフローをフィーチャーフラグの背後に配置し、重大な問題が検出された場合に完全にオフにできるようにする。
顧客体験の改善例
Rufus が注文履歴を照会して顧客の質問に答えた例を紹介します。
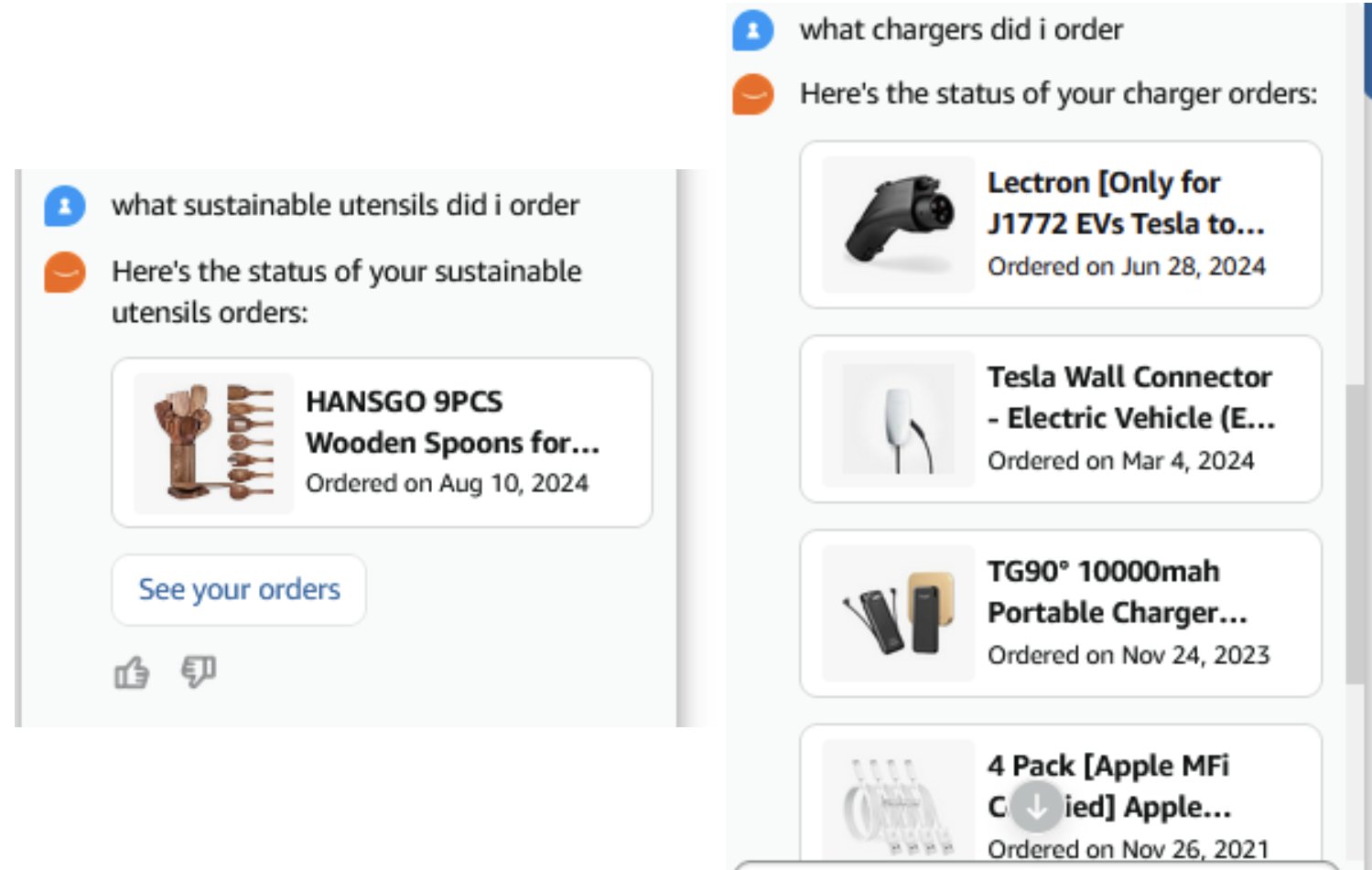
次のスクリーンショットは、「sustainable utensils」のクエリで木製スプーンが検出される例と、タイトルの説明に「charger」というキーワードがないウォールコネクターを含むさまざまな種類の充電器が検出される例を示しています。
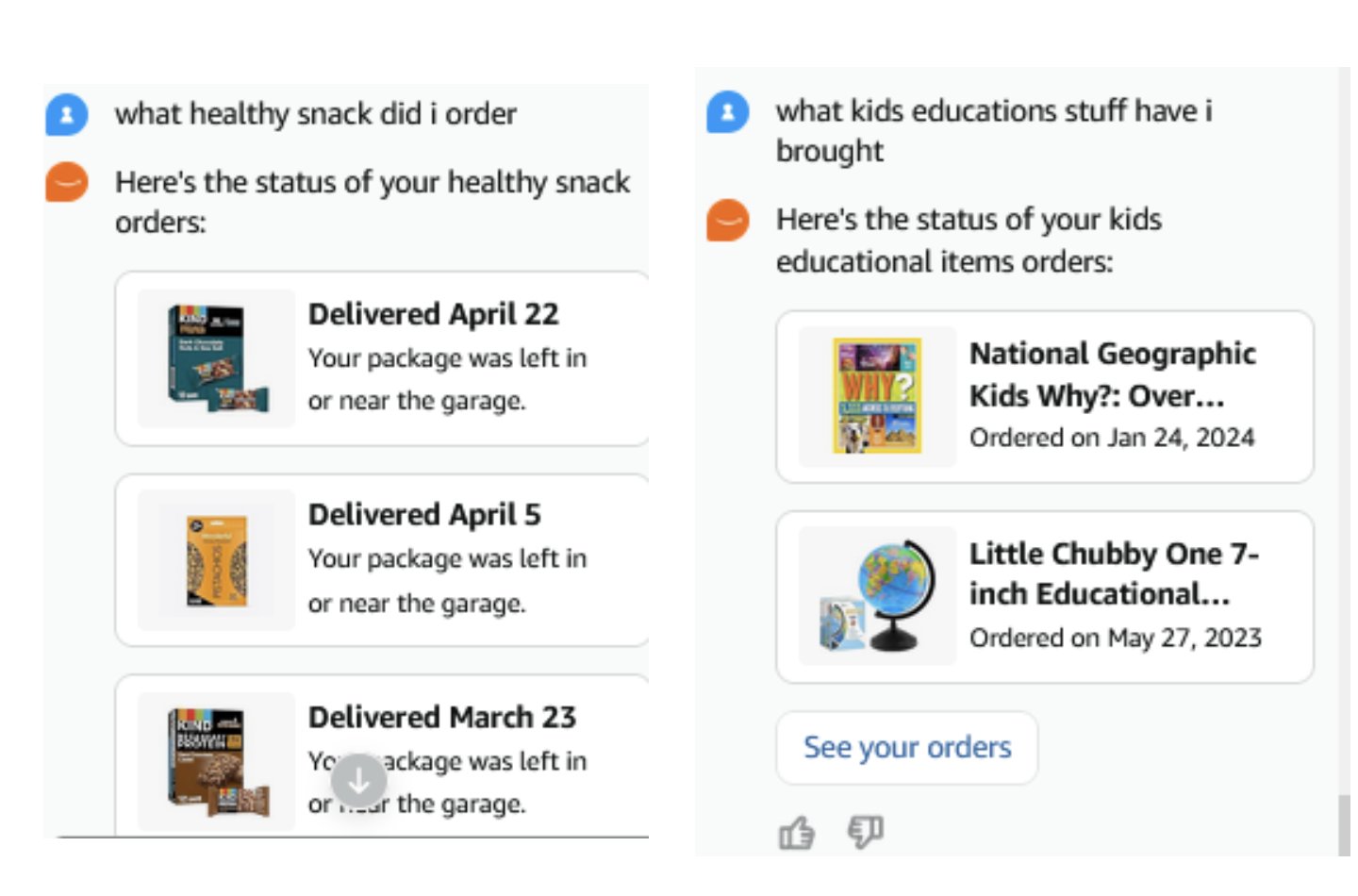
次のスクリーンショットは、タイトルの説明にクエリキーワードが含まれていなくても、セマンティック検索が関連する結果を検出する例を示しています。
セマンティック検索機能の導入により、Rufus が関連商品を取得して顧客に表示できるようになりました。導入前は、こうしたクエリに対して結果を返せませんでした。
ビジネスへの影響
主なビジネス成果は以下のとおりです。
- 顧客体験の改善 – クエリの再現率が 10% 向上し、関連する結果を返す検索の割合が増加しました。また、過去の注文の検索に関するカスタマーサービスへの問い合わせも減少しました。
- パートナー連携の成功 – Alexa と Rufus の自然言語処理能力が強化され、注文履歴クエリの解釈精度が向上しました。パートナーチームによるリランキングや後処理の必要性も軽減されました。クエリ成功率は 20% 向上し、より多くの顧客検索が少なくとも 1 つの関連商品を返すようになりました。また、結果カバレッジが 48% 向上し、レキシカル検索では見逃されていた関連する一致をセマンティック検索が一貫して検出するようになりました。
まとめ
本記事では、Amazon の注文履歴検索をセマンティック検索機能に対応させた方法を紹介しました。既存インフラストラクチャの制約の中で最先端の AI 技術を活用し、機能アップグレード中もサービスの中断を回避して SLA を維持するソリューションを開発しました。実装にはバックフィルも含まれ、通常の取り込み速度の数倍のレートで数十億のドキュメントを処理し、過去に購入された商品のエンベディングベクトルを計算しました。慎重なエンジニアリングが求められましたが、極端な負荷下でも OpenSearch Service のレジリエンシーを活用して対応しました。
この基盤を活かして、検索技術を継続的に進化させられます。エンベディングベクトルのフレームワークに改良モデルを組み込めるほか、パーソナライゼーションやマルチモーダル検索など新機能への拡張にも対応できます。
Exact k-NN search の手順に従って、正確な k-NN 検索を今すぐ始められます。OpenSearch クラスターのマネージドソリューションをお探しの場合は、Amazon OpenSearch Service をご確認ください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。