Amazon Web Services ブログ
MLflow と Amazon SageMaker による機械学習のライフサイクル管理
機械学習(ML) や MLOps の急速な普及に伴い、企業は ML プロジェクトの実験から本番までの速度を高めたいと考えています。
MLプロジェクトの初期段階では、データサイエンティストは、ビジネスニーズに対するソリューションを見つけるために、共同で実験結果を共有します。運用フェーズでは、本番に向けたさまざまなモデルのバージョンや、ライフサイクルの管理も必要です。この記事では、オープンソースのプラットフォームである MLflow がどのようにこれらの問題に対処しているかをご紹介します。完全に管理されたソリューションに興味のある方のために、Amazon Web Services は最近、re:Invent 2020で、機械学習のための初めての、継続的統合および継続的配信(CI/CD)サービスである Amazon SageMaker Pipelines を発表しました。SageMaker Pipelines については、こちらの記事で詳しくご紹介しています。
MLflowは、実験や、再現性、デプロイメント、モデルレジストリなど、MLのライフサイクルを管理するためのオープンソースのプラットフォームです。以下のコンポーネントが含まれています。
- トラッキング – 実験の記録と照会:コード、データ、構成、結果
- プロジェクト – データサイエンスのコードを、あらゆるプラットフォームでの実行を再現できる形式でパッケージ化
- モデル – MLモデルを多様なサービス環境に展開
- レジストリ – 中央のリポジトリでモデルの保存、アノテーション、発見、管理
次の図は、アーキテクチャを示しています。

次のセクションでは、AWS Fargate に MLflow をデプロイし、Amazon SageMaker を使ったMLプロジェクト中に MLflow を使用する方法を紹介します。SageMaker を使用して、Boston House Pricesデータセットを使用したScikit-learnベースの ML モデル(ランダムフォレスト)の開発、学習、チューニング、デプロイを行います。MLワークフローにおいて、MLflow で実験管理とモデルの追跡を行います。
SageMakerは、開発者やデータサイエンティストがMLモデルの迅速な構築、学習、デプロイを支援するフルマネージドサービスです。SageMakerは、MLプロセスの各ステップから重い作業を取り除き、高品質のモデルを簡単に開発することができます。
実行手順の概要
この記事では、以下の方法を示しています。
- サーバーレスの MLflow サーバーを Fargate 上でホストする
- Amazon Simple Storage Service(Amazon S3)と Amazon Relational Database Service(Amazon RDS)をそれぞれアーティファクトストアとバックエンドストアとして設定する
- SageMaker で行われている実験を MLflow で追跡する
- SageMaker で学習したモデルを MLflow Model Registry に登録する
- MLflow モデルを SageMaker のエンドポイントにデプロイする
実行手順の詳細は、GitHub repo で公開されています。
アーキテクチャの概要
MLプロジェクトでは、中心となる MLflow Trackingサーバーを設定することができます。このリモート MLflow サーバーを使って、実験やモデルを共同で管理します。このセクションでは、MLflow Tracking サーバーを Docker 化し、Fargate 上でホストする方法を紹介します。
また、MLflow Tracking サーバーには、バックエンドストアとアーティファクトストアという2つのストレージ用コンポーネントがあります。
アーティファクトストアとしてS3バケットを、バックエンドストアとして Amazon RDS for MySQL インスタンスを使用しています。
次の図は、このアーキテクチャを示しています。

pip install mlflow で MLflow をインストールし、mlflow server コマンドで Tracking サーバーを起動します。
デフォルトでは、サーバーは5000番ポートで動作しているので、コンテナ内で公開します。他のマシンからトラッキングサーバにアクセスしたい場合は、0.0.0.0を使ってすべてのアドレスにバインドします。MLflow サーバーが S3 バケットと RDS for MySQL データベースと通信するために、boto3 と pymysql の依存関係をインストールします。以下のコードをご覧ください。
Fargate で MLflow のトラッキングサーバーをホスティング
このセクションでは、Fargate でホストされている Docker コンテナ上で MLflow Tracking サーバーを実行する方法を紹介します。
Fargateは、AWS 上でコンテナを展開するための簡単な方法です。これにより、基礎となるインスタンスを管理することなく、コンテナを基本的なコンピュートプリミティブとして使用することができます。必要なのは、デプロイするイメージと、それに必要なCPUとメモリの量を指定することだけです。Fargateは、基盤となるLinux OS、Dockerデーモン、Amazon Elastic Container Service(Amazon ECS)エージェントの更新やセキュリティの確保、インフラの容量管理やスケーリングなどをすべて行います。
Fargate でのアプリケーションの実行については、Building, deploying, and operating containerized applications with AWS Fargate を参照してください。
MLflow コンテナは、まずビルドして Amazon Elastic Container Registry(Amazon ECR)のリポジトリにプッシュする必要があります。コンテナイメージの URI は、私たちの Amazon ECS タスク定義の登録時に使用されます。ECS タスクには、AWS Identity and Access Management(IAM)ロールが添付されており、Amazon S3 などの AWS サービスとのやり取りが可能になります。
次のスクリーンショットは、私たちのタスク構成を示しています。

Fargateサービスにはオートスケーリングとネットワークロードバランサーが設定されているので、私たち側の最小限のメンテナンス作業で必要な計算負荷に調整することができます。
MLプロジェクトを実行する際には、mlflow.set_tracking_uri(<load balancer uri>) を設定し、ロードバランサーを介して MLflow サーバーとやりとりするようにしています。
Amazon S3 をアーティファクトストアとして、Amazon RDS for MySQL をバックエンドストアとして使用する
アーティファクトストアは、大きなデータ(S3バケットや共有NFSファイルシステムなど)に適しており、クライアントがアーティファクトの出力(例えば、モデル)を記録する場所です。MLflow はアーティファクトストアとして Amazon S3 をネイティブにサポートしており、—default-artifact-root ${BUCKET} を使うことで任意のS3バケットを参照することができます。
バックエンドストアは、MLflow Tracking サーバーが実験のメタデータやパラメータ、メトリックス、タグなどを保存する場所です。MLflowでは、ファイルストアとデータベースバックアップストアの2種類のバックエンドストアをサポートしています。メタデータの保存には、外部のデータベースバックドストアを使うのが良いでしょう。
この記事を書いている時点では、MySQL、SQLite、PostgreSQL などのデータベースを MLflow のバックエンドストアとして使用することができます。詳しくは、バックエンドストアをご覧ください。Amazon Aurora は、MySQL や PostgreSQL と互換性のあるリレーショナルデータベースであり、これも使用することができます。
この例では、RDS for MySQLインスタンスをセットアップしました。Amazon RDSは、クラウド上での MySQL のセットアップ、運用、拡張を容易にします。Amazon RDS を使用すると、コスト効率が高くサイズ変更可能なハードウェア容量で、スケーラブルな MySQL サーバーを数分で展開できます。
また、--backend-store-uri mysql+pymysql://${USERNAME}:${PASSWORD}@${HOST}:${PORT}/${DATABASE} を使って、MLflow を任意の MySQL データベースに参照することができます。
MLflow スタックの起動
MLflowスタックを起動するには、以下の手順で行います。
- GitHubのレポで提供されている AWS CloudFormation スタックを起動します
- Nextを選択します
- 最終画面になるまで、すべてのオプションをデフォルトのままにしておきます
- I acknowledge that AWS CloudFormation may create IAM resources.を選択します
- Createを選択します
スタックは数分で Fargate 上の MLflow サーバーを起動し、S3バケットとRDS上のMySQLデータベースを使用します。ロードバランサーの URI は、スタックの「Outputs」タブで確認できます。

そして、ロードバランサーの URI を使って MLflow の UI にアクセスすることができます。
このサンプルのスタックでは、ロードバランサーはパブリックサブネット上で起動し、インターネットに公開されています。
セキュリティ上の理由から、外部からの直接の接続がないVPCのプライベートサブネットに内部ロードバランサーをプロビジョニングしたい場合があります。詳細については、Access Private applications on AWS Fargate using Amazon API Gateway PrivateLink を参照してください。
これで、ロードバランサーのURIを介して REST API でアクセスできる、リモートの MLflow Tracking サーバーが稼働しました。
SageMaker でML プロジェクトを実行する際に、MLflow Tracking APIを使ってパラメータ、メトリクス、モデルのログを取ることができます。そのためには、SageMaker上でコードを実行する際にMLflowライブラリをインストールし、リモートトラッキングURIにロードバランサーのアドレスを設定する必要があります。
以下の Python API コマンドは、SageMaker 上で実行されているコードを MLflow リモートサーバーに向けることができます。
import mlflow
mlflow.set_tracking_uri('YOUR LOAD BALANCER URI')
SageMakerとMLflowでMLのライフサイクルを管理
GitHub repo にあるノートブックを実行することで、このサンプルラボに従うことができます。
このセクションでは、SageMaker Python SDK で Scikit-learn を使用して、ランダムフォレストモデルを開発、トレーニング、チューニング、デプロイする方法を説明します。ここでは、Scikit-learn で提供されている Boston Housing データセットを使用し、MLflow で ML の実行を記録しています。
SageMaker でカスタムの Scikit-learn スクリプトを使用することについての詳細は、SageMaker Examples GitHub repoでサンプルコードを確認することができます。
実験の作成とML実行の追跡
このプロジェクトでは、boston-houseという名前のMLflow実験を作成し、SageMakerでモデルのトレーニングジョブを起動します。SageMakerでトレーニングジョブを実行するたびに、Scikit-learnスクリプトはMLflowに新しい実行を記録し、入力パラメータ、メトリクス、生成されたランダムフォレストモデルを追跡します。
以下のAPIコールによって、MLflow での実験管理の開始および管理をすることができます。
- start_run() – 新しいMLflowランを開始し、メトリクスやパラメータが記録されるアクティブなランとして設定する
- log_params() – 現在のランの下でパラメータを記録する
- log_metric() – 現在の実行の下で、メトリックを記録する
- sklearn.log_model() – 現在の実行で、Scikit-learnモデルをMLflowアーティファクトとしてログに記録する
コマンドの完全なリストについては、MLflow Tracking を参照してください。
次のコードは、これらのAPIコールをtrain.pyスクリプトで使用する方法を示しています。
# set remote mlflow server
mlflow.set_tracking_uri(args.tracking_uri)
mlflow.set_experiment(args.experiment_name)
with mlflow.start_run():
params = {
"n-estimators": args.n_estimators,
"min-samples-leaf": args.min_samples_leaf,
"features": args.features
}
mlflow.log_params(params)
# TRAIN
logging.info('training model')
model = RandomForestRegressor(
n_estimators=args.n_estimators,
min_samples_leaf=args.min_samples_leaf,
n_jobs=-1
)
model.fit(X_train, y_train)
# ABS ERROR AND LOG COUPLE PERF METRICS
logging.info('evaluating model')
abs_err = np.abs(model.predict(X_test) - y_test)
for q in [10, 50, 90]:
logging.info(f'AE-at-{q}th-percentile: {np.percentile(a=abs_err, q=q)}')
mlflow.log_metric(f'AE-at-{str(q)}th-percentile', np.percentile(a=abs_err, q=q))
# SAVE MODEL
logging.info('saving model in MLflow')
mlflow.sklearn.log_model(model, "model")train.pyスクリプトで、実行のログを取るためにどの MLflow tracking_uri と experiment_name を使うかを設定する必要があります。これらの値は、SageMaker のトレーニングジョブのハイパーパラメータを使ってスクリプトに渡すことができます。以下のコードを参照してください。
# uri of your remote mlflow server
tracking_uri = '<YOUR LOAD BALANCER URI>'
experiment_name = 'boston-house'
hyperparameters = {
'tracking_uri': tracking_uri,'experiment_name': experiment_name,'n-estimators': 100,'min-samples-leaf': 3,'features': 'CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT','target': 'target'
}
estimator = SKLearn(
entry_point='train.py',
source_dir='source_dir',
role=role,
metric_definitions=metric_definitions,
hyperparameters=hyperparameters,
train_instance_count=1,
train_instance_type='local',
framework_version='0.23-1',
base_job_name='mlflow-rf',)SageMakerによるモデルの自動チューニングとMLflowによるトラッキングの実行
SageMaker の自動モデルチューニングは、ハイパーパラメータ最適化(HPO)としても知られており、指定されたアルゴリズムとハイパーパラメータの範囲を使用して、データセット上で多くのトレーニングジョブを実行することにより、モデルのベストバージョンを見つけます。そして、選択した指標で測定した結果、最高のパフォーマンスを発揮するモデルになるハイパーパラメータ値を選択します。
2_track_experiments_hpo.ipynb サンプルノートブックでは、SageMaker のチューニングジョブを起動し、そのトレーニングジョブを MLflow でトラッキングする方法を紹介しています。単一のトレーニングジョブで使用されているのと同じtrain.pyスクリプトとデータを使用しているので、最小限の労力で MLflow モデルのハイパーパラメータ検索を加速することができます。
SageMaker のジョブが完了すると、MLflow の UI に移動し、異なる学習の結果を比較することができます(次のスクリーンショットを参照)。
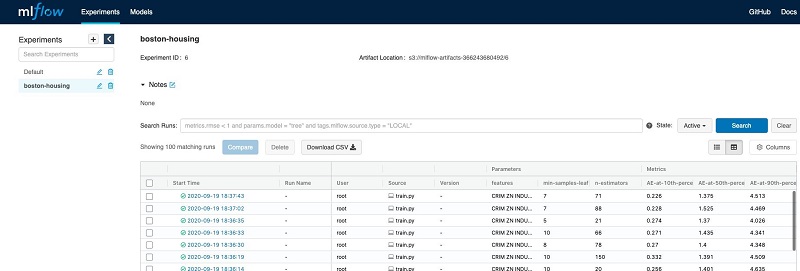
これは、開発チーム内のコラボレーションを促進するのに役立ちます。
MLflow Model Registry コンポーネントを使用すると、ユーザーとチームが共同でモデルのライフサイクルを管理することができます。SageMaker のトレーニングジョブで作成されたモデルを、UI や API を通じてモデルレジストリに追加、修正、更新、移行、削除することができます。

モデルが登録されると、モデルページに移動して、そのモデルの特徴を確認することができます。

このセクションでは、MLflow が提供する mlflow.sagemaker モジュールを使って、モデルを SageMaker が管理するエンドポイントにデプロイする方法を紹介します。この記事を書いている時点では、MLflow は SageMakerエンドポイントへのデプロイのみをサポートしていますが、Amazon S3 アーティファクトストアのモデルバイナリを使用して、デプロイシナリオに合わせることができます。
次に、推論コードを含む Docker コンテナを構築し、Amazon ECR にプッシュする必要があります。
自分でイメージを構築することもできますし、mlflow sagemaker build-and-push-container コマンドを使って MLflow にイメージを作成してもらうこともできます。これは、ローカルにイメージを構築し、mlflow-pyfuncというAmazon ECRリポジトリにプッシュします。
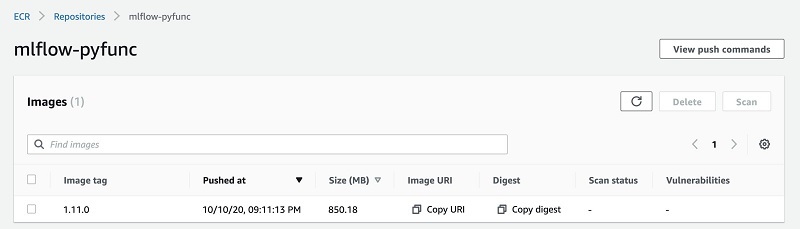
以下のサンプルコードでは、mlflow.sagemaker.deploy を使ってモデルをSageMakerのエンドポイントにデプロイする方法を示しています。
# URL of the ECR-hosted Docker image the model should be deployed into
image_uri = '<YOUR mlflow-pyfunc ECR IMAGE URI>'
endpoint_name = 'boston-housing'
# The location, in URI format, of the MLflow model to deploy to SageMaker.
model_uri = '<YOUR MLFLOW MODEL LOCATION>'
mlflow.sagemaker.deploy(
mode='create',
app_name=endpoint_name,
model_uri=model_uri,
image_url=image_uri,
execution_role_arn=role,
instance_type='ml.m5.xlarge',
instance_count=1,
region_name=region
)このコマンドを実行すると、アカウントに SageMaker のエンドポイントが起動し、以下のコードを使ってリアルタイムに予測を行うことができます。
# URL of the ECR-hosted Docker image the model should be deployed into
image_uri = '<YOUR mlflow-pyfunc ECR IMAGE URI>'
endpoint_name = 'boston-housing'
# The location, in URI format, of the MLflow model to deploy to SageMaker.
model_uri = '<YOUR MLFLOW MODEL LOCATION>'
mlflow.sagemaker.deploy(
mode='create',
app_name=endpoint_name,
model_uri=model_uri,
image_url=image_uri,
execution_role_arn=role,
instance_type='ml.m5.xlarge',
instance_count=1,
region_name=region
)現在のユーザーアクセス制御の制限
現時点では、オープンソース版の MLflow は、MLflow サーバーに複数のテナントが存在する場合のユーザーアクセス制御機能を提供していません。つまり、サーバーにアクセスできるユーザーであれば、実験やモデルのバージョン、ステージなどを変更することができます。これは、監査目的で強力なモデルガバナンスを維持する必要がある規制された業界の企業にとっては課題となります。
まとめ
この記事では、Fargate、Amazon S3、Amazon RDS を使用して、AWS 上でオープンソースのMLflow サーバーをホストする方法を説明しました。そして、SageMaker のトレーニングやチューニングジョブを MLflow でトラッキングし、MLflow Model Registry でモデルのバージョンを管理し、MLflow モデルを SageMaker のエンドポイントにデプロイして予測を行うという ML プロジェクトのライフサイクルの例を紹介しました。このソリューションをお試しになりたい方は、GitHub repo にアクセスしてください。また、ご質問があれば、コメントでお知らせください。
翻訳は SA 上総が担当しました。原文はこちらをご覧ください。