Amazon Web Services ブログ
テラバイト級のデータを Google BigQuery 用 AWS Glue Connector を使って Google Cloud から Amazon S3 へ素早く移行
本記事は Amazon Web Services, Senior Analytics Specialist Solutions Architect である Fabrizio Napolitano によって投稿されたものです。
データレイクは、クラウドに構築すると有利になることがあります。セキュリティ、デプロイ時間の短縮、可用性、頻繁な機能の更新、弾力性、地理的に広範囲なサービス展開、および使った分だけ発生するコストが理由です。ところが、最近の Gartner や Harvard Business Review の調査によると、マルチクラウドやインタークラウド・アーキテクチャは、データマネージメント、(データ)ガバナンス、(データ)インテグレーションを複雑にすると言われています。データサイエンティストが、適切なデータにアクセスし、分析プロセスを実施するためには、シンプルで素早くコスト効率の高いやり方で、様々な(データ)ソースから、テラバイト級のデータを持って来れるようにするのが必要不可欠なのです。
この記事では、 AWS Glue と AWS Glue Connector for Google BigQuery の使い方について記載します。 AWS Glue は、完全マネージドで、サーバーレスの、抽出・変換・ロード( ETL )サービスであり、分析用データの準備やロードを容易にします。 AWS Glue Connector for Google BigQuery を使うことによって、最適化された ETL プロセスを構築して、大規模で複雑なデータセットを Google BigQuery ストレージから Amazon Simple Storage Service (Amazon S3) へ、 Parquet 形式で、 30 分以内に移行することができます。
この記事で扱うデータセットは、 BigQuery テーブルの 1000_genomes_phase_3_variants_20150220 に保存されています。このデータセットは、 IGRS の the 1000 Genomes Project によって収集されたオープンデータです。このサンプルデータセットは、サイズが 1.94 TB で約 8,500 万行であるために選択しました。また、下記のスクリーンショットのような、属性が繰り返される複雑なスキーマ(ネスト構造)があることも選択した理由です。
(訳注)実際のワークロードと比較しても同等か十分な大きさがあり、かつ適度な複雑なスキーマを持っているという観点から本オープンデータを選択しています。

ソリューション概要
このソリューションは、 AWS Glue カスタムコネクタを使用した Google BigQuery から Amazon S3 へのデータの移行 の記事に記載されている手順に基づいて構築されています。以下の図が、簡略化されたアーキテクチャです。
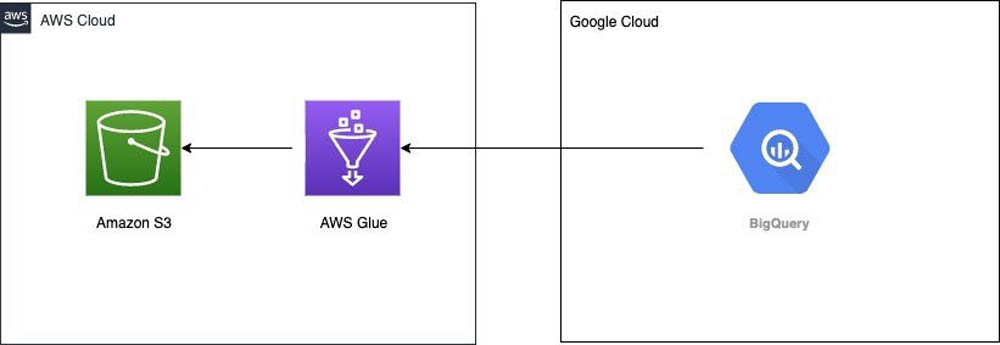
AWS Glue Studio の新機能によって、ジョブからデータカタログのテーブルを作成したり、更新したりすることにより、ソリューションをさらに簡略化します。このことから、 Amazon Athena を使ってデータをクエリーする前に、 AWS Glue のクローラーを実行することが不要になります。
前提条件
開始する前に、次の前提条件を満たしていることを確認をしてください。
- Google Cloud のアカウントを持っていること。具体的には、 Google BigQuery へのアクセス権を持ったサービスアカウントを持っていること。
- AWS Glue カスタムコネクタを使用した Google BigQuery から Amazon S3 へのデータの移行 の記事にある最初の3つの手順を完了していること。すなわち、 Google のアカウントを設定していること、 AWS Identity and Access Management (IAM) のロール(ロール名を書き留めておきます)を作成していること、 BigQuery connector を有効化していること、の 3 点です。
AWS Glue Studio で ETL ジョブを作成する
ETL ジョブを作成するために、以下の手順を実施してください。
- AWS Glue のコンソールにて、 AWS Glue Studio を起動します。
- ナビゲーションペインにて、 Jobs を選択します。
- Create job を選択します。
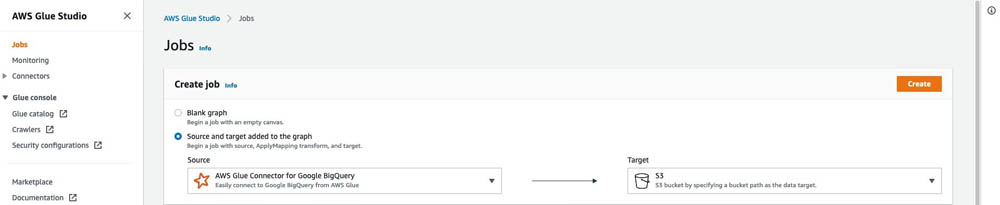
- Visual with a source and target を選択します。
- Source に AWS Glue Connect for Google BigQuery を設定します。
- Target に Amazon S3 を設定します。
- Create を選択します。
- job editor において Visual タブの ApplyMapping のノードを選択します。
- Remove を押します。

- Data source ノードを選択します(AWS Glue Connector for Google BigQuery と書かれているものです)。
- Data source properties – Connector タブにて、 Connection は BigQuery を選択します。
- Connection options の下にある Add new option を選択します。

2 つの key-value ペアを追加します。
- 最初のキーペアとして、 Key に
parentProjectを、 Value に 自身の Google プロジェクト名を入力します。 - 2 つ目のキーペアとして、 Key に table を、 Value に
bigquery-public-data.human_genome_variants.1000_genomes_phase_3_optimized_schema_variants_20150220を入力します。

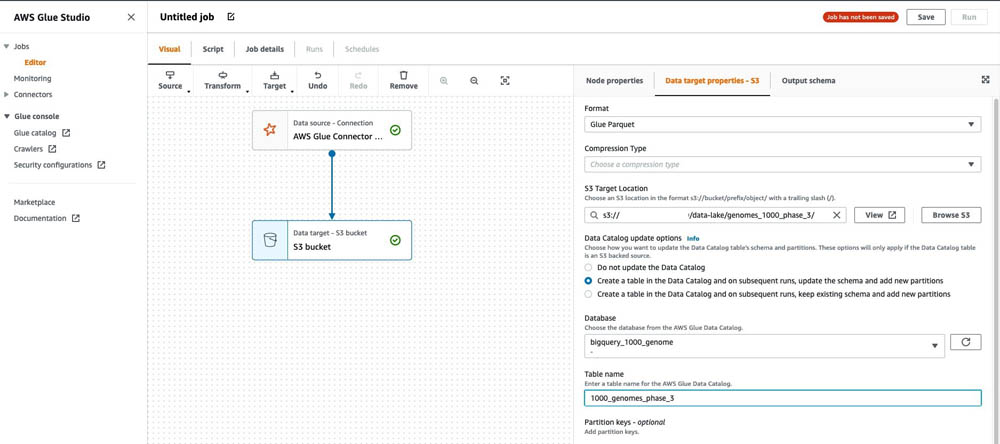
- Data target ノードを選択します(自身の S3 バケットです)。
- Data target properties – S3 タブにおいて、 Format は Glue Parquet を選択します。
これは、DynamicFrames に最適化されたカスタム Parquet ライターです。書き込む前に事前計算されたスキーマは不要です。Amazon S3 にあるファイルは、標準的な Apache Parquet ファイルです。
- S3 Target Location には、自身のバケットの S3 パスを入力してください。
- Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions を選択してください。
- Database は、テーブルを配置したいデータベースを選択します。
- Table name には、
1000_genomes_phase_3を入力します。
- Save を選択します。
- Job details タブの Name には
BigQuery_S3を入力します。 - IAM Role は、前提条件の手順にて作成したロールを選択します。
- Type は、 Spark を選択します。
- Glue version は、 Glue 2.0 – Supports Spark 2.4, Scala 2, Python3 を選択します。
- データ転送の際の最大スループットを実現するため、 Number of workers には
126を入力します。
Worker typeに G.1X がデフォルトで選択されている場合、それぞれの worker は 4 vCPU、 16 GB のメモリ、 64 GB のディスクにマップされ、 1 つの Spark executor を提供します。詳しくは、 Job Properties の定義 を参照ください。 1 つの Spark ドライバー用ノードと、 executor 単位で 8 つのタスクがあるため、 1,000 個のタスクを同時に実行することが可能です。執筆時点で、 Google Cloud BigQuery Storage API には、最大で 1,000 の読み取りストリームがあります。
- Save を選択します。

- ジョブを実行するため、 Run を選択します。
次のスクリーンショットは、 1.9 TB データの移行および変換処理の全実行時間が 26 分であることを示しています。 GCP データの場所を US に設定して、 us-east-1 および eu-central-1 のリージョンで、 AWS Glue ジョブを使ってテストしました。

移行を検証する
移行作業が成功したことを確認するため、以下の手順を実行します。
- AWS Glue コンソール上で、データベースの下にあるテーブルを選択します。
genomes_1000_phase_3テーブルを探します。

- テーブルを選択肢、スキーマを確認します。
BigQuery の繰り返しフィールドは、 Parquet の配列に変換されています。
- S3 Location のリンクを選択して、 Amazon S3 のコンソールを開きます。

S3 には、平均サイズが約 70 MB の Parquet ファイルが、数千存在します。
- データセットの全サイズを(BigQuery の 1.9 TB のサイズと比較して)確認するために、 S3 パスにある
data_lake/という親のプレフィックスを選択します。

genomes_1000_phase_3オブジェクトを選択します。- アクション メニュー上で、合計サイズを計算する を選択します。

Amazon S3 におけるサイズの合計は、わずか 142.2 GB で、 BigQuery ストレージにあるデータの合計量の 7.48 % です。 Amazon S3 では、 Snappy エンコーディングを使って Apache Parquet 形式でデータを保存するためです。これは、高圧縮率を実現できるオープンな列指向ファイル形式です。対象的に、 Google BigQuery のデータサイズは、データが内部で圧縮されているとは言え、各カラムのデータ型を基に計算されているからです。
全てのデータが正常に移行されていることを検証するために、 Athena で 2 つのクエリを実行します。
- Athena コンソール上で、次のクエリを実行します。
結果は、レコード数が BigQuery の 84,801,880 と一致することを示しています。

- 2 つ目のクエリを実行します。
このクエリは、 Athena が、(BigQuery のように) 274.1 MB ではなく、 222.93 KB のデータをスキャンするだけで良いことを示しています。コストの観点から、全テーブルスキャン(142.2 GB に対して BigQuery における 1,900 GB のデータスキャン)の影響を考えてみてください。

スケールアウト
テーブルがパーティション化されているか、大規模であり移行を複数のジョブに分割したい場合には、 Connection options に 2 つの追加パラメータを設定することができます。
- filter – 変換する行を選択するための条件を設定します。テーブルがパーティション化されている場合には、選択された行はプッシュダウンされ、指定されたパーティション行のみが AWS Glue に転送されます。他のケースでは、全てのデータがスキャンされ、 AWS Glue Spark 処理において filter が適用されます。ただし、依然としてメモリ利用量を制限するのに役立ちます。
- maxParallelism – BigQuery ストレージへクエリするために使用される読み取りストリーム数を定義します。この値により、複数のジョブを並列実行する際に、プロジェクトごとにユーザー 1 人につき 1 分あたり 5,000 回という BigQuery ストレージの API 呼び出し回数の上限に達するのを回避できます。
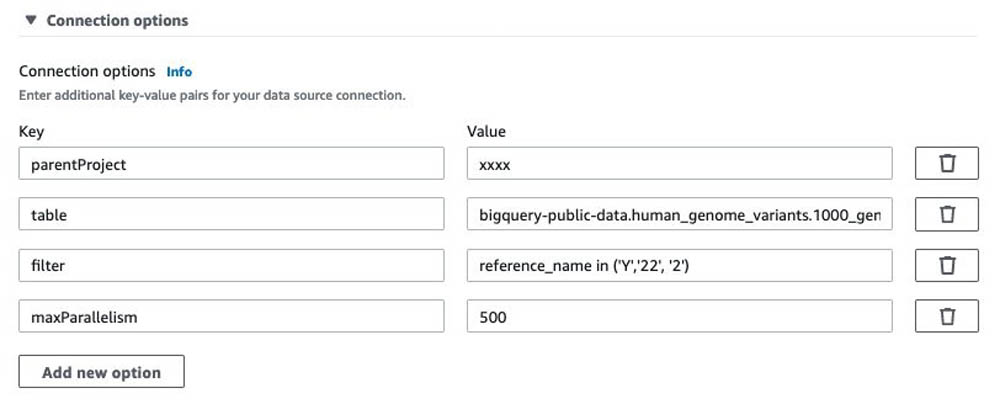
例えば、次のスナップショットでは、maxParallelism を 500 に設定し、テーブルの行の約 1/10 (800 万行)を選択する reference_name の値を filter に設定する構成にし、ワークフローはソーステーブルで 10 個のジョブを並列実行ました。このワークフローは、 19 分で完了しました。

価格に関する考慮事項
Google BigQuery から Amazon S3 へデータを移行する際に、転送料金がかかる場合があります。データ移動にかかるコストを確認、計算してみましょう。この記事の執筆時点で、 AWS Glue 2.0 は DPU 時間あたり 0.44 ドルが 1 秒単位で課金されます。 Spark ETL ジョブの場合は、最小 1 分単位です。テストのジョブは、 126 DPU で構成され、 26 分間実行されました。総実行時間は 54.6 DPU 時間で、コストはおおよそ 24 ドルでした。詳細は、 AWS Glue の料金をご確認ください。
将来的な請求が発生しないようにするためには、 S3 バケット内のデータを削除してください。 ETL ジョブやクローラーを実行していないのであれば、料金はかかりません。その代わりに、 AWS Glue ETL ジョブや Data Catalog のテーブルを削除することも可能です。
結論
本記事では、 BigQuery のテーブルに接続し、大規模なデータ(1.9 TB)を素早く(約 26 分) S3 へ移行する AWS Glue ETL ジョブを簡単にカスタマイズする方法を学びました。次に、 Athena でクエリを実行し、ストレージ料金を節約する方法(90 % 以上の圧縮率)をデモしました。
AWS Glue によって、コスト、複雑性、および ETL ジョブ作成にかかる時間を大幅に削減できます。 AWS Glue はサーバーレスです。そのため、構築および管理するインフラはありません。自身のジョブ実行中に消費するリソースに対して料金が発生するのみです。
AWS Glue ETL ジョブに関する詳細な情報は、 AWS Glue の自動コード生成機能とワークフローを利用して、データパイプラインをシンプル化するおよび Making ETL easier with AWS Glue Studio をご確認ください。
原文はこちらです。