Amazon Web Services ブログ
AWS Glueカスタムコネクタを使用したGoogle BigQueryからAmazon S3へのデータの移行
本記事はAmazon Web Services, Senior Big Data Specialist Solutions ArchitectであるSaurabh Bhutyaniによって投稿されたものです。
今日の接続された世界では、さまざまなデータソースにさまざまな形式のデータが存在することが一般的です。データは意思決定の重要な要素ですが、多くの組織にとって、これらのデータは複数のクラウドに分散しています。組織は、これらの無数のデータ ソースからデータを簡単に取り込み、ニーズに合わせてデータ取り込みをカスタマイズできるツールを求めています。
AWS Glueは分析用のデータの準備とロードを容易にする完全マネージド型の抽出、変換、およびロード(ETL)サービスです。 AWS Glueにはデータ統合に必要なすべての機能を提供し、分析は数週間または数か月ではなく数分で実行できます。AWS Glueおよび AWS Glue Studioの新機能であるAWS Glueカスタムコネクタにより、SaaSアプリケーションおよびカスタムデータソースから Amazon Simple Storage Service(Amazon S3)のデータレイクにデータを簡単に転送できます。数回クリックするだけで、AWS Marketplaceからコネクタを検索、選択し、データ準備のワークフローを数分で開始できます。カスタムコネクタを構築してチーム間で共有し、オープンソースのSparkコネクタとAthena Federated Query機能をデータ準備用のワークフローに統合することもできます。AWS Glue Connector for Google BigQueryを使用すると、Google BigQueryからAmazon S3にクラウド間でデータを移行できます。AWS Glue Studioは、抽出の作成、実行、監視を簡単にする新しいGUIを持っています。これにより、AWS Glueでの変換およびロード (ETL) ジョブ、データ変換ワークフローを視覚的に表現し、AWS GlueにおけるApache SparkベースのサーバーレスETLエンジンでシームレスに実行できます。
この投稿では、AWS Glue Studioを使用してBigQueryテーブルにクエリを実行し、そのデータをParquet形式で Amazon Simple Storage Service (Amazon S3) に保存することに焦点を当てます。そして、その後保存した内容に対してAmazon Athenaでクエリを実行します。 AWS Glueで BigQuery テーブルをクエリするには、AWS Marketplaceの新しいAWS Glue Connector for Google BigQueryを使用します。
ソリューションの概要:
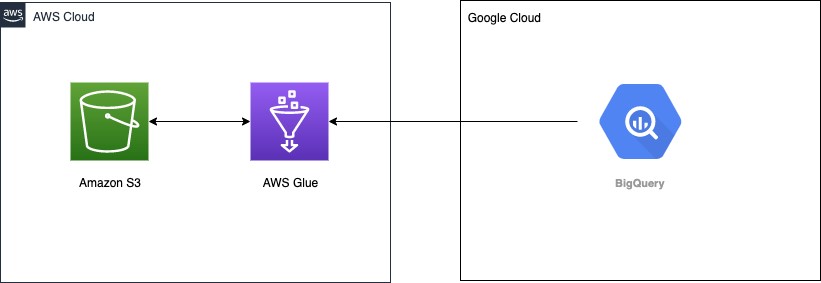
次のアーキテクチャ図は、AWS Glueがデータ取り込みを行うために、Google BigQueryに接続する方法を示しています。
前提条件
開始する前に、次のものがあることを確認してください。
- Google Cloudのアカウント、具体的にはGoogle BigQueryへのアクセス許可を持つサービスアカウント
- AWSコマンドラインインターフェイス(AWS CLI)を設定するためのアクセスキーとシークレットキーを持つAWS Identity and Access Management(IAM)ユーザー
- IAMユーザーには、IAMロールとポリシーを作成するためのアクセス許可も必要です。
Googleアカウントの設定
(注)以下の操作手順において、画面上の操作(太字)は原文およびスクリーンショットと同じ、英語で表記します。
AWS Secrets Managerでシークレットを作成して、Googleサービスアカウントファイルのコンテンツをbase64でエンコードした文字列として保存します。
- Google Cloudからサービスアカウントの認証情報が入ったJSONファイルをダウンロードします。
base64エンコーディングの場合、オンラインユーティリティまたはシステムコマンドのいずれかを使用してそれを行うことができます。LinuxおよびMacの場合、base64 <<service_account_json_file>>を使用して、ファイルの内容をbase64でエンコードされた文字列として出力されます。
- Secrets Managerコンソールで、Store a new secretを選択します。
- Secret typeで、Other type of secretを選択します。
- キーを
credentialsとして入力し、値をbase64でエンコードされた文字列として入力します。 - 残りのオプションはデフォルトのままにします。
- Nextを選択します。

- シークレット
bigquery_credentialsに名前を付けます。 - 残りの手順に従って、シークレットを保存します。
詳細については、チュートリアル: シークレットの作成と取得を参照してください。
AWS Glue用IAMロールの作成
次のステップでは、AWS Glueジョブに必要なアクセス許可を持つIAMロールを作成します。次のAWS管理ポリシーをロールにアタッチします。
Secrets Managerからのシークレットの読み取りとS3バケットへの書き込みアクセスを許可するポリシーを作成してアタッチします。
次のサンプルポリシーは、この投稿の一部としてAWS Glueジョブを示しています。本番環境で使用する場合は、必ずポリシーのスコープを絞ってください。前の手順で作成したbigquery_credentialsシークレットのシークレットARNと、BigQueryからデータを保存するためのS3バケットを更新します。
AWS Glue Connector for Google BigQueryのサブスクライブ
コネクタをサブスクライブするには、次の手順を実行します。
- AWS MarketplaceのAWS Glue Connector for Google BigQueryに移動します。
- Continue to Subscribeを選択します。
- 利用規約、価格、その他の詳細を確認します。
- Continue to Configurationを選択します。
- Delivery Methodに、提供方法を選択してください。
- Software Versionで、ソフトウェアバージョンを選択します。
- Continue to Launchを選択します。
- 利用説明にて、Activate the Glue connector in AWS Glue Studioを選択します。

AWS Glue Studioにリダイレクトされます。
- Nameに、接続の名前(たとえば、bigquery)を入力します。
- オプションで、VPC、サブネット、セキュリティグループを選択します。
- AWS Secretには、
bigquery_credentialsを選択します。 - Create connectionを選択します。
接続が正常に作成されたことを示すメッセージが表示され、接続がAWS Glue Studioコンソールに表示されます。
AWS Glue StudioでのETLジョブの作成
- Glue Studioで、Jobsを選択します。
- Sourceで
BigQueryを選択します。 - Targetには
S3を選択します。 - Createを選択します

- ApplyMappingを選択して削除します。
- BigQueryを選択します。
- 接続には、biggueryを選択します。
- Connection optionsを展開します。
- Add new optionを選択します。

- 以下のキーと値を追加します。
- Key:
parentProject, Value:<<google_project_id>> - Key:
table, Value:bigquery-public-data.covid19_open_data.covid19_open_data
- Key:
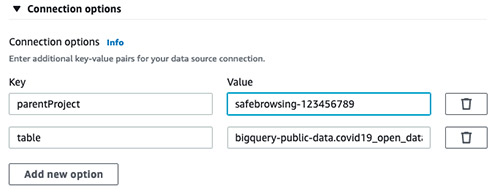
- S3 bucketを選択します。
- フォーマットと圧縮タイプを選択します。
- S3のターゲット場所を指定します。

- Job detailsを選択します。
- Nameに
BigQuery_S3と入力します。 - IAM Roleでは、前の手順で作成したロールを選択します。
- Typeで、Sparkを選択します。
- Glue versionに、Glue2.0–Supports Spark2.4, Scala2, Python3を選択します。
- 残りのオプションはデフォルトのままにします。
- Saveを選択します。

- ジョブを実行するには、ジョブの実行ボタンを選択します。

- ジョブの実行が成功したら、S3バケットのデータを確認します。

このジョブでは、コネクタを使用して、COVID-19のBigQueryパブリックデータセットからデータを読み取ります。詳細については、Apache Spark SQL connector for Google BigQuery (ベータ版)を参照してください。
このコードは、AWS GlueのDynamic DataFrameでcovid19テーブルを読み取り、データをAmazon S3に書き込みます。
データへのクエリ
Glueクローラーを使用して、S3バケット内のデータをクロールすると、covidというテーブルが作成されます。その後、Athenaに移動すると、このデータに対してクエリできます。次のスクリーンショットは、クエリ結果を示しています。

価格に関する考慮事項
Google BigQueryからAmazon S3にデータを移行する場合、データ転送の下り料金が発生する場合があります。データをAmazon S3に移動するためのコストを確認して計算します。
AWS Glue 2.0の料金はDPU時間あたり$0.44、秒単位で課金され、Spark ETLジョブの最小料金は1分です。AWS Glueで実行されるApache Sparkジョブには、最低2つのDPUが必要です。デフォルトでは、AWS Glueは各Apache Sparkジョブに10個のDPUを割り当てます。ジョブの要件に基づいて、ワーカーの数を変更する必要があります。詳細については、AWS Glueの料金表を参照してください。
まとめ
この投稿では、AWS Glue ETLを簡単に使用してBigQueryテーブルに接続し、データをAmazon S3に移行してから、Athenaですぐにデータをクエリする方法を学びました。AWS Glueを使用すると、ETLジョブの作成にかかるコスト、複雑さ、時間を大幅に削減できます。AWS Glueはサーバーレスであるため、セットアップまたは管理するインフラストラクチャはありません。ジョブの実行中に消費されたリソースに対してのみ料金が発生します。
AWS Glue ETLジョブの詳細については、AWS Glueの自動コード生成とワークフローによるデータパイプラインの簡素化およびAWS Glue StudioでETLを容易にするを参照してください。
原文はこちらです。
本ブログはソリューションアーキテクト 倉光が翻訳しました。