Amazon Web Services ブログ
Amazon Aurora スナップショットから Amazon Aurora DSQL へのデータ移行
本記事は 2026 年 5 月 7 日 に公開された「Migrating data from an Amazon Aurora snapshot into Amazon Aurora DSQL」を翻訳したものです。
Amazon Aurora DSQL は、高可用性、無制限のスケール、マルチリージョンの強整合性、そしてインフラ管理不要を実現したサーバーレス分散 SQL データベースです。Aurora DSQL はデータベースへのデータ移行に PostgreSQL の COPY コマンドをサポートしており、Aurora DSQL 向けに COPY コマンドを利用しやすくした dataloader スクリプトも提供しています。ただしこの方式は、テーブルを 1 つずつ移行する必要があるうえ、ソースデータベースから移行先 Aurora DSQL クラスターへデータをコピーする中継用コンピュートインスタンスを別途用意しなければならず、ソースとターゲット間でデータを変換する手段も用意されていません。大規模なデータ移行や、データ型変換、スキーマ変更、その他の変換が必要な移行には、マネージドな移行手法のほうが適しています。本記事では AWS Glue を使って Amazon Aurora のスナップショットから Aurora DSQL クラスターへデータを移行する方法を紹介します。
ソリューション概要
AWS Glue は、Extract, Transform, Load (ETL) 処理を行う Apache Spark ジョブ向けにマネージドな並列実行環境を提供するデータ統合サービスです。AWS Glue では、移行に必要なデータ変換を PySpark スクリプトとして記述でき、移行に利用するコンピュートノードの数とキャパシティを指定して実行できます。AWS Glue が背後のコンピュートインフラを管理し、コンピュートノード間で処理の分散と並列実行をオーケストレーションします。
本記事では、Amazon Aurora PostgreSQL-Compatible Edition から Aurora DSQL へ、データベーススナップショットと AWS Glue を使って 2 つのテーブルを持つデータベースを移行する例で、この移行手法を紹介します。今回の移行のワークフローは次の図のとおりです。
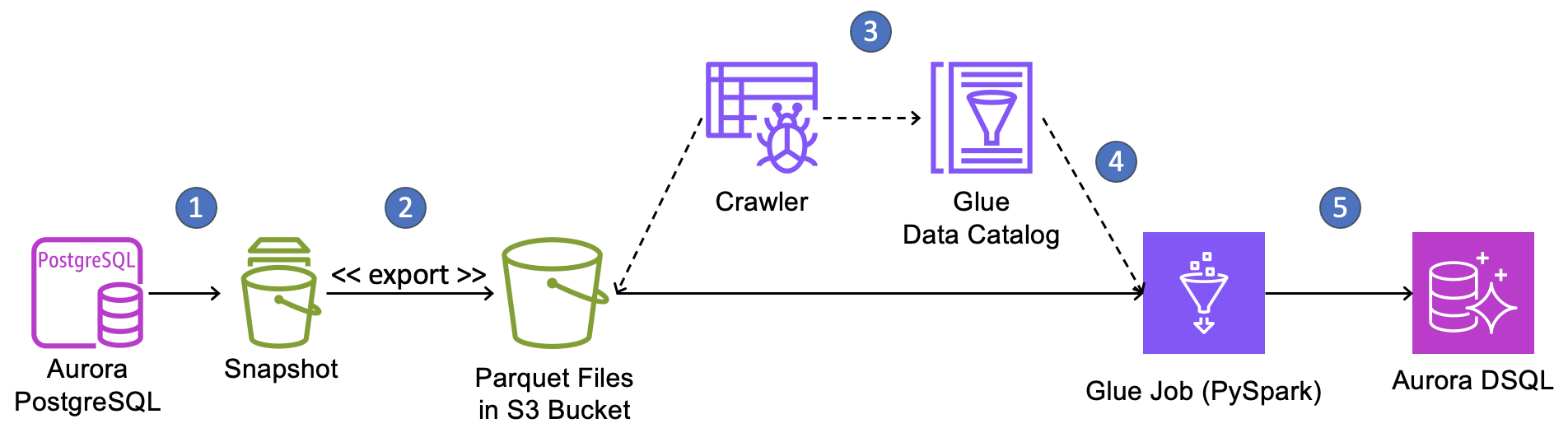
移行ワークフローは次のとおりです。
- Aurora PostgreSQL クラスターのスナップショットを作成します。
- Aurora スナップショットの S3 へのエクスポート機能を使い、スナップショットから Amazon Simple Storage Service (Amazon S3) バケットへ Parquet 形式でデータを抽出します。
- AWS Glue クローラーを作成・実行して S3 上の Parquet ファイルを発見し、スキーマを判定し、スキーマとファイルの場所を AWS Glue Data Catalog に記録します。ソースデータベースのテーブルごとに 1 つのクローラーを作成します。
- Data Catalog を参照して S3 からファイルを見つけて読み込み、必要なデータ変換を行ったうえで Aurora DSQL に書き込む PySpark ETL ジョブを AWS Glue で作成します。
- ETL ジョブを実行し、ワンタイムのデータロードを行います。
Aurora DSQL は 1 クラスターあたり 1 データベースのみをサポートしますが、Aurora クラスターは複数のデータベースをホストできます。複数のデータベースをホストする Aurora クラスターを移行するには、Aurora スナップショットに含まれるデータベースごとにこの移行プロセスを繰り返し、データベースをそれぞれ独立した Aurora DSQL クラスターにデプロイするか、Aurora DSQL の 1 つのデータベース内に複数のスキーマとして移行する必要があります。
データ型変換
Aurora スナップショットの S3 エクスポート処理では、Aurora DSQL への最終的な書き込みに影響するデータ変換が行われます。一部の変換は修正や再変換が必要になる場合があり、その作業は AWS Glue ETL ジョブ内の PySpark で行えます。たとえば、ソースデータベースの timestamp 型カラムは、スナップショットエクスポート時に Parquet のバイト配列に変換され、PySpark で読み込んだ際には文字列オブジェクトとして解釈されます。Aurora DSQL に書き込む前に、この文字列を timestamp 型へ戻す必要があります。スナップショットエクスポート処理が PostgreSQL のデータ型を Parquet にどう変換するかは、エクスポート関連のドキュメントを参照してください。
Aurora DSQL はオープンソースの PostgreSQL で利用できる全データ型をサポートしているわけではありません。Aurora DSQL がサポートするデータ型の一覧は Aurora DSQL ユーザーガイドを参照してください。ソースデータベースのテーブルで Aurora DSQL がサポートしないデータ型を使っているカラムを特定し、Aurora DSQL ではどう表現するかを決め、AWS Glue PySpark ジョブで変換を行う必要があります。該当するカラムはスナップショットエクスポート時にも変換される場合があるため、PySpark スクリプトでその点も考慮しなければなりません。
主キーの扱い
多くのアプリケーションは主キーに連番の整数を使います。新しいデータに一意の識別子を自動付与でき、ほとんどのリレーショナルデータベースでは新しい行がストレージ上で近い位置に配置されるため、最近追加された行が他の新しい近接行の読み取りでバッファキャッシュに乗りやすくなります。アプリケーションでは古いデータより新しいデータのほうが頻繁に読まれる傾向があり、ストレージからの読み取りよりキャッシュからの読み取りのほうがはるかに高速なため、連番識別子は多くのアプリケーションで読み取り性能の向上につながります。
ただし Aurora DSQL はバッファキャッシュを提供しておらず、大規模に連番整数キーを使うとホットなストレージパーティションが発生する可能性があります。Aurora DSQL のレンジパーティショニングでは新しいデータがすべて同じストレージパーティションに配置されるためです。代わりに、レンジパーティション化されたストレージで分散が良くなる主キーを選びましょう。テーブル内に既に存在するカラムの中から、カーディナリティの高いカラムに他の 1 つ以上のカラムを続けた複合キーを選ぶことを推奨します。この種のキーはデータへのアクセス方法と一致しやすく、追加のセカンダリインデックスを必要としません。また、テーブル定義のみを変更しテーブル内のデータは変えないため、移行時に追加のデータ変換も必要ありません。
ただし、これが常に可能とは限りません。場合によっては、UUID (Universally Unique Identifier) かランダム化された識別子で旧主キーを置き換える新しい主キーカラムを作成する必要があります。移行時に主キーを変換するのは難しく、外部キー関係も修正しなければなりません。移行検証のためにソースデータベースとターゲットデータベース間で行をマップできるよう、元の識別子を別カラムに残しておきたい場合もあります。データベースを利用するすべてのアプリケーションも新しい識別子を使うように更新する必要があります。
本記事の例では主キーを UUID に変換し、外部キー関係を修正することで、AWS Glue と PySpark を使った主キー変換の進め方を示します。元の主キーは別カラムに残し、ソースデータベースへマップし直せるようにします。
移行手順
本セクションでは、架空の小売アプリケーション向けデータベースを Aurora PostgreSQL から Aurora DSQL へ移行する手順を順を追って説明します。本記事では、例を交えて移行プロセスを示し、実際の移行に応用していただくことを目的としています。
Aurora PostgreSQL のソースデータベース名は「storefront」です。storefront には次のテーブルを持つ sales スキーマが含まれています。
これらのテーブルは実際の小売データベースとしては必ずしも適切ではありませんが、Aurora DSQL でどう変換されるかを示すためにさまざまなデータ型のカラムを持たせています。sales.orders テーブルの customer_id カラムは sales.customers テーブルの id カラムを参照しています。簡潔にするためインデックスや制約は省略しています。
前提条件
この例の移行は本番環境で実施しないでください。実行には、AWS アカウントと、移行に必要なリソース (AWS Identity and Access Management (IAM) のロールやアクセス許可を含む) を作成できる十分な権限が必要です。例のソリューションを自分の移行に応用する場合は、本番データを移行する前に必ず非本番アカウントで作業し、十分にテストしてください。
また、ワークステーションのローカルか、AWS 環境で動作するコンピュートインスタンス上で動作する Unix bash シェルセッションへのアクセスも必要です。ワークステーションは AWS アカウントおよびソース/ターゲットデータベースへのネットワークアクセスを持ち、最近のバージョンの AWS Command Line Interface (AWS CLI) がインストールされている必要があります。AWS CLI は前述の IAM ロールで設定されている必要があります。
AWS 環境でのデータベース操作、Unix シェル、AWS マネジメントコンソールや AWS CloudFormation などの AWS サービスについて中級程度の経験があることを前提としています。そのため、ソースデータベースの構築、データベースへの接続、コマンドを実行するワークステーションのセットアップについての具体的な手順は示しません。
本移行には Amazon S3 バケット、AWS Glue クローラー、AWS Glue ジョブ、AWS Key Management Service (AWS KMS) キー、エンドツーエンドのワークフローを実現するためのアクセス許可を付与する複数の IAM ポリシーとロールが必要です。利便性のため、これらのコンポーネントは AWS CloudFormation テンプレートでデプロイし、移行に使う PySpark コードもあわせてデプロイします。CloudFormation テンプレートと関連ファイルは GitHub リポジトリで公開しており、ワークステーションにダウンロードしてください。次のコマンドでプロジェクトファイルをダウンロードします。
リポジトリには amazon-aurora-snapshots-to-dsql というサブディレクトリがあり、以下のファイルが含まれています。本記事ではこのディレクトリを「プロジェクトディレクトリ」と呼びます。
プロジェクトに含まれるファイルは次のとおりです。
| stack.yml | 後続のセクションで参照する S3 バケット、AWS KMS キー、AWS Glue クローラー、AWS Glue ジョブ、関連する IAM ポリシーおよびロールを作成します。 |
| ddl-dsql.sql | ターゲットの Aurora DSQL クラスターに必要なスキーマ、テーブル、インデックスを作成する SQL コマンドが含まれています。 |
| storefront.sql.zip | ソースデータベースのスキーマとテーブルを作成し、サンプルデータをテーブルに投入する SQL コマンドが含まれています。 |
AWS アカウント内の Amazon Virtual Private Cloud (Amazon VPC) のプライベートサブネットに、新しい Aurora PostgreSQL クラスターを作成します。本例では PostgreSQL 17.7 を使用しています。クラスター名は「prod-cluster」とし、初期データベース名には「storefront」を指定します。クラスター作成時に初期データベース名を設定し忘れた場合は、クラスターにログインし、次の SQL 文でデータベースを作成します。
プロジェクトディレクトリの bash シェルで次のコマンドを実行し、データベーススキーマを作成してサンプルデータをロードします。
データベースクラスターの「postgres」ユーザーのパスワード入力を求められます。データのロード後、storefront データベースにログインし、次の SQL コマンドでサンプルデータを確認します。
これでソースデータベースの準備ができました。Aurora DSQL へのデータ移行に進みます。
移行の実行
まず Aurora DSQL クラスターを作成します。Unix 系のコマンドラインで次のコマンドを実行し、「storefront」という名前の単一リージョン Aurora DSQL クラスターを作成し、エンドポイントと Amazon Resource Name (ARN) を新しい環境変数に保存します。クラスター作成は数秒で完了します。
クラスターのステータスは次のコマンドで確認します。
ステータスが「ACTIVE」になるまで何度か実行します。Aurora DSQL クラスターがアクティブになったら、クラスターに接続し、GitHub プロジェクトの ddl-dsql.sql ファイルにあるコマンドを実行してスキーマとテーブルを作成します。
次に、先ほどの GitHub プロジェクトの stack.yml テンプレートファイルを使い、「apg-to-dsql」という名前の AWS CloudFormation スタックを作成します。スタック名は後で参照するため重要です。スタックには次のパラメータが必要です。
| DSQLClusterEndpoint | 作成した Aurora DSQL クラスターのエンドポイント。AWS マネジメントコンソールのクラスター詳細ページで確認できます。 |
| DSQLClusterArn | 作成した Aurora DSQL クラスターの ARN。AWS マネジメントコンソールのクラスター詳細ページで確認できます。 |
| LoaderJobCapacity | DSQL ローダージョブに割り当て可能な AWS Glue data processing unit (DPU) の最大キャパシティで、2〜100 の範囲で指定します。DPU は処理能力の相対的な指標で、4 vCPU と 16 GB メモリで構成されます。移行のサイズと複雑さに応じて DPU 数を選びます。 |
| ExportJobName | スナップショットエクスポートジョブの名前。アカウント内で一意である必要があります。 |
| SourceDatabaseName | Aurora PostgreSQL のソースデータベース名。 |
| SourceSchemaName | ソースデータベースから移行するスキーマ名。 |
サンプル移行のデフォルト値でスタックを作成するには、プロジェクトディレクトリで次のコマンドを実行します。
スタックの完了を待ちます。後続の手順で必要となる出力値が複数あります。
| KmsKeyArn | エクスポートしたスナップショットデータを暗号化するために作成された AWS KMS キーの ARN。 |
| SnapshotExportRoleArn | スナップショットエクスポート処理が S3 にデータを保存するために必要な IAM ロールの ARN。 |
| GlueRoleName | AWS Glue ジョブが必要なアクセスを得るための IAM ロール名。 |
| GlueRoleArn | AWS Glue ジョブが必要なアクセスを得るための IAM ロールの ARN。 |
| GlueJobName | AWS Glue ジョブの名前。 |
後続のコマンドで使いやすいように、スタックパラメータと出力値を環境変数に取り込みます。スタック名を「apg-to-dsql」以外にした場合は、コマンドを設定したスタック名に合わせて修正してください。
次のコマンドでデータベーススナップショットを作成します。スナップショット名は「migrate-to-dsql」、ソースデータベースクラスター名は前述の「prod-cluster」です。スナップショットの ARN は後で使うため SNAPSHOT_ARN という環境変数に取り込みます。
スナップショットのステータスは次のコマンドで確認します。
ステータスが「available」になるまで何度か実行し、その後で次のコマンドでスナップショットをエクスポートします。
エクスポートジョブのステータスが「COMPLETE」になるまで、次のコマンドを定期的に実行して状態を確認します。
ここまでで、移行に必要なインフラの構築、ソースデータベースのスナップショット作成、Parquet ファイルとしての S3 バケットへのスナップショットエクスポートが完了しました。次に AWS Glue クローラーを実行してエクスポート済みデータをカタログ化し、PySpark ジョブを実行して Aurora DSQL にデータをロードします。
ソースデータベースからエクスポートした両方のテーブルに対して、次のコマンドで AWS Glue クローラーを実行します。クローラーは CloudFormation テンプレートで作成済みです。
クローラージョブの状態は次のコマンドで取得できます。クロール対象データの量によっては完了まで数分かかることがあります。両方のジョブが「COMPLETED」になるまで 1 分ごとに実行してください。
両方のクローラージョブが完了したら、次のコマンドでクローラーがエクスポート済みスナップショットデータからカタログ化したテーブルとカラムを確認します。AWS Glue ローダージョブはこのカタログを使って S3 バケット内のエクスポート済みスナップショットデータを見つけます。
出力は次のようになります。
次のコマンドで AWS Glue ジョブを実行します。
ジョブのステータスは次のコマンドで取得します。完了するまで定期的に実行してください。
ジョブが完了すれば、データ移行は完了です。
検証
行数のカウントと数値カラムの合計を取り、移行が正しく完了したか検証します。
まずソースの Aurora PostgreSQL データベースとターゲットの Aurora DSQL クラスターの両方で次のクエリを実行します。
両方の件数が一致するはずです。次のクエリもソースとターゲットの両方で実行し、件数と合計値がすべて一致することを確認します。
この単純な検証方法は本番環境の移行には十分ではありません。実際には、移行中に行った変換処理を考慮しつつ、すべてのカラム値を行ごとに比較する必要があります。
AWS Glue ジョブを理解する
本移行手法には多くの構成要素がありますが、唯一複雑なのはスクリプトを自分で書く必要のある AWS Glue ジョブです。本記事の AWS Glue ジョブはシンプルで、いくつかのデータ型変換と整数識別子から UUID への変更しか行っていませんが、より複雑な移行を構築する際の基本要素を示しています。本サンプル移行の AWS Glue ジョブのコードは CloudFormation スタックでデプロイ済みです。閲覧するには AWS Glue コンソールで ETL jobs を選択し、storefront-snapshot-dsql-loader ジョブを選びます。スクリプトエディタにスクリプトが読み込まれます。コードを順に確認していきましょう。
ファイル冒頭はセットアップコードで、ライブラリのインポート、API コンポーネントの初期化、CloudFormation テンプレートで設定したジョブ設定パラメータの取得を行います。該当部分は次のとおりです。
続く数行のコードでは、AWS Glue カタログを使って S3 上のファイルを見つけ構造を解釈しつつ、customers と orders のデータを読み込みます。
次にデータにいくつかの変換を適用します。データ型をいくつか変換し、テーブルの主キーを UUID に変換しつつ、元の ID は別カラム名で残します。まず customers テーブルから始めます。
ここでは id カラムを「old_id」にリネームします。続いて新しい「id」カラムを作成し、各行に新たに生成した UUID 値を設定します。これらの変換と後続ステップで残すカラムの選択は、使い慣れた SQL で行えます。
orders テーブルでも同様の処理を行いますが、加えて customer_id カラムを「old_customer_id」にリネームします。「old_customer_id」カラムは一時的なもので、後ほど UUID 主キーへの切り替えに伴う外部キー関係の修正で使います。
次に「order_timestamp」カラムと「order_date」カラムを修正し、Parquet 変換で文字列になっていた値を本来の timestamp 型と date 型に戻します。to_timestamp() と to_date() を使っている点に注目してください。
続いて orders と customers の外部キー関係を新しい UUID 主キーを使うように修正し、Aurora DSQL のデータベースには残したくない「old_customer_id」カラムを削除します。Aurora DSQL は現状で外部キー制約を強制しませんが結合はサポートしているため、効率的な結合のために関係を修正することは重要です。
データ変換の作業はこれで完了です。移行のアーキテクチャを示すために基本的な変換のみを紹介しましたが、PySpark は表現力が高く、移行で必要なあらゆる変換を実装できます。
データの準備ができたので、DSQL に書き込みます。次のコードがその処理です。
まず、コードは IAM 認証用のトークンを生成します。このトークンをデータベースのパスワードとして使います。移行ジョブの実行を通じてトークンが有効であり続けるよう、認証トークンに長めのタイムアウトを設定しています。
次に DataFrameWriter を使い、DataFrame の write() を呼び出して customers と orders の DataFrame を Aurora DSQL のそれぞれのテーブルに書き込みます。Spark が Aurora DSQL でテーブル作成を試みないよう、DataFrameWriter の書き込みモードを「append」に設定します。Aurora DSQL は SSL 接続が必須のため、「sslmode」を「require」に設定します。
DataFrameWriter のデフォルト動作では、insert を複数バッチに分割しつつもすべてを 1 つのデータベーストランザクションで実行します。この挙動は Aurora DSQL の「1 トランザクションあたり 3,000 行まで」という変更行数の制限に抵触し、AWS Glue ジョブが失敗する原因になります。これを回避するため「isolationLevel」を「NONE」に設定し、各バッチの後に DataFrameWriter がコミットするよう強制します。バッチサイズが DSQL の制限を超えないよう「batchsize」を「2500」に設定しています。
クリーンアップ
移行を実行し、結果を検証し、AWS Glue スクリプトを理解できたところで、本記事で作成したリソースをクリーンアップします。
まず、次のコマンドで CloudFormation スタックを削除します。
次のコマンドを定期的に実行し、コマンドが「Stack with id apg-to-dsql does not exist」というエラーを返すまで状態を確認します。エラーが返ればスタックが削除されたことを意味します。
CloudFormation スタックが削除されたら、次のコマンドで Aurora DSQL クラスターを削除します。
続いて、次のコマンドでデータベーススナップショットを削除します。
最後に、本例でソースデータベースとして使った Aurora PostgreSQL クラスターを削除します。
まとめ
本記事では、AWS Glue を使って Aurora PostgreSQL のスナップショットから Aurora DSQL へデータを移行する方法を紹介しました。AWS Glue はマネージドな並列実行環境を提供し、大量のデータを Aurora DSQL に短時間で移行しつつ、表現力の高いプログラミング言語でデータ変換を行えます。プロセス全体は複雑に見えますが、難しいのは AWS Glue スクリプトを書く部分だけで、その難易度は移行の複雑さや PySpark の習熟度によって変わります。本記事では、ご自身の移行に合わせて修正できるベーススクリプトを提供しています。
ブラウザベースのプレイグラウンドを使えば、AWS アカウントがなくても今日から Aurora DSQL を評価できます。プレイグラウンドは一時的なデータベース環境で、Aurora DSQL を素早く試して数分でハンズオンを始められます。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Koji Shinkubo がレビューしました。