Amazon Web Services ブログ
Oracle から Amazon Aurora DSQL へのデータ移行
本記事は 2026 年 6 月 3 日 に公開された「Migrating data from Oracle to Amazon Aurora DSQL」を翻訳したものです。
Amazon Aurora DSQL は、サーバーレスで柔軟にスケールする分散 SQL データベースサービスです。複数の AWS リージョンにまたがって、強力な ACID 準拠を実現します。データベースのモダナイゼーションに向けて Amazon Aurora DSQL を検討している場合、サービスの現在の機能と制約の範囲内で既存のエンタープライズデータベースを移行するという課題に直面することがあります。
本記事では、AWS Database Migration Service (AWS DMS)、Amazon Simple Storage Service (Amazon S3)、AWS Glue、AWS Step Functions を使い、Oracle ソースから Amazon Aurora DSQL へデータを移行する手順を説明します。エンタープライズ規模のデプロイに適した、自動化されたコスト効率の高い移行パイプラインを構築します。
このソリューションの完全なソースコードは、GitHub の sample-oracle-to-aurora-dsql-migration リポジトリで入手できます。
Amazon Aurora DSQL の概要
Amazon Aurora DSQL は、高可用性、スケーラビリティ、パフォーマンスを必要とするアプリケーション向けに設計された、サーバーレスの分散 SQL データベースです。主な特長は次のとおりです。
- サーバーレスアーキテクチャ – Amazon Aurora DSQL はフルマネージドのサーバーレスデータベースサービスで、需要に応じてコンピューティング、ストレージ、実行レイヤーを自動的にスケールします。
- PostgreSQL 互換性 – Amazon Aurora DSQL は PostgreSQL 互換の SQL 構文と機能を提供するため、PostgreSQL インターフェイスで動作するアプリケーションに適しています。
- 分散設計 – 分散アーキテクチャを採用し、複数のアベイラビリティーゾーンにわたる高可用性と耐久性を実現します。
- マルチリージョン対応 – Amazon Aurora DSQL は、ディザスタリカバリやグローバルアプリケーション向けにマルチリージョンデプロイをサポートします。
- IAM 統合 – AWS Identity and Access Management (IAM) と統合し、認証とアクセス制御を行います。
- 暗号化 – Amazon Aurora DSQL は、データセキュリティのために保管時と転送時の暗号化を提供します。
移行の課題と要件
エンタープライズデータベースを Amazon Aurora DSQL に移行する際には、いくつかの固有の課題に直面します。
- 認証の複雑さ – Amazon Aurora DSQL では、特定のトークン生成要件を伴う IAM ベースの認証が必要です。必要なロールを引き受けられる AWS サービスは限られているため、直接接続できる手段が制限され、認証を慎重に管理する必要があります。
- スキーマ作成の自動化 – Amazon Aurora DSQL では、データをロードする前にスキーマとテーブルを明示的に作成する必要があります。そのため、ソースデータベースからのスキーマ分析と変換を自動化する仕組みが必要です。
- データロードの制約 – Amazon Aurora DSQL は主にファイルからの
COPYコマンドでのデータロードをサポートしており、移行戦略に固有の要件が生じます。ファイルはデータベースエンジンからローカルにアクセスできる必要があり、移行パイプラインの構成方法に影響します。 - コスト最適化 – 中間処理に Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを使う従来の方法では、特に移行期間が長期にわたる大規模データベースで、ストレージとコンピューティングのコストが大きくなることがあります。
ソリューションの概要
次の図は、ソリューションのアーキテクチャを示しています。
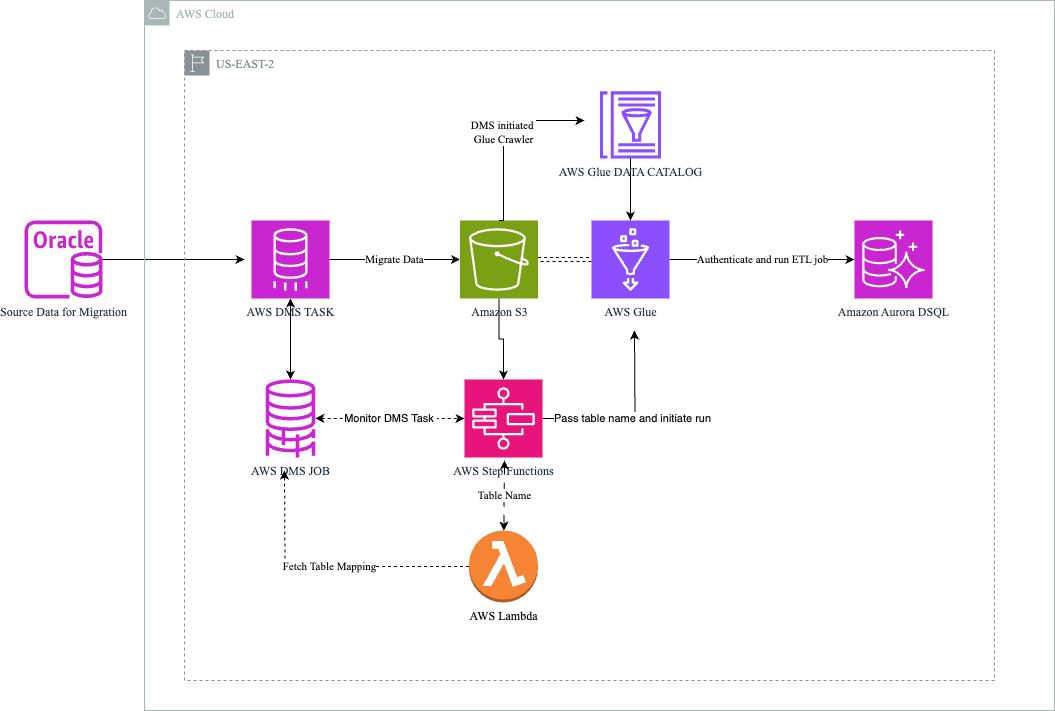
ワークフローは次のステップで構成されます。
- パイプラインがオンプレミスの Oracle データベースからデータを抽出します。ソースには、AWS DMS がサポートする他のリレーショナルデータベースを使うこともできます。
- AWS DMS がデータを Amazon S3 に移行し、AWS Glue データカタログを作成します。
- Step Functions が AWS DMS タスクの進行を開始・監視し、AWS Lambda 関数と AWS Glue ジョブを起動します。
- Lambda 関数が AWS DMS からテーブルマッピングを取得して Step Functions に返し、Step Functions がそれを AWS Glue ジョブに渡します。
- AWS Glue がターゲットの Amazon Aurora DSQL データベースに接続し、データカタログを使ってカラムを識別します。続いてターゲットにスキーマを作成し、ターゲットのデータ型にデータを変換します。最後に Amazon S3 からデータを読み取り、Amazon Aurora DSQL データベースにロードします。
前提条件
始める前に、次の前提条件を満たしていることを確認してください。
- AWS DMS のレプリケーションソースとして設定し、データベース移行の準備が整ったソース Oracle データベース。
- 中間データストレージ用の S3 バケット。次の設定を行います。
- ブロックパブリックアクセスを有効化。
- デフォルト暗号化 (SSE-S3 または SSE-KMS) を構成。
- AWS DMS がターゲットとして使用し、AWS Glue がアクセスするために必要な権限。
- AWS DMS タスクの監視、Lambda 関数の起動、AWS Glue ジョブの管理を行うサービスロールを引き受ける Step Functions ワークフローを作成するためのユーザー権限。
- 特定の Amazon Aurora DSQL クラスターにスコープを限定した次の IAM 権限。
iam:CreateServiceLinkedRole。dsql:DbConnect。dsql:DbConnectAdmin。dsql:GenerateDbConnectAdminAuthToken。dsql:GenerateDbConnectAuthToken。
Amazon Aurora DSQL のターゲットインスタンスを作成する
Amazon Aurora DSQL クラスターを作成するには、次のステップを実行します。
- Amazon Aurora DSQL コンソールのナビゲーションペインで、[Clusters] を選択します。
- [Create cluster] を選択し、[Single-Region] または [Multi-Region] を選択します。
- 暗号化設定、削除保護、タグを構成します。
- [Create cluster] を選択します。
クラスター作成の詳細な手順、高度な設定、マルチリージョンのセットアップオプションについては、Aurora DSQL の開始方法 を参照してください。
AWS DMS タスクを構成する
次のステップで AWS DMS タスクを構成します。
- データ量を処理できる十分な容量のレプリケーションインスタンスを作成します。
- 接続情報を設定し、転送時の暗号化のために SSL モードを
verify-fullに設定した Oracle ソースエンドポイントを作成します。 - 次の設定で Amazon S3 ターゲットエンドポイントを作成します。
DataFormatをCSVに設定。EncryptionModeをSSE_KMSに設定。ServerSideEncryptionKmsKeyIdを KMS キーの ARN に設定。GlueCatalogGenerationとIncludeOpForFullLoadをTrueに設定。
- AWS DMS 移行タスクを作成します。
- 移行タイプに [full load] を選択します。
- ソーススキーマのテーブルマッピングを構成します。
- ラージオブジェクト (LOB) の処理とパフォーマンスに適したタスク設定を行います。
- 移行タスクの起動設定を [Manually later] に設定します。
AWS DMS の詳細な構成手順、エンドポイント設定、タスク構成オプションについては、Creating a task、Using an Oracle database as a source for AWS DMS、Using Amazon S3 as a target for AWS Database Migration Service を参照してください。
Lambda 関数を作成する
AWS DMS タスクのマッピングからテーブル情報を抽出する Lambda 関数を作成します。この関数は DMS タスクのテーブルマッピングを解析してターゲットのテーブル名を特定し、それを AWS Glue ETL ジョブに渡します。
Lambda 関数の完全なコードは、GitHub の sample-oracle-to-aurora-dsql-migration リポジトリを参照してください。
この関数は主に次の処理を行います。
- DMS タスクイベントから
tableMappingsを解析します。 - DMS ルールを順に処理し、選択タイプのルールを見つけます。
object-locatorからテーブル名を抽出して返します。
Lambda の構成
- メモリ – 128 MB (テーブル名の抽出には十分です)。
- タイムアウト – 15 秒 (5 秒より長く設定します)。
- IAM ロール – 次の AWS DMS 権限を持つ基本的な Lambda 実行ロール。
dms:DescribeReplicationTasks– AWS DMS タスクの詳細とテーブルマッピングを読み取ります。dms:DescribeTableStatistics– テーブル単位の移行統計にアクセスします。
Lambda の IAM 権限要件の詳細については、AWS Lambda アクセス許可の管理 および AWS DMS API Reference を参照してください。
AWS Glue ETL ジョブを作成する
AWS Glue ETL ジョブは、スキーマの作成、データ型のマッピング、Amazon Aurora DSQL へのデータロードを担います。
データカタログのセットアップ
Amazon S3 をターゲットにすると、AWS DMS がデータカタログのエントリを自動的に作成します。別途クローラーを用意する必要はありません。AWS DMS は移行中にデータカタログを生成し、Oracle ソースの適切なスキーマ情報を使ってテーブルをカタログ化します。
ジョブの構成
- ジョブタイプ – Spark ETL。
- AWS Glue バージョン – 3.0 以降。
- 依存 JAR のパス –
postgresql-42.7.4.jar(JAR ファイルをダウンロードし、S3 のアクセスパスを指定します)。 - Python モジュールのパス –
boto3>=1.35.95(Amazon Aurora DSQL の認証に使用します)。 - ワーカータイプ – データ量に応じて調整します。
Glue ジョブの IAM 権限
AWS Glue ジョブには、次のサービスにまたがる権限が必要です。完全な IAM ポリシーについては、GitHub の sample-oracle-to-aurora-dsql-migration リポジトリを参照してください。
| ステートメント | アクション | 目的 |
S3Access |
s3:GetObject, s3:ListBucket |
移行データを Amazon S3 から読み取る |
GlueDataCatalogAccess |
glue:GetDatabase, glue:GetTable, glue:GetPartitions |
スキーマのメタデータにアクセスする |
AuroraDSQLAccess |
dsql:DbConnect, dsql:DbConnectAdmin |
ターゲットデータベースに接続する |
DSQLTokenGeneration |
dsql:GenerateDbConnectAdminAuthToken, dsql:GenerateDbConnectAuthToken |
認証トークンを生成する |
AWS Glue の IAM 要件の詳細については、「AWS Glue」 のセキュリティ および Aurora DSQL での Identity and Access Management を参照してください。
AWS Glue ETL ジョブのスクリプト
完全なスクリプトは、GitHub の sample-oracle-to-aurora-dsql-migration リポジトリを参照してください。
このスクリプトは主に次の処理を行います。
- トークン生成 –
boto3.client("dsql")のgenerate_db_connect_admin_auth_token()を使って IAM 認証トークンを生成します。 - スキーマ検出 – AWS Glue データカタログからテーブルスキーマを読み取ります。
- データ型マッピング – 次の表のように、Oracle と Glue のデータ型を Amazon Aurora DSQL 向けの PostgreSQL 互換型にマッピングします。
| Glue の型 | Amazon Aurora DSQL の型 |
string |
VARCHAR(255) |
int |
INTEGER |
bigint |
BIGINT |
double |
DOUBLE PRECISION |
float |
REAL |
boolean |
BOOLEAN |
timestamp |
TIMESTAMP |
date |
DATE |
decimal |
NUMERIC |
long |
BIGINT |
binary |
BYTEA |
map |
JSONB |
struct |
JSONB |
array |
TEXT[] |
- 入力検証 – SQL インジェクションを防ぐため、テーブル名を SQL ステートメントで使用する前に、正規表現
^[a-zA-Z0-9_]{1,64}$で検証します。 - DDL 実行 – 明示的なトランザクション管理を伴う JDBC 接続を使って、Amazon Aurora DSQL にテーブルを作成します。
- データロード – Amazon S3 から CSV データを読み取り、型キャストを適用し、トランザクション分離レベル
REPEATABLE_READとバッチサイズ 9,900 行で JDBC を使って Amazon Aurora DSQL に書き込みます。
Glue ジョブの主な設定
- トークン生成 –
boto3.client("dsql")のgenerate_db_connect_admin_auth_token()メソッドを使用します。 - トークンの有効期限 – 最大 24 時間です。ここでは 1 時間に設定しています。
- ユーザー ID – サンプルコードで使用するユーザー ID は
adminです。 - データ型マッピング戦略 –
GlueCatalogGenerationを使うと、スキーマのカラムにはソースの値と一致しないことがあるデフォルトのデータ型が割り当てられます。AWS Glue のコードでデータ型マッピング戦略を定義してください。Amazon Aurora DSQL がサポートするデータ型については、Amazon Aurora DSQL ユーザーガイド を参照してください。 - トランザクション分離レベル – Amazon Aurora DSQL ターゲットでは、データ整合性のために
REPEATABLE_READが必要です。
Step Functions ステートマシンを作成する
Step Functions ステートマシンが移行ワークフローを制御します。ステートマシンは AWS DMS タスクを開始し、その状態を監視します。AWS DMS タスクが完了すると、テーブルマッピングを抽出してテーブル名を AWS Glue ジョブに渡します。その後、AWS Glue ジョブを起動します。
次の図は、ステートマシンのワークフローを示しています。
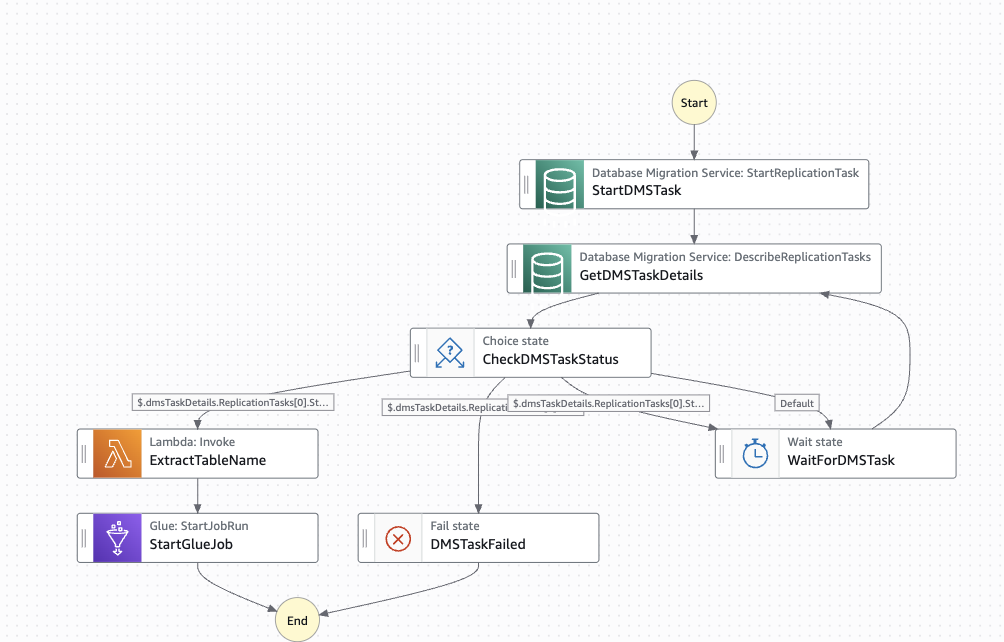
ステートマシンワークフローの特徴
- AWS DMS の自動開始 – レプリケーションタスクをプログラムで開始します。
- 進行状況の監視 – AWS DMS タスクの状態を 60 秒ごとにポーリングします。
- 完了の検出 –
stoppedステータスと進行状況 100% を待ちます。 - エラー処理 – 失敗した AWS DMS タスクを適切に処理します。
- Lambda 連携 – AWS Glue ジョブ向けにテーブル情報を抽出します。
- AWS Glue ジョブの起動 – テーブルパラメータを指定して AWS Glue ETL ジョブを開始します。
セットアップの手順
ステートマシンを構成するには、次のステップを実行します。
- Step Functions コンソールで、[Create state machine] を選択します。
- [Write your workflow in code] を選択し、ステートマシン定義を入力します。完全なステートマシン定義については、GitHub の sample-oracle-to-aurora-dsql-migration リポジトリを参照してください。
- 定義内の Amazon リソースネーム (ARN) とジョブ名を更新します。
- AWS DMS タスクの ARN を、自分のタスクの ARN に置き換えます。
- Lambda 関数の ARN を、自分の関数の ARN に置き換えます。
- AWS Glue ジョブ名を、自分のジョブ名に置き換えます。
- ステートマシンを作成する前に、参照する ARN が存在することを確認します。
- 次の権限を持つ IAM 実行ロールを作成します。
dms:StartReplicationTask。dms:DescribeReplicationTasks。lambda:InvokeFunction。glue:StartJobRun。CloudWatchLogsDeliveryFullAccessPolicy(ステートマシンの実行ログを保存するため)。
ステートマシンのステート
ステートマシンは、次のステートを通じて移行を制御します。
| ステート | タイプ | 目的 |
StartDMSTask |
Task | DMS レプリケーションタスクを開始する |
GetDMSTaskDetails |
Task | レプリケーションタスクの状態を取得する |
CheckDMSTaskStatus |
Choice | ステータス (stopped、failed、running) に応じて分岐する |
WaitForDMSTask |
Wait | 60 秒ごとにポーリングする |
DMSTaskFailed |
Fail | 失敗したタスクのエラー処理 |
ExtractTableName |
Task | Lambda を呼び出してテーブル名を取得する |
StartGlueJob |
Task | テーブル名パラメータを指定して AWS Glue ETL ジョブを起動する |
Step Functions のセットアップと AWS DMS との統合パターンの詳細については、AWS Step Functions デベロッパーガイド および Create and run AWS DMS tasks using AWS Step Functions を参照してください。
セキュリティに関する考慮事項
このソリューションでは、機密データを扱う可能性のある複数の AWS サービスを使用します。次のセキュリティのベストプラクティスに従ってください。
責任共有モデル
このアーキテクチャは AWS 責任共有モデル に従います。責任は次のように分担されます。
| サービス | AWS の管理範囲 | お客様の管理範囲 |
| Amazon Aurora DSQL | データベースエンジン、パッチ適用、高可用性、インフラストラクチャのセキュリティ | IAM ポリシー、VPC エンドポイントの構成、暗号化キーの選択 |
| Amazon S3 | ストレージインフラストラクチャ、耐久性、可用性 | バケットポリシー、暗号化の構成、アクセス制御、ブロックパブリックアクセス |
| AWS DMS | レプリケーションインスタンスの OS、エンジンのパッチ適用 | エンドポイントのセキュリティ、SSL/TLS の構成、ネットワークアクセス |
セキュリティ実装の優先順位
データ移行を開始する前に、次の順序でセキュリティ対策を実装してください。
- S3 バケットの暗号化 (SSE-KMS) とブロックパブリックアクセスを構成します。
- 各サービス (AWS DMS、Lambda、AWS Glue、Step Functions) に最小権限の IAM ロールを作成します。
- カスタマーマネージド KMS キーで Amazon Aurora DSQL クラスターの暗号化を有効にします。
- データがパブリックインターネットを経由しないように、Amazon S3 と AWS Glue の VPC エンドポイントを構成します。
- 監査とモニタリングのために、AWS CloudTrail と Amazon CloudWatch のログ記録を有効にします。
- すべてのデータベース接続で SSL/TLS が強制されていることを確認します。
セキュリティ検証の手順
デプロイ後、次の点を確認します。
さらに、次の点を確認します。
- 本番環境の IAM ポリシーにワイルドカード (
*) リソースが含まれていないこと。 - DMS レプリケーションインスタンスがパブリック IP を持たないプライベートサブネットに配置されていること。
- すべての JDBC 接続文字列で、Amazon Aurora DSQL への接続に
sslmode=requireが使われていること。 - 認証トークンが設定した期間内 (AWS は 1 時間を推奨) に失効すること。
移行中のデータ保護
- AWS DMS エンドポイントで転送時の暗号化を有効にします (Oracle ソースには SSL/TLS、Amazon S3 ターゲットには SSE-KMS)。
- 認証トークンをログに出力しないでください。有効期間の短いトークン (1 時間) を使い、設定は環境変数または AWS Secrets Manager に保存します。
aws:SecureTransport条件を使って、暗号化されていない通信を拒否する S3 バケットポリシーを適用します。完全なバケットポリシーについては、GitHub の sample-oracle-to-aurora-dsql-migration リポジトリを参照してください。- AWS Glue ジョブの IAM ロールを、特定の S3 プレフィックスと Amazon Aurora DSQL クラスターに限定します。ワイルドカードの ARN は避けてください。
- KMS キーポリシーを使って、移行データを暗号化・復号できるプリンシパルを制御します。
脅威モデル
次の表は、このアーキテクチャで特定し、緩和した脅威を示しています。
| 脅威 | 緩和策 |
| 過剰な権限を持つ IAM ロール | すべての IAM ポリシーを、ワイルドカードではなく特定のリソース ARN に限定します。 |
| テーブル名を介した SQL インジェクション | テーブル名を SQL ステートメントで使用する前に、正規表現 ^[a-zA-Z0-9_]{1,64}$ で入力を検証します。 |
| 認証トークンの盗難やリプレイ | 有効期間の短いトークン (有効期限 1 時間) を使い、ログには出力せず、認証情報はコードではなく環境変数に保存します。 |
| S3 中間ストレージへの不正アクセス | ブロックパブリックアクセスを有効にし、バケットポリシーを特定の IAM ロールに限定し、SSE-KMS 暗号化を使用します。 |
コードのセキュリティレビュー
本記事のすべてのコードサンプルは、入力検証、安全な認証処理、最小権限のアクセスパターン、インジェクション攻撃への防御を対象に、手動でセキュリティレビューを実施しています。レビューは、Bandit 1.7 (Python) と ESLint security plugin (JavaScript) による静的解析を使って行いました。
検出結果: Critical または High の重大度の問題は見つかりませんでした。Medium の検出結果 (情報レベルのログ出力) はレビューのうえ、サンプルコードとして妥当と判断しました。
本番環境にデプロイする前に、Amazon Inspector や同等のツール (Bandit (Python)、ESLint security plugin (JavaScript) など) で独自に静的解析スキャンを実行し、組織のセキュリティ基準に照らして検証してください。
Lambda のセキュリティガイドライン
- インターネットアクセスのない VPC プライベートサブネットに関数をデプロイします。AWS サービスには VPC エンドポイントを使用します。
- AWS Key Management Service (AWS KMS) を使って環境変数を暗号化します。
- リソースベースのポリシーを適用し、呼び出しを Step Functions のみに制限します。
- 実行ロールには最小権限の原則を適用します (
dms:DescribeReplicationTasksとdms:DescribeTableStatisticsのみ)。 - 予約済み同時実行数を設定し、呼び出しの暴走を防ぎます。
Step Functions のセキュリティガイドライン
- AWS KMS カスタマーマネージドキーを使って、ステートマシンの保管時の暗号化を有効にします。
- 実行履歴のために、暗号化を有効にした Amazon CloudWatch Logs を有効にします。
- ステートマシンの入力や出力で機密データ (トークン、パスワード) を渡さないようにします。AWS Systems Manager Parameter Store または AWS Secrets Manager を使用します。
- 実行ロールが最小権限に従っていることを確認します (AWS DMS、Lambda の呼び出し、AWS Glue の StartJobRun の権限のみ)。
- IAM リソースベースのポリシーを使って、ステートマシンへのアクセスを制限します。
クリーンアップ
今後の課金を避けるため、このチュートリアルで作成したリソースを削除します。
- Step Functions コンソールで、対象のステートマシンを選択し、[Delete] を選択します。
- Lambda コンソールで、対象の関数を選択し、[Actions]、[Delete] の順に選択します。
- AWS Glue コンソールで、対象の ETL ジョブを選択し、[Action]、[Delete job] の順に選択します。
- AWS DMS コンソールで、次のリソースをこの順序で削除します。
- 移行タスク。
- エンドポイント (ソースとターゲット)。
- レプリケーションインスタンス。
- Amazon S3 コンソールで、移行用バケットを空にして削除します。
- Amazon Aurora DSQL コンソールで、対象のクラスターを選択し、[Delete] を選択します。
- IAM コンソールで、このソリューション用に作成した IAM ロールとポリシーを削除します。
カスタマーマネージド KMS キーを使用した場合は、まだ必要かどうかを評価し、適切であれば削除をスケジュールします。
まとめ
本記事では、AWS DMS、Step Functions、Lambda、AWS Glue を使った自動化のアプローチで、Oracle から Amazon Aurora DSQL へ移行する手順を説明しました。このソリューションは、Amazon Aurora DSQL のサーバーレスアーキテクチャ特有の課題に対応します。Amazon S3 を中間ストレージとして使い、ワークフロー全体に十分なエラー処理を組み込むことで、手作業や運用の複雑さを抑えつつ、信頼性の高いデータ移行を実現できます。
Amazon Aurora DSQL の進化に合わせて、この移行フレームワークはデータベースモダナイゼーションを進めるうえで確かな基盤になります。インフラストラクチャのコストと管理の負荷を抑えながら、Amazon Aurora DSQL を最大限に活用できます。
この移行アプローチを始めるには、次の手順を実行します。
- GitHub の sample-oracle-to-aurora-dsql-migration リポジトリをクローンします。
- テストテーブルを使って、AWS アカウントに Step Functions ワークフローをデプロイします。
- 本番のワークロード全体に拡張します。
ご質問やフィードバックがあれば、コメントで共有するか、AWS re:Post community をご覧ください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Kenta Nagasue がレビューしました。