Amazon Web Services ブログ
Amazon SageMaker を使用したレイクハウスのアーキテクチャ選択ガイド
本記事は 2026 年 1 月 12 日 に公開された「Navigating architectural choices for a lakehouse using Amazon SageMaker」を翻訳したものです。
組織がデータを活用して意思決定やイノベーションを推進する動きは加速しています。ペタバイト規模の情報を扱う中で、従来はデータレイクとデータウェアハウスという 2 つの異なるパラダイムに分かれてきました。それぞれ特定のユースケースに強みがある一方、データ資産間に意図しない障壁を生むことがあります。
データレイクは Amazon Simple Storage Service (Amazon S3) などのオブジェクトストレージ上に構築されることが多く、多様なデータ形式とスキーマ・オン・リード機能をサポートする柔軟性を提供します。そのため、Apache Spark、Trino、Presto などの様々な処理フレームワークが同じデータにクエリできるマルチエンジンアクセスが可能になります。一方、データウェアハウス (Amazon Redshift など) は、ACID (原子性、一貫性、分離性、耐久性) 準拠、パフォーマンス最適化、簡単なデプロイメントに優れており、構造化された複雑なクエリに適しています。データ量の増加と分析ニーズの複雑化に伴い、組織はデータレイクとデータウェアハウスのサイロを橋渡しし、両方のパラダイムの強みを活用しようとしています。レイクハウスアーキテクチャはデータ管理と分析を統合的に扱うアプローチとして注目されています。
時間の経過とともに、いくつかの異なるレイクハウスアプローチが登場しました。本記事では、ニーズに合った適切なレイクハウスパターンの評価と選択方法を紹介します。
データレイク中心のレイクハウスアプローチは、オブジェクトストレージ上に構築された従来のデータレイクのスケーラビリティ、コスト効率、柔軟性から始まります。目標は、主にオープンテーブルフォーマット (Apache Hudi、Delta Lake、Apache Iceberg) を通じて、従来データベースにあったトランザクション機能とデータ管理レイヤーを追加することです。オープンテーブルフォーマットはデータレイクの単一テーブル操作に ACID 保証を導入する点で大きく進歩しましたが、複雑な参照整合性制約やジョインを伴うマルチテーブルトランザクションの実装は依然として困難です。オブジェクトストレージ上のペタバイト規模のファイルに対するクエリは、分散クエリエンジンを介することが多く、高度に最適化・インデックス化・マテリアライズ化されたデータウェアハウスと比較すると、高い同時実行性でのインタラクティブクエリが遅くなる可能性があります。オープンテーブルフォーマットはコンパクションとインデックスを導入していますが、成熟した独自仕様のデータウェアハウスに見られる高度なストレージ最適化機能は、データレイク中心のアーキテクチャではまだ発展途上です。
データウェアハウス中心のレイクハウスアプローチは充実した分析機能を提供しますが、相互運用性に大きな課題があります。データウェアハウスは外部アクセス用に JDBC および ODBC ドライバーを提供していますが、基盤となるデータは独自仕様の形式のままであり、複雑な ETL や API レイヤーなしでは外部ツールやサービスが直接アクセスすることが困難です。データの重複とレイテンシーにつながる可能性があります。データウェアハウスアーキテクチャはオープンテーブルフォーマットの読み取りをサポートする場合がありますが、書き込みやトランザクションレイヤーへの参加能力は限定的です。真の相互運用性が制限され、意図しないデータサイロが生まれる可能性があります。
AWS では、データウェアハウスとデータレイクの両方への統合アクセスを実現するモダンでオープンなレイクハウスアーキテクチャを構築できます。このアプローチにより、データの単一の信頼できるソースを維持しながら、高度な分析、機械学習 (ML)、生成 AI アプリケーションを構築できます。データレイクかデータウェアハウスかを選ぶ必要はありません。既存の投資を活用し、両方のパラダイムの強みを維持しつつ、それぞれの弱点を解消できます。AWS のレイクハウスアーキテクチャは、Apache Hudi、Delta Lake、Apache Iceberg などのオープンテーブルフォーマットを採用しています。
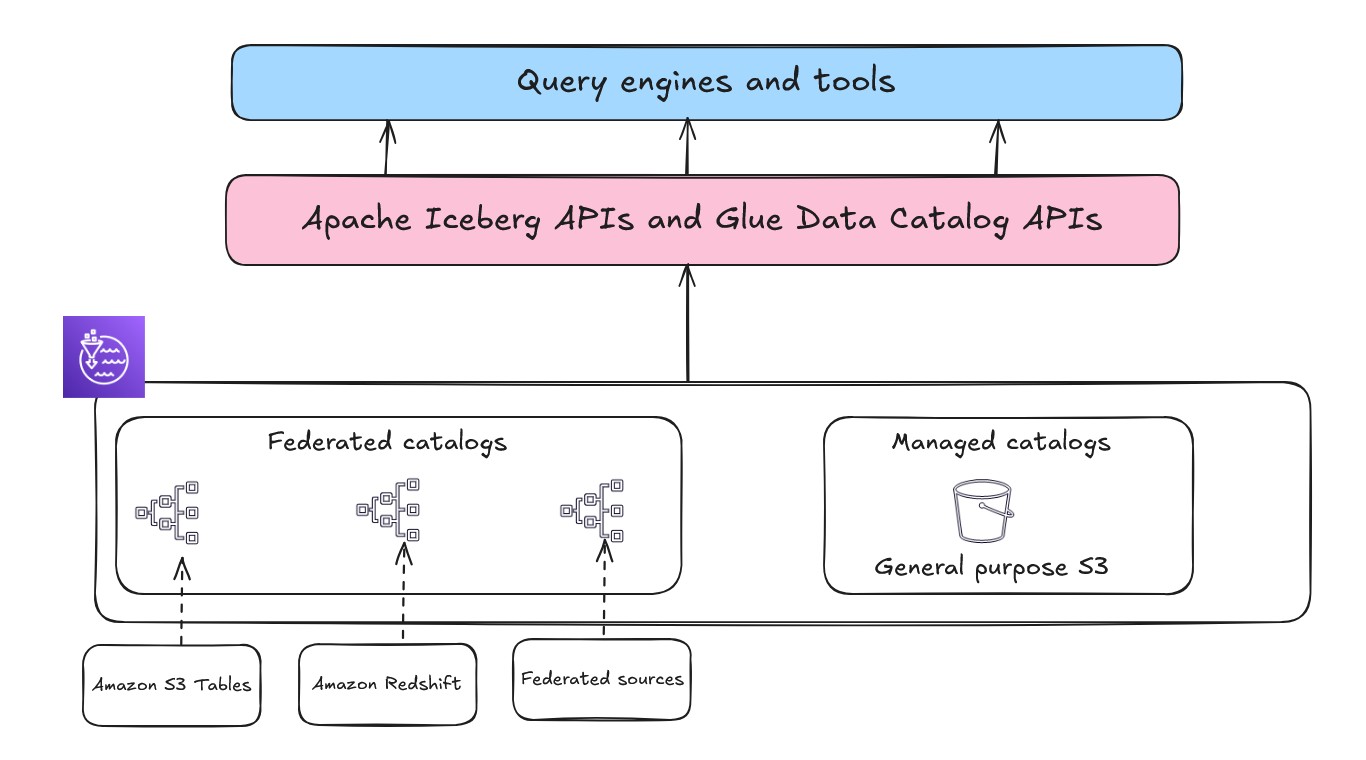
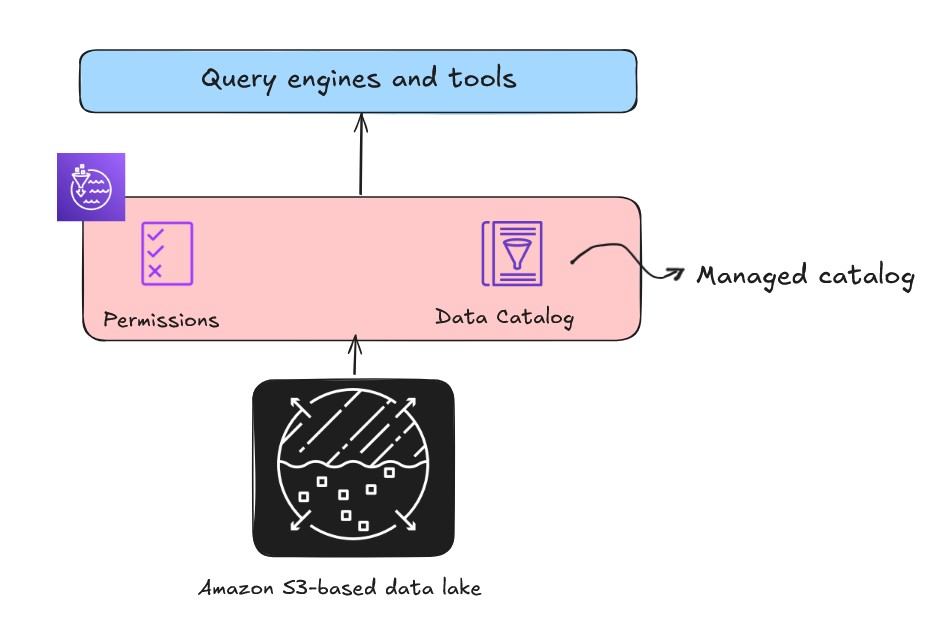
次世代の Amazon SageMaker でレイクハウスの導入を加速できます。SageMaker はデータへの統合アクセスを備えた分析と AI の統合エクスペリエンスを提供します。SageMaker は Apache Iceberg と完全互換のオープンレイクハウスアーキテクチャ上に構築されています。Apache Iceberg REST API のサポートを拡張することで、SageMaker は様々な Apache Iceberg 互換クエリエンジンやツール間の相互運用性とアクセシビリティを大幅に向上させています。このアーキテクチャの中核には、AWS Glue Data Catalog と AWS Lake Formation 上に構築されたメタデータ管理レイヤーがあり、統合ガバナンスと一元的なアクセス制御を提供します。
Amazon SageMaker レイクハウスアーキテクチャの基盤
Amazon SageMaker のレイクハウスアーキテクチャには、統合データプラットフォームを構成する 4 つの主要コンポーネントがあります。
- ワークロードパターンと要件に適応する柔軟なストレージ
- すべてのメタデータの単一の信頼できるソースとなるテクニカルカタログ
- すべてのデータ資産にわたるきめ細かなアクセス制御を備えた統合権限管理
- Apache Iceberg REST API 上に構築された、ユニバーサル互換性のためのオープンアクセスフレームワーク
カタログと権限
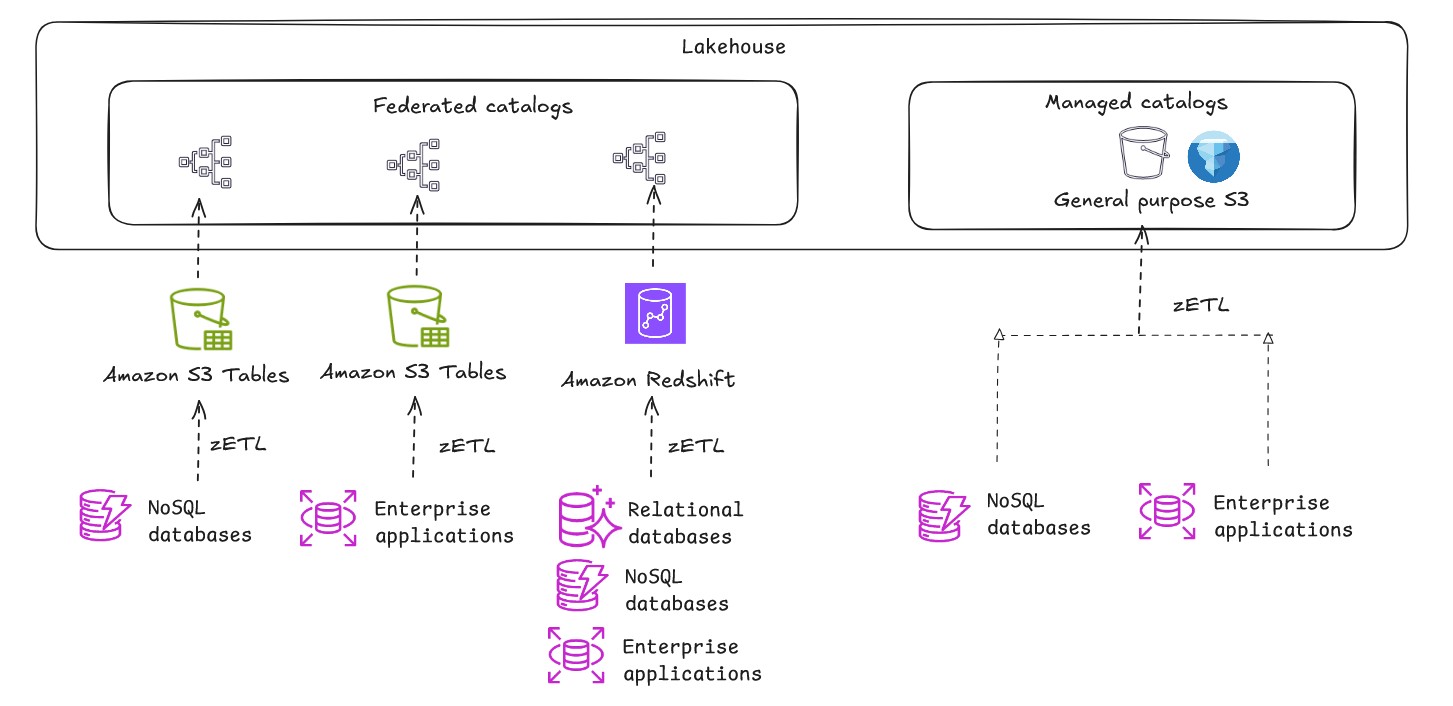
オープンレイクハウスを構築する際、メタデータの中央リポジトリであるカタログは、データ検出とガバナンスの重要なコンポーネントです。Amazon SageMaker のレイクハウスアーキテクチャには、マネージドカタログとフェデレーテッドカタログの 2 種類のカタログがあります。
- マネージドカタログは、レイクハウスがメタデータを管理し、データを汎用 S3 バケットに保存する形態です。
- フェデレーテッドカタログは、外部や既存のデータソースをマウント・接続し、データを移動せずに Amazon Redshift、Snowflake、Amazon DynamoDB などのデータソースに直接クエリできる形態です。詳細は「Data connections in the lakehouse architecture of Amazon SageMaker」を参照してください。
AWS Glue クローラーを使用して、Data Catalog にメタデータを自動的に検出・登録できます。Data Catalog はデータ資産のスキーマとテーブルメタデータを保存し、ファイルを論理テーブルに変換します。データがカタログ化されたら、次の課題はアクセス制御です。フォルダごとに複雑な S3 バケットポリシーを使用することもできますが、管理とスケーリングが困難です。Lake Formation は Data Catalog 上にデータベーススタイルの一元的な権限モデルを提供し、個々のユーザーやロールに対して行、列、セルレベルのきめ細かなアクセスを付与または取り消す柔軟性を備えています。
Apache Iceberg REST API によるオープンアクセス
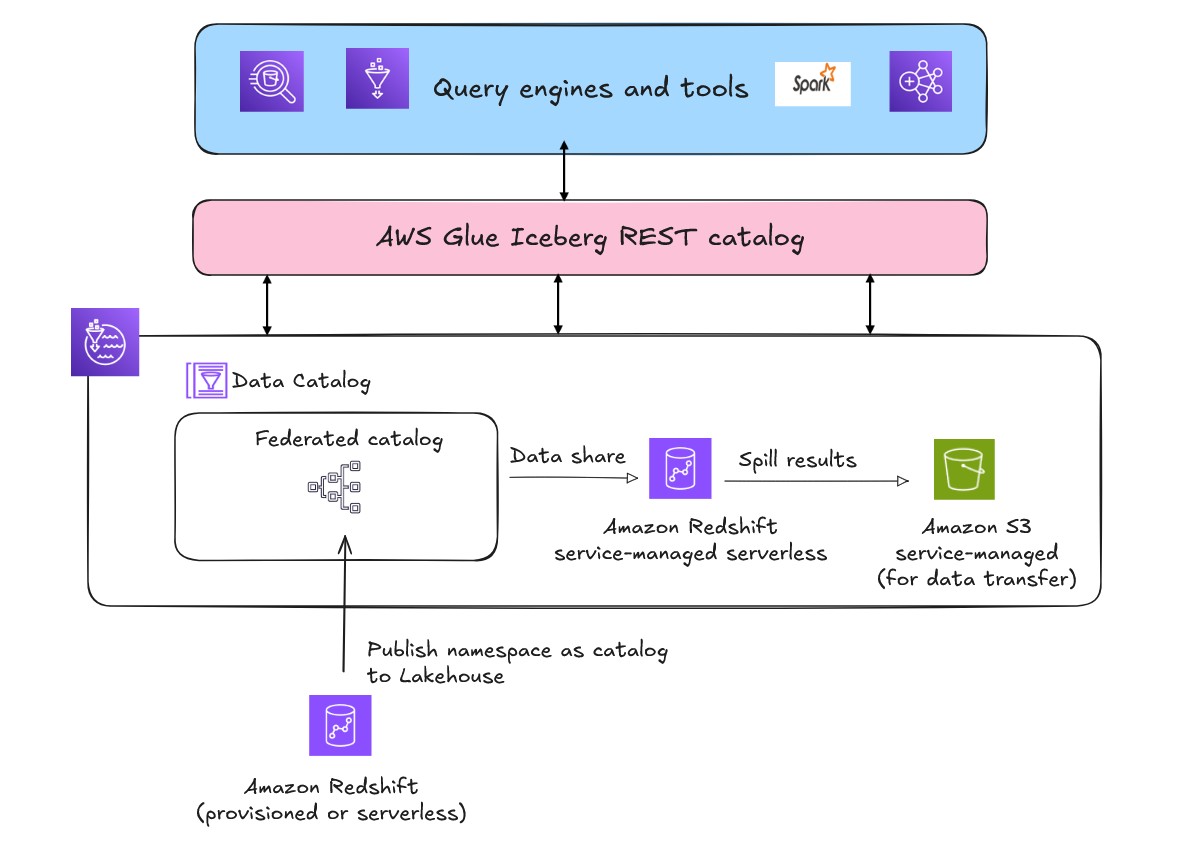
前述のレイクハウスアーキテクチャ (以下の図の) は、サービスエンドポイントを通じて AWS Glue Iceberg REST カタログも使用しています。OSS 互換性を提供し、Spark やその他のオープンソース分析エンジン間で Iceberg テーブルメタデータを管理するための相互運用性を向上させます。テーブルフォーマットとユースケースの要件に基づいて適切な API を選択できます。
本記事では、データレイクとデータウェアハウスを最適に活用してスケーラブルで高パフォーマンスなデータソリューションを構築する方法に焦点を当て、様々なレイクハウスアーキテクチャパターンを探ります。
AWS でレイクハウスにデータを取り込む
レイクハウスアーキテクチャを構築する際、データのアクセスと統合には 3 つの異なるパターンから選択でき、それぞれ異なるユースケースに固有の利点を提供します。
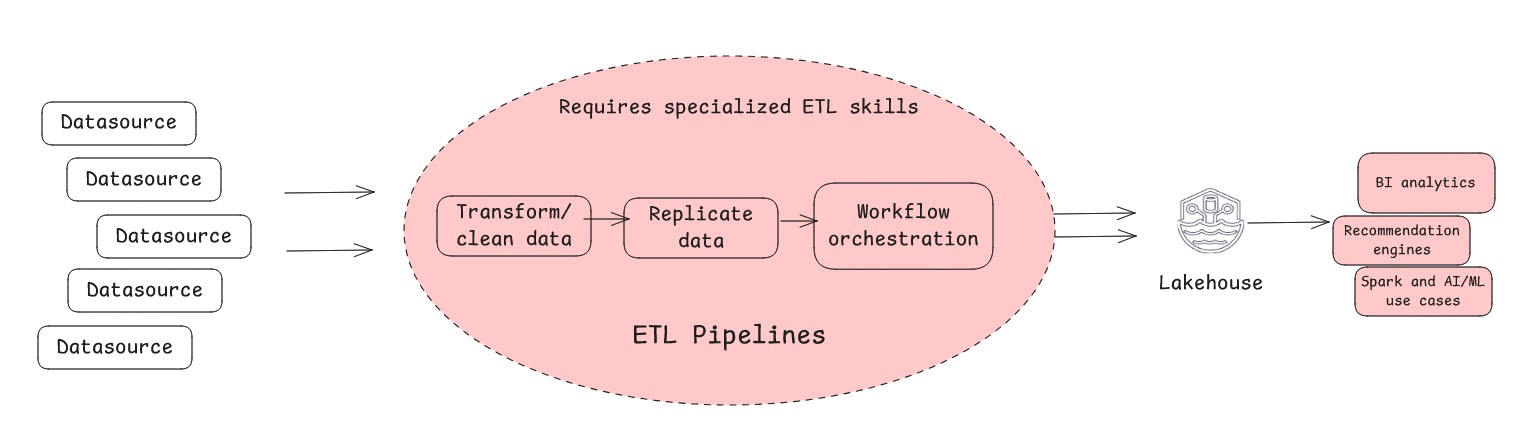
- 従来の ETL は、データを抽出し、変換してレイクハウスにロードする従来の方法です。
使用すべきケース:
-
- 複雑な変換が必要で、パフォーマンス向上のためにダウンストリームアプリケーション向けに高度にキュレーションされ最適化されたデータセットが必要な場合
- 過去データの移行が必要な場合
- 大規模なデータ品質の適用と標準化が必要な場合
- レイクハウスに高度にガバナンスされたキュレーション済みデータが必要な場合
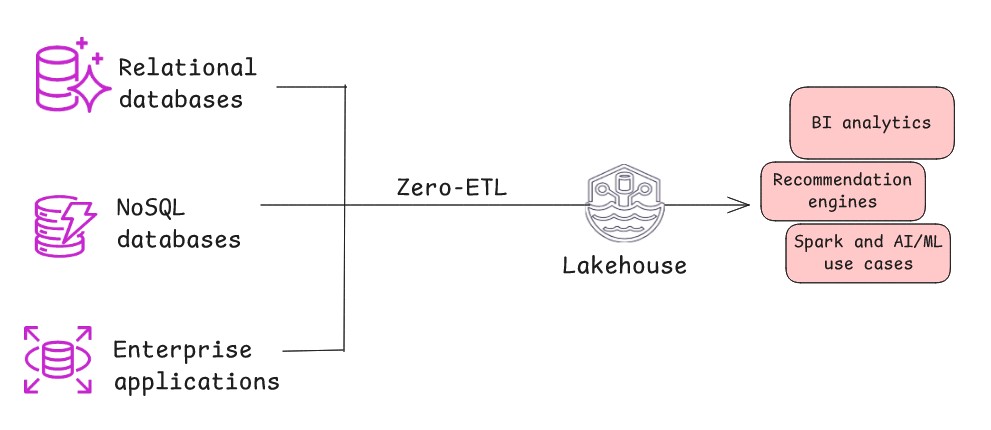
- Zero-ETL は、ソースシステムからレイクハウスへデータを最小限の手動介入やカスタムコードで自動的かつ継続的にレプリケートするモダンなアーキテクチャパターンです。内部的には、変更データキャプチャ (CDC) を使用して、ソースからターゲットへのすべての新規挿入、更新、削除を自動的にストリーミングします。このアーキテクチャパターンは、ソースシステムが高いデータクリーンネスと構造を維持しており、ロード前の重い変換の必要性が最小限の場合、またはデータの精製と集約がレイクハウス内のターゲット側で行える場合に効果的です。Zero-ETL は最小限の遅延でデータをレプリケートし、変換ロジックはインサイトが生成される場所に近いターゲット側で、より効率的なロード後フェーズとして実行されます。
使用すべきケース:
-
- 運用の複雑さを軽減し、準リアルタイムとバッチの両方のユースケースでデータレプリケーションを柔軟に制御する必要がある場合
- カスタマイズが限定的で十分な場合。Zero-ETL は最小限の作業を意味しますが、レプリケートされたデータに軽い変換が必要な場合もあります
- 専門的な ETL の専門知識の必要性を最小限に抑えたい場合
- 処理遅延なしでデータの鮮度を維持し、データの不整合リスクを軽減する必要がある場合。Zero-ETL はインサイトまでの時間を短縮します
- データフェデレーション (データ移動なしのアプローチ) は、データを単一の集中場所に物理的に移動またはコピーせずに、複数の異なるソースからデータをクエリ・結合できる方法です。このクエリインプレースアプローチにより、クエリエンジンが外部ソースシステムに直接接続し、クエリを委任・実行し、結果をオンザフライで結合してユーザーに提示できます。このアーキテクチャパターンの効果は、システム間のネットワークレイテンシー、ソースシステムのパフォーマンス能力、クエリエンジンの述語のプッシュダウン能力の 3 つの要因に依存します。このデータ移動なしのアプローチにより、ソースデータへのリアルタイムアクセスを提供しながら、データの重複とストレージコストを大幅に削減できます。
使用すべきケース:
-
- オペレーショナル分析のためにソースシステムに直接クエリする必要がある場合
- レイクハウス内のストレージスペースと関連コストを節約するためにデータを複製したくない場合
- 即時のデータ可用性とライブデータの一回限りの分析のために、クエリパフォーマンスとガバナンスの一部をトレードオフしてもよい場合
- データを頻繁にクエリする必要がない場合
AWS でのレイクハウスのストレージレイヤーを理解する
レイクハウスにデータを取り込む様々な方法を確認したところで、次の問題はデータの保存先です。以下の図のように、AWS ではデータレイク (Amazon S3 または Amazon S3 Tables) またはデータウェアハウス (Redshift Managed Storage) にデータを保存してモダンなオープンレイクハウスを構築でき、ワークロード要件に基づいて柔軟性とパフォーマンスの両方を最適化できます。
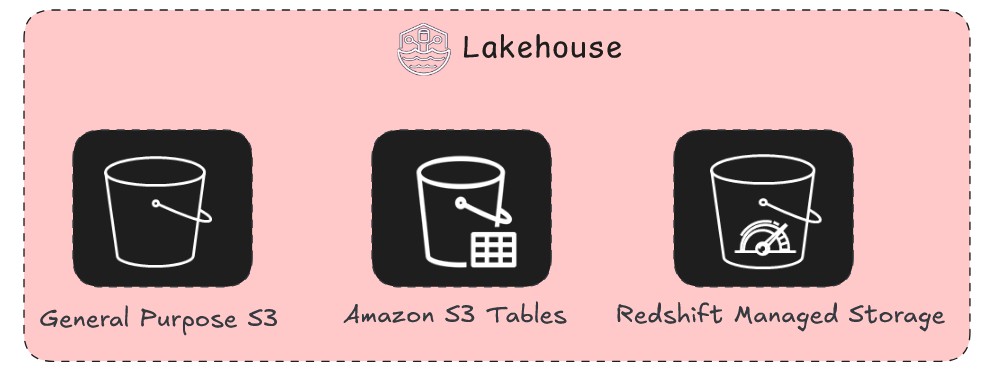
モダンなレイクハウスは単一のストレージ技術ではなく、それらの戦略的な組み合わせです。データの保存場所と方法は、ダッシュボードの応答速度から ML モデルの効率まで幅広く影響します。ストレージの初期コストだけでなく、データ取得の長期コスト、ユーザーが求めるレイテンシー、単一の信頼できるソースを維持するためのガバナンスも考慮が必要です。このセクションでは、データレイクとデータウェアハウスのアーキテクチャパターンを掘り下げ、各ストレージパターンをいつ使用すべきかの明確なフレームワークを提供します。かつては競合するアーキテクチャと見なされていましたが、モダンでオープンなレイクハウスアプローチは両方を活用して単一の強力なデータプラットフォームを構築します。
汎用 S3
Amazon S3 の汎用 S3 バケットは、オブジェクトの保存に使用される標準的な基本バケットタイプです。厳格な事前スキーマなしでネイティブ形式のデータを保存できる柔軟性を提供します。S3 バケットはストレージとコンピューティングを分離できるため、高度にスケーラブルな場所にデータを保存しながら、様々なクエリエンジンが独立してアクセス・処理できます。データの移動や複製なしに、ジョブに適したツールを選択できます。ストレージ容量のプロビジョニングや管理なしでペタバイト規模のデータを保存でき、階層型ストレージクラスにより、アクセス頻度の低いデータをより手頃なストレージに自動的に移動して大幅なコスト削減を実現します。
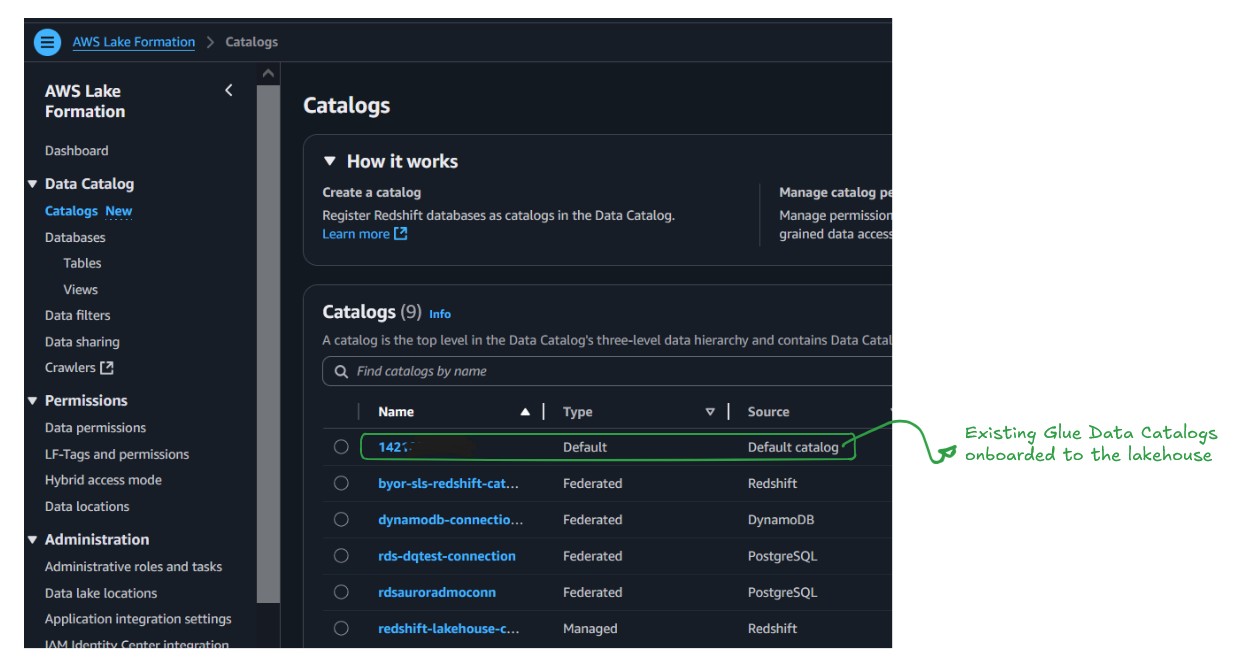
既存の Data Catalog はマネージドカタログとして機能します。AWS アカウント番号で識別されるため、既存の Data Catalog の移行は不要で、レイクハウスですでに利用可能であり、以下の図のように新しいデータのデフォルトカタログになります。
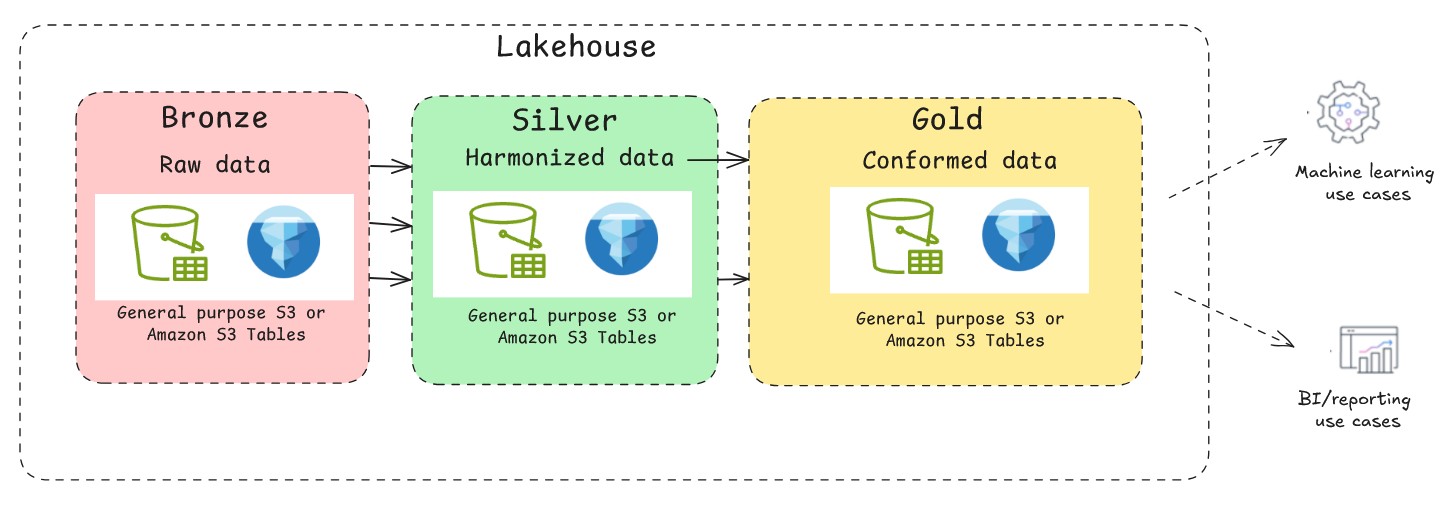
汎用 S3 上の基本的なデータレイクは、追記専用ワークロードに非常に効率的です。ただし、ファイルベースの性質上、従来のデータベースのトランザクション保証が欠けています。Apache Hudi、Delta Lake、Apache Iceberg などのオープンソースのトランザクショナルテーブルフォーマットを活用すると、この課題を解決できます。テーブルフォーマットによりマルチバージョン同時実行制御(MVCC)を実装でき、複数のリーダーとライターが競合なく同時に操作できます。スナップショット分離を提供するため、書き込み操作中でもリーダーはデータの一貫したビューを参照できます。以下の図は Apache Iceberg を使用した典型的なメダリオンアーキテクチャパターンを示しています。AWS で Apache Iceberg を使用してレイクハウスを構築する場合、Amazon S3 上のデータ保存には、セルフマネージド Iceberg を使用した汎用 S3 バケットと、フルマネージドの S3 Tables の 2 つの主要なアプローチから選択できます。それぞれに明確な利点があり、制御、パフォーマンス、運用負荷に対する具体的なニーズによって適切な選択が異なります。
セルフマネージド Iceberg を使用した汎用 S3
セルフマネージド Iceberg を使用した汎用 S3 バケットは、データと Iceberg メタデータファイルの両方を標準 S3 バケットに保存する従来のアプローチです。このオプションでは完全な制御を維持しますが、コンパクションやガベージコレクションなどの必須メンテナンスタスクを含む、Iceberg テーブルのライフサイクル全体を自分で管理する必要があります。
使用すべきケース:
- 最大限の制御: データライフサイクル全体を完全に制御できます。コンパクションのスケジュールや戦略の定義など、テーブルメンテナンスのあらゆる側面を微調整でき、特定の高パフォーマンスワークロードやコスト最適化に重要です。
- 柔軟性とカスタマイズ: 強力な社内データエンジニアリング専門知識を持ち、より幅広いオープンソースツールやカスタムスクリプトとの統合が必要な組織に最適です。Amazon EMR や Apache Spark を使用してテーブル操作を管理できます。
- 初期コストの低さ: Amazon S3 ストレージ、API リクエスト、メンテナンス用コンピューティングリソースの料金のみ発生します。継続的な自動最適化が不要な小規模または低頻度のワークロードでは、よりコスト効率が高くなる可能性があります。
注意: クエリパフォーマンスは最適化戦略に完全に依存します。コンパクションの継続的なスケジュールジョブがないと、データの断片化に伴いパフォーマンスが低下する可能性があります。効率的なクエリを確保するために、コンパクションジョブを監視する必要があります。
S3 Tables
S3 Tables は、分析ワークロードに最適化された S3 ストレージを提供し、大規模な表形式データを保存するための Apache Iceberg 互換性を備えています。S3 テーブルバケットとテーブルを Data Catalog と統合し、Lake Formation コンソールまたはサービス API で Lake Formation データロケーションとしてカタログを登録できます (以下の図の)。このカタログはフェデレーテッドレイクハウスカタログとして登録・マウントされます。
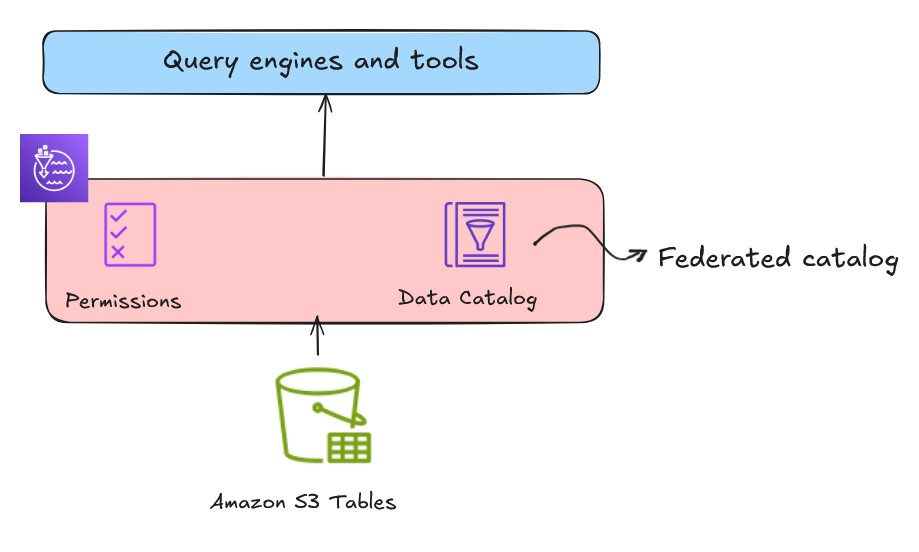
使用すべきケース:
- 運用の簡素化: S3 Tables はコンパクション、スナップショット管理、孤立ファイルのクリーンアップなどのテーブルメンテナンスタスクをバックグラウンドで自動的に処理します。カスタムメンテナンスジョブの構築・管理が不要になり、運用負荷を大幅に軽減できます。
- 自動最適化: S3 Tables はクエリパフォーマンスを向上させる組み込みの自動最適化を提供します。スモールファイル問題に対処するファイルコンパクションや、表形式データに特化したデータレイアウト最適化などのバックグラウンドプロセスが含まれます。ただし、自動化と柔軟性はトレードオフの関係にあります。コンパクション操作のタイミングや方法を制御できないため、特定のパフォーマンス要件を持つワークロードではクエリパフォーマンスにばらつきが生じる可能性があります。
- データ活用への集中: S3 Tables はエンジニアリングの負荷を軽減し、データの消費、データガバナンス、価値創造に焦点を移します。
- オープンテーブルフォーマットへの簡単な導入: Apache Iceberg の概念は初めてだが、データレイクでトランザクション機能を活用したいチームに適しています。
- 外部カタログ不要: 外部カタログを管理したくない小規模チームに適しています。
Redshift Managed Storage
データレイクはすべてのデータの中央の信頼できるソースとして機能しますが、すべてのジョブに最適なデータストアではありません。最も要求の厳しいビジネスインテリジェンスとレポーティングワークロードでは、データレイクのオープンで柔軟な性質がパフォーマンスの予測不可能性をもたらす可能性があります。望ましいパフォーマンスを確保するために、以下の理由でデータレイクからデータウェアハウスへキュレーション済みデータのサブセットを移行することを検討してください:
- 高同時実行 BI とレポーティング: 数百のビジネスユーザーがライブダッシュボードで複雑なクエリを同時に実行する場合、データウェアハウスは予測可能なサブ秒のクエリレイテンシーで高同時実行ワークロードを処理するよう特別に最適化されています。
- 予測可能なパフォーマンス SLA: 財務レポートや日次売上分析など、保証された速度でデータを配信する必要がある重要なビジネスプロセスでは、データウェアハウスが一貫したパフォーマンスを提供します。
- 複雑な SQL ワークロード: データレイクは強力ですが、多数のジョインや大規模な集約を伴う非常に複雑なクエリでは苦戦する可能性があります。データウェアハウスは複雑なリレーショナルワークロードを効率的に実行するために構築されています。
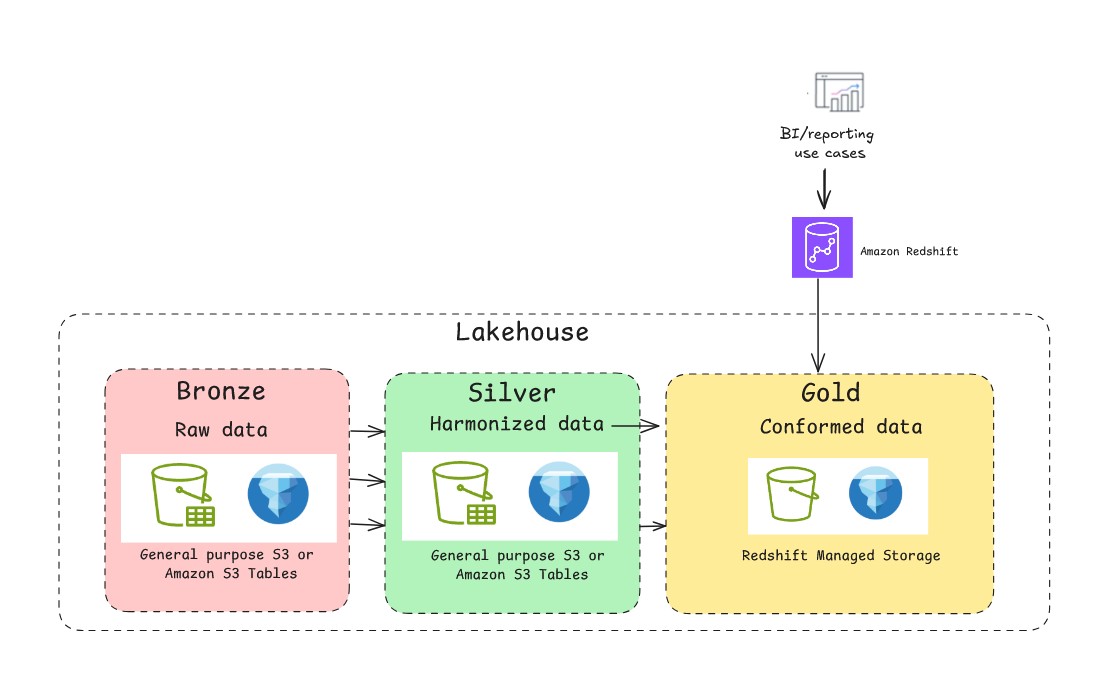
AWS のレイクハウスアーキテクチャは Redshift Managed Storage (RMS) をサポートしています。RMS は、Amazon Redshift が提供するフルマネージドのストレージオプションです。RMS ストレージは、データウェアハウジングワークロード向けの組み込みクエリ最適化、自動マテリアライズドビュー、頻繁に実行されるワークロード向けの AI 駆動の最適化とスケーリングなど、Amazon Redshift が提供する自動テーブル最適化をサポートしています。
フェデレーテッド RMS カタログ: 既存の Amazon Redshift データウェアハウスをレイクハウスにオンボード
既存の Amazon Redshift データウェアハウスでフェデレーテッドカタログを実装すると、データ移動を必要としないメタデータのみの統合が作成されます。このアプローチにより、既存のワークフローとの互換性を維持しながら、確立された Amazon Redshift への投資をモダンなオープンレイクハウスフレームワークに拡張できます。Amazon Redshift は階層的なデータ組織構造を使用しています:
- クラスターレベル: 名前空間から始まる
- データベースレベル: 複数のデータベースを含む
- スキーマレベル: データベース内のテーブルを整理する
既存の Amazon Redshift プロビジョンドまたはサーバーレスの名前空間を Data Catalog のフェデレーテッドカタログとして登録すると、この階層がレイクハウスのメタデータレイヤーに直接マッピングされます。AWS のレイクハウス実装は、基盤となるストレージメタデータを整理・マッピングする動的階層を使用して複数のカタログをサポートしています。
名前空間を登録すると、フェデレーテッドカタログは AWS リージョンとアカウント内のすべての Amazon Redshift データウェアハウスに自動的にマウントされます。登録プロセス中、Amazon Redshift はデータ共有に対応する外部データベースを内部的に作成します。エンドユーザーからはこの仕組みは完全に隠蔽されています。フェデレーテッドカタログを使用することで、データエコシステム全体にわたる即時の可視性とアクセシビリティを実現できます。フェデレーテッドカタログの権限は、同一アカウントとクロスアカウントアクセスの両方で Lake Formation によって管理できます。
フェデレーテッドカタログが特に効果を発揮するのは、Amazon Athena、Amazon EMR、オープンソース Spark などの外部 AWS エンジンから Amazon Redshift マネージドストレージにアクセスする場面です。Amazon Redshift は Amazon Redshift エンジンのみがネイティブに読み取れる独自仕様のブロックベースストレージを使用しているため、AWS はバックグラウンドでサービスマネージドの Amazon Redshift Serverless インスタンスを自動的にプロビジョニングします。このサービスマネージドインスタンスは、外部エンジンと Amazon Redshift マネージドストレージ間の変換レイヤーとして機能します。AWS は、登録されたフェデレーテッドカタログとサービスマネージドの Amazon Redshift Serverless インスタンス間に自動データ共有を確立し、安全で効率的なデータアクセスを実現します。AWS はデータ転送用のサービスマネージド Amazon S3 バケットもバックグラウンドで作成します。
Athena などの外部エンジンが Amazon Redshift フェデレーテッドカタログに対してクエリを送信すると、Lake Formation がリクエストサービスに一時的な認証情報を提供してクレデンシャルベンディングを処理します。クエリはサービスマネージドの Amazon Redshift Serverless を通じて実行され、自動的に確立されたデータ共有を通じてデータにアクセスし、結果を処理してサービスマネージドの Amazon S3 ステージングエリアにオフロードし、元のリクエストエンジンに結果を返します。
既存の Amazon Redshift ウェアハウスのフェデレーテッドカタログのコンピューティングコストを追跡するには、以下のタグを使用します。
aws:redshift-serverless:LakehouseManagedWorkgroup value: "True"
請求インサイトのために AWS 生成コスト配分タグを有効にするには、有効化手順に従ってください。AWS Billing でリソースのコンピューティングコストも確認できます。
使用すべきケース:
- 既存の Amazon Redshift への投資: フェデレーテッドカタログは、既存の Amazon Redshift デプロイメントを持ち、移行なしで複数のサービス間でデータを活用したい組織向けに設計されています。
- クロスサービスデータ共有: チームが既存の Amazon Redshift データウェアハウスのデータを異なるウェアハウス間で共有し、権限を一元管理できるように実装します。
- エンタープライズ統合要件: 確立されたデータガバナンスとの統合が必要な組織に適しています。レイクハウス機能を追加しながら、現在のワークフローとの互換性を維持します。
- インフラストラクチャの制御と料金: 予測可能なワークロードに対して既存のウェアハウスのコンピューティング容量を完全に制御できます。コンピューティング容量の最適化、オンデマンドとリザーブドキャパシティの料金の選択、パフォーマンスパラメータの微調整が可能です。一貫したワークロードに対してコストの予測可能性とパフォーマンス制御を提供します。
複数のカタログタイプを使用してレイクハウスアーキテクチャを実装する場合、パフォーマンスとコスト最適化の両方にとって適切なクエリエンジンの選択が重要です。本記事ではレイクハウスのストレージ基盤に焦点を当てていますが、Amazon Redshift データ操作を多用する重要なワークロードでは、可能な限り Amazon Redshift 内でクエリを実行するか、Spark を使用することを検討してください。複数の Amazon Redshift テーブルにまたがる複雑なジョインを外部エンジンで実行すると、エンジンが完全な述語のプッシュダウンをサポートしていない場合、コンピューティングコストが高くなる可能性があります。
その他のユースケース
マルチウェアハウスアーキテクチャの構築
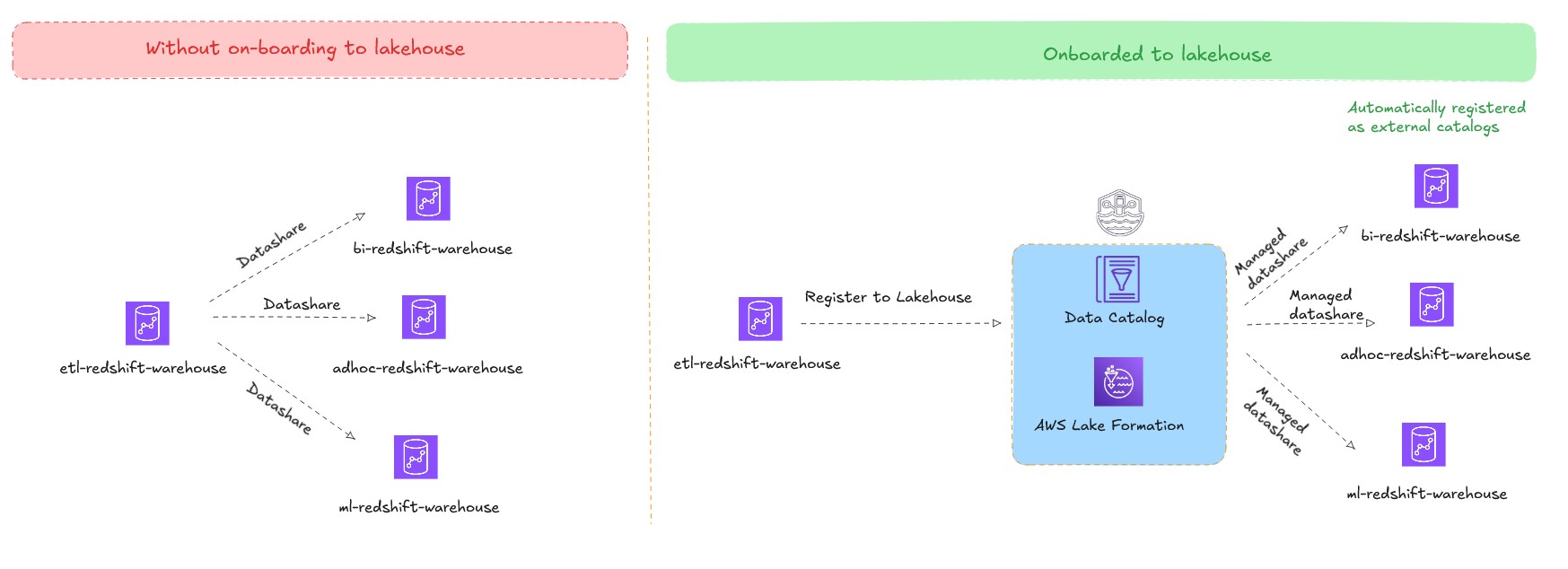
Amazon Redshift はデータ共有をサポートしており、ソースとターゲットの Amazon Redshift クラスター間でライブデータを共有できます。データ共有を使用すると、コピーの作成やデータの移動なしでライブデータを共有でき、ワークロード分離 (ハブアンドスポークアーキテクチャ) やクロスグループコラボレーション (データメッシュアーキテクチャ) などのユースケースが可能になります。レイクハウスアーキテクチャがない場合、ソースとターゲットの Amazon Redshift クラスター間に明示的なデータ共有を作成する必要があります。小規模なデプロイメントではデータ共有の管理は比較的簡単ですが、データメッシュアーキテクチャでは複雑になります。
レイクハウスアーキテクチャはこの課題に対応し、既存の Amazon Redshift ウェアハウスをフェデレーテッドカタログとして公開できます。フェデレーテッドカタログは、同一アカウントとリージョン内の他のコンシューマー Amazon Redshift ウェアハウスに外部データベースとして自動的にマウントされ、利用可能になります。データの単一コピーを維持しながら複数のデータウェアハウスからクエリでき、複数のデータ共有の作成と管理が不要になり、ワークロード分離でスケールできます。権限管理は Lake Formation を通じて一元化され、マルチウェアハウス環境全体のガバナンスが効率化されます。
パイプライン管理不要のペタバイト規模トランザクションデータの準リアルタイム分析:
Zero-ETL 統合は、OLTP データソースから Amazon Redshift、汎用 S3 (セルフマネージド Iceberg)、または S3 Tables へトランザクションデータをシームレスにレプリケートします。ETL パイプラインの維持が不要になり、データアーキテクチャの可動部品と潜在的な障害ポイントが削減されます。ビジネスユーザーは、前回の ETL 実行からの古いデータではなく、新鮮な運用データをすぐに分析できます。
Amazon Redshift ウェアハウスにレプリケートできる OLTP データソースの一覧は「Aurora zero-ETL integrations」を参照してください。
既存の Amazon Redshift ウェアハウス、セルフマネージド Iceberg を使用した汎用 S3、S3 Tables にレプリケートできるその他のサポートされるデータソースについては「Zero-ETL integrations」を参照してください。
まとめ
レイクハウスアーキテクチャは、データレイクとデータウェアハウスのどちらかを選ぶものではありません。両方のフレームワークが統合データアーキテクチャ内で共存し、異なる目的を果たす相互運用性のアプローチです。基本的なストレージパターンを理解し、効果的なカタログ戦略を実装し、ネイティブストレージ機能を活用することで、現在の分析ニーズと将来のイノベーションの両方をサポートする、スケーラブルで高パフォーマンスなデータアーキテクチャを構築できます。詳細は「The lakehouse architecture of Amazon SageMaker」を参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Woosuk Choi がレビューしました。