Amazon Web Services ブログ
株式会社ラクス: 伝票作成 AI エージェントの構築と、品質を支える評価設計の取り組み
本ブログは株式会社ラクス様と Amazon Web Services Japan 合同会社が共同で執筆しました。
株式会社ラクス (以下、ラクス) は、「IT サービスで企業の成長を継続的に支援します!」というミッションを掲げ、企業の業務効率化に貢献する複数のクラウドサービスを提供している IT 企業です。「楽楽精算」「楽楽明細」など複数のサービスを提供しています。
今回は AI エージェントプロダクト「伝票作成 AI エージェント」の開発に AWS を活用して迅速にプロダクトをリリースできた成果と、AWS の生成 AI イノベーションセンター (以下、GenAIIC) とともに取り組んだ「AI エージェントの評価設計」に関する知見についてご紹介します。
伝票作成 AI エージェントの提供開始
経費精算は多くの企業で日常的に発生する重要な業務です。しかし領収書の確認や入力、申請内容の紐づけといった作業は依然として手作業に依存しており、業務負荷やミスの原因となっています。こうした課題に対し、ラクスは「伝票作成 AI エージェント」をリリースしました。生成 AI を活用して経費精算業務そのものを自動化し、従来の入力支援を超えた業務プロセスの効率化を実現するものです。
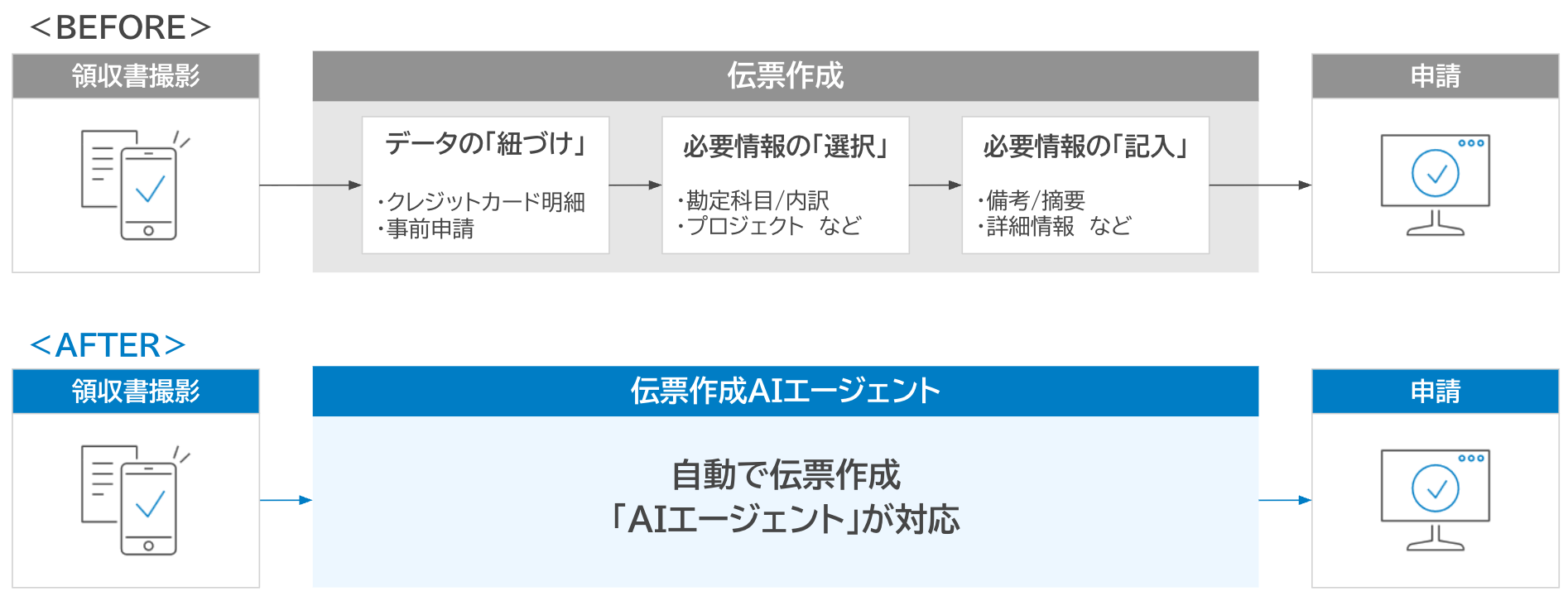
従来、ユーザーは領収書の内容を確認して金額や日付を入力しながら、事前申請やクレジットカード明細と照合する必要がありました。 伝票作成 AI エージェントはこうした一連の処理を横断的に実行し、領収書データや過去の申請履歴など複数の情報をもとに最適な申請内容を自動で生成します。
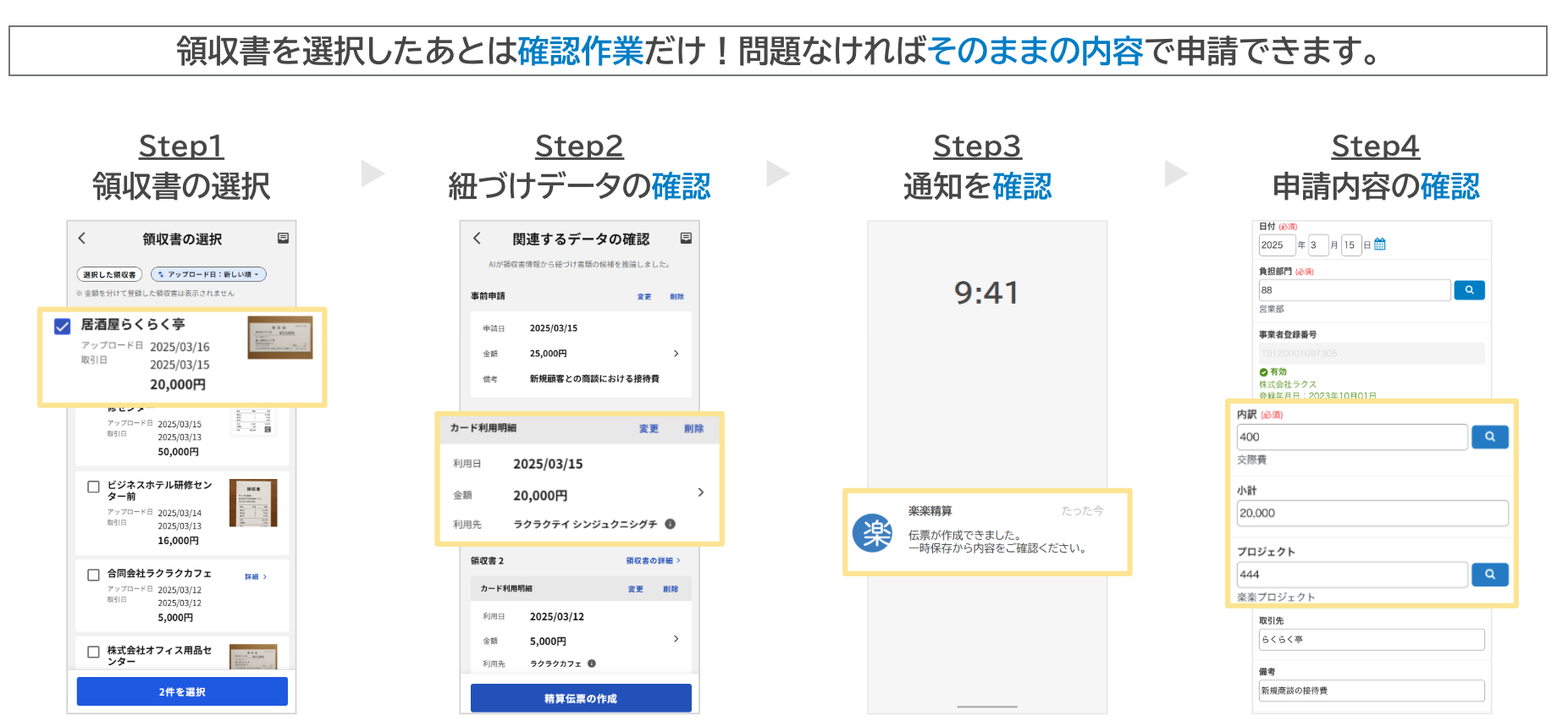
ユーザーは領収書を選択するだけで、必要な項目が補完された状態で申請を進められます。繰り返しが多い申請作業の時間短縮ができ、業務負荷を大幅に軽減します。
マネージドサービスを活用した迅速な AI エージェント機能リリース
伝票作成 AI エージェントは、社内知見を活かす・インフラの管理負荷を下げることを重点に置き、開発速度の最大化を目指しました。AWS のマネージドサービスを積極的に活用し、チームがエージェントのロジック開発に集中できる環境を整えています。 エージェント実行基盤には Amazon Elastic Kubernetes Service (Amazon EKS) を採用し、既存サービスでも運用実績のある Argo CD による GitOps で高速なリリースサイクルを実現しています。キーバリューストア・キャッシュには、運用工数を下げるためそれぞれ Amazon DynamoDB とAmazon ElastiCache Serverless for Valkey を採用しました。
アプリケーションアーキテクチャ
アプリケーション側では AI エージェントの関心事を明確に分離するため、Amazon EKS 上に 3 層のサービスを構成するアーキテクチャを採用しました。
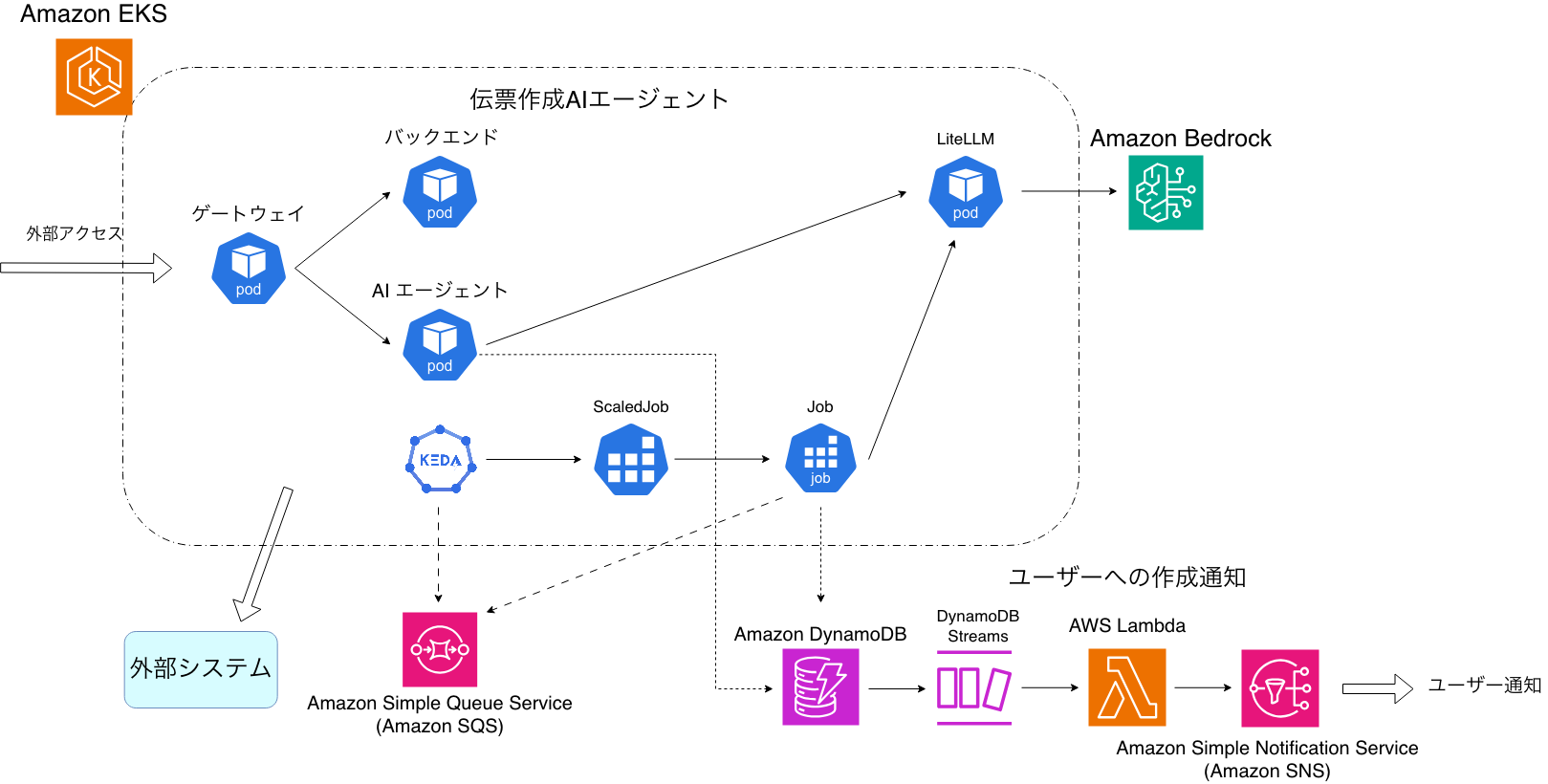
ゲートウェイ
すべての外部アクセスの入口となる API ゲートウェイです。認証・認可をこの層に集約し認証済みのコンテキストを後段のサービスへ伝搬します。バックエンドや AI エージェントは認証ロジックから解放され、ビジネスロジックに集中できます。内部サービスへはゲートウェイ経由でのみアクセスでき、外部から直接到達できない構成です。
バックエンド
楽楽精算の業務データへのアクセス層です。領収書、クレジットカード明細、事前申請、伝票履歴といった業務データを扱う API を提供します。プライベートな MCP サーバーも提供しており、AI エージェントがツールとして業務データにアクセスできます。AI エージェントとバックエンドを分離することで、エージェントフレームワーク・実装言語を柔軟に変更できる構成としています。
AI エージェント
Mastra フレームワークを用いたワークフロー実行基盤です。領収書データを起点に、クレジットカード明細の提案、事前申請との紐づけ、伝票項目の補完といった複数のステップを順に実行し、最終的な伝票を自動生成します。LLM の呼び出しには LiteLLM プロキシを経由し、モデルの切り替えやリトライ、フォールバックをインフラ層に委譲しています。AI エージェントのコードはビジネスロジックのみに集中できます。ワークフローには Human-in-the-Loop のステップを組み込んでいます。AI エージェントが提案を生成した後、ワークフローを一時停止してユーザーの確認を待ちます。ユーザーが内容を確認・選択すると、Amazon Simple Queue Service (Amazon SQS) にメッセージが送信されワークフローが再開されます。確認待ちの間はリソースを消費しないため、効率的なスケーリングを実現しています。
オブザーバビリティ
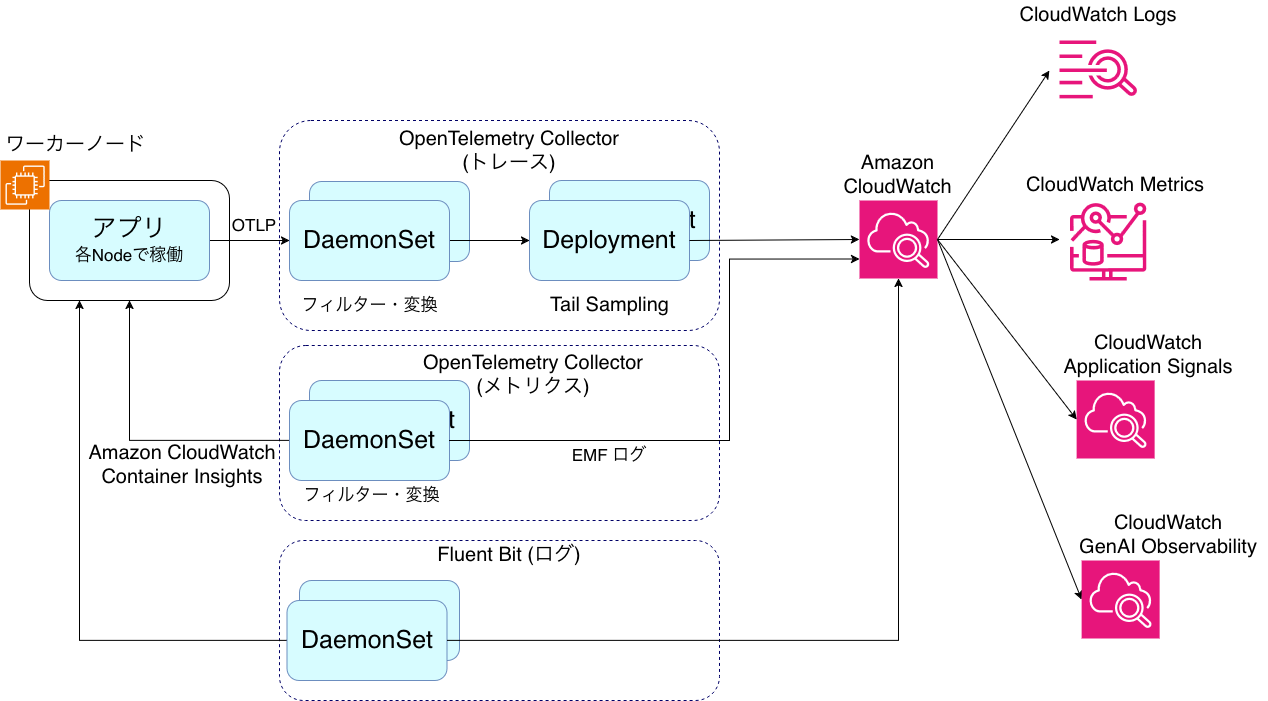
AI エージェントの評価には振る舞いを把握できるオブザーバビリティが重要です。Amazon EKS 上では Fluent Bit と OpenTelemetry Collector を用いて、不要なテレメトリをフィルタリングしつつログ・メトリクス・トレースを統合的に収集しています。
- ログ: Web 上の情報の豊富さを重視し Fluent Bit で CloudWatch Logs に送る構成にしています。
- メトリクス: OpenTelemetry Collector の AWS Container Insights Receiver と AWS CloudWatch EMF Exporter を利用し、EC2 メトリクスを収集・フィルタリング・CloudWatch Metrics に送信しています。
- トレース: AWS X-Ray OTLP エンドポイントへ送信し、Amazon CloudWatch Application Signals と CloudWatch Generative AI Observability で可視化しています。OpenTelemetry Collector の構成を工夫し、多段の tail-based sampling と loadbalancer exporter を組み合わせて、収集コストを抑えつつ必要な軌跡を追えるようにしています。
このように Amazon EKS 上で、スケーラビリティと変更柔軟性を担保した AI エージェントを設計し、継続的に改善するためのオブザーバビリティを整備しています。
AI エージェントの評価の難しさ
伝票作成 AI エージェントは、複数の AI エージェントが連携して一連の業務を完結させる構成です。ユーザーの入力を起点に、提案、照合、データ生成といった各 AI エージェントが順に実行され、それぞれの結果が統合されて伝票が自動生成されます。
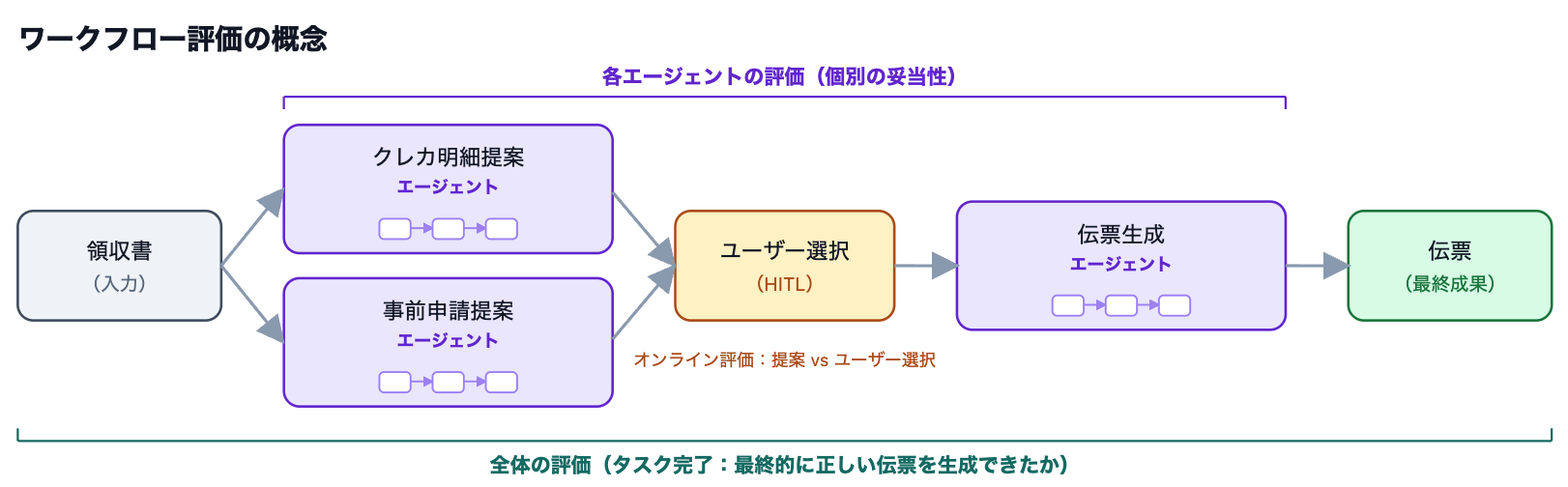
オフライン評価 (リリース前の性能評価) における課題
この構造においてまず課題となるのは、各 AI エージェントの正しさをどのように評価するかです。各 AI エージェントはそれぞれ独立して一定の妥当性を持つように見えても、それが本当に適切な判断であるかは、単体の出力だけでは判断できません。さらに、各 AI エージェントの結果が後続の処理に影響を与えるため、最終結果に問題があった場合でも、どの段階に起因するのかを特定することが難しくなります。 また、リリース前の段階では、AI エージェントのパフォーマンスを十分に把握したうえでリリースすることが求められます。特に伝票作成 AI エージェントにおいては、外貨処理や端数の扱い、入力の揺れといったエッジケースに対しても適切に動作するかを入念に確認する必要がありました。しかし、こうしたケースは実運用で初めて顕在化することも多く、事前にどこまで網羅的に検証できているかを判断することは容易ではありません。
オンライン評価 (リリース後の本番稼働における性能評価) における課題
リリース後の評価はさらに複雑です。伝票作成 AI エージェントからユーザーに提示されるのは途中段階の提案であり、正しさはユーザーの選択によって初めて確定します。AI エージェントの実行ログだけでは「その提案がユーザーにとって適切だったか」は判断できません。 加えて、AI エージェントが提示した候補がユーザーに選択されるかどうかは、別の処理として扱われ非同期的な状態遷移が発生します。その結果、単一のリクエストとレスポンスの対応関係だけでは処理全体を捉えることができず、従来のような単発の評価では実際の業務上の正しさを十分に測ることができません。
このように、複数の AI エージェントで構成され、かつユーザーの選択が結果に影響する構成では、各 AI エージェントの妥当性と最終的な成果の両方をどう評価するかが課題となります。
オフライン評価とオンライン評価の設計
これらの課題に対して私たちは AWS のアカウントチームおよび GenAIIC と協業し、AI エージェントの品質を担保するためのオフライン評価とオンライン評価を組み合わせた仕組みを設計しています。
評価設計における学び
GenAIIC との協議を通じて、評価設計に対する考え方が大きく変わりました。
当初は個々の LLM 推論の精度指標(正解率や F1 スコアなど)を個別に設計し精度を高めることに注力していました。しかし GenAIIC との議論で、まず問うべきは「AI エージェントがタスクを完了できるかどうか」であるという視点を得ました。個々の LLM 推論の精度がどれだけ高くても、最終的にユーザーの経費精算タスクを完遂できなければ意味がありません。精度向上はタスク完了を実現するための手段であり、ゴールそのものではないのです。
もうひとつの学びは、全体の評価フレームワークを先に整理する重要性です。個々の精度を積み上げて全体を捉えようとするのではなく、まずワークフロー全体を俯瞰して「何をもってタスク完了とするか」を定義し、そこから各 AI エージェントの評価指標へと分解していくアプローチを取りました。全体像を体系的に整理することで、各指標の位置づけや優先度が明確になり、効率的な評価設計が可能になりました。
オフライン評価の解決策
まずリリース前の段階では、エージェントの挙動を再現可能な形で評価するために、オフライン評価用のデータセットを構築しました。伝票作成 AI エージェントは、業務プロセスごとに分かれた 3 つのエージェント(クレジットカード明細の提案・事前申請の提案・伝票の生成)で構成されています。評価の起点に置いたのは、「ワークフロー全体(業務全体)として、最終的に正しい伝票を生成できたか」というタスク完了の観点です。そのうえで、この全体評価を各エージェントの単位へと分解しました。分解にあたっては、途中の Human-in-the-Loop での人間への確認をはさんでいます。
各 AI エージェントは LLM の単発の呼び出しではなく、複数の推論ステップからなる業務プロセスです。評価も個々の LLM 呼び出しの正否ではなく、AI エージェントが業務プロセスとして期待される出力を達成できたかを単位としています。これにより最終的な成果だけでなく、どの AI エージェントが成否に影響しているかを切り分けて評価できるようにしました。
具体的には、各 AI エージェントが解いている問題の性質に合わせて評価指標を設計しました。AI エージェントごとに起こりうる誤り方が違うため、指標も分けて確認しています。
クレジットカード明細提案エージェントの評価
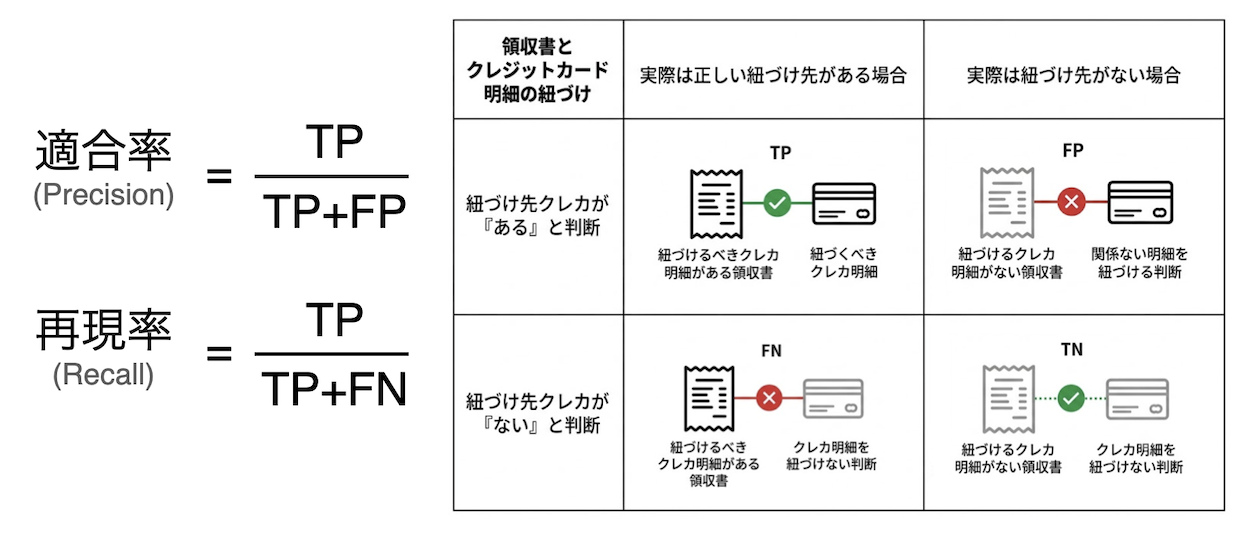
クレジットカード明細の提案エージェントは、領収書の明細とクレジットカード明細を突き合わせて「どの領収書がどのカード明細に対応するか」を判断します。複数の明細をまとめて対応づけたり対応相手が存在しないケースもあり、「取りこぼし」と「誤った対応づけ」の両方が起こりえます。そこで次の指標で評価します。
- 適合率 (Precision) : 提案した紐づけのうち正しかった割合。高いほど誤った提案が少ない。
- 再現率 (Recall) : 本来紐づけるべき紐づけのうち提案できた割合。高いほど取りこぼしが少ない。
- F1 : 適合率と再現率のバランス。
たとえば「適合率は高いが再現率が低い」なら、提案は正確だが拾いきれていない候補がある状態だと分かります。
事前申請提案エージェントの評価
事前申請の提案エージェントは、領収書の明細を「既存の事前申請のどの明細に紐づけるか」それとも「新規の明細として扱うか」を判断します。マッチングに加えて「既存か新規か」の振り分けが入るため、確認すべき指標も多くなります。
- 既存マッチの適合率/再現率 :「既存」と判断した明細で、正しい相手を選べたか
- 振り分けの正答率 : そもそも「既存か新規か」の判断自体が正しいか
- 新規ケースの正答率 : 新規にすべき明細を、新規と判断できたか
これにより「既存と判断した中での取り違え」なのか「既存/新規の判断ミス」なのか、どちらでつまずいたかを切り分けられます。こうして指標を分けて見ることで、各 AI エージェントの信頼できる範囲と弱点を具体的に把握できます。
伝票生成エージェントの評価
最終的な伝票については、生成された伝票がタスクとして正しく完成しているかを、次の観点で評価します。
- 提示したすべての領収書(明細)が、漏れなく伝票に反映されているか
- クレジットカード明細が正しく紐づけられているか
- 事前申請が伝票に正しく対応づけられているか
- 各ステップ間で金額が整合しているか
- 伝票全体が論理的に整合し、業務上そのまま利用できる形に完成しているか
これらのうち、ID の一致や金額の整合のように決定的に判定できる項目はその形で確認し、伝票全体としての論理的な完成度は LLM-as-a-Judge で評価します。決定的な指標と確率的な推論評価を組み合わせ、タスクを完了できたかを総合的に判断しています。
また、通常のケースだけでなく実運用で発生し得るエッジケースを意図的に含めたデータセットを構築しました。GenAIIC との協議を通じて誤りが発生しやすいパターンを体系的に洗い出し、例えば、以下のような観点でテストケースを設計しています。
- 金額処理の複雑性: 外貨処理、為替レートによる端数差、税込・税抜の表記差、軽減税率の混在
- 表記の揺れ: 法人名の略称や言語差(英語/日本語)、同義語
- 時間的な不整合: 海外出張における日付またぎ、購入日と利用日のずれ
- パターンの多様性: 月額サブスクリプション、1伝票に対する複数明細・複数領収書の紐づけ
これにより「想定通りに動くか」だけでなく、「想定外の入力にどこまで耐えられるか」を評価することが可能になりました。
オフライン評価の結果、AI エージェントごとに成熟度に差があることが明確になりました。本番投入可能な水準に達している AI エージェントがある一方で、明細行が多いケースなど特定の条件で精度が落ちる AI エージェントも特定でき、改善の優先順位を明確にすることができました。
オンライン評価の解決策
オフライン評価だけでは、実際のユーザー利用における正しさを十分に捉えることはできません。そのためリリース後は、オンラインで取得できるデータを活用した評価の仕組みを整備しました。 具体的には、AI エージェントの提案内容と、ユーザーが実際に選択した内容をそれぞれ DB 上に保存し、両者を突き合わせることで提案の妥当性を定量的に評価できる仕組みを整備しました。
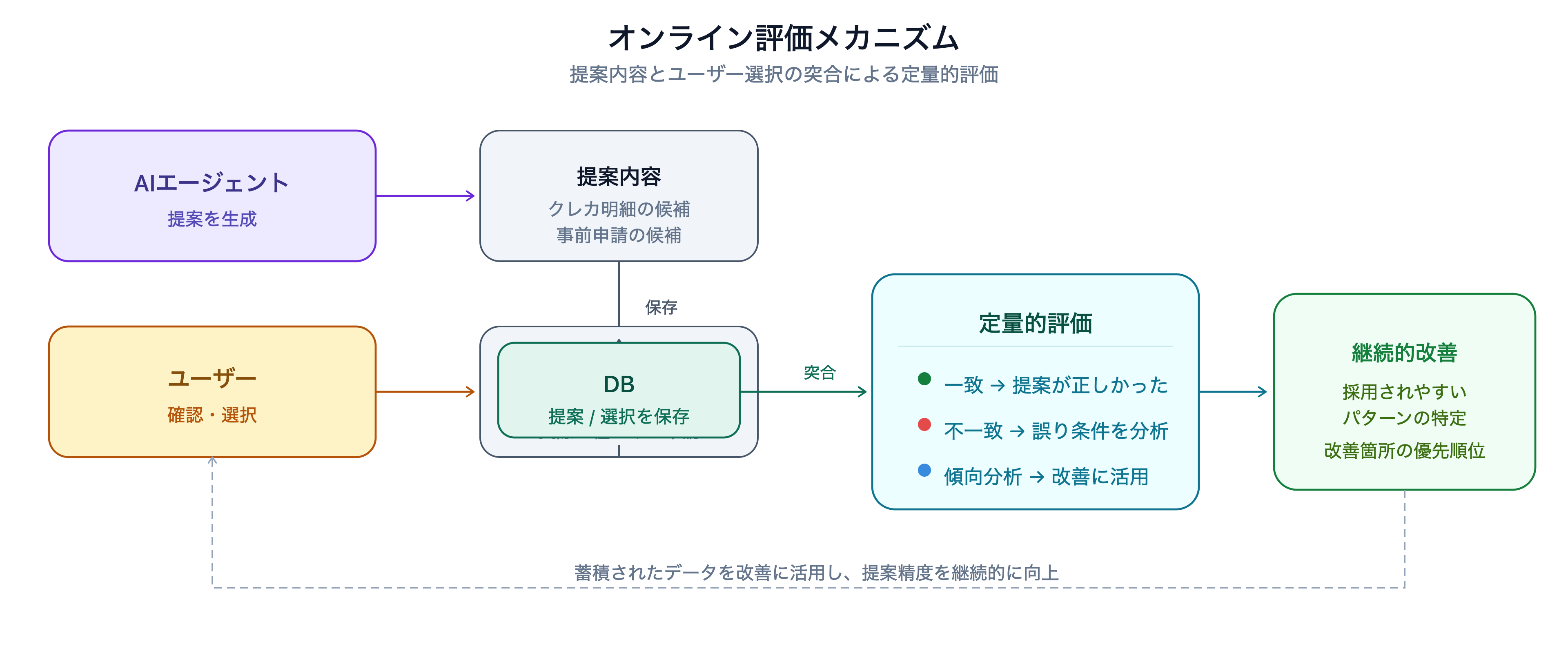
例えば、クレジットカード明細の提案ステップにおいては、AI エージェントが提案した明細とユーザーが実際に採用した明細を比較します。一致していれば提案が正しかったと判断でき、不一致であればどのような条件で誤った提案をしたのかを分析できます。こうしたデータを継続的に蓄積することで、どのようなケースで提案が採用されやすいのか、あるいは改善が必要なのかといった傾向を分析し、AI エージェントの改善に活用できる基盤を構築しました。
このようにリリース前のオフライン評価とリリース後のオンライン評価を組み合わせることで、AI エージェントの挙動を多面的に捉え、継続的に品質を向上させる仕組みを実現できました。
今後の展望
今回構築した評価の仕組みは、単に現時点の品質を担保するためのものだけではなく、AI エージェントを継続的に改善していくための基盤として位置づけています。
自己改善ループの構築
AI エージェントは一度リリースして終わりではなく、実運用の中で得られるデータをもとに自ら改善していく仕組みが重要だと考えています。オンライン評価で蓄積されるユーザーの選択や修正の履歴は、エージェントにとっての「経験」です。この経験を Episodic Memory (エピソード記憶) のような形で蓄積し、過去の成功・失敗パターンをエージェントの振る舞いに反映させることで「使うほどに精度が向上する」自己改善ループの実現を目指しています。
評価の高度化
今回の評価設計は出発点であり、今後は評価基盤そのものも進化させていきます。
評価の多層化
評価対象には、入力の変換や ID の突合のように決定的に正誤を判定できる処理と、LLM の推論のように確率的に振る舞う処理が混在します。今後はこれらを役割の異なる層に整理し、決定的に検証できる部分は高速なユニットテストで固め、個々の推論ステップやプロンプト・ツール選択の粒度では確率的に評価し、ワークフロー全体ではタスクを完遂できるかを評価する多層構成を目指します。これにより品質劣化が「LLM の揺らぎ」か「実装不具合」かを切り分けやすくし、エージェント内部のどの判断が精度に効いているかをより細かく特定できるようにします。
評価データセットの継続的な拡充
オフライン評価の網羅性には限界があり、難しいケースの多くは実運用で初めて顕在化します。 今後は、オンライン環境で蓄積される実データから得られる洞察を、オフライン評価用データセットへ継続的に取り込む仕組みを整備していきます。 特に、エージェントの提案とユーザーの選択が食い違ったケースや、想定外の入力が行われたケースを分析し積極的に取り込むことで、既存の評価データセットを発展させ、本番で間違えやすいエッジケースを含む実践的な評価データセットへと拡充します。これにより、リリース前にエージェントの想定外の動作や意図しない品質低下を検知できる範囲を、継続的に広げていきます。
伝票作成 AI エージェントは、経費精算という業務を起点に、AI が業務の一部を担う新しい働き方を提示する取り組みです。今後も評価と改善を繰り返しながら、より実用的で信頼できる業務支援 AI へと進化させていきます。