Amazon Web Services ブログ
単一アベイラビリティーゾーンでのアプリケーション障害からの迅速な復旧
2023 年 5 月 3 日のアップデート
このアップデートにより、Amazon Route 53 Application Recovery Controller のゾーンシフトは、以下の AWS リージョンでも利用できるようになりました。
詳しくは、更新された What’s New ポストまたはゾーンシフトのドキュメントでご確認ください。
本日は、Elastic Load Balancing (ELB) に組み込まれた Amazon Route 53 Application Recovery Controller (Route 53 ARC) の新機能であるゾーンシフトをご紹介します。ゾーンシフトを実行することで、単一のアベイラビリティゾーン (AZ) 内のアプリケーション障害からの迅速なリカバリを実現することができます。
この記事では、ゾーンシフトの仕組みと、ロードバランサーのヘルスチェック機能などを利用する高い耐障害性を持つマルチ AZ アプリケーションにおける信頼性戦略へどのように適合するかを説明します。さらに、AWS サービスによるマルチ AZ アプリケーションの設計と監視、ゾーンシフトについて、AWS re:Invent 2022: Operating highly available multi-AZ applications のセッションを補足として確認頂く事ができます。
以下の AWS リージョンで、本日からプレビューでゾーンシフトの利用を開始できます: 米国東部 (オハイオ州)、米国東部 (バージニア州) 、米国西部 (オレゴン州) 、アジア太平洋 (ジャカルタ) 、アジア太平洋 (シドニー) 、アジア太平洋 (東京) 、ヨーロッパ (フランクフルト) 、ヨーロッパ (アイルランド) 、ヨーロッパ (ストックホルム) 。ゾーンシフトは、クロスゾーン負荷分散がオフになっているアプリケーションロードバランサー (ALB) およびネットワークロードバランサー (NLB) で使用することができます。ゾーンシフトを使用する際、追加の料金はかかりません。
AZ を利用したフォールトトレラントサービスの構築
AWS サービスや AWS 上で耐障害性の高いアプリケーションを運用するお客様が採用している、信頼性の高いシステムを設計するための重要な戦略は、複数の独立したレプリカを使用し、一つのレプリカが故障した場合の計画を立てることです。この戦略では、システム全体を複数のアプリケーションレプリカ (通常は 3 つ) として構築し、一度に 1 つのレプリカが故障することを想定して計画を立てます。そして、1 つのレプリカが一時的にオフラインになった場合でも、負荷を処理できるように、各レプリカに十分な容量を用意する必要があります。
次に、すべての一般的な障害モード (つまり、デプロイの失敗、応答待ち時間の長さ、エラー率の上昇) が 1 つのレプリカ、または 1 つの障害コンテナに封じ込めるようにします。そして、万が一レプリカに障害が発生した場合は、そのレプリカを一時的にシステムから切り離すことで、顧客への正常なサービスを回復することができます。正常なサービスが回復したら、故障したレプリカを調査して修復することができます。障害の原因は、ソフトウェアの導入、オペレーターのミス、ハードウェア障害、電源障害、ネットワーク機器の障害、証明書の有効期限切れ、さらにはデータセンターの障害など、さまざまです。障害が発生するのはまれですが、1 つのレプリカにとどめるように制御し、迅速に回復できるようにすることで、より信頼性の高いシステムを運用できるようになります。
この戦略はリカバリ指向であり、調査や修復よりもまずリカバリを優先させることを意味します。まず、障害のあるレプリカを切り離し、アプリケーションを正常な状態に回復させます。その後、根本的な原因を調査して障害のあるレプリカを修復し、レプリカをサービスに戻すことができます。根本原因を特定する前に、まず復旧できることを確認することで、平均復旧時間 (MTTR) を短縮し、顧客に対する影響期間を短縮します。
この戦略の重要な部分は、2 つのレプリカが同時に、または連携して故障する可能性を最小化することです。そのためには、レプリカが可能な限り独立して動作するようにする必要があります。これには通常、一度に 1 つのレプリカだけにソフトウェアを展開する、一度に 1 つのレプリカだけに変更を加える、レプリカ間で制限を分散させる (または「ジッタリング」する) などの一連の対策が必要です。これは、ファイルシステムのサイズ、ヒープメモリの制限、証明書の有効期限、スケジュールされたジョブの実行時間などの運用上の項目です。そのようにすることで、復数のレプリカで同時に問題が発生することを防ぎます。例えば、レプリカに異なる制限を設定することで、制限に関連する問題の初期発生を 1 つのレプリカに抑え、一時的な切り離しを可能とします。
レプリカを独立した物理的なフォールトコンテナに配置すると、システムはこのレプリカ戦略からさらに多くの恩恵を受けることができます。AWS で構築する場合、物理的なフォールトコンテナとして AZ を使用します。AZ を利用することで、レプリカを十分な距離 (通常は数マイル) 離れた物理データセンターに配置し、多様な電力、接続性、ネットワークデバイス、および洪水対策ができるようにすることができます。この場合も、2 つのレプリカで同時に発生するイベントの数を最小限に抑え、相関性のある障害を防止することを目的としています。
ハード障害からの復旧
アプリケーションを複数の独立したレプリカとして構築し、AZ にあわせて配置し、1 つのレプリカの損失を処理するのに十分な容量をプロビジョニングしたら、次のステップは、AZ またはゾーンレプリカ内の異常なレプリカを迅速に検出して切り離すメカニズムをセットアップすることです。ALB または NLB を使用する場合、AZ の障害に対する防御の最前線はヘルスチェックです。ヘルスチェックでは、ロードバランサーは一定の間隔で各ターゲットを調査し、正常なレスポンス、つまり HTTP ステータス 200 があるかどうかをチェックします。正常でないレスポンスやタイムアウトがあった場合、障害が検出され、通常1分以内に、リクエストは障害のあるターゲットから正常なターゲットへルーティングされます。さらに、各ロードバランサーノードは Amazon Route 53 のヘルスチェックによって健全性をチェックされ、AZ 内のターゲットがすべて正常でない場合は、ロードバランサーの DNS から該当の AZ が削除されます。
ターゲットのヘルスチェックは、明らかに検出可能な障害、つまりターゲットインスタンスの故障のようなハードな障害に対して迅速かつ効果的です。その他のハード障害の例としては、接続を受け付けなくなったアプリケーションや、ヘルスチェックの応答で HTTP ステータス 500 を返しているアプリケーションなどがあります。ヘルスチェックが最も効果的になるようにするために、ディープヘルスチェックハンドラーを設計すると便利です。これにより、アプリケーションをより徹底的にテストすることができます。しかし、ディープヘルスチェックは、過負荷のような状況で発生しうる誤った検知を回避する必要があるため、慎重に検討する必要があります。詳しくは、Amazon Builder’s Library の優れた記事ヘルスチェックの実装を参照してください。
ハードな障害を検出するために使用できるもう 1 つの機能は、最小健全性ターゲットです。ALB と NLB は最近この機能を追加し、ターゲットグループまたは AZ 内の正常なターゲットの最小数を指定できるようになりました。これで、1 つのゾーンレプリカに障害が発生し、設定した最小容量の閾値を下回った場合、そのレプリカはヘルスチェックに失敗し、トラフィックは他のレプリカにルーティングされます。これにより、障害が発生したレプリカが過負荷状態になるのを防ぐことができます。
グレー障害からの回復
ディープヘルスチェックを実施していても、より曖昧で断続的なグレー障害モードが発生し、検出が困難な場合があります。例えば、ゾーン展開の後、レプリカは正常であるとプローブに応答するかもしれませんが、顧客に影響を与える機能的なバグがあるかもしれません。また、新しいコードのパフォーマンスが低下していたり、断続的にクラッシュしているにもかかわらず、チェックすると正常に見えるほど応答性が良い場合もあります。パケットロスや断続的な依存関係の障害など、インフラに関わる微妙な問題も、ヘルスチェックを通過しても応答が遅くなる可能性があります。
このようなグレー障害の場合、ゾーンレプリカ全体のカスタマーエクスペリエンスを調査できる、人間または自動化されたより高度なメカニズムを用意することが有効です。そして、ゾーンレプリカがグレー障害を経験しているとき、人または自動化されたシステムによって、その AZ を切り離す事ができます。AWS は長年この 2 本立ての戦略を使ってきましたが、今回、お客様が AWS でアプリケーションを実行する際に、同様の戦略を採用しやすくしました。ELB には、クロスゾーン負荷分散をオフにした ALB と NLB の両方について、ゾーンシフトを開始するためのオプションが追加されました。このビルトインリカバリーコントロールにより、アプリケーションに不具合が生じた場合に、AZ から一時的に離れることができます。
まず、クロスゾーン負荷分散がオフになっていることを確認します。次の図に示すように、これにより、ロードバランサーノードは、ローカル AZ 内のターゲットにのみリクエストをルーティングするように設定されます。こうすることで、各ゾーンの障害コンテナをロードバランサーとそのターゲットに合わせ、1 つのゾーンのレプリカ内の障害を簡単に検出できるようになります。ALB と NLB の両方でクロスゾーン負荷分散をオフにすることができます。
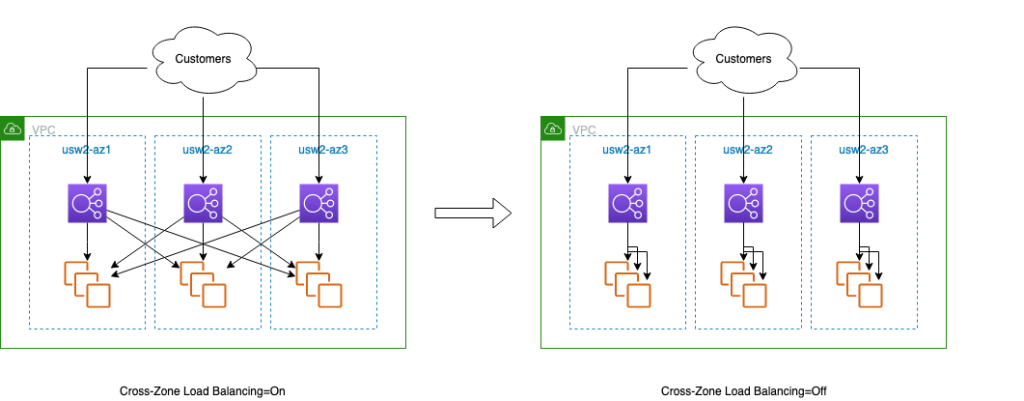
図 1. クロスゾーン負荷分散オン/オフ時のルーティング方法
さて、ELB でゾーンシフトを開始することができます。ゾーンシフトの制御は組み込まれているため、設定は不要ですが、AWS Identity and Access Management (IAM) ユーザーまたはロールがゾーンシフト API を呼び出す権限を持っていることを確認する必要があります。ゾーンシフトでは、単純な StartZonalShift API コールを使用して、不健全なゾーンレプリカからお客様のトラフィックを一時的に移動させることができます。他のレプリカが正常で、顧客にサービスを提供できる容量があれば、数分以内に顧客体験を回復することができます。その後、顧客が快適にアプリケーションを使い続けている間に、異常なゾーンレプリカのデバッグと修復に取り組むことができます。修復したゾーンにアプリケーションのワークロードを戻す準備ができたら、ゾーンシフトをキャンセルするか、単に期限切れにすることができます。
ゾーンシフトはどのように機能するのか?
ゾーンシフト API を呼び出して AZ からトラフィックを移動するよう要求した場合、どのように動作するのでしょうか?次の図に示すように、クロスゾーン負荷分散をオフにして、NLB の背後にある 3 つの AZ で動作するウェブサービスを考えてみましょう。NLB の各ゾーンエンドポイントで合成監視をしているので、各 AZ のリクエストの成功率とレイテンシを見ることができます。Amazon CloudWatch ダッシュボードでは、顧客リクエストの 1 % (P99) に 1 秒のレイテンシーが発生していることがわかります。AZ ごとのメトリクスを見ると、AZ3 では同様にレイテンシが増加しており、AZ1 と AZ2 ではレイテンシは変化せず、通常の範囲 (~60ms) であることがわかります。何が原因でレイテンシーが上昇しているのかはまだ分かりませんが、問題は AZ3 のレプリカに含まれていることが強く示唆されます。リクエストは成功し続けているので、ヘルスチェックは通過していますが、このようなレイテンシの増加は顧客に問題を引き起こす可能性があります。
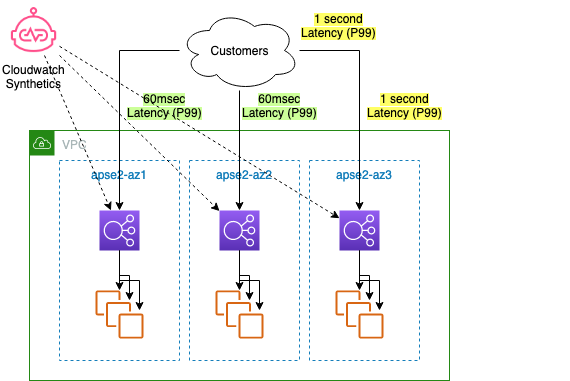
図 2. CloudWatch Synthetics が 1 つの AZ でレイテンシの上昇を検出した 3-AZ ロードバランサーアーキテクチャー
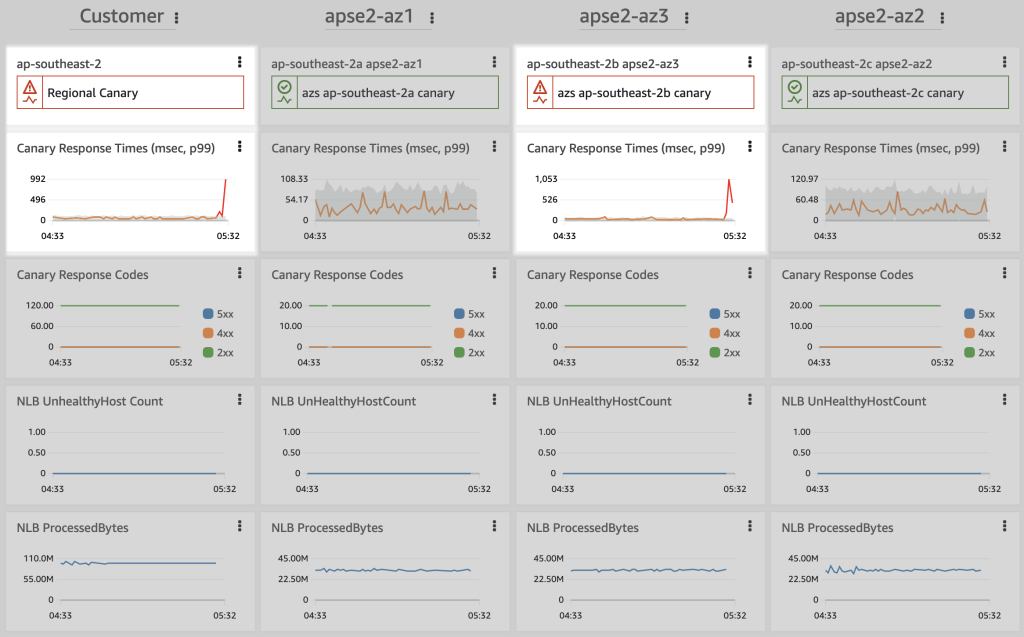
図 3. 顧客と AZ ごとのビューを持つ運用中の CloudWatch ダッシュボード。レイテンシーメトリクスは、カスタマーエクスペリエンスと 1 つの AZ でレイテンシーの上昇を示す
Webサービスに1つのAZを切り離しても、処理するのに十分な予備の計算能力がある場合、まず回復するために AZ3 からトラフィックをシフトし、その後問題を調査することができます。これはどのように機能するのでしょうか?ゾーンシフトを開始すると、顧客のトラフィックを AZ3 から遠ざけるように要求します。ゾーンシフトにより、AZ3 のロードバランサーのヘルスチェックが失敗し、その IP アドレスは DNS から削除されます。この結果、新しい接続は他の AZ のみに向かうことになります。クライアントの動作や接続の再利用状況によっては、既存の接続が枯渇するまでに時間がかかることがありますが、通常は数分で完了します。
StartZonalShift API コールを使用すると、AZ からトラフィックをシフトさせることができ、ゾーンシフト ID を返します。ゾーンシフトによってトラフィックが AZ から一時的に切り離されます。一時的な期限の設定が必要となります。これはロードバランサーの永続的な設定変更ではありません。StartZonalShift API を使用した次の CLI コマンドの例は、12 時間で期限切れになるように設定されたゾーンシフトを開始します:
aws arc-zonal-shift start-zonal-shift \ --resource-identifier arn:aws:elasticloadbalancing:ap-southeast-2:123456789012:loadbalancer/net/zonal-shift-demo/1234567890abcdef \ --away-from apse2-az3 \ --expires-in 12h \ --comment "Anomaly detected in AZ3, shifting away proactively"
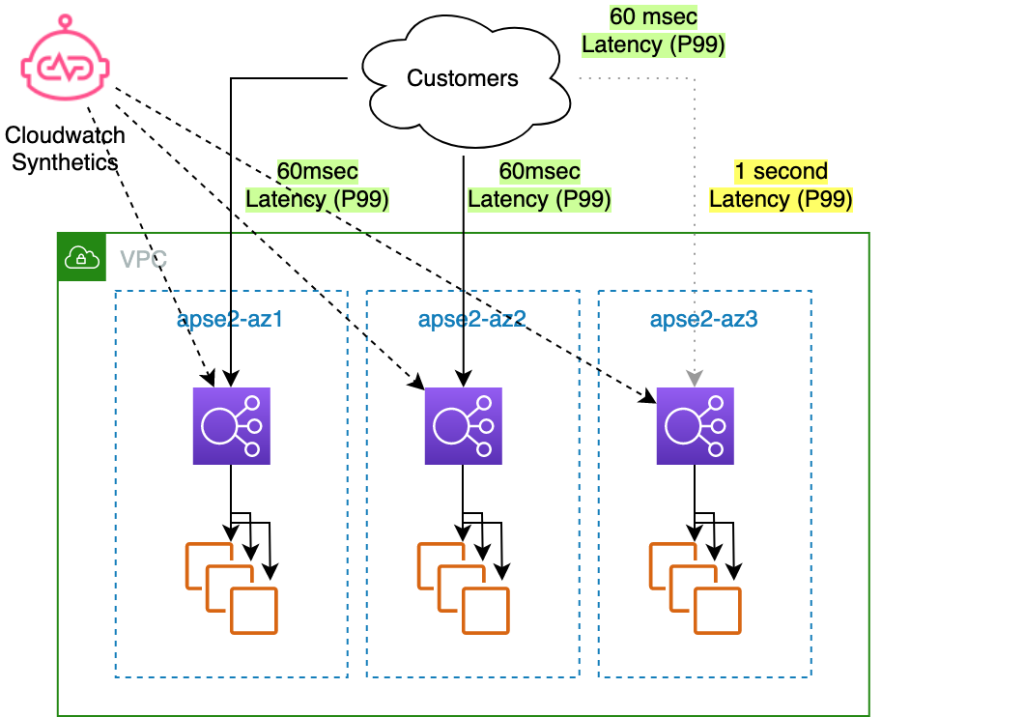
図 4. 同じ 3-AZ ロードバランサーアーキテクチャで、障害のある AZ からトラフィックを遠ざけるためにゾーンシフトが有効になっている。
ゾーン・シフトが有効になり、CloudWatch のダッシュボードでは、顧客のエンドポイントで ResponseTime メトリックが正常に戻っていることが示されています。モニタリングでは、AZ3 でレイテンシーの問題が残っていますが、その AZ は顧客のトラフィックを受けなくなりました。また、ProcessedBytes が AZ1 と AZ2 で上昇し、AZ3 で低下していることも確認できます。
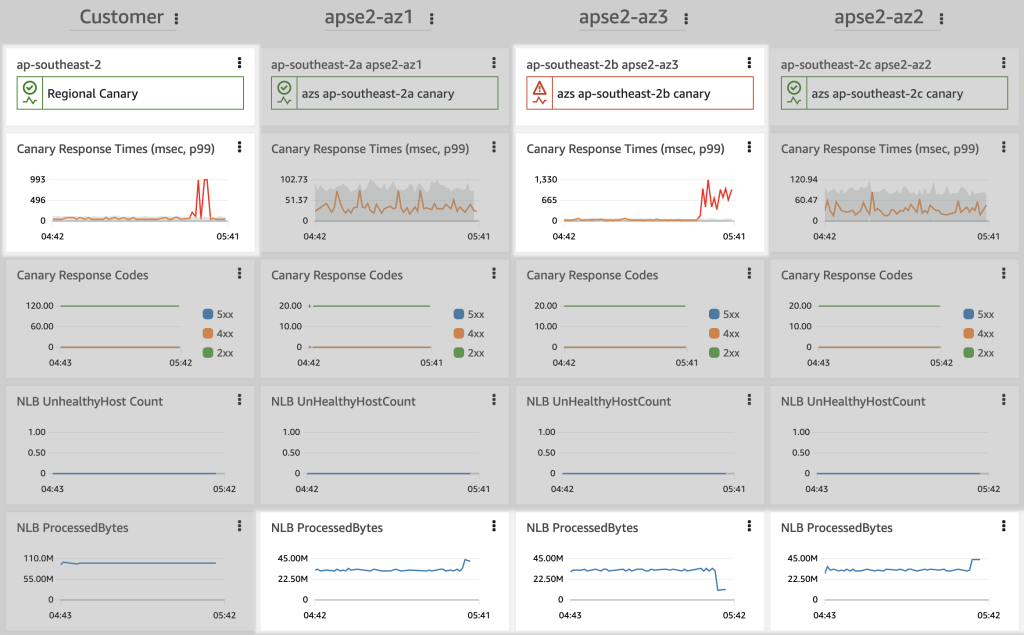
図 5. ゾーンシフトにより、障害を受けた AZ からリクエストを遠ざけることで、顧客エクスペリエンスが回復したことを示す運用中の CloudWatch ダッシュボード
顧客は再び通常のサービスを受けられるようになったので、今度は AZ3 で問題を調査します。最近 AZ にデプロイされたのではないでしょうか?他のチームメンバーがその AZ のレプリカに影響を与えるような作業をしていたのでしょうか?あるいは、AWS Health Dashboard に表示されている AZ3 に進行中の問題があるのでしょうか?障害の理由が何であれ、問題を調査し、対処するための時間ができました。必要な期間だけゾーンシフトを維持することができます。
トラブルシューティングのための時間を確保するためにゾーンシフトを延長する必要がある場合は、簡単な UpdateZonalShift API 呼び出しで実行できます。次の CLI コマンドの例では、ゾーンシフトが今から 4 時間後に期限切れになるように設定しています:
aws arc-zonal-shift update-zonal-shift \ --zonal-shift-id <zonal-shift-id> \ --expires-in 4h
AZ3 のゾーンレプリカが回復したら、ゾーンシフトをキャンセルするか、自動的に期限切れになるのを待つことができます。キャンセルするには、CancelZonalShift API コールにゾーンシフト ID を指定して使用します。たとえば、次の CLI コマンドを使用します:
aws arc-zonal-shift cancel-zonal-shift \ --zonal-shift-id <zonal-shift-id>
Amazon Virtual Private Cloud (Amazon VPC) エンドポイントサービスを使用している場合、Amazon VPC エンドポイントサービスに関連付けられたリージョンの NLB のゾーンシフトを開始すると、ゾーンシフトが対応するすべての Amazon VPC エンドポイントにも自動的に適用されることに注意してください。これにより、AWS PrivateLink によって NLB に到着するトラフィックもゾーンシフトを考慮するようになります。
単一 AZ アプリケーションの障害に対応するための準備
さて、回復のためにゾーンシフトを開始する方法について説明しましたが、この戦略を効果的に準備し適用する方法について見ていきましょう。
障害を検出する
アプリケーションに異常なゾーンレプリカが1つでもあると、それを検出できるようにする必要があります。これを確実に行うには、アプリケーションの健全性を示すゾーンごとのシグナルが必要です。これを行うには、いくつかの補完的な方法があります。
パッシブ・モニタリング ほとんどのアプリケーションは、致命的なエラー、例外、応答時間、HTTP ステータスコード (HTTP ステータス 200 や HTTP ステータス 500 など) を追跡するメトリクスを作成します。メトリックのディメンションにホストの AZ の情報を含めると、単一のゾーンレプリカの問題を示す集約メトリックを作成することができます。さらに、ALB と NLB の両方が、UnhealthyHostCount や ProcessedBytes などの AZ 単位のメトリックを提供します。ALB は、HTTP ステータス 500 エラーの AZ ごとのカウントも提供します。これらのメトリクスはすべて判断材料になります。
アクティブモニタリングと外形監視 パッシブ・モニタリングに加えて、アプリケーションに対して合成リクエストを作成し、カスタマーエクスペリエンスをより完全に把握できるようにすると便利です。Amazon CloudWatch Synthetics は、エンドポイントに対して選択したコードを定期的に実行し、メトリクスを作成できるマネージド型カナリアサービスを提供します。ALB と NLB の両方が、標準のリージョンの DNS 名に加えて、ゾーン DNS 名を提供します。これにより、以下のように、各ゾーンのアプリケーションレプリカの応答性と信頼性を個別に監視するカナリアを作成することができます:
ELB name: zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2A: ap-southeast-2a.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2B: ap-southeast-2b.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2C: ap-southeast-2c.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com
CloudWatch Synthetics はマネージドサービスであり、また別 AWS リージョンにカナリアを配置する事も可能な為、アププリケーションが実行されているリージョン内で障害が発生しても、継続してモニタリングが可能となります。
追加入力 アプリケーションの健全性に関するシグナルを直接監視することに加えて、AWS Health Dashboard からの通知など、他のインプットを評価することが有用な場合があります。Health Dashboard が AZ の問題を示すとき、必ずしも自分のアプリケーションが影響を受けていることを意味しないことに注意してください。このため、通常は、アプリケーションのゾーンレプリカの健全性も直接測定するのがベストです。
ダッシュボードと集計 AZ からトラフィックを移動させるための一般的な出発点は、その種のトラフィック移動を自動化しようとする前に、オペレータが手動でアクションを起こすこと (つまり、人間が決定を下すこと) です。人間のオペレーターにとって、先に示した例のようなシンプルな CloudWatch ダッシュボードは、AZ の単一の全体的なビューを提供し、迅速な決定を下すのに役立つことができます。CloudWatch のダッシュボードはグローバルであることに注意してください。そのため、作成後はどの AWS リージョンからでもアクセスすることができ、耐障害性を高めることができます。
ゾーンシフトのベストプラクティス
ゾーンシフトは、稼働中のアプリケーションから容量を奪う可能性があるため、本番で使用する場合は注意が必要です。ここでは、ゾーンシフトを安全に使用するための準備と安全確認について説明します。
プリスケールキャパシティヘッドルーム リカバリ指向の戦略をとる場合、1 つのゾーンレプリカをオフラインにしてもピークトラフィックに対応できるような十分なヘッドルームを備えた計算容量を事前にスケーリングすることをお勧めします。ゾーンシフトは、この点をさらに重要視しています。ゾーンシフトを開始すると、ロードバランサーの後ろから 1 つの AZ のキャパシティが一時的に削除されます。つまり、ゾーンシフトを使用する前に、すべての AZ に十分なキャパシティがあることを確認する必要があります。クロスゾーン負荷分散をオフにした 3-AZ の ALB または NLB の場合、1 つの AZ からシフトすると、他の 2 つの AZ のそれぞれで約 50 %の追加負荷が予想されます。2AZ のロードバランサーの場合、もう一方の AZ の負荷が 2 倍になることを想定しておく必要があります。
キャパシティを事前にスケーリングする代わりにスケーリングポリシーを使用することにした場合、使用するポリシーとメトリックについて慎重に考えてください。例えば、平均 CPU 使用率は、ゾーンシフトに対応して増加をもたらさないかもしれません。それは、Auto Scaling グループのある部分が CPU 使用率を下げると、別の部分が上昇するからです。
すべてのゾーンレプリカが正常で、トラフィックを受けていることを確認します ゾーンシフトは、ある AZ にあるアプリケーションレプリカを異常とみなすことで機能します。したがって、レプリカの 1 つに影響を与えるイベントが発生する前に、他のゾーンレプリカでターゲットが正常で、トラフィックを積極的に受け入れていることを確認する必要があります。この認識を維持するために、ここに示すダッシュボードの例のように、異常なターゲットと AZ ごとの bytesProcessed の両方の ELB メトリクスを含むダッシュボードを作成します。
事前にテストする どのような回復メカニズムでもそうですが、必要なときに機能するかどうかを確認するために、定期的に練習する必要があります。実際のイベントの前に、理想的にはテスト環境と本番環境の両方でゾーンシフトを使用することをお勧めします。テストすることで、運用上のイベントが発生したときに、慣れと自信を持つことができます。
API または CLI を使用する練習をする 障害を素早くうまく処理するためには、通常、最も早く、最も信頼性の高い、依存関係の少ないツールを使用することをお勧めします。使いやすいように、ゾーンシフトは AWS マネジメントコンソールで利用できます。ただし、迅速な復旧が不可欠な場合は、復旧手順書で、可能であれば、事前に保存された AWS 認証情報を使用して、AWS コマンドラインインターフェース (AWS CLI) または zonal shift API コールを使用するようにオペレータに伝えることをお勧めします。
ゾーンシフトでトラフィックを一時的にしか移動させない アプリケーションの異常なゾーンレプリカが修復されるとすぐに、そのレプリカをサービスに戻す必要があります。これにより、アプリケーション全体が完全に冗長で弾力性のある状態にできるだけ早く戻るようにします。
慎重に自動化する 次のステップとして、ゾーンシフトの自動化に取り組むのは自然な流れです。これは合理的ですが、エッジケースについては慎重に考えてください。たとえば、トラフィックが急激に増加してアプリケーションが過負荷になった場合、通常、AZ を切り離すことは望ましくありません。また、追加する自動化は、ゾーンシフトが始まったときに他のレプリカが正常であることを確認するように注意してください。
第二のリージョンから監視する 隣接する AWS リージョンからアクティブモニタリングを行うことを検討してください。近くのリージョンはアプリケーションの顧客体験をよりよく表すことができ、別のリージョンから監視することで、アプリケーションと監視の間で運命が共有されるという問題が軽減されます。
ゾーンシフトの試行
Route 53 ARC のゾーンシフトを始めるのに役立つように、サンプルの NLB アプリケーションでこの機能を試すために、ダウンロードしてデプロイできる AWS CloudFormation テンプレートの例が含まれています。AWS Fault Injection Service (AWS FIS) を使用して、グレー障害イベントをシミュレートし、回復するためにゾーンシフトを開始することができます。このテンプレートは、このブログ記事で説明したものと同様のアーキテクチャを作成します。ダウンロードには以下が含まれます:
- クロスゾーン負荷分散をオフにした 3-AZ NLB
- Auto Scaling グループ。1MB のファイルを提供するために Apache Web サーバーを実行しているホスト
- NLB 経由で 1MB ファイルをポーリングする地域限定の CloudWatch Synthetics カナリア (顧客の視点)
- 3 つの AZ ごとの CloudWatch Synthetics カナリアは、特定のゾーン NLB エンドポイントに対して 1MB ファイルをポーリングします (AZ ごとの視点)
- 異常検知に基づく CloudWatch アラーム
- すべてのデータを 1 つのビューで表示する CloudWatch ダッシュボード
- AWS FIS 実験テンプレート: 1 つの AZ にグレー障害 ( 2 %のパケットロス) を 30 分間注入する。
この CloudFormation テンプレートを使って、自分でゾーンシフトを試してみてください。以下の手順で、回復志向の戦略がどのように機能するかを確認することができます:
- ゾーンシフトが利用可能な任意の AWS リージョンに CloudFormation テンプレートをダウンロードし、デプロイします。
- AWS Management Console で、CloudWatch ダッシュボードを開き、データパターンが確立されるのを待ちます。
- FIS ダッシュボードを開き、1 つのゾーンレプリカでパケットロスを注入する実験 PacketLossOnInstancesIn-AZ-B を開始します。
- CloudWatch ダッシュボードに戻り、3 ~ 5 分待ってから、カスタマーエクスペリエンスの ResponseTime メトリックの変化を確認します。2 つの AZ は正常な応答時間を持ち、1 つの AZ は応答時間が上昇し、問題が発生しているゾーンレプリカを示すはずです
- 応答時間が上昇しているゾーンレプリカの AZ ID をメモまたはコピーします
- Route 53 ARC コンソールを開き、Zonal shift を選択します
- Start zonal shift を選択し、Select the Availability Zone ドロップダウン・メニューで、CloudWatch ダッシュボードからメモまたはコピーした AZ ID を選択します
- Resources テーブルで、CloudFormation スタックから NLB の ARN を選択します
- Set zonal shift expiration で、6 hours を選択します
- Acknowledgement チェックボックスを選択し、Start を選択します
ここで、CloudWatch ダッシュボードに戻ります。カスタマーエクスペリエンスの列が回復を示す一方、問題のあるゾーンレプリカのカナリアが問題を示し続けていることがわかるはずです。また、BytesProcessed グラフで、トラフィックが 1 つのレプリカから離れ、他のレプリカに向かって移動していることがわかるはずです。
これで、FIS 実験をキャンセルするか、期限切れにすることができ、影響を受けるゾーンレプリカの問題は解決します。Route 53 ARC コンソールで、開始したゾーンシフトを選択し、Cancel zonal shift を選択します。
最後に、CloudFormation スタックを削除して、ゾーンシフトの実験からリソースをクリーンアップします。
ゾーンシフトを使用するには、zonal shift API に対するパーミッションが必要です。Elastic Load Balancing のマネージドポリシーである ElasticLoadBalancingFullAccess または AdministratorAccess を持つ IAM ユーザーとロールには、アクセスが自動的に付与されます。また、独自の IAM ポリシーで arc-zonal-shift API アクションへのアクセスを明示的に付与することも可能です。
現在利用可能
Route 53のARC ゾーンシフトは、クロスゾーン負荷分散をオフにした ALB と NLB で、冒頭に記載した AWS リージョンで利用可能になりました。今後、より多くの AWS リージョンとロードバランサーの構成がサポートされる予定です。ゾーンシフトをお試しいただき、ご意見をお聞かせください!

Gavin McCullagh
Gavin は AWS レジリエンスインフラストラクチャおよびソリューションチームのプリンシパルエンジニアです。2011 年から AWS に勤務し、Amazon の内部負荷分散や DNS ソリューションのほか、Amazon Route 53 、Amazon Route 53 リゾルバー、Amazon Route 53 アプリケーションリカバリコントローラーなどの AWS サービスにも携わっています。Gavin は、ダブリン大学で化学の学士号と博士号を、アイルランド国立大学メイヌース校のハミルトン研究所でコンピューターサイエンスの修士号を取得しています。

Deepak Suryanaryanan
Deepak は AWS レジリエンスインフラストラクチャおよびソリューションチームのゼネラルマネージャーです。2011 年から AWS に勤務しており、Amazon Route 53 Application Recovery Controller などの機能を使用して、マルチ AZ やマルチリージョンのアプリケーション向けにリカバリ指向のアーキテクチャを運用するなど、AWS で耐障害性の高いアプリケーションを構築する方法について顧客と定期的に話し合っています。Deepak はマドラス大学とノースカロライナ州立大学で工学の学位を、デューク大学で経営学修士号を取得しています。
翻訳はソリューションアーキテクト 渡部 拓実 が担当しました。原文はこちらです。