Networking & Content Delivery
Rapidly recover from application failures in a single AZ
Update – 3rd May 2023
With this update, zonal shift for Amazon Route 53 Application Recovery Controller is now also available in the following AWS Regions.
Learn more in the updated What’s New post or zonal shift documentation.
Today we’re introducing zonal shift, a new capability of Amazon Route 53 Application Recovery Controller (Route 53 ARC) that is built into Elastic Load Balancing (ELB). Performing a zonal shift enables you to achieve rapid recovery from application failures in a single Availability Zone (AZ).
In this post, we’ll explain how zonal shifts work and how they fit into an overall reliability strategy for a highly resilient multi-AZ application that uses features such as load balancer health checks. In addition, you can watch this complementary talk on designing and monitoring multi-AZ applications with AWS services that also discusses zonal shifts, presented at AWS re:Invent 2022: Operating highly available multi-AZ applications.
You can start using zonal shifts in preview today in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Jakarta), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm). You can use zonal shift with Application Load Balancers (ALBs) and Network Load Balancers (NLBs) that have cross-zone load balancing turned off. There’s no additional charge for using zonal shift.
Building fault tolerant services using AZs
A key strategy for designing reliable systems, adopted by AWS services and customers who operate highly resilient applications on AWS, is using multiple, independent replicas and planning for the failure of any one replica at a time. In this strategy, you build the overall system as multiple application replicas (commonly three) and plan for the failure of one replica at a time. You must then provision sufficient capacity in each replica to handle the load should one replica be offline temporarily.
Next, you work to ensure all common failure modes (that is, bad deployments, response latencies too high, elevated error rates) are contained within one replica, or one fault container. Then, should a replica fail, you can temporarily remove it from the system to restore normal service for your customers. Once normal service is restored, you can investigate and repair the failing replica. Failures can come from various sources, including software deployments, operator errors, hardware failures, power failures, network device failures, certificate expiry, and even data center failures. By working to make sure that failures are rare, contained to one replica, and rapidly recovered from, you can operate more reliable systems.
This strategy is recovery oriented, meaning that it prioritizes recovery first, over investigation and repair. You first recover the application to a healthy state, by removing the failing replica. Then, you can investigate the root cause and repair the failing replica, and then return the replica to service. Making sure that you can recover first, before determining the root cause, reduces the Mean Time to Recovery (MTTR) and decreases the duration of impact on customers.
A critical part of this strategy is minimizing the chance that any two replicas fail at the same time or in a coordinated fashion. To do this, you must make sure that your replicas operate as independently as possible. This typically involves a series of measures, such as deploying software to only one replica at a time, making changes to only one replica at a time, and diversifying (or “jittering”) limits across replicas. These are operational items such as file system sizes, heap memory limits, certificate expiry times, the time a scheduled job runs, and so on. Then the issue won’t arise for multiple replicas simultaneously. For example, you could set different limits on your replicas to help contain the initial occurrence of a limit-related issue to one replica, which you can afford to remove temporarily.
Systems benefit from this replica strategy even more when you align the replicas with independent physical fault containers. When you build on AWS, you use AZs as the physical fault containers. AZs let you place your replicas in distinct physical data centers at a meaningful distance apart (typically miles) to make sure that they have diverse power, connectivity, network devices, and flood plains. Again, this aims to minimize the number of events that any two replicas experience simultaneously and helps prevent correlated failure.
Recovering from hard failures
After you build an application as multiple independent replicas, aligned with AZs and provisioned with sufficient capacity to handle the loss of one replica, the next step is to set up mechanisms to rapidly detect and remove an unhealthy replica in an AZ, or zonal replica. If you use ALB or NLB, the first line of defense against failures in an AZ is health checks. With health checks, load balancers probe each of their targets at regular intervals to check for a healthy response—that is, an HTTP status 200. If there’s an unhealthy response or timeout, a failure is detected and requests are routed away from the failing target, typically in under a minute. In addition, each load balancer node is health checked by Amazon Route 53 health checks, which remove an AZ from the load balancer’s DNS if its targets are all unhealthy.
Target health checks are quick and effective for clearly detectable failures, or hard failures, such as a failed target instance. Other examples of hard failures are an application that is no longer listening for connections, or one that is returning an HTTP status 500 in response to health checks. To make sure that health checks are most effective, it’s often helpful to design a deep health check handler, to test the application more thoroughly. However, deep health checks require careful thought, to avoid false failures, such as can happen with overloads. For more information, see the excellent Amazon Builder’s Library article on Implementing Health Checks.
Another feature that you can use to detect hard failures is minimum healthy targets. ALB and NLB recently added this feature, which lets you specify a minimum number of healthy targets in a target group or AZ. Now, should one zonal replica fail and fall below a minimum capacity threshold that you configure, the replica fails health checks and traffic is routed to other replicas. This prevents the impaired replica from potentially being overwhelmed.
Recovering from gray failures
Even with deep health checks in place, more ambiguous or intermittent gray failure modes can arise that are challenging to detect. For example, after a zonal deployment, a replica might respond to probes as healthy, but have a functional bug that impacts customers. Or perhaps new code is performing less efficiently or is crashing intermittently but is still responsive enough to appear healthy when checked. Subtle infrastructure issues, such as packet loss or intermittent dependency failures, can also result in slower responses that still pass health checks.
For these gray failure situations, it’s helpful to have a higher level mechanism, either human or automated, that can examine the customer experience across your zonal replicas. Then, when a zonal replica is experiencing a gray failure, the person or automatic system can shift away from the AZ. AWS has used this two-pronged strategy for many years, and now we are making it easier for customers to adopt a similar strategy when they run applications on AWS. ELB now includes the option for you to start a zonal shift, for both ALBs and NLBs with cross-zone load balancing turned off. This built-in recovery control lets you temporarily shift away from an AZ should your application become unhealthy.
First, make sure that you turn off cross-zone load balancing. As shown in the following diagram, this sets the load balancer node to route requests to targets in the local AZ only. Doing this aligns each zonal fault container with the load balancer and its targets, and makes it easier to detect failures within a single zonal replica. You can turn off cross-zone load balancing for both ALB and NLB.
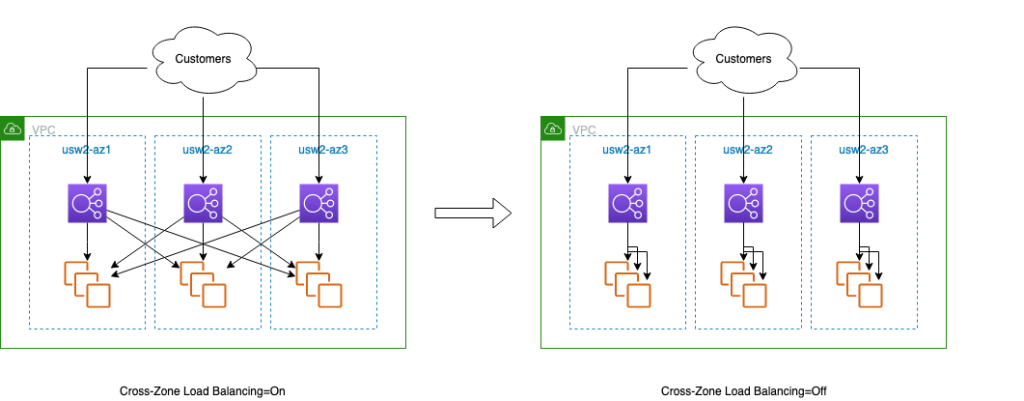
Figure 1. How requests are routed with cross-zone load balancing on and off
Now, you can start a zonal shift in ELB. Because zonal shift controls are built in, no setup is required, though you should make sure that your AWS Identity and Access Management (IAM) user or role has permissions to call the zonal shift APIs. A zonal shift lets you temporarily move your customer traffic away from an unhealthy zonal replica by using a simple StartZonalShift API call. If the other replicas are healthy and have capacity to serve customers, you can restore your customer experience within minutes. Then, with your customers happily continuing to use your application, you can work on debugging and repairing the unhealthy zonal replica. When you’re ready to return the application workload to the repaired zone, you can cancel the zonal shift, or simply let it expire.
How does a zonal shift work?
When you request to move traffic away from an AZ by calling the zonal shift API, how does it work? Consider a web service running across three AZs behind an NLB, with cross-zone load balancing turned off, as shown in the following diagram. You have synthetic monitoring on each of the NLB’s zonal endpoints, so you can see the success rate and latency for requests for each AZ. Your Amazon CloudWatch dashboard shows that 1% of customer requests (P99) are seeing one second latency. Based on per-AZ metrics, you can see similar elevated latency in AZ3, while latency is unchanged and nominal (~60 ms) in AZ1 and AZ2. You don’t yet know what is causing the elevated latency, but there’s a strong indication that the problem is contained to the replica in AZ3. Requests continue to succeed, so health checks are passing, but a latency increase like this can cause problems for customers.
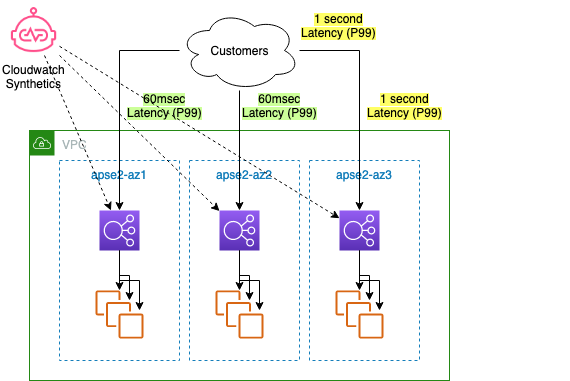
Figure 2. A 3-AZ load balancer architecture with CloudWatch Synthetics detecting elevated latency in one AZ
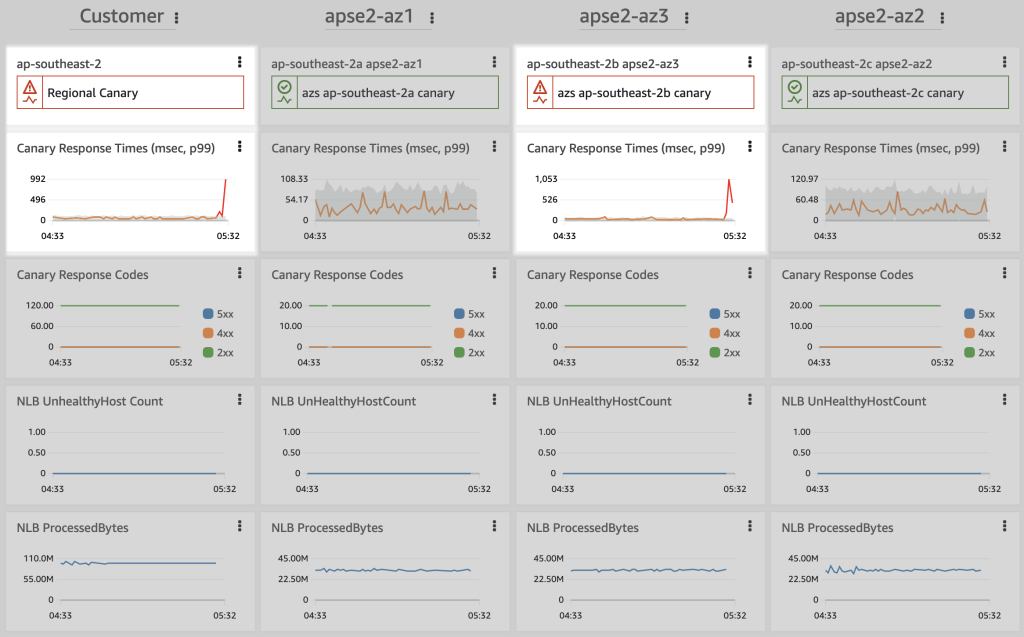
Figure 3. An operational CloudWatch dashboard with customer and per-AZ views. Latency metrics show elevated latency for the customer experience and one AZ
If your web service has sufficient spare compute capacity to handle the removal of one AZ, you can shift traffic away from AZ3 to recover first, and then investigate the problem. How does this work? When you start a zonal shift, you request to route customer traffic away from AZ3. The zonal shift forces the AZ3 load balancer health checks to fail and its IP addresses are withdrawn from DNS. This results in new connections going to only the other AZs. Depending on client behavior and connection reuse, it might take some time for existing connections to drain, though typically it’s only a few minutes.
You can shift traffic away from an AZ by using the StartZonalShift API call, which returns a zonal shift ID. The zonal shift temporarily moves traffic away from an AZ, so it requires an expiration time. It isn’t a permanent configuration change to the load balancer. The following example CLI command with the StartZonalShift API starts a zonal shift that’s set to expire in 12 hours:
aws arc-zonal-shift start-zonal-shift \ --resource-identifier arn:aws:elasticloadbalancing:ap-southeast-2:123456789012:loadbalancer/net/zonal-shift-demo/1234567890abcdef \ --away-from apse2-az3 \ --expires-in 12h \ --comment "Anomaly detected in AZ3, shifting away proactively"
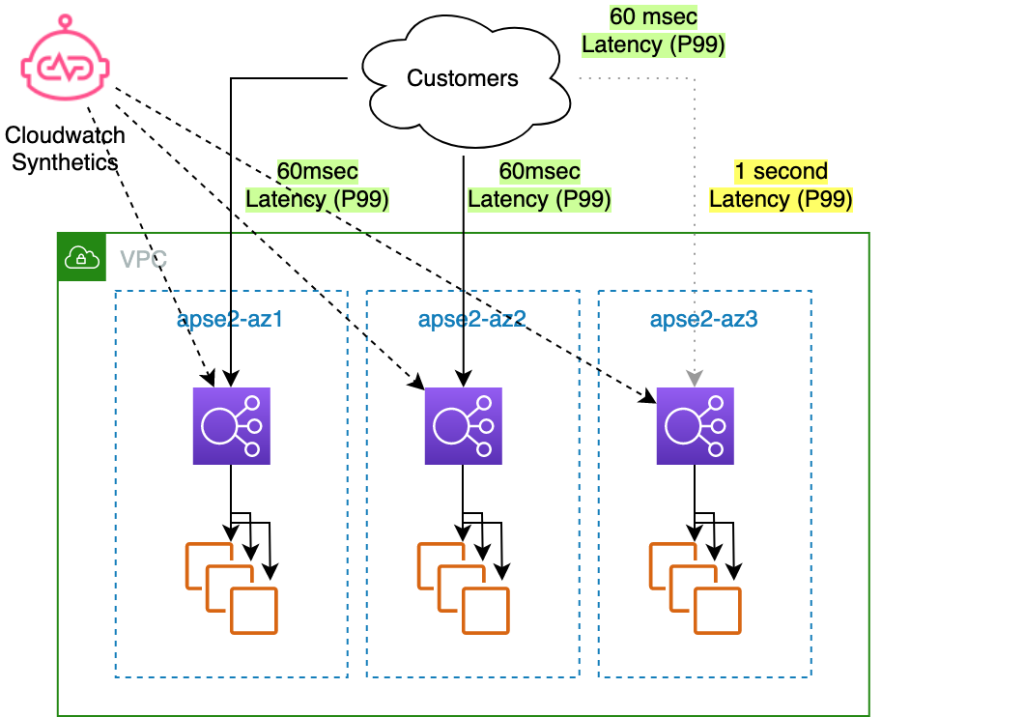
Figure 4. The same 3-AZ load balancer architecture, with a zonal shift in effect to move traffic away from the impaired AZ
Now that the zonal shift has taken effect, the CloudWatch dashboard shows that the ResponseTime metric is back to normal for the customer endpoint. Monitoring shows that the latency problem persists in AZ3, but the AZ is no longer taking customer traffic. You can also see that ProcessedBytes have risen in AZ1 and AZ2, and lowered in AZ3.
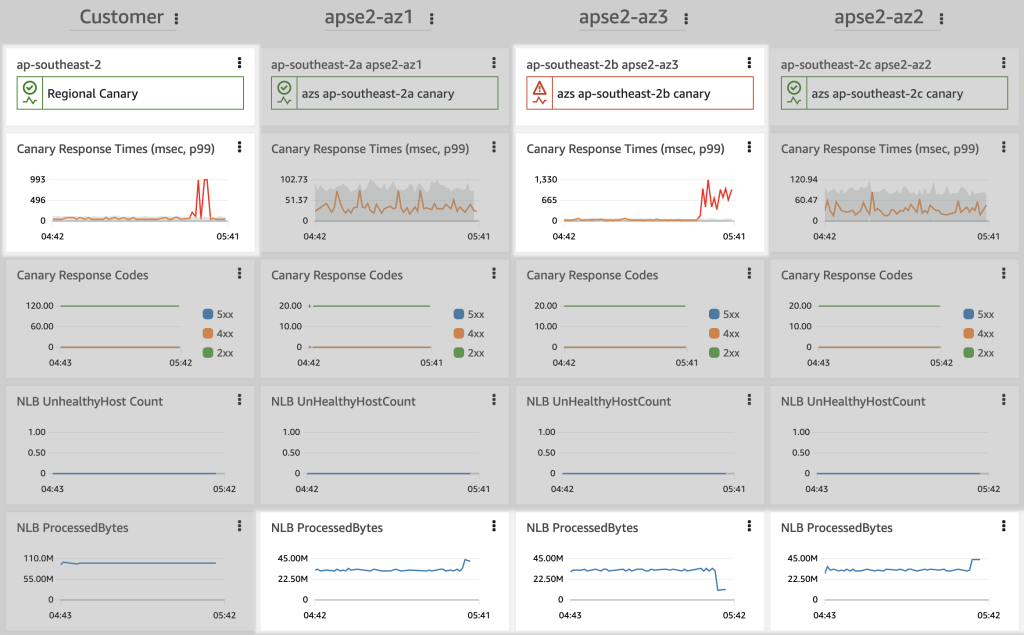
Figure 5. An operational CloudWatch dashboard showing that the zonal shift has resulted in a recovery for the customer experience by moving requests away from the impaired AZ
With your customers now experiencing normal service again, it’s time to investigate the issue in AZ3. Perhaps there was a recent deployment to the AZ? Maybe another team member was doing work that impacted the replica there? Or maybe there’s an ongoing problem in AZ3 that’s visible on the AWS Health Dashboard? Whatever the reason for the impairment, you now have time to investigate and work to address the problem. You can keep the zonal shift in place for as long as it’s needed.
If you need to extend the zonal shift to allow more time for troubleshooting, you can do that with a simple UpdateZonalShift API call. The following example CLI command sets the the zonal shift to expire four hours from now:
aws arc-zonal-shift update-zonal-shift \ --zonal-shift-id <zonal-shift-id> \ --expires-in 4h
When the zonal replica in AZ3 has recovered, you can cancel the zonal shift, or wait for it to expire automatically. To cancel it, use the CancelZonalShift API call with the zonal shift ID. For example, use the following CLI command:
aws arc-zonal-shift cancel-zonal-shift \ --zonal-shift-id <zonal-shift-id>
If you use Amazon Virtual Private Cloud (Amazon VPC) endpoint services, it’s useful to note that when you start a zonal shift for a Regional NLB associated to an Amazon VPC endpoint service, the zonal shift also applies automatically to all of the corresponding Amazon VPC endpoints. This ensures that traffic arriving to your NLB by AWS PrivateLink also respects the zonal shift.
Preparing to respond to single AZ application failures
Now that we’ve discussed how you can start zonal shifts for recovery, let’s look at how to prepare for and apply this strategy effectively.
Detecting failures
You should be able to detect when your application has one unhealthy zonal replica. To do this reliably, you need a per-zone signal of application health. There are several complementary ways that you can do this.
Passive monitoring. Most applications create metrics to track fatal errors, exceptions, response times, or HTTP status codes, such as HTTP status 200 and HTTP status 500. If you include the AZ of the host in your metric dimensions, you can create aggregate metrics that show problems in a single zonal replica. In addition, both ALB and NLB provide per-AZ metrics, such as UnhealthyHostCount and ProcessedBytes. ALB also offers a per-AZ count of HTTP status 500 errors. All of these metrics can help inform your decisions.
Active and synthetic monitoring. In addition to passive monitoring, it’s useful to create synthetic requests against your application to provide a more complete view of the customer experience. Amazon CloudWatch Synthetics provides a managed canary service that can regularly run code of your choice against an endpoint and create metrics. Both ALBs and NLBs provide zonal DNS names in addition to standard Regional DNS names. This lets you create a canary to monitor the responsiveness and reliability of each zonal application replica separately, similar to the following:
ELB name: zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2A: ap-southeast-2a.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2B: ap-southeast-2b.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com Zone 2C: ap-southeast-2c.zonal-shift-demo-1234567890.elb.ap-southeast-2.amazonaws.com
Because CloudWatch Synthetics is a managed service, you can deploy your canary in a nearby AWS Region, to make sure that your monitoring is resilient even to issues within the Region where your application runs.
Additional inputs. In addition to monitoring your application directly for signals about its health, it can be useful to evaluate other inputs, such as notifications from the AWS Health Dashboard. Note that when the Health Dashboard shows an issue in an AZ, it doesn’t necessarily mean that your own application is impacted. For this reason, it’s usually best to also directly measure the health of your application’s zonal replicas.
Dashboards and aggregation. A common starting point for moving traffic away from AZs is to have an operator take manual action (that is, to have a human make the decision) before trying to automate those kinds of traffic moves. For human operators, a simple CloudWatch dashboard similar to the example shown earlier provides a single overall view of your AZs that can help with making quick decisions. Note that CloudWatch dashboards are global. Therefore, after you create one, you can access it from any AWS Region, for added resilience.
Best practices with zonal shifts
Because zonal shifts can remove capacity from a live application, you must be careful when you use them in production. Let’s discuss some of the preparations and safety checks to help make sure that zonal shifts are used safely.
Prescale capacity headroom. When you follow a recovery-oriented strategy, we recommend that you prescale your compute capacity with enough headroom that you can serve your peak traffic with one zonal replica offline. Zonal shifts make this even more important. Starting a zonal shift temporarily removes the capacity of one AZ from behind your load balancer. This means that before you use a zonal shift, you must make sure that you have enough capacity in place in all your AZs. For a 3-AZ ALB or NLB with cross-zone load balancing turned off, when you shift away from one AZ, you should expect about 50% additional load in each of the other two AZs. For a 2-AZ load balancer, you should expect a doubling of load in the other AZ.
If you decide to use a scaling policy instead of prescaling your capacity, think carefully about the policy and metric that you use. For example, average CPU utilization might not produce an increase in response to a zonal shift. That’s because as one part of your Auto Scaling group lowers CPU usage, another part rises.
Ensure that all zonal replicas are healthy and taking traffic. A zonal shift works by marking your application replica in one AZ as unhealthy. Therefore, you must make sure that in other zonal replicas, your targets are healthy and actively taking traffic, before an event occurs that impacts one of the replicas. To ensure that you maintain this awareness, create a dashboard that includes the ELB metrics for both unhealthy targets and the bytesProcessed per AZ, as the example dashboard shown here does.
Test in advance. As with any recovery mechanism, you must practice it regularly to make sure that it works when you need it. We recommend using zonal shifts in advance of a real event, ideally both in your test and production environments. Testing will give you familiarity and confidence when an operational event occurs.
Practice using the API or CLI. To handle failures quickly and successfully, you typically want to use the quickest, most reliable tools with the fewest dependencies. For ease of use, zonal shift is available on the AWS Management Console. But when fast recovery is critical, we recommend that your recovery runbook tell operators to use the AWS Command Line Interface (AWS CLI) or zonal shift API calls, with pre-stored AWS credentials, if possible.
Move traffic only temporarily with zonal shift. As soon as an unhealthy zonal replica for an application is repaired, you should return the replica to service. This makes sure that the overall application returns to its fully redundant and resilient state as quickly as possible.
Automate carefully. A natural next step is to work on automating zonal shifts. This is reasonable, but think carefully about edge cases. For example, if your application becomes overloaded because it experiences a sudden increase in traffic, then you typically don’t want to remove an AZ, as that would make the problem worse. Also, make sure that any automation that you add is careful to check that the other replicas are healthy when a zonal shift starts.
Monitor from a second Region: Consider doing your active monitoring from an adjacent AWS Region. Nearby Regions can be more representative of your application’s customer experience, and monitoring from another Region reduces the issue of shared fate between your application and its monitoring.
Trying out zonal shift
To help you get started with zonal shift in Route 53 ARC, we’ve included an example AWS CloudFormation template that you can download and deploy, to try this capability with a sample NLB application. You can use AWS Fault Injection Simulator (AWS FIS) to simulate a grey failure event, and then start a zonal shift to recover. The template creates an architecture similar to the one described in this blog post. The download includes the following:
- Three-AZ NLB, with cross-zone load balancing turned off
- Auto Scaling group, with hosts running an Apache web server to serve a 1MB file
- Regional CloudWatch Synthetics canary, which polls the 1MB file via the NLB (the customer view)
- Three per-AZ CloudWatch Synthetics canaries, which also poll the 1MB file against their specific zonal NLB endpoints (the per-AZ view)
- CloudWatch alarms based on anomaly detection
- CloudWatch dashboard that shows all data in one view
- AWS FIS experiment template, which injects a gray failure (2% packet loss) into one AZ for 30 minutes
Use this CloudFormation template to try a zonal shift yourself. You can see how a recovery-oriented strategy works by following these steps:
- Download and deploy the CloudFormation template in any AWS Region where zonal shift is available.
- In the AWS Management Console, open the CloudWatch dashboard, and wait for a data pattern to be established.
- Open the FIS dashboard, and start the experiment PacketLossOnInstancesIn-AZ-B, which will inject packet loss in one zonal replica.
- Return to the CloudWatch dashboard, wait for 3-5 minutes, and then look for changes in the customer experience ResponseTime metric. Two AZs should have normal response times, and one AZ should have elevated response times, demonstrating a zonal replica that’s experiencing problems.
- Note or copy the AZ ID of the zonal replica with the elevated response times.
- Open the Route 53 ARC console, and choose Zonal shift.
- Choose Start zonal shift, and then, in the Select the Availability Zone drop-down menu, choose the AZ ID that you noted or copied from the CloudWatch dashboard.
- In the Resources table, select the ARN for the NLB from the CloudFormation stack.
- Under Set zonal shift expiration, select 6 hours.
- Select the Acknowledgement check box, and then choose Start.
Now return to the CloudWatch dashboard. You should see that the customer experience column shows recovery, while the canary for the problem zonal replica continues to show issues. You should also see on the BytesProcessed graph that traffic is moving away from one replica and toward the others.
You can now cancel the FIS experiment or let it expire, and the problem in the affected zonal replica will resolve. You can also cancel the zonal shift: in the Route 53 ARC console, choose the zonal shift that you started, and then choose Cancel zonal shift.
Finally, clean up the resources from your zonal shift experiment by deleting the CloudFormation stack.
To use zonal shift, you need permissions for the zonal shift APIs. Access is granted automatically to IAM users and roles with the Elastic Load Balancing managed policies, ElasticLoadBalancingFullAccess or AdministratorAccess. You can also explicitly grant access to arc-zonal-shift API actions in your own IAM policies.
Available now
Route 53 ARC zonal shift is available now for ALBs and NLBs with cross-zone load balancing turned off, in the AWS Regions listed in the introduction. More AWS Regions and load balancer configurations will be supported in the future. Give zonal shifts a try and let us know your feedback!

Gavin McCullagh
Gavin is a Principal Engineer on the AWS Resilience Infrastructure and Solutions team. He has been with AWS since 2011, working on Amazon’s internal load balancing and DNS solutions as well as AWS services such as Amazon Route 53, Amazon Route 53 Resolver, and Amazon Route 53 Application Recovery Controller. Gavin has a bachelor’s degree and PhD in Chemistry from University College Dublin and a master’s degree in Computer Science from the Hamilton Institute, NUI Maynooth, Ireland.

Deepak Suryanaryanan
Deepak is the General Manager for the AWS Resilience Infrastructure and Solutions team. He has been with AWS since 2011, and regularly engages with customers on how to build resilient applications on AWS, including using capabilities such as Amazon Route 53 Application Recovery Controller to operate recovery-oriented architectures for multi-AZ and multi-Region applications. Deepak has engineering degrees from the University of Madras and North Carolina State University, and an MBA from Duke University.