Amazon Web Services ブログ
オブザーバビリティエージェントで平均復旧時間を短縮する
本記事は 2026 年 2 月 5 日 に公開された「Reduce Mean Time to Resolution with an observability agent」を翻訳したものです。
あらゆる規模のお客様が Amazon OpenSearch Service を活用してオブザーバビリティワークフローを構築し、アプリケーションやインフラストラクチャの可視性を確保しています。インシデント調査では、Site Reliability Engineer (SRE) やオペレーションセンターの担当者が OpenSearch Service でログをクエリし、可視化を確認し、パターンを分析し、トレースを相関させて根本原因を特定し、平均復旧時間 (MTTR) を短縮しています。アラートがトリガーされるインシデントが発生すると、SRE は通常、複数のダッシュボードを行き来し、特定のクエリを作成し、最近のデプロイを確認し、ログとトレースを相関させてイベントのタイムラインを組み立てます。調査プロセスは大部分が手動であるだけでなく、すべてのデータがすぐに利用可能な状態であっても、担当者に認知的負荷をかけます。ここでエージェント AI が役立ちます。クエリ方法を理解し、さまざまなテレメトリシグナルを解釈し、インシデントを体系的に調査できる的確なアシスタントです。
本記事では、OpenSearch Service と Amazon Bedrock AgentCore を使用したオブザーバビリティエージェントを紹介します。根本原因の特定やインサイト取得を高速化し、複数のクエリや相関サイクルを処理して、MTTR をさらに短縮できます。
ソリューション概要
次の図は、オブザーバビリティエージェントの全体アーキテクチャを示しています。
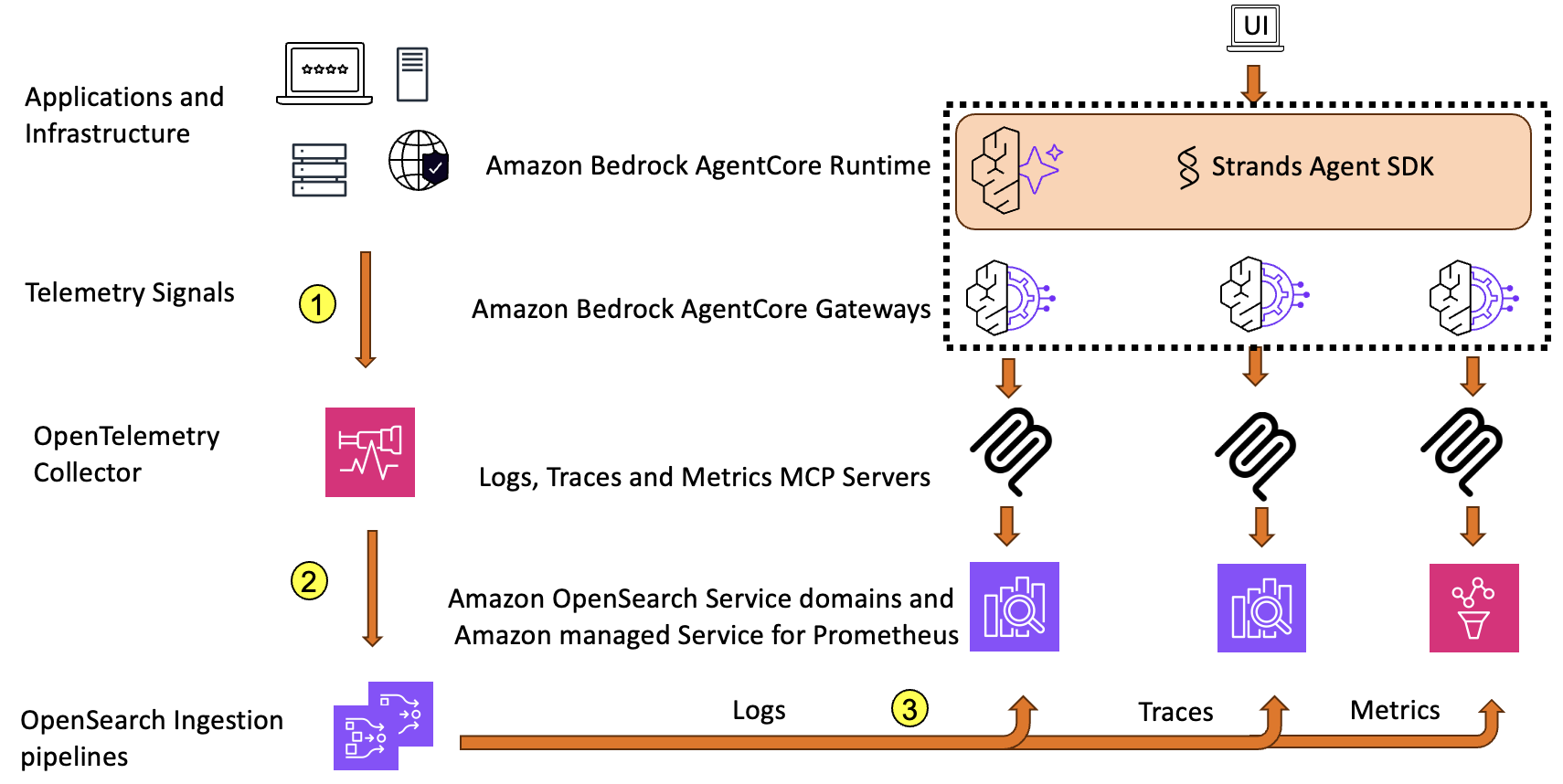
アプリケーションとインフラストラクチャは、ログ、トレース、メトリクスの形式でテレメトリシグナルを出力します。テレメトリシグナルは OpenTelemetry Collector (ステップ 1) で収集され、各シグナル用の個別パイプライン (ログ、トレース、メトリクス) を使用して Amazon OpenSearch Ingestion にエクスポートされます (ステップ 2)。各パイプラインは、シグナルデータを OpenSearch Service ドメインと Amazon Managed Service for Prometheus に配信します (ステップ 3)。
OpenTelemetry は計装の標準であり、幅広い言語とフレームワークにわたってベンダー中立のデータ収集を提供します。さまざまな規模の企業が、特にオープンソースツールにコミットしている企業を中心に、オブザーバビリティのニーズに対してこのアーキテクチャパターンを採用しています。特筆すべきは、オープンソース基盤の上に構築されたアーキテクチャにより、企業がベンダーロックインを回避し、オープンソースコミュニティの恩恵を受け、オンプレミスやさまざまなクラウド環境にわたって実装できる点です。
本記事では、オブザーバビリティのユースケースを示すために OpenTelemetry Demo アプリケーションを使用します。約 20 の異なるマイクロサービスで構成される e コマースアプリケーションで、負荷生成や障害シミュレーション機能とともに、リアルなテレメトリデータを生成します。
オブザーバビリティシグナルデータ用の Model Context Protocol サーバー
Model Context Protocol (MCP) は、エージェントを外部データソースやツールに接続するための標準的な仕組みを提供します。本ソリューションでは、各シグナルタイプに 1 つずつ、3 つの異なる MCP サーバーを構築しました。
Logs MCP サーバーは、OpenSearch Service ドメインに保存されたログデータの検索、フィルタリング、選択のためのツール関数を公開します。エージェントは、単純なキーワードマッチング、サービス名フィルター、ログレベル、時間範囲などのさまざまな条件でログをクエリできます。調査中に実行する一般的なクエリを模倣しています。次のスニペットは、ツール関数の疑似コードを示しています。
Traces MCP サーバーは、分散トレースの検索と情報取得のためのツール関数を公開します。Traces MCP サーバーの関数は、トレース ID によるトレースの検索、特定のサービスのトレースの検索、トレースに属するスパン、スパンに基づいて構築されたサービスマップ情報、レート、エラー、期間 (RED メトリクスとも呼ばれる) の取得に役立ちます。エージェントはサービス間のリクエストパスを追跡し、障害が発生した場所やレイテンシーの発生源を特定できます。
Metrics MCP サーバーは、時系列メトリクスをクエリするためのツール関数を公開します。エージェントはこれらの関数を使用して、エラー率のパーセンタイルやリソース使用率を確認できます。システム全体の健全性を理解し、異常な動作を特定するための重要なシグナルです。
3 つの MCP サーバーは、調査エンジニアが使用するさまざまなタイプのデータにまたがり、エージェントがログ、トレース、メトリクス間で自律的に相関させて問題の根本原因を特定するための完全なワーキングセットを提供します。さらに、カスタム MCP サーバーは、収益、売上、その他のビジネスメトリクスに関するビジネスデータのツール関数を公開します。OpenTelemetry デモアプリケーションでは、影響やその他のビジネスレベルのメトリクスのコンテキストを提供するための合成データを開発できます。簡潔にするため、アーキテクチャの一部としてそのサーバーは示していません。
オブザーバビリティエージェント
オブザーバビリティエージェントはソリューションの中心です。インシデント調査を支援するために構築されています。従来の自動化や手動のランブックは通常、事前定義された運用手順に従いますが、オブザーバビリティエージェントでは定義する必要がありません。エージェントは利用可能なデータに基づいて分析、推論し、発見した内容に基づいて戦略を適応させます。ログ、トレース、メトリクス間で発見を相関させて根本原因に到達します。
オブザーバビリティエージェントは、AI エージェントの開発を簡素化するオープンソースフレームワークである Strands Agent SDK で構築されています。SDK は、公開されたツールを呼び出し、一貫したターンベースのインタラクションを維持することで、基盤となるオーケストレーションと推論 (エージェントループ) を処理する柔軟性を備えたモデル駆動型アプローチを提供します。ツールを動的に検出する実装のため、機能変更時もエージェントは最新情報に基づいて意思決定できます。
エージェントは Amazon Bedrock AgentCore Runtime で実行されます。エージェントのホスティングと実行のためのフルマネージドインフラストラクチャを提供し、Strands、LangGraph、CrewAI などの一般的なエージェントフレームワークをサポートしています。また、多くの企業が本番グレードのエージェントを実行するために必要とするスケーリング、可用性、コンピューティングも提供します。
3 つすべての MCP サーバーに接続するために Amazon Bedrock AgentCore Gateway を使用します。エージェントを大規模にデプロイする場合、ゲートウェイはカスタムコード開発、インフラストラクチャのプロビジョニング、入出力のセキュリティ、統合アクセスなどの管理タスクを削減するために不可欠なコンポーネントです。ワークロードを本番環境に移行する際に必要な企業機能です。このアプリケーションでは、Server-Sent Events を使用して 3 つすべての MCP サーバーをターゲットとして接続するゲートウェイを作成します。ゲートウェイは Amazon Bedrock AgentCore Identities と連携して、安全な認証情報管理とユーザーから通信エンティティへの安全な ID 伝播を提供します。サンプルアプリケーションでは、ID 管理と伝播に AWS Identity and Access Management (IAM) を使用しています。
インシデント調査は多くの場合、複数のステップからなるプロセスです。反復的な仮説検証、複数回のクエリ、時間をかけたコンテキストの構築が含まれます。会話コンテキストの維持に Amazon Bedrock AgentCore Memory を使用します。本ソリューションでは、セッションベースの名前空間を使用して、異なる調査の会話スレッドを分離しています。たとえば、調査中にユーザーが「Payment service はどうですか?」と尋ねると、エージェントはメモリから最近の会話履歴を取得して、以前の発見を認識し続けます。ユーザーの質問とエージェントの応答の両方をタイムスタンプとともに保存し、エージェントが会話を時系列で再構築し、すでに完了した発見について推論できるようにしています。
オブザーバビリティエージェントは、推論に Amazon Bedrock の Anthropic Claude Sonnet v4.5 を使用するように設定しています。モデルは質問を解釈し、呼び出す MCP ツールを決定し、結果を分析し、一連の質問または結論を策定します。システムプロンプトを使用して、モデルに経験豊富な SRE またはオペレーションセンターエンジニアのように考えるよう指示しています。「高レベルのチェックから始め、影響を受けるコンポーネントを絞り込み、テレメトリシグナルタイプ間で相関させ、根拠とともに結論を導き出す。サービス間の依存関係を調査するためのドリルダウンなど、論理的な次のステップを提案するようモデルに求める。」エージェントは一般的なさまざまなインシデント調査を分析し推論する汎用性を持ちます。
オブザーバビリティエージェントの動作
次の図のように、アプリケーション全体のリアルタイム RED (レート、エラー、期間) メトリクスダッシュボードを構築しました。
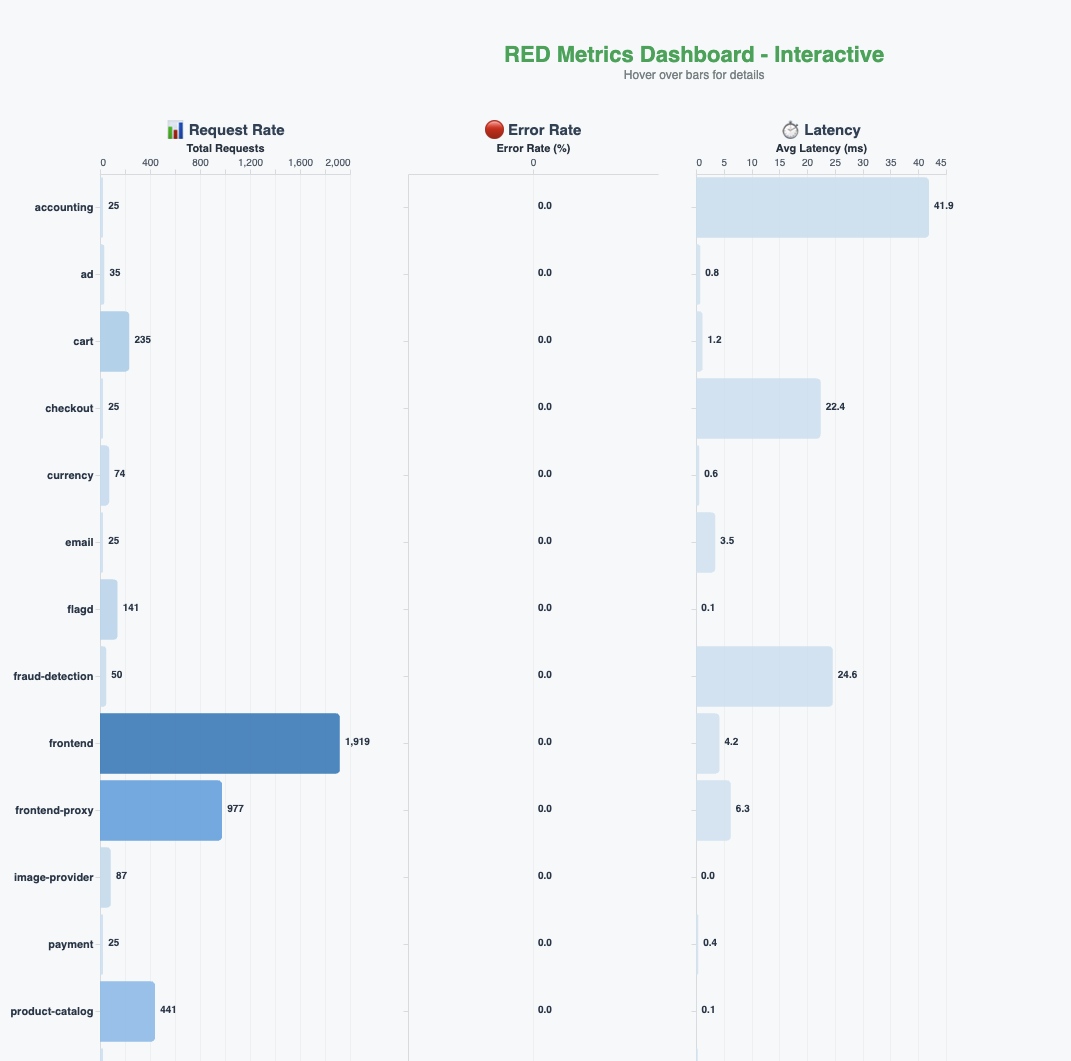
ベースラインを確立するために、エージェントに次の質問をしました。「過去 5 分間にアプリケーションでエラーは発生していますか?」エージェントはトレースとメトリクスをクエリし、結果を分析し、システムにエラーがないと応答します。すべてのサービスがアクティブで、トレースは正常で、システムはリクエストを正常に処理していると報告します。エージェントはさらなる調査に役立つ可能性のある次のステップも積極的に提案します。
障害の導入
OpenTelemetry デモアプリケーションには、システムに意図的な障害を導入するために使用できるフィーチャーフラグがあります。また、エラーが顕著に表面化するように負荷生成も含まれています。フィーチャーフラグと負荷生成を使用して、payment service にいくつかの障害を導入します。前の図のリアルタイム RED メトリクスダッシュボードは影響を反映し、エラー率の上昇を示しています。
調査と根本原因分析
エラーを生成しているので、再びエージェントを使用します。通常、調査セッションの開始です。また、アラームのトリガーやページの送信など、調査の開始をトリガーするワークフローもあります。
「ユーザーから商品の購入に時間がかかるという苦情が来ています。何が起きているか確認してもらえますか?」と質問します。
エージェントはメモリから会話履歴を取得し (存在する場合)、ツールを呼び出してサービス全体の RED メトリクスをクエリし、結果を分析します。重大な購入フローのパフォーマンス問題を特定します。payment service は接続危機にあり完全に利用不可で、fraud detection、ad service、recommendation service で極端なレイテンシーが観測されています。エージェントは即時のアクション推奨事項 (payment service の接続復旧を最優先) を提供し、payment service のログ調査を含む次のステップを提案します。
エージェントの提案に従い、ログを調査するよう依頼します。「payment service のログを調査して接続の問題を理解してください。」
エージェントは checkout と payment service のログを検索し、トレースデータと相関させ、サービスマップからサービスの依存関係を分析します。cart service、product catalog service、currency service は正常ですが、payment service は完全に到達不能であることを確認し、意図的に導入した障害の根本原因を正常に特定します。
根本原因を超えて: ビジネスへの影響分析
前述のとおり、別の MCP サーバーに合成ビジネス売上および収益データがあるため、ユーザーがエージェントに「checkout と payment service の障害によるビジネスへの影響を分析してください」と尋ねると、エージェントはビジネスデータを使用し、トレースからトランザクションデータを調べ、推定収益への影響を計算し、checkout 障害による顧客離脱率を評価します。エージェントが根本原因の特定を超えて、将来の問題解決のためのランブック作成などの運用活動を支援できることを示しています。SRE を介さない自動修復を提供するための第一歩となり得ます。
メリットと結果
本記事の障害シナリオは説明のために簡略化されていますが、MTTR の短縮に直接貢献するいくつかの主要なメリットを強調しています。
調査サイクルの高速化
トラブルシューティングの従来のワークフローでは、各ステップで仮説、検証、クエリ、データ分析の複数の反復が必要で、コンテキストスイッチングが発生し、何時間もの労力を消費します。オブザーバビリティエージェントは、自律的な推論、相関、アクションにより、調査時間を数分に大幅に短縮し、MTTR を削減します。
複雑なワークフローの処理
実際の本番シナリオでは、カスケード障害や複数のシステム障害が発生することがよくあります。オブザーバビリティエージェントの機能は、履歴データとパターン認識を使用して複雑なシナリオにも拡張できます。たとえば、時間的または ID ベースの相関、依存関係グラフ、その他の手法を使用して、関連する問題を誤検知から区別し、SRE が無関係な異常に対する無駄な調査労力を回避できるようにします。
単一の回答を提供するのではなく、エージェントは潜在的な根本原因にわたる確率分布を提供し、SRE の修復方法の優先順位付けを支援できます。例:
- Payment service のネットワーク接続の問題: 75%
- ダウンストリームの payment gateway タイムアウト: 15%
- データベース接続プールの枯渇: 8%
- その他/不明: 2%
エージェントは現在の症状を過去のインシデントと比較し、過去に同様のパターンが発生したかどうかを特定できるため、リアクティブなクエリツールからプロアクティブな診断アシスタントへと進化します。
まとめ
インシデント調査は依然として大部分が手動です。SRE はダッシュボードを操作し、クエリを作成し、すべてのデータがすぐに利用可能な状態であっても、プレッシャーの下でシグナルを相関させています。本記事では、Amazon Bedrock AgentCore と OpenSearch Service で構築されたオブザーバビリティエージェントが、ログ、トレース、メトリクスを自律的にクエリし、発見を相関させ、SRE をより迅速に根本原因に導くことで、認知的負担を軽減できることを示しました。本記事のパターンは 1 つのアプローチですが、Amazon Bedrock AgentCore の柔軟性と OpenSearch Service の検索および分析機能を組み合わせることで、インシデントライフサイクルのさまざまな段階で、さまざまなレベルの自律性で、または特定の調査タスクに焦点を当てて、組織固有の運用ニーズに合わせてエージェントをさまざまな方法で設計およびデプロイできます。エージェント AI は既存のオブザーバビリティへの投資を置き換えるのではなく、インシデント調査中にデータを効果的に活用する方法を提供することで増幅します。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。