Amazon Web Services ブログ
AWS Fault Injection Service を使用した Amazon ElastiCache の耐障害性テスト
本記事は 2026 年 2 月 23 日に公開された “Resilience testing on Amazon ElastiCache with AWS Fault Injection Service” を翻訳したものです。
Amazon ElastiCache は、Valkey、Memcached、Redis OSS をサポートするフルマネージドのインメモリキャッシングサービスで、99.99% の可用性を提供しながら、コスト効率の良い価格でアプリケーションのパフォーマンスをリアルタイムに向上させます。
頻繁にアクセスされるデータに対してサブミリ秒のレスポンスタイムを提供するため、データベースクエリのキャッシング、Web セッション状態の管理、ゲームのリアルタイムリーダーボードの実現などに広く使用されています。
多くのアプリケーションは、キャッシュが常に利用可能であることを前提に構築されています。
耐障害性テストを行わないと、Amazon ElastiCache へのアクセスが失われた際にアプリケーションで問題が発生することがよくあります。
アプリケーションがデータベースへ適切にフォールバックせずにクラッシュすることに気づくかもしれませんが、それは本番環境でのインシデント発生時、つまり手遅れになってからのことです。
そのため、キャッシュが利用できなくなるイベントに備えて構築し、アプリケーションが期待どおりにそれらの障害ケースを処理することをテストする必要があります。
この投稿では、AWS Fault Injection Service (AWS FIS) を使用して Amazon ElastiCache で耐障害性テストを実行する方法と、アプリケーションの耐障害戦略を強化するためにAWS FISをどのように活用できるかをご紹介します。
ソリューションの概要
このソリューションでは、AWS FIS を使用しています。
これは、AWS ワークロードに対して制御された障害注入実験を実施するためのフルマネージドな耐障害性テストサービスです。
メンテナンスや特権を必要とするカスタムスクリプトやサードパーティツールに頼る代わりに、AWS FIS はシステムの耐障害性をテストするための安全でスケーラブル、かつ高可用性のプラットフォームを提供します。
AWS FIS は、システムにストレスがかかった際の応答を観察するために、意図的に障害を発生させるという手法に基づいて動作します。
これらの実験により、弱点を特定し、システムの動作に関する仮定を検証し、実際の障害に耐えるアプリケーションの能力に対する信頼を高めることができます。
AWS FIS を使用すると、テスト環境または本番環境で耐障害性テストを実施できます。
例えば、ピークトラフィック時の Amazon ElastiCache ノード障害のような現実的なシナリオをテストし、最も重要な場面でフェイルオーバーの仕組みが機能することを確認できます。
この記事では、耐障害性テスト用の ElastiCache クラスターのセットアップ方法、AWS FIS 実験テンプレートの作成方法、制御されたフェイルオーバーテストの実行方法、および結果のモニタリングと解釈方法について説明します。
前提条件
このソリューションを実装する前に、以下を確認してください:
- アクティブな AWS アカウント
- テスト用の非本番環境
- Amazon ElastiCache サービスの基本的な理解
このソリューションでは、新しい AWS リソースの作成と利用が必要です。
そのため、アカウントに費用が発生します。
詳細については、AWS Pricing を参照してください。
本番環境に実装する前に、非本番環境でセットアップし、エンドツーエンドの検証を実行することを強くお勧めします。
方法論
この実験では、Amazon ElastiCache が自動フェイルオーバーを使用してノード障害時に高可用性を維持する方法を示します。
Multi-AZ が有効でクラスターモードが無効な Amazon ElastiCache for Valkey クラスターでノード障害を発生させ、アプリケーションが手動介入なしで復旧できることを確認します。
フェイルオーバー中は、以下のアクションが実行されます。
- 障害検出: ElastiCache がプライマリノードの障害を検出します。
- レプリカの昇格: レプリケーションラグが最も小さいレプリカがプライマリに昇格します。
- DNS 更新: プライマリエンドポイントが自動的に新しいプライマリを指すようになるため、アプリケーションは同じ接続文字列を引き続き使用できます。
- ノードの復旧: 障害が発生したノードは、復旧後にリードレプリカとして再参加します。
クラスターモード無効の構成を使用しているのは、フェイルオーバープロセスをコンソールで観察しやすくするためです。個々のノードの役割がプライマリからレプリカに変わる様子を明確に確認できます。
ただし、これらのテスト原則はクラスターモード有効のデプロイメントにも適用されます。クラスターモード有効の場合、設定エンドポイントがすべてのシャード間のルーティングを自動的に管理します。
この実験は実は ElastiCache Serverless では意味がありません。ElastiCache Serverless はマネージドプロキシの背後で Multi-AZ フェイルオーバーを処理するため、アプリケーションは中断の影響を受けません。
ElastiCache Serverless の仕組みについては、ドキュメントを参照してください。
耐障害性の高いアプリケーションでは、接続の中断は短時間にとどまり、自動的に再接続し、データベースに過負荷をかけることなく一時的にフォールバックできる必要があります。
ウォークスルー
Valkey クラスターの作成
既存の Amazon ElastiCache for Valkey クラスターモード無効クラスターを使用するか、Valkey (クラスターモードが無効) クラスターの作成 (コンソール) の手順に従って新しいクラスターを起動できます。
このテストでは、Amazon ElastiCache の汎用バースト可能な T4g または T3-Standard microキャッシュノードを使用することで、コストを抑えることができます。
次のスクリーンショットは、プライマリノードと 3 つのレプリカノードを持つクラスターを示しています:
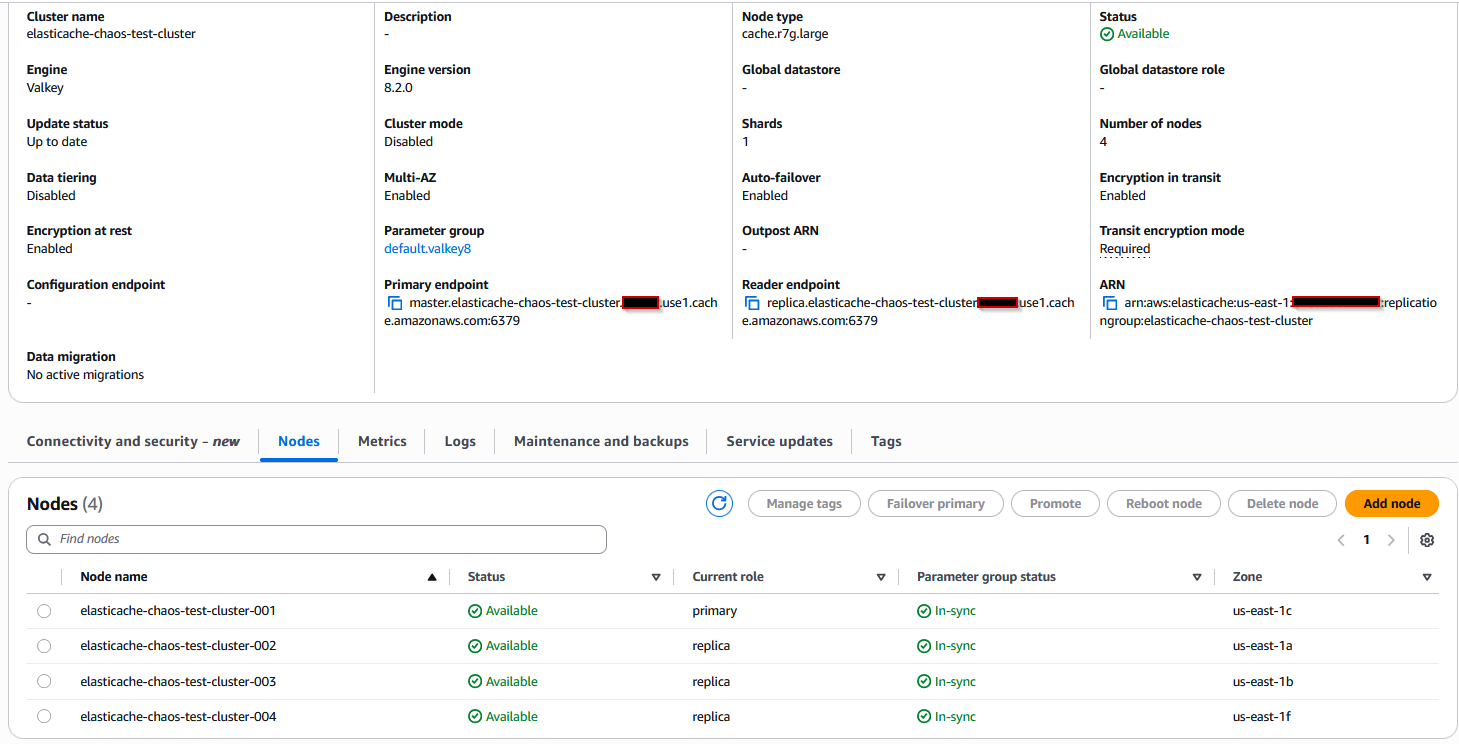
また、クラスターにキー名と値を持つタグを作成します。
以下のスクリーンショットでは、キーを fis-testing、値を yes としています。
このタグは、AWS FIS 実験テンプレートでターゲットの詳細を編集する際に使用します。

AWS FIS テンプレートのセットアップ
Amazon ElastiCache クラスターの準備が整い利用可能になったら、以下のような AWS FIS テンプレートを作成します。このテンプレートでは、注入する障害の種類と対象となるリソースを定義します。
AWS FIS を使用するには、AWS リソースで実験を実行して、障害条件下でアプリケーションやシステムがどのように動作するかという仮説をテストします。
実験を実行するには、まず実験テンプレートを作成します。
テンプレートの詳細については、ドキュメントを参照してください。
- AWS FIS コンソールを開きます。
- ナビゲーションペインで、Experiment templates を選択します。
- Create experiment template を選択します。
- 最初のステップ Specify template details で、テンプレートの詳細に関連する説明と名前を入力し、Account targeting はこのアカウントのままにしておきます。
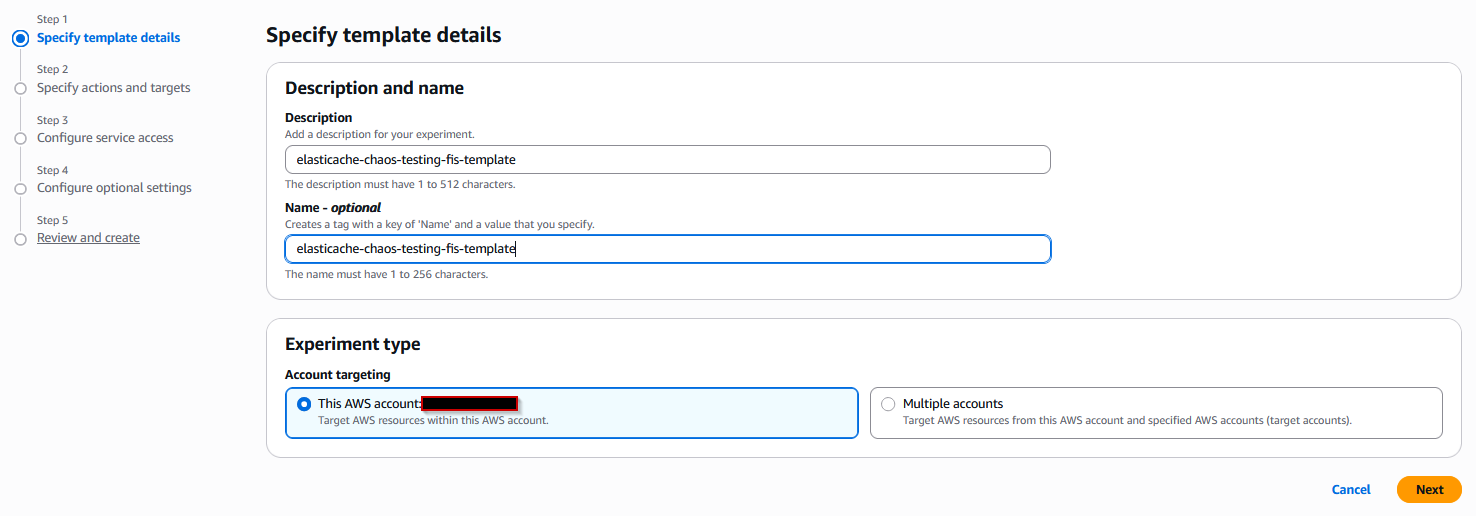
- Next を選択します。Actions と Targets コンポーネントを設定する前に、それらの用途を理解しておく必要があります。
アクションは、ターゲットに対して実行される障害注入アクティビティです。
AWS FIS は、さまざまな AWS サービス向けのアクションを提供しています。
実験テンプレートにアクションを追加すると、AWS FIS はそれを使用して実験を実行します。
ターゲットは、実験中に AWS FIS がアクションを実行する AWS リソースです。
実験テンプレートを作成するときにターゲットを定義し、複数のアクションで使用できます。
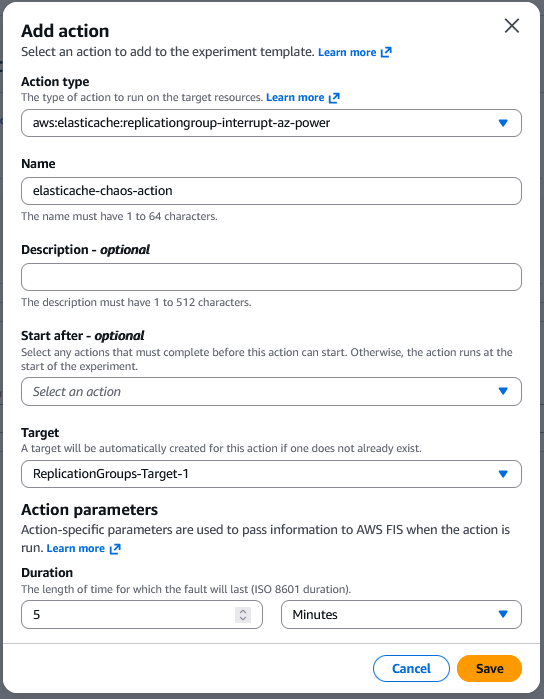
AWS FIS は、アクションを開始する前にターゲットを特定し、実験全体を通じてそれらを使用します。 - Add Action を選択します。
- Action Type で、
aws:elasticache:replicationgroup-interrupt-az-powerを選択して、Multi-AZ が有効になっているターゲット ElastiCache レプリケーショングループの指定されたアベイラビリティーゾーン内のノードへの電源を中断します。レプリケーショングループごとに一度に影響を受けるアベイラビリティーゾーンは 1 つだけです。
プライマリノードがターゲットになると、レプリケーションラグが最も少ない対応するリードレプリカがプライマリに昇格します。
指定されたアベイラビリティーゾーン内のリードレプリカの置き換えは、このアクションの期間中ブロックされます。
つまり、ターゲットのレプリケーショングループは容量が減少した状態で動作します。
詳細については、ドキュメントを参照してください。 - 必要に応じて関連する Name を入力します。
- Target には、Targets セクションで定義したターゲットを選択します。
このアクションのターゲットをまだ定義していない場合、AWS FIS が新しいターゲットを作成します。 - Action parameters で、アクションのパラメータを指定します。
テスト要件に応じて duration を設定してください。
これは、ターゲットノードで障害アクションが継続する時間の長さです。 - Save を選択します。
- アクションを保存すると、次のスクリーンショットに示すようにターゲットが自動的に作成されます。
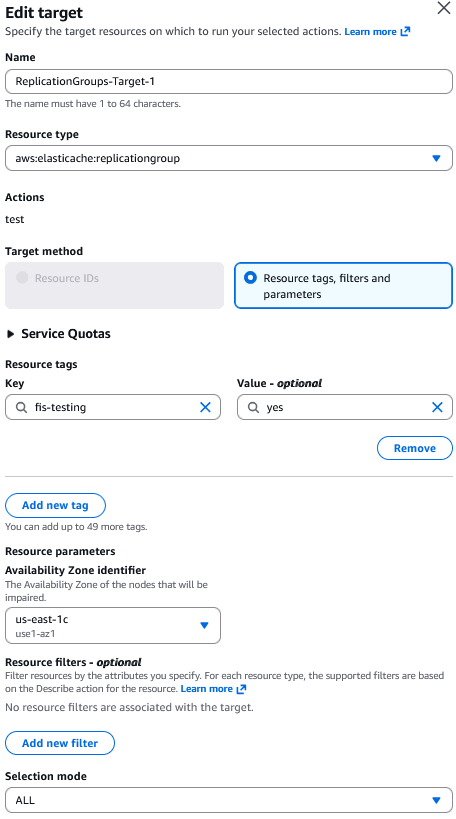
aws:elasticache:replicationgroupを選択して Edit Target ページを開きます。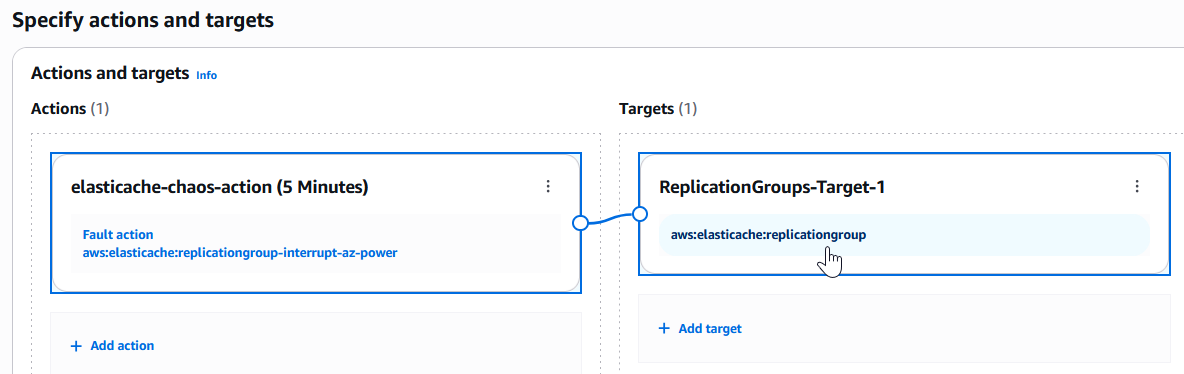
- Target method では、Resource tags, filters and parameters ラジオボタンがすでに選択されています。
Amazon ElastiCache をターゲットにするには、resourceTags要素でタグのみを指定できます。 - Add new tag ボタンを選択してリソースタグを追加します。
ここでは、キーをfis-testing、値をyesとして使用しています。 - Availability Zone identifier ドロップダウンで、このテストで障害を発生させたいノードのアベイラビリティーゾーンを選択する必要があります。
プライマリノードを含むアベイラビリティーゾーンを選択すると、その AZ が影響を受けたときにフェイルオーバーがトリガーされます。 - Selection mode では、識別されたすべてのターゲットで実行するデフォルトオプションの ALL を選択します。
- Save を選択します。
- Next を選択します。
- Service access セクションで、デフォルトの選択である Create a new role for the experiment template のままにします。
コンソールに表示されているサービスロール名をコピーしてください。後で使用します。
このステップが完了すると、コンソールに表示されている名前で IAM ロールが作成されます。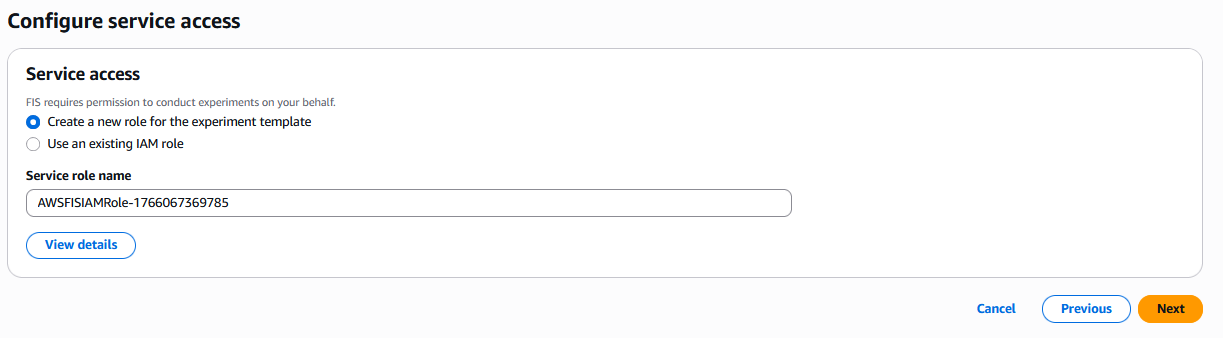
- Next を選択します。
- Send to CloudWatch Logs チェックボックスを選択します。
- ロギングは、実験のタイミングとアプリケーションの動作を関連付けるのに役立つため、Amazon CloudWatch 統合を設定しましょう。
そのためには、まず CloudWatch にロググループを作成する必要があります。
ロググループを作成するには、CloudWatch ドキュメントの手順に従ってください。 - テンプレート作成の AWS FIS タブで、Logs セクションの Browse オプションを選択し、右側の Refresh ボタンを使用します。
- 作成したロググループ名を検索します。
Log version として Version 2 を選択します。
次のスクリーンショットでは、ロググループ名としてaws-fis-elasticacheを使用しています。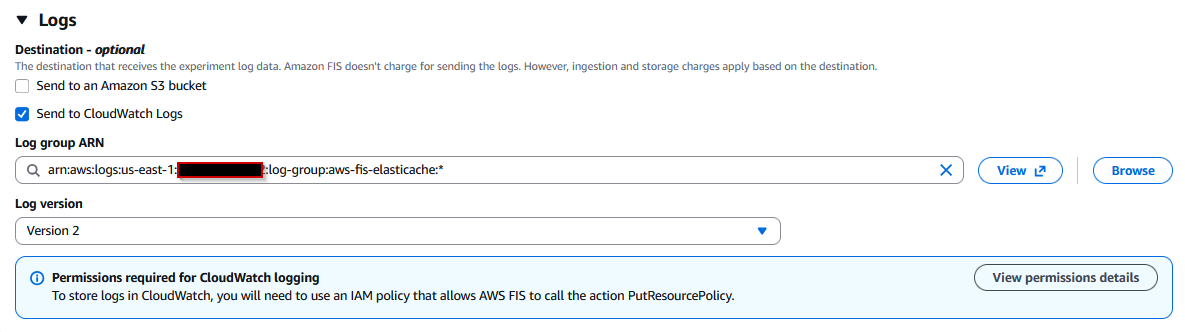
- View Permission details ボタンを選択し、Amazon CloudWatch ロギングに必要な権限ポリシーをコピーしてメモ帳に貼り付けます。
後のセクションで、ステップ 19 で作成されたロールを更新するために使用します。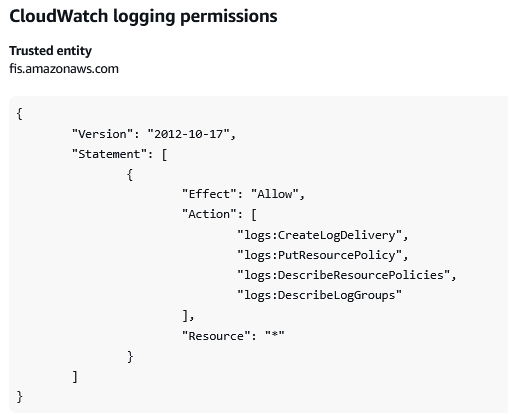
- ロギングは、実験のタイミングとアプリケーションの動作を関連付けるのに役立つため、Amazon CloudWatch 統合を設定しましょう。
- Next を選択します。
- テンプレートを確認し、Create experiment template を選択します。
Amazon CloudWatch 用の AWS IAM ロールの編集
テンプレートが作成されたら、CloudWatch ロギングに必要な権限を持つように、作成した IAM ロールを編集する必要があります。
IAM コンソールを開き、IAM ロールを選択すると、このロールに 2 つのポリシーがアタッチされていることがわかります。
FIS-Console-CWLogging-XXXX という名前で作成されたポリシーを編集し、前述のポリシー JSON ドキュメントをコピーして、ポリシーを保存します。
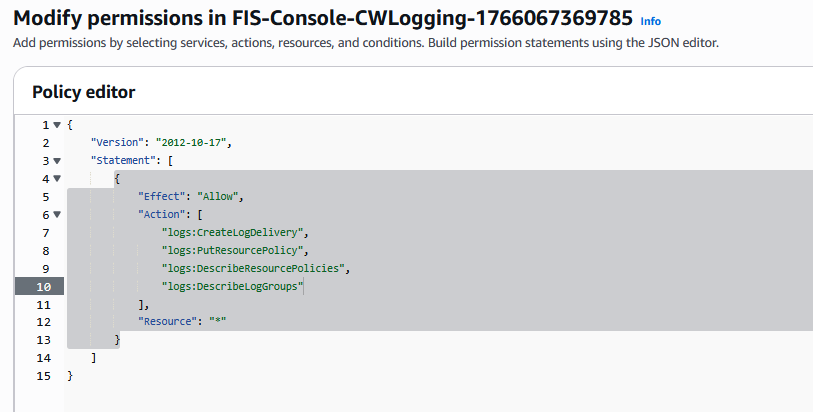
AWS FIS 実験の実行
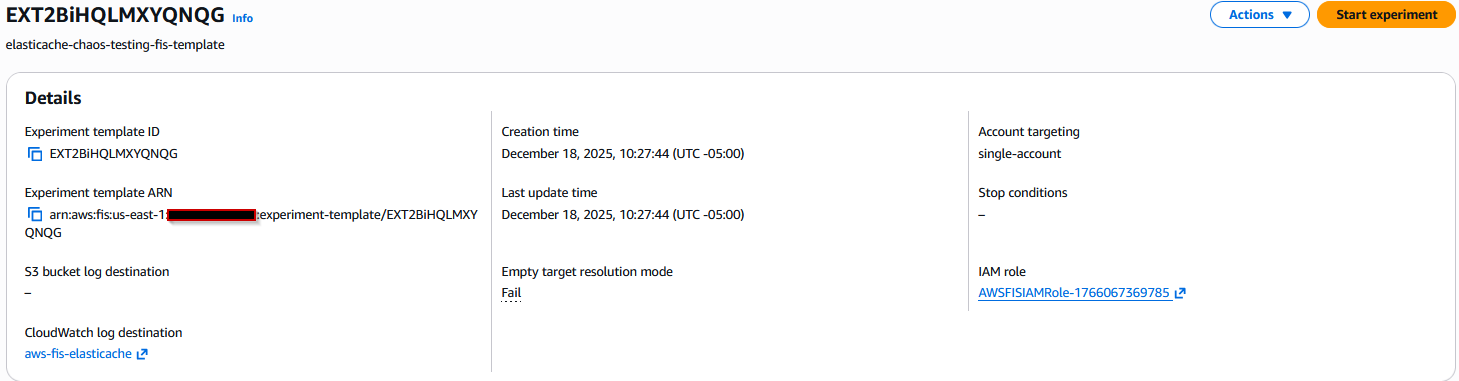
AWS FIS コンソールページで、ステップ 2 で作成したテンプレートの右上にある Start experiment を選択し、開始操作を続行します。
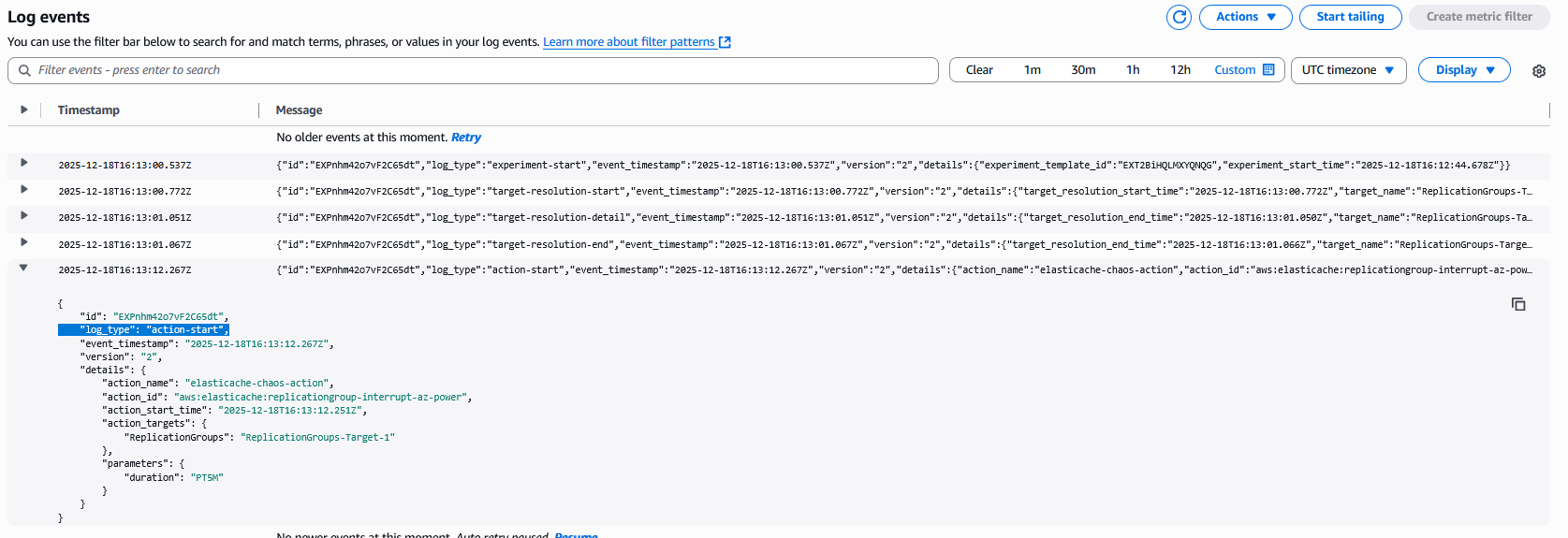
モニタリングとログの確認
実験の状態が Running 状態になることを確認できます。
CloudWatch ログの送信先リンクを選択して、先ほど作成したロググループ aws-fis-elasticache の CloudWatch ログを開きます。
ログイベントには、log_type:action-start のログエントリが 1 つ表示されます。
これは、実験が実際にアクションを実行している、または有効になっている時刻を示しています。
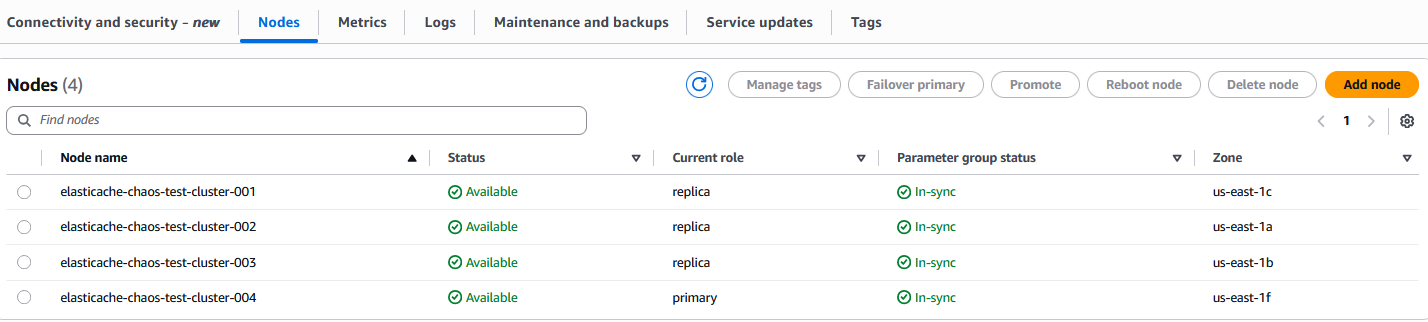
Amazon ElastiCache コンソールに移動すると、クラスターのステータスとノードが以下のように Modifying 状態になっていることが確認できます:
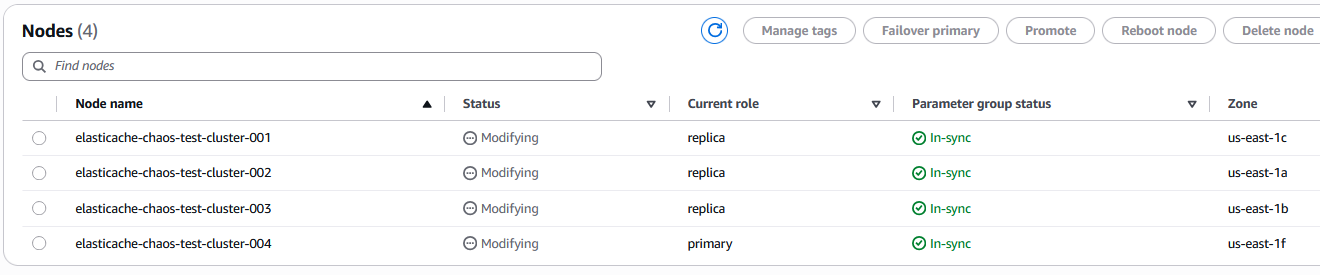
また、ノード elasticache-chaos-test-cluster-001 のロールが primary から replica に変更されていることにも気づくでしょう。
これは、以下に示すように Amazon ElastiCache で公開されたイベントからも確認できます:
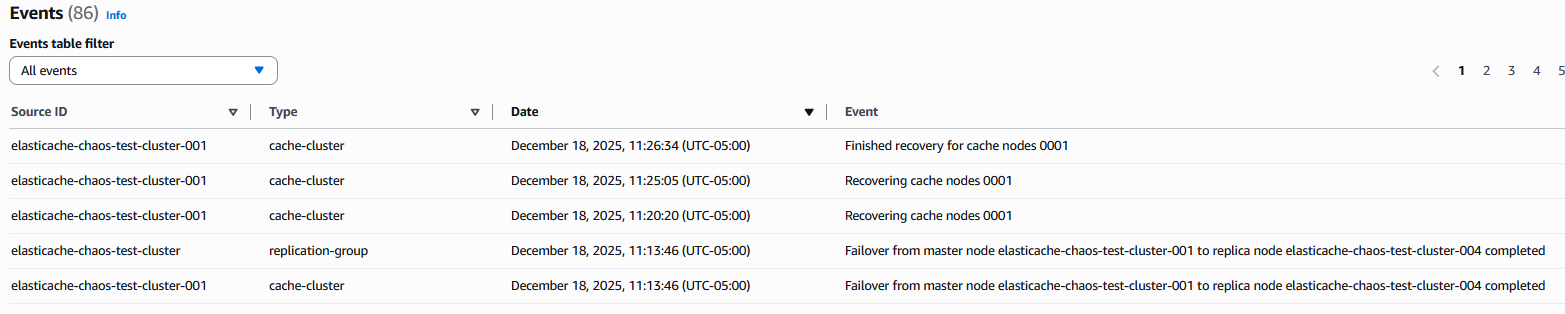
フェイルオーバーは、ロググループ aws-fis-elasticache の AWS FIS ログによると、アクション開始時刻から数秒以内に完了しました。
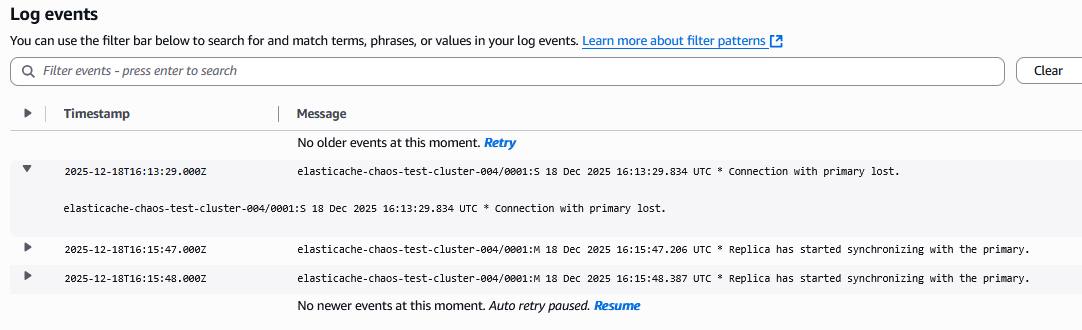
Amazon ElastiCache クラスターのログを有効にしている場合、他のノードがプライマリノードとの接続の問題を示すログも確認できます。
5 分間 (テンプレートの Action ページのデフォルト設定) が経過すると、AWS FIS ログに log_type:action-end が表示されます:

Amazon ElastiCache コンソールでは、ノードとクラスターのステータスが Available と表示されます。
耐障害性の検証: 確認すべきポイントと対応方法
耐障害性テストの実行は最初のステップに過ぎません。
本当の価値は、フェイルオーバー中に何が起こったかを理解し、アプリケーションがそれを適切に処理できることを確認することにあります。
ElastiCache イベントの理解
ElastiCache イベントは、フェイルオーバー中のクラスターの健全性を可視化します。
確認すべき主要なイベントは以下の通りです:
- Recovering cache nodes は、影響を受けたノードが復元中であることを示します
- Finished recovery for cache nodes は、元のノードがレプリカとしてクラスターに再参加したことを確認します
- フェイルオーバープロセス全体は、Multi-AZ 構成の場合、通常数秒以内に完了します
クラスターログの分析
ElastiCache クラスターでエンジンログを有効にしている場合、フェイルオーバー中の詳細な接続動作を確認できます:
- レプリカがプライマリノードの障害を検出した正確なタイミング
- 「Connecting to MASTER」や「Replica has started synchronizing with the primary」などのメッセージは、リカバリプロセスを示しています
- 同期成功のメッセージは、データの一貫性が維持されたことを確認しています
アプリケーションの耐障害性テスト
ElastiCache はフェイルオーバーを自動的に処理しますが、この期間中のアプリケーションの動作が重要です。
- 接続処理: 適切に設計されたアプリケーションでは、短時間の接続エラー (5 〜 15 秒) の後に自動的に再接続されるはずです。より長い停止時間は、接続プールの設定やリトライロジックに問題があることを示しています。
- キャッシュミス時の動作: アプリケーションがデータベースに過負荷をかけることなく、適切にフォールバックすることを確認してください。データベースのクエリレートは一時的に増加しますが、管理可能な範囲に収まるべきです。
- パフォーマンスの低下: フェイルオーバーの前、最中、後のレスポンスタイムを測定してください。耐障害性のあるアプリケーションでは、フェイルオーバー中にレイテンシーが 50ms から 200ms に増加し、その後正常に戻ることがあります。1 秒を超えるスパイクが発生した場合は、接続タイムアウトとリトライの設定を調査する必要があります。
Amazon ElastiCache でのアプリケーション動作の監視の詳細については、Monitoring best practices with Amazon ElastiCache for Redis using Amazon CloudWatch を参照してください。
まとめ
この記事では、AWS Fault Injection Service (AWS FIS) を使用して Amazon ElastiCache で耐障害性テストを実装する方法を学びました。
このテストにより、キャッシュ戦略の弱点を事前に特定し、フェイルオーバーメカニズムを検証し、実際のインシデントが発生する前に適切な縮退動作を確保できます。
これらの実験を実行することで、チームはインシデント対応手順を練習し、キャッシュ障害がシステムアーキテクチャ全体に与える連鎖的な影響を理解できるようになります。
Amazon ElastiCache 全般のベストプラクティスについては、ElastiCache のベストプラクティスとキャッシュ戦略を参照してください。
クリーンアップ
このウォークスルーのために新しい Amazon ElastiCache クラスターを作成した場合は、ElastiCache でのクラスターの削除ドキュメントの手順に従ってクラスターを終了し、コストを最適化できます。
また、実験テンプレートを削除するドキュメントの手順に従って AWS FIS 実験テンプレートを削除することもできます。
IAM ロールの削除と CloudWatch ロググループの削除については、それぞれIAM ロールの削除 (コンソール)とCloudWatch Logs の削除のドキュメントを参照してください。
この記事の翻訳は Solutions Architect の堤 勇人が担当しました。