Amazon Web Services ブログ
AWS Entity Resolution の高度なルールベースファジーマッチングを使用して不完全なデータを解決する
この記事は Resolve imperfect data with advanced rule-based fuzzy matching in AWS Entity Resolution (記事公開日 : 2025 年 7 月 30 日) を翻訳したものです。
様々な業界の企業は、顧客情報を正確に把握することで、パーソナライズされた顧客体験と最適化された広告キャンペーンの提供を目指しています。しかし、断片化され、一貫性がなく、しばしば乱雑なデータセット間でレコードを確実にマッチングすることは、困難で複雑な作業です。
従来のルールベースのマッチング技術を使用して完全一致のレコードを照合しようとする組織は、名前、メールアドレス、住所のわずかな違い (例 : Jon Smith と Jonathan Smith、または 123 Main St., Apt. 4B と 123 Main Street #4B) により、重要なつながりを見逃してしまうことがあります。このようなミスマッチは、キャンペーンのパフォーマンス低下、オーディエンスリーチの制限、広告費の無駄遣いにつながる可能性があります。
これらの課題に対応するために、企業は AWS Entity Resolution を使用して、複数のアプリケーション、チャネル、データストアにまたがる関連レコードのマッチング、リンク、情報の付加を行っています。これにより、顧客をより良く理解し、エンゲージメントを高めるためのデータ品質が向上します。AWS Entity Resolution は、ルールベースのマッチングと機械学習 (ML) ベースのマッチングを含む、複数の柔軟で設定可能なマッチング技術を提供します。
- ルールベースのマッチングは、複数のフィールドにわたる厳密な条件を使用して、決定論的なロジックを定義します。例えば、メールアドレスと姓でマッチングを行うようなルールを設定することができます。この手法は高い精度と完全な透明性を提供し、事前に定義されたルールによる説明可能性が重要なユースケースで特に好まれます。
- 機械学習ベースのマッチングは、事前に学習させたモデルを活用し、データ内のパターンを自動的に学習して、データにノイズがある場合や一貫性がない場合、あるいは主要な識別子が不足している場合でも、適切なマッチングを特定することができます。この手法は設定の手間を軽減し、様々なタイプのデータに適応できる特徴があり、決定論的なルールでは見落としてしまう可能性のあるケースでも、より高い検出率を実現します。
本日、AWS Entity Resolution で高度なルールベースファジーマッチング機能を発表しました。これにより、Levenshtein Distance (レーベンシュタイン距離)、Cosine Similarity (コサイン類似度)、Soundex (サウンデックス) などのファジーマッチングアルゴリズムを使用してレコードをマッチングできるようになります。
この機能は、表記の揺れや入力ミスに対する許容性を持たせることで、特別な前処理を必要とせずに、より正確で柔軟な本人確認を可能にします。マーケターにとってこれは、マッチング率の向上、パーソナライゼーションの強化、そして効果的なクロスチャネルでのターゲティングやリターゲティング、効果測定のために必要な統合的な顧客視点の構築を実現できることを意味します。
業界のユースケース
高度なルールベースファジーマッチングは、様々な業界のお客様が直面する複雑なデータ統合の課題解決に役立ちます。具体的には以下のような例があります :
- 広告・マーケティング分野 : 識別子が不完全であったり、わずかなズレがある場合でも、異なるデータセット間でレコードをマッチングすることで、リーチや頻度分析の精度を向上させることができます。
- 小売・消費財分野 : 顧客関係管理 (CRM) データ内の誤字や異なる表記を含むレコードを紐付けることができます。
- 金融サービス分野 : 本人確認 (KYC) の検証、不正検知、またはマーケティング目的のために、本人確認データの解決を行うことができます。
高度なルールベースファジーマッチングの概要
AWS Entity Resolution の高度なルールベースファジーマッチングは、ルールベースと機械学習ベースのアプローチの間のギャップを埋めるものです。従来の厳密なルールベースの枠組みに確率的なマッチングを導入し、ユーザーがファジーマッチングアルゴリズム (レーベンシュタイン距離やコサイン類似度など) を使用して文字列フィールドの類似度のしきい値を設定できるようにします。これにより、ルールの説明可能性とコントロール性を保ちながら、確率的マッチングの柔軟性を実現する中間的なアプローチを提供します。
AWS Entity Resolution では、以下のファジーマッチングアルゴリズムを利用できます :
- レーベンシュタイン距離 : タイプミスや文字の小さな編集を検出し、名前やメールアドレス、スペルミスのあるエントリーをマッチングします (例 : john@gmail.co と jon@gmail.com の比較) 。
- サウンデックス : 音声的な類似性を評価し、似た発音だが異なるスペルの名前をマッチングします (例 : Mary と Marie の比較) 。
- コサイン類似度 : 単語やトークンの重なりに基づいて類似性を測定します。これは会社名や、語順が異なる、または部分的に一致するフリーテキストフィールドのマッチングに使用されます (例 : Acme Inc. と Acme Corporation の比較) 。
お客様は、ノイズを含むデータや一貫性のないデータ間でより柔軟で正確なマッチングを可能にするために、アルゴリズムを使用してカスタムの類似度のしきい値を定義できるようになりました。これは、ルールベースシステムのコントロール性と、機械学習ベースの近似マッチングの適応性を組み合わせたもので、説明可能性を損なうことなくマッチング率を向上させることができます。
お客様は、関連するファジーマッチングアルゴリズムでルール条件を設定し、必要に応じて適切なしきい値を設定することができます (図 1 参照) 。
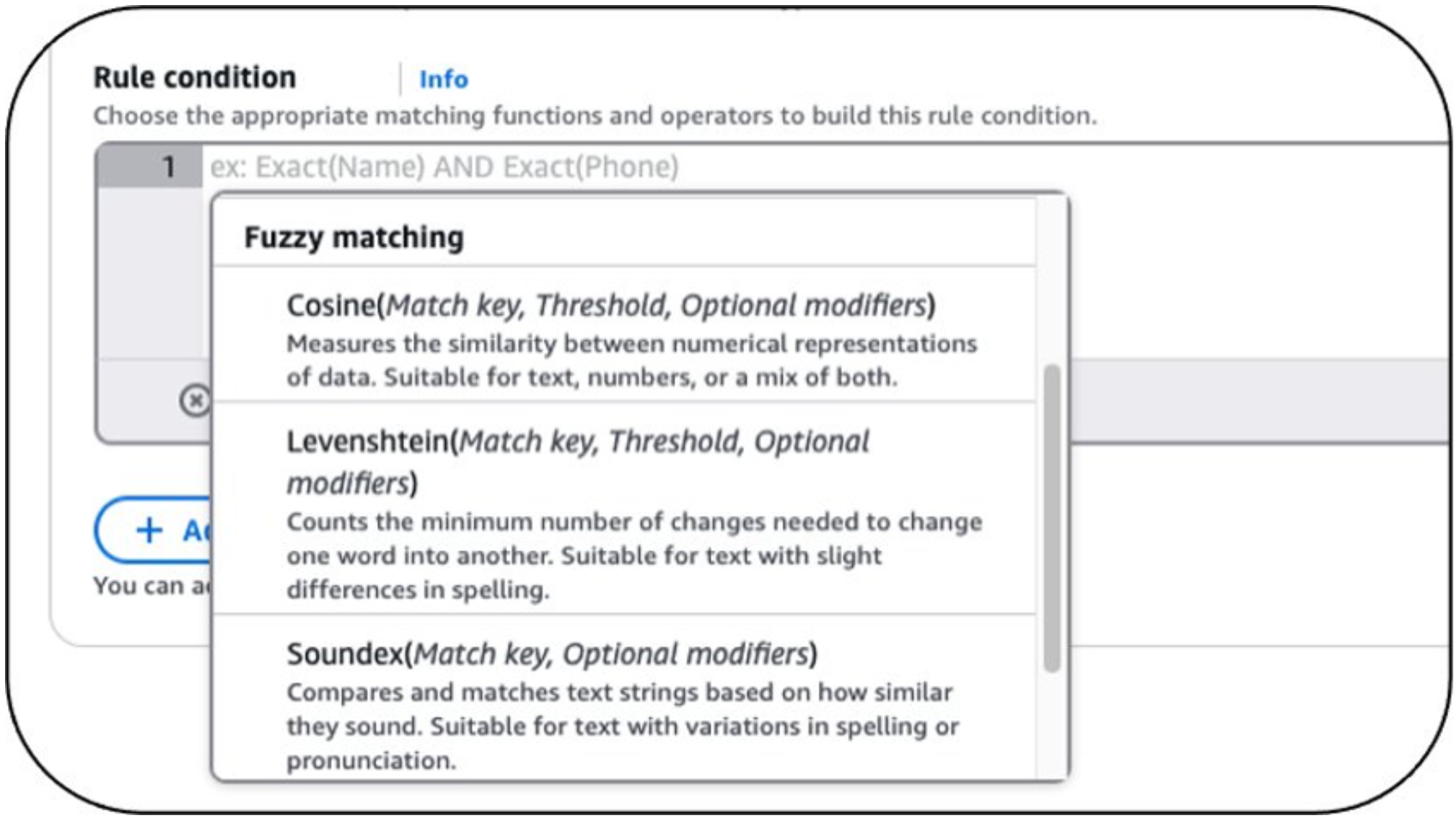
図 1 : 高度なマッチングアルゴリズム
仕組み
AWS Entity Resolution の新機能をソリューションで使用するには、まず、複数のアプリケーション、チャネル、データストアにまたがるレコードがデータレイク (Amazon Simple Storage Service (Amazon S3) バケット) で利用可能な状態になっていることを確認します。AWS Glue crawler を使用して Amazon S3 のデータの内容を自動的に判別し、AWS Glue Data Catalog 内のメタデータテーブルを更新します。
AWS Entity Resolution は、サービス内で定義したルールを使用して、データセットを適切なマッチンググループに解決します。AWS Entity Resolution からの出力は Amazon S3 バケットで利用可能です。図 2 は、このソリューションを示すハイレベルのアーキテクチャ図です。
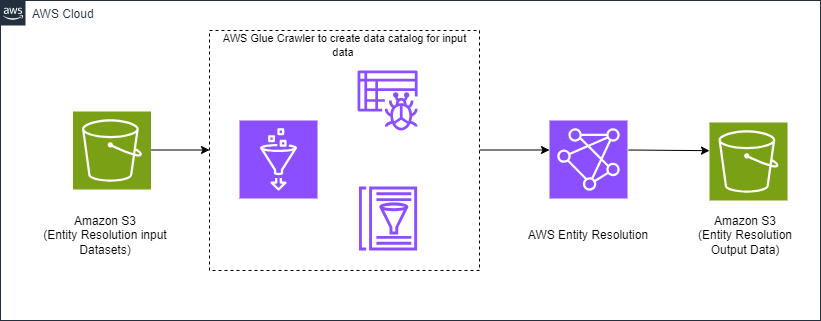
図 2 : ハイレベルアーキテクチャ
使用例の説明
AWS Entity Resolution のファジーマッチングルールを説明するために、テストデータセットを作成しました。このデータセットは架空の顧客情報で構成されており、CSV ファイル形式で Amazon S3 バケットにアップロードされています。

図 3 : サンプルデータセット
図 3 のデータセットには 4 つの個別のエンティティが含まれています。ただし、これらの個別エンティティには、名前、住所、電話番号フィールドが変更された複数のバリエーションも含まれています。
サンプルデータの問題を解決するために、以下の手順を実行しました :
- AWS Entity Resolution でサンプルデータのスキーマを解決するには、まず AWS Glue crawler を使用して AWS Glue Data Catalog テーブルを作成する必要があります。このテーブルは、入力されるクリックストリームデータを保持する Amazon S3 バケットを指します。
- AWS Entity Resolution 内でスキーママッピングを定義し、サービスにデータの解釈方法を指示する必要があります。
- スキーママッピング作成画面で、ソースデータを表す適切な AWS Glue データベースとテーブルを選択します。この例では、”fuzzymatchingaerdemo” を含むデータベース “fuzzymatchingdemo” を使用します。このデータベースのテーブルは、サンプルデータセットを含む Amazon S3 バケットで AWS Glue crawler を実行した際に作成されました。
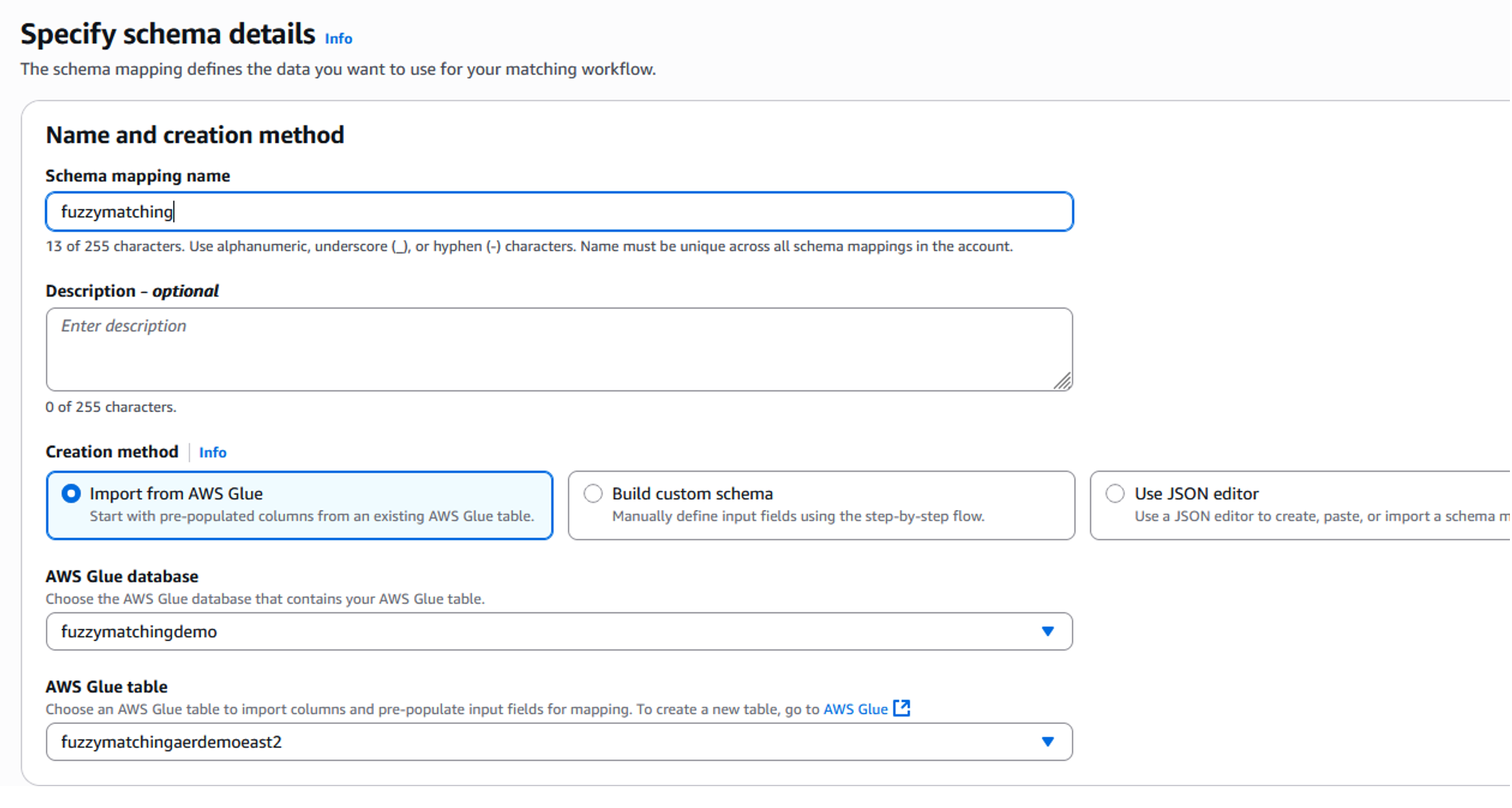
図 4 : スキーママッピング – セットアップ
- ドロップダウンから一意の ID (Unique ID) を選択します (図 5 参照) 。一意の ID カラムは、データの各行を個別に参照する必要があります。これはデータベースの主キーカラムのようなものと考えてください。この場合、CSV ファイル内の uniqueid がそれに該当します。
- 下にスクロールし、解決に必要な入力フィールドを選択します (図 5 参照) 。この場合、address (住所) 、first_name (名) 、last_name (姓) 、phone の各カラムが選択されています。
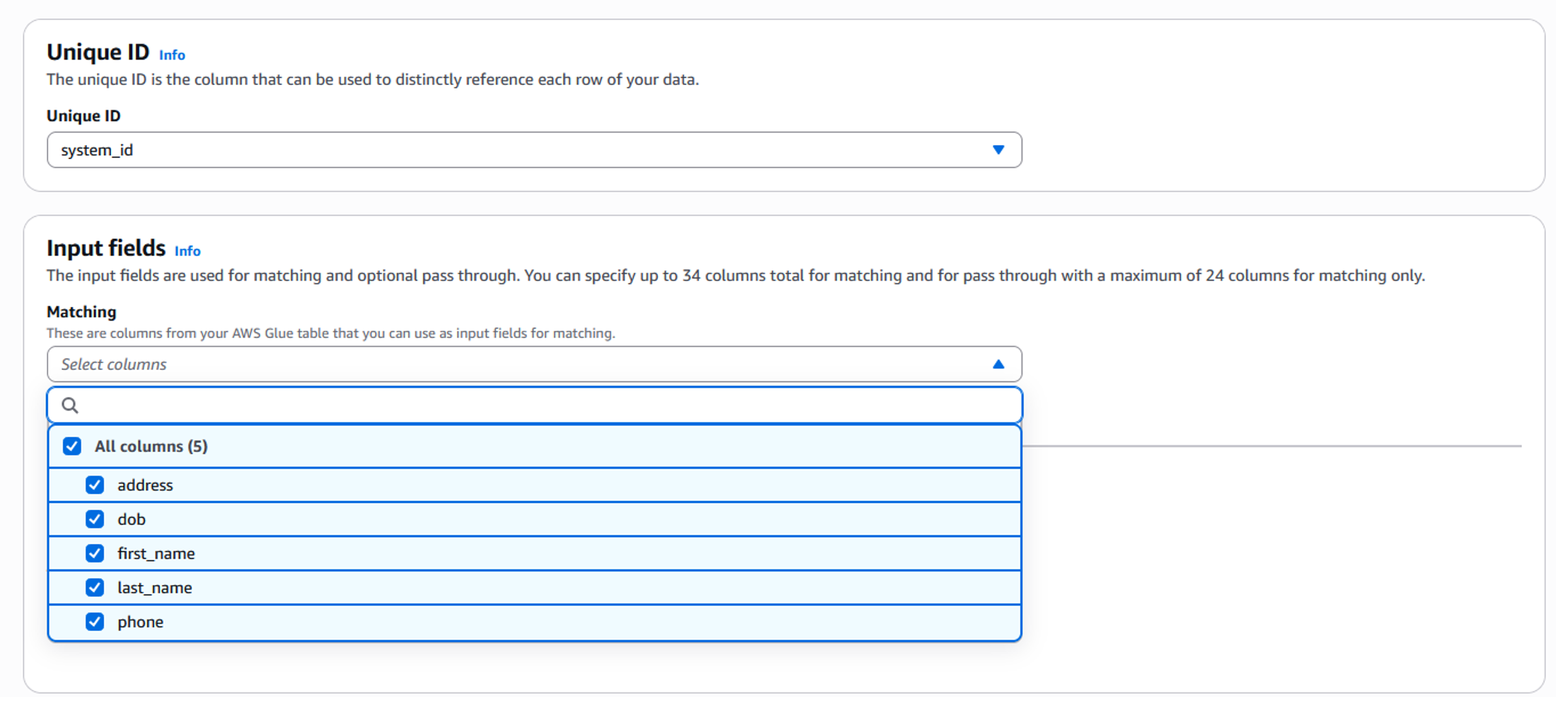
図 5 : スキーママッピング – 入力データフィールド セットアップ
- 次に、選択した入力フィールドを適切なデータタイプとマッチキーにマッピングします。入力タイプ (名前、メール、住所など) を指定することで、AWS Entity Resolution に各カラムのデータの解釈方法を指示し、必要に応じてそのカラムに適用する正規化ルールを設定できます。マッチキーは、どのフィールドが類似しているか、そしてマッチング処理中に単一のユニットとして扱う必要があるかを決定します。
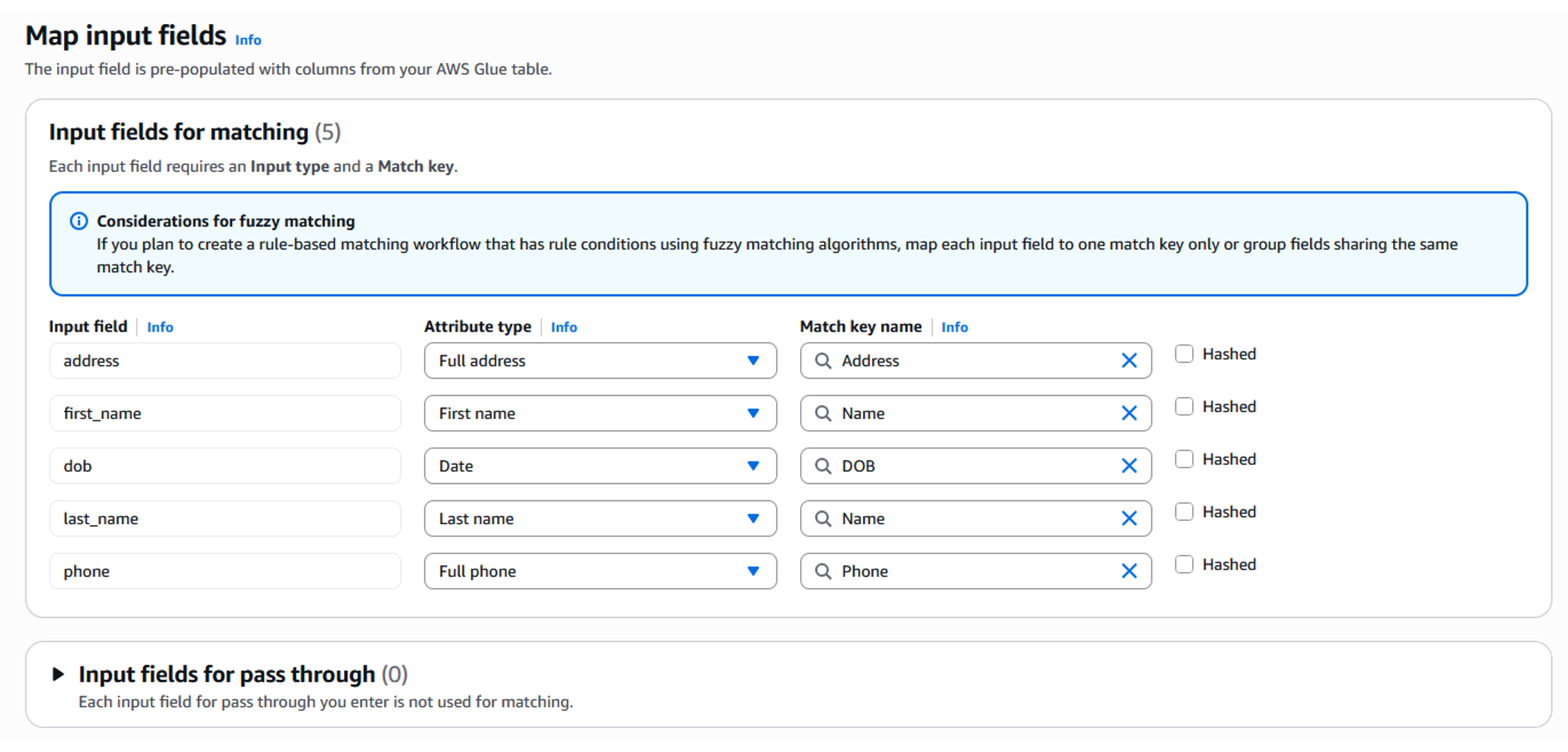
図 6 : スキーママッピング – フィールドのマッピング
- 「次へ」をクリックしてグループの作成に進みます。グループとは、単一の「名前」カラムの下にある関連する入力フィールド (名と姓など) のセットです。これにより、AWS Entity Resolution はマッチングや類似度の計算時に、個別ではなくまとめて比較することができ、より正確なマッチングが可能になります。
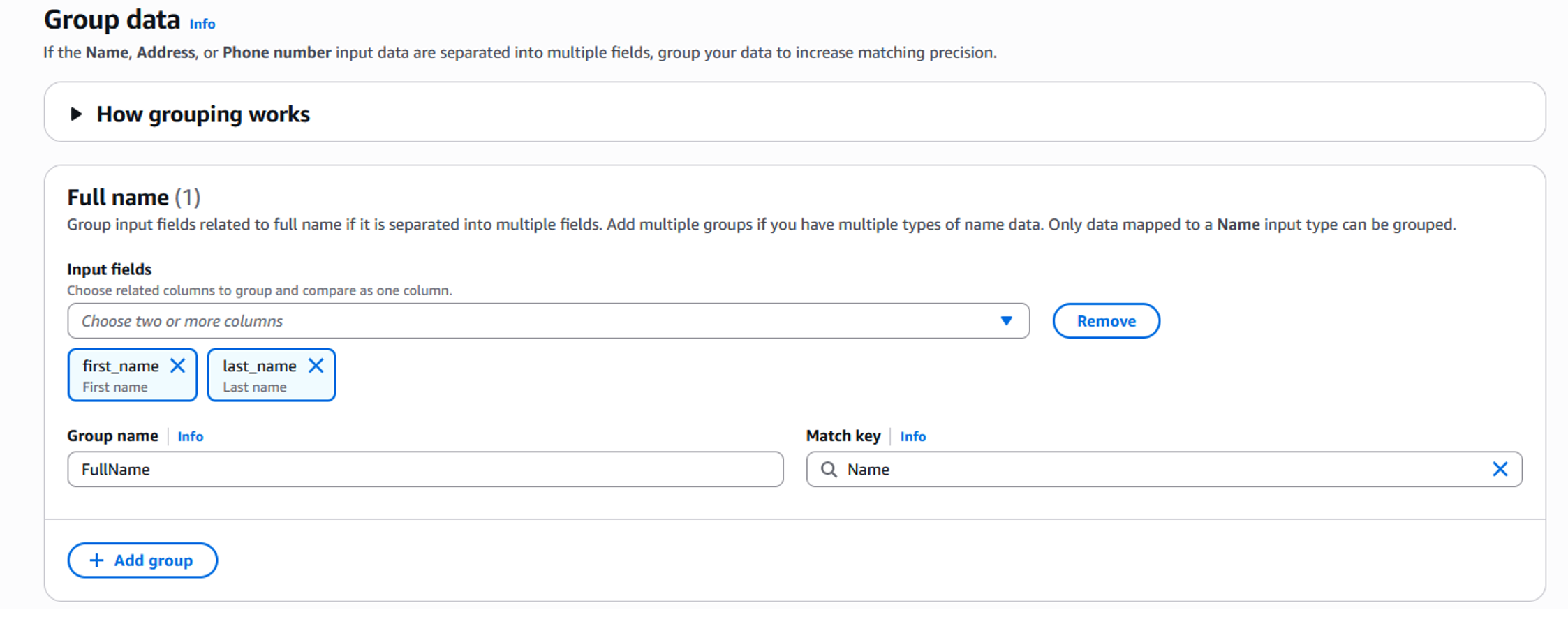
図 7 : スキーママッピング – グループフィールド
- グループの設定が完了したら、「次へ」をクリックして確認と作成画面に進みます。
- すべての設定を確認し、「スキーママッピングの作成」をクリックします。これによりスキーママッピングが作成されます。
- スキーママッピングが作成されたら、次はマッチングワークフローを作成します。マッチングワークフローは、ソース間でレコードをマッチングおよびリンクするために必要な入力、関連するマッチング手法、ルール、または機械学習を定義するのに役立ちます。マッチングワークフローを作成するには、左側のメニューにあるワークフローのドロップダウンから「マッチング」を選択し、「マッチングワークフローの作成」をクリックします。マッチングワークフローの詳細指定画面でワークフロー名を追加します。この例では「Fuzzymatchingdemo」としています。データ入力エリアで、前のステップで作成した適切な AWS Glue データベーステーブルとスキーママッピングを選択する必要があります (図 8 参照) 。
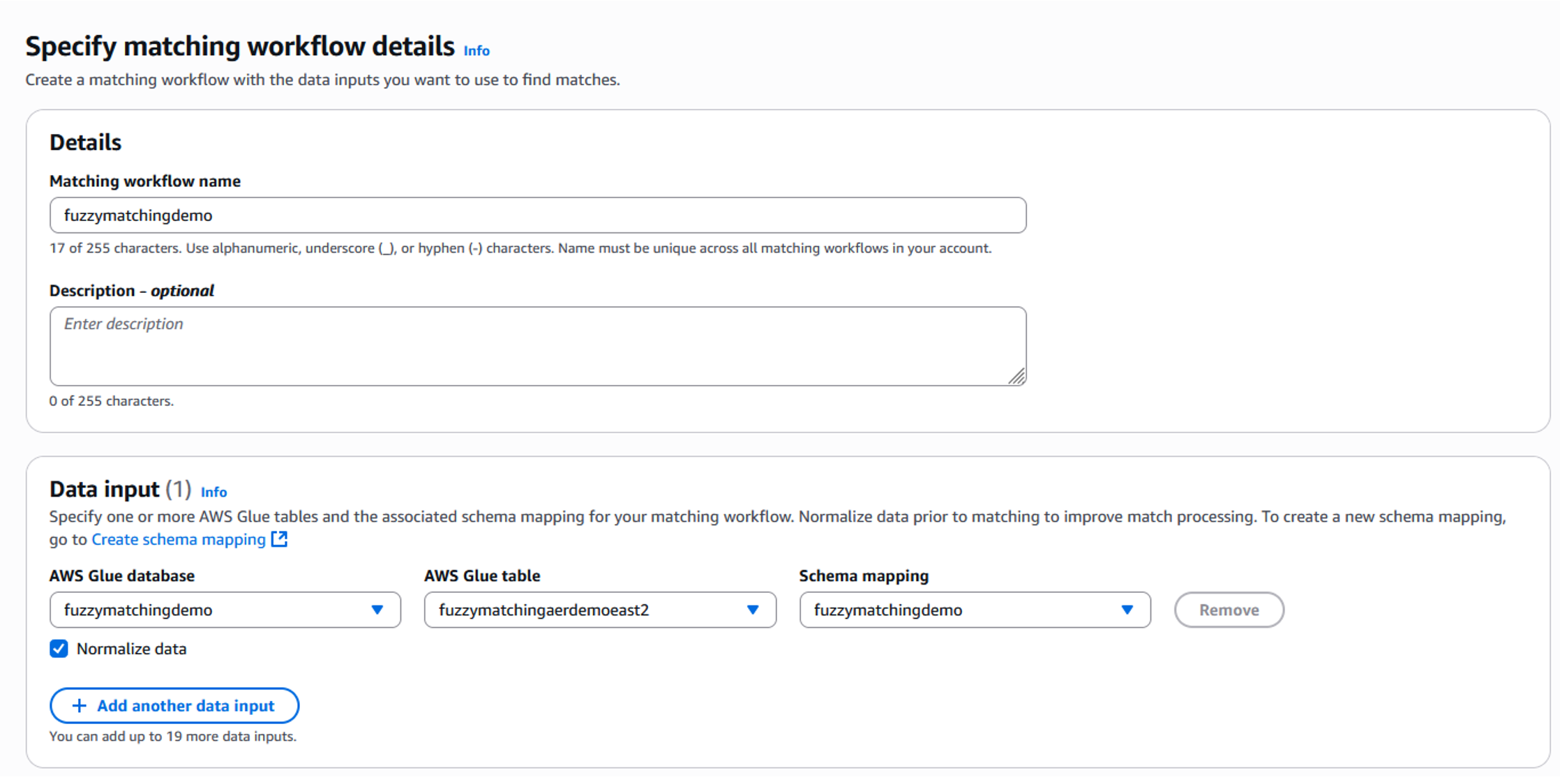
図 8 : マッチングワークフロー
- マッチング手法では、「ルールベースマッチング」を選択し、ファジーマッチングアルゴリズムを使用するためにルールタイプとして「Advanced-new」を選択します。
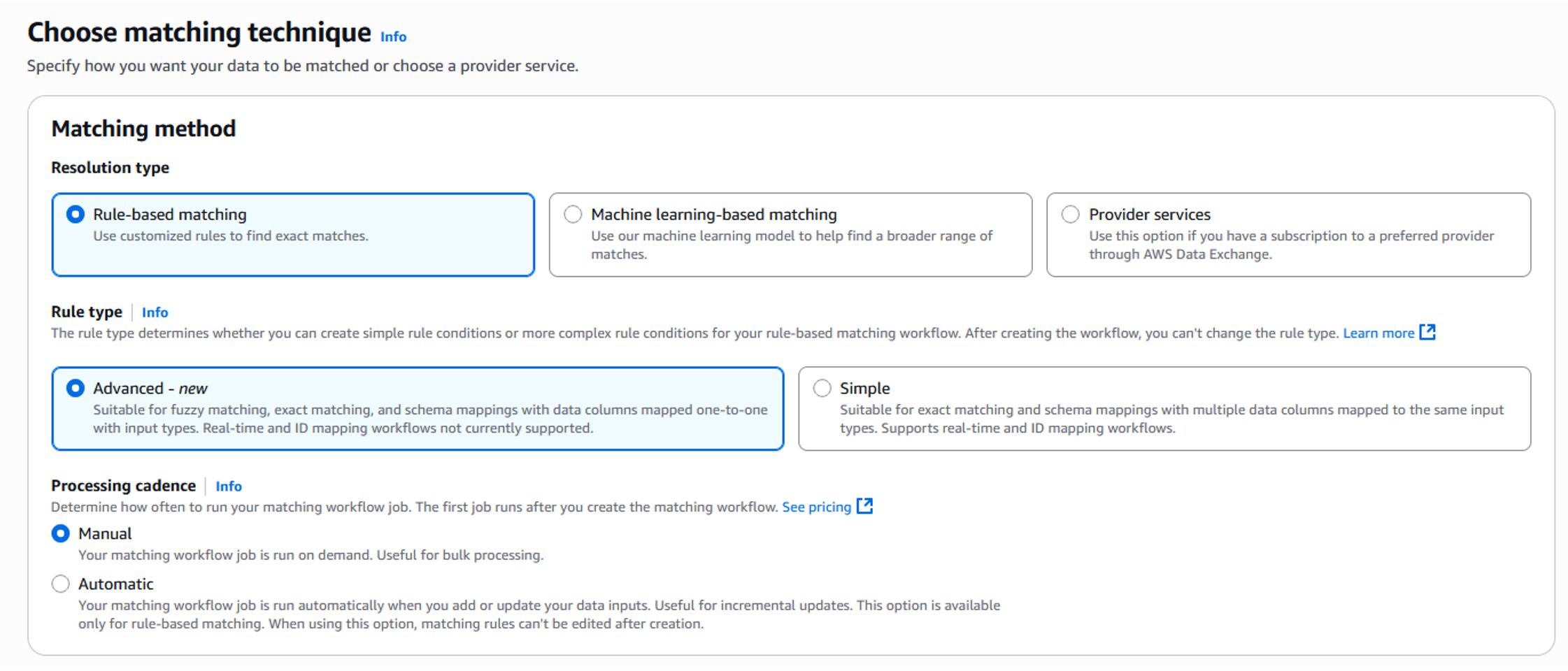
図 9 : マッチング手法
- マッチングルールセクションでは、マッチングの目的に合わせて、ドロップダウンリストからマッチングアルゴリズムと適切なしきい値を選択し、ルールと条件を定義できます (図 10 参照) 。高度なマッチングルールビルダーでは、特定のフィールドに複数のマッチングアルゴリズムを適用することができます。「OR」条件を使用して2つの異なるアルゴリズムを組み合わせることで、マッチング解決の精度を最大化することができます。例えば、「名前」属性に対してサウンデックスとコサインの両方のアルゴリズムを適用することで、異なる種類の表記のバリエーションを捉えることができます。図 11 は、サンプルデータセットの重複を効果的に排除するために使用したルールを示しています。
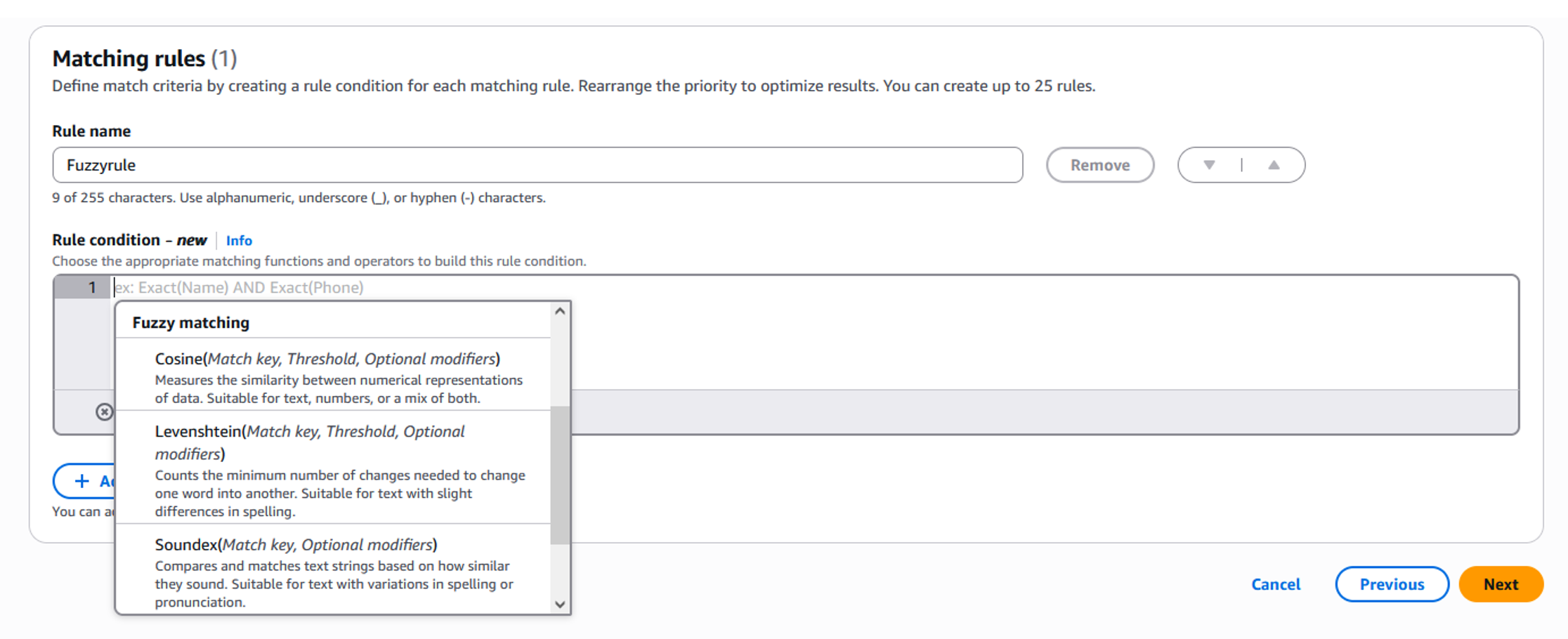
図 10 : ファジーマッチング手法 セットアップ
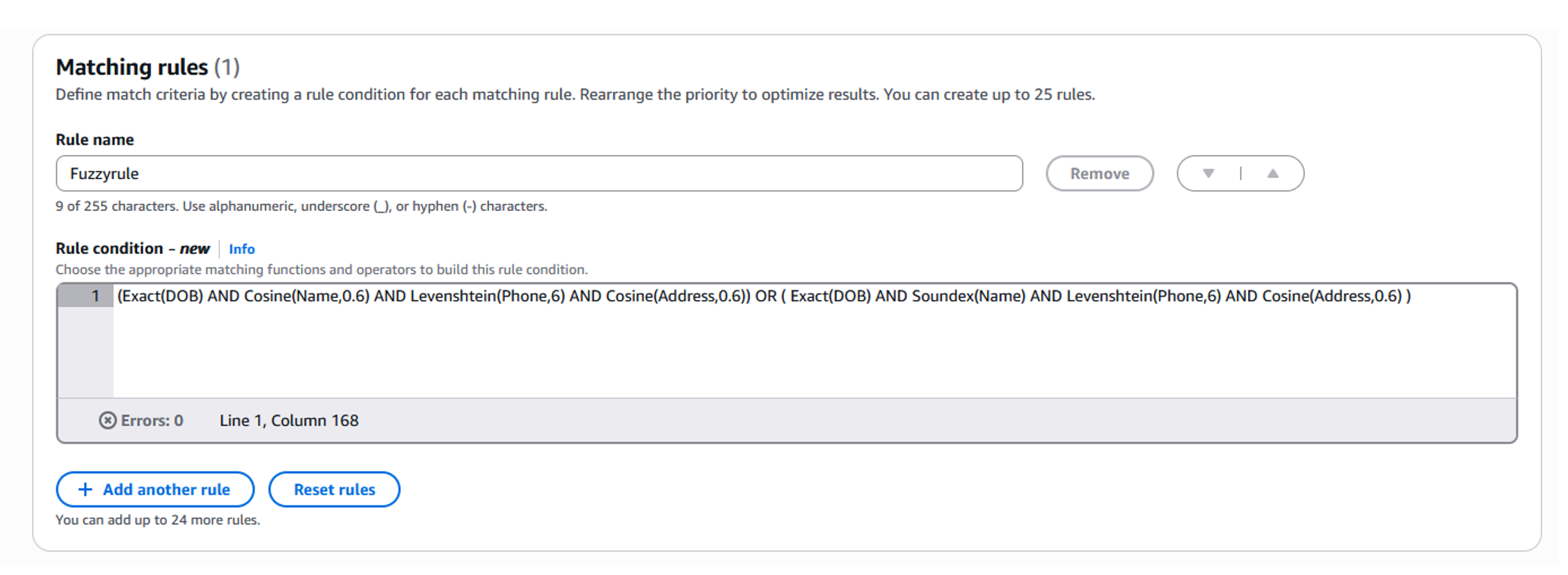
図 11 : ファジーマッチングルール
- 最後のステップとして、ワークフローを作成する前に、すべての設定がマッチングの要件を正確に反映しているか確認し、「作成して実行」をクリックします。これによりマッチングワークフローが作成され、最初の処理が開始されます。
ジョブの完了までしばらく待つと (図 12 参照) 、ジョブメトリクスに処理された入力レコードの数と生成された一意のマッチ ID の数が表示されます。出力結果は設定された Amazon S3 バケットに書き込まれます。指定された出力用 S3 の場所に移動して出力ファイルをダウンロードし、結果を分析することができます。
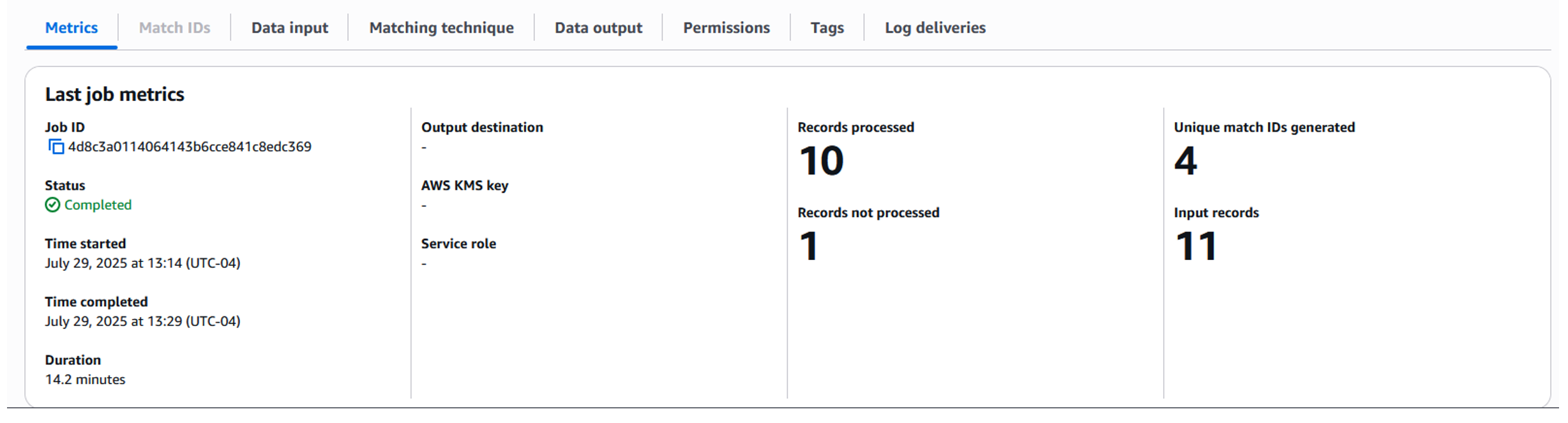
図 12 : ファジーマッチングのジョブメトリクス
出力データ (図 13 参照) では、出力データの各レコードに AWS Entity Resolution が割り当てた MatchID が付与されます。マッチングレコードは、MatchRule で定義された条件を満たすデータセットから重複が排除されたエントリーを表します。MatchRule フィールドは、各マッチングレコードセットの生成に適用された具体的なルールを示しています。

図 13 : ファジーマッチングワークフローの出力
このチュートリアルで示したサンプルデータセットでは、AWS Entity Resolution のファジーマッチングワークフローは、関連するレコードをグループ化する 4 つの一意のマッチキーを生成しました。マッチングワークフローは、名前、住所、電話番号フィールドにバリエーションを含むレコードの重複を正常に排除し、4 つの個別のエンティティとして解決しました。
まとめ
AWS Entity Resolution の高度なルールベースファジーマッチングは、カスタムコードを書くことなく、ファジーロジックを使用して現実世界の不完全なデータをマッチングするための柔軟性を提供します。広告、小売、金融、医療など、どの分野で働いているかに関わらず、この機能はデータに隠された関係性を見つけ出すのに役立ちます。お客様は、マッチングのためのファジーロジックに対して適切なしきい値を管理および設定することができます。
これは、ルールベースシステムのコントロール性と、機械学習ベースの近似マッチングの適応性を組み合わせたバランスの取れたマッチングアプローチです。説明可能性を損なうことなく、マッチング率を向上させることができます。
開始するには、AWS Entity Resolution コンソールにアクセスし、高度なルールベースファジーマッチングを有効にして、今すぐインテリジェントなワークフローの構築を始めるか、AWS の担当者に連絡して、ビジネスの加速化に向けた支援方法についてご相談ください。
追加リソース
- AWS Entity Resolution Resources
- AWS Entity Resolution と Amazon Neptune を使用して顧客の 360 度ビューを作成
- AWS Entity Resolution: Match and Link Related Records from Multiple Applications and Data Stores
- AWS Entity Resolution Workshops
- 顧客の統一ビューを構築する方法
本稿の翻訳は、ソリューションアーキテクトの髙橋が担当しました。原文はこちら。