Amazon Web Services ブログ
AWS Glue zero-ETLによるSAPデータの取り込みとレプリケーション
(本稿は、2025年12月8日に公開された “SAP data ingestion and replication with AWS Glue zero-ETL” を翻訳したものです)
組織では、複雑なデータパイプラインを維持することなく、SAPシステムからデータを取り込み、インサイトへより迅速にアクセスするニーズが高まっています。AWS Glue zero-ETL with SAP は、Operational Data Provisioning(ODP)管理のSAP Business Warehouse(BW)エクストラクター、Advanced Business Application Programming(ABAP)、Core Data Services(CDS)ビュー、その他の非ODPデータソースなどのSAPデータソースからのデータ取り込みとレプリケーションをサポートしています。Zero-ETLデータレプリケーションとスキーマ同期により、抽出されたデータをAmazon Redshift、Amazon SageMaker lakehouse アーキテクチャ、Amazon S3 TablesなどのAWS環境に保存することを容易にし、手動でのパイプライン開発を減らします。これにより、Amazon Q、 Kiro、Amazon Quick Suiteなどのサービスと組み合わせて使用することで、自然言語クエリを使用してSAPデータを分析し、自動化のためのAIエージェントを作成し、エンタープライズデータランドスケープ全体でコンテキストに応じたインサイトを生成できる、AI駆動型インサイトの基盤が構築されます。
この記事では、さまざまなODPおよび非ODP SAPソースとのzero-ETL統合を作成および監視する方法を紹介します。
ソリューション概要
SAPとデータ連携する際の主要コンポーネントは、SAPデータ構造とプロトコルで動作するように設計されたAWS Glue SAP ODataコネクタです。このコネクタは、ABAPベースのSAPシステムへの接続を提供し、SAPのセキュリティとガバナンスフレームワークに準拠しています。AWS SAPコネクタの主な機能は以下の通りです:
- ODataプロトコルを使用して、さまざまなSAP NetWeaverシステムからデータ抽出
- BWエクストラクター(2LIS_02_ITMなど)やCDSビュー(C_PURCHASEORDERITEMDEXなど)などの複雑なSAPデータモデルを、管理された形でレプリケーション
- SAP変更データキャプチャ(CDC)テクノロジーを使用したODPおよび非ODPエンティティの両方への対応
SAPコネクタは、AWS Glue StudioまたはAWS管理のzero-ETLレプリケーションの両方で動作します。AWS Glue Studioでのセルフマネージドレプリケーションは、データ処理ユニット、レプリケーション頻度、価格パフォーマンスの調整、ページサイズ、データフィルター、宛先、ファイル形式、データ変換、および選択したランタイムでの独自コードの記述をコントロールできる環境です。zero-ETLでのAWS管理データレプリケーションは、カスタム設定の負担を取り除き、AWS管理の代替手段を提供し、15分から6日間のレプリケーション頻度を可能にします。以下のソリューションアーキテクチャは、さまざまなSAPソースからzero-ETLを使用してODPおよび非ODP SAPデータを取り込み、Amazon Redshift、SageMaker lakehouse、S3 Tablesに書き込むアプローチを示しています。
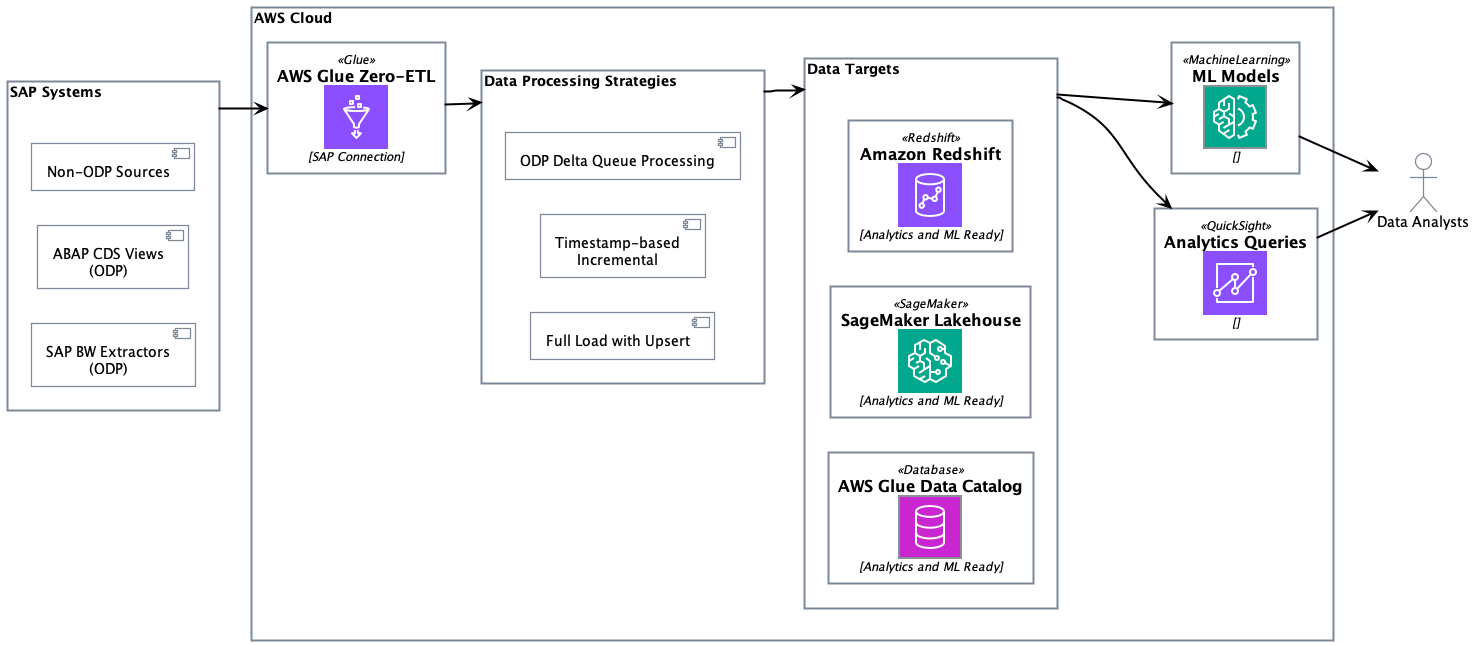
ODPソースの変更データキャプチャ
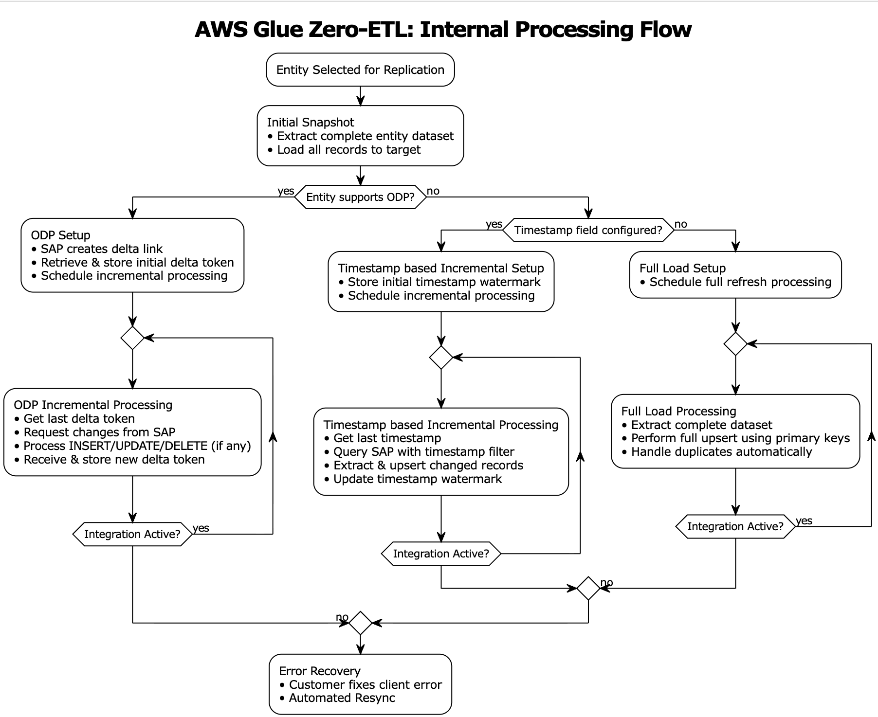
SAP ODPは、SAPソースシステムからターゲットシステムへの増分データレプリケーションを可能にするデータ抽出フレームワークです。ODPフレームワークは、アプリケーション(サブスクライバー)がBWエクストラクター、CDSビュー、BWオブジェクトなどのサポートされているオブジェクトから増分的にデータを要求できるようにします。
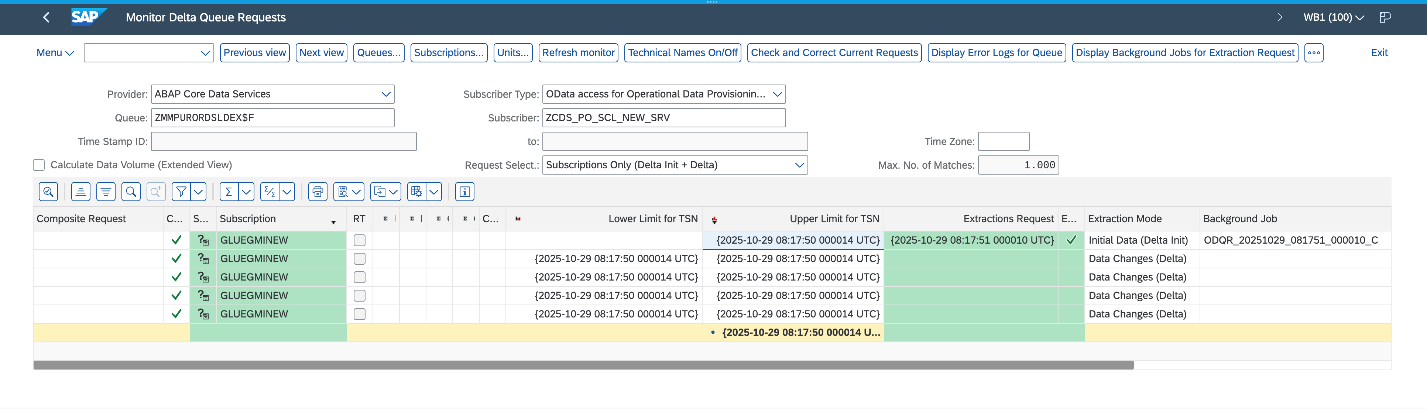
AWS Glue zero-ETLデータ取り込みは、ターゲットシステムでベースラインデータセットを確立するために、エンティティデータの初期フルロードを実行することから始まります。初期フルロードが完了すると、SAPは削除を含むデータ変更をキャプチャするOperational Delta Queue(ODQ)として知られるデルタ(増分)キューをプロビジョニングします。デルタトークンは初期ロード中にサブスクライバーに送信され、zero-ETL内部の状態管理システム内に永続化されます。
増分処理は、状態ストアから最後に保存されたデルタトークンを取得し、ODataプロトコルを使用してこのトークンを使用してSAPにデルタ変更リクエストを送信します。システムは、SAP ODQメカニズムを通じて返されたINSERT/UPDATE/DELETE操作を処理し、レコードが変更されていないシナリオでもSAPから新しいデルタトークンを受信します。この新しいトークンは、取り込みが成功した後、状態管理システムに永続化されます。エラーシナリオでは、システムは既存のデルタトークン状態を保持し、データ損失なしで再試行メカニズムを可能にします。
以下のスクリーンショットは、SAPシステムでの成功した初期ロードとそれに続く4回の増分データ取り込みを示しています。
非ODPソースの変更データキャプチャ
非ODP構造は、ODP対応でないODataサービスです。これらは、ODPフレームワークなしで直接公開されるAPI、関数、ビュー、またはCDSビューです。このメカニズムを使用してデータが抽出されますが、増分データ抽出はオブジェクトの性質に依存します。たとえば、オブジェクトに「最終更新日」フィールドが含まれている場合、それを使用して変更を追跡し、増分データ抽出を提供します。
AWS Glue zero-ETLは、エンティティに変更を追跡するフィールド(最終更新日または時刻)が含まれている場合、非ODP ODataサービスに対してすぐに使える増分データ抽出を提供します。これらのSAPサービスに、zero-ETLはデータ取り込みに2つのアプローチを提供します:タイムスタンプベースの増分処理と完全ロードです。
タイムスタンプベースの増分処理
タイムスタンプベースの増分処理は、zero-ETLでユーザーが設定したタイムスタンプフィールドを使用して、データ抽出プロセスを最適化します。zero-ETLシステムは、後続の増分処理操作の基礎となる開始タイムスタンプを確立します。ウォーターマークとして知られるこのタイムスタンプは、データの一貫性を促進するために重要です。クエリ構築メカニズムは、タイムスタンプ比較に基づいてODataフィルターを構築します。これらのクエリは、最後に成功した処理実行以降に作成または変更されたレコードを抽出します。システムのウォーターマーク管理機能は、各処理サイクルから最高のタイムスタンプ値の追跡を維持し、この情報を後続の実行の開始点として使用します。zero-ETLシステムは、設定されたプライマリキーを使用してターゲットでアップサートを実行します。このアプローチは、データ整合性を維持しながら更新を適切に処理することを促進します。各ターゲットシステム更新が成功した後、ウォーターマークタイムスタンプが進められ、将来の処理サイクルのための信頼できるチェックポイントが作成されます。
ただし、タイムスタンプベースのアプローチには制限があります – SAPシステムは削除タイムスタンプを維持しないため、物理的な削除を追跡できません。タイムスタンプフィールドが利用できないか設定されていないシナリオでは、システムはアップサート処理を伴うフルロードに移行します。
フルロード(完全ロード)
フルロードアプローチは、独立した(前後関係のない)処理として、またはタイムスタンプベースの処理が実行可能でない場合のフォールバックメカニズムとして機能します。この方法は、各処理サイクル中に完全なエンティティデータセットを抽出することを含み、変更追跡が利用できないか必要でないシナリオに適しています。抽出されたデータセットは、ターゲットシステムでアップサートされます。アップサート処理ロジックは、新しいレコードの挿入と既存レコードの更新の両方を処理します。
増分ロードまたはフルロードを選択するタイミング
タイムスタンプベースの増分処理アプローチは、頻繁に更新される大規模なデータセットに対して最適なパフォーマンスとリソース使用率を提供します。変更されたレコードのみの選択的転送により、データ転送量が削減され、ネットワークトラフィックが削減されます。この最適化は、運用コストの削減に直接つながります。アップサートを伴うフルロードは、増分処理が実行可能でないシナリオでのデータ同期を促進します。
これらのアプローチは、非ODP SAP構造とのzero-ETL統合のための完全なソリューションを形成し、エンタープライズデータ統合シナリオの多様な要件に対応します。これらのアプローチを使用する組織は、2つのアプローチのいずれかを選択する際に、特定のユースケース、データ量、およびパフォーマンス要件を評価する必要があります。
SAP zero-ETL統合の監視
AWS Glueは、Amazon CloudWatchログを使用して状態管理、ログ、およびメトリクスを維持します。可観測性を設定する手順については、「統合の監視」を参照してください。ログ配信用にAWS Identity and Access Management(IAM)ロールが設定されていることを確認してください。統合は、ソース取り込みと選択したターゲットへの書き込みの両方から監視されます。
ソース取り込みの監視
AWS Glue zero-ETLとCloudWatchの統合により、データ統合プロセスを追跡およびトラブルシューティングするための監視機能が提供されます。CloudWatchを通じて、問題を特定し、パフォーマンスを監視し、SAPデータ統合の運用状態を維持するのに役立つ詳細なログ、メトリクス、およびイベントにアクセスできます。成功とエラーのシナリオのいくつかの例を見てみましょう。
シナリオ1: ロールに権限がない
このエラーは、SAPデータへのアクセスを試みる際に、AWS Glueでのデータ統合プロセス中に発生しました。接続は、400 Bad Requestステータスコードを持つCLIENT_ERRORに遭遇し、ロールに権限がないことを示しています。
シナリオ2: デルタリンクの破損
CloudWatchログは、SAPからAWS Glueへのデータ同期中にデルタトークンが欠落している問題を示しています。エラーは、ODataサービスを通じてSAP販売ドキュメント項目テーブルFactsOfCSDSLSDOCITMDXにアクセスしようとしたときに発生します。増分データロードと変更の追跡に必要なデルタトークンがないため、システムがデータ抽出API RODPS_REPL_ODP_OPENを開こうとしたときにCLIENT_ERROR(400 Bad Request)が発生しました。
シナリオ3: SAPデータ取り込みのクライアントエラー
このCloudWatchログは、SAPエンティティEntityOf0VENDOR_ATTRがODataサービスを通じて見つからないか、アクセスできないクライアント例外シナリオを明らかにしています。このCLIENT_ERRORは、AWS GlueコネクタがSAPシステムからの応答を解析しようとしたが、エンティティがソースSAPシステムに存在しないか、SAPインスタンスが一時的に利用できないために失敗したときに発生します。
ターゲット書き込みの監視
Zero-ETLは、ターゲットシステムに応じた監視メカニズムを採用しています。Amazon Redshiftターゲットの場合、統合ステータス、ジョブ実行、およびデータ移動統計に関する詳細情報を提供するsvv_integrationシステムビューを使用します。SageMaker lakehouseターゲットを使用する場合、zero-ETLはzetl_integration_table_stateテーブルを通じて統合状態を追跡し、同期ステータス、タイムスタンプ、および実行の詳細に関するメタデータを維持します。さらに、CloudWatchログを使用して統合の進行状況を監視し、成功したコミット、メタデータの更新、およびデータ書き込みプロセス中の潜在的な問題に関する情報をキャプチャできます。
シナリオ1: SageMaker lakehouseターゲットでの処理成功
CloudWatchログは、CDCモードを使用したプラントテーブルの成功したデータ同期アクティビティを示しています。最初のログエントリ(IngestionCompleted)は、タイムスタンプ1757221555568での取り込みプロセスの成功した完了を確認し、最後の同期タイムスタンプは1757220991999です。2番目のログ(IngestionTableStatistics)は、データ変更の詳細な統計を提供し、このCDC同期中に300の新しいレコードが挿入され、8つのレコードが更新され、2つのレコードがターゲットデータベースglueetlから削除されたことを示しています。このレベルの詳細は、ターゲットシステムに伝播される変更の量とタイプを監視するのに役立ちます。
シナリオ2: Amazon SageMaker lakehouse ターゲットのメトリクス
SageMaker lakehouseのzetl_integration_table_stateテーブルは、統合ステータスとデータ変更メトリクスのビューを提供します。この例では、テーブルは、testdbデータベースの統合ID 62b1164f-5b85-45e4-b8db-9aa7ab841e98を持つSAP CDSビューテーブルの成功した統合を示しています。レコードは、タイムスタンプ1733000485999で、10の挿入レコードが処理されたことを示しています(recent_insert_record_count: 10)、更新または削除はありません(両方のカウントは0)。このテーブルは監視ツールとして機能し、統合状態とデータ変更に関する詳細な統計の集中ビューを提供し、lakehouseでのデータ同期アクティビティを追跡および検証することを簡単にします。
シナリオ3: Redshift用監視システムは、zero-ETL統合ステータスを追跡するために2つのビューを使用
svv_integrationは、統合ステータスの高レベルの概要を提供し、統合ID 03218b8a-9c95-4ec2-81ad-dd4d5398e42aが失敗なしで18のテーブルを正常にレプリケートし、最後のチェックポイントがトランザクションシーケンス1761289852999であったことを示しています。
svv_integration_table_stateは、統合内の個々のテーブルのステータスを示すテーブルレベルの監視詳細を提供します。この場合、SAP材料グループテキストエンティティテーブルは同期済み状態にあり、最後のレプリケーションチェックポイントは統合チェックポイント(1761289852999)と一致しています。テーブルは現在0行と0サイズを示しており、新しく作成されたことを示唆しています。
これらのビューは、Amazon Redshiftでの全体的な統合の健全性と個々のテーブル同期ステータスの両方を追跡するための包括的な監視ソリューションを提供します。
前提条件
以下のセクションでは、SAP接続を設定し、その接続を使用してzero-ETL統合を作成するために必要な手順を説明します。このソリューションを実装する前に、以下を準備する必要があります:
- SAPアカウント
- 管理者アクセス権を持つAWSアカウント
- S3 Tablesターゲットを作成し、S3バケットsap_demo_table_bucketをデータベースのロケーションとして関連付ける
- zero-ETLのData Catalogのきめ細かいアクセス制御のために、以下のIAMポリシーを使用してAWS Glue Data Catalog設定を更新する
- zero-ETLがSAPアカウントからデータにアクセスするために使用するIAMロール zero_etl_bulk_demo_role を作成する
- SAP認証情報を保存するためにAWS Secrets Managerでシークレット zero_etl_bulk_demo_secret を作成する
SAPインスタンスへの接続を作成
SAPインスタンスへの接続を設定し、アクセスするデータを提供するには、以下の手順を実行します:
- AWS Glueコンソールで、ナビゲーションペインのData catalogの下で、Connectionsを選択し、Create Connectionを選択します。
- Data sourcesで、SAP ODataを選択し、Nextを選択します。
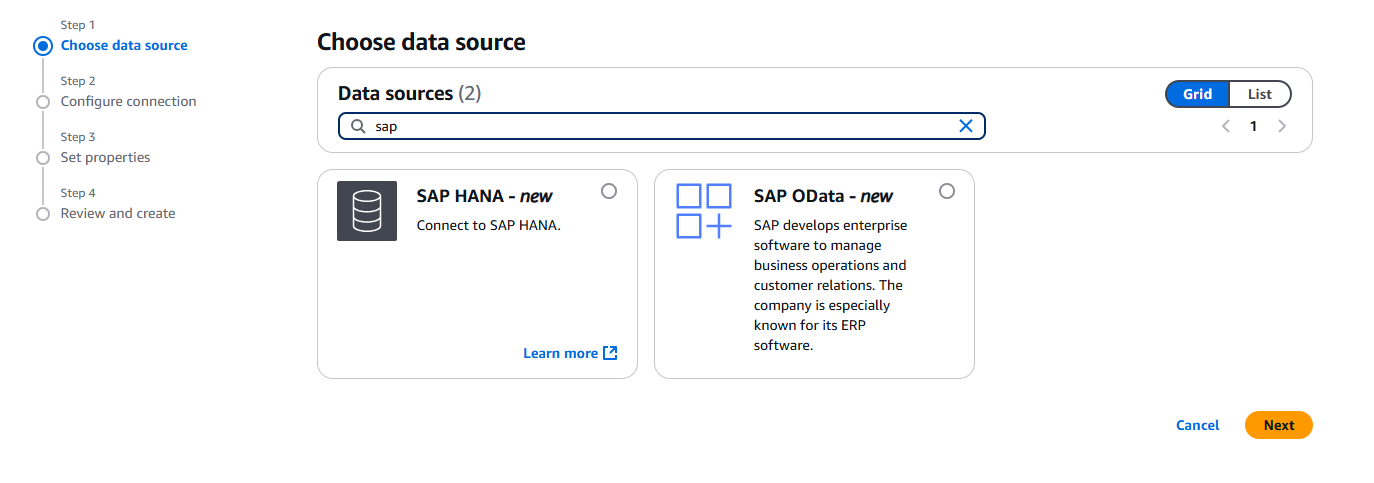
- SAPインスタンスのURLを入力します。
- IAM service roleで、ロールzero_etl_bulk_demo_role(前提条件として作成)を選択します。
- Authentication Typeで、SAPに使用している認証タイプを選択します。
- AWS Secretで、シークレットzero_etl_bulk_demo_secret(前提条件として作成)を選択します。
- Nextを選択します。
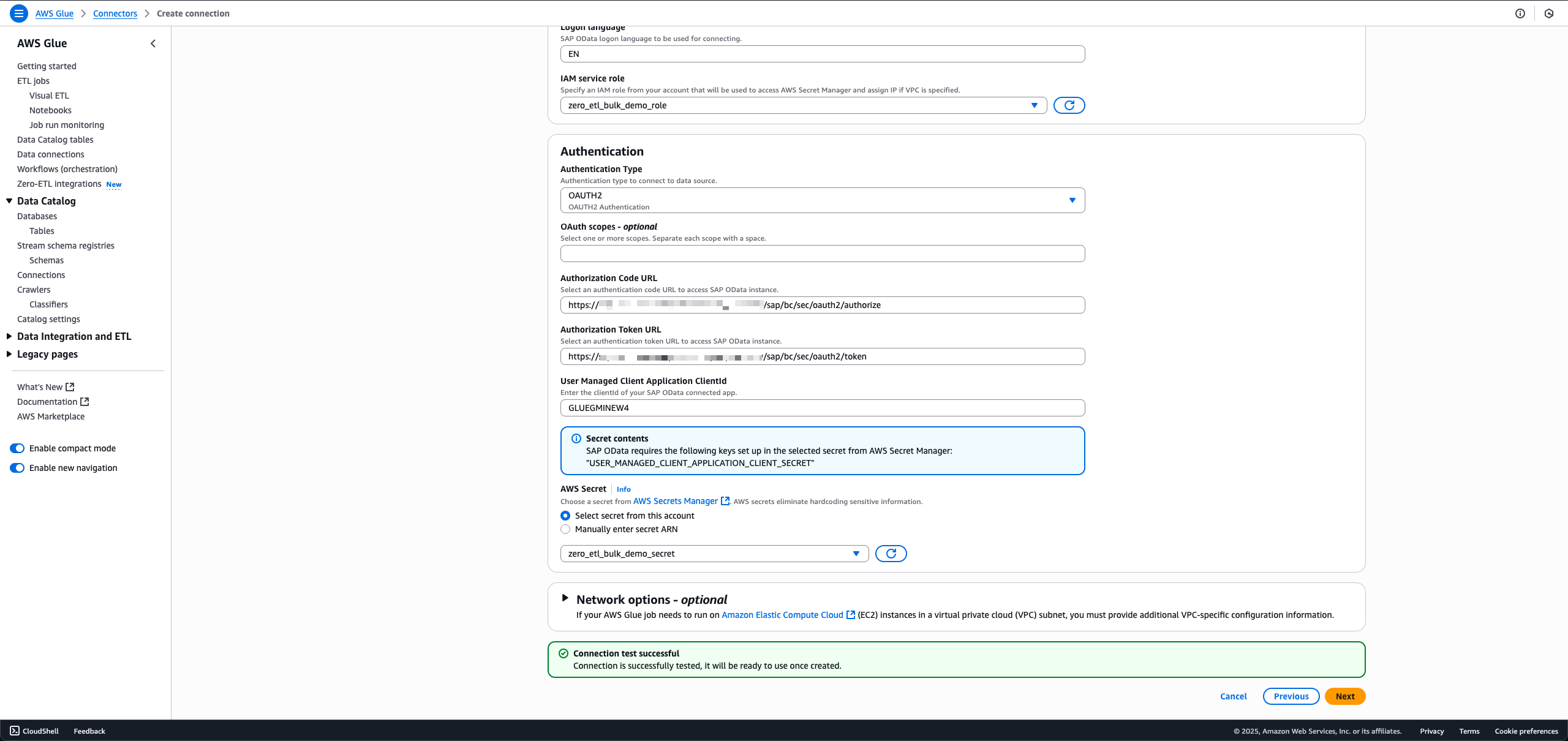
- Nameに、sap_demo_connなどの名前を入力します。
- Nextを選択します。
zero-ETL統合を作成
zero-ETL統合を作成するには、以下の手順を実行します:
- AWS Glueコンソールで、ナビゲーションペインのData catalogの下で、Zero-ETL integrationsを選択し、Create zero-ETL integrationを選択します。
- Data sourceで、SAP ODataを選択し、Nextを選択します。
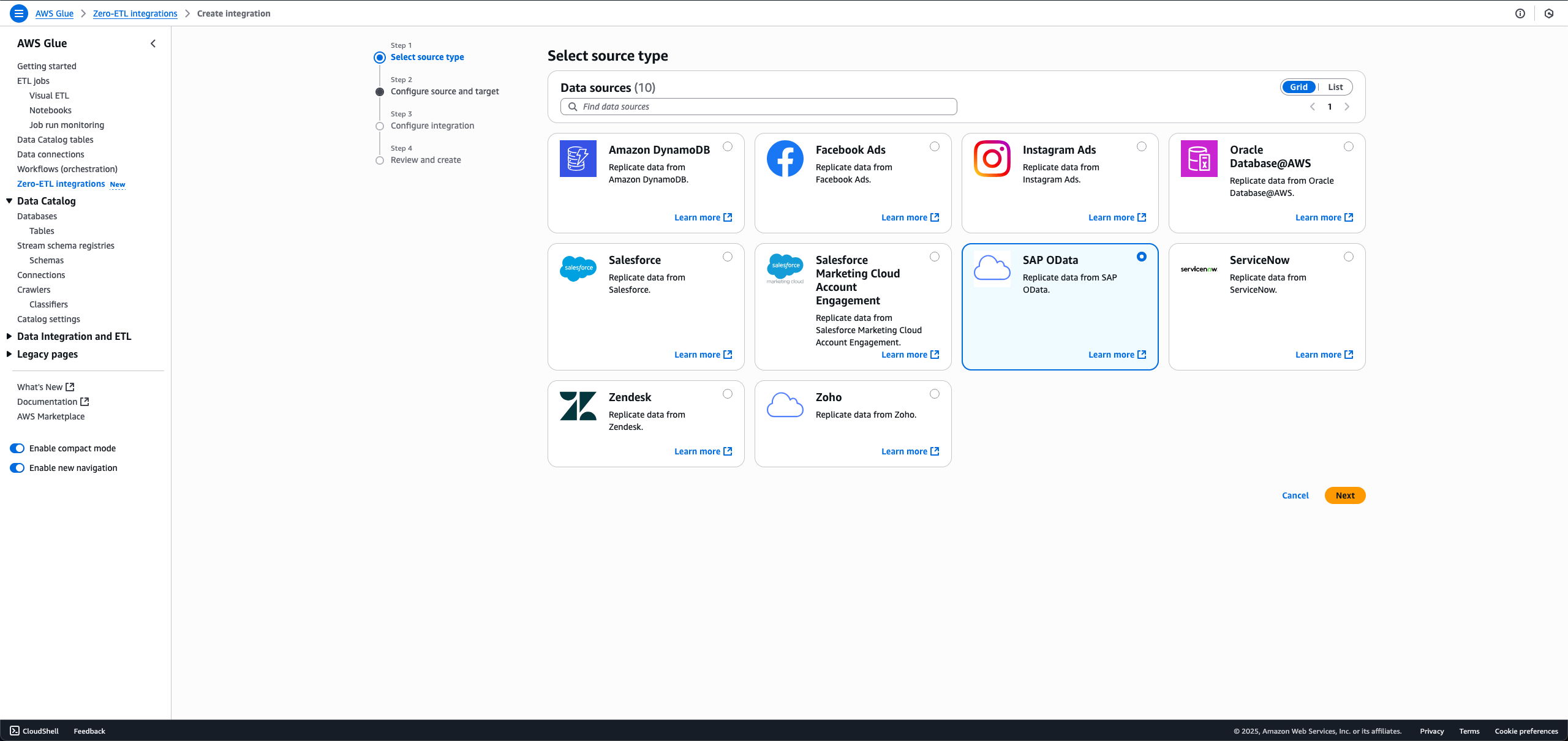
- 前の手順で作成した接続名とIAMロールを選択します。
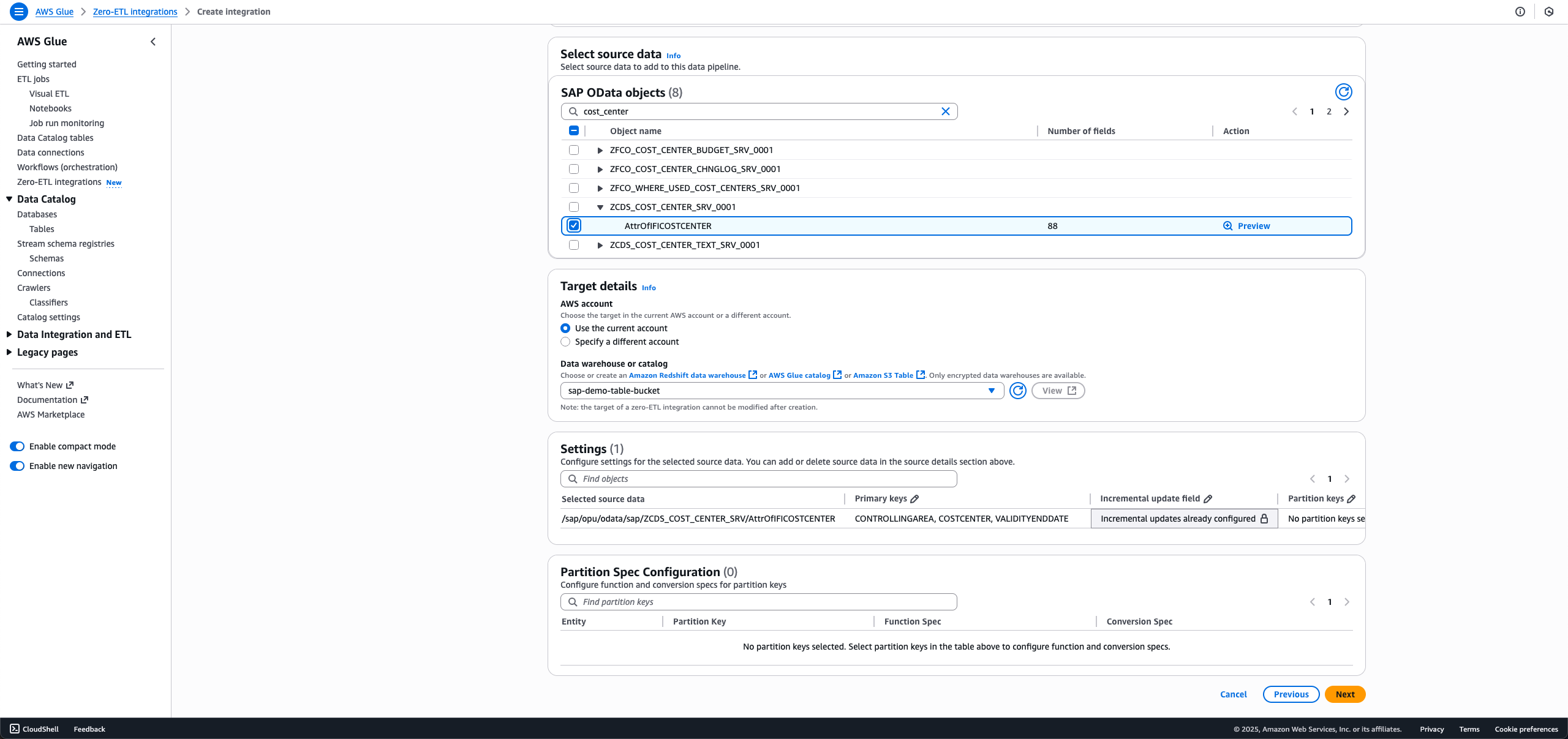
- 統合に含めるSAPオブジェクトを選択します。非ODPオブジェクトは完全ロードまたは増分ロード用に設定され、ODPオブジェクトは増分取り込み用に自動的に設定されます。
- 完全ロードの場合、Incremental update fieldをNo timestamp field selectedのままにします。
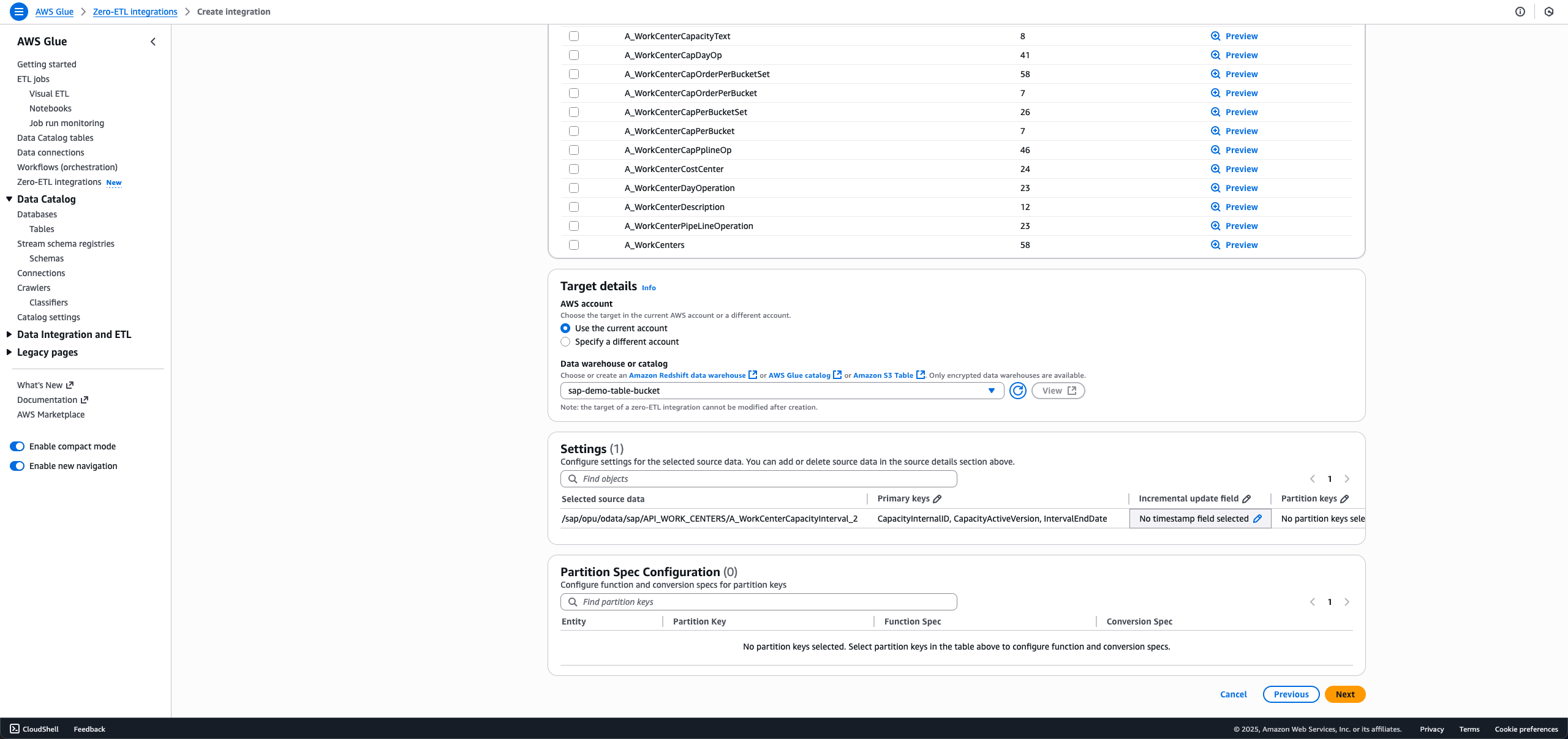
- 増分ロードの場合、Incremental update fieldの編集アイコンを選択し、タイムスタンプフィールドを選択します。
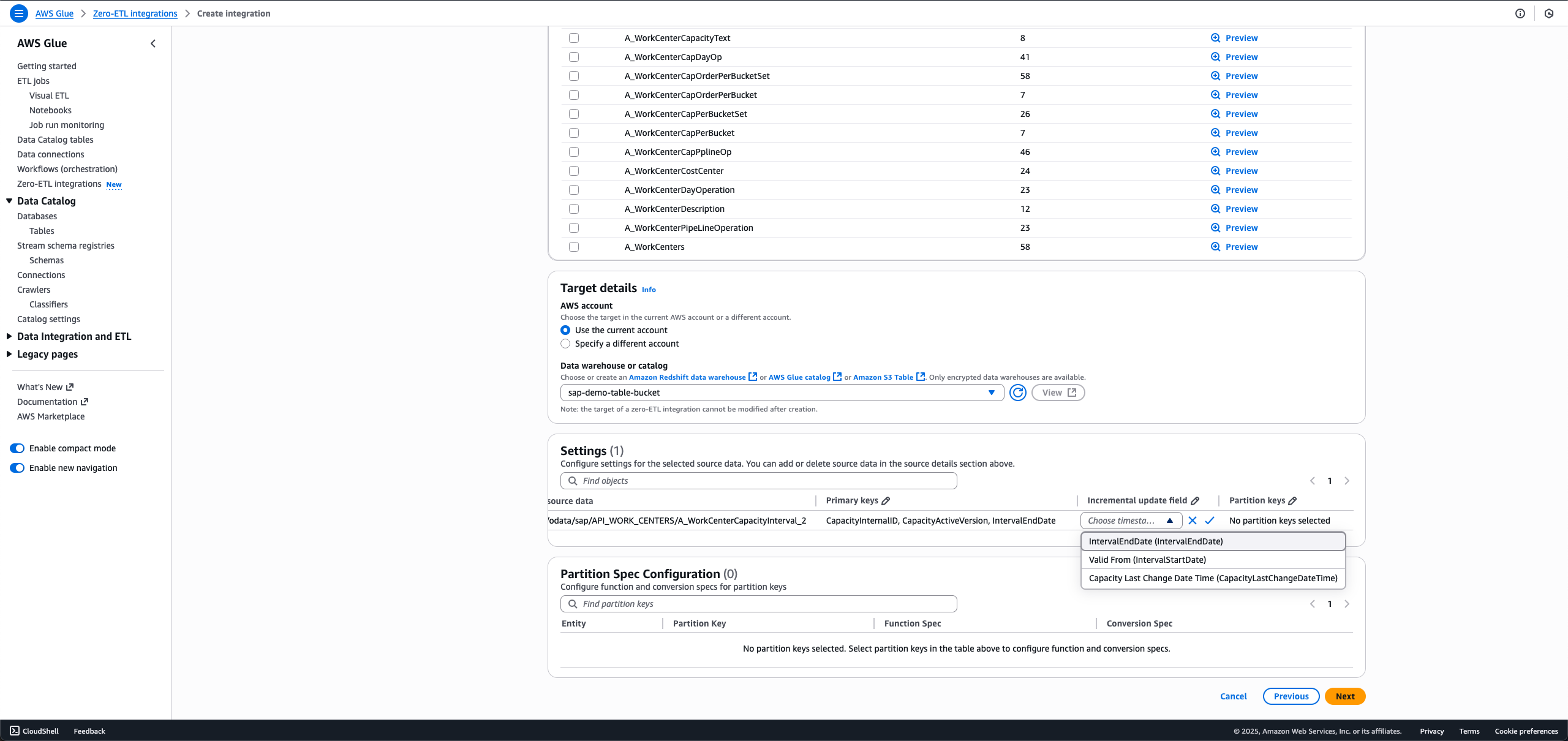
- デルタトークンを提供するODPエンティティの場合、増分更新フィールドは事前に選択されており、ユーザーのアクションは必要ありません。
同じSAP接続とエンティティをデータフィルターで使用して新しい統合を作成する場合、最初の統合とは異なる増分更新フィールドを選択することはできません。
- 完全ロードの場合、Incremental update fieldをNo timestamp field selectedのままにします。
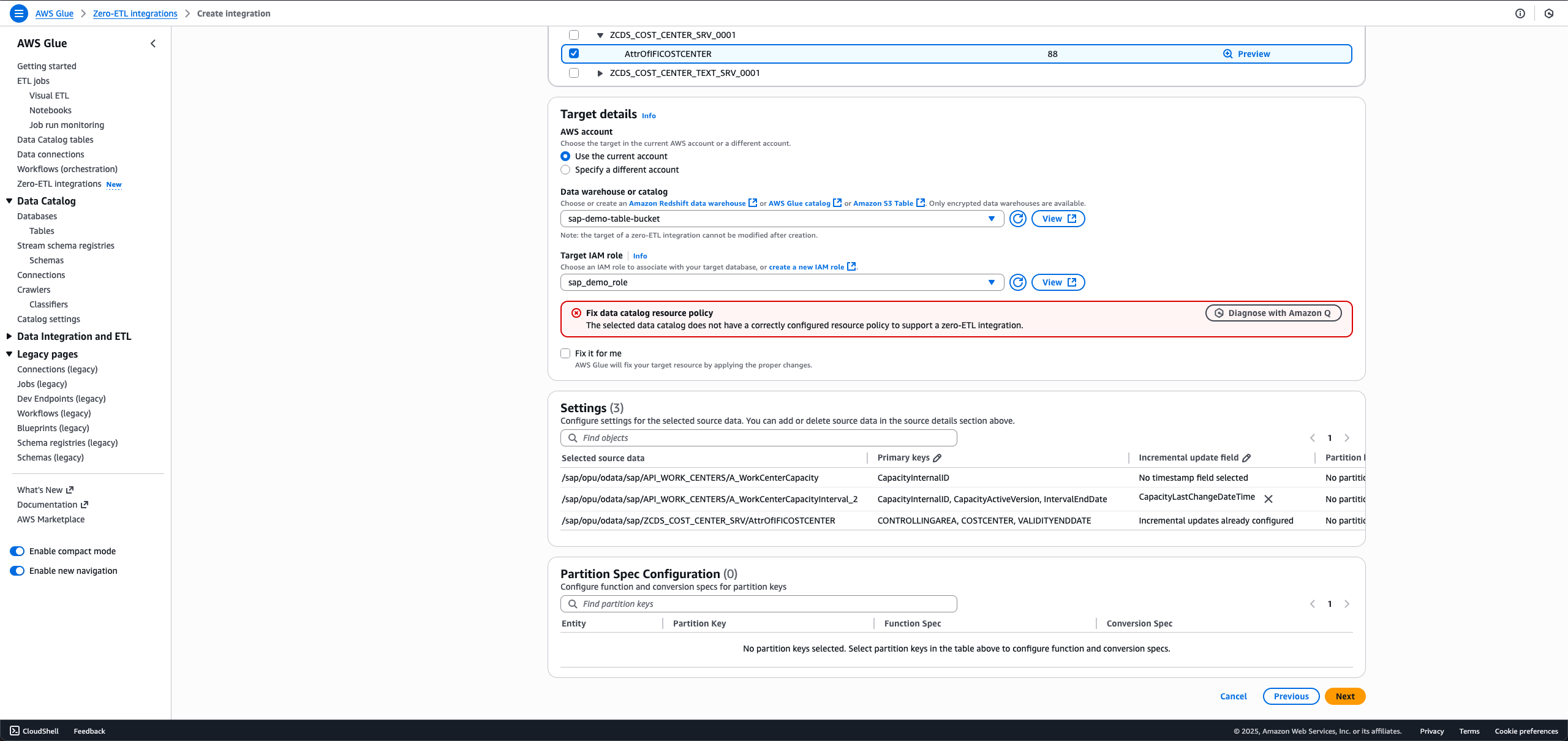
- Target detailsで、sap_demo_table_bucket(前提条件として作成)を選択します。
- Target IAM roleで、sap_demo_role(前提条件として作成)を選択します。
- Nextを選択します。
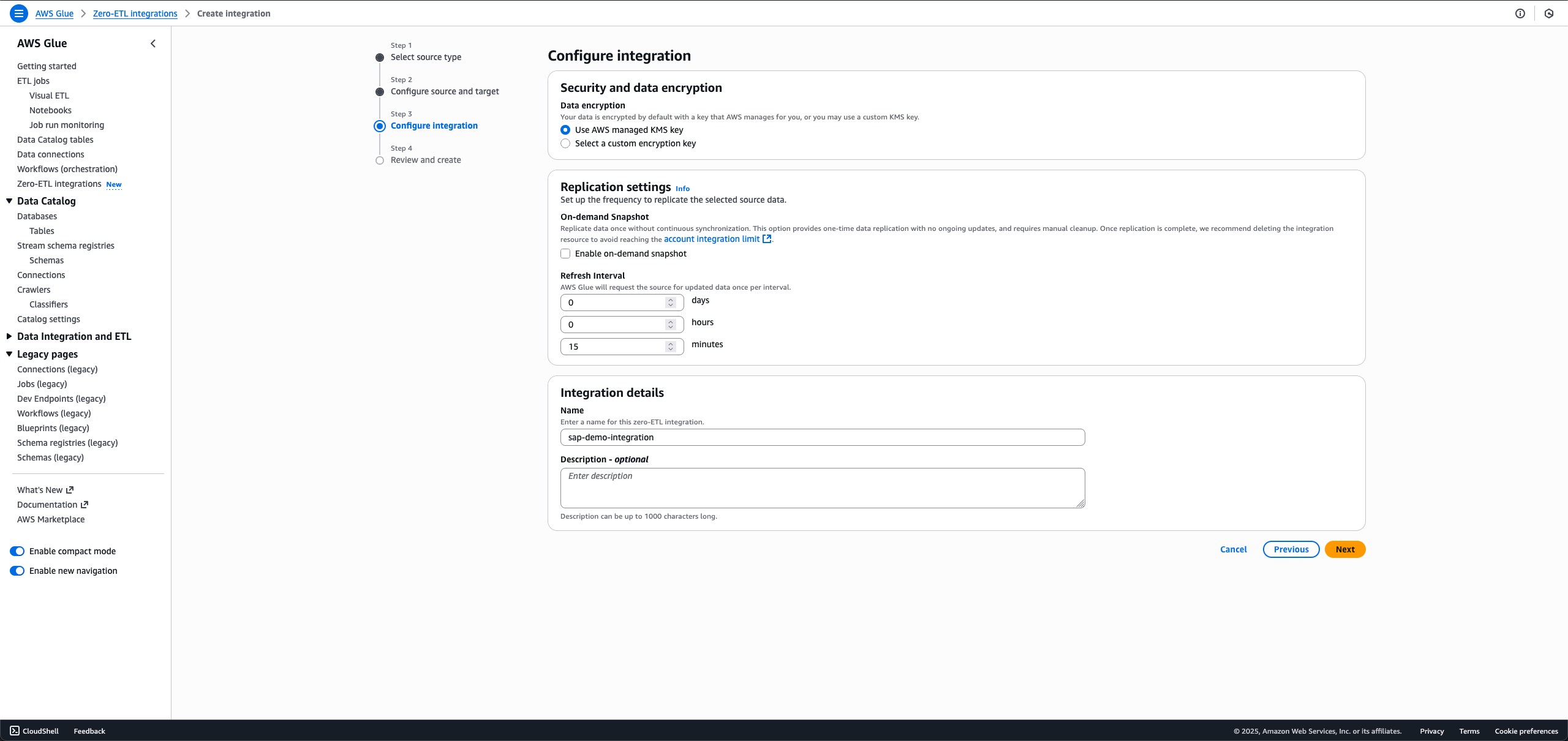
- Integration detailsセクションで、Nameにsap-demo-integrationと入力します。
- Nextを選択します。
- 詳細を確認し、Create and launch integrationを選択します。
新しく作成された統合は、約1分でActiveとして表示されます。
クリーンアップ
リソースをクリーンアップするには、以下の手順を実行します。このプロセスは、この記事で作成されたリソースを完全に削除します。続行する前に重要なデータをバックアップしてください。
- zero-ETL統合 sap-demo-integration を削除します。
- S3 Tablesターゲットバケット sap_demo_table_bucket を削除します。
- Data Catalog接続 sap_demo_conn を削除します。
- Secrets Managerシークレット zero_etl_bulk_demo_secret を削除します。
まとめ
ここまでの手順で、従来のようなETL構築の複雑さなしに、SAPデータ分析を大きく改善できるようになりました。AWS Glue zero-ETLを使用すると、S3 Tables、SageMaker lakehouseアーキテクチャ、Amazon Redshiftに、元の構造を維持しながらデータを連携でき、SAPデータに即座にアクセス可能な環境を構築できます。チームは、コスト効率の高いクラウドストレージにデータを保持しながら、Apache Iceberg のタイムトラベル機能、スキーマ進化、および大規模な同時読み取り/書き込みを備えたACID準拠のストレージを使用できます。Amazon QとSageMaker等のAI機能は、ビジネスがオンデマンドデータ製品を作成し、テキストからSQLへのクエリを実行し、Amazon BedrockとQuick Suiteを使用してAIエージェントをデプロイするのに役立ちます。
詳細については、以下のリソースを参照してください:
- AWS Glue Documentation
- Zero-ETL integrations
- Connecting to SAP OData
- Amazon SageMaker lakehouse アーキテクチャ
- Amazon S3 tables をターゲットとして設定する
- Amazon Q Documentation
- Amazon Quick Suite Documentation
SAPデータ戦略を近代化する準備はできていますか?AWS Glue zero-ETLを探索し、組織のデータ分析機能を強化しましょう。
著者について

Shashank Sharma
Shashankは、エンタープライズ顧客向けのファーストパーティおよびサードパーティのデータベースとSaaSのデータ統合およびレプリケーションソリューションの提供において15年以上の経験を持つエンジニアリングリーダーです。彼はAWS Glue Zero-ETLとAmazon AppFlowのエンジニアリングをリードしています。

Parth Panchal
Parthは、10年以上の開発経験を持つ経験豊富なソフトウェアエンジニアで、AWS Glue zero-ETLとSAPデータ統合ソリューションを専門としています。彼は、複雑なデータレプリケーションの課題に深く取り組み、パフォーマンスと信頼性の高い基準を維持しながらスケーラブルなソリューションを提供することに優れています。

Diego Lombardini
Diegoは、SAPテクノロジー全体で20年以上の経験を持つ経験豊富なエンタープライズアーキテクトで、SAPイノベーションとデータおよび分析を専門としています。彼はパートナーとユーザーの両方として働いてきたため、システムと組織を販売、実装、運用するために必要なことについて完全な視点を持っています。彼はテクノロジーとイノベーションに情熱を持ち、顧客の成果とビジネス価値の提供に焦点を当てています。

Abhijeet Jangam
Abhijeet は、複数の業界にわたる戦略と提供をリードする20年のSAP技術機能経験を持つデータおよびAIリーダーです。数十のSAP実装経験により、彼はアプリケーション開発、データエンジニアリング、統合における深い技術的専門知識とともに、幅広い機能プロセス知識をもたらします。
翻訳: 下佐粉 昭 (AWS Japan ソリューションアーキテクト)