Amazon Web Services ブログ
Sim-to-Real と Real-to-Sim: 高性能な Physical AI を支える原動力
本記事は 2026 年 5 月 13 日 に公開された「Sim-to-Real and Real-to-Sim: The Engine Behind Capable Physical AI」を翻訳したものです。
はじめに
現実世界で知覚・推論・行動するロボット、いわゆる Physical AI システムの進化が加速しています。その中心にあるのが Sim-to-Real パイプラインです。しかし、実験室の外でも安定して動作するモデルの構築は、この分野で最も難しい課題の一つです。シミュレーションで機能するものと実際のハードウェアで機能するものの間にあるギャップこそ、多くのプロジェクトが行き詰まる原因です。
本記事では、Sim-to-Real (Sim2Real) と Real-to-Sim (Real2Sim) が、物理環境で動作する AI モデル構築において最も重要な技術となった理由を解説します。シミュレーションと現実のギャップがなぜ埋まりにくいのか、現代的なアプローチでどう克服するのか、そしてロボティクスをけん引する Vision Language Action モデル (VLA) がこのパイプラインの品質に全面的に依存している理由についても説明します。
実世界のデータだけではスケールしない理由
ロボットに操作タスクを学習させるには、照明・物体の位置・表面テクスチャ・グリッパーの向きといった条件を横断して汎化するために、通常数万件のデモンストレーションが必要です。それを実機で実施するのは時間もコストもかかり、リスクも伴います。
この制約はあらゆる分野に共通します。倉庫の自動化では通常、数千種類の SKU バリエーションへの対応が必要です。自動運転車は通常、数百万件の走行シナリオを必要とします。手術ロボットは、実際の患者で倫理的にリハーサルできない処置を扱います。必要な規模での物理的なデータ収集は、現実的に不可能です。
シミュレーションはこの課題に直接対処します。物理的に正確な仮想環境では、通常、はるかに低コストで安全な環境から桁違いの速さでトレーニングデータを生成できます。ただし、純粋にシミュレーションで学習したモデルは、常に変化し予測不可能な物理環境での動作という性質上、実世界に展開すると失敗しがちです。この失敗パターンには名前があります。シミュレーションと現実のギャップ、すなわち「リアリティギャップ」です。
シミュレーションと現実のギャップ
シミュレーションと現実のギャップとは、シミュレーションで学習したモデルを実機に展開したときの性能差のことです。シミュレーションはあくまで近似であるため、このギャップは避けられません。実際のカメラはノイズ・歪み・露出変動をもたらしますが、合成レンダリングはデフォルトではそれを再現しません。実際の表面には、どの物理エンジンも完全にはモデル化できない摩擦係数があります。実際のアクチュエータにはバックラッシュ・遅延・熱ドリフトがあります。クリーンな合成データで学習したモデルはシミュレーションの完全性を利用することを覚えてしまい、その挙動は現実には転用できません。
ギャップを埋めるには、二つの補完的なアプローチが必要です。
シミュレーション精度の向上 NVIDIA Isaac Sim のような現代の物理シミュレーターは、剛体ダイナミクス・変形可能物体・流体挙動・接触力を、数年前には実現できなかったレベルの精度でモデル化します。パストレーシングと物理ベースマテリアルを用いたフォトリアリスティックなレンダリングにより、実際のカメラ映像との区別がますます難しい視覚入力が生成されます。
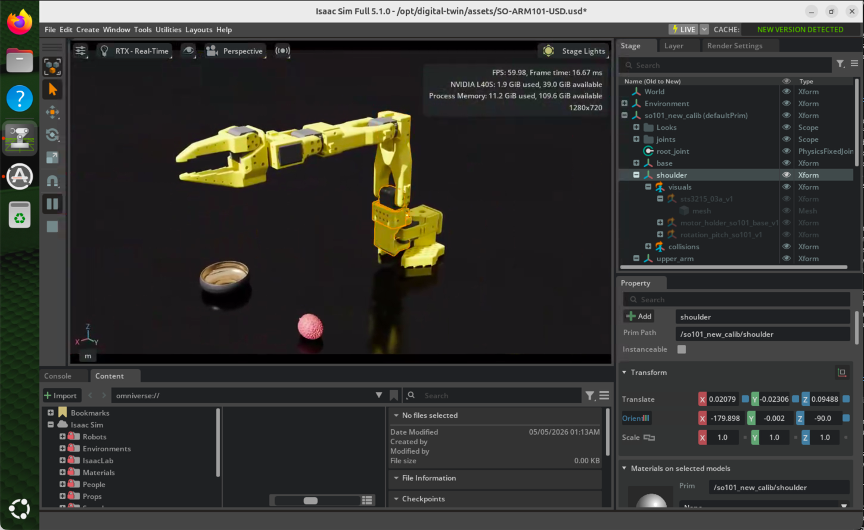
Figure 1: Amazon EC2 G6e.4xlarge インスタンス上で動作する NVIDIA Isaac Sim
ドメインランダム化 単に一つのシミュレーションを完全に正確にするのではなく、多数のランダム化されたバリエーションにわたって学習します。照明・テクスチャ・物体の質量・関節摩擦・センサーノイズを変化させることで、幅広い条件の分布に対してロバストなポリシーを学習します。重要なのは、純粋なデータ量ではなく、シミュレーションパラメータの十分な多様性とカバレッジです。これにより、ニューラルネットワークは多様な環境において、対象物のキーとなる要素を識別することを学習します。

Figure 2: OpenAI が実証した、ルービックキューブを解くロボット。(出典: OpenAI, https://openai.com/index/solving-rubiks-cube/)
Real-to-Sim: 物理世界をトレーニングインフラに変える
Real-to-Sim とは、現実の環境をキャプチャしてシミュレーション対応のデジタル表現に変換するプロセスです。Sim2Real が学習済みポリシーを実機に転用することを目的とするなら、Real2Sim はそのシミュレーションがハードウェアの実際の動作環境を反映することを保証するためのものです。
使用される技術は複数の分野にまたがります。LiDAR スキャンとフォトグラメトリーは、3D メッシュに処理できる点群を生成します。Neural Radiance Fields (NeRF) と 3D Gaussian Splatting は、通常のカメラ映像からシーンのジオメトリと外観を再構築し、物理シミュレーション環境に直接取り込めるアセットを生成します。これはリアリティギャップ、すなわち仮想アセットと物理アセットのモデル化における性能差の解消に役立ちます。これらのアセットは、多様な照明条件やカメラアングルにわたって現実の見た目や質感を保持する技術を用いて仮想世界に取り込まれます。
Physical AI のトレーニングパイプラインにおいて、Real2Sim は遠隔操作によるデータ収集で特に重要な役割を果たします。人間のオペレーターがデモンストレーションインターフェースを通じて物理的なロボットアームを操作すると、システムはその動きをシミュレーション上のデジタルツインに同時にミラーリングします。これにより現実世界で記録された人間品質のデモンストレーションデータセットと、同じタスクの追加的な合成バリエーションを生成できる同期済みシミュレーショントレースという二つのデータを同時に得られます。。

Figure 3: SO-101 を使ったテレオペレーション
このアプローチが実用的な加速手段となるのは、模倣学習の中心的なボトルネックに対処しているからです。模倣学習とは、報酬ベースの試行錯誤ではなく人間のデモンストレーションを観察することでロボットが学習する枠組みです。高品質な人間のデモンストレーションは模倣学習が依存するトレーニングシグナルであり、Real2Sim インフラを活用することで、物理ハードウェアのコストを比例的に増やすことなくそのシグナルをスケールできます。
合成データの生成とフィルタリング
実世界およびテレオペレーションで収集したデータは分布に沿った教師信号を提供します。つまり、トレーニングサンプルがロボットの展開時に実際に直面する条件 (照明・物体の種類・カメラアングル) を反映しています。シミュレーションはスケールを提供します。現代の Physical AI トレーニングパイプラインはこの二つを組み合わせます。
合成データ生成とは、シミュレーション環境内でラベル付きトレーニングサンプルをプログラム的に大規模生成することです。操作タスクでは、異なる物体姿勢・照明条件・グリッパー構成にわたって把持シナリオの数千バリエーションをレンダリングし、それぞれに深度・セグメンテーションマスク・アクションラベルのグラウンドトゥルースを自動アノテーションします。
データ量だけでは不十分です。フィルタリングパイプラインは、自動品質メトリクスと学習済み識別器を使って、分布外または物理的に不自然なサンプルをトレーニングセットに入る前に除去します。適切に構築されたパイプラインの出力は、実際のデモンストレーションによる物理的な根拠、合成生成の規模、および自動フィルタリングによる品質管理を備えたトレーニングデータセットとなります。
VLM・VLA と、シミュレーション品質がモデル性能を決める理由
Physical AI チームがロボット制御の基盤レイヤーとして注目しているモデルが、Vision Language Model (VLM) と Vision Language Action モデル (VLA) です。
VLM は、大規模な画像とテキストのコーパスで学習したマルチモーダル基盤モデルです。幅広い視覚的理解で、画像内の内容を推論し、空間的な関係を説明し、物体を識別し、視覚的なコンテンツを参照する言語指示に従う能力を獲得します。Amazon Bedrock 上の Amazon Nova、Anthropic Claude、Qwen、Mistral などがこのクラスの例です。Amazon Bedrock は、基盤インフラを管理することなくこれらのモデルにアクセスするためのマネージド API レイヤーを提供します。これは、独自のインフラの複雑さを持つ Physical AI パイプラインに視覚的推論を統合する際に重要です。
VLA は、VLMのパラダイムを物理的な動作へと拡張したものです。VLAは、テキストを出力するのではなく、視覚的な観察と言語による指示に応じて、ロボットの動作、関節の位置、速度指令、エンドエフェクタの軌道などを生成します。VLAのトレーニング目標は、視覚的理解と物理的な因果関係の両方に基づいた方針を学習することです。つまり、「自分が見ているものと、自分がするように求められていることを踏まえて、どのような行動をとるべきか?」を学習します。
シミュレーションデータの品質は、VLAが明示的に学習されていないタスクに対してどれだけうまく汎化できるかを直接左右します。学習に使用した視覚ドメイン(合成レンダリング)が展開ドメイン(現実世界)と一致しない場合、学習されたポリシーは破綻し、ぎこちない動作制御、タスクの失敗、ポリシー評価の精度低下といったパフォーマンス上の問題が即座に発生します。ドメインランダム化は、高品質のベースデータセットを取り込み、それを拡張して、新しいオブジェクト、異なる照明条件や色を持つ環境などを含むさらに高品質のデータセットを生成することで、ポリシーの堅牢性を高めます。高忠実度物理演算により、動作出力が物理的に意味のあるものとなることが保証されます。
合成データパイプラインは、実際のデモンストレーションだけではカバーできないタスク分布、まれな障害モード、エッジケース構成、そしてまだ物理的に存在しない環境に対してVLAを学習させることを可能にします。
産業への応用
このパイプラインが最も即効性のある価値をもたらす業界には、ある共通の特徴があります。それは、物理的な環境がリスクが高く、変化に富み、直接学ぶには費用がかかったり危険を伴ったりするという点です。
製造業では、倉庫自動化システムが SKU のバリエーション・梱包の損傷・フロアレイアウトの変化に対応する汎化能力を必要とします。Real2Sim キャプチャがシミュレーショントレーニングに供給され、Sim2Real 転用により実世界のバリエーションに耐えるポリシーが生成されます。
自動車業界では、自動運転システムは通常、実世界では安全に再現できない数百万件のエッジケースシナリオにわたるトレーニングを必要とします。
医療分野では、手術や患者ケアへの応用が厳格な安全規制上の制約を受けます。高精度なシミュレーションにより、患者への接触なしにモデルのトレーニングと検証を進められます。
エネルギー・公益事業では、点検用の自律ロボットが変電所・パイプライン・風力発電所など、人間が立ち入ることに実際の身体的リスクを伴う環境で稼働します。
小売業界では、自律型フルフィルメントシステムは、絶えず変化するレイアウトの中で膨大な種類のSKU(在庫管理単位)に対応しなければなりません。数千種類もの製品バリエーションにわたるトレーニングデータを生成するシミュレーションこそが、生産規模での汎用化を実現する唯一の現実的な方法です。
今後の展望
本記事では、Physical AIモデルを現実世界で動作させるためのコアエンジンであるSim2Real/Real2Simパイプラインの目的と内容について解説しました。本シリーズの次回記事では、LeRobot SO-101 AWS Sim2Real2Sim リファレンスプロジェクトのハンズオン技術解説を通じて、これらの概念を具体化します。AWS インフラストラクチャ・NVIDIA Isaac Sim・公開されている LeRobot プラットフォームを使ってエンドツーエンドで実装する、完全にデプロイ可能なアーキテクチャを紹介します。
まずは基盤モデルへのアクセスに Amazon Bedrock を、シミュレーションワークロードに最適化された Amazon EC2 G6e インスタンスをご確認ください。
翻訳は Visual Compute SSA 森が担当しました。原文はこちらをご覧ください。