Amazon Web Services ブログ
Amazon SageMaker レイクハウスアーキテクチャによる Amazon S3 上の Apache Iceberg テーブルの最適化設定の自動化
本記事は、2025 年 8 月 8 日に公開された The Amazon SageMaker lakehouse architecture now automates optimization configuration of Apache Iceberg tables on Amazon S3 を翻訳したものです。翻訳は Solutions Architect の 松岡勝也 が担当しました。
組織が Amazon Web Services (AWS) 上のデータレイクアーキテクチャに Apache Iceberg テーブルを採用するようになるにつれ、これらのテーブルのメンテナンスが長期的な成功の鍵となります。適切なメンテナンスがないと、Iceberg テーブルはクエリパフォーマンスの低下、削除すべき古いデータの不要な保持、ストレージコスト効率の低下など、いくつかの課題に直面する可能性があります。これらの問題は、データレイクの効果とコスト効率に大きな影響を与える可能性があります。定期的なテーブルメンテナンス作業により、本番ワークロードの Iceberg テーブルの高いパフォーマンス、データ保持ポリシーの遵守、コスト効率を確保することができます。Iceberg テーブルを大規模に管理できるよう、AWS Glue では以下の Iceberg テーブルメンテナンス作業を自動化しました:sort や z-order でのコンパクション、そしてスナップショットの有効期限設定と孤立データの管理です。この機能のリリース後、多くのお客様が運用負荷を軽減するために AWS Glue Data Catalog を通じて自動テーブル最適化を有効にしています。
Amazon SageMaker レイクハウスアーキテクチャでは、カタログレベルの設定により、Amazon S3 に保存された Iceberg テーブルの最適化 が自動化されるようになり、Iceberg テーブルのストレージを最適化してクエリのパフォーマンスを向上させます。これまでは、AWS Glue Data Catalog の Iceberg テーブルを最適化するには、各テーブルの設定を個別に更新する必要がありました。現在は、Data Catalog の一度の設定で新しい Iceberg テーブルの自動最適化を有効にできます。有効化すると、新規テーブルまたは更新されたテーブルに対して、Data Catalog は小さなファイルの圧縮、スナップショットの削除、不要な参照されていないファイルの削除を行い、継続的にテーブルを最適化します。
このポストでは、カタログレベルのテーブル最適化設定を有効にするための一連のフローをご紹介します。
前提条件
新しいカタログレベルのテーブル最適化を使用するには、以下の前提条件が必要です:
- アクティブな AWS アカウント。
- カタログレベルでテーブル最適化を設定するデータレイク管理者。データレイク管理者を作成するには、AWS Lake Formation のセットアップを参照してください。
- Iceberg テーブルにアクセスするためのテーブル最適化用の AWS Identity and Access Management (IAM) ロール。手順については、カタログレベルのテーブル最適化の前提条件を参照してください。
カタログレベルでのテーブル最適化の有効化
データレイク管理者は、AWS Lake Formation コンソールでカタログレベルのテーブル最適化を有効にできます。以下の手順を実行してください:
- AWS Lake Formation コンソールで、ナビゲーションペインの Catalogs を選択します。
- カタログレベルのテーブル最適化を有効にするカタログを選択します。
- 次のスクリーンショットのように、Table optimizations タブを選択し、Table optimizations の Edit を選択します。
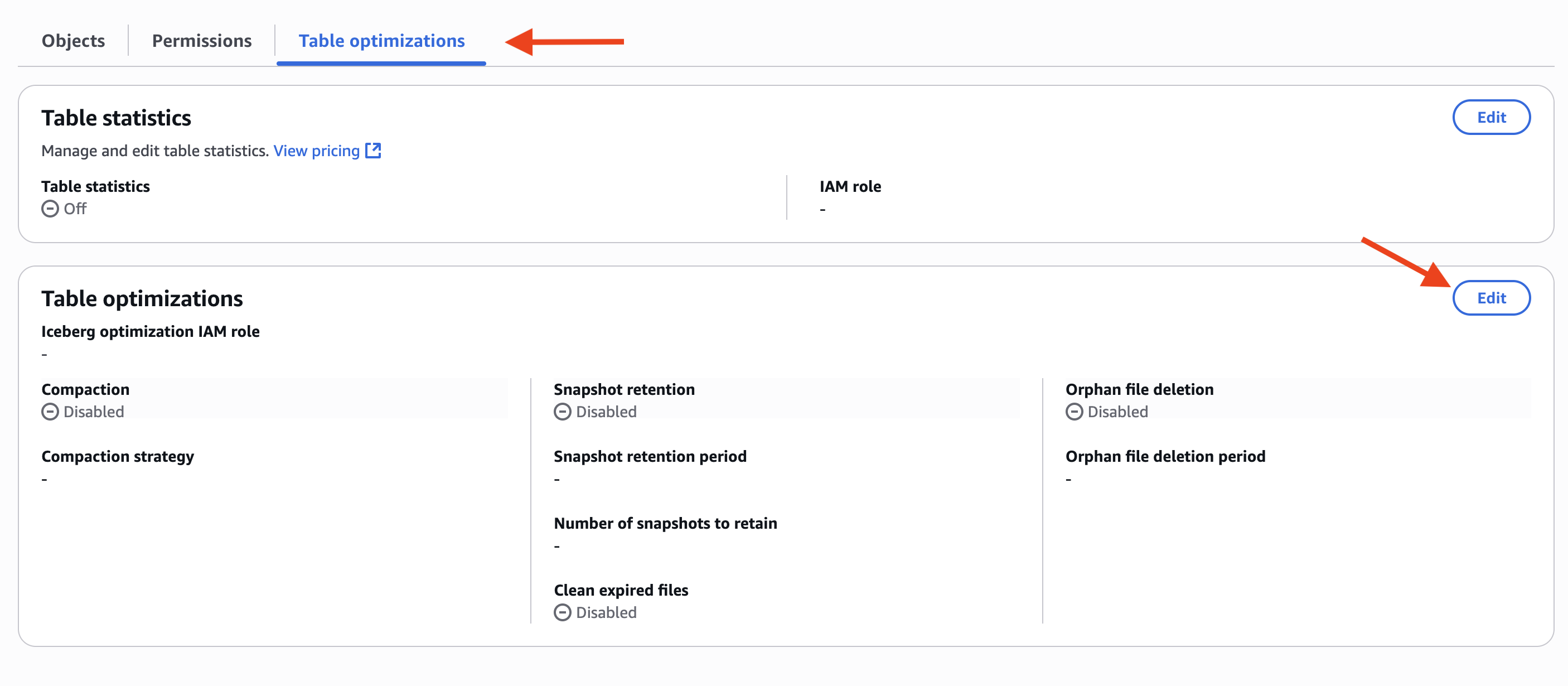
- Optimization options で、次のスクリーンショットに示すように、Compaction、Snapshot retention、Orphan file deletion を選択します。
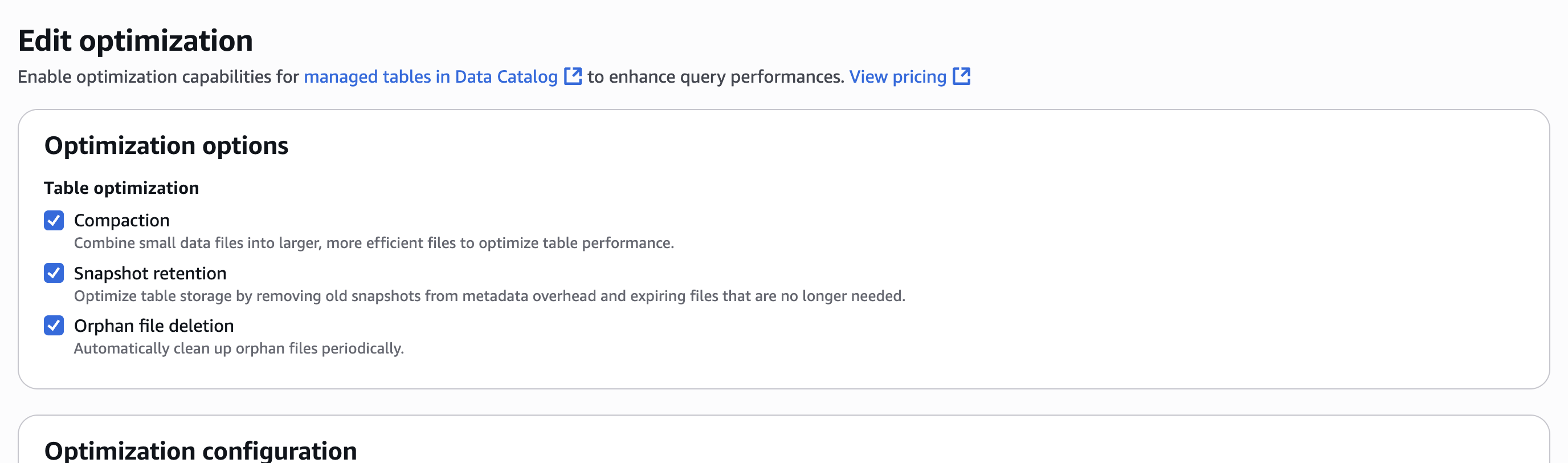
- IAM ロールを選択します。権限については テーブル最適化の前提条件 を参照してください。
- Grant required permissions を選択します。
- I acknowledge that expired data will be deleted as part of the optimizers を選択します。
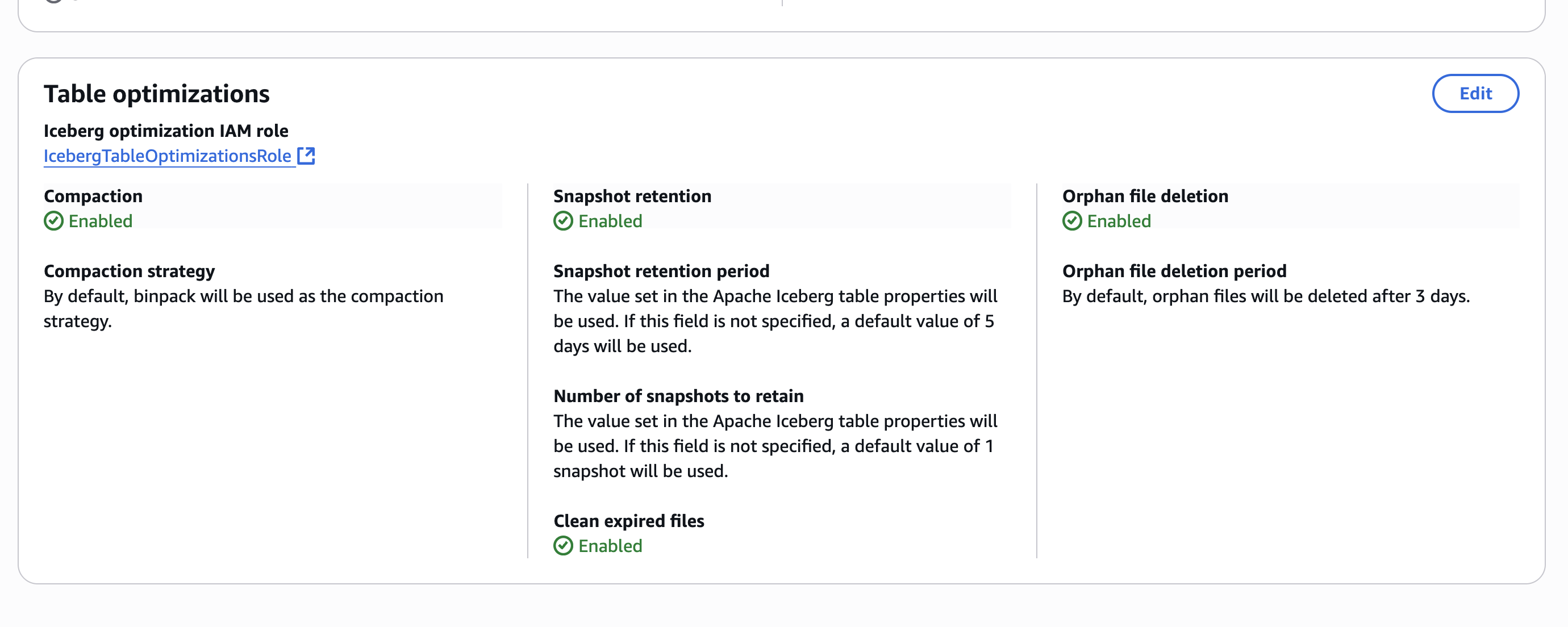
カタログレベルでテーブルの最適化を有効にすると、次のスクリーンショットのように、AWS Lake Formation コンソールに設定が表示されます。
カタログに登録された Iceberg テーブルを選択すると、次のスクリーンショットに示すように、Configuration source に catalog と表示されることから、テーブルの最適化設定がテーブルビューから継承されていることを確認できます。
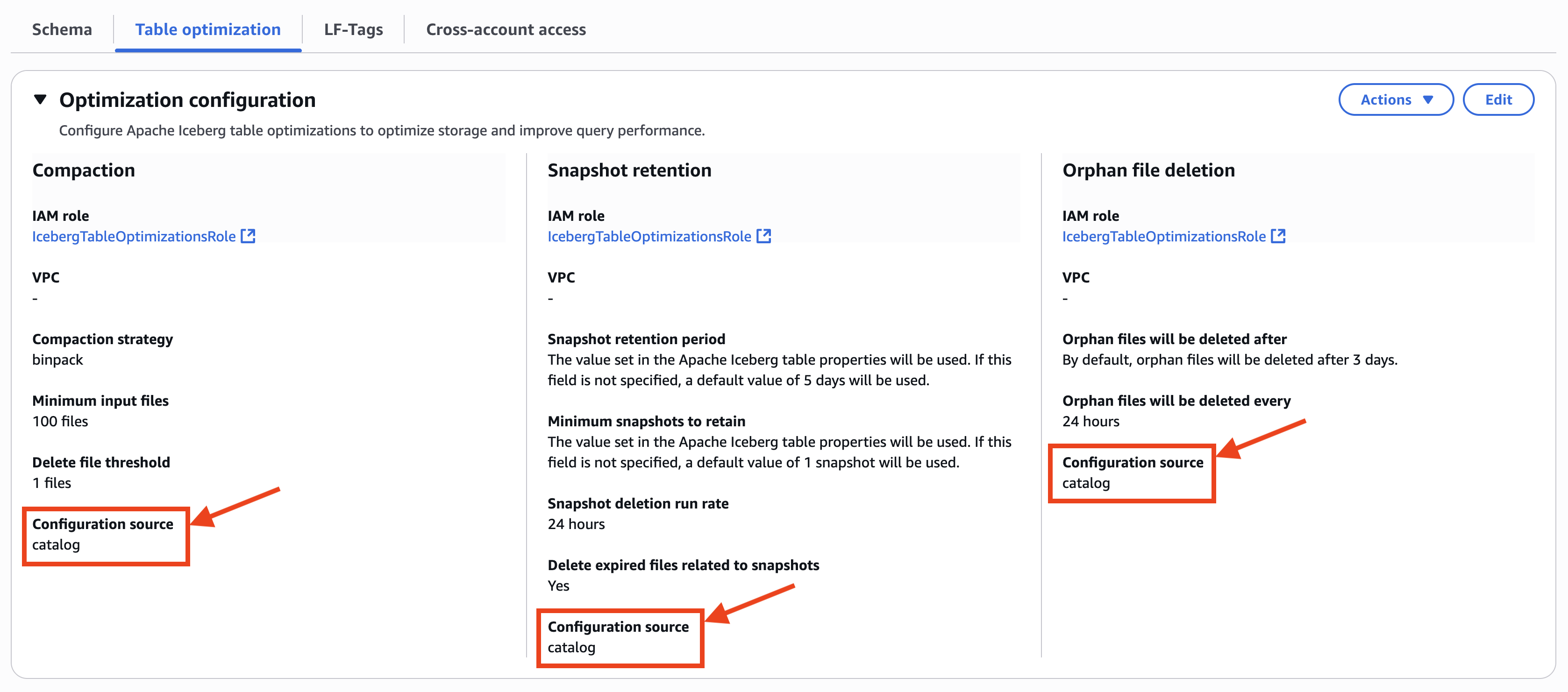
テーブルの最適化履歴は、テーブルビューに表示されます。
以下の結果は、テーブルの最適化によるコンパクション処理の 1 つを示しています。
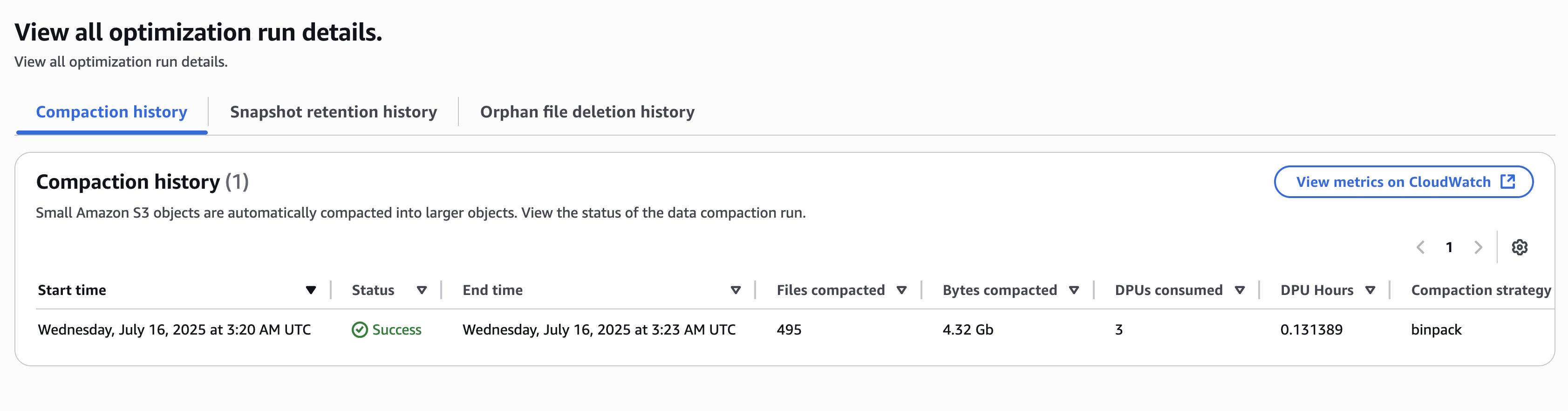
すべてのデータベースと Iceberg テーブルに対するカタログレベルのテーブル最適化が有効になりました。
カタログレベルとテーブルレベルでのテーブル最適化設定のカスタマイズ
カタログレベルの最適化は、カタログ内のすべてのデータベースと Iceberg テーブルに共通の設定を適用しますが、特定の Iceberg テーブルに対して異なる戦略を適用したい場合があります。
AWS Glue Data Catalog を使用して、特定のテーブルの特性とアクセスパターンに基づいて、カタログレベルとテーブルレベルの両方の最適化を有効にできます。
例えば、汎用的な Iceberg テーブル向けに binpack 戦略を使用したカタログレベルのコンパクション設定に加えて、タイムスタンプカラムに対する範囲クエリが頻繁に実行されるテーブルには、テーブルレベルでソート戦略を適用できます。
このセクションでは、実践的なシナリオを通じて、カタログレベルとテーブル固有の最適化の設定方法を説明します。
頻繁な書き込み操作が行われるリアルタイム分析テーブルを想像してください。このテーブルでは、メタデータの更新が頻繁に行われるため、より多くの孤立ファイルが生成されます。
また、ユーザーは特定のカラムをフィルタリングして一部のデータを対象とするクエリを実行するため、sort 戦略が望ましいものとなります。
以下のステップを実行してください:
- AWS Lake Formation コンソールでテーブルレベルの最適化を設定するために、先ほどと同じカタログ内の別の Iceberg テーブルを選択します。なお、このテーブルにはカタログレベルのテーブル最適化が設定されています。
- 次のスクリーンショットに示すように、Optimization configuration で Edit を選択します。
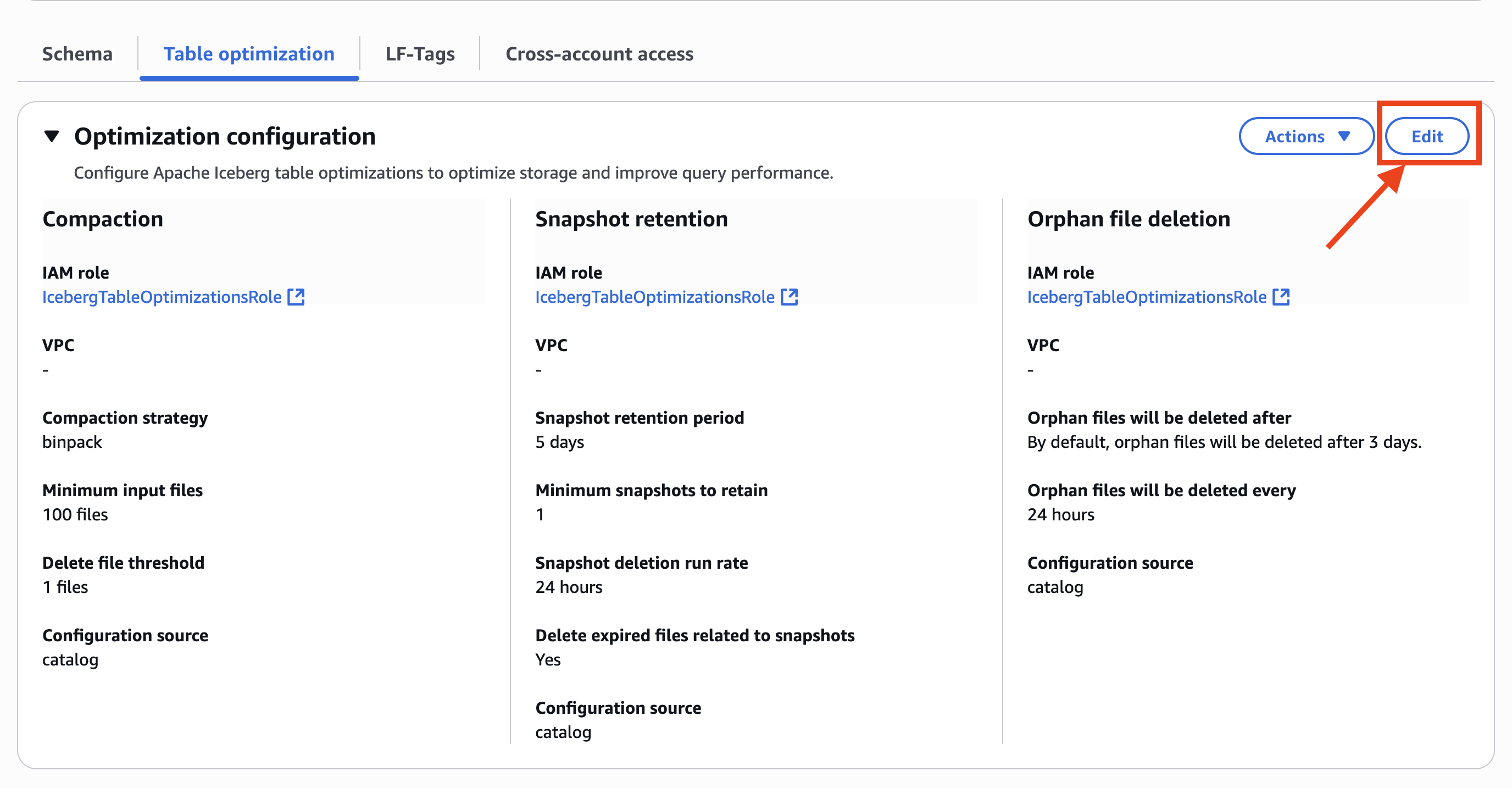
- Optimization options で、Compaction、Snapshot retention、Orphan file deletion を選択します。
- Optimization configuration で、Customize settings を選択します。
- 同じ IAM ロールを選択します。
- Compaction configuration で、次のスクリーンショットのように Sort を選択します。また、Minimum input files に 80 ファイルを設定します。これはコンパクションをトリガーするファイル数の閾値です。Sort を設定するには、Iceberg テーブルでソート順を定義する必要があります。ソート順は
ALTER TABLE db.tbl WRITE ORDERED BYのような Spark SQL で定義できます。
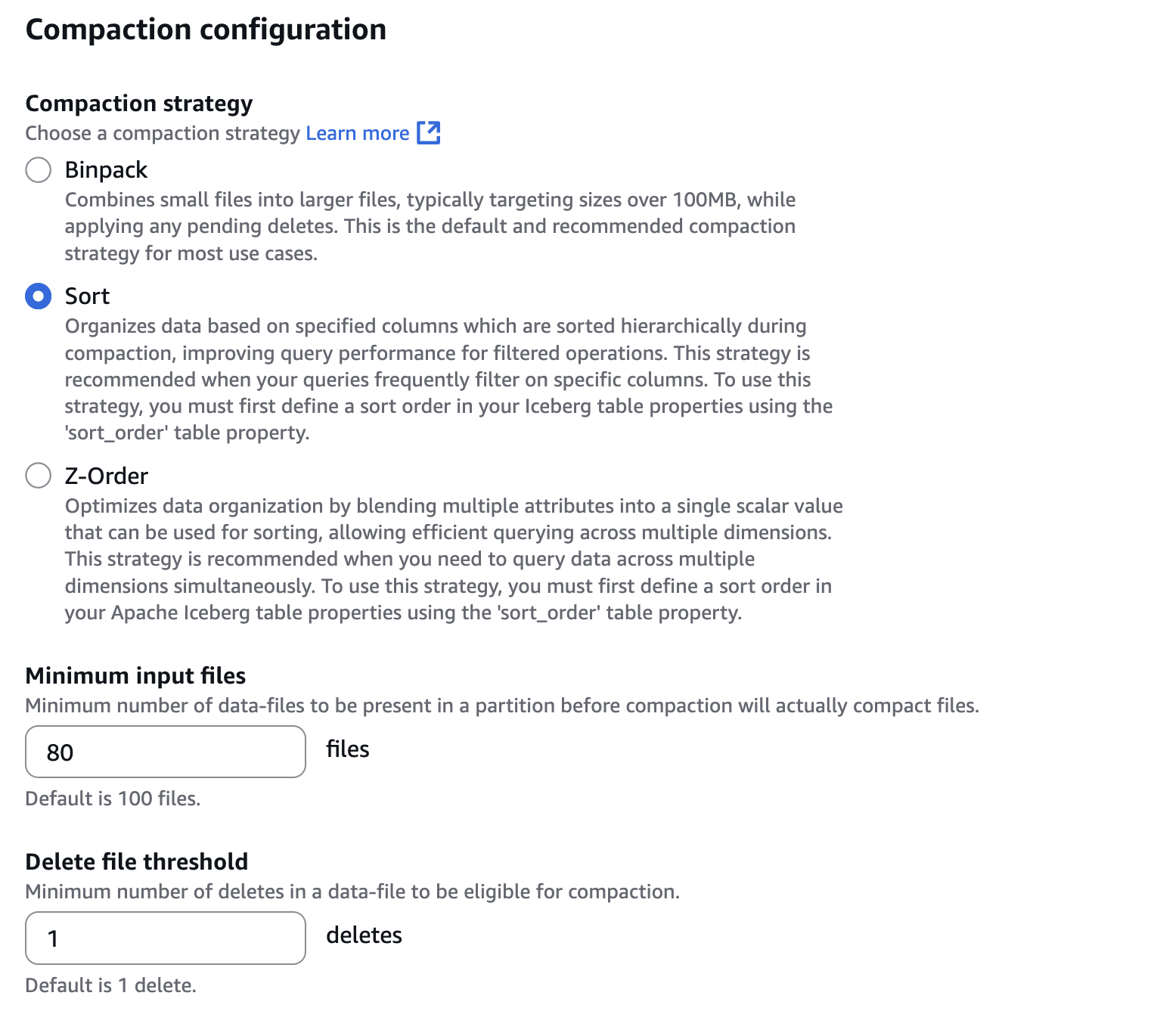
- Snapshot retention configuration と Snapshot deletion run rate で、Specify a custom value in hours を選択します。次のスクリーンショットに示すように、2 つの削除ジョブの実行間隔を 12 時間に設定します。

- Orphan file deletion configuration で、Files under the provided Table Location with a creation time older than this number of days will be deleted if they are no longer referenced by the Apache Iceberg Table metadata を 1 日に設定します。これにより、作成日数がこの値より古いファイルが Apache Iceberg Tableのメタデータで参照されなくなると削除されます。

- Grant required permissions を選択します。
- I acknowledge that expired data will be deleted as part of the optimizers を選択します。
- Save を選択します。
- AWS Lake Formation コンソールの Table optimization タブに、テーブルオプティマイザーのカスタム設定が表示されます。Compaction では、Compaction strategy が sort に設定され、Minimum input files は 80 files に設定されています。Snapshot retention と Snapshot deletion run rate が 12 hours に設定されています。 Orphan file deletion では Orphan files will be deleted after が 1 days に設定されています。これらは以下のスクリーンショットに示されています。
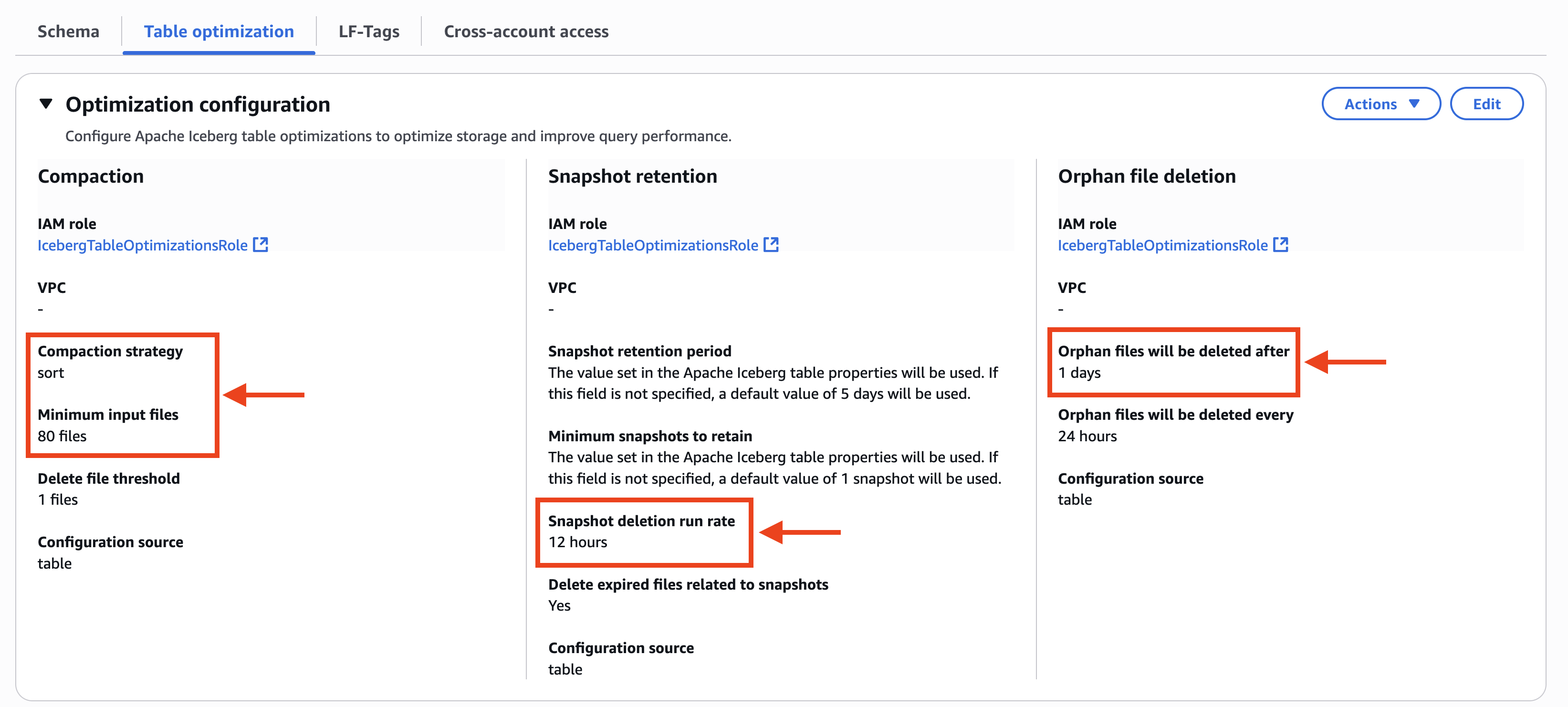
以下のスクリーンショットに示すように、カタログレベルの戦略が binpack に設定されていても、コンパクション履歴ではテーブルレベルのコンパクション戦略として sort が表示されます。
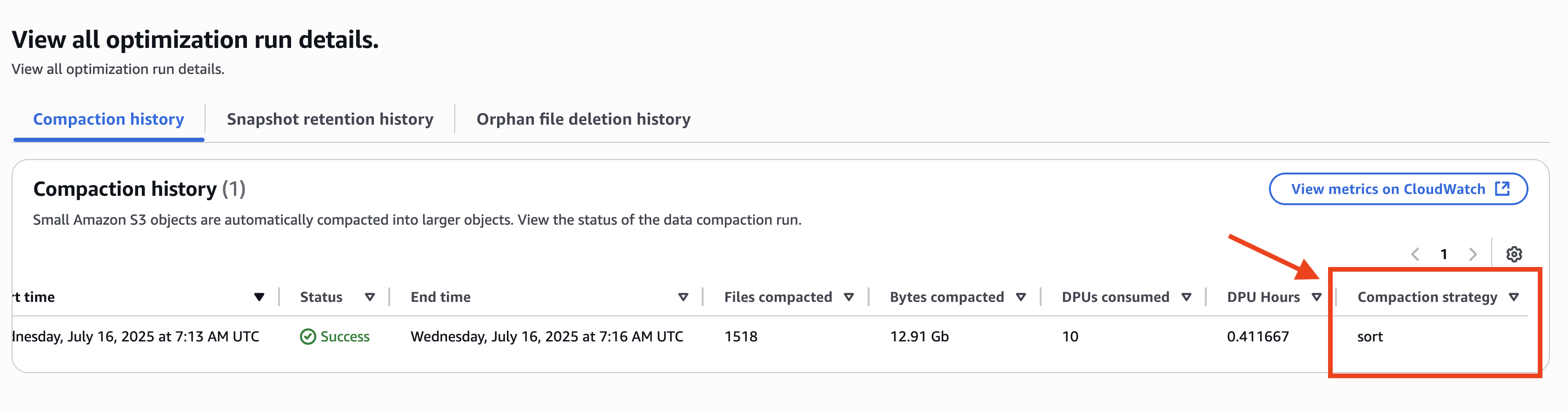
このシナリオでは、カタログレベルの最適化と共にテーブルレベルの最適化が設定されています。
テーブルレベルとカタログレベルの最適化を組み合わせることで、Iceberg テーブルのデータ削除とコンパクション処理をより柔軟に管理できます。
まとめ
この投稿では、AWS Glue Data Catalog のカタログレベルのテーブル最適化機能を使用して、Amazon SageMaker レイクハウスアーキテクチャで Iceberg テーブルを有効化し管理する方法を説明しました。
この機能強化により、単一の設定ですべてのテーブルに対して自動メンテナンス操作を有効にできるため、Iceberg テーブルの管理が大幅に簡素化されます。
個々のテーブルごとに最適化設定を構成する代わりに、データレイク全体をより効率的に維持できるようになり、運用オーバーヘッドを削減しながら一貫した最適化ポリシーを確保できます。
カタログレベルのテーブル最適化を有効にすることで、チームがデータの価値を最大限に活用することに集中できるようになり、整理された、高性能で費用対効果の高いデータレイクの維持を支援することをお勧めします。
この機能をお客様のユースケースで試していただき、コメントでフィードバックや質問をお寄せください。
AWS Glue Data Catalog テーブルオプティマイザーの詳細については、Iceberg テーブルの最適化をご覧ください。
謝辞:A special thanks to everyone who contributed to the development and launch of catalog level optimization: Siddharth Padmanabhan Ramanarayanan, Dhrithi Chidananda, Noella Jiang, Sangeet Lohariwala, Shyam Rathi, Anuj Jigneshkumar Vakil, and Jeremy Song.
著者について
 Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
 Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
 Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data.
 Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.
Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.