Amazon Web Services ブログ
株式会社タイミー様の Amazon EKS 活用事例: Amazon EKS Auto Mode × Actions Runner Controllerで実現するGitHub Actions Self-hosted Runner基盤 〜柔軟なスケーリングとセキュリティ強化を両立〜
このブログ記事は、株式会社タイミー様が執筆し、Amazon Web Services Japan が監修しています。
はじめに
株式会社タイミーは、「働きたい時間」と「働いてほしい時間」をマッチングするスキマバイトサービスを提供しています。
私たちは、Amazon EKS Auto Mode (EKS Auto Mode) × Actions Runner Controller (ARC) を活用し、コスト・パフォーマンス・運用性のバランスを兼ね備えた Self-hosted Runner 基盤を構築しました。
本記事では、その背景と設計方針、導入時に直面した課題と解決への取り組み、導入によって得られた効果、そして今後の展望について紹介します。
背景と課題
スキマバイトサービス『タイミー』を中心にプロダクト開発が拡大する中で、CI/CD 基盤の改善には継続的に取り組んできました。
2024年10月に公開した「CI 基盤を GitHub Actions へ移行した記事」で紹介したとおり、
CircleCI から GitHub Actions への移行によって、開発体験やパイプライン速度は大きく改善しました。
しかし、開発者数やテストケースの増加、そして AI エージェントの活用拡大により、時間の経過とともに新たな課題が見えてきました。
コスト面での課題
- CI 実行回数の急増
開発者や AI エージェント (例 : Devin) の利用が増えるにつれ、CI の実行回数も増加しました。
2025年初頭には、ピーク時で 1 時間あたり 60 件を超えるワークフローを処理する必要があり、コストとパフォーマンスの両立が新たな課題となりました。 - GitHub-hosted Runner のコスト最適化限界
GitHub-hosted Runner は安定性に優れる一方で、割引オプションが少なく、コストコントロールの柔軟性に欠けます。実行頻度が高いワークロードに対しては、効率的なコスト最適化が難しい状況でした。 - 柔軟な最適化が可能な基盤の必要性
一方で、AWS では Savings Plans や Spot インスタンスを活用することで、柔軟な最適化が可能です。利用量が増え続けるタイミーのユースケースにおいては、こうした 柔軟に最適化できる基盤 が求められるようになりました。
技術面での課題
- 高並列・高頻度な実行負荷
CI ワークフローでは最大 35 並列でジョブを実行しており、ピーク時には 1 時間あたり約 60 回のワークフローが走ることもありました。CI ワークフローだけでも、1 時間に最大で 2,000 件以上の Runner が起動する規模 となり、開発速度を維持しながら、この高い実行頻度に耐えられる仕組みが求められていました。 - 環境構築コストによる実行時間の肥大化
GitHub-hosted Runner ではジョブごとに環境を都度構築するため、apt installなどのセットアップ処理によって実行時間が長くなり、まれに依存パッケージの取得に失敗してジョブが落ちるケースも発生していました。 - テストケースの増加による実行時間の延伸
テスト数の増加に伴い、CI 全体の実行時間が徐々に長くなる傾向がありました。
その結果、「Self-hosted Runner (テスト実行用のコンテナ環境) にテスト実行に必要なライブラリをあらかじめインストールしておけば、テストのたびに毎回ライブラリをインストールする必要がなくなり、より高速化できるのでは?」という意見が開発者から上がるようになりました。 - セキュリティと運用負荷のトレードオフ
Terraform の適用など、強い IAM 権限を必要とするワークフローも存在しており、
セキュリティを強化しつつ、Self-hosted Runner 基盤に過剰な運用コストをかけないバランスが課題となっていました。
これらの課題を踏まえ、私たちは「コスト」「パフォーマンス」「セキュリティ」「運用性」のバランスを両立できる Self-hosted Runner 基盤を設計することにしました。そのために、複数のアプローチを比較検討しながら、最適なアーキテクチャを模索していきました。
プロジェクト概要
検討のプロセス
最初に検討したのは、Amazon ECS (ECS) + AWS Lambda (Lambda) + Amazon API Gateway を組み合わせて Self-hosted Runner を構築する方法でした。 スケーラブルでサーバーレスに見える魅力的な構成でしたが、実際に検証してみるといくつかの課題が見えてきました。
- GitHub API のレートリミット対応が難しい
1回の CI 実行で最大 35 並列の Runner を起動し、ピーク時には 1 時間に 60 回以上実行されるケースもあります。
これを Lambda 側で制御するのはかなり複雑で、実装コストが高くなってしまう懸念がありました。 - 起動の速さに限界がある
Runnerは「30秒以内に起動してほしい」という要件がありますが、Lambda 経由で ECS タスクを起動する構成ではコールドスタートが発生し、安定 して要件を満たすのが難しい状態でした。 - メンテナンスコストが高い
Lambda 側のコードを継続的に更新・管理する必要があり、長期運用を考えると負担が大きいと判断しました。
そこで次の候補として、Kubernetes クラスタ上で ARC を運用する方法を検討しました。
ただし Kubernetes は強力である一方、クラスタバージョンアップやノード管理といった運用コストの高さが懸念でした。
こうした背景から、最終的に採用したのが EKS Auto Mode × ARC の組み合わせです。
- EKS Auto Mode: クラスタ管理・ノード管理の運用負荷を大幅削減
- ARC: GitHub API と連携し、Runner Pod を動的にスケーリング
「Kubernetes の柔軟性を活かしながら、運用負荷を抑えて安定した Self-hosted Runner 基盤を実現できる」
そう判断し、この構成を選びました。
プロジェクト体制と期間
本プロジェクトは、プラットフォームエンジニア 1 名と壁打ち役 1 名という少人数体制で進行しました。
EKS Auto Mode では、クラスターを立ち上げるだけで主要な Add-on が自動的にセットアップされるため、そこに ARC(Actions Runner Controller)を Helm でデプロイするだけで、基本的な骨組みをすぐに構築できます。
これにより、検証と調整を素早く繰り返せる環境を整え、効率的に構築を進めることができました。
さらに、EKS Auto Mode ではノードや主要な Add-on の更新・管理を AWS 側が自動で行ってくれるため、運用設計にかける手間を大幅に減らすことができました。
その結果、短いサイクルで構築から本番導入までスムーズに完了し、検証開始から約 2 か月で安定稼働に至りました。
システムアーキテクチャー
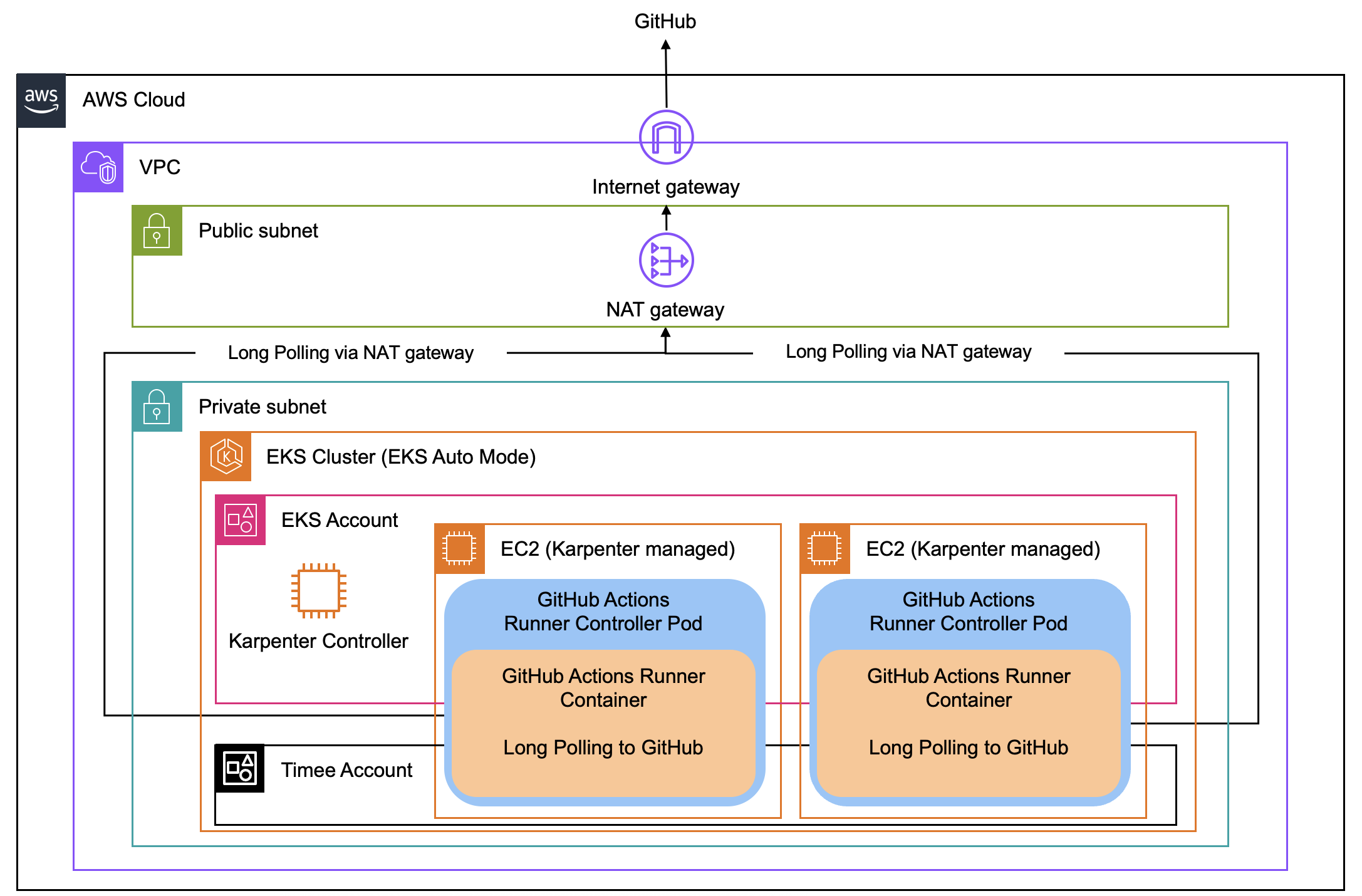
- ARC: GitHub API と連携し、必要に応じて Runner Pod を自動で起動・削除
- EKS Auto Mode: Karpenter による高速スケーリングを実現
EKS Auto Mode のおかげでノード管理の負担を大幅に軽減し、「Kubernetes を使いたいが運用コストは最小限にしたい」という要件を満たすことができました。
導入時に直面した課題と解決策
① Spot インスタンスの安定性問題
当初はコスト削減を狙って、停止率の低いインスタンスタイプの Spot インスタンス を採用していました。しかし、弊社のCIは 35 並列で高頻度に実行されるため、必要なインスタンス数が多くなり、停止確率が低いタイプでも 1 日あたり 5〜10 回ほどノードが落ちることがありました。その結果、CIが途中で失敗するケースが頻発し、開発者体験を大きく損ねる要因となってしまいました。
対策
そこで思い切って オンデマンドインスタンスに切り替え、必要に応じて Savings Plans を適用する方針にしました。
- オンデマンドにしたことで、Runnerが突然落ちるリスクがなくなり、安定して CI を回せるようになった
- 安定性が向上したことで、CIだけでなく デプロイなど他のワークフローも Self-hosted Runner に寄せる ことが可能に
- これにより EC2 のアイドル時間を減らし、稼働率を高めることでコスト効率も改善できました
② スケールインで Runner Pod が強制終了する問題
次に直面したのは「EC2 のスケールインによって、Runner Pod が CI 実行中に突然落ちる」という問題です。
原因は、Karpenter の設定でした。
デフォルトでは disruption.consolidationPolicy が WhenEmptyOrUnderutilized になっており、リソース使用率が低いと、Pod が稼働中でも容赦なくノードを落としてしまうのです。
(参考: https://karpenter.sh/docs/concepts/disruption/ )
対策
- consolidationPolicy を WhenEmpty に変更
- Podがないノードのみスケールイン対象とするよう設定
これで Runner Pod が実行中に消える問題は解消しました。
③ ノードが全然スケールインしない問題
しかし、ここで新たな課題が発生します。
それは「一度スケールアウトすると、ノードがほとんどスケールインしなくなる」という現象です。
原因は、Kubernetes のスケジューリングの仕組みにありました。Kubernetes は、Pod をできるだけ均等にノードへ分散配置しようとする特性があります。そのため、ノード上の Pod 数がバラけやすく、どのノードも完全に空になることがほとんどありません。
結果として、スケールインのトリガー条件 (=Pod が存在しないノード) がなかなか満たされず、
ノードが減らない状態が続いてしまいました。
対策
- Pod Affinity を利用し、Runner Pod はなるべく同じノードに詰めるよう設定
- Pod 配置の断片化を防ぎ、スケールインしやすくしました
これによりリソース効率が大きく改善されました。
④ 夜間にリソースを最適化する作戦
リソース効率をさらに高めるため、日中は安定性を優先し、夜間だけ段階的にノードを整理する仕組みを導入しました。
具体的には、disruption.consolidationPolicy を WhenEmptyOrUnderutilized に設定したうえで、夜間に 一定間隔で 15 分だけ pod が存在するノードのスケールインを許可 → その後は再び禁止 というサイクルを繰り返します。
これにより、ノード上にPodが残っていても一気に消されることはなく、「急に Pod が落ちて CI が止まる」といったリスクを避けながら、少しずつリソースを最適化できるようになります。
この仕組みによって、日中は安定して CI を回しつつ、夜間は少しずつノードを整理してリソースを効率的に活用できるようになりました。
導入の効果
コスト面
現時点では、GitHub-hosted Runner を利用していた頃とコストはほぼ同水準です。
しかし今後、Savings Plans の適用やリソースチューニングを進めることで、段階的なコスト削減を見込んでいます。
GitHub-hosted Runner は、利用時間に応じて課金される従量課金モデル であり、Private リポジトリ向けは 2core 固定 の課金体系になっています。
一方、Self-hosted Runner は EC2 の実行時間に基づく課金 となるため、ジョブの内容に応じて柔軟にリソースを割り当てることが可能になりました。
- CPU バウンドなジョブでは多コアを割り当てて高速化
- I/O 中心や軽量なジョブでは 1core またはそれ以下に制限
このようにリソースを使い分けることで、EC2 の起動台数を最適化し、コストを柔軟にコントロールできるようになりました。
さらに、Self-hosted Runner の課金体系は基本的に EC2 の稼働時間に依存するため、開発者数が増えても、GitHub-hosted Runner のように Runner 利用料金が比例して膨らむことがない点も大きな利点です。
パフォーマンス面
Runner イメージに事前に必要な apt パッケージなどをインストールしておくチューニングにより、CI 実行時間を 平均で約 3 分短縮 しました。
運用コスト面
EKS を利用する上で手間のかかるポイントのひとつが、ノードや Add-on のバージョン管理です。しかし、EKS Auto Mode を採用したことで、ノードと主要な Add-on のアップデートは AWS 側で自動的に管理されるようになりました。
そのため、利用者がノードの入れ替えや Add-on の更新を手動で行う必要がなく、運用負荷を大幅に削減できました。
一方で、クラスタ本体 (control plane) のバージョンアップは引き続き手動で行う必要があります。
ただし、ARC Runner (Helm) で使用している Kubernetes 関連の依存関係については、
Renovate や Dependabot により継続的に最新化しています。その結果、常に最新の API 群を利用できており、非推奨 API に依存するリスクが低減されています。これにより、クラスタ本体のバージョンアップ時にも大きな修正を伴うことが少なく、安全かつスムーズにアップグレードを進められる運用体制を実現できました。最終的には、定期的にクラスタのバージョンを上げるだけで安定稼働を維持できるようになり、ほぼ手放しで安定稼働できる運用体制を実現しており、日常的なメンテナンス工数は従来に比べて大幅に軽減されています。
今後の取り組み
Runner イメージのチューニングによって、実行時間の短縮には一定の成果を得られました。
今後は、セキュリティ強化を目的として、Self-hosted Runner のさらなる活用を検討しています。
たとえば、Terraform を用いて AWS 構成管理を行う GitHub Actions のワークフローでは、
その性質上、比較的強い IAM Role の権限を付与する必要があります。
ワークフロー内では IAM ユーザーを直接使用していないものの、一時的に発行される STS トークン(セッションクレデンシャル)によって、一定期間 AWS リソースにアクセスできる状態になります。
このような仕組みの中で、仮に悪意のあるアクションや依存ライブラリによって環境変数からクレデンシャル情報が抜き取られた場合、そのトークンを悪用して AWS リソースを破壊・改ざんされるリスクがあります。
これは、GitHub-hosted Runner 利用時における攻撃対象領域の一つとなり得ます。
Self-hosted Runner を活用することで、こうしたリスクに対してより強固なセキュリティ対策が可能です。
たとえば、Runner の送信元 IP は NAT 経由で固定されているため、Terraform 実行時に利用する IAM Role に IP 制限を付与することで、不正アクセスを防止できます。
さらに、DNS Firewall や Network Firewall を組み合わせることで、ワークフロー内から外部への不正な通信(例:環境変数を外部サーバーに送信するなど)を遮断できます。これらの対策により、ワークフロー内で利用される一時的なクレデンシャル情報の漏えいを防ぎ、よりセキュアで信頼性の高い環境を実現できると考えています。
まとめ
EKS Auto Mode × Actions Runner Controller (ARC) の導入により、タイミーでは運用負荷を抑えながら、スケーラブルで安定した Self-hosted Runner 基盤を実現しました。
EKS Auto Mode によるノード管理の自動化と、ARC・Karpenter による柔軟なスケーリングによって、高速な CI 実行と高い安定性を両立し、開発者体験も大きく向上しました。
今後は、コスト最適化やセキュリティ強化を継続的に進めるとともに、EKS Auto Mode の運用ナレッジが社内に蓄積されていけば、必要に応じてサービス基盤への適用も検討していきたいと考えています。
著者について


徳富 博 (Tokudomi Hiroshi)
株式会社タイミー
プラットフォーム エンジニアリング1G
2024年5月にタイミーへ入社。オブザーバビリティ、開発者体験やセキュリティの向上、インフラ整備、パフォーマンスチューニングなどに取り組んでいます。