Amazon Web Services ブログ
Amazon MSK Connect と Iceberg Kafka Connect でリアルタイムデータレイクを構築する
本記事は 2026 年 2 月 3 日 に公開された「Use Amazon MSK Connect and Iceberg Kafka Connect to build a real-time data lake」を翻訳したものです。
分析ワークロードでリアルタイムなインサイトが求められる中、ビジネスデータを生成直後にデータレイクへ取り込む必要性が高まっています。リアルタイム CDC データ取り込みには AWS Glue や Amazon EMR Serverless など様々な方法がありますが、Amazon MSK Connect と Iceberg Kafka Connect を組み合わせることで、フルマネージドかつシンプルなアプローチで運用の複雑さを軽減し、継続的なデータ同期を実現できます。
本記事では、Amazon Managed Streaming for Apache Kafka (Amazon MSK) Connect で Iceberg Kafka Connect を使用し、トランザクションデータベースから Apache Iceberg テーブルへの同期プロセスを簡素化しながら、データレイクへのリアルタイムデータ取り込みを高速化する方法を紹介します。
ソリューション概要
本記事では、Amazon Relational Database Service (Amazon RDS) for MySQL からトランザクションログデータをキャプチャし、append モードで Iceberg テーブル形式として Amazon Simple Storage Service (Amazon S3) に書き込む実装方法を説明します。単一テーブルと複数テーブルの同期をカバーします。

ダウンストリームのコンシューマーは、変更レコードを処理してデータ状態を再構築してから Iceberg テーブルに書き込みます。
シンク側のビジネスロジックには Iceberg Kafka Sink Connector を使用します。Iceberg Kafka Sink Connector には以下の特徴があります:
- exactly-once 配信をサポート
- 複数テーブル同期をサポート
- スキーマ変更をサポート
- Iceberg のカラムマッピング機能によるフィールド名マッピング
前提条件
デプロイを開始する前に、以下のコンポーネントを準備してください:
Amazon RDS for MySQL: Iceberg データレイクに同期したいデータを持つ Amazon RDS for MySQL データベースインスタンスが稼働していることを前提としています。Change Data Capture (CDC) 操作をサポートするため、RDS インスタンスでバイナリログが有効になっていることを確認してください。
Amazon MSK クラスター: ターゲットの AWS リージョンに Amazon MSK クラスターをプロビジョニングする必要があります。このクラスターは MySQL データベースと Iceberg データレイク間のストリーミングプラットフォームとして機能します。適切なセキュリティグループとネットワークアクセスが設定されていることを確認してください。
Amazon S3 バケット: カスタム Kafka Connect プラグインをホストする Amazon S3 バケットを準備してください。このバケットは AWS MSK Connect がプラグインを取得してインストールするストレージロケーションです。バケットはターゲットの AWS リージョンに存在し、オブジェクトをアップロードする適切な権限が必要です。
カスタム Kafka Connect プラグイン: MSK Connect でリアルタイムデータ同期を有効にするには、2 つのカスタムプラグインを作成する必要があります。1 つ目のプラグインは Debezium MySQL Connector を使用してトランザクションログを読み取り、Change Data Capture (CDC) イベントを生成します。2 つ目のプラグインは Iceberg Kafka Connect を使用して Amazon MSK から Apache Iceberg テーブルにデータを同期します。
ビルド環境: Iceberg Kafka Connect プラグインをビルドするには、Java と Gradle がインストールされたビルド環境が必要です。Amazon EC2 インスタンス (推奨: Amazon Linux 2023 または Ubuntu) を起動するか、要件を満たすローカルマシンを使用できます。十分なディスク容量 (最低 20GB) と、リポジトリのクローンおよび依存関係のダウンロードに必要なネットワーク接続を確保してください。
オープンソースから Iceberg Kafka Connect をビルドする
コネクタの ZIP アーカイブは Iceberg ビルドの一部として作成されます。以下のコードでビルドを実行できます:
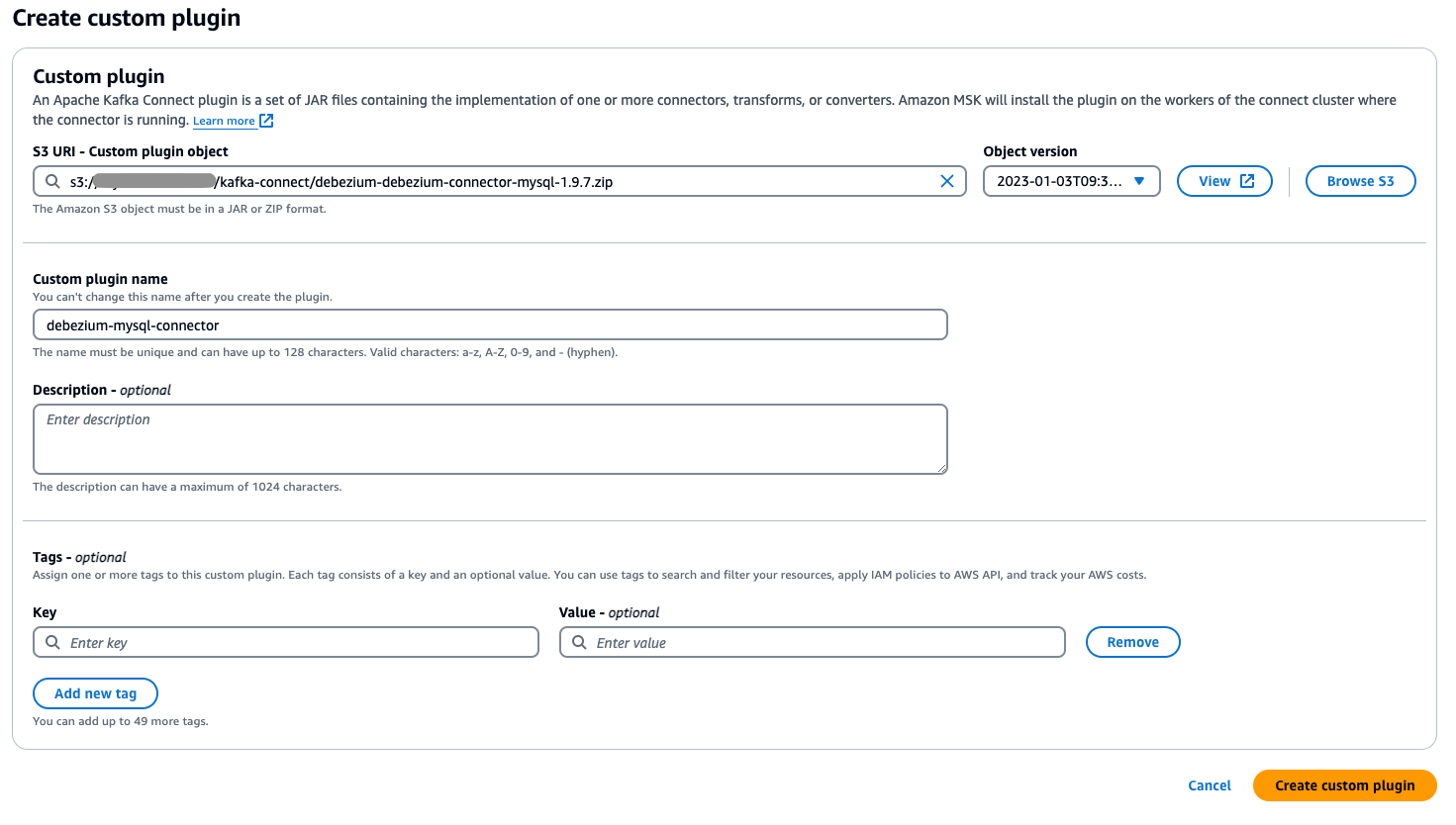
カスタムプラグインを作成する
次のステップでは、データの読み取りと同期を行うカスタムプラグインを作成します。
- 前のステップでコンパイルしたカスタムプラグイン ZIP ファイルを指定の Amazon S3 バケットにアップロードします。
- AWS マネジメントコンソールで Amazon MSK に移動し、ナビゲーションペインで Connect を選択します。
- Custom plugins を選択し、S3 にアップロードしたプラグインファイルを参照または S3 URI を入力して選択します。
- カスタムプラグインに一意でわかりやすい名前を指定します (例: my-connector-v1)。
- Create custom plugin を選択します。
MSK Connect を設定する
プラグインをインストールしたら、MSK Connect を設定する準備が整いました。
データソースアクセスを設定する
まずデータソースアクセスを設定します。
- ワーカー設定を作成するには、MSK Connect コンソールで Worker configurations を選択します。
- Create worker configuration を選択し、以下の設定をコピーして貼り付けます。
- Amazon MSK コンソールで、Amazon MSK Connect の下にある Connectors を選択し、Create connector を選択します。
- セットアップウィザードで、前のステップで作成した Debezium MySQL Connector プラグインを選択し、コネクタ名を入力して同期先の MSK クラスターを選択します。設定に以下の内容をコピーして貼り付けます:
設定では、
Routeを使用して複数のレコードを同じトピックに書き込みます。パラメータtransforms.Reroute.topic.regexでは、同じトピックに書き込むテーブル名をフィルタリングする正規表現を設定します。以下の例では、テーブル名に <tablename-prefix> を含むデータが同じトピックに書き込まれます。例えば、
transforms.Reroute.topic.replacementを$1all_recordsと指定すると、MSK に作成されるトピック名は<database.server.name>.all_recordsになります。 - Create を選択すると、MSK Connect が同期タスクを作成します。
データ同期 (単一テーブルモード)
Iceberg テーブルのリアルタイム同期タスクを作成できます。まず単一テーブルのリアルタイム同期ジョブを作成します。
- Amazon MSK コンソールで、MSK Connect の下にある Connectors を選択します。
- Create connector を選択します。
- 次のページで、前に作成した Iceberg Kafka Connect プラグインを選択します。
- コネクタ名を入力し、同期先の MSK クラスターを選択します。
- 設定に以下のコードを貼り付けます。
Iceberg Connector は、デフォルトで
control-icebergという名前のトピックを作成してオフセットを記録します。topic.creation.enable = trueを含む前に作成したワーカー設定を選択してください。デフォルトのワーカー設定を使用し、MSK ブローカーレベルで自動トピック作成が有効になっていない場合、コネクタはトピックを自動作成できません。パラメータ
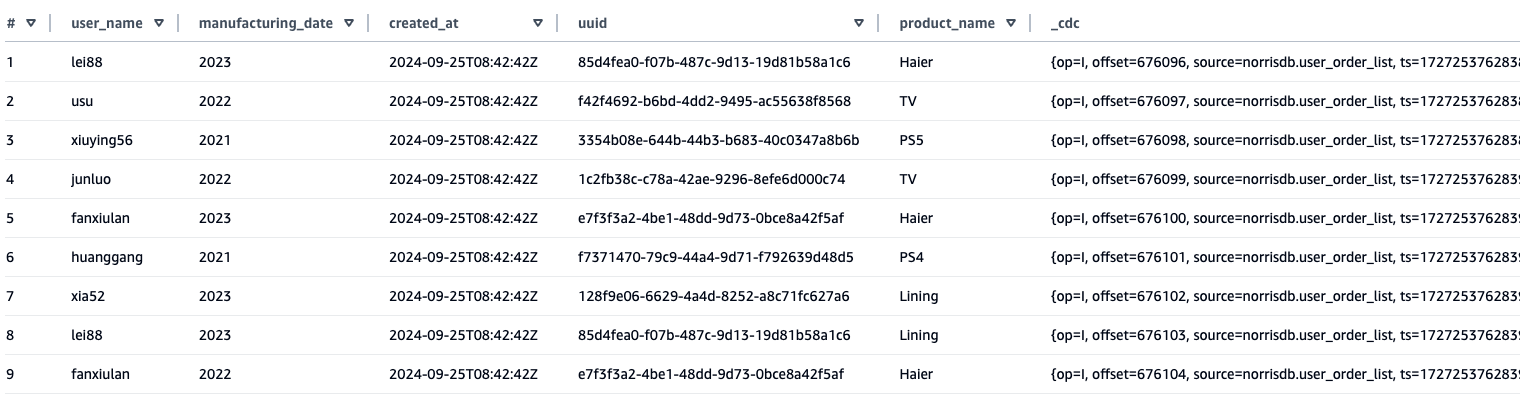
iceberg.control.topic = <offset-topic>を設定してトピック名を指定することもできます。カスタムトピックを使用する場合は、以下のコードを使用できます。 - Amazon Athena で同期されたデータ結果をクエリします。Athena に同期されたテーブルから、ソーステーブルのフィールドに加えて、CDC のメタデータ内容を格納する
_cdcフィールドが追加されていることがわかります。
コンパクション
コンパクションは Iceberg テーブルに不可欠なメンテナンス操作です。小さなファイルを頻繁に取り込むとクエリパフォーマンスに悪影響を与えますが、定期的なコンパクションで小さなファイルを統合し、メタデータの負荷を抑え、クエリ効率を大幅に向上できます。最適なテーブルパフォーマンスを維持するには、専用のコンパクションワークフローを実装する必要があります。AWS Glue は最適なソリューションを提供し、小さなファイルを適切にマージしてテーブルレイアウトを再構築する自動コンパクション機能を備えています。
スキーマ進化のデモ
スキーマ進化機能を示すため、ソースデータベースでのフィールド変更が MSK Connect と Iceberg Kafka Connect を通じて Iceberg テーブルに自動的に同期される様子をテストしました。
初期セットアップ:
まず、以下のスキーマを持つ顧客情報テーブル (tb_customer_info) を含む RDS MySQL データベースを作成しました:
次に、Debezium MySQL Connector を使用して MSK Connect を設定し、このテーブルからの変更をキャプチャして Amazon MSK にリアルタイムでストリーミングしました。その後、Iceberg Kafka Connect を設定して MSK からデータを消費し、Iceberg テーブルに書き込みました。
スキーマ変更テスト:
スキーマ進化機能をテストするため、ソーステーブルに phone という新しいフィールドを追加しました:
次に、phone フィールドを含む新しいレコードを挿入しました:
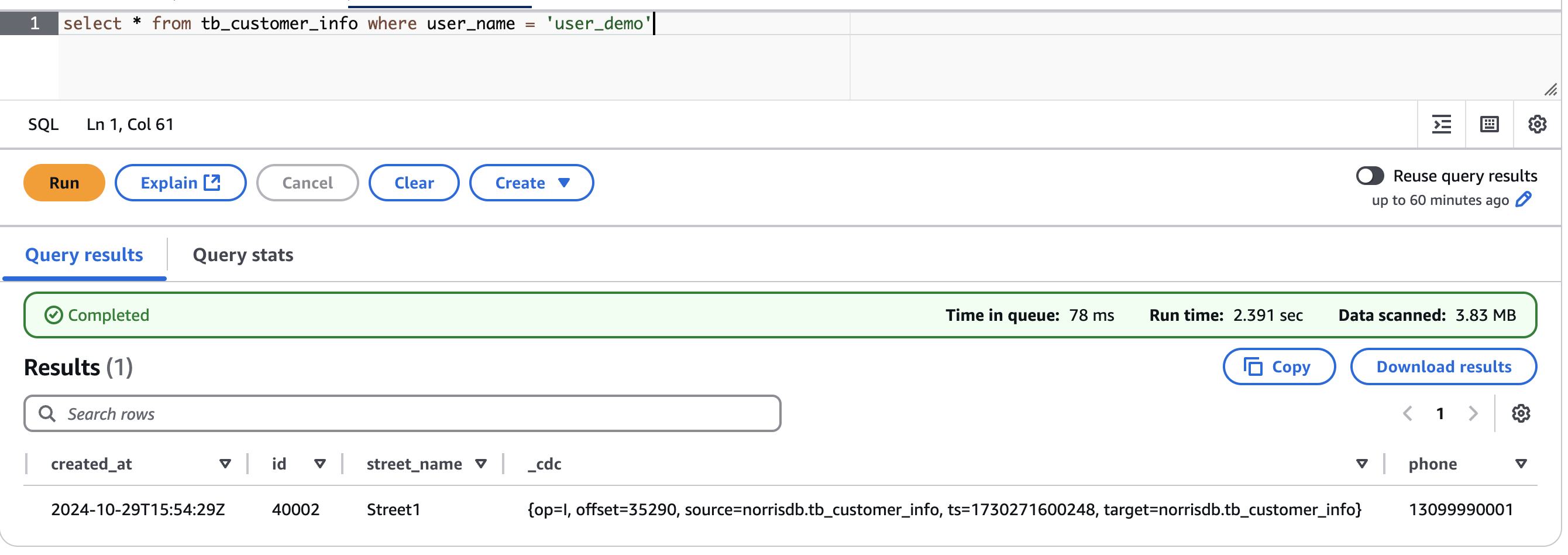
結果:
Amazon Athena で Iceberg テーブルをクエリすると、phone フィールドが最後のカラムとして自動的に追加され、新しいレコードがすべてのフィールド値を含めて正常に同期されていることが確認できました。Iceberg Kafka Connect の自己適応スキーマ機能により、ソースでの DDL 変更がシームレスに処理され、データレイクでの手動スキーマ更新が不要になることが実証されました。
データ同期 (複数テーブルモード)
データ管理者が単一のコネクタで複数テーブルのデータを移動したいケースはよくあります。例えば、CDC 収集ツールを使用して複数テーブルのデータを 1 つのトピックに書き込み、コンシューマー側で 1 つのトピックから複数の Iceberg テーブルにデータを書き込むことができます。「データソースアクセスを設定する」セクションでは、Route を使用して指定ルールに従ったテーブルをトピックに同期する MySQL 同期 Connector を設定しました。ここでは、このトピックから複数の Iceberg テーブルにデータを分配する方法を確認します。
- AWS Glue Data Catalog を使用して Iceberg Kafka Connect で複数テーブルを Iceberg テーブルに同期する場合、同期プロセスを開始する前に Data Catalog にデータベースを事前作成する必要があります。AWS Glue のデータベース名はソースデータベース名と完全に一致する必要があります。Iceberg Kafka Connect コネクタは複数テーブル同期時にソースデータベース名をターゲットデータベース名として自動的に使用するためです。コネクタには複数テーブルシナリオでソースデータベース名を異なるターゲットデータベース名にマッピングするオプションがないため、この命名の一貫性が必要です。
- カスタムトピック名を使用する場合は、MSK Connect レコードオフセットを格納する新しいトピックを作成できます。データ同期 (単一テーブルモード) を参照してください。
- Amazon MSK コンソールで、以下の設定を使用して別のコネクタを作成します。
この設定では、2 つのパラメータが追加されています:
iceberg.tables.route-field: 異なるテーブルを区別するルーティングフィールドを指定します。Debezium でパースされた CDC データの場合はcdc.sourceと指定します。iceberg.tables.dynamic-enabled:iceberg.tablesパラメータが設定されていない場合、ここでtrueを指定する必要があります。
- 完了後、MSK Connect がシンクコネクタを作成します。
- プロセス完了後、Athena で新しく作成されたテーブルを確認できます。
その他のヒント
ここでは、ユースケースに合わせてデプロイをカスタマイズするためのヒントを紹介します。
- 指定テーブルの同期「データ同期 (複数テーブルモード)」セクションでは、
iceberg.tables.route-field = _cdc.Sourceとiceberg.tables.dynamic-enabled=trueを指定しました。この 2 つのパラメータで、複数テーブルを Iceberg テーブルに書き込めます。指定したテーブルのみを同期する場合は、iceberg.tables.dynamic-enabled = falseを設定し、iceberg.tablesパラメータで同期するテーブル名を指定します。例: - パフォーマンステスト結果
データ同期機能を評価するため、sysbench を使用してパフォーマンステストを実施しました。テストでは、システムのスループットとスケーラビリティを示すために大量書き込みシナリオをシミュレートしました。テスト設定:- データベースセットアップ: sysbench を使用して MySQL データベースに 25 テーブルを作成
- データロード: 各テーブルに 2,000 万レコードを書き込み (合計 5 億レコード)
- リアルタイムストリーミング: 書き込みプロセス中に MySQL から Amazon MSK にリアルタイムでデータをストリーミングするよう MSK Connect を設定
- Kafka Connect 設定:
- Kafka Iceberg Connect を起動
- 最小ワーカー数: 1
- 最大ワーカー数: 8
- ワーカーあたり 2 MCU を割り当て
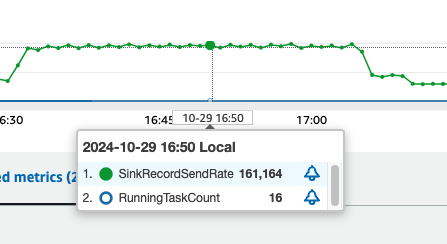
パフォーマンス結果:
上記の設定でテストした結果、各 MCU が約 10,000 レコード/秒のピーク書き込みパフォーマンスを達成しました。高スループットのデータ同期ワークロードを効果的に処理できることが実証されました。
クリーンアップ
リソースをクリーンアップするには、以下の手順を実行します:
- MSK Connect コネクタを削除: このソリューション用に作成した Debezium MySQL Connector と Iceberg Kafka Connect コネクタの両方を削除します。
- Amazon MSK クラスターを削除: このデモ用に新しい MSK クラスターを作成した場合は、課金を停止するために削除します。
- S3 バケットを削除: カスタム Kafka Connect プラグインと Iceberg テーブルデータの保存に使用した S3 バケットを削除します。削除前に必要なデータをバックアップしてください。
- EC2 インスタンスを削除: Iceberg Kafka Connect プラグインをビルドするために EC2 インスタンスを起動した場合は、終了します。
- RDS MySQL インスタンスを削除 (オプション): このデモ用に新しい RDS インスタンスを作成した場合は削除します。既存の本番データベースを使用している場合は、このステップをスキップしてください。
- IAM ロールとポリシーを削除 (作成した場合): セキュリティのベストプラクティスを維持するため、このソリューション用に作成した IAM ロールとポリシーを削除します。
まとめ
本記事では、Amazon MSK Connect と Iceberg Kafka Connect を使用して、トランザクションデータベースからデータレイクへのリアルタイムで効率的なデータ同期を実現するソリューションを紹介しました。エンタープライズレベルのビッグデータ分析に低コストで効率的なデータ同期パラダイムを提供します。EC トランザクション、金融取引、IoT デバイスログなど、どのようなデータを扱う場合でも、データレイクへの迅速なアクセスを実現し、分析ビジネスが最新のビジネスデータを素早く取得できるようになります。ぜひご自身の環境でお試しいただき、コメントセクションで体験を共有してください。詳細については、Amazon MSK Connect をご覧ください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。