- AWS Builder Center›
- builders.flash
データを集めて、整えて、分析しよう ! AWS の ETL サービスをグラレコで解説
2025-03-03 | Author : 米倉 裕基 監修 : 大薗 純平、佐藤 悠、久保 和隆
はじめに
builders.flash の読者のみなさん、こんにちは ! テクニカルライターの米倉裕基と申します。
近年、企業が扱うデータの量と種類は急速に増加しています。社内の基幹システムや顧客管理システム、ウェブサイトのアクセスログ、IoT デバイスからのセンサーデータなど、多種多様なデータソースから構造化および非構造化のデータが生成され続けています。これらの異なるソースからデータを効率的に収集し、分析に適した形に加工し、適切な場所に格納するというプロセスが ETL (Extract、Transform、Load) です。
AWS は、この ETL プロセスを効率的に実行するための多様なサービスを提供しています。本記事では、AWS が提供する ETL サービスの使い分けについて紹介します。各サービスの主要な機能と特徴を説明し、データの規模や処理の複雑さに応じた最適なソリューションの選び方を探っていきます。
-
ETL パイプラインの概要
-
AWS が提供する ETL サービス
-
ETL サービス選択の基準
-
構成例 1 - シンプルなサーバーレス構成
-
構成例 2 - AWS Glue を中心とした構成
-
構成例 3 - Amazon EMR と Amazon Managed Workflows for Apache Airflow (MWAA) を活用した大規模構成
-
モニタリングとリトライロジック
-
Amazon SageMaker Unified Studio を使った ETL 構築
それでは、項目ごとに詳しく見ていきましょう。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
ETL パイプラインの概要
ETL パイプラインは、データ駆動型のビジネスにおいて不可欠な要素となっています。多様なデータソースから大量のデータを効率的に収集し、分析に適した形に加工し、適切な場所に格納することで、企業はデータを根拠とした意思決定を行い、競争力を維持するための基盤を構築できます。
ETL とは
ETL パイプラインは、データ駆動型のビジネスにおいて不可欠な要素となっています。多様なデータソースから大量のデータを効率的に収集し、分析に適した形に加工し、適切な場所に格納することで、企業はデータを根拠とした意思決定を行い、競争力を維持するための基盤を構築できます。
データの価値が広く認識されるようになってから久しいですが、様々なシステムに散在する膨大なデータから、意味のある洞察 (インサイト) を得ることは容易ではありません。
例えば、小売企業のマーケティング部門が新商品企画のために顧客購買傾向を分析する場合、POS システム、顧客管理システム、ウェブサイトのアクセスログなど、複数のソースからのデータが必要になります。
しかし、これらのデータは形式や更新頻度が異なるため、単純な収集では効果的な分析が難しい場合があります。
そこで ETL (Extract、 Transform、Load) プロセスの必要性が浮かび上がります。ETL プロセスを導入することで、異なるシステムからデータを抽出し、統一された形式に変換し、分析用のデータベースに格納することで、横断的な分析が可能になります。
このような ETL のプロセスを踏むことで、膨大なデータの中から新商品企画などに有効な貴重なインサイトを得ることができます。
ETL プロセスは散在するデータを有意義な情報に変換し、データ駆動型の意思決定を支援する重要な役割を果たします。
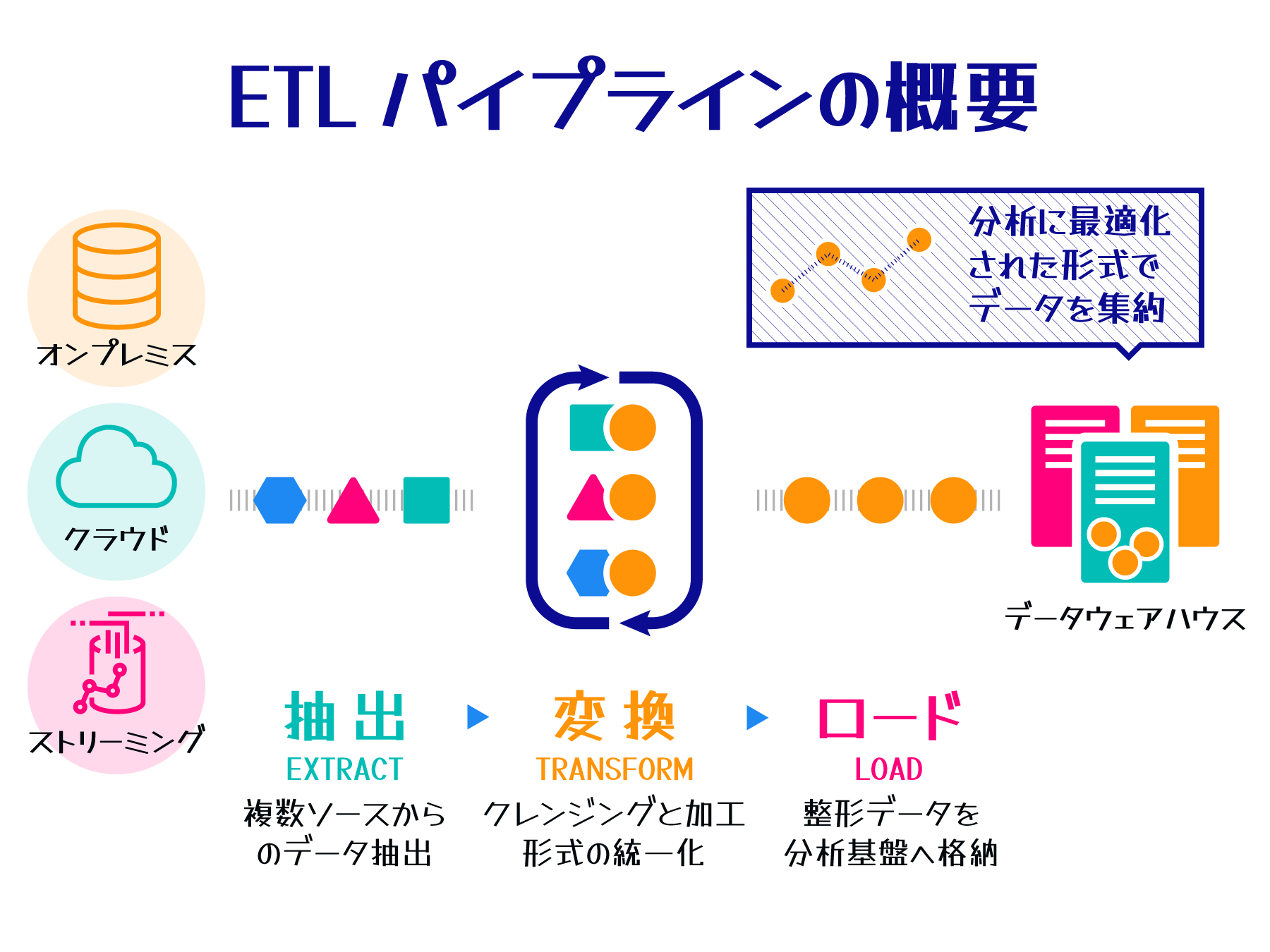
ETL の 3 つのステップ
ETL は、データ統合の中心となるプロセスです。ETL は以下の 3 つのステップから構成されます。
|
ステップ |
目的 |
説明 |
|
Extract (抽出) |
データの収集 |
データベース、ファイル、API など、様々な形式のデータソースから必要な情報を抽出する。 |
|
Transform (変換) |
データの整形 |
抽出したデータを目的に合わせて加工する。データのクレンジング、フォーマット変更、結合、集計などの処理を行い、分析や報告に適した形に整える。 |
|
Load (ロード) |
データの保存 |
変換したデータを目的のシステムに格納する。データウェアハウスやデータストアなど、分析や意思決定に利用しやすい形でデータを保存する。 |
この 3 ステップにより、異なるシステムのデータを統一された形式で分析に役立てることが可能になります。
ETL プロセスで得られるメリット
ETL プロセスを導入することで得られる主な利点は以下のようなものがあります。
-
データの一元化:散在するデータを 1 箇所に集約することで、包括的な分析が可能になります。
-
データ品質の向上:データのクレンジングや標準化を行うことで、高品質なデータセットを作成できます。
-
効率的な分析:適切に構造化されたデータにより、迅速かつ効率的な分析が実現できます。
-
コンプライアンスとガバナンス:データの流れを管理し、必要に応じて監査が行えるようになります。
-
自動化によるコスト削減:定期的なデータ処理を自動化することで、人的リソースとコストを削減できます。
-
意思決定の迅速化:最新の統合されたデータに基づいて、より迅速かつ正確な意思決定が可能になります。
これらのメリットにより、ETL プロセスは組織のデータ活用能力を向上させ、ビジネスの効率性と競争力強化に貢献します。適切に実装された ETL パイプラインは、データ駆動型の意思決定を促進させることができます。
その他、ETL について詳しくは、「ETL (抽出、変換、ロード) とは何ですか?」をご覧ください。
AWS が提供する ETL サービス
ETL プロセスは、主に「ワークフロー制御」と「ジョブ実行」という 2 つの要素から構成されます。
- ワークフロー制御:ETL プロセス全体の流れを管理します。各タスクの実行順序の決定、タスク間の依存関係の管理、エラー発生時の対処などを担当します。
- ジョブ実行:ETL の中核となる実際のデータ処理を行います。データソースからのデータ抽出、データのクレンジングや変換、そして最終的なデータストアへのロードが含まれます。
ワークフロー制御には、ETL 特化の AWS Glue、複雑なワークフロー管理に適した Amazon Amazon Managed Workflows for Apache Airflow (MWAA)、汎用的な AWS Step Functions が利用できます。
ジョブ実行については、タスクの規模や実装方法に応じて AWS Lambda、Amazon EMR、Amazon Redshift など、適切なサービスを選択します。これらのサービスを組み合わせることで、効率的な ETL プロセスを構築できます。
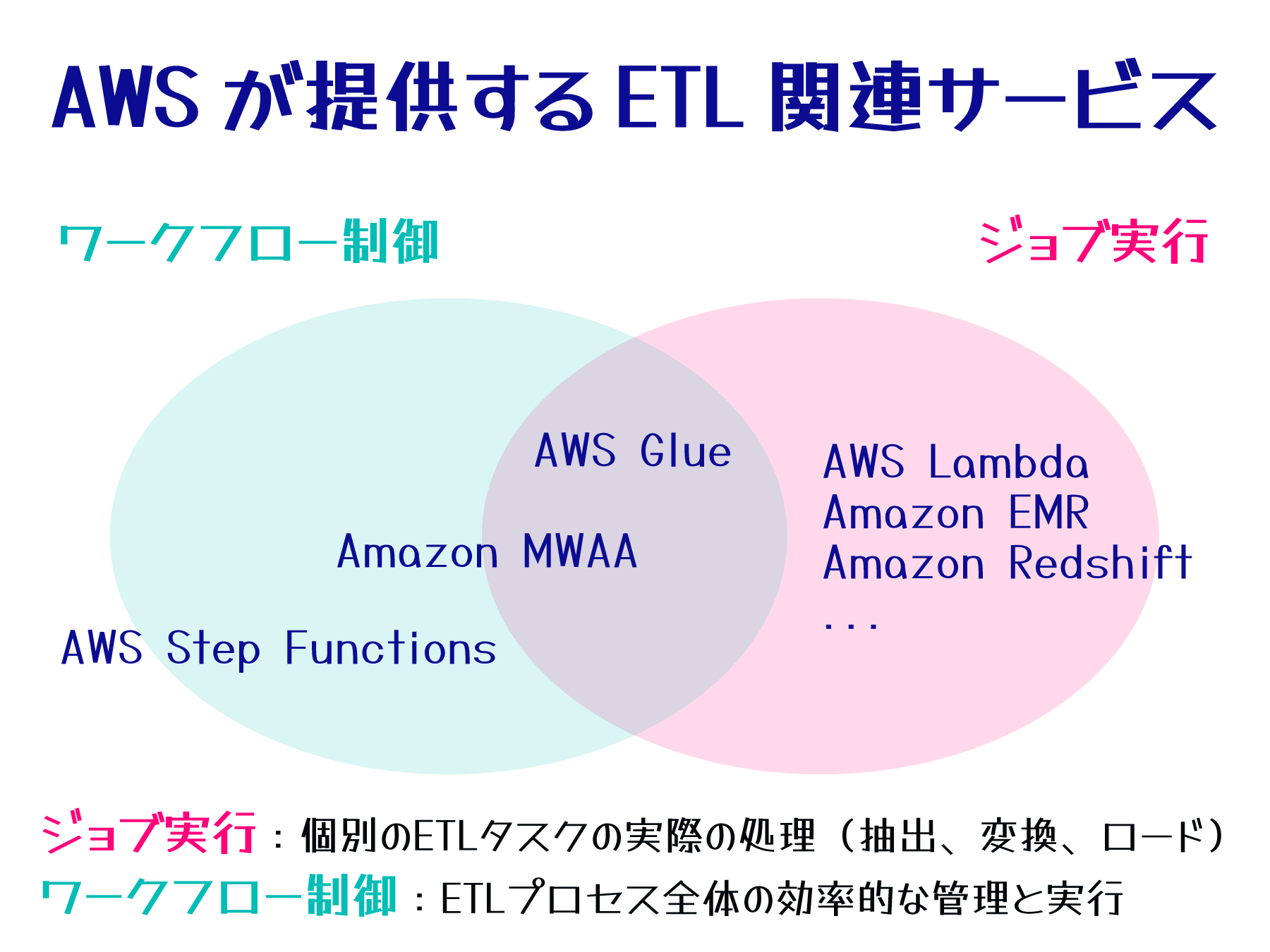
ETL で利用できる AWS サービス
以下は、ETL プロセスの構築に利用できる AWS サービスの一部です。特にジョブ実行には、多くの AWS サービスが利用可能で、ニーズに応じてこれらのサービスをブロックのように自由に組み合わせることができます。
サービス ワークフロー制御 ジョブ実行 備考 AWS Glue ⚪︎ ⚪︎ ETL に特化したフルマネージドサービス。ETL プロセスに必要な様々な機能を提供する関連サービス群の総称 Amazon MWAA ⚪︎ ⚪︎ (MWAA のワーカーで実行) Apache Airflow ベースのワークフロー管理。ジョブ実行は基本的には他サービスに委譲するが、ワーカーで軽微な処理であれば実施可能 AWS Step Functions ⚪︎ - ETL に限らない汎用的なワークフロー制御。ジョブ実行は他サービスに委譲 AWS Lambda - ⚪︎ サーバーレスのデータ変換処理 Amazon EMR - ⚪︎ ビッグデータ向けの分散処理 Amazon Redshift - ⚪︎ データウェアハウスへのロードワークフロー制御とジョブ実行の連携の流れ
ワークフロー制御とジョブ実行は密接に連携して、効率的な ETL プロセスを実現します。以下は、典型的な連携の流れです。
-
ワークフロー開始:[ワークフロー制御]
Step Functions や Glue Workflows などのワークフロー制御サービスが全体のプロセスを開始します。 -
データ抽出:[ジョブ実行]
ワークフロー制御サービスの指示に基づき、Glue や AWS Lambda がソースシステムからデータを抽出します。 -
データ変換:[ジョブ実行]
抽出されたデータに対し、Glue、EMR、Lambda などのサービスがクレンジング、集約、変換処理を実行します。 -
データロード:[ジョブ実行]
変換されたデータを、Glue や Redshift を使用してターゲットシステムにロードします。 -
エラーハンドリング:[ワークフロー制御]
各ステップでエラーが発生した場合、ワークフロー制御サービスが検知し、必要に応じて再試行や代替フローを実行します。 -
ワークフロー終了:[ワークフロー制御]
ワークフロー制御サービスがプロセス全体を終了し、AWS CloudTrail や Amazon CloudWatch で実行履歴とメトリクスを記録します。
このように自由度の高いサービス群から、ワークフロー制御とジョブ実行を組み合わせて ETL プロセス全体を構成することができます。多様な AWS サービスの中から最適なサービス群を選択するには、プロジェクトの目的やユースケースに応じて適切なものを選別する必要があります。
次の「ETL サービス選択の基準」では、ETL サービス選択の際に検討すべき代表的な観点について紹介します。
ETL サービス選択の基準
AWS は多様な ETL 関連サービスを提供していますが、ワークロードに最適なサービスを選択するには、様々な条件を検討する必要があります。
ここでは、ETL サービス選択の主な基準として以下 6 つの観点を紹介します。
これらの扱うデータ量や処理の複雑さ、開発体制など、プロジェクトの特性に合わせて最適な ETL サービスを選択します。
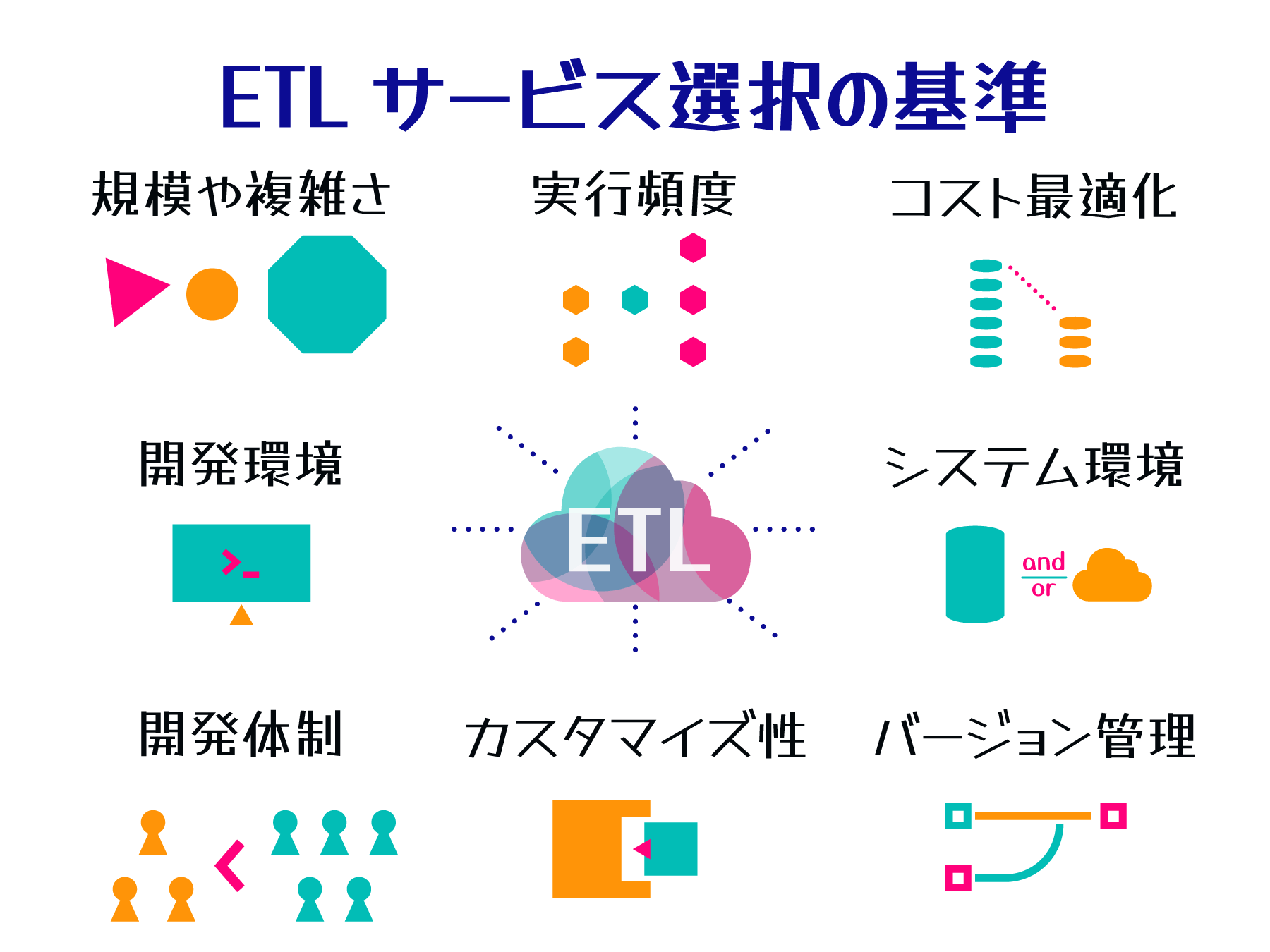
ETL サービス選択の主な基準
ETL サービス選択の主な基準
- 軽量タスク: AWS Lambda、 AWS Glue Python Shell
短時間で完了する単純な処理に適し、コスト効率が高い。 - 大規模タスク: Amazon EMR、 AWS Glue Spark Job
大量データの処理や複雑な分析に適し、高いパフォーマンスを発揮。
データ量と処理の複雑さに応じてサービスを選択します。
- 低頻度: AWS Lambda、 AWS Glue
使用時のみ課金されるため、コスト効率が高い。 - 高頻度: Amazon EMR
常時稼働型で一貫したパフォーマンスを維持。
ジョブの実行パターンに応じてコストとパフォーマンスのバランスを取ります。
- Python: Amazon MWAA、 AWS Glue
データサイエンティストや開発者に馴染みやすく、豊富なライブラリを活用可能。 - SQL: Amazon EMR、 Amazon Athena、 Amazon Redshift
データアナリストや BI 専門家にとって直感的で、既存の SQL スキルを活用可能。
開発チームの専門性や既存システムとの整合性を考慮します。
- GUI / ビルトイン機能: AWS Glue Studio
迅速な開発が可能だが、高度なカスタマイズには制限あり。 - コーディング: AWS Glue ETL ジョブ、 Amazon EMR with custom scripts
柔軟で高度なカスタマイズが可能だが、開発に時間とスキルが必要。
プロジェクトの要件の複雑さと開発速度のトレードオフを考慮します。
- 少人数・アジリティ重視: AWS Lambda、 AWS Glue
インフラ管理の負担を減らし、迅速な開発とデプロイが可能。 - 大規模・堅牢性重視: Amazon EMR
細かな設定やスケーリングの制御が可能で、複雑なワークフローに対応。
チーム規模と開発スピードに応じて選択します。
- 管理コスト低減: AWS Glue
フルマネージドサービスで、Spark クラスタの管理やチューニングの負担を軽減。 - 長期的なコスト最適化: Amazon EMR、 Amazon EC2
Amazon EMR は、基盤となる EC2 インスタンスに対して、リザーブドインスタンスや Savings Plans を活用することで、長期的なコスト削減が可能。
初期コスト、運用コスト、スケーラビリティを総合的に評価します。
その他のサービス選定において考慮すべき要素
これらに加えて、システム環境 (AWS のみか、ハイブリッドクラウドか) や、複製/再利用性、バージョン管理の必要性などもサービス選定において考慮すべき要素になります。複数の検討要素を総合的に評価し、現在のニーズだけでなく将来の拡張性も見据えながら、最適な ETL 構成を選択します。
主な構成例
次のセクションからは、実際に AWS の各種サービスを利用した 3 つの ETL プロセスの具体的な構成例を紹介します。
-
構成例 1 - シンプルなサーバーレス構成:
小規模から中規模のデータ処理に適した、運用負荷の低い構成 -
構成例 2 - AWS Glue を中心にした構成:
多様なデータソースとカタログ管理が必要な場合に効果的な構成 -
構成例 3 - Amazon EMR と Amazon Managed Workflows for Apache Airflow (MWAA) を活用した大規模構成:
大規模データセットや複雑な処理要件に対応する高度な構成
各構成で利用する主要なサービス群や、特徴、ワークフローもあわせて説明します。
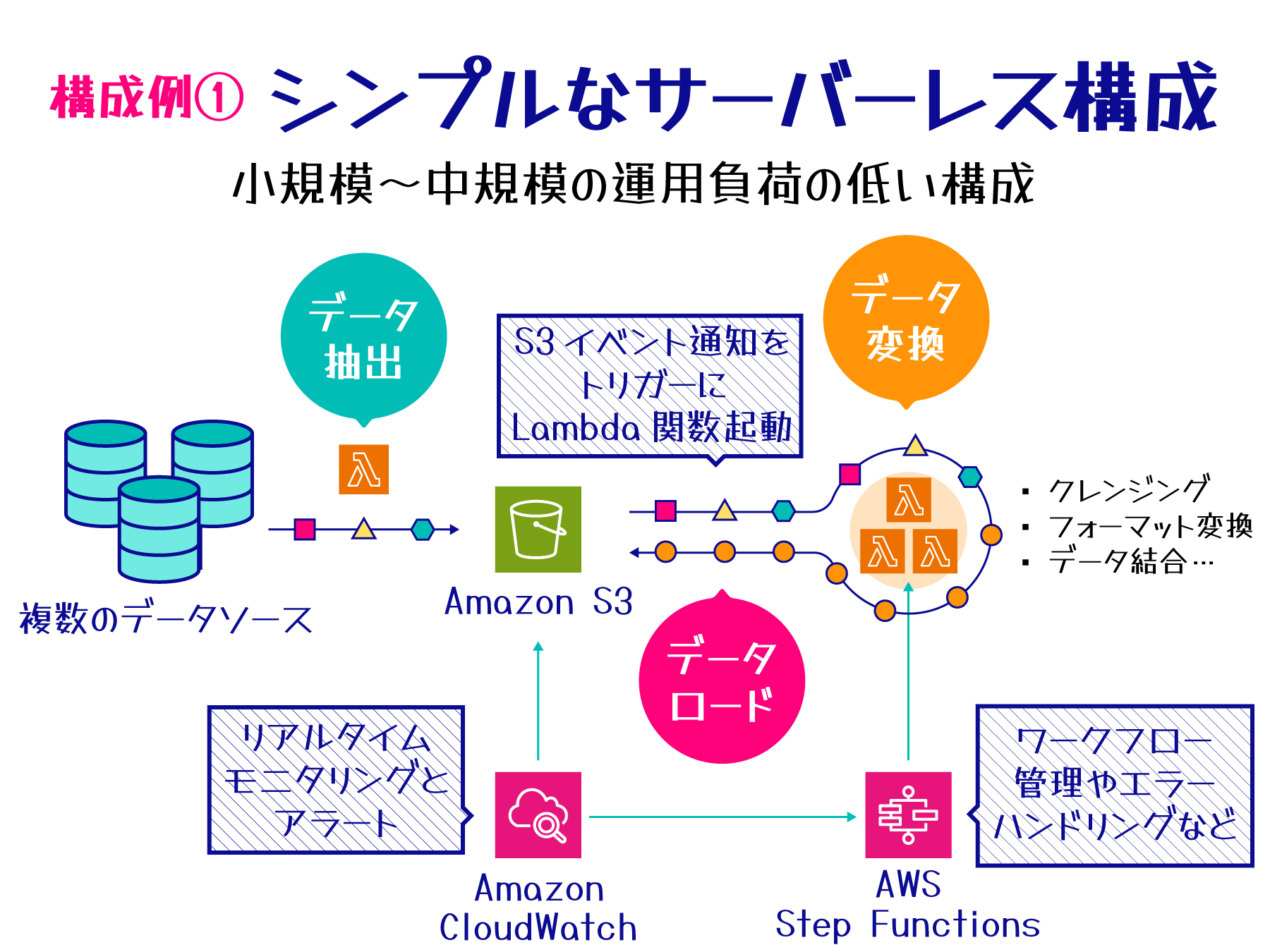
構成例 1 - シンプルなサーバーレス構成
AWS のサーバーレスサービスを活用することで、専用の ETL サービスを使用せずともシンプルで効率的なデータ処理パイプラインを構築できます。この構成では、AWS Step Functions や AWS Lambda などを組み合わせ、柔軟性の高い ETL プロセスを実現します。
小規模から中規模のデータ処理や定期的なバッチジョブの実行に適しており、クラウドネイティブな環境での運用を目指す場合に効果的です。サーバーレス構成のため、インフラストラクチャの管理が不要で、需要に応じて自動的にスケールする柔軟性を備えています。
主要コンポーネント
この構成では、以下の AWS サービスを組み合わせて ETL プロセスを実現します。各サービスの役割と、それぞれの主な特徴や利点は以下の表のとおりです。
|
機能 |
使用するサービス |
役割と特徴 |
|
データ抽出/データ処理 |
様々なソースからのデータ収集。サーバーレスでのデータ変換、フィルタリング、集計。S3 イベント通知をトリガーとして実行 |
|
|
データストア |
高い耐久性と可用性を持つオブジェクトストレージ。入力データと処理結果の保存に使用 |
|
|
ワークフロー制御 |
複雑なワークフローの視覚化と管理。複数の Lambda 関数の連携、条件分岐、エラーハンドリングの実装 |
|
|
モニタリング |
ログとメトリクスの監視、パフォーマンス追跡、アラート設定 |
特徴と利点
この構成は完全サーバーレスで使用量に応じた課金モデルを採用し、最小限の管理で運用可能です。
Amazon S3 の高い耐久性と可用性、AWS Lambda の自動スケーリング機能、そして AWS Step Functions による視覚的なワークフロー管理により、安全なデータ保管と柔軟な処理能力の調整、複雑な ETL プロセスの容易な設計と管理を実現します。
ETL ワークフロー
この構成は完全サーバーレスで使用量に応じた課金モデルを採用し、最小限の管理で運用可能です。
Amazon S3 の高い耐久性と可用性、AWS Lambda の自動スケーリング機能、そして AWS Step Functions による視覚的なワークフロー管理により、安全なデータ保管と柔軟な処理能力の調整、複雑な ETL プロセスの容易な設計と管理を実現します。
この構成では、ETL プロセスは以下の流れで実行されます。
-
データ抽出:
Lambda を使用して様々なソースからデータを抽出し、S3 に格納。 -
データ処理:
S3 イベント通知をトリガーとし、Lambda でデータのクレンジング、変換、結合などを実行。 -
ワークフロー管理:
Step Functions で複数の Lambda 関数を連携させ、複雑なワークフローを視覚的に管理。 -
結果の保存:
処理結果を S3 の別バケットやプレフィックスに保存。 -
モニタリング:
Amazon CloudWatch で各コンポーネントのログとメトリクスを監視し、アラート設定や分析を実施。
この構成のように、AWS Glue などの統合的な ETL 専用のサービスを使わなくても、AWS の基本的なサービスを組み合わせることでシンプルな ETL プロセスを実現できます。Amazon CloudWatch を使用したモニタリングにより、パフォーマンスの追跡やログ分析も効果的に行えるため、システムの健全性と効率性を常に把握し、必要に応じて最適化を行うことができます。
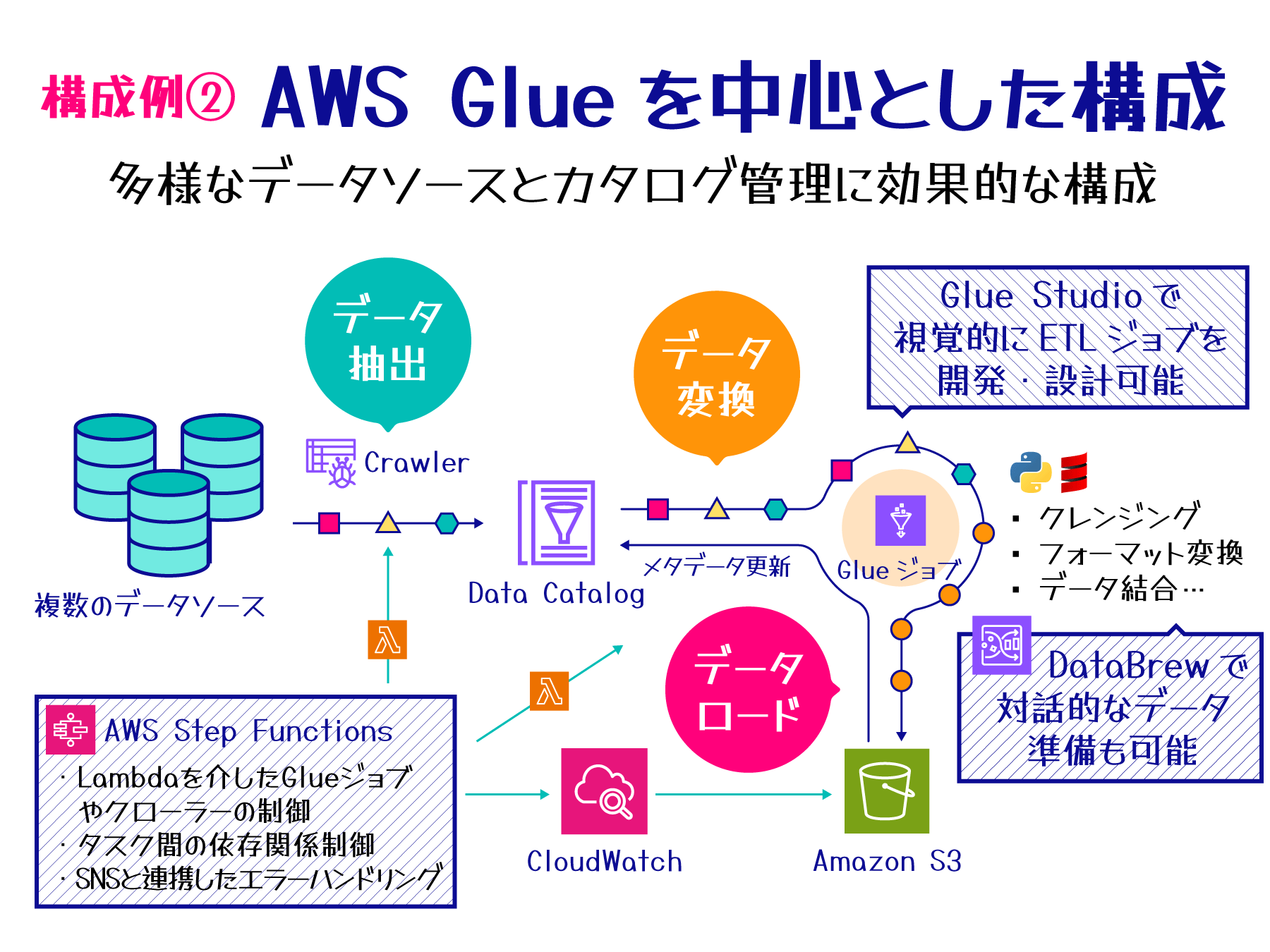
構成例 2 - AWS Glue を中心とした構成
この構成は、AWS Glue のサーバーレス ETL 機能を中心に据え、ワークフロー制御に AWS Step Functions を活用します。データカタログ管理と柔軟なデータ処理を実現し、中規模から大規模のデータ処理や多様なデータソースを扱う場合に適しています。
主要コンポーネント
この構成では、AWS Glue を中心に以下のサービスを組み合わせて ETL プロセスを構築します。
|
機能 |
使用するサービス |
役割と特徴 |
|
ETL 処理 |
サーバーレス ETL サービス、自動スケーリングとジョブのオーケストレーション |
|
|
データカタログ |
メタデータの一元管理、データディスカバリーの効率化 |
|
|
データ抽出 |
データソースの自動スキャンとメタデータ抽出 |
|
|
データ処理 |
対話的なデータ準備と可視化 |
|
|
データストア |
高い耐久性と可用性を持つオブジェクトストレージ。入力データと処理結果の保存に使用 |
|
|
ワークフロー管理 |
ETL プロセス全体の制御とオーケストレーション |
|
|
モニタリング |
ログとメトリクスの監視、パフォーマンス追跡、アラート設定 |
特徴と利点
AWS Glue を中心としたこの構成は、サーバーレスアーキテクチャによる運用負荷の軽減とデータカタログによるメタデータの一元管理が特徴です。自動スケーリングによる柔軟な処理能力の調整、データディスカバリーと分析の効率化、開発の容易さと迅速な導入、多様なデータソースとの統合が容易に実現できます。また、AWS Step Functions によるワークフロー管理により、複雑な ETL プロセスの可視化と制御が可能になります。
ETL ワークフロー
この構成では、ETL プロセスは以下の流れで実行されます。
-
データ抽出:
Glue Crawler を起動し、データソースからメタデータを検出して Data Catalog に登録。 -
データ処理:
Glue ETL ジョブで Spark ベースの分散処理を実行。 -
ワークフロー管理:
Step Functions で全体のワークフローを管理。Lambda 関数を介して Glue ジョブやクローラーを制御し、エラーハンドリングや条件分岐を設定。 -
結果の保存:
処理済みデータを Amazon S3 に保存し、必要に応じて Lambda 関数を使用して Data Catalog のメタデータを更新。 -
モニタリング:
Amazon CloudWatch で Step Functions の実行状況、Glue ジョブのパフォーマンス、カスタムメトリクスを監視。
この構成は、AWS Glue の ETL 機能を中心に据えつつ、AWS Step Functions でワークフローを制御することで、柔軟で管理しやすいデータ処理パイプラインを実現します。データカタログによるメタデータ管理、サーバーレスアーキテクチャによる運用負荷の軽減、そして AWS Step Functions による複雑なワークフローの管理が可能となり、データレイクの構築や大規模なデータ統合プロジェクトに適しています。
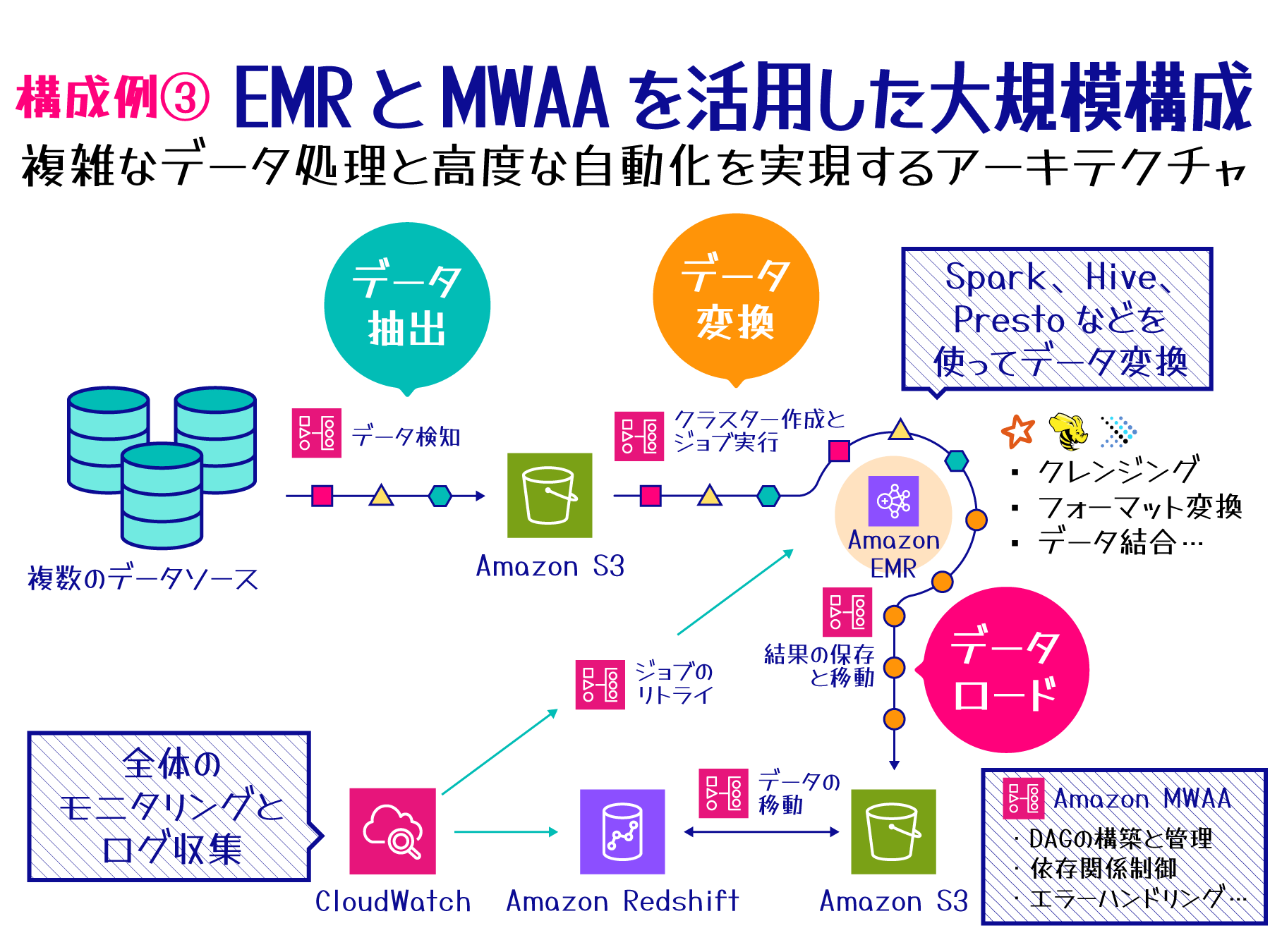
構成例 3 - Amazon EMR と Amazon Managed Workflows for Apache Airflow (MWAA) を活用した大規模構成
この構成は、AWS の様々なマネージドサービスを組み合わせることで、大規模かつ複雑な ETL プロセスを実現します。高度なカスタマイズが必要な場合や、機械学習のための特徴量エンジニアリングなど、より複雑なデータ処理要件がある場合に適しています。
主要コンポーネント
以下の AWS サービスを組み合わせて、柔軟で拡張性の高い ETL プロセスを構築します。
|
機能 |
使用するサービス |
役割と特徴 |
|
ワークフロー管理/データ抽出 |
Apache Airflow ベースのワークフロー管理、複雑な DAG の構築と管理。様々なソースからのデータ抽出を Airflow オペレーターで自動化 |
|
|
データ処理 |
大規模分散処理フレームワーク、Hadoop、Spark、Hive 等のサポート |
|
|
データストア |
データレイクとしての利用、高い耐久性と可用性 |
|
|
大規模データの高速処理、SQL ベースの分析が可能 |
||
|
モニタリング |
リソースとアプリケーションのモニタリング、メトリクス収集と可視化 |
特徴と利点
この構成は高い拡張性と柔軟性、強力な処理能力が特徴です。大規模データセットの効率的な処理、複雑なワークフローの管理と自動化が可能で、高度なカスタマイズと既存のビッグデータツールの活用、詳細なモニタリングと分析機能を提供します。
ETL ワークフロー
この構成は高い拡張性と柔軟性、強力な処理能力が特徴です。大規模データセットの効率的な処理、複雑なワークフローの管理と自動化が可能で、高度なカスタマイズと既存のビッグデータツールの活用、詳細なモニタリングと分析機能を提供します。
この構成では、ETL プロセスは以下の流れで実行されます。
-
データ抽出:
MWAA を使用してソースデータの到着を検知し、必要に応じてカスタムオペレーターでデータ抽出を自動化。 -
データ処理:
MWAA で EMR クラスタを作成し、大規模データ処理ツールを使用してデータの変換、クレンジング、結合を実施。 -
ワークフロー管理:
MWAA でタスクの依存関係を設計・管理し、Airflow の機能を活用して高度なワークフロー制御を実装。 -
結果の保存:
処理済みデータを S3 に保存し、必要に応じて分析用に Redshift にデータを移動。 -
モニタリング:
CloudWatch で MWAA の実行状況と EMR のパフォーマンスを監視し、Airflow UI でワークフローをリアルタイムに可視化。
Apache Airflow とは:
ワークフローの作成、スケジューリング、モニタリングのためのプラットフォーム。Python でワークフローを定義し、複雑なタスク管理を容易にします。
DAG (Directed Acyclic Graph) とは:
Airflow のワークフロー定義の中核概念。タスクとその依存関係を表現する有向非巡回グラフで、複雑な ETL プロセスを視覚的に管理します。
この構成は、大規模なデータ処理や分析基盤の構築に適しており、ビッグデータプロジェクトや機械学習パイプラインの実装に活用できます。
モニタリングとリトライロジック
ETL パイプラインを安全かつ安定的に運用するためには、適切なモニタリングとエラー発生時のリトライロジックの検討が不可欠です。モニタリングやリトライの方法も ETL ワークフロー制御ツール選択の根拠になりえます。
ここでは、ETL パイプラインのワークフロー制御を担う AWS Step Functions、AWS Glue Workflows、Amazon MWAA について、モニタリング機能とリトライロジックの観点から比較します。
- AWS Step Functions:
視覚的な複雑な AWS サービス連携ワークフロー管理。柔軟なリトライロジック設定が可能。 - AWS Glue Workflows:
Glue と密接に統合された ETL ジョブのオーケストレーション。基本的なモニタリングとリトライ機能を提供。 - Amazon MWAA:
Apache Airflow ベースの包括的なモニタリングと柔軟なリトライ機能を持つ複雑な ETL パイプライン管理。
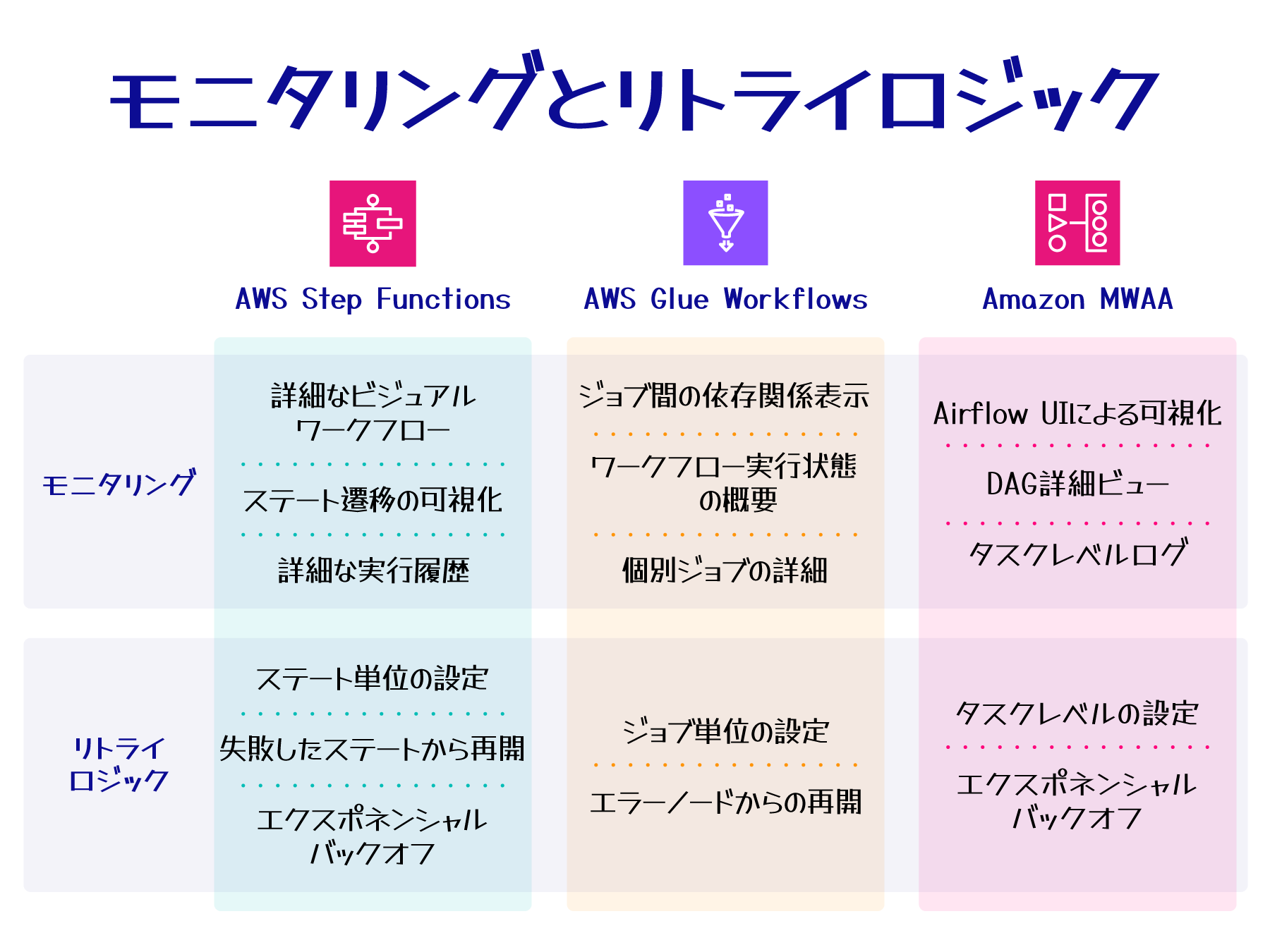
サービスごとの特徴と適用シナリオ
以下は、3 つのワークフロー制御サービスのモニタリングとリトライ機能の主な特徴をまとめたものです。
|
サービス |
モニタリングの特徴 |
リトライロジックの特徴 |
適用シナリオ |
|
AWS Step Functions |
|
|
複数の AWS サービスを連携させる複雑なワークフローに適しています。特に、状態管理が重要な長時間実行プロセスや、エラー処理とリトライロジックが複雑なワークフローの制御に強みを発揮します。 |
|
AWS Glue Workflows |
|
|
データカタログとの連携が必要なデータ処理ワークフローや、AWS のデータ分析サービスと密接に連携するデータパイプラインの構築に適しています。 |
|
Amazon MWAA |
|
|
既存の Airflow ベースのワークフローの移行に適しています。また、複数のクラウドやオンプレミスシステムを跨ぐデータ処理や、カスタムオペレーターを多用する複雑なワークフローの管理にも強みがあります。 |
サービス共通の特徴と個別の機能
-
モニタリングの共通点:
すべてのサービス (Step Functions、Glue Workflows、MWAA) は CloudWatch と統合されており、同等のリアルタイムモニタリング機能を利用できます。そのため、CPU 使用率などのシステムメトリクスは、全サービスで同じリアルタイム性で確認できます。 -
ワークフロービューの特徴:
各サービスは独自のワークフロービューを提供しており、これらは主にワークフローの構造や実行状況の可視化に使用されます。ただし、詳細なシステムメトリクスの監視には CloudWatch を使用します。 -
リトライ機能の実装:
各サービスでリトライの実装方法や設定オプションが異なりますが、いずれも効果的なエラーハンドリングとワークフロー再実行の機能を提供しています。
ETL の構成を検討する際に、モニタリングやリトライ機能の特徴からワークフロー制御用のサービスを選択するのも有効な方法です。これらのサービスの特徴と適用シナリオを把握し、プロジェクトの要件や規模、既存のインフラストラクチャ、チームのスキルセットなどを考慮しつつ最適なソリューションを選択します。
AWS Glue のモニタリングについて詳しくは、「AWS Glue のモニタリング」をご覧ください。
Amazon SageMaker Unified Studio を使った ETL 構築
これまで、AWS の様々なサービスを組み合わせた ETL パイプラインの選択肢について見てきました。しかし、実際に各サービスを使って ETL パイプラインを構築するとなると、個々のサービスに関する知識やスキルが必要となり、不慣れなユーザーには困難が伴います。
そこで、ETL パイプラインを簡単に構築するための有力な候補として、Amazon SageMaker Unified Studio (プレビュー) の活用が挙げられます。
SageMaker Unified Studio の始め方
SageMaker Unified Studio は、AWS re:Invent 2024 で発表された新サービスで、本記事執筆時点ではプレビューリリース版として提供されています。ML モデル開発、生成 AI アプリケーション開発、データ処理、SQL 分析などの完全な開発ワークフローを単一の管理環境で実現できるサービスです。
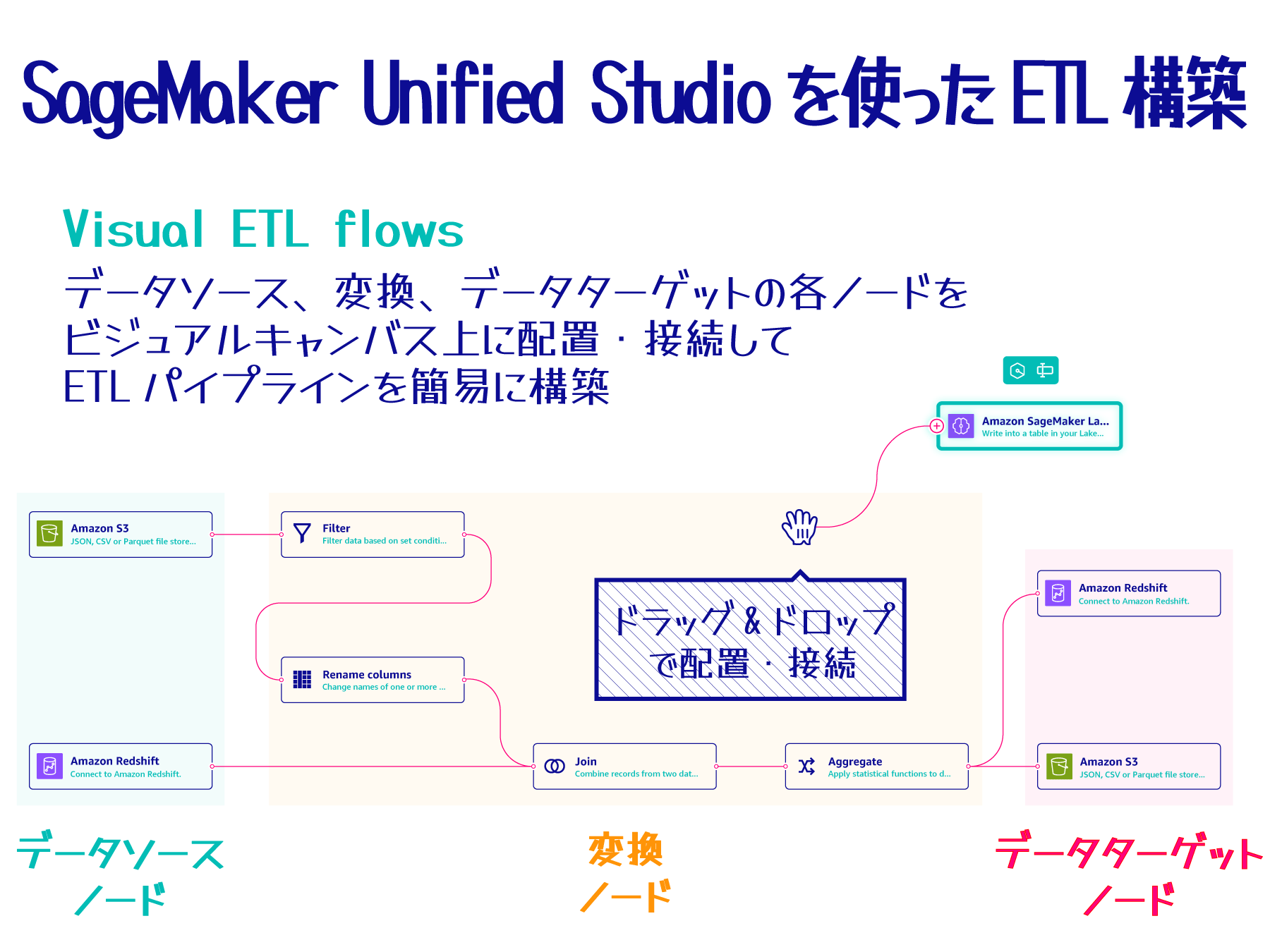
SageMaker Unified Studio は、ETL パイプライン作成専用のサービスではありませんが、「Visual ETL」という機能を提供しています。この機能を使うことで、ビジュアル化されたキャンバス上で ETL フローを直感的に構成することができます。
ここでは、SageMaker Unified Studio の始め方を説明します。
- ドメインの作成:
AWS マネジメントコンソールから SageMaker ドメインを作成します。これにより、SageMaker Unified Studio コンソール (統合スタジオ) が利用可能になります。 - 統合スタジオへのアクセス:
作成されたドメインを通じて、統合スタジオにアクセスします。 - プロジェクトの作成:
統合スタジオで「Data analytics and AI-ML model development」など、目的に応じたプロファイルを選択し、プロジェクトを作成します。 - Visual ETL フローの作成:
Build メニューから Visual ETL flows を開き、Visual ETL フローを作成します。データソースや変換、ターゲットソースのアイコンを、専用のビジュアルキャンバス上でドラッグ & ドロップで結合して ETL フローを構成したら、Run ボタンをクリックして ETL フローを実行します。
生成 AI アシスタントの Amazon Q を使って自然言語でフローを構成することも可能です。 - 結果の確認:
ETL フローを実行したら、出力先のデータソースに対してクエリを実行することで結果を確認できます。
SageMaker Unified Studio は、ETL パイプラインの構築からデータ分析、AI/ML モデルの開発まで、幅広いデータワークフローを包括的にサポートする統合環境です。Visual ETL 機能を活用することで、ETL プロセスに不慣れな方や複雑なアーキテクチャの設計に不安がある方でも、効率的にデータ処理パイプラインを構築できます。
より複雑なデータ処理や分析のワークフローが必要な場合は、Build > Orchestration > Workflows 機能を使用して、高度にカスタマイズされたワークフローを構築することもできます。
さらに、SageMaker Unified Studio では、処理済みデータを使った分析、BI、モデル開発までをシームレスに行えるため、データ関連プロジェクト全体をワンストップで管理することが可能です。
SageMaker Unified Studio はプレビューリリースの段階にあるため、機能や仕様に変更がある場合があります。使用する際は製品ページや「Amazon SageMaker Unified Studio User Guide (英語)」で最新の情報を確認してください。
まとめ
最後に、本記事で紹介した機能の全体図を見てみましょう。
本記事で紹介したように、AWS Glue や Amazon MWAA、AWS Step Functions などのワークフロー制御サービスを基盤とし、多様なAWSサービスを組み合わせることで、データ量や処理の複雑さに応じた最適な ETL パイプラインを構築できます。
さらに、プレビュー版の Amazon SageMaker Unified Studio は、Visual ETL 機能を通じて ETL プロセスの構築と運用を簡素化する新たなオプションとして活用できます。
AWS Glue や Amazon MWAA などは頻繁に機能が更新されるため、導入を進める際は公式サイトで最新情報をご覧になることをお勧めします。その他、最適な ETL プロセスの構築のための最適な AWS サービス選定について詳しく知りたい方は、「AWS ETL サービス適材適所選択のコツ」もあわせてご覧ください。
全体図
筆者・監修者プロフィール

筆者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。
趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。
現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール
大薗 純平
アマゾン ウェブ サービス ジャパン合同会社
シニアアナリティクススペシャリストソリューションアーキテクト
Data&AI の事業開発の組織でデータアナリティクスのスペシャリストとして、お客様の技術支援を担当しています。好きなサービスは Amazon SageMaker です。🍶とIPAが好きです。

監修者プロフィール
佐藤 悠
アマゾン ウェブ サービス ジャパン合同会社
プロフェッショナル サービス本部
データ アナリティクス コンサルタント
お客様のデータ基盤構想策定から構築まで、ビジネス成功に向けた包括的な支援を行っています。好きなサービスは AWS Glue と Amazon Managed Workflows for Apache Airflow (MWAA) です。サウナとウイスキーと鰻が好きです。

監修者プロフィール
久保 和隆
アマゾン ウェブ サービス ジャパン合同会社
エンタープライズ技術本部 ソリューションアーキテクト
銀行員として自社環境へのクラウド導入を経験し、ソリューションアーキテクトとしてアマゾンウェブサービスジャパン合同会社に入社。現在は、西日本の製造業のお客様に向けたクラウドに関する技術支援業務に従事。
表向きの趣味は、フットサル、スキューバダイビング、スノーボード。本当の趣味はゲーム・漫画・アニメ。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages