AWS Big Data Blog
Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy.
The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance benchmark to compare this new optimized committer with existing committer algorithms, namely FileOutputCommitter algorithm versions 1 and 2. We close with a discussion on current limitations for the new committer, providing workarounds where possible.
Comparison with FileOutputCommitter
In Amazon EMR version 5.19.0 and earlier, Spark jobs that write Parquet to Amazon S3 use a Hadoop commit algorithm called FileOutputCommitter by default. There are two versions of this algorithm, version 1 and 2. Both versions rely on writing intermediate task output to temporary locations. They subsequently perform rename operations to make the data visible at task or job completion time.
Algorithm version 1 has two phases of rename: one to commit the individual task output, and the other to commit the overall job output from completed/successful tasks. Algorithm version 2 is more efficient because task commits rename files directly to the final output location. This eliminates the second rename phase, but it makes partial data visible before the job completes, which not all workloads can tolerate.
The renames that are performed are fast, metadata-only operations on the Hadoop Distributed File System (HDFS). However, when output is written to object stores such as Amazon S3, renames are implemented by copying data to the target and then deleting the source. This rename “penalty” is exacerbated with directory renames, which can happen in both phases of FileOutputCommitter v1. Whereas these are single metadata-only operations on HDFS, committers must execute N copy-and-delete operations on S3.
To partially mitigate this, Amazon EMR 5.14.0+ defaults to FileOutputCommitter v2 when writing Parquet data to S3 with EMRFS in Spark. The new EMRFS S3-optimized committer improves on that work to avoid rename operations altogether by using the transactional properties of Amazon S3 multipart uploads. Tasks may then write their data directly to the final output location, but defer completion of each output file until task commit time.
Performance test
We evaluated the write performance of the different committers by executing the following INSERT OVERWRITE Spark SQL query. The SELECT * FROM range(…) clause generated data at execution time. This produced ~15 GB of data across exactly 100 Parquet files in Amazon S3.
Note: The EMR cluster ran in the same AWS Region as the S3 bucket. The trial_id property used a UUID generator to ensure that there was no conflict between test runs.
We executed our test on an EMR cluster created with the emr-5.19.0 release label, with a single m5d.2xlarge instance in the master group, and eight m5d.2xlarge instances in the core group. We used the default Spark configuration properties set by Amazon EMR for this cluster configuration, which include the following:
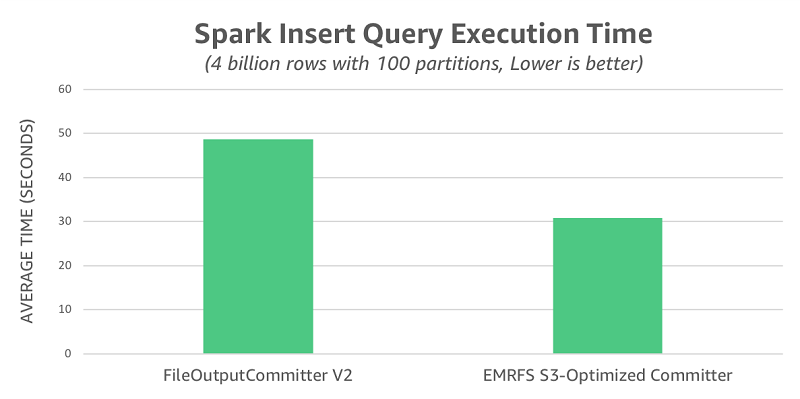
After running 10 trials for each committer, we captured and summarized query execution times in the following chart. Whereas FileOutputCommitter v2 averaged 49 seconds, the EMRFS S3-optimized committer averaged only 31 seconds—a 1.6x speedup.
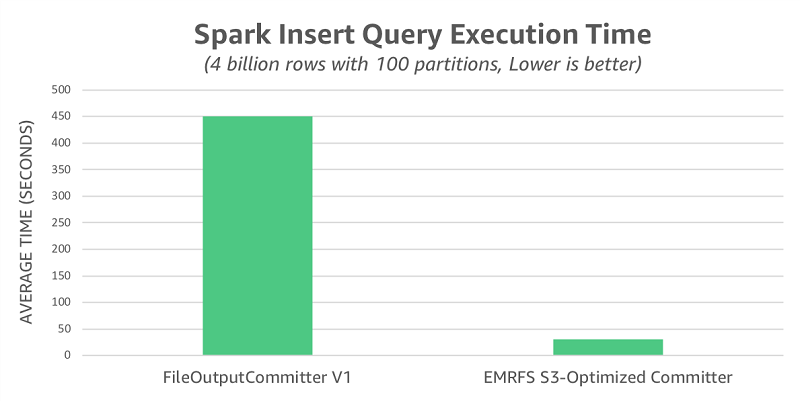
As mentioned earlier, FileOutputCommitter v2 eliminates some, but not all, rename operations that FileOutputCommitter v1 uses. To illustrate the full performance impact of renames against S3, we reran the test using FileOutputCommitter v1. In this scenario, we observed an average runtime of 450 seconds, which is 14.5x slower than the EMRFS S3-optimized committer.
The last scenario we evaluated is the case when EMRFS consistent view is enabled, which addresses issues that can arise due to the Amazon S3 data consistency model. In this mode, the EMRFS S3-optimized committer time was unaffected by this change and still averaged 30 seconds. On the other hand, FileOutputCommitter v2 averaged 53 seconds, which was slower than when the consistent view feature was turned off, widening the overall performance difference to 1.8x.

Job correctness
The EMRFS S3-optimized committer has the same limitations that FileOutputCommitter v2 has because both improve performance by fully delegating commit responsibilities to the individual tasks. The following is a discussion of the notable consequences of this design choice.
Partial results from incomplete or failed jobs
Because both committers have their tasks write to the final output location, concurrent readers of that output location can view partial results when using either of them. If a job fails, partial results are left behind from any tasks that have committed before the overall job failed. This situation can lead to duplicate output if the job is run again without first cleaning up the output location.
One way to mitigate this issue is to ensure that a job uses a different output location each time it runs, publishing the location to downstream readers only if the job succeeds. The following code block is an example of this strategy for workloads that use Hive tables. Notice how output_location is set to a unique value each time the job is run, and that the table partition is registered only if the rest of the query succeeds. As long as readers exclusively access data via the table abstraction, they cannot see results before the job finishes.
This approach requires treating the locations that partitions point to as immutable. Updates to partition contents require restating all results into a new location in S3, and then updating the partition metadata to point to that new location.
Duplicate results from non-idempotent tasks
Another scenario that can cause both committers to produce incorrect results is when jobs composed of non-idempotent tasks produce outputs into non-deterministic locations for each task attempt.
The following is an example of a query that illustrates the issue. It uses a timestamp-based table partitioning scheme to ensure that it writes to a different location for each task attempt.
You can avoid the issue of duplicate results in this scenario by ensuring that tasks write to a consistent location across task attempts. For example, instead of calling functions that return the current timestamp within tasks, consider providing the current timestamp as an input to the job. Similarly, if a random number generator is used within jobs, consider using a fixed seed or one that is based on the task’s partition number to ensure that task reattempts uses the same value.
Note: Spark’s built-in random functions rand(), randn(), and uuid() are already designed with this in mind.
Enabling the EMRFS S3-optimized committer
Starting with Amazon EMR version 5.20.0, the EMRFS S3-optimized committer is enabled by default. In Amazon EMR version 5.19.0, you can enable the committer by setting the spark.sql.parquet.fs.optimized.committer.optimization-enabled property to true from within Spark or when creating clusters. The committer takes effect when you use Spark’s built-in Parquet support to write Parquet files into Amazon S3 with EMRFS. This includes using the Parquet data source with Spark SQL, DataFrames, or Datasets. However, there are some use cases when the EMRFS S3-optimized committer does not take effect, and some use cases where Spark performs its own renames entirely outside of the committer. For more information about the committer and about these special cases, see Using the EMRFS S3-optimized Committer in the Amazon EMR Release Guide.
EMRFS S3-optimized committer is enabled by default on Amazon EMR 5.20.0 and later as stated in the post and starting with Amazon EMR 6.4.0, the committer can be used for all common formats including parquet, ORC and text-based formats such as CSV and JSON. Although, there are circumstances where the committer is not used. For more information, see Requirements for the EMRFS S3-optimized committer.
Remember that you should use the s3:// filesystem in your big data applications to use it and is the recommended route. More information on Working with storage and file systems with Amazon EMR.
Related Work – S3A Committers
The EMRFS S3-optimized committer was inspired by concepts used by committers that support the S3A file system. The key take-away is that these committers use the transactional nature of S3 multipart uploads to eliminate some or all of the rename costs. This is also the core concept used by the EMRFS S3-optimized committer.
For more information about the various committers available within the ecosystem, including those that support the S3A file system, see the official Apache Hadoop documentation.
Summary
The EMRFS S3-optimized committer improves write performance compared to FileOutputCommitter. Starting with Amazon EMR version 5.19.0, you can use it with Spark’s built-in Parquet support. For more information, see Using the EMRFS S3-optimized Committer in the Amazon EMR Release Guide.
About the authors
 Peter Slawski is a software development engineer with Amazon Web Services.
Peter Slawski is a software development engineer with Amazon Web Services.
 Jonathan Kelly is a senior software development engineer with Amazon Web Services.
Jonathan Kelly is a senior software development engineer with Amazon Web Services.
Audit History
Last reviewed and updated in November 2024 by Angel Conde Manjon | Partner Sollutions Architect