AWS Big Data Blog
Tag: Spark

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]

Run fault tolerant and cost-optimized Spark clusters using Amazon EMR on EKS and Amazon EC2 Spot Instances
Amazon EMR on EKS is a deployment option in Amazon EMR that allows you to run Spark jobs on Amazon Elastic Kubernetes Service (Amazon EKS). Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances save you up to 90% over On-Demand Instances, and is a great way to cost optimize the Spark workloads running on Amazon […]

Design considerations for Amazon EMR on EKS in a multi-tenant Amazon EKS environment
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) in order to take advantage of Kubernetes without the burden of managing the Kubernetes control plane. With Kubernetes, you can centrally manage your workloads and offer administrators a multi-tenant environment where they can create, update, scale, and secure workloads using a single API. Kubernetes also […]

Disaster recovery considerations with Amazon EMR on Amazon EC2 for Spark workloads
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR launches all nodes for a given cluster in the same Amazon Elastic Compute Cloud (Amazon EC2) Availability Zone […]
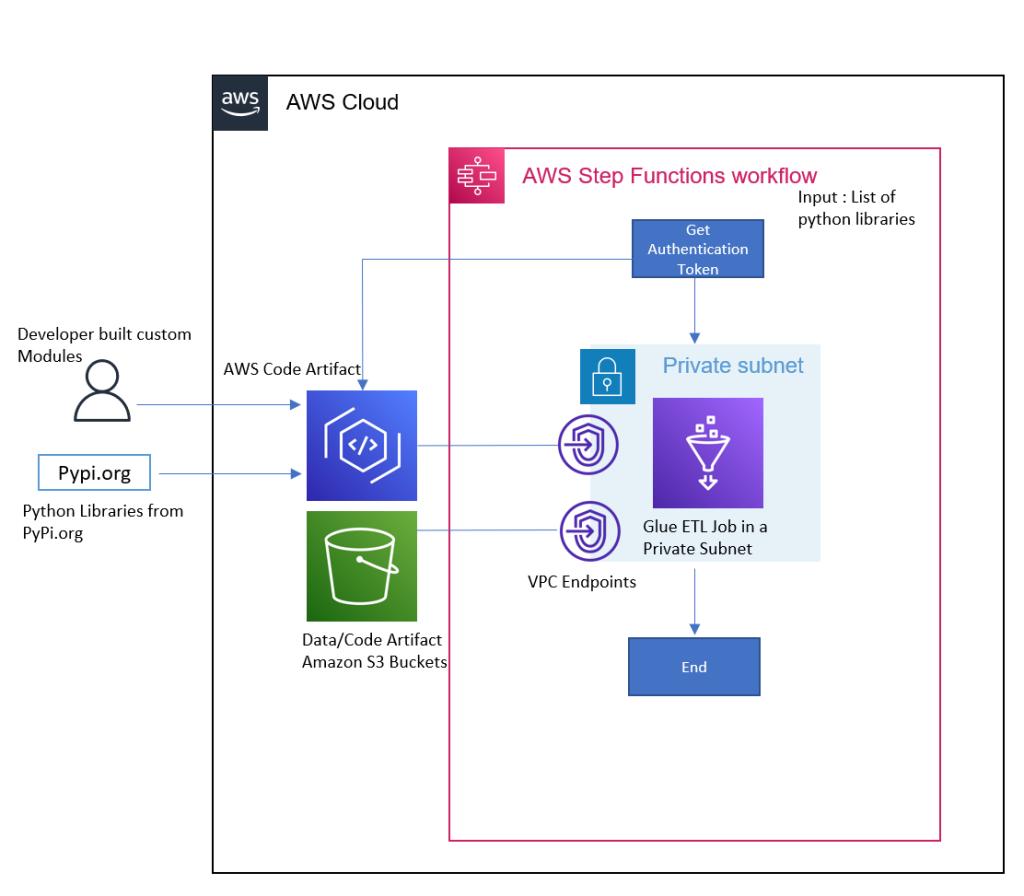
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]

EMR Notebooks: A managed analytics environment based on Jupyter notebooks
Notebooks are increasingly becoming the standard tool for interactively developing big data applications. It’s easy to see why. Their flexible architecture allows you to experiment with data in multiple languages, test code interactively, and visualize large datasets. To help scientists and developers easily access notebook tools, we launched Amazon EMR Notebooks, a managed notebook environment […]

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]
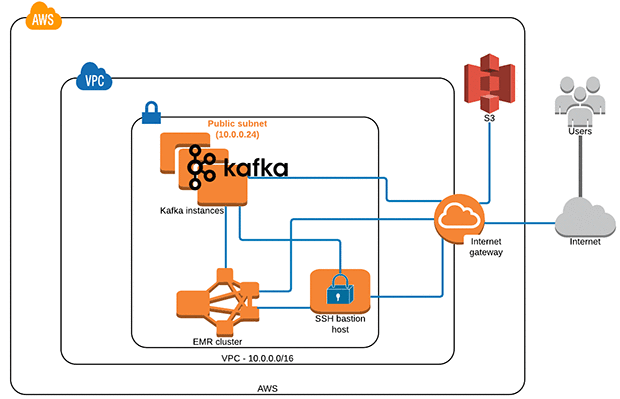
Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWS
This post demonstrates how to set up Apache Kafka on EC2, use Spark Streaming on EMR to process data coming in to Apache Kafka topics, and query streaming data using Spark SQL on EMR.

How SmartNews Built a Lambda Architecture on AWS to Analyze Customer Behavior and Recommend Content
This is a guest post by Takumi Sakamoto, a software engineer at SmartNews. SmartNews in their own words: “SmartNews is a machine learning-based news discovery app that delivers the very best stories on the Web for more than 18 million users worldwide.” Data processing is one of the key technologies for SmartNews. Every team’s workload […]
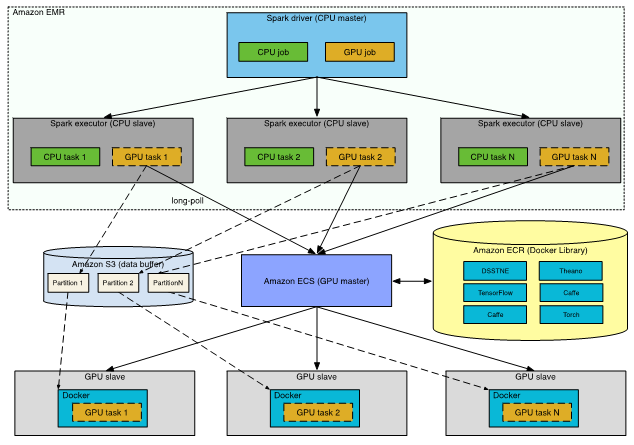
Generating Recommendations at Amazon Scale with Apache Spark and Amazon DSSTNE
In this post, I discuss an alternate solution; namely, running separate CPU and GPU clusters, and driving the end-to-end modeling process from Apache Spark.