AWS Big Data Blog
Generating Recommendations at Amazon Scale with Apache Spark and Amazon DSSTNE
Kiuk Chung is a Software Development Engineer with the Amazon Personalization team
In Personalization at Amazon, we use neural networks to generate personalized product recommendations for our customers. Amazon’s product catalog is huge compared to the number of products that a customer has purchased, making our datasets extremely sparse. And with hundreds of millions of customers and products, our neural network models often have to be distributed across multiple GPUs to meet space and time constraints.
For this reason, we have created and open-sourced DSSTNE, the Deep Scalable Sparse Tensor Neural Engine, which runs entirely on the GPU. We use DSSTNE to train neural networks and generate recommendations that power various personalized experiences on the retail website and Amazon devices.
On the other hand, data for training and prediction tasks is processed and generated from Apache Spark on a CPU cluster. This presents a fundamental problem: data processing happens on CPU while training and prediction happen on GPU.
Data generation and analysis are often overlooked in favor of modeling. But for fluid and rapid model prototyping, we want to analyze data, and train and evaluate our models inside of a single tool, especially since at least as much time is spent preparing data as designing models. Moreover, while DSSTNE is optimized for sparseness and scalability, it can help to use other libraries, such as Keras, which includes additional features such as recurrent network architectures.
Managing a hybrid cluster of both CPU and GPU instances poses challenges because cluster managers such as Yarn/Mesos do not natively support GPUs. Even if they did have native GPU support, the open source deep learning libraries would have to be re-written to work with the cluster manager API.
In this post, I discuss an alternate solution; namely, running separate CPU and GPU clusters, and driving the end-to-end modeling process from Apache Spark.
Architecture overview
We wanted an architecture where tasks could be run on both CPU and GPU from a single tool, and deep learning libraries could be plugged in without the need to re-write the algorithms in a different language or API. Keeping Spark as the main entry point, we thought of the training and prediction of neural networks as coarse grained tasks that could be delegated to a separate cluster with specialized GPU hardware. This is different from a more traditional approach where a lower level task such as matrix multiplication is exposed as a task primitive.
The Spark (CPU) cluster runs on Amazon EMR and the GPU instances are managed by Amazon ECS. In other words, we treat ECS as our GPU master. ECS runs tasks on Docker containers that reside in Amazon ECR, hence a deep learning library can easily be plugged in by exporting its Docker image to ECR.
The following diagram shows the high-level architecture.

In this architecture, data analytics and processing (i.e., CPU jobs) are executed through vanilla Spark on Amazon EMR, where the job is broken up into tasks and runs on a Spark executor. The GPU job above refers to the training or prediction of neural networks. The partitioning of the dataset for these jobs is done in Spark, but the execution of these jobs is delegated to ECS and is run inside Docker containers on the GPU slaves. Data transfer between the two clusters is done through Amazon S3.
When a GPU job is run, it is broken down into one or more GPU tasks (see later sections for details). Like Spark, a GPU task is assigned for each partition of the data RDD. The Spark executors save their respective partitions to S3, then call ECS to run a task definition with container overrides that specify the S3 location of its input partitions and the command to execute on the specified Docker image. Then they long-poll ECS to monitor the status of the GPU tasks.
On the GPU node, each task does the following:
- Downloads its data partition from S3.
- Executes the specified command.
- Uploads the output of the command back to S3.
Because the training and predictions run in a Docker container, all you need to do to support a new library is to create a Docker image, upload it to ECR, and create an ECS task definition that maps to the appropriate image.
In the next section, I dive into the details of what type of GPU tasks we run with DSSTNE.
Deep learning with DSSTNE
Our neural network models often have hundreds of thousands of nodes in the input and output layers (i.e. wide networks). At this scale, we can easily reach trillions of weights for a fully-connected network, even if it is shallow. Therefore, our models often do not fit in the memory of a single GPU.
As mentioned above, we built DSSTNE to support large, sparse layers. One of the ways it does so is by supporting model parallel training. In model parallel training, the model is distributed across N GPUs – the dataset (e.g., RDD) is replicated to all GPU nodes. Contrast this with data parallel training where each GPU only trains on a subset of the data, then shares the weights with each other using synchronization techniques such as a parameter server.
After the model is trained, we generate predictions (e.g., recommendations) for each customer. This is an embarrassingly parallel task as each customer’s recommendations can be generated independently. Thus, we perform data parallel predictions, where each GPU handles the prediction of a batch of customers. This allows us to scale linearly simply by adding more GPUs. That is, doubling the number of partitions (GPUs) halves the amount of time to generate predictions. Thanks to Auto Scaling, we can scale our GPU cluster up and down based on our workload and SLA constraints.
The following diagram depicts model parallel training and data parallel predictions.

Now that you have seen the types of GPU workloads, I’ll show an example of how we orchestrated an end-to-end modeling iteration from Spark.
Orchestration with Apache Spark
As explained earlier, the deep learning algorithms run inside Docker containers on a separate GPU cluster managed by ECS, which gives us programmatic access to the execution engine on a remote cluster. The entry point for the users is Spark. Leveraging notebooks such as Zeppelin or Jupyter, users can interactively pull and analyze data, train neural networks, and generate predictions, without ever having to leave the notebook.
In the next two parts, I discuss how to train/predict a sample neural network as described in DSSTNE’s Github page from a Zeppelin notebook using the previously mentioned two-cluster setup.
Model parallel training
This section describes how to train a three-layer autoencoder using model parallel training across four GPUs on the MovieLens dataset. The data, model configurations, and model topology are defined in the Zeppelin notebook on the EMR cluster and propagated to the GPU slaves by using S3 as a shared filesystem. A list of commands are run on ECS to download data and configurations, kick off training, and upload the model artifacts to S3.
To delegate the GPU tasks to ECS, you must set up the ECS cluster and the task definition. The following steps summarize the ECS setup.
- Add AWS Java SDK for Amazon ECS in the Spark classpath.
- Ensure that the EC2 instance profile on the EMR cluster has permissions to call ECS.
- Create an ECS cluster with a GPU instance and install a DSSTNE compatible NVIDIA driver.
- Create an ECS task definition with a container that has the privileged flag set and points to DSSTNE’s Docker image with the AWS CLI.
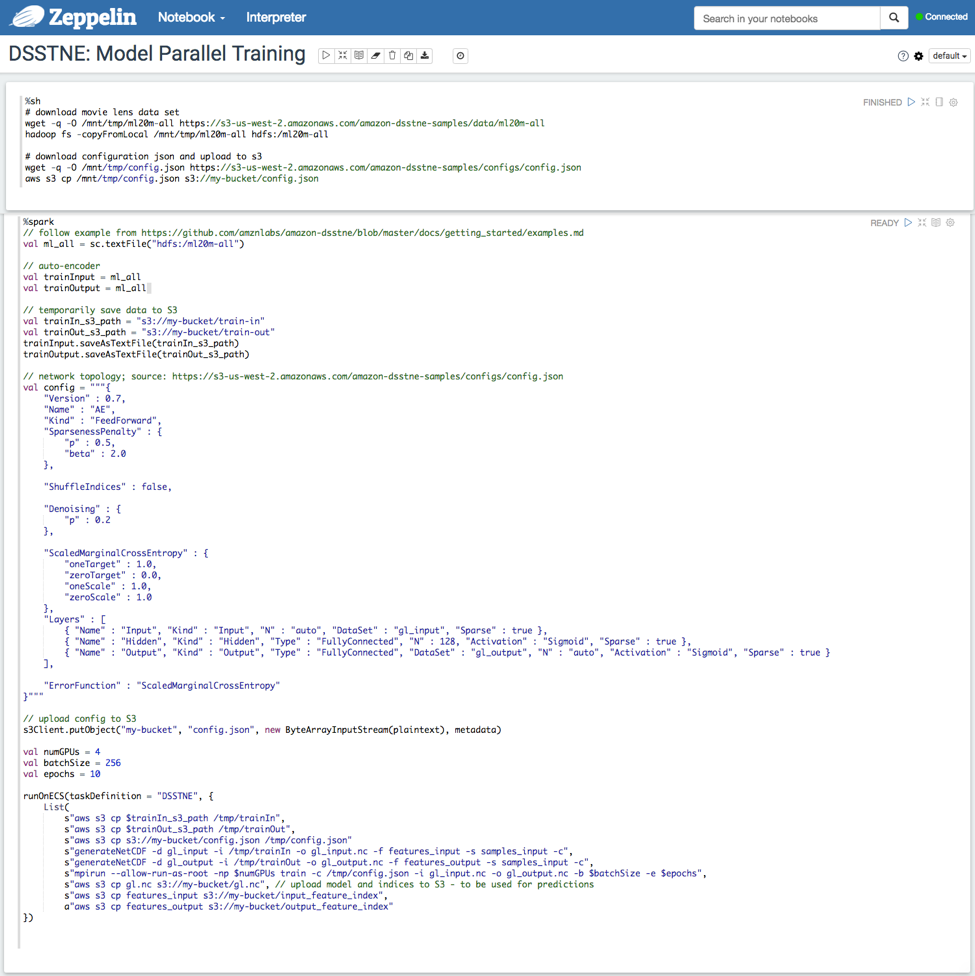
On an EMR cluster with Spark and Zeppelin (Sandbox) installed, the %sh interpreter in Zeppelin is used to download the required files. The size and instance type of the EMR cluster depends on the size of your dataset. We recommend using two c3.2xlarge instances for the MovieLens dataset.
Switch to the spark interpreter to kick-start training. The runOnECS() method, runs the given list of commands on the Docker container specified by the provided task definition. You can define this method on the Zeppelin notebook and implement it by instantiating an AmazonECSClient with InstanceProfileCredentialsProvider, and submitting a RunTaskRequest with the list of commands as container overrides.
The following graphic demonstrates model parallel training driven from a Zeppelin notebook.
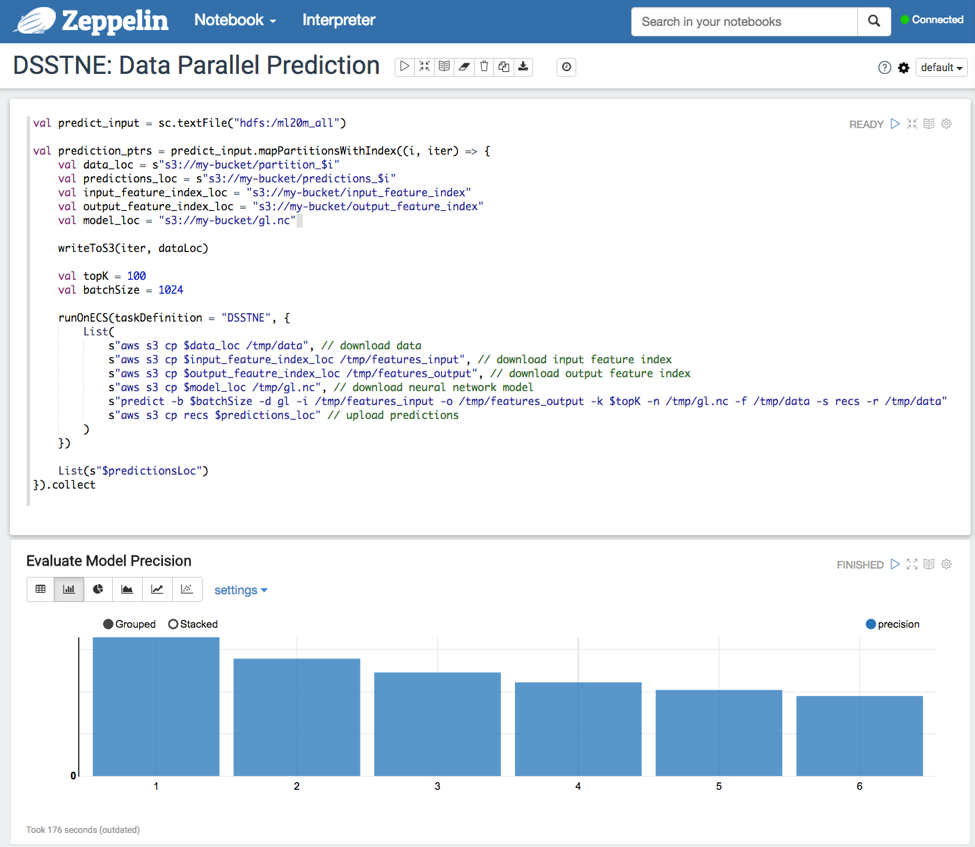
Data parallel prediction
Using the network trained above, we run data parallel predictions and generate the top 100 recommendations for each customer. Each partition of the predict_input RDD is processed in parallel on separate GPUs. After generating the predictions, you can evaluate the precision of the model by comparing against a test dataset. If you are not satisfied with the performance of the model, then you can go back to training the network with different slices of data, model parameters, or network topology and iterate quickly inside the same notebook.
The following graphic demonstrates data parallel predictions and plotting the precision metrics.
Conclusion and future work
In this post, I have explained how Personalization uses Spark and DSSTNE to iterate on large deep learning problems quickly and generate recommendations for millions of customers daily.
Both Spark and DSSTNE allow you to scale to large amounts of data by exploiting parallelism wherever it exists. By using ECS to run mini-batch jobs on GPU hardware, you can circumvent the complexity of managing a heterogeneous cluster with both CPU and GPU nodes where multiple deep learning library installations coexist. Furthermore, deep learning libraries can be plugged into the platform with ease, giving scientists and engineers the freedom to choose the library most appropriate to their problems.
By using EMR to provision Spark clusters, you can easily scale the size and number of CPU clusters based on our workload. However, we currently share a single GPU cluster in ECS, which lacks the ability to queue tasks at this time. Consequently, a user may suffer from GPU starvation. To alleviate this, we have implemented a Mesos scheduler on top of ECS based on the ECS Mesos Scheduler Driver prototype.
Orchestrating the entire machine learning life-cycle from Spark allows you to stack Spark and deep learning libraries to build creative applications. For example, you can leverage Spark Streaming to feed streaming data into the GPU prediction tasks to update the recommendations of customers near real-time. Models supported by MLlib can be used as baselines for the neural networks, or can be joined together to create ensembles. You can take advantage of Spark’s parallel execution engine to run parallel hyper-parameter optimizations. And the list goes on….
The management and setup of this stack is simple, repeatable, and elastic when you run on AWS. We are excited to see the applications that you will build on these tools!
Please leave a comment below to tell us about your apps and problems.
Passionate about deep learning and recommendations at scale? Check out Personalization’s careers page.
———————————
Related
Sharpen your Skill Set with Apache Spark on the AWS Big Data Blog

Want to learn more about Big Data or Streaming Data? Check out our Big Data and Streaming data educational pages.