Amazon Web Services 한국 블로그
Amazon SageMaker Profiler 미리 보기 – 모델 훈련 시 하드웨어 성능 데이터 추적 및 시각화 제공
새롭게 미리보기로 출시되는 Amazon SageMaker Profiler 기능은 SageMaker에서 딥 러닝(Deepl Learning) 모델을 훈련하는 동안 프로비저닝된 AWS 컴퓨팅 리소스에 대한 자세한 성능 데이터와 시각화를 제공합니다. SageMaker Profiler를 사용하면 CPU 및 GPU 사용률, GPU에서 커널 실행, CPU에서 커널 실행, 동기화 작업, GPU 전반의 메모리 작업, 커널 시작과 해당 실행 간의 지연 시간, 데이터 전송 등 CPU 및 GPU의 모든 활동을 추적할 수 있습니다.
SageMaker Profiler는 PyTorch 또는 TensorFlow 훈련 스크립트에 주석을 달고 SageMaker Profiler를 활성화하기 위한 Python 모듈을 제공합니다. Profile 또한 GPU와 CPU 간 이벤트의 시간 관계를 추적하고 이해하기 위해 프로파일링된 이벤트의 통계 요약, 훈련 작업의 타임라인 을 시각화하는 사용자 인터페이스(UI)를 제공합니다.
모델 학습 작업 프로파일링의 필요성
딥 러닝이 부상하면서 기계 학습(Machine Learning, ML)은 컴퓨팅 및 데이터 집약적이 되었으며 일반적으로 다중 노드, 다중 GPU 클러스터가 필요합니다. 최첨단 모델의 크기가 수조 개의 매개변수로 증가함에 따라 계산 복잡성과 비용도 급격히 증가합니다. ML 실무자는 이러한 대규모 모델을 학습할 때 효율적인 리소스 활용이라는 일반적인 문제에 대처해야 합니다. 이는 일반적으로 수십억 개의 매개변수가 있으므로 효율적으로 훈련하기 위해 대규모 다중 노드 GPU 클러스터가 필요한 대형 언어 모델(LLM)에서 특히 두드러집니다.
대규모 컴퓨팅 클러스터에서 이러한 모델을 교육할 때 I/O 병목 현상, 커널 실행 대기 시간, 메모리 제한 및 낮은 리소스 활용도와 같은 컴퓨팅 리소스 최적화 문제에 직면할 수 있습니다. 훈련 작업 구성이 최적화되지 않으면 이러한 문제로 인해 하드웨어 활용이 비효율적이고 훈련 시간이 길어지거나 훈련 실행이 불완전해져서 프로젝트의 전체 비용과 일정이 늘어날 수 있습니다.
전제 조건
다음은 SageMaker Profiler 사용을 시작하기 위한 전제 조건입니다.
- AWS 계정의 SageMaker 도메인 – 도메인 설정에 대한 지침은 빠른 설정을 사용하여 Amazon SageMaker 도메인에 온보딩 문서를 참조하시기 바랍니다. 또한 개별 사용자가 SageMaker Profiler UI 애플리케이션에 액세스하려면 도메인 사용자 프로필을 추가해야 합니다. 자세한 내용은 SageMaker 도메인 사용자 프로필 추가 및 제거 문서를 참조하시기 바랍니다.
- 권한 – 다음 목록은 SageMaker Profiler UI 애플리케이션을 사용하기 위해 실행 역할에 할당되어야 하는 최소 권한 집합입니다.
sagemaker:CreateAppsagemaker:DeleteAppsagemaker:DescribeTrainingJobsagemaker:SearchTrainingJobss3:GetObjects3:ListBucket
SageMaker Profiler를 사용하여 모델 훈련 작업 준비 및 실행
모델 훈련 작업이 실행되는 동안 GPU에서 커널 실행 캡처를 시작하려면 SageMaker Profiler Python 모듈을 사용하여 학습 스크립트를 수정하시기 바랍니다. 라이브러리를 가져오고, 프로파일링의 시작과 끝을 정의하기 위해 start_profiling()및 stop_profiling()를 추가합니다. 또한, 선택적 사용자 정의 주석을 사용하여 교육 스크립트에 마커를 추가하여 각 단계의 특정 작업 중에 하드웨어 활동을 시각화할 수 있습니다.
SageMaker Profiler를 사용하여 훈련 스크립트를 프로파일링하는 데 사용할 수 있는 두 가지 접근 방식이 있습니다. 첫 번째 접근 방식은 전체 기능의 프로파일링을 기반으로 합니다. 두 번째 접근 방식은 함수의 특정 코드 줄을 프로파일링하는 것을 기반으로 합니다.
기능별로 프로파일링하려면, 전체 기능에 주석을 달기 위해 smppy.annotate컨텍스트 관리자를 사용하세요. 다음 예제 스크립트는 컨텍스트 관리자를 구현하여 각 반복에서 훈련 루프와 전체 기능을 래핑하는 방법을 보여줍니다.
또한, 함수의 특정 코드 줄에 주석을 추가하기 위해 smppy.annotation_begin()와 smppy.annotation_end()를 사용할 수 있습니다. 자세한 내용은 설명서를 참고하세요.
SageMaker 훈련 작업 실행 프로그램 구성
프로파일러 시작 모듈에 주석을 달고 설정한 후에는 훈련 스크립트를 저장하고 SageMaker Python SDK를 사용하여 교육용 SageMaker 프레임워크 추정기를 준비합니다.
ProfilerConfig그리고Profiler모듈을 사용하는profiler_config객체를 다음과 같이 설정합니다.- 이전 단계에서 생성된
profiler_config객체를 사용하여 SageMaker 추정기를 생성합니다. 다음 코드는 PyTorch 추정기를 생성하는 예를 보여줍니다.
TensorFlow 추정기를 생성하려면 다음을 가져오세요. sagemaker.tensorflow.TensorFlow대신 SageMaker Profiler에서 지원하는 TensorFlow 버전 중 하나를 지정하세요. 지원되는 프레임워크 및 인스턴스 유형에 대한 자세한 내용은 지원되는 프레임워크를 참조하시기 바랍니다.
- fit 메서드를 실행하여 훈련 작업을 시작합니다.
SageMaker 프로파일러 UI 실행
이제 모델 훈련 작업이 완료되면 SageMaker Profiler 사용자 인터페이스(UI를 시작하여 훈련 작업의 프로필을 시각화하고 탐색할 수 있습니다. SageMaker 콘솔의 SageMaker 프로파일러 랜딩 페이지 또는 SageMaker 도메인을 통해 SageMaker 프로파일러 UI 애플리케이션에 액세스할 수 있습니다.
SageMaker 콘솔에서 SageMaker Profiler UI 애플리케이션을 시작하려면 다음 단계를 완료하십시오.
- SageMaker 콘솔의 탐색창에서 프로파일러를 선택합니다.
- 시작하기 메유 아래의 SageMaker 프로파일러 UI 애플리케이션을 시작하려는 도메인을 선택합니다.
사용자 프로필이 하나의 도메인에만 속하는 경우 도메인 선택 옵션이 표시되지 않습니다.
- SageMaker Profiler UI 애플리케이션을 시작하려는 사용자 프로필을 선택합니다.
도메인에 사용자 프로필이 없으면 사용자 프로필 생성을 선택합니다. 새 사용자 프로필 생성에 대한 자세한 내용은 사용자 프로필 추가 및 제거 문서를 참조하시기 바랍니다.
- 프로파일러 열기를 선택합니다. 도메인 세부 정보 페이지에서 SageMaker 프로파일러 UI를 시작할 수 있습니다.
SageMaker Profiler 시각화 기능 사용하기
SageMaker 프로파일러 UI를 열면, 다음 스크린샷과 같이 프로필 선택 및 읽기 페이지가 열립니다.
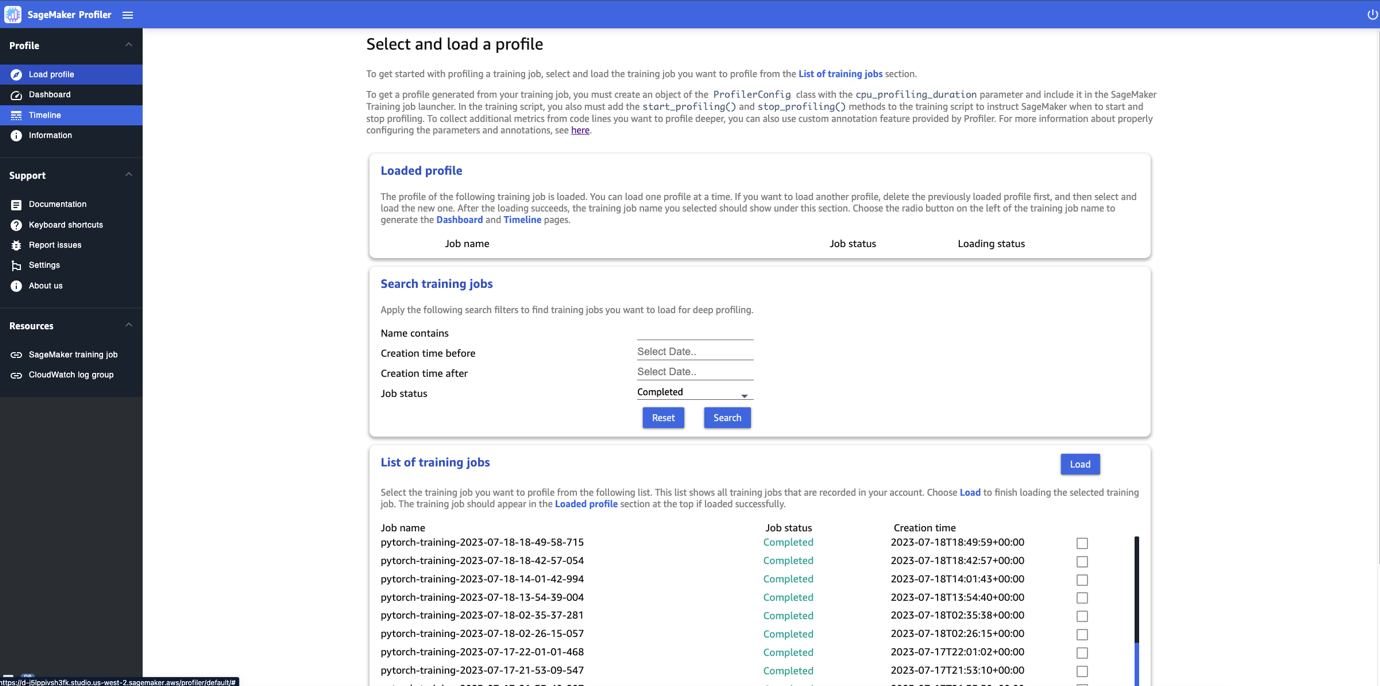
SageMaker 프로파일러에 제출된 모든 훈련 작업 목록을 보고 이름, 생성 시간 및 실행 상태(진행 중, 완료됨, 실패함, 중지됨 또는 중지 중)별로 특정 훈련 작업을 검색할 수 있습니다. 프로필을 로드하려면 보려는 훈련 작업을 선택하고 로드를 선택합니다. 작업 이름은 상단의 로드된 프로필 섹션에 표시되어야 합니다.
대시보드와 타임라인을 생성하려면 작업 이름을 선택하세요. 작업을 선택하면 UI가 자동으로 대시보드를 엽니다. 한 번에 하나의 프로필을 로드하고 시각화할 수 있습니다. 다른 프로필을 로드하려면 먼저 이전에 로드한 프로필을 언로드해야 합니다. 섹션 에서 휴지통 아이콘을 선택합니다 프로필을 언로드하려면 프로필 로드 .
이 게시물에서는 ALBEF 훈련 작업의 두 개의 ml.p4d.24xlarge 인스턴스의 프로필을 봅니다. 훈련 작업 로드 및 선택을 마치면, 다음 스크린샷과 같이 UI에서 대시보드 페이지가 열립니다.
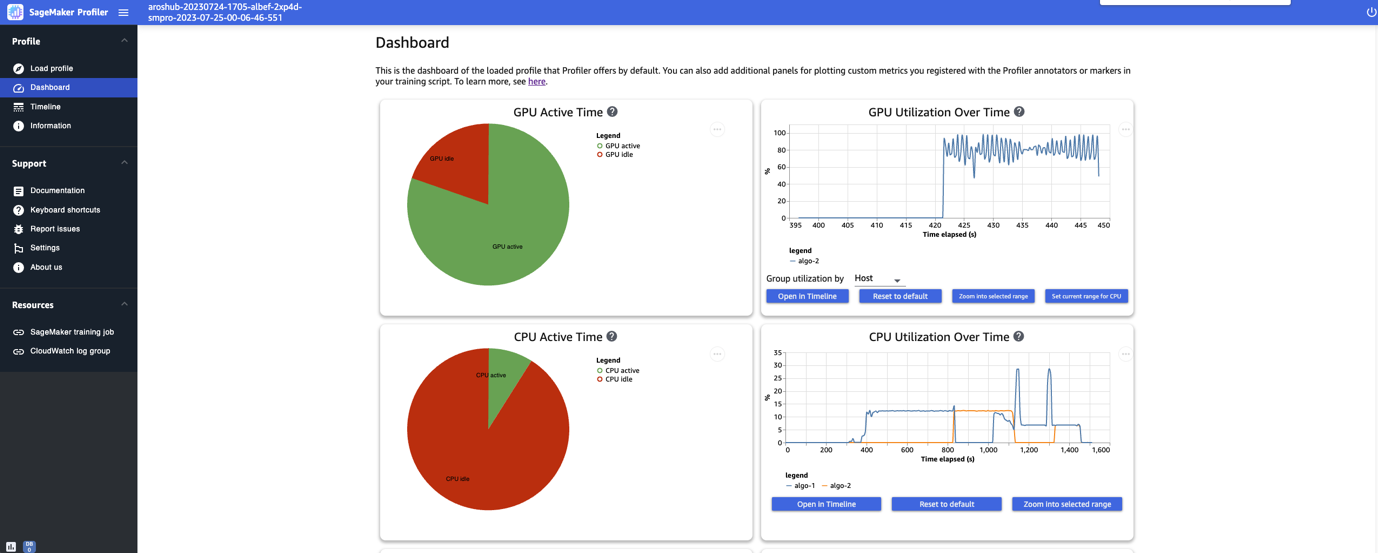
주요 지표, 즉 GPU 활성 시간, 시간 경과에 따른 GPU 활용도, CPU 활성 시간, 시간 경과에 따른 CPU 활용도에 대한 도표를 볼 수 있습니다. GPU 활성 시간 파이 차트는 GPU 활성 시간과 GPU 유휴 시간의 비율을 보여줍니다. 이를 통해 전체 훈련 작업에서 GPU가 유휴 시간보다 더 활동적인지 확인할 수 있습니다.
시간 경과에 따른 GPU 사용률 타임라인 그래프는 노드당 시간에 따른 평균 GPU 사용률을 표시하여 모든 노드를 단일 차트에 집계합니다. 특정 시간 간격 동안 GPU에 불균형 작업 부하, 활용도 부족 문제, 병목 현상 또는 유휴 문제가 있는지 확인할 수 있습니다. 이러한 측정항목 해석에 대한 자세한 내용은 설명서를 참고하세요.
대시보드는 다음 스크린샷과 같이 모든 GPU 커널이 소비한 시간, 상위 15개 GPU 커널이 소비한 시간, 모든 GPU 커널의 실행 횟수, 상위 15개 GPU 커널의 실행 횟수를 포함한 추가 플롯을 제공합니다.
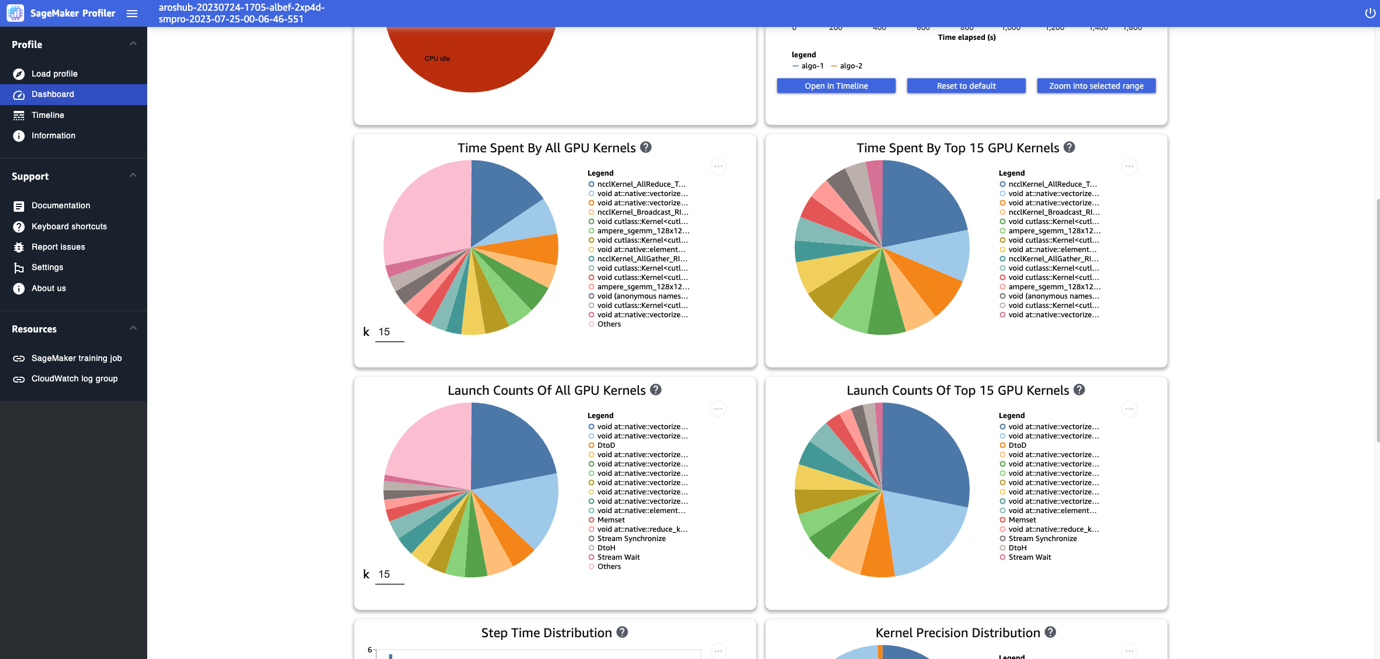
마지막으로 대시보드를 사용하면 GPU의 단계 지속 시간 분포를 보여주는 히스토그램인 단계 시간 분포와 FP32, FP16, INT32 및 INT8과 같은 다양한 데이터 유형의 커널 실행에 소요된 시간의 백분율을 보여주는 커널 정밀도 분포 원형 차트와 같은 추가 측정항목을 시각화할 수 있습니다.
커널 실행, 메모리( memcpy그리고 memset) 및 동기화( sync)와 같은 GPU 활동에 소요된 시간의 백분율을 표시하는 GPU 활동 분포에 대한 원형 차트를 얻을 수도 있습니다. GPU 메모리 작업 분포 원형 차트에서 GPU 메모리 작업에 소요된 시간 비율을 시각화할 수 있습니다.
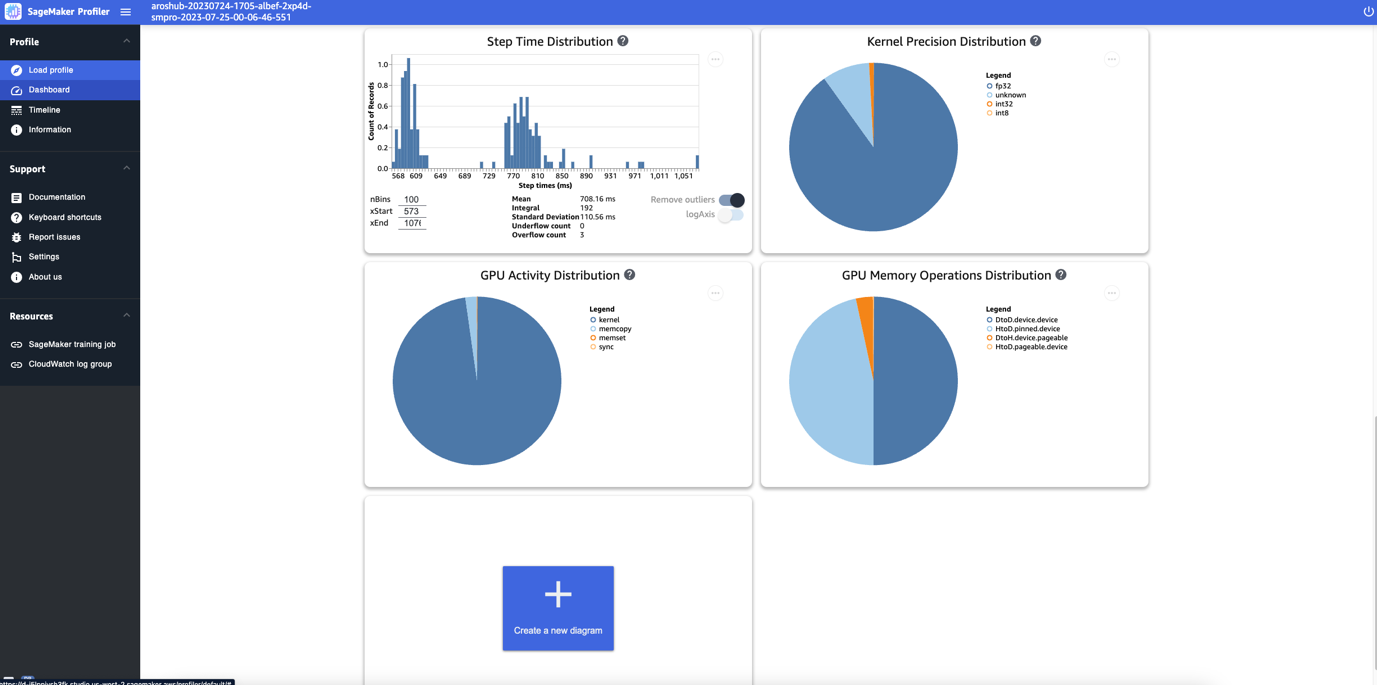
이 게시물의 앞부분에서 설명한 대로 수동으로 주석을 추가한 사용자 정의 측정항목을 기반으로 자신만의 히스토그램을 만들 수도 있습니다. 새 히스토그램에 사용자 정의 주석을 추가할 때 훈련 스크립트에 추가한 주석의 이름을 선택하거나 입력하십시오.
타임라인 인터페이스
SageMaker 프로파일러 UI에는 CPU에서 예약되고 GPU에서 실행되는 작업 및 커널 수준의 컴퓨팅 리소스에 대한 자세한 보기를 제공하는 타임라인 인터페이스도 포함되어 있습니다. 타임라인은 트리 구조로 구성되어 다음 스크린샷과 같이 호스트 수준에서 장치 수준까지 정보를 제공합니다.
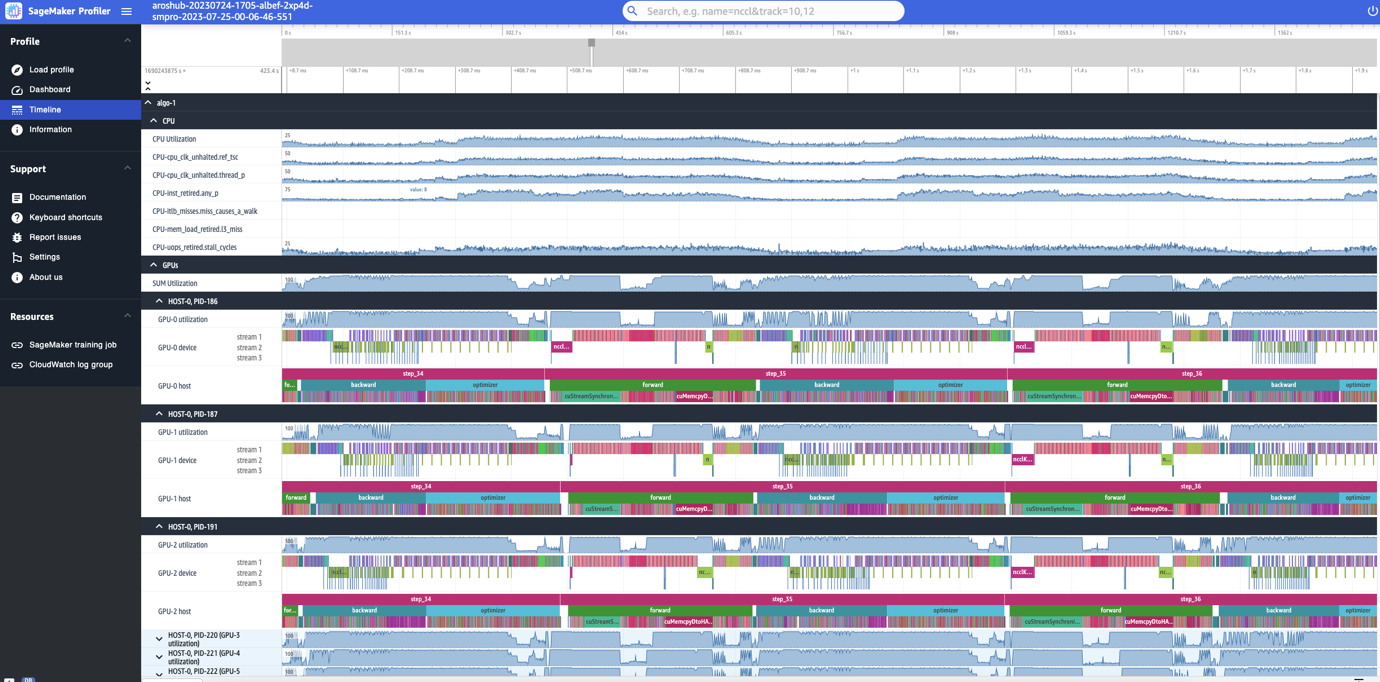
각 CPU에 대해 clk_unhalted_ref.tsc그리고 itlb_misses.miss_causes_a_walk와 같은 CPU 성능 카운터를 추적할 수 있습니다. 2대의 p4d.24xlarge 인스턴스의 각 GPU에 대해 호스트 타임라인과 디바이스 타임라인을 볼 수 있습니다. 커널 실행은 호스트 타임라인에 있고 커널 실행은 장치 타임라인에 있습니다.
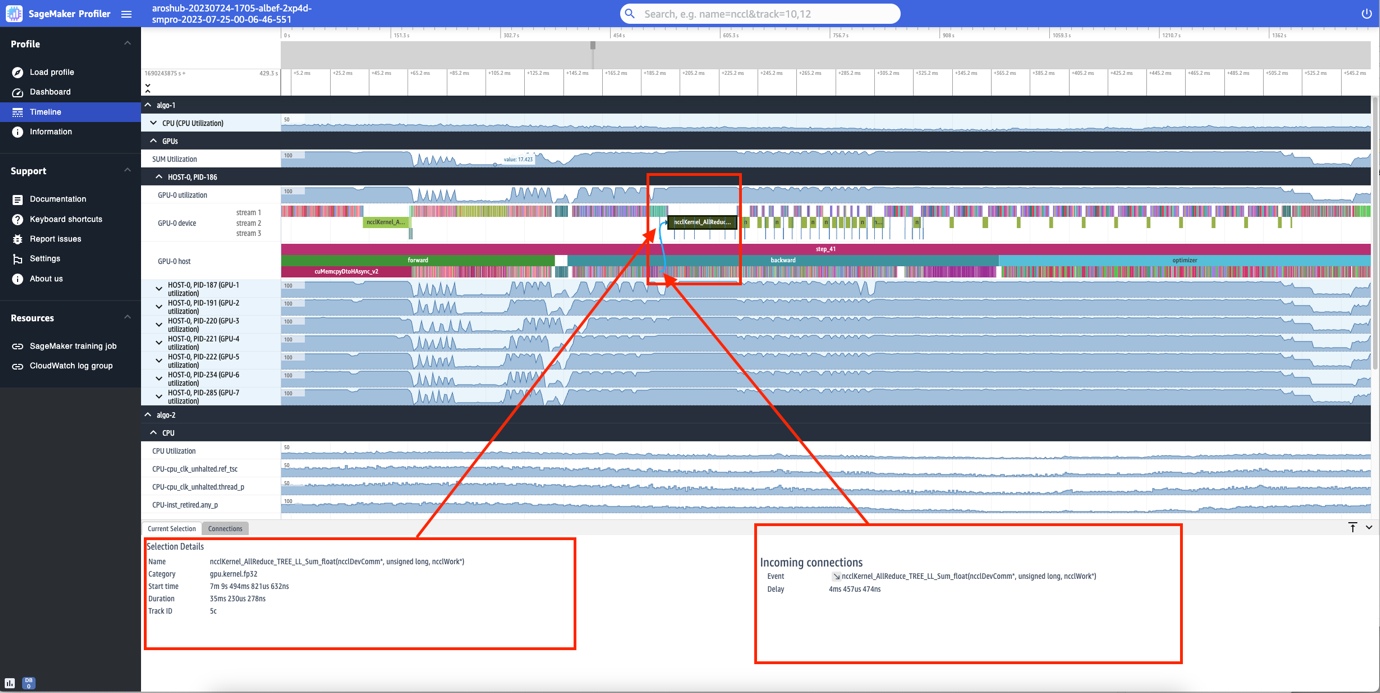
개별 단계를 확대할 수도 있습니다. 다음 스크린샷에서는 step_41을 확대했습니다. 다음 스크린샷에서 선택한 타임라인 스트립은 GPU-0에서 실행되는 분산 훈련의 필수 통신 및 동기화 단계인 AllReduce 작업입니다. 스크린샷에서 GPU-0 호스트의 커널 실행은 하늘색 화살표로 표시된 GPU-0 장치 스트림 1의 커널 실행에 연결됩니다.
가용성 및 고려 사항
SageMaker 프로파일러는 PyTorch(버전 2.0.0 및 1.13.1) 및 TensorFlow(버전 2.12.0 및 2.11.1)에서 사용할 수 있습니다. 다음 표에서는 SageMaker에 대해 지원되는 AWS Deep Learning Containers 에 대한 링크를 제공합니다 .
| 프레임워크 | 버전 | AWS DLC 이미지 URI |
| Pytorch | 2.0.0 | 763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| Pytorch | 1.13.1 | 763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:1.13.1-gpu-py39-cu117-ubuntu20.04-sagemaker |
| TensorFlow | 2.12.0 | 763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:2.12.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| TensorFlow | 2.11.1 | 763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:2.11.1-gpu-py39-cu112-ubuntu20.04-sagemaker |
SageMaker Profiler의 성능
SageMaker Profiler의 오버헤드를 다양한 오픈 소스 프로파일러와 비교했습니다. 비교에 사용된 기준은 프로파일러 없이 훈련 작업을 실행하여 얻은 것입니다. 저희의 주요 조사 결과에 따르면 SageMaker Profiler는 종단 간 훈련 실행에서 오버헤드 시간이 적기 때문에 일반적으로 청구 가능한 훈련 기간이 더 짧아졌습니다. 또한 오픈 소스 대안과 비교할 때 더 적은 프로파일링 데이터(최대 10배 더 적음)를 생성했습니다. SageMaker Profiler에서 생성된 더 작은 프로파일링 아티팩트에는 더 적은 스토리지가 필요하므로 비용도 절약됩니다.
SageMaker Profiler를 사용하면 딥 러닝 모델을 훈련할 때 컴퓨팅 리소스 활용에 대한 자세한 통찰력을 얻을 수 있습니다. 이를 통해 성능 핫스팟과 병목 현상을 해결하여 효율적인 리소스 활용을 보장하여 궁극적으로 훈련 비용을 절감하고 전체 학습 기간을 단축할 수 있습니다.
미리보기 출시
Amazon SageMaker Profiler는 현재 미국 동부(오하이오, 버지니아 북부), 미국 서부(오레곤) 및 유럽(아일랜드 프랑크푸르트) 리전에서 사용할 수 있습니다. SageMaker Profiler는 훈련 인스턴스 유형 ml.p4d.24xlarge, ml.p3dn.24xlarge 및 ml.g4dn.12xlarge에서 사용할 수 있습니다. 지원되는 프레임워크 및 버전의 전체 목록은 설명서를 참조하세요.
SageMaker Profiler에는 SageMaker 프리 티어 또는 해당 기능의 무료 미리보기 기간이 종료된 후, 요금이 부과됩니다. 자세한 내용은 Amazon SageMaker 요금 페이지를 참고하시기 바랍니다.
– Roy Allela, Senior AI/ML Specialist Solutions Architect, AWS
– Sushant Moon, Data Scientist, AWS
– Diksha Sharma, AI/ML Specialist Solutions Architect, AWS
이 글은 AWS Machine Learning Blog의 Announcing the Preview of Amazon SageMaker Profiler: Track and visualize detailed hardware performance data for your model training workloads 한국어 번역입니다.