Amazon Web Services 한국 블로그
Amazon SageMaker Factorization Machines 알고리즘을 확장하여 추천 시스템 구현하기
Amazon SageMaker는 기계 학습 워크로드와 관련한 복잡한 비즈니스 문제를 해결하는 데 필요한 유연성을 제공합니다. 내장된 알고리즘은 빠르게 시작하는 데 도움이 됩니다. 이 블로그 게시물에서는 내장된 Factorization Machines 알고리즘을 확장하여 상위 x개의 권장 사항을 예측하는 방법을 설명합니다.이 접근 방식은 정해진 수의 사용자 권장 사항을 배치 형식으로 생성하려고 할 때 이상적입니다. 예를 들어, 이 접근 방식을 사용하여 대규모 세트의 사용자 및 제품 구매 정보에서 특정 사용자가 구매할 가능성이 높은 상위 20개 제품을 생성할 수 있습니다. 그런 다음 추후 대시보드 표시 또는 개인화된 이메일 마케팅에 사용하기 위해 권장 사항을 데이터베이스에 저장할 수 있습니다. 또한 주기적인 재훈련 및 예측을 위해 AWS Batch 또는 AWS Step Functions를 사용하여 이 블로그에 설명된 단계를 자동화할 수 있습니다.Factorization Machines는 모든 종류의 분류 및 회귀 작업 에 사용할 수 있는 범용 지도 학습 알고리즘입니다. 추천 시스템을 위한 엔진으로 설계되었던 이 알고리즘은 기존 기능 위에 이차 함수를 학습하는 동시에 이차 계수를 저등급 구조에 제한하는 방식으로 협업적 필터링 접근 방식을 확장합니다. 이러한 제한은 과다 적합을 방지하며 뛰어난 확장성을 제공하여 대규모의 스파스 데이터(sparse data)에 매우 적합하므로 수 백만 개의 입력 기능을 가진 전형적인 권장 문제가 수 조 개가 아닌 수 백만 개의 파라미터를 가질 수 있습니다.
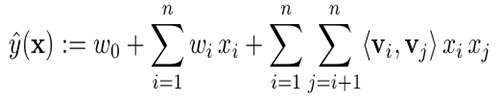
산출할 모델 파라미터는 다음과 같습니다.
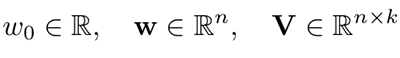
여기서, n은 입력 크기이며 k 는 잠재 공간의 크기입니다. 이렇게 산출된 모델 파라미터는 모델을 확장하는 데 사용됩니다.
모델 확장
Amazon SageMaker Factorization Machines 알고리즘을 사용하면 사용자, 항목 같은 쌍에 대하여 해당 쌍이 얼마나 일치하는지를 기반으로 점수를 예측할 수 있습니다. 권장 사항 모델을 적용할 때에는 종종 사용자를 입력으로 제공하고 해당 사용자의 선호 사항과 가장 잘 일치하는 상위 x개 항목의 목록을 얻고자 할 수 있습니다. 항목 수가 많지 않을 경우에는 모든 가능한 항목에 대해 사용자, 항목을 쿼리하여 이러한 결과를 얻을 수 있습니다. 그러나 이 접근 방식은 항목 수가 많을 경우 제대로 확장이 되지 않습니다. 이 시나리오에서는 Amazon SageMaker K-Nearest Neighbors(k-NN) 알고리즘을 사용하여 상위 x개를 예측하는 작업을 가속화활 수 있습니다.
다음 다이어그램은 Factorization Machines 모델 구축, 모델 데이터 리패키징, k-NN 모델 피팅 및 상위 x개 예측 생산 등 이 블로그 게시물에서 다루고 있는 단계의 고수준 개요를 제공합니다.

함께 제공되는 Jupyter 노트북을 다운로드하여 참조할 수도 있습니다. 다음의 각 섹션은 노트북에 있는 섹션과 일치하므로 각 단계를 읽으면서 코드를 실행할 수 있습니다.
1 단계: Factorization Machines 모델 구축
Factorization Machines 모델 구축을 위한 단계는 함께 제공되는 Jupyter 노트북의 파트 1을 참조하십시오. Factorization Machines 모델 구축에 대한 자세한 내용은 Factorization Machines 설명서를 참조하십시오.
2 단계: 모델 데이터 리패키징
Amazon SageMaker Factorization Machines 알고리즘은 Apache MXNet 딥러닝 프레임워크를 활용합니다. 이 섹션에서는 MXNet을 사용하여 모델 데이터를 리패키징하는 방법을 다룹니다.
Factorization Machines 모델 추출
먼저, MXNet 객체를 구성하기 위해 Factorization Machines 모델을 다운로드한 다음 압축을 해제합니다. MXNet 객체의 주된 용도는 모델 데이터를 추출하는 것입니다.
모델 데이터 추출
Factorization Machines 모델에 대한 입력은 사용자 u 및 항목 i를 나타내는 벡터 xu + xi와 레이블(영화에 대한 사용자 평점)이 결합된 목록입니다. 그 결과로 구성된 입력 매트릭스는 사용자, 항목 및 그 이에 추가할 기능에 대한 스파스 원핫(sparse one-hot) 인코딩된 값을 포함합니다.
Factorization Machines 모델 출력은 세 개의 N차원 배열(ndarrays)로 구성됩니다.
- V – N x k 매트릭스:
- k = 잠재 공간의 차원
- N = 사용자 및 항목의 총 개수
- w – N차원 벡터
- b – 단일 숫자: 편향 항
아래 단계를 완료하여 MXNet 객체에서 모델 출력을 추출합니다.
k-NN 모델 구축을 위한 데이터 준비
이제 Factorization Machines 모델에서 추출된 모델 데이터를 k-NN 모델 구축을 위해 리패키징할 수 있습니다. 이 프로세스는 두 가지의 데이터 세트를 생성합니다.
- 항목 잠재 매트릭스 – k-NN 모델 구축용
- 사용자 잠재 매트릭스 – 추론용
3 단계: k-NN 모델 피팅
이제 k-NN 모델 입력 데이터를 Amazon S3에 업로드하고, k-NN 모델을 생성한 다음 Amazon SageMaker에서 사용할 수 있도록 이를 저장할 수 있습니다. 이 모델은 아래 단계에 서명된 대로 배치 변환을 호출할 때에도 유용합니다.
k-NN 모델은 기본 mindex_type(faiss.Flat)을 사용합니다. 이 모델은 정확도가 높지만 대형 데이터 세트의 경우 속도가 느릴 수 있습니다. 그러한 경우 정확도는 조금 떨어지지만 더 빠른 답변을 제공하도록 다른 index_type 파라미터를 사용하기를 원할 수 있습니다. 인덱스 유형에 대한 자세한 내용은 k-NN 설명서 또는 이 Amazon Sagemaker 예제 노트북을 참조하십시오.
4 단계: 모든 사용자에 대한 추천 시스템 구현
Amazon SageMaker 배치 변환 기능을 사용하면 대규모로 배치 예측을 생성할 수 있습니다. 이 예에서는 사용자 추론 입력을 Amazon S3에 업로드하는 것으로 시작한 다음 배치 변환을 트리거합니다.
결과 출력 파일은 모든 사용자에 대한 예측을 포함합니다. 출력 파일의 각 라인 항목은 항목 ID 및 특정 사용자에 대한 거리를 포함하는 JSON 라인입니다.
다음은 특정 사용자에 대한 샘플 출력입니다. 권장 영화 ID를 데이터베이스에 저장하여 나중에 사용할 수 있습니다.
다중 기능 및 범주 시나리오
이 블로그의 프레임워크는 사용자 및 항목 ID가 있는 시나리오에 적용됩니다. 그러나 데이터는 사용자 및 항목 기능과 같은 추가 정보를 포함할 수 있습니다. 예를 들어, 사용자의 나이, 우편 번호 또는 성별에 대한 정보를 가지고 있을 수 있습니다. 항목의 경우 범주, 영화 장르 또는 텍스트 설명에 있는 중요 키워드를 가지고 있을 수 있습니다. 이러한 다중 기능 및 범주 시나리오에서는 다음을 사용하여 사용자 및 항목 벡터를 추출할 수 있습니다.
- 사용자 및 사용자 기능 모두를 사용하여 xi를 인코딩합니다.
ai =concat(VT · xi , wT · xi) - 항목 및 항목 기능을 사용하여 xu를 인코딩합니다.
au =concat(VT · xu, 1)
그런 다음 ai를 사용하여 k-NN model을 구축하고 au를 추론에 사용합니다.
결론
Amazon SageMaker는 개발자 및 데이터 과학자가 기계 학습 모델을 빠르게 구축, 훈련 및 배포할 수 있는 유연성을 제공합니다. 위에 설명된 프레임워크를 사용하면 배치 방식으로 사용자에 대한 상위 x개 권장 사항을 예측하는 추천 시스템을 구축하고 출력을 데이터베이스로 캐싱할 수 있습니다. 어떤 경우에는 주어진 기간의 사용자 응답을 기반으로 예측에 대해 추가 필터링을 적용하거나 일부 예측을 필터링해야 할 수 있습니다. 이 프레임워크는 그러한 사용 사례를 수정하기에 충분한 유연성을 제공합니다.
작성자 소개
 Zohar Karnin은 Amazon AI 수석 과학자입니다. 그의 연구 분야에는 대규모 및 온라인 기계 학습 알고리즘이 포함되어 있습니다. 그는 Amazon SageMaker를 위한 무한 확장 가능한 기계 학습 알고리즘을 개발하고 있습니다.
Zohar Karnin은 Amazon AI 수석 과학자입니다. 그의 연구 분야에는 대규모 및 온라인 기계 학습 알고리즘이 포함되어 있습니다. 그는 Amazon SageMaker를 위한 무한 확장 가능한 기계 학습 알고리즘을 개발하고 있습니다.
 Rama Thamman은 전략 계정 팀의 선임 솔루션 아키텍트입니다. 그는 고객과 협력하면서 AWS 기반의 확장 가능한 클라우드 및 기계 학습 솔루션을 개발합니다.
Rama Thamman은 전략 계정 팀의 선임 솔루션 아키텍트입니다. 그는 고객과 협력하면서 AWS 기반의 확장 가능한 클라우드 및 기계 학습 솔루션을 개발합니다.
이 글은 AWS Machine Learning Blog의 Extending Amazon SageMaker factorization machines algorithm to predict top x recommendations의 한국어 번역으로 정도현 AWS 테크니컬 트레이너가 감수하였습니다.