Amazon Web Services 한국 블로그
Parquet 형식의 EMRFS S3 최적화 커미터를 통한 Apache Spark 쓰기 성능 개선하기
EMRFS S3 최적화 커미터는 Amazon EMR 5.19.0부터 Apache Spark 작업에 사용할 수 있는 새로운 출력 커미터입니다. 이 커미터는 EMRFS(EMR 파일 시스템)을 사용하는 Amazon S3에 Apache Parquet 파일을 쓸 때의 성능을 개선합니다.
이 게시물에서는 최근 성능 벤치마크를 실행하여 신규 최적화된 커미터를 기존 커미터 알고리즘(FileOutputCommitter 알고리즘 버전 1 및 2)과 비교하여 어떻게 Spark 쓰기 성능이 개선되었는지 알아봅니다. 실제 사용 시, 제약 사항에 대해 설명하고 가능한 해결 방법을 제시해 드리고자 합니다.
EMRFS S3와 FileOutputCommitter와 비교
Amazon EMR 버전 5.19.0 이하에서는 Amazon S3에 Parquet를 쓰는 Spark 작업에는 기본적으로 FileOutputCommitter라고 하는 Hadoop 커밋 알고리즘이 사용해 왔습니다. 이 알고리즘에는 버전 1과 버전 2의 두 가지 버전이 있습니다. 두 버전 모두 임시 위치에 중간 작업 출력을 쓰는 방법을 활용합니다. 그런 다음 이름 바꾸기 작업을 수행하여 작업 완료 시간에 데이터를 표시합니다.
알고리즘 버전 1에는 두 가지 단계의 이름 바꾸기가 있습니다. 개별 작업 출력을 커밋하는 단계와 전체 작업 출력을 커밋하는 단계입니다. 알고리즘 버전 2는 작업의 이름 바꾸기 파일이 최종 출력 위치로 직접 커밋되기 때문에 더 효율적입니다. 두 번째 이름 바꾸기 단계가 제거되지만 작업이 완료되기 전에는 일부 데이터만 표시되므로 모든 워크로드에 적합한 것은 아닙니다.
이름 바꾸기 작업은 HDFS(Hadoop 분산 파일 시스템)에서 빠르게 수행되는 메타데이터 전용 작업입니다. 그러나 Amazon S3 같은 객체 스토어에 출력을 쓰는 경우 이름 바꾸기는 데이터를 대상에 복사한 후 소스를 삭제하는 방식으로 구현됩니다. FileOutputCommitter v1의 두 단계에서 수행될 수 있는 디렉터리 이름 바꾸기에서는 이 이름 바꾸기 “페널티”가 더 심해집니다. 이러한 작업은 HDFS에서 수행되는 단일의 메타데이터 전용 작업이지만 커미터는 S3에서 N개의 복사 후 삭제 작업을 실행해야 합니다.
이 페널티를 부분적으로 완화하기 위해 Amazon EMR 5.14.0+는 Spark에서 EMRFS를 사용하는 S3에 Parquet 데이터를 쓸 때 FileOutputCommitter v2로 기본 설정됩니다. 새로운 EMRFS S3 최적화된 커미터는 Amazon S3 멀티파트 업로드의 트랜잭션 속성을 사용하여 이름 바꾸기 작업을 완전히 방지하도록 이 작업을 개선합니다. 작업의 데이터는 최종 출력 위치에 직접 기록되며 각 출력 파일의 완료는 작업 커밋 시간까지 연기됩니다.
커미터간 성능 테스트
다음과 같은 INSERT OVERWRITE Spark SQL 쿼리를 실행하여 다양한 커미터의 쓰기 성능을 평가했습니다. SELECT * FROM range(…) 절은 실행 시간에 데이터를 생성했습니다. Amazon S3에 있는 정확히 100개의 Parquet 파일 전체에 걸쳐 약 15GB의 데이터가 생성되었습니다.
참고: EMR 클러스터는 S3 버킷과 동일한 AWS 리전에서 실행되었습니다. trial_id 속성에는 테스트 실행 간의 충돌을 방지하기 위해 UUID 생성기가 사용되었습니다.
emr-5.19.0 릴리스 레이블로 생성된 EMR 클러스터에서 마스터 그룹의 단일 m5d.2xlarge 인스턴스와 코어 그룹의 m5d.2xlarge 인스턴스 8개를 사용하여 테스트를 실행했습니다. 이 클러스터 구성에는 Amazon EMR을 통해 설정된 기본 Spark 구성 속성이 사용되었으며 여기에는 다음이 포함됩니다.
각 커미터에 대한 10개의 평가판을 실행한 후 쿼리 실행 시간을 캡처하고 다음과 같은 차트에 요약했습니다. FileOutputCommitter v2의 평균은 49초였지만 EMRFS S3 최적화된 커미터의 평균은 31초로, 1.6배 빨랐습니다.
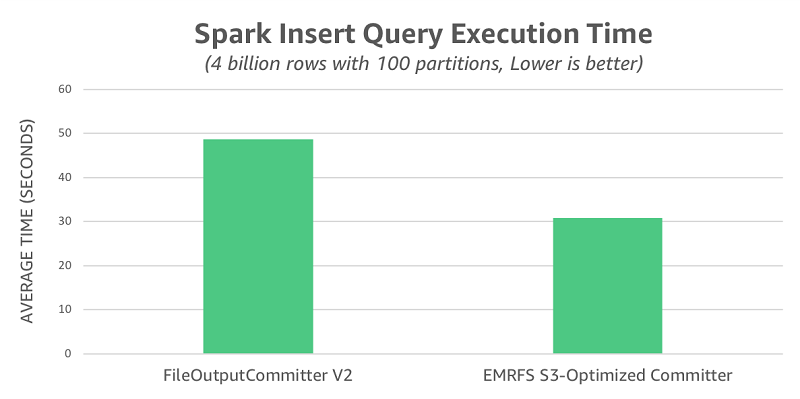
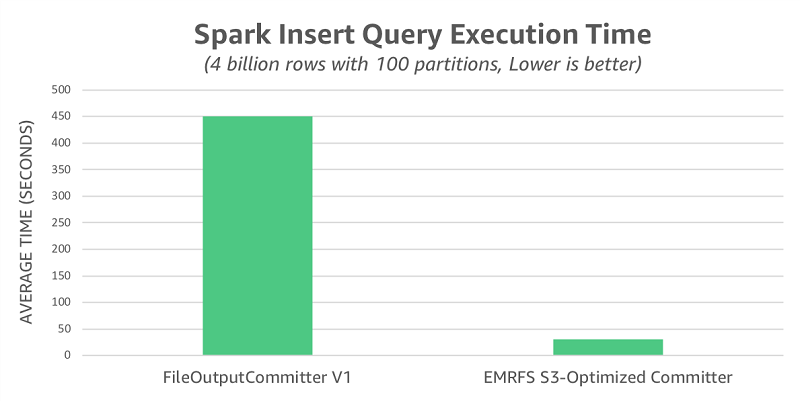
앞서 언급한 대로 FileOutputCommitter v2는 FileOutputCommitter v1에 사용되는 이름 바꾸기 작업을 일부 제거합니다. 이름 바꾸기 작업이 S3의 성능에 미치는 전체적인 영향을 설명하기 위해 FileOutputCommitter v1을 사용하여 테스트를 다시 실행했습니다. 이 시나리오에서는 EMRFS S3 최적화된 커미터보다 14.5배 느린 평균 450초의 런타임이 관찰되었습니다.
마지막으로 평가한 시나리오는 Amazon S3 데이터 일관성 모델로 인해 발생할 수 있는 문제를 해결하는 EMRFS 일관성 보기가 활성화된 경우입니다. 이 모드에서 EMRFS S3 최적화된 커미터 시간은 이 변경의 영향을 받지 않았고 여전히 평균 30초였습니다. 반면, FileOutputCommitter v2의 평균은 일관성 보기 기능이 비활성화되었을 때보다 느린 53초로, 전반적인 성능 차이가 1.8배까지 넓어졌습니다.

몇 가지 제약 사항
EMRFS S3 최적화된 커미터의 제약 사항은 기존의 FileOutputCommitter v2와 같습니다. 두 커미터 모두 커밋 책임을 개별 작업에 완전히 위임함으로써 성능을 개선하기 때문입니다. 다음은 이 설계를 선택할 때의 주목할 만한 결과를 설명한 것입니다.
1. 불완전하거나 실패한 작업의 부분적인 결과
두 커미터 모두 작업을 최종 출력 위치에 쓰기 때문에 판독기에서 둘 중 하나를 사용하여 해당 출력 위치를 동시에 읽는 경우 부분적인 결과가 표시될 수 있습니다. 작업이 실패하는 경우 전체 작업이 실패하기 전에 커밋된 작업의 부분적인 결과가 남습니다. 이 상황에서 출력 위치를 정리하지 않고 작업을 다시 실행하면 출력이 중복될 수 있습니다.
이 문제를 완화하는 한 가지 방법은 작업을 실행할 때마다 다른 출력 위치를 사용하여 작업이 성공하는 경우에만 다운스트림 판독기에 위치를 게시하는 것입니다. 다음 코드 블록은 Hive 테이블을 사용하는 워크로드에 대한 이 전략의 예제입니다. output_location은 작업이 실행될 때마다 고유한 값으로 설정되며 테이블 파티션은 나머지 쿼리가 성공하는 경우에만 등록됩니다. 판독기가 테이블 추상화를 통해 단독으로 데이터에 액세스하는 경우 작업이 완료되기 전에 결과가 표시되지 않습니다.
이 접근 방식에서는 파티션이 가리키는 위치를 변경 불가능한 위치로 처리해야 합니다. 파티션 콘텐츠를 업데이트하려면 모든 결과의 위치를 S3의 새 위치로 다시 지정한 다음 새 위치를 가리키도록 파티션 메타데이터를 업데이트해야 합니다.
2. 비멱등성 작업의 중복된 결과
두 커미터에서 잘못된 결과가 생성되는 또 다른 시나리오는 비멱등성 작업으로 구성된 작업의 출력이 각 작업 시도 시 비결정적 위치에 생성될 때입니다.
다음은 이 문제를 보여주는 쿼리의 예제입니다. 이 쿼리는 각 작업이 시도될 때마다 다른 위치에 출력을 쓰기 위해 타임스탬프 기반 테이블 파티셔닝 스키마를 사용합니다.
이 시나리오에서 결과가 중복되는 문제를 방지하려면 전체 작업 시도에서 일관된 위치에 결과를 쓰면 됩니다. 예를 들어 작업 내에서 현재 타임스탬프를 반환하는 함수를 호출하는 대신 현재 타임스탬프를 작업의 입력으로 제공할 수 있습니다. 마찬가지로 작업 내에서 난수 생성기를 사용하는 경우 고정 시드 또는 작업의 파티션 번호에 따른 시드를 사용하여 작업을 재시도할 때 동일한 값이 사용되도록 할 수 있습니다.
참고: Spark의 기본 제공되는 난수 함수인 rand(), randn() 및 uuid()는 이를 염두에 두고 설계되었습니다.
EMRFS S3 최적화 커미터 사용해 보기
Amazon EMR 버전 5.20.0 이상에서는 EMRFS S3 최적화된 커미터가 기본적으로 활성화됩니다. Amazon EMR 버전 5.19.0에서는 Spark 내에서 또는 클러스터를 생성할 때 spark.sql.parquet.fs.optimized.committer.optimization-enabled 속성을 true로 설정하여 커미터를 활성화할 수 있습니다.
커미터는 Spark의 기본 제공되는 Parquet 지원을 사용하여 EMRFS를 사용하는 Amazon S3에 Parquet 파일을 쓸 때 적용됩니다. Parquet 데이터 원본을 Spark SQL, DataFrames 또는 Datasets와 함께 사용할 때도 마찬가지입니다. 그러나 일부 사용 사례에서는 EMRFS S3 최적화된 커미터가 적용되지 않으며 Spark가 자체 이름 바꾸기 작업을 완전히 커미터 외부에서 수행하는 사용 사례도 있습니다.
커미터 및 이러한 특수한 사례에 대한 자세한 내용은 Amazon EMR 출시 안내서에서 EMRFS S3 최적화된 커미터 사용을 참조하십시오.
향후 작업 – S3A 커미터 개발
EMRFS S3 최적화된 커미터는 S3A 파일 시스템을 지원하는 커미터에 사용된 개념에서 영감을 얻었습니다. 주요 요점은 이러한 커미터가 S3 멀티파트 업로드의 트랜잭션 속성을 사용하여 이름 바꾸기로 인한 성능 저하의 일부 또는 전부를 제거한다는 것입니다. 이 또한 EMRFS S3 최적화된 커미터에 사용된 핵심 개념입니다.
S3A 파일 시스템을 지원하는 커미터를 비롯하여 에코시스템 내에서 사용 가능한 다양한 커미터에 대한 자세한 내용은 공식 Apache Hadoop 설명서를 참조하십시오.
요약
EMRFS S3 최적화된 커미터는 FileOutputCommitter보다 개선된 쓰기 성능을 제공합니다. Amazon EMR 버전 5.19.0 이상에서는 Spark의 기본 제공되는 Parquet 지원을 통해 이 커미터를 사용할 수 있습니다. 자세한 내용은 Amazon EMR 릴리스 안내서에서 EMRFS S3 최적화된 커미터 사용을 참조하십시오.
– Peter Slawski, Jonathan Kelly, AWS 소프트웨어 개발 엔지니어
이 글은 AWS Bigdata 블로그 Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer의 한국어 번역입니다.