Amazon Web Services 한국 블로그
Amazon SageMaker HyperPod, Checkpointless 및 Elastic Training 기능 출시
오늘 Amazon SageMaker HyperPod의 2가지 새로운 AI 모델 훈련 기능을 발표합니다. 하나는 피어 투 피어(P2P) 상태 복구를 지원하여 기존 체크포인트 기반 복구의 필요성을 줄이는 접근 방식인 체크포인트리스 훈련(Checkpointless Training)이고, 다른 하나는 리소스 가용성에 따른 AI 워크로드 자동 조정이 지원되는 탄력적 훈련 (Elastic Training)입니다.
- 체크포인트리스 훈련 – 체크포인트리스 훈련은 중단을 유발하는 체크포인트 재시작 주기를 없애고, 장애 발생 시에도 지속적인 훈련이 가능해 복구 시간을 몇 시간에서 몇 분으로 단축합니다. AI 모델 개발을 가속화하고, 개발 일정에서 여유를 확보하고, 훈련 워크플로를 수천 개의 AI 액셀러레이터로 확장할 수 있습니다.
- 탄력적 훈련 – 탄력적 훈련은 훈련 워크로드가 사용 가능한 상태가 된 유휴 용량을 사용하도록 자동으로 확장되고, 추론 볼륨과 같이 우선 순위가 높은 워크로드가 최대치에 도달하면 리소스를 활용하도록 축소되므로 클러스터 활용도가 극대화됩니다. 컴퓨팅 가용성에 따라 훈련 작업을 재구성하는 데 소요되는 주당 엔지니어링 시간을 절약할 수 있습니다.
새로운 훈련 기술을 사용하면 교육 인프라 관리에 시간을 보내는 대신 팀이 모델 성능 향상에 전적으로 집중할 수 있어 결과적으로 AI 모델을 더 빠르게 시장에 출시할 수 있습니다. 기존의 체크포인트 종속성을 없애고 가용 용량을 최대한 활용하면서 모델 훈련 완료 시간을 크게 줄일 수 있습니다.
체크포인트리스 훈련: 작동 방식
기존의 체크포인트 기반 복구에는 1) 작업 종료 및 재시작, 2) 프로세스 검색 및 네트워크 설정, 3) 체크포인트 검색, 4) 데이터 로더 초기화, 5) 교육 루프 재개라는 순차적인 작업 단계가 있습니다. 장애가 발생하면 각 단계에 병목 현상이 발생할 수 있고 자체 관리형 훈련 클러스터에서는 복구에 최대 1시간이 걸릴 수 있습니다. 전체 클러스터는 모든 단일 단계가 완료될 때까지 기다려야 훈련을 재개할 수 있습니다. 이로 인해 복구 작업 중에는 전체 훈련 클러스터가 유휴 상태가 되기에 이로 인해 비용이 증가하고 출시 기간이 길어질 수 있습니다.
체크포인트리스 훈련은 훈련 클러스터 전체에 걸쳐 지속적인 모델 상태 보존을 유지하여 이러한 병목 현상을 완전히 없앱니다. 장애가 발생하면 정상 피어를 사용하여 시스템이 즉시 복구되기에 전체 작업을 다시 시작해야 하는 체크포인트 기반 복구가 필요하지 않습니다. 따라서 체크포인트리스 훈련은 몇 분 만에 장애 복구가 가능합니다.
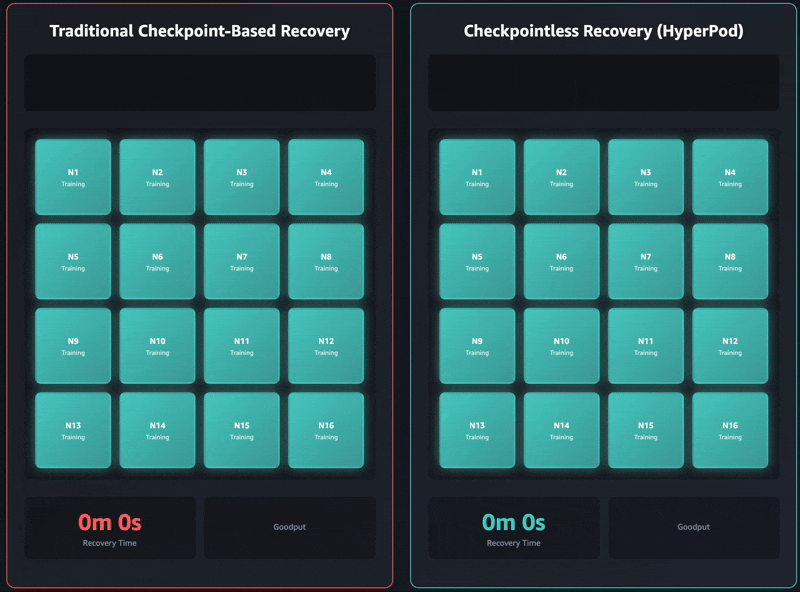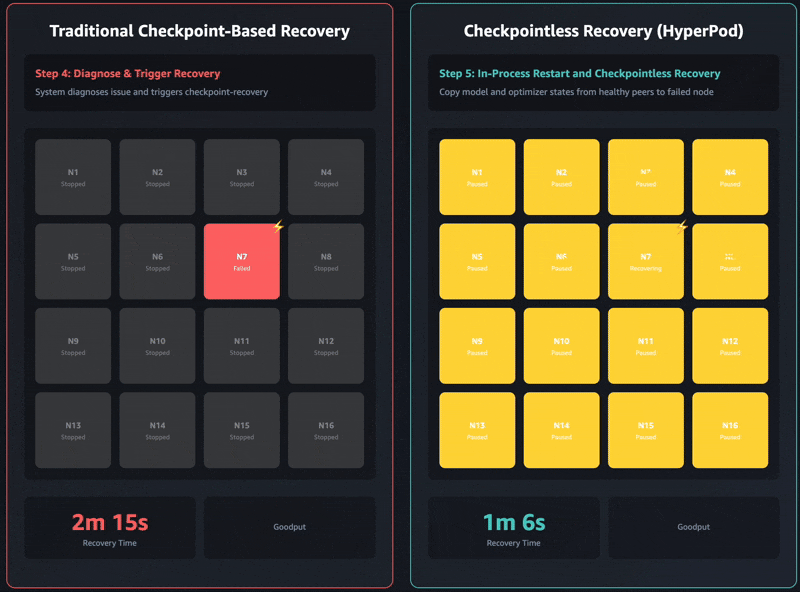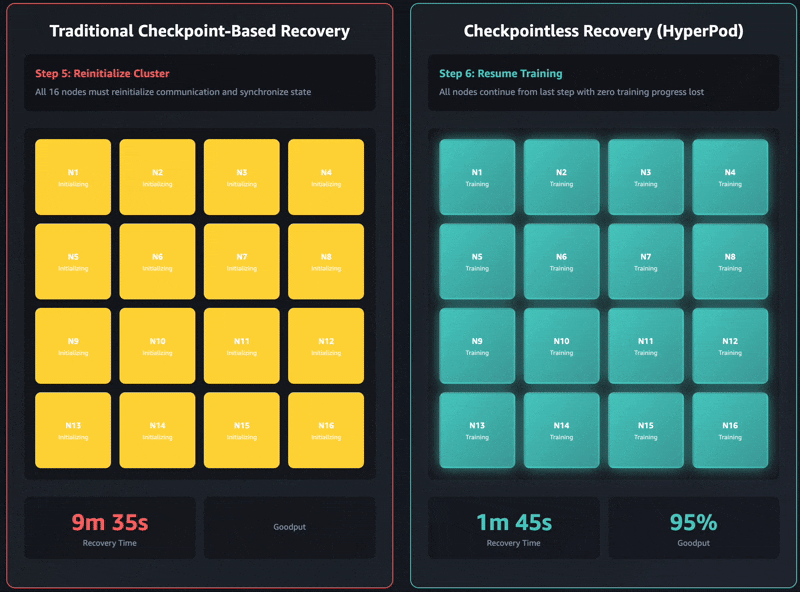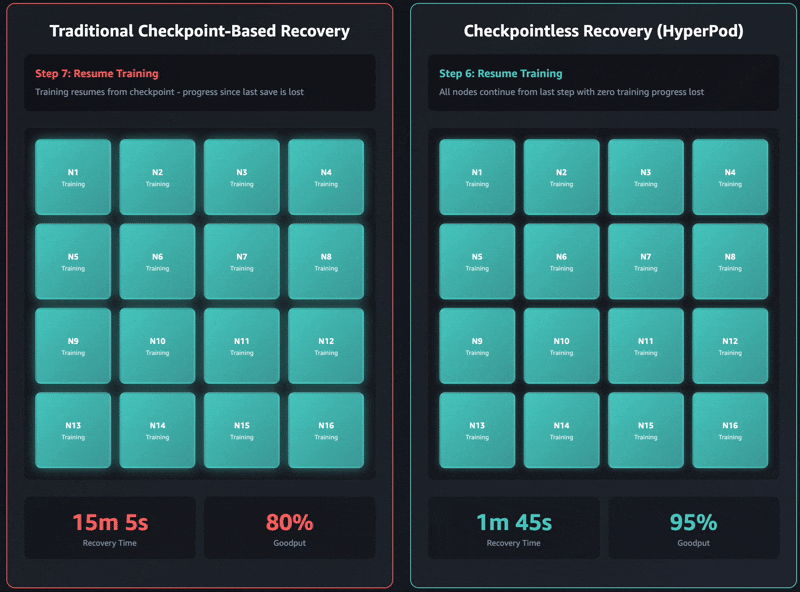
체크포인트리스 훈련은 점진적 도입에 맞춰 설계되었고, 1) 집단적 통신 초기화 최적화, 2) 캐싱을 지원하는 메모리 매핑된 데이터 로딩, 3) 프로세스 내 복구, 4) 체크포인트리스 P2P 상태 복제라는 함께 작동하는 4가지 핵심 구성 요소를 기반으로 합니다. 이러한 구성 요소는 작업 시작에 사용되는 HyperPod Training Operator를 통해 조정됩니다. 각 구성 요소는 복구 프로세스의 특정 단계를 최적화하고, 이를 함께 사용하면 수천 개의 AI 액셀러레이터를 사용하더라도 수동 개입 없이 몇 분 만에 인프라 결함을 자동으로 감지 및 복구할 수 있습니다. 훈련 규모가 커짐에 따라 각 기능을 점진적으로 활성화할 수 있습니다.
최신 Amazon Nova 모델은 수만 개의 액셀러레이터에서 이 기술을 사용하여 훈련되었습니다. 추가로 16개 GPU에서 2,000개 이상의 GPU에 이르는 클러스터 크기와 관련된 내부 연구에 따르면 체크포인트리스 훈련이 기존 체크포인트 기반 복구에 비해 가동 중지 시간을 80% 이상 줄여 복구 시간이 크게 개선된 것으로 나타났습니다.
자세히 알아보려면, Checkpointless training GitHub page 및 Amazon SageMaker AI 개발자 안내서의 HyperPod Checkpointless Training를 참조하세요.
탄력적 훈련: 작동 원리
다양한 유형의 최신 AI 워크로드를 실행하는 클러스터에서는 단기 훈련 실행이 완료되거나, 추론이 급증 또는 급감하거나, 완료된 실험에서 리소스가 확보되는 가운데 액셀러레이터 가용성이 지속적으로 변할 수 있습니다. 이러한 AI 액셀러레이터의 동적 가용성에도 불구하고 기존 훈련 워크로드는 초기 컴퓨팅 할당에 종속되어 수동 개입 없이는 유휴 액셀러레이터를 활용할 수 없습니다. 이러한 경직성으로 인해 소중한 GPU 용량을 사용하지 못하게 하고 조직의 인프라 투자가 극대화되지 못합니다.
 탄력적 훈련은 훈련 워크로드와 클러스터 리소스와의 상호 작용 방식을 변화시킵니다. 훈련 작업은 훈련 품질을 유지하면서 사용 가능한 액셀러레이터를 활용하도록 자동으로 확장하고, 다른 곳에 리소스가 필요할 때는 적절하게 축소할 수 있습니다.
탄력적 훈련은 훈련 워크로드와 클러스터 리소스와의 상호 작용 방식을 변화시킵니다. 훈련 작업은 훈련 품질을 유지하면서 사용 가능한 액셀러레이터를 활용하도록 자동으로 확장하고, 다른 곳에 리소스가 필요할 때는 적절하게 축소할 수 있습니다.
워크로드 탄력성은 Kubernetes 컨트롤 플레인 및 Resource Scheduler와의 통합을 통해 규모 조정 결정을 조율하는 HyperPod Training Operator를 통해 지원됩니다. 포드 수명 주기 이벤트, 노드 가용성 변경, Resource Scheduler 우선 순위 신호라는 3가지 기본 채널을 통해 클러스터 상태를 지속적으로 모니터링합니다. 이 포괄적 모니터링을 통해 새로 사용 가능한 리소스든 우선 순위가 높은 워크로드의 요청에서든 관계없이 규모 조정 기회를 거의 즉각적으로 탐지할 수 있습니다.
규모 조정 메커니즘은 데이터 병렬 복제본의 추가 및 제거를 활용합니다. 추가 컴퓨팅 리소스를 사용할 수 있게 되면 새로운 데이터 병렬 복제본이 훈련 작업에 추가되어 처리량을 높입니다. 반대로 축소 이벤트(예: 우선 순위가 높은 워크로드에서 리소스를 요청하는 경우) 시에는 전체 작업을 종료하는 대신 복제본을 제거하여 시스템이 축소되므로 줄어든 용량으로 훈련을 계속할 수 있습니다.
시스템은 다양한 규모에서 전체 배치 크기를 보존하고 학습 속도를 조정하여 모델 수렴에 부정적인 영향을 미치지 않도록 합니다. 덕분에 수동 개입 없이도 사용 가능한 AI 액셀러레이터를 활용하도록 워크로드를 동적으로 확장 또는 축소할 수 있습니다.
Llama 및 GPT-OSS를 포함하여 공개적으로 사용 가능한 파운데이션 모델(FM)에 대한 HyperPod 레시피를 통해 탄력적 훈련을 시작할 수 있습니다. 추가로 PyTorch 훈련 스크립트를 수정하여 작업을 동적으로 규모를 조정할 수 있는 탄력적 이벤트 핸들러를 추가할 수 있습니다.
자세히 알아보려면 Amazon SageMaker AI 개발자 안내서의 HyperPod 탄력적 훈련을 참조하세요. 시작하려면 AWS GitHub 리포지토리에서 제공되는 HyperPod 레시피를 찾아보세요.
지금 이용 가능
두 기능 모두 Amazon SageMaker HyperPod를 사용할 수 있는 모든 리전에서 사용할 수 있습니다. 추가 비용 없이도 이러한 훈련 기술을 사용할 수 있습니다. 자세히 알아보려면 SageMaker HyperPod 제품 페이지 및 SageMaker AI 요금 페이지를 방문하세요.
사용해 보시고 AWS re:Post for SageMaker 또는 일반 AWS Support 문의로 피드백을 보내주세요.
– Channy