Amazon Web Services 한국 블로그
Amazon SageMaker 차세대 노트북 – 데이터 준비, 실시간 협업 및 노트북 자동화 기능 내장
2019년 당사는 데이터 과학 및 기계 학습(ML)을 위한 최초의 완전 통합 개발 환경(IDE)인 Amazon SageMaker Studio를 도입했습니다. SageMaker Studio를 사용하면 전용 도구와 통합되어 데이터 준비부터 모델 학습 및 디버깅, 실험 추적, 모델 배포 및 모니터링, 파이프라인 관리에 이르기까지 모든 ML 단계를 수행하는 완전 관리형 Jupyter Notebook에 액세스할 수 있습니다.
오늘 ML 개발 워크플로 전반의 효율성을 높이는 차세대Amazon SageMaker 노트북을 발표하게 되어 매우 기쁩니다. 이제 내장된 데이터 준비 기능으로 몇 분 안에 데이터 품질을 개선하고, 팀과 함께 동일한 노트북을 실시간으로 편집하며, 노트북 코드를 프로덕션 준비 작업으로 자동 변환할 수 있습니다.
새로워진 요소들을 보여드리겠습니다!
간소화된 데이터 준비를 위한 새로운 노트북 기능
새로운 내장 데이터 준비 기능은 Amazon SageMaker Data Wrangler로 구동하며 SageMaker Studio 노트북에서 사용할 수 있습니다. SageMaker Studio 노트북은 Pandas 데이터 프레임 위에 주요 시각화를 자동으로 생성하여 데이터 분포를 이해하고 누락된 값, 잘못된 데이터 및 이상값과 같은 데이터 품질 문제를 식별하는 데 도움을 줍니다. ML 모델의 목표 열을 선택하고 불균형 클래스 또는 높은 상관 관계 열과 같은 ML별 인사이트를 생성할 수도 있습니다. 그런 다음 문제 해결을 위한 데이터 변환 관련 권장 사항을 받게 됩니다. UI에서 바로 데이터 변환을 적용할 수 있으며, SageMaker Studio 노트북은 데이터 준비 파이프라인을 재생하는 데 사용할 수 있는 해당 변환 코드를 노트북 셀에 자동으로 생성합니다.
내장된 데이터 준비 기능 사용
시작하려면 pip를 설치하고 sagemaker_datawrangler를 pandas Python 패키지와 함께 가져옵니다. 그런 다음 분석하려는 데이터 세트를 노트북 작업 디렉터리에 다운로드하고 팬더와 함께 데이터 세트를 읽습니다.
import pandas as pd
import sagemaker_datawrangler
!aws s3 cp s3://<YOUR_S3_BUCKET>/data.csv .
df = pd.read_csv("data.csv")
이제 데이터 프레임을 표시하면 자동으로 각 열의 상단에 주요 데이터 시각화가 나타나고, 데이터 인사이트가 보이며, 데이터 품질 문제를 감지하고, 데이터 품질 개선을 위한 솔루션을 제안합니다. 열을 ML 예측의 대상 열로 선택하면 대상의 혼합 데이터 유형(회귀 사용 사례의 경우) 또는 클래스당 너무 적은 인스턴스(분류 사용 사례의 경우) 등의 대상별 인사이트 및 경고를 받을 수 있습니다.
이 예제에서는 여성 의류에 대한 고객 리뷰와 평점을 포함하는 여성 전자 상거래 의류 리뷰 데이터 세트를 사용하고 있습니다. 이 데이터 세트는 Kaggle에서 가져왔으며 Amazon에서 합성 데이터 품질 문제를 추가하도록 수정했습니다.

제안된 데이터 변환을 검토하여 데이터 품질을 개선하고 UI에 바로 적용할 수 있습니다. 지원하는 모든 데이터 변환 목록은 설명서를 참조하십시오. 데이터 변환을 적용하면 SageMaker Studio 노트북은 자동으로 코드를 생성하여 다른 노트북 셀에서 해당 데이터 준비 단계를 재현합니다.
예를 들어, 저는 등급을 목표 열로 선택합니다. 대상 열 인사이트는 우선순위가 높은 경고를 통해 이 열에 클래스당 인스턴스가 너무 적다고 알리며, 중간 우선순위의 경고를 통해 클래스가 너무 불균형하다는 것을 알려줍니다. 제안에 따라 희귀한 목표 값을 빼고 누락된 값을 삭제해 보겠습니다. 또한 일부 기능 열에 대한 제안에 따라 텍스트 검토 열에 누락된 값을 삭제하고 부서 이름 열을 삭제하겠습니다.
변환을 적용하면 노트북에서 다음 코드를 자동으로 생성합니다.
# Pandas code generated by sagemaker_datawrangler
output_df = df.copy(deep=True)
# Code to Drop rare target values for column: Rating to resolve warning: Too few instances per class
rare_target_labels_to_drop = ['-100', '100']
output_df = output_df[~output_df['Rating'].isin(rare_target_labels_to_drop)]
# Code to Drop missing for column: Rating to resolve warning: Missing values
output_df = output_df[output_df['Rating'].notnull()]
# Code to Drop missing for column: Review Text to resolve warning: Missing values
output_df = output_df[output_df['Review Text'].notnull()]
# Code to Drop column for column: Division Name to resolve warning: Missing values
output_df=output_df.drop(columns=['Division Name'])이제 필요한 경우 코드를 검토 및 수정하거나 ML 개발 워크플로의 일부로 데이터 변환을 통합할 수 있습니다.
팀 기반 공유 및 실시간 협업을 위한 공유 공간 소개
SageMaker Studio는 이제 데이터 과학 및 ML 팀이 함께 노트북을 읽고, 편집하며, 실행할 수 있는 작업 공간을 제공하는 공유 공간을 제공하여 개발 프로세스 중에 협업과 커뮤니케이션을 간소화할 수 있습니다. 공유 공간은 공유 공간 내에서 파일을 공유하는 데 활용할 수 있는 공유 Amazon EFS 디렉터리를 제공합니다. 공유 공간에서 생성하는 태그 지정 가능한 모든 SageMaker 리소스는 자동으로 태그가 지정되어 해당 공간에서 작업하는 비즈니스 문제와 관련된 ML 리소스(예: 교육 작업, 실험, 모델 등)를 구성 및 필터링하여 볼 수 있습니다. 또한 이를 통해 AWS Budgets 및 AWS Cost Explorer 등의 도구를 사용하여 비용을 모니터링하고 예산을 계획할 수 있습니다.
그것이 전부는 아닙니다. 또한 이제 동일한 AWS 계정 내에 여러 SageMaker 도메인을 생성하여 액세스 범위를 지정하고 조직 내 여러 팀 또는 사업부에 리소스를 격리할 수 있습니다. 이제 SageMaker 도메인 내에서 사용자를 위한 공유 공간을 생성하는 방법을 보여드리겠습니다.
공유 공간 사용
SageMaker 콘솔 또는 AWS CLI를 사용하여 SageMaker 도메인을 위한 공유 공간을 생성할 수 있습니다. SageMaker 콘솔에서 시작하려면 도메인으로 이동하여 새 도메인을 선택 또는 생성한 다음 스페이스 관리를 도메인 세부 정보 페이지에서 선택합니다. 그런 다음 생성을 선택하고 공유 공간에 이름을 지정합니다.
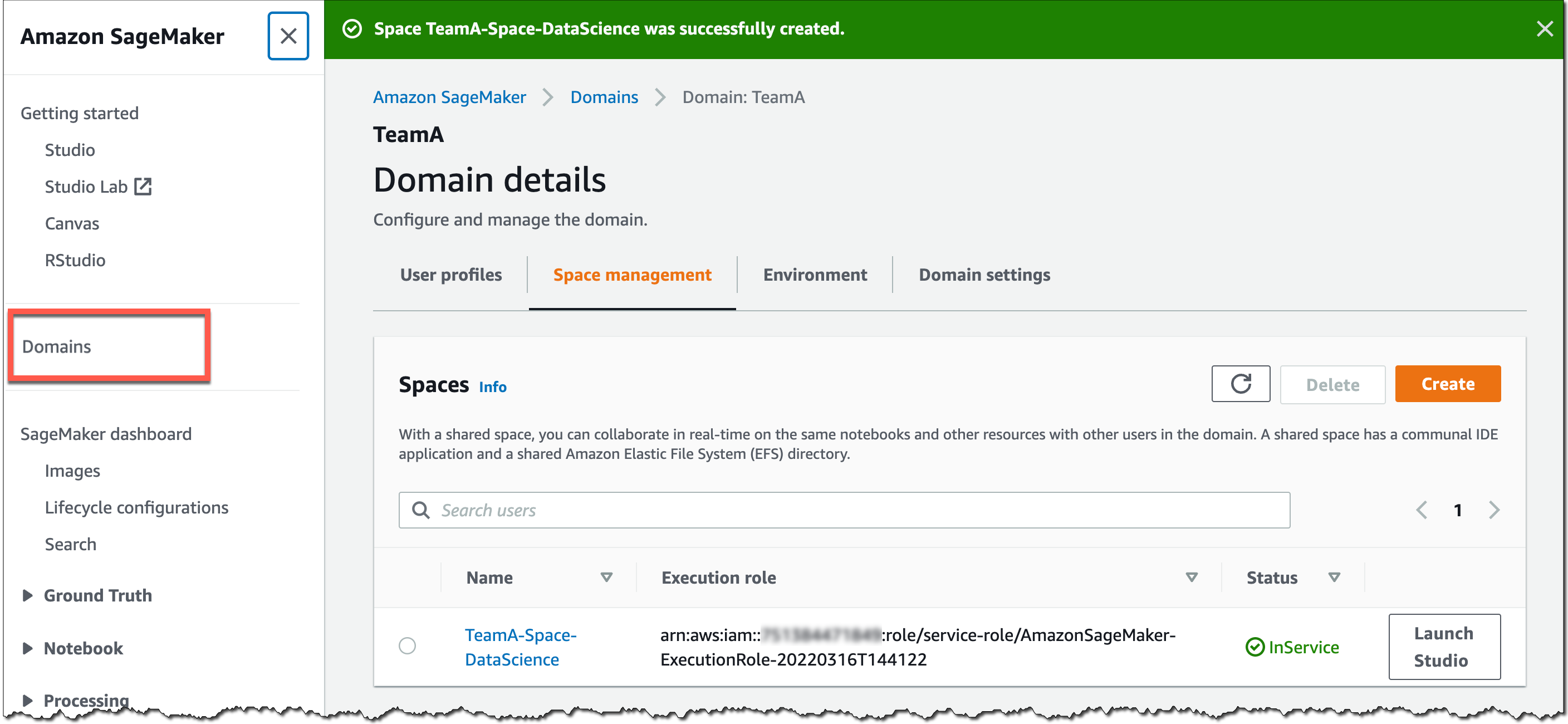
이 SageMaker 도메인의 사용자는 이제 SageMaker 도메인 사용자 프로필을 통해 공유 공간을 시작하고 이에 참여할 수 있습니다.
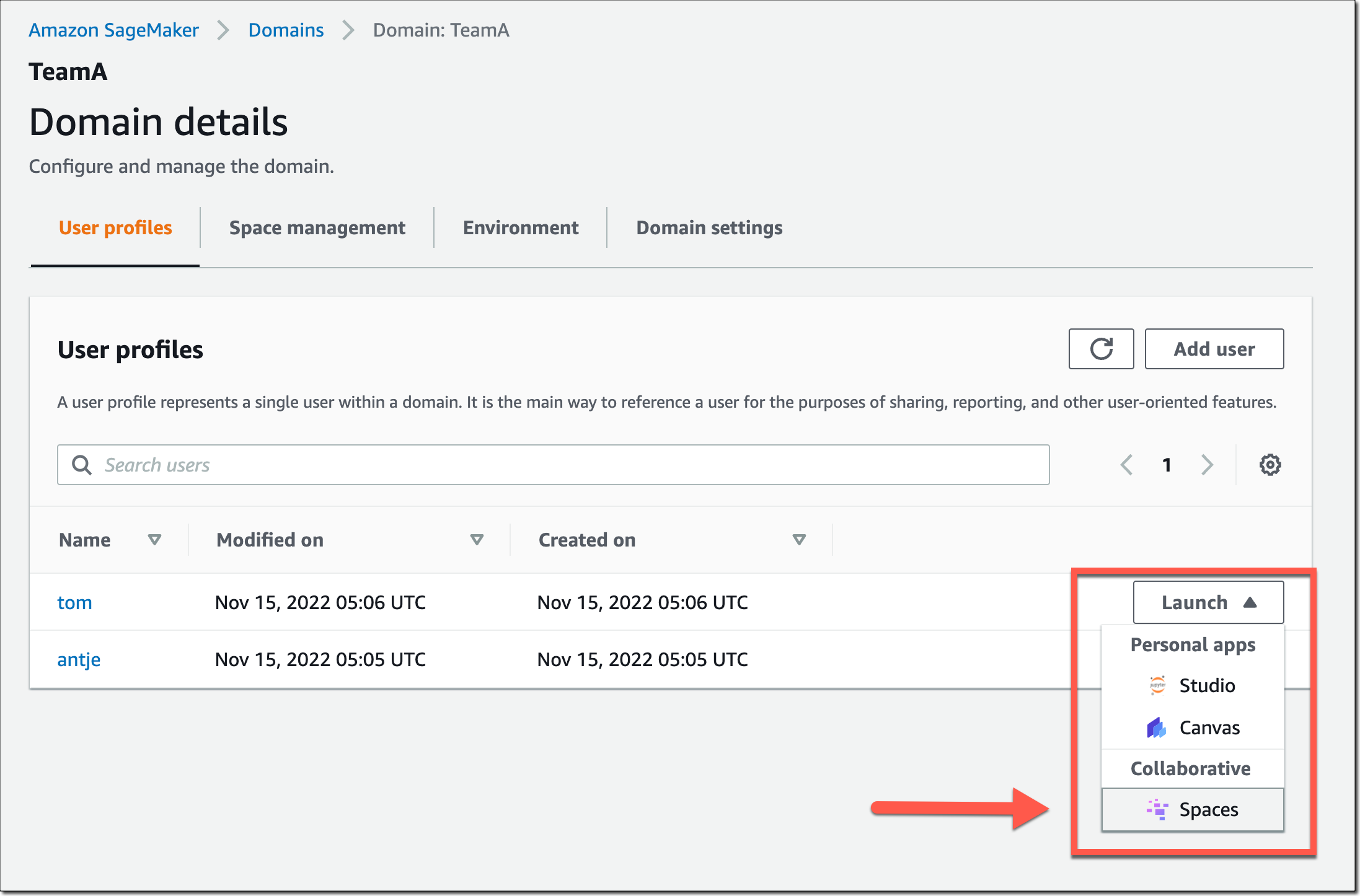
공유 공간에서 왼쪽 탐색 메뉴의 새 공동 작업자 아이콘을 선택합니다. 이제 이 스페이스에서 현재 활동하는 다른 사람을 볼 수 있습니다. 다음 스크린샷은 좌측에 노트북 파일을 편집 중인 사용자 tom을 보여줍니다. 우측의 사용자 antje는 해당 노트북 셀을 현재 편집하고 있는 사용자 이름의 주석과 함께 편집 내용을 실시간으로 볼 수 있습니다.

노트북 코드를 생산 준비 작업으로 자동 변환하는 새로운 노트북 기능
이제 노트북을 선택하여 기본 인프라를 관리할 필요 없이 프로덕션 환경에서 실행할 수 있는 작업으로 자동화할 수 있습니다. SageMaker Notebook 작업을 생성하면 SageMaker Studio는 전체 노트북의 스냅샷을 생성하고, 해당 종속성을 컨테이너에 패키징하며, 인프라를 구축하고, 사용자가 정의한 일정에 따라 노트북을 자동화 작업으로 실행하며, 작업 완료 시 인프라를 디프로비저닝합니다. 이 노트북 기능은 이제 ML을 학습 및 실험할 수 있는 컴퓨팅, 스토리지 및 보안을 제공하는 무료 ML 개발 환경인 SageMaker Studio Lab에서도 사용할 수 있습니다.
노트북 기능을 사용하여 노트북 자동화
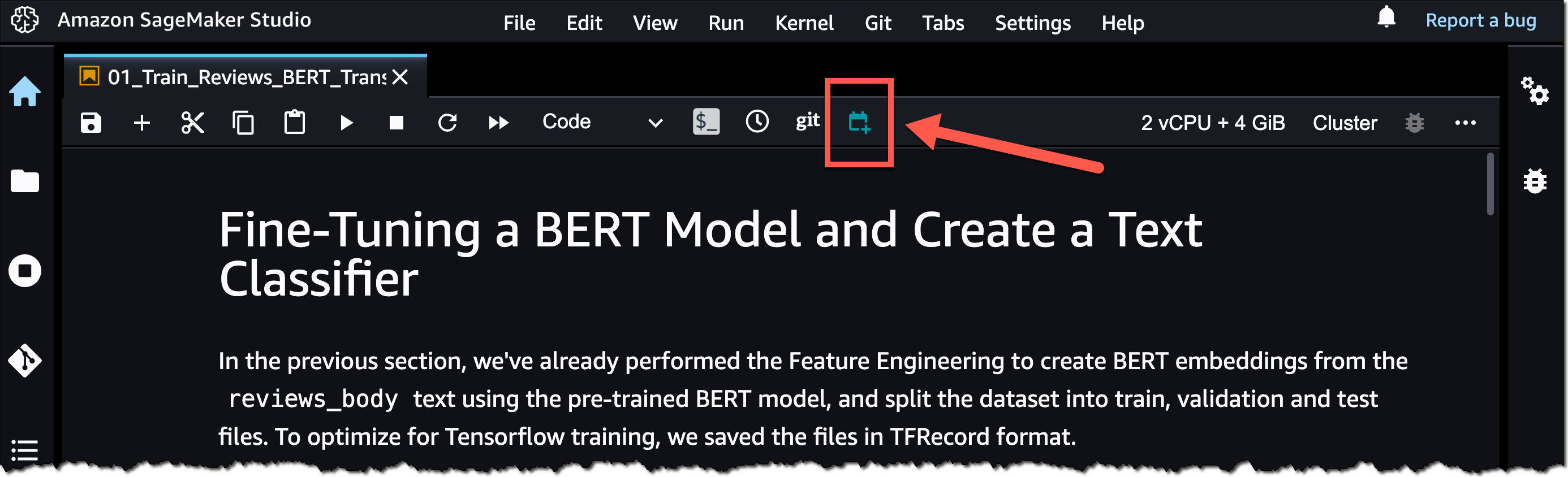
시작하려면 SageMaker 스튜디오에서 노트북 파일을 여십시오. 그런 다음 노트북 파일을 마우스 우측 단추로 클릭하여 노트북 작업 생성을 선택하거나 다음 스크린샷에 강조 표시된 대로 노트북 작업 생성 아이콘을 선택합니다.
Notebook 작업의 이름을 정의하고, 입력 파일 위치를 검토하며, 사용할 컴퓨팅 유형을 지정하고, 작업을 즉시 실행할지 일정에 따라 실행할지 지정합니다. 그런 다음 생성을 선택합니다.
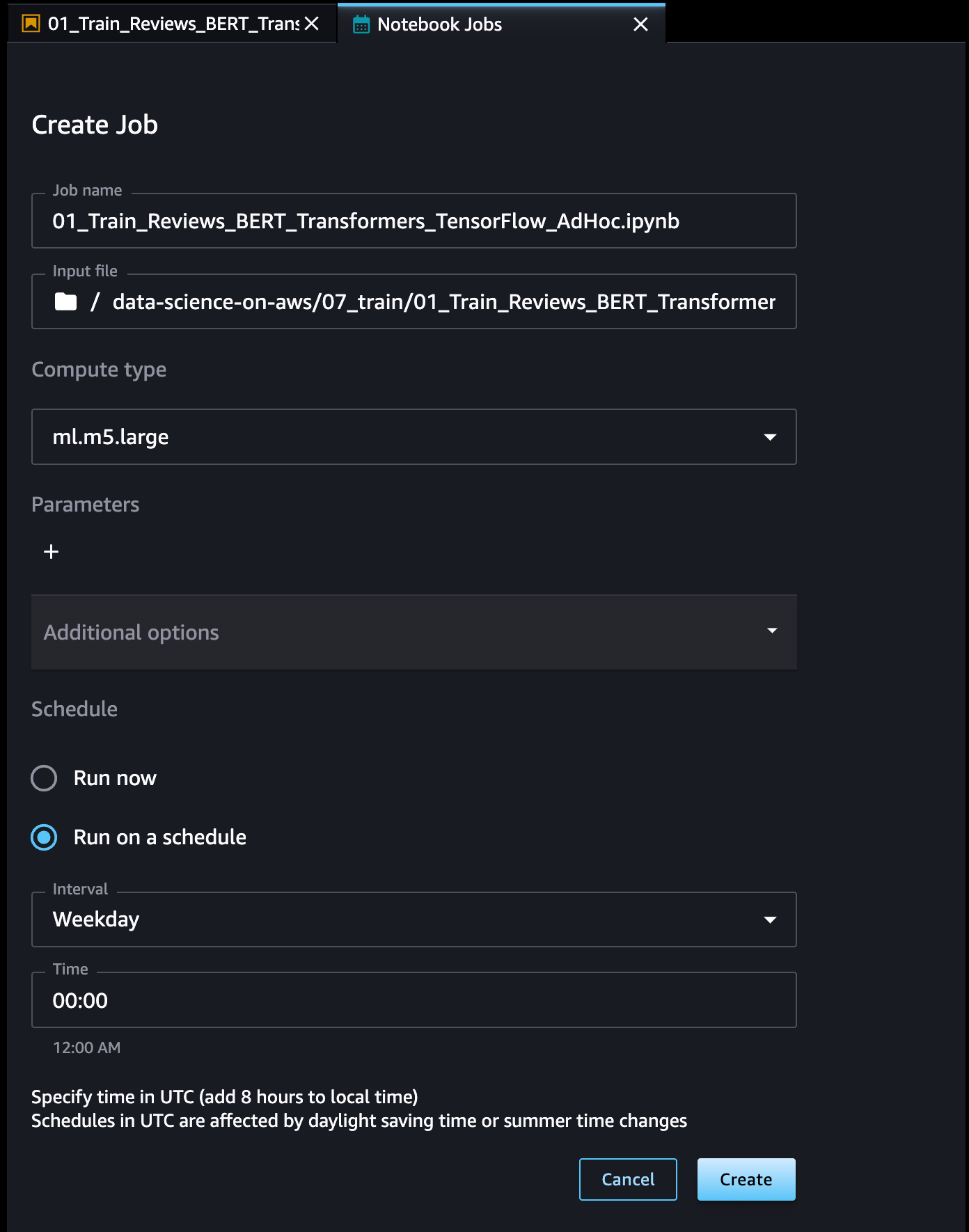
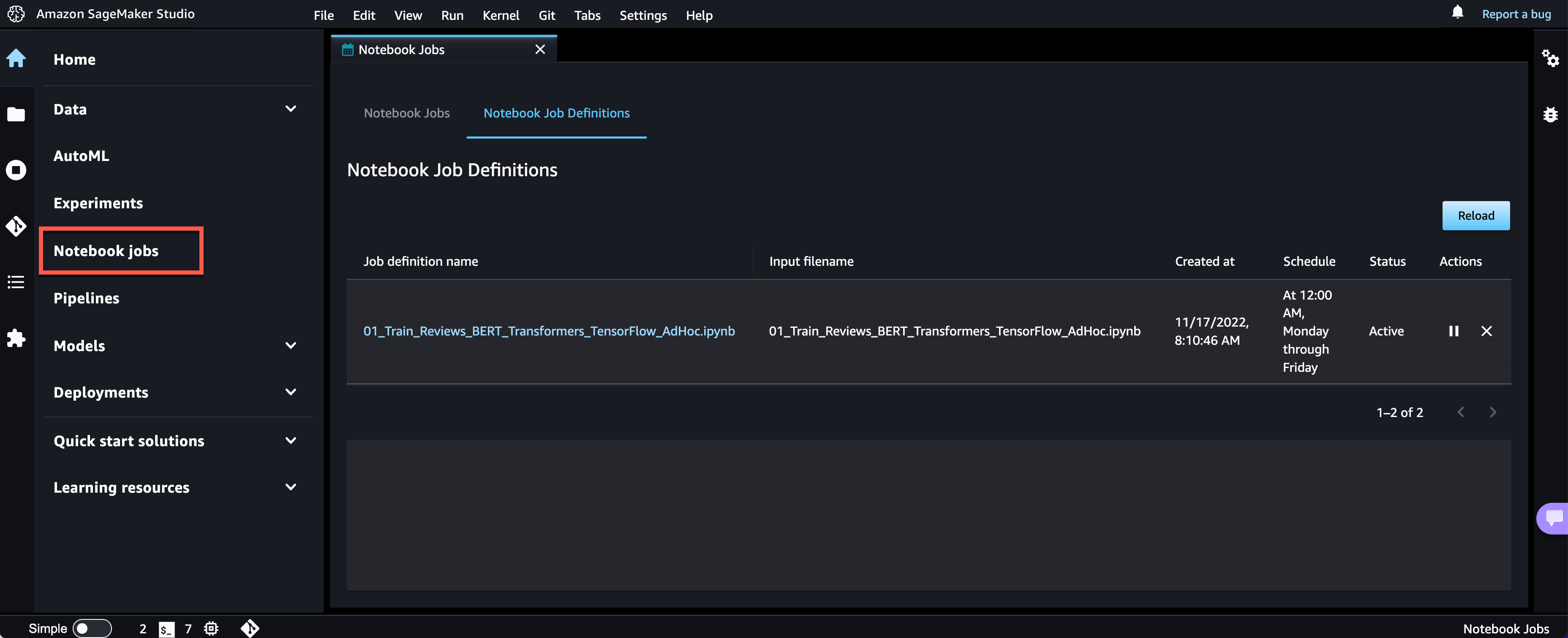
노트북 작업을 생성하였으므로 UI에서 모든 노트북 작업 정의를 검토할 수 있습니다.
정식 출시
새로운 Amazon SageMaker Studio 노트북 기능은 이제 AWS 중국 리전을 제외하고 아마존 SageMaker 스튜디오를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다.
출시 시 SageMaker Data Wrangler 기반의 내장 데이터 준비 기능을 SageMaker Studio 노트북 및 다음 노트북 커널 이미지에 지원합니다.
- Python 3.7을 사용한 Python 3(데이터 과학)
- Python 3.8을 사용한 Python 3(데이터 과학 2.0)
- Python 3.10을 사용한 Python 3(데이터 과학 3.0)
- Spark Analytics 1.0 및 2.0
자세한 내용은 Amazon SageMaker 노트북을 참조하십시오.
지금 바로 차세대 Amazon SageMaker 노트북으로 ML 프로젝트 구축을 시작해 보십시오!
— Antje