Amazon Web Services 한국 블로그
AWS Batch 및 Amazon FSx for Lustre 기반 다중 노드 병렬 작업을 통한 확장 가능한 딥 러닝 학습 방법
AWS Batch는 분산된 학습 작업의 특정 작업 요구 사항을 바탕으로 컴퓨팅 리소스를 동적으로 프로비저닝합니다. 최근 다중 노드 병렬 작업을 지원하기 시작했으며, 그 결과 밀접하게 결합된 작업 실행이 가능해졌습니다. 이 컴퓨팅 계층은 FSx for Lustre 파일 시스템과 결합할 수 있습니다.
FSx for Lustre는 Lustre를 기반으로 수백만 IOPS 및 초당 수백 기가 바이트까지 확장할 수 있는 완전 관리형 병렬 파일 시스템입니다. FSx for Lustre는 Amazon S3와 완벽하게 통합되어 객체 스토어의 데이터 수집을 병렬 처리합니다.
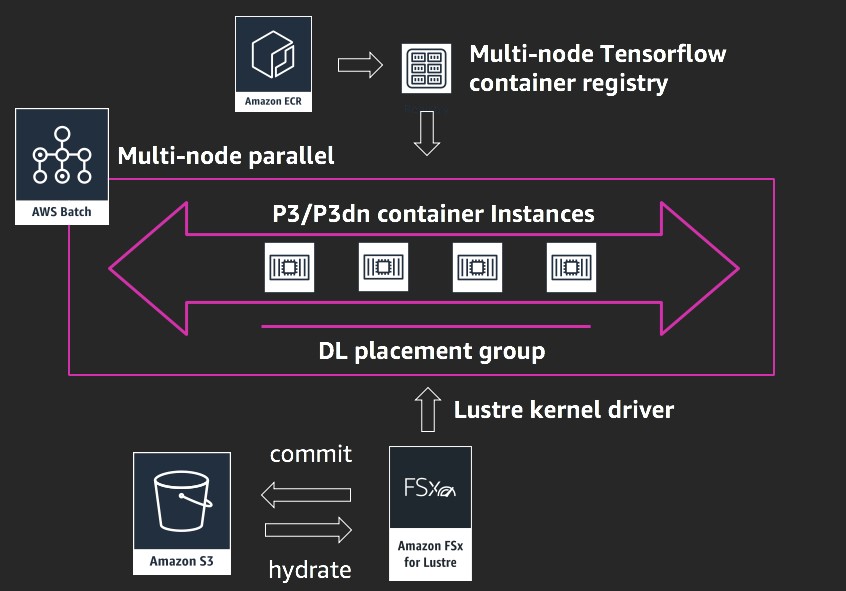
이러한 결합을 통해 고성능 계층을 필요로 하는 워크로드를 실행하기 위한 핵심 컴퓨팅 솔루션을 제공합니다. 또 다른 이점은 AWS Batch 및 FSx for Lustre가 API 기반 서비스이며 프로그래밍 방식으로 오케스트레이션이 가능하다는 점입니다.
이 게시물은 혁신적인 아키텍처를 선보여 자체 관리형 롤업 파일 시스템을 대체하는 것을 목표로 합니다. 또한 컨테이너 애플리케이션을 실행하는 FSx for Lustre 및 AWS Batch를 사용하여 플랫폼 관리 서비스에 컴퓨팅을 수행함으로써 복잡성과 유지 관리 작업을 줄이고자 합니다. 이는 유사한 컴퓨팅/네트워킹 및 스토리지 토폴로지가 필요한 다른 HPC 애플리케이션을 위한 템플릿 역할을 수행할 수도 있습니다. 이러한 점을 고려할 때 분산형 딥 러닝과 관련된 벤치마크는 범위에 해당하지 않습니다. 이 게시물의 끝부분에서 확인할 수 있듯, 1~20개의 p3.16xlarge 노드에 걸친 광범위한 GPU(8~160)에 대해 선형 확장성이 달성되었습니다.
배포
이전 게시물인 Building a tightly coupled molecular dynamics workflow with multi-node parallel jobs in AWS Batch에서 대부분의 배포를 다루었습니다. 하지만 그 이후 일부의 기능 업데이트는 초기 배포를 단순화했습니다.
요약하면 다음과 같은 리소스를 프로비저닝합니다.
- 원본 ImageNet 2012 이미지를 제공하는 S3 버킷에서 수화된 FSx for Lustre 파일 시스템
- 새로운 Ubuntu 16.04 ECS 인스턴스:
- Lustre 커널 드라이버 및 FS 마운트
- NVIDIA Tesla 410 드라이버가 탑재된 CUDA 10
- nvidia-docker2가 포함된 Docker 18.09-ce
- 다음과 같은 스택이 포함된 다중 노드 병렬 배치 호환 TensorFlow 컨테이너:
- Ubuntu 18.04 컨테이너 이미지
- TENSORFLOW_VERSION=1.12.0
- HOROVOD_VERSION=0.15.2
- CUDNN_VERSION=7.4.2.24-1+cuda10.0
- NCCL_VERSION=2.3.7-1+cuda10.0
- OPENMPI 4.0.0
FSx for Lustre 설정
먼저, FSx for Lustre 콘솔에 파일 시스템을 생성합니다. 3600GiB 크기의 기본적인 최소 파일 시스템이면 충분합니다.
- 파일 시스템 이름: ImageNet2012 dataset
- 스토리지 용량: 3600(GiB)
콘솔에서 클라이언트가 FSx for Lustre 파일 시스템에 액세스할 수 있도록 적절한 네트워크 액세스 및 보안 그룹을 지정했는지 확인합니다. 이 게시물의 경우, deep-learning-models GitHub 리포지토리에서 데이터 세트를 준비하는 스크립트를 찾습니다.
- 데이터 리포지토리 유형: Amazon S3
- 가져오기 경로: ImageNet 2012 데이터 세트를 포함하는 S3 버킷을 가리킵니다.
FSx for Lustre 계층이 프로비저닝되는 동안 p3.2xlarge 인스턴스 유형을 사용하여 Ubuntu 16.04 ECS AMI로 Amazon EC2 콘솔의 인스턴스를 등록합니다. ecs-agent systemd 파일을 준비할 때 한 가지를 수정해야 합니다. ExecStart=stanza를 다음의 내용으로 바꿉니다.
ExecStart=docker run --name ecs-agent \
--init \
--restart=on-failure:10 \
--volume=/var/run:/var/run \
--volume=/var/log/ecs/:/log \
--volume=/var/lib/ecs/data:/data \
--volume=/etc/ecs:/etc/ecs \
--volume=/sbin:/sbin \
--volume=/lib:/lib \
--volume=/lib64:/lib64 \
--volume=/usr/lib:/usr/lib \
--volume=/proc:/host/proc \
--volume=/sys/fs/cgroup:/sys/fs/cgroup \
--volume=/var/lib/ecs/dhclient:/var/lib/dhclient \
--net=host \
--env ECS_LOGFILE=/log/ecs-agent.log \
--env ECS_DATADIR=/data \
--env ECS_UPDATES_ENABLED=false \
--env ECS_AVAILABLE_LOGGING_DRIVERS='["json-file","syslog","awslogs"]' \
--env ECS_ENABLE_TASK_IAM_ROLE=true \
--env ECS_ENABLE_TASK_IAM_ROLE_NETWORK_HOST=true \
--env ECS_UPDATES_ENABLED=true \
--env ECS_ENABLE_TASK_ENI=true \
--env-file=/etc/ecs/ecs.config \
--cap-add=sys_admin \
--cap-add=net_admin \
-d \
amazon/amazon-ecs-agent:latest프로비저닝 워크플로가 진행되는 동안 500GB SSD(gp2) Amazon EBS 볼륨을 추가합니다. 설치가 용이하도록 Lustre 커널 드라이버를 먼저 설치합니다. 또한 호환성을 위해 커널을 수정합니다. 우선 dkms 패키지를 설치합니다.
sudo apt install -y dkms gitUbuntu 16.04용 지침을 따릅니다.
NVIDIA에서 제공하는 지침에 따라 CUDA 10 및 NVIDIA 410 드라이버 브랜치를 설치합니다. dkms 시스템을 이전에 설치된 커널에 대해 구축된 커널 모듈과 함께 설치하는 것이 중요합니다.
작업이 완료되면 nvidia-docker GitHub 리포지토리의 지침에 따라 기본 런타임을 “nvidia”로 설정하여 최신 Docker 릴리스와 nvidia-docker2를 설치합니다.
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia"
}
이 단계에서 이 AMI를 생성하여 향후 배포를 위해 보관할 수 있습니다. 일반 AMI를 다양한 애플리케이션에 사용할 수 있으므로 부트스트래핑 시 시간을 절약할 수 있습니다.
FSx for Lustre 파일 시스템이 완성되면 /etc/fstab에 파일 시스템 정보를 추가합니다.
<file_system_dns_name>@tcp:/fsx /fsx lustre defaults,_netdev 0 0다음 명령을 사용해 마운트가 성공적으로 수행되었는지 확인하십시오.
sudo mkdir /fsx && sudo mount -a다중 노드 병렬 배치 TensorFlow Docker 이미지 제작
이제 다중 노드 TensorFlow 컨테이너 이미지를 설정하십시오. 이 프로세스는 p3.2xlarge에 구축하는 데 2시간 정도가 소요됩니다. 다중 노드 병렬 배치 작업을 설정하기 위한 Dockerfile 빌드 스크립트를 사용하십시오.
git clone https://github.com/aws-samples/aws-mnpbatch-template.git
cd aws-mnpbatch-template
docker build -t nvidia/mnp-batch-tensorflow .
Docker 컨테이너 ENTRYPOINT의 일부로 Building a tightly coupled molecular dynamics workflow with multi-node parallel jobs in AWS Batch 게시물의 mpi-run.sh 스크립트를 사용하십시오. TensorFlow 분산 학습을 실행하기 위해 다음과 같이 최적화 하십시오.
cd $SCRATCH_DIR
export INTERFACE=eth0
export MODEL_HOME=/root/deep-learning-models/models/resnet/tensorflow
/opt/openmpi/bin/mpirun --allow-run-as-root -np $MPI_GPUS --machinefile ${HOST_FILE_PATH}-deduped -mca plm_rsh_no_tree_spawn 1 \
-bind-to socket -map-by slot \
$EXTRA_MPI_PARAMS -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib \
-x NCCL_SOCKET_IFNAME=$INTERFACE -mca btl_tcp_if_include $INTERFACE \
-x TF_CPP_MIN_LOG_LEVEL=0 \
python3 -W ignore $MODEL_HOME/train_imagenet_resnet_hvd.py \
--data_dir $JOB_DIR --num_epochs 90 -b $BATCH_SIZE \
--lr_decay_mode poly --warmup_epochs 10 --clear_log
시작 명령에 정의되지 않은 환경 변수가 있습니다. 이 게시물의 이후 단계에서 다중 노드 배치 작업 정의 파일을 만들 때 해당 내용이 채워집니다.
Docker 이미지를 성공적으로 작성하면 이 이미지를 Amazon ECR에 커밋하여 나중에 가져오도록 합니다. 레지스트리를 선택하고 푸시 명령 보기를 선택하여 레지스트리의 ECR 푸시 명령을 참조하십시오.
추가 팁: Docker 이미지가 약 12GB이므로 컨테이너 인스턴스가 신속하게 시작됩니다. Docker 캐시에 이 이미지를 캐시하여 전체 이미지를 가져오는 대신 점진적 계층 업데이트를 ECR에서 가져오도록 하여 시간을 절약할 것입니다.
마지막으로 워크플로의 AWS Batch 컴퓨팅 환경 단계를 위해 이 AMI를 생성할 준비를 해야 합니다. AWS Batch 콘솔에서 컴퓨팅 환경을 선택하여 다음 파라미터가 포함된 환경을 생성하십시오.
컴퓨팅 환경
- 컴퓨팅 환경 유형: 관리형
- 컴퓨팅 환경 이름: tensorflow-gpu-fsx-ce
- 서비스 역할: AWSBatchServiceRole
- EC2 인스턴스 역할: ecsInstanceRole
컴퓨팅 리소스
최소 vCPU 및 원하는 vCPU를 0으로 설정합니다. 작업이 제출되면 기본 AWS Batch 서비스는 AWS에서 제공되는 탄력성 및 확장성을 활용하여 노드를 모집합니다.
- 프로비저닝 모델: 온디맨드
- 허용된 인스턴스 유형: p3 패밀리, p3dn.24xlarge
- 최소 vCPU: 0
- 원하는 vCPU: 0
- 최대 vCPU: 4096
- 사용자 지정 AMI: 앞서 언급한 Amazon Linux 2 AMI를 사용합니다.
네트워킹
AWS Batch를 사용하면 배치 그룹을 쉽게 지정할 수 있습니다. 이 작업을 수행할 경우 인스턴스 사이의 노드 간 통신의 대기 시간이 최저가 되며, 이는 밀접하게 결합된 워크플로를 실행할 때 필요합니다.
- VPC ID: 앞에서 만든 FSx 클러스터에 대한 액세스를 허용하는 VPC를 선택합니다.
- 보안 그룹: FSx 보안 그룹, 클러스터 보안 그룹
- 배치 그룹: tf-group(배치 그룹 생성)
EC2 태그
- 키: 이름
- 값: tensorflow-gpu-fsx-processor
이 컴퓨팅 환경을 tf-queue라는 대기열과 연결합니다. 마지막으로 프로세스를 묶고 컨테이너를 실행하는 작업 정의를 작성하십시오.
다음과 같은 JSON 형식의 파라미터는 mnp-tensorflow 작업 정의를 설정합니다.
{
"jobDefinitionName": "mnptensorflow-gpu-mnp1",
"jobDefinitionArn": "arn:aws:batch:us-east-2:<accountid>:job-definition/mnptensorflow-gpu-mnp1:1",
"revision": 2,
"status": "ACTIVE",
"type": "multinode",
"parameters": {},
"retryStrategy": {
"attempts": 1
},
"nodeProperties": {
"numNodes": 20,
"mainNode": 0,
"nodeRangeProperties": [
{
"targetNodes": "0:19",
"container": {
"image": "<accountid>.dkr.ecr.us-east-2.amazonaws.com/mnp-tensorflow",
"vcpus": 62,
"memory": 424000,
"command": [],
"jobRoleArn": "arn:aws:iam::<accountid>:role/ecsTaskExecutionRole",
"volumes": [
{
"host": {
"sourcePath": "/scratch"
},
"name": "scratch"
},
{
"host": {
"sourcePath": "/fsx"
},
"name": "fsx"
}
],
"environment": [
{
"name": "SCRATCH_DIR",
"value": "/scratch"
},
{
"name": "JOB_DIR",
"value": "/fsx/resized"
},
{
"name": "BATCH_SIZE",
"value": "256"
},
{
"name": "EXTRA_MPI_PARAMS",
"value": "-x HOROVOD_HIERARCHICAL_ALLREDUCE=1 -x HOROVOD_FUSION_THRESHOLD=16777216 -x NCCL_MIN_NRINGS=8 -x NCCL_LAUNCH_MODE=PARALLEL"
},
{
"name": "MPI_GPUS",
"value": "160"
}
],
"mountPoints": [
{
"containerPath": "/fsx",
"sourceVolume": "fsx"
},
{
"containerPath": "/scratch",
"sourceVolume": "scratch"
}
],
"ulimits": [],
"instanceType": "p3.16xlarge"
}
}
]
}
}
MPI_GPUS
클러스터에 있는 GPU의 총수입니다. 이 경우 20 x p3.16xlarge = 160입니다.
BATCH_SIZE
GPU당 16GB 메모리에서 학습 시간에 로드할 GPU당 이미지 수 = 256.
JOB_DIR
shards의 수에 최적화되어 이전에 준비된 TFrecord의 위치 = /fsx/resized.
SCRATCH_DIR
모델 출력 경로 = /scratch.
추가 팁: 작업 정의에서 추가 파라미터를 자유롭게 노출할 수 있습니다. 즉, 모델 학습 하이퍼파라미터를 노출할 수 있으므로 AWS Batch 계층에서 다중 파라미터 최적화(MPO) 연구를 시작할 수 있습니다.
작업 정의가 생성된 상태에서 이전에 작성한 tf-queue에서 실행하여 이 작업 정의를 소싱하는 새로운 작업을 제출하십시오. 이 작업은 컴퓨팅 환경을 생성합니다.
AWS Batch 서비스는 요청된 노드 수만 개시합니다. 요청된 노드가 전부 컴퓨팅 환경에서 시작될 때까지 실행 중인 EC2 인스턴스 비용을 지불하지 않아도 됩니다.
작업이 실행 중 상태가 되면 이 작업에 대해 생성된 CloudWatch 로그 스트림을 사용하여 주요 컨테이너(0)를 모니터링할 수 있습니다. 주요 항목 중 일부는 다음과 같으며 클러스터에 20개 노드가 포함됩니다. 추가 팁: 추가 모니터링을 위해 이 인프라를 사용하여 모델 파라미터 및 학습 성능을 Tensorboard로 보낼 수 있습니다.
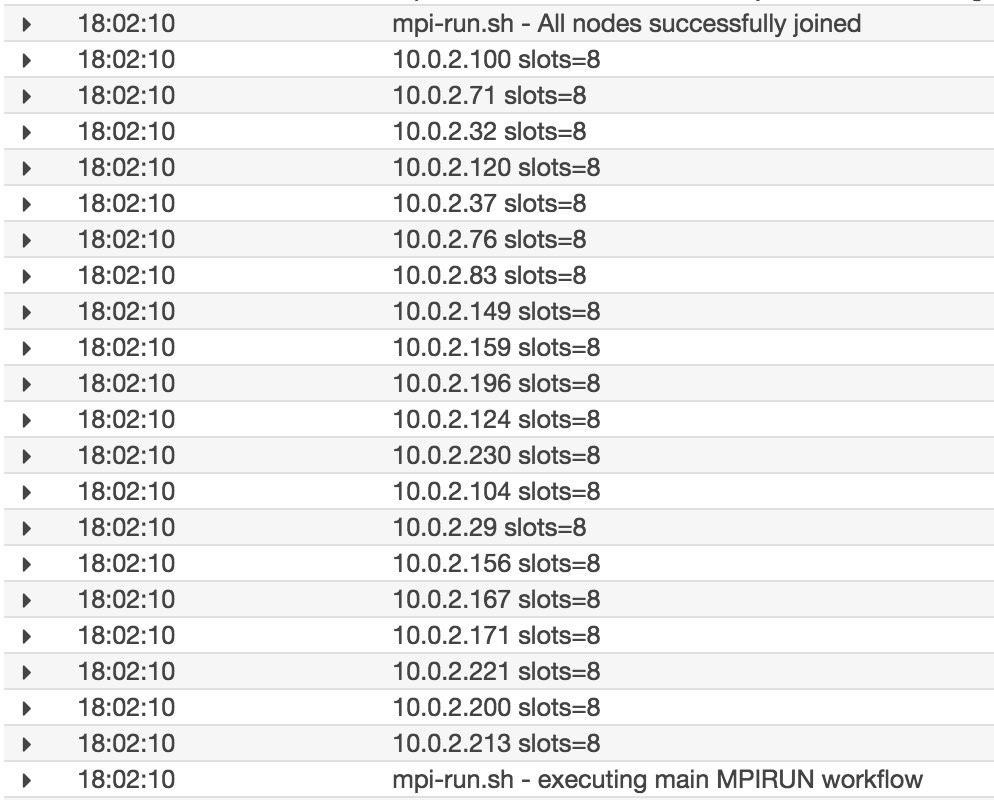
다음 로그 스크린샷은 주요 TensorFlow 및 Horovod 워크플로가 시작되는 것을 보여줍니다. 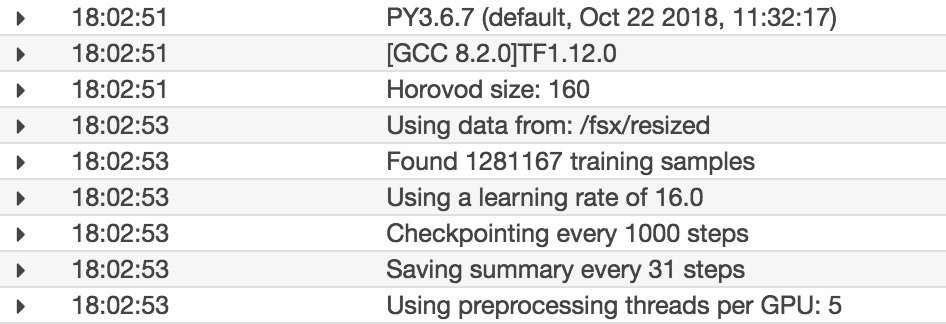
성능 모니터링
20개의 p3.16xl 노드에서 컨테이너화된 Horovod TensorFlow Docker 이미지를 사용하여 160개의 GPU에서 90~100%에 가까운 GPU 사용률 수준으로 약 100,000 이미지/초와 비슷한 속도를 구현했습니다.
이를 구현한 후에는 최근 발표된 100Gbps 네트워킹이 포함된 p3.16xl의 32GB NVIDIA Tesla V100 메모리 변형인 p3dn.24xlarge를 사용하여 클러스터를 시험해 보십시오. 작업 정의에서 p3dn의 전체 GPU 메모리를 활용하려면 BATCH_SIZE 환경 변수를 늘리십시오.

결론
확장성이 뛰어나며 딥 러닝 중심의 고성능 컴퓨팅 환경이 발전함에 따라 이제 클라우드 고유의 접근 방식을 사용할 수 있습니다. AWS가 구분이 어려운 과중한 작업을 처리하는 동안 코드와 학습에 집중하십시오.
앞서 언급했듯이 이 참조 아키텍처에는 API 인터페이스가 있으므로 이벤트 기반 워크플로는 이 작업을 더욱 확장할 수 있습니다. 예를 들어, AWS Step Functions 워크플로에 이 핵심 컴퓨팅을 통합하여 FSx for Lustre 계층을 구현할 수 있습니다. 배치 작업을 제출하고 FSx for Lustre 계층을 축소하십시오.

또는 API 게이트웨이를 통해 작업 제출을 위한 웹 애플리케이션을 만듭니다. 온프레미스 리소스와 통합하여 데이터를 S3 버킷으로 전송하고 FSx for Lustre 파일 시스템을 수화합니다.
이 배포나 더욱 긴 AWS 상태와 통합하는 방법에 대한 질문이 있는 경우 아래에 댓글을 달아주시기 바랍니다. 이제 완벽하게 관리되는 고성능 컴퓨팅 프레임워크를 사용하여 딥 러닝 워크로드의 역량을 강화하십시오!
– Amr Ragab, AWS Professional Services / HPC애플리케이션 컨설턴트