Artificial Intelligence
Scalable multi-node deep learning training using GPUs in the AWS Cloud
A key barrier to the wider adoption of deep neural networks on industrial-size datasets is the time and resources required to train them. AlexNet, which won the 2012 ImageNet Large Scale Visual Recognition Competition (ILSVRC) and kicked off the current boom in deep neural networks, took nearly a week to train across the 1.2-million-image, 1000-category dataset. Developing and optimizing machine learning models is an iterative process. It involves frequently retraining models with new data and optimizing model and training parameters to increase prediction accuracy. While GPU performance has increased significantly since 2012, reducing training times from weeks to hours, Machine Learning (ML) practitioners seek opportunities to further lower model training times. At the same time, to drive higher prediction accuracy, models are getting larger and more complex, thus increasing the demand for compute resources.
The cloud has become the default option for training deep neural networks because it offers the ability to scale on demand, which provides increased agility. In addition, the cloud makes it easy to get started, and it provides pay-as-you-go usage models.
In this blog post we demonstrate how to optimize AWS infrastructure to further minimize deep learning training times by using distributed/multi-node synchronous training. We use ResNet-50 with the ImageNet dataset and Amazon EC2 P3 instances with NVIDIA Tesla V100 GPUs to benchmark our training times. We train the model using a standard training schedule of 90 epochs to a top-1 validation accuracy greater than 75.5% in about 50 minutes using just 8 P3.16xlarge instances (64 V100 GPUs).
Since ML practitioners use a variety of machine learning frameworks for building and training their models, we demonstrate the versatility of the AWS Cloud by showing performance results using Apache MXNet and TensorFlow with Horovod. With Amazon EC2 P3 instances, customers also have the flexibility to train a variety of model types (CNNs, RNNs, and GANs), and we expect that the high performance computing architecture that we outline here to efficiently scale across different frameworks and model types.
Achieved performance and results
We’ll start by reviewing the performance and validation accuracy that we were able to achieve using 8 P3.16xlarge instances.
| Framework | Time to train | Training throughput | Achieved Top-1 Validation Accuracy | Scaling Efficiency |
| Apache MXNet | 47min | ~44,000 Images/Sec | 75.75% | 92% |
| TensorFlow + Horovod | 50min | ~41,000 Images/Sec | 75.54% | 90% |
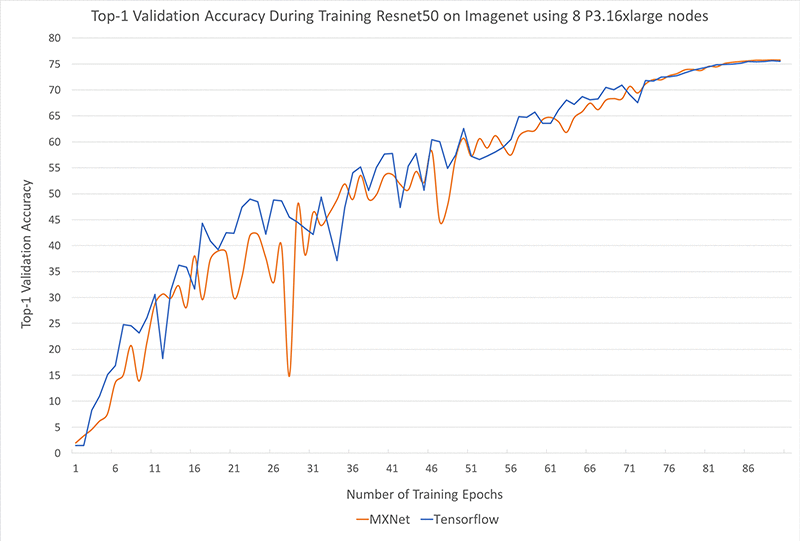
Time-to-train – With 8 P3.16xlarge instances, we observe an average time-per-epoch of 31 seconds when using MXNet and 33 seconds using TensorFlow. This translates to a wall-clock training time of 47 minutes with MXNet and 50 minutes with TensorFlow to churn through 90 epochs and hit Top-1 validation accuracy of 75.75% and 75.54%, respectively, on the ImageNet dataset. The time indicated here for both frameworks includes the time for training and checkpointing at each epoch. To keep the training job of MXNet consistent with the standard workflow of TensorFlow, we only perform validation at the end of the training instead of at the end of each epoch.
Multi-node training throughput – We trained using mixed precision on 8 P3.16xlarge instances (64 V100 GPUs) with a batch size of 256 per GPU (aggregate batch size of ~16k) and observed near linear scaling hitting about 41k images/second with TensorFlow and 44k images/second with MXNet. For TensorFlow we used the distributed training framework Horovod instead of the native parameter server approach for its better scaling efficiency[6]. For MXNet we used the native parameter server approach, and the scaling efficiency of MXNet was computed using a kvstore of type ‘device’ on a single node and ‘dist_device_sync’ on multiple nodes. Future work using all-reduce based approaches for distributed training via MXNet can further improve performance.
Validation accuracy – The following graph shows top 1 validation accuracy during our training of Resnet50 on ImageNet using 8 P3.16xlarge instances. We used similar training settings for both MXNet and TensorFlow, and we found that the convergence behavior of both frameworks was very similar.
Cluster architecture
An illustration of the high performance computing cluster we used follows. M4 instances for parameter servers are not required when using Horovod with TensorFlow.
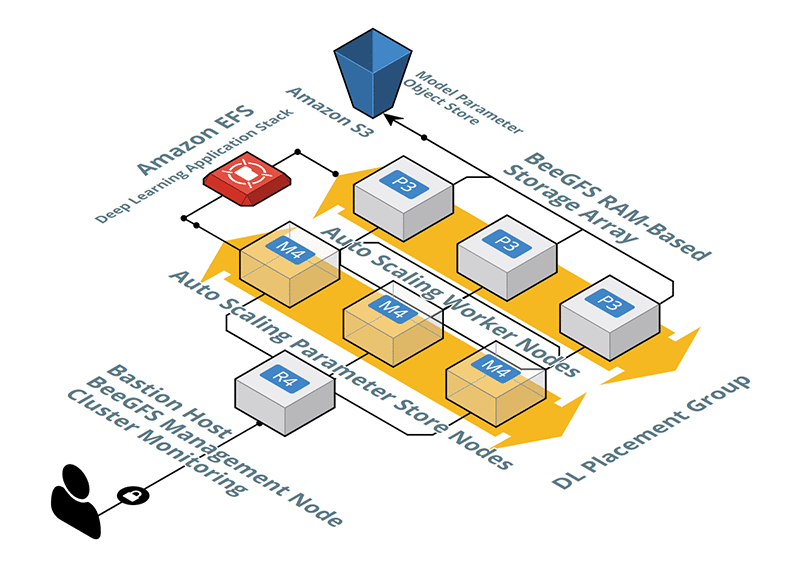
We created shared storage using the RAM of the compute cluster as a storage target. Using a parallel file system (BeeGFS) we expose the RAM target as a global namespace on each node. You can use this approach or alternatively use Amazon EBS, Amazon S3, or Amazon EFS storage services to source their training data.
The compute cluster loads data from the global namespace, augments it (using crops, flips, or blurs), and then performs the forward pass, back propagation, gradient synchronization, and weight updates. We use eight p3.16xlarge instances each having 8 NVIDIA Tesla V100 GPUs, 64 virtual CPUs, 488 GB of memory, and a network bandwidth of 25 Gb/s.
MXNet uses the parameter server approach, where separate processes act as parameter servers to aggregate gradients from each worker node and perform weight updates. During development we found that it’s more performant to have additional nodes that act only as parameter servers. We chose M4.16xl instances to play this role at a 2:1 ratio to the P3 instances. This combination allows near linear scaling of training throughput. For TensorFlow, we found that using Horovod to scale up training across many nodes performs significantly better than using the native parameter server approach in TensorFlow [6].
Training approach
Quickly training neural networks often requires using large batch sizes across many nodes. It has been observed in practice that using large batch sizes leads to some loss in generalization ability [4]. Using large batch sizes thus requires some special care to ensure that the models reach the same accuracy achieved at lower batch size. Next, we’ll describe the approach taken to train these models at this scale.
Model
We used a Resnet50 v1 model in both MXNet and TensorFlow. We used the version in which the bottleneck block downsamples the feature map size at the 3×3 convolutional layer instead of the 1×1 layer. This preserves more information and allows training to slightly higher accuracies. While there is no formal literature discussing this version in detail, this version has been mentioned in a few papers ([1][2]) and is used as standard in examples of frameworks like TensorFlow and PyTorch.
Data preprocessing and augmentation
We trained using data parallelism so that each GPU trains the full model with its own portion of the dataset. To enable this, each mini-batch is sharded into 64 parts, one for each GPU. Each worker then loads its shard of data and performs some data augmentation. Data augmentation increases the training dataset and provides a regularization effect when training the network. This regularization helps to combat the tendency to overfit when training with large batch sizes [4]. During training, we randomly cropped the original images to the size 224×224 while maintaining the aspect ratio to be in a specific range [3./4. , 4./3.]. We then randomly flipped the image horizontally. In MXNet, we performed some additional augmentation in the form of jittering saturation, hue and brightness, and adding noise sampled from Principal Component Analysis (PCA) distribution. We believe this helped the MXNet training job reach a higher validation accuracy with a similar training schedule. The validation images in both cases were only center cropped and did not undergo any randomized augmentation. Both training and validation images were normalized to subtract the mean of images in the whole dataset.
Optimization
In agreement with previous work [3] we found that the learning rate is an important optimizer parameter to tune based on the mini-batch size. For one Volta V100 GPU with a mini-batch size of 256 images, a learning rate of 0.1, momentum of 0.9, and weight decay of 0.0001 were used with Nesterov Accelerated Gradient Descent as the optimizer. As we scaled from one GPU to 64 GPUs (eight P3.16xlarge instances), we linearly scaled the learning rate by the number of GPUs used (0.1 for one GPU to 6.4 for 64 GPUs) while keeping the number of images per GPU constant at 256 (mini-batch size of 256 for one GPU to 16,384 for 64 GPUs). The weight decay and momentum parameters were not altered as the number of GPUs increase.
To combat optimization instability with the large learning rate, we used a warmup scheme [3] where the learning rate is gradually, linearly scaled up from 0.001 to 6.4 over 10 epochs. After 10 epochs, the learning rate was decayed over the next 80 epochs by a polynomial (degree=2) decay scheme. All models were trained for a total of 90 epochs regardless of the number of nodes used. It has been shown that initializing the gamma parameter of the last batch norm layer in each residual block to 0 can help with convergence at large batch sizes[3]. We observed that this did help us improve our accuracies. We did not change the hyper parameters further in the interest of providing a standard approach which could potentially be used for other scenarios.
Mixed precision
To leverage the accelerated float16 computation supported by Nvidia Volta GPUs in P3 instances, we trained using mixed precision in both frameworks. This helped reduce the training time by about 50%. Interestingly, TensorFlow required us to scale the loss by a factor of 1024 while computing the gradients to prevent it from going out of range and diverging. MXNet, however, did not need loss scaling. More details about loss scaling and how it works can be found in this paper [5].
Steps to reproduce
With broad and at-scale availability of P3 instances, we hope developers and data scientists around the world can take advantage of this work and reduce their time-to-train. We are sharing the scripts used for training these models as well as the scripts to set up the cluster we described here in the following GitHub repository: https://github.com/aws-samples/deep-learning-models. We encourage you to check them out and leverage the power of the cloud for your deep learning workloads.
The performance numbers reported earlier uses a stack that includes these major components:
Ubuntu 16.04, NVIDIA Driver 396, CUDA 9.2, cuDNN 7.1, NCCL 2.2, OpenMPI 3.1.1, Intel MKL and MKLDNN, TensorFlow 1.9 and Horovod 0.13, MXNet 1.3b (current master, soon to be released as v1.3).
Steps
- We provide scripts to setup a P3 cluster using AWS CloudFormation in the repository described earlier under hpc-cluster, along with instructions on how to use them. You can use the CloudFormation template with the script to launch and run the cluster easily.
- The ImageNet dataset is provided by http://www.image-net.org/ . You will need to register and download the following files from the original dataset: ILSVRC2012_img_train.tar.gz and ILSVRC2012_img_val.tar.gz. This contains the original 1.28M images among 1000 classes. Use the scripts provided in utils directory to process the ImageNet images to create RecordIO files for MXNet, or TF Records for Tensorflow.
- Now you can use the models and scripts in the repository to start your training job on AWS.
Future work
The results of this work demonstrate that AWS can be used for rapid training of deep learning networks, using a performant, flexible, and scalable architecture. The implementation described in this blog post has room for further optimization. A single Amazon EC2 P3 instance with 8 NVIDIA V100 GPUs can train ResNet50 with ImageNet data in about three hours (NVIDIA, Fast.AI) using SuperConvergence and other advanced optimization techniques. We believe we can further lower the time-to-train across a distributed configuration by applying similar techniques.
Another area where we can extract more performance is by improving the scaling efficiency. Lastly, in keeping with our desire to equally support all popular frameworks, future efforts will be focused on replicating similar results on other frameworks, such as PyTorch and Chainer.
References
[1] Xie, Saining, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. “Aggregated residual transformations for deep neural networks.” In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pp. 5987-5995. IEEE, 2017.
[2] Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” arXiv preprint arXiv:1709.01507 7 (2017).
[3] Goyal, Priya, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. “Accurate, large minibatch SGD: training imagenet in 1 hour.” arXiv preprint arXiv:1706.02677 (2017).
[4] Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. “On large-batch training for deep learning: Generalization gap and sharp minima.” arXiv preprint arXiv:1609.04836 (2016).
[5] Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg et al. “Mixed precision training.” arXiv preprint arXiv:1710.03740(2017).
[6] Sergeev, Alexander, and Mike Del Balso. “Horovod: fast and easy distributed deep learning in TensorFlow.” arXiv preprint arXiv:1802.05799 (2018).
About the Authors
 Amr Ragab is a ML and HPC Professional Services Consultant for AWS, devoted to helping customers run computational workloads at scale. In his spare time he likes traveling and finds ways to integrate technology into daily life.
Amr Ragab is a ML and HPC Professional Services Consultant for AWS, devoted to helping customers run computational workloads at scale. In his spare time he likes traveling and finds ways to integrate technology into daily life.
 Rahul Huilgol is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. Outside of work, he enjoys delving into science fiction particularly the kind he is helping realize with his work.
Rahul Huilgol is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. Outside of work, he enjoys delving into science fiction particularly the kind he is helping realize with his work.
 Yong Wu is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. He enjoys hiking and playing table tennis in his spare time.
Yong Wu is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. He enjoys hiking and playing table tennis in his spare time.
 Chetan Kapoor is a Senior Product Manager with Amazon EC2 team and manages GPU Compute instances. In this spare time he enjoys being outdoors, running, and spending time with his two boys.
Chetan Kapoor is a Senior Product Manager with Amazon EC2 team and manages GPU Compute instances. In this spare time he enjoys being outdoors, running, and spending time with his two boys.
 Tyler Mullenbach is a data scientist with AWS Professional Services focusing on helping customers using machine learning. Beyond coding, he enjoys woodworking and car tuning.
Tyler Mullenbach is a data scientist with AWS Professional Services focusing on helping customers using machine learning. Beyond coding, he enjoys woodworking and car tuning.
 Jarvis Lee is a data scientist with AWS Professional Services, working within the ML Solutions Labs. Outside of work, he enjoys road cycling and trail riding.
Jarvis Lee is a data scientist with AWS Professional Services, working within the ML Solutions Labs. Outside of work, he enjoys road cycling and trail riding.