AWS 기술 블로그
Amazon SageMaker HyperPod로 슈퍼브에이아이의 비전 파운데이션 모델 ‘ZERO’ 효율적으로 대규모 분산 학습하기
이 블로그는 슈퍼브에이아이의 차문수 (공동창업자, CTO), 장태웅 (머신러닝 엔지니어), 최상범(머신러닝 엔지니어) 님과 AWS 유용환 (GenAI Solutions Architect) 님이 작성해주신 블로그 입니다.
슈퍼브에이아이는 압도적인 비전 AI 노하우와 경험을 바탕으로 피지컬 AI로 확장 중인 비전 인텔리전스 기업입니다. 산업 현장에서 바로 적용 가능한 비전 파운데이션 모델 ‘ZERO(Zero-shot Object Detector)’를 어떻게 Amazon SageMaker HyperPod를 이용하여 효율적으로 학습시키고 개선했는지 소개하려 합니다.
슈퍼브에이아이는 당사가 보유한 약 10억 장의 방대한 원시 데이터 중, 산업 현장에 실제로 의미 있는 약 400만 장의 고품질 데이터를 선별 및 큐레이션하여 비전 파운데이션 모델 ZERO를 집중적으로 학습시켰습니다. 그 결과, ZERO는 특정 도메인에 국한되지 않고 실제 산업 현장을 포함하는 오픈 월드(Open World) 환경에서 다양한 객체와 패턴을 인식할 수 있는 범용성을 확보했습니다.
ZERO의 핵심 기능은 멀티모달 그라운딩(Multi-modal Grounding)입니다. 사용자가 텍스트 프롬프트로 객체를 설명하거나, 이미지 기반의 비주얼 프롬프트를 제시하면 모델은 해당 객체의 위치를 정밀하게 탐지합니다. 이를 통해 고객은 별도의 데이터 수집이나 추가 학습(Fine-tuning) 없이도, 제로샷(Zero-shot) 방식으로 산업 현장의 다양한 결함과 객체를 즉시 검출할 수 있습니다.
Amazon SageMaker HyperPod를 선택한 이유
기존 클라우드 환경에서는 단일 노드 환경만을 제공하거나, 클러스터를 제공하더라도 연 단위 플랜만 사용 가능하여 유연성이 부족하다는 한계가 있었습니다. 반면, Amazon SageMaker HyperPod는 사용 시나리오에 따라 인스턴스 크기를 유연하게 변경할 수 있으며, 고성능 노드 사용 시 EFA(Elastic Fabric Adapter)와 같은 고성능 네트워크가 기본으로 탑재되어 인프라 구성에 매우 유리합니다.
슈퍼브에이아이의 개발 프로세스는 ‘데이터 정제 및 학습 알고리즘/파라미터 개선 → 학습 → 결과 분석’의 사이클로 이루어지며, GPU를 1년 내내 사용하는 것이 아니기 때문에 HyperPod의 유연한 인스턴스 크기 조절 기능은 비용 효율성 측면에서 큰 이점을 제공했습니다.
또한, 오래된 드라이버와 운영 체제(Ubuntu 20.04 등)를 기본 탑재한 타사 클라우드와 달리, HyperPod의 AMI(Amazon Machine Image)는 최신 드라이버와 운영 체제로 꾸준히 업데이트됩니다. 이 덕분에 Flash Attention과 같이 종속성(dependency) 관리가 까다로운 핵심 패키지도 문제없이 설치할 수 있었습니다.
전체 워크플로우 개요
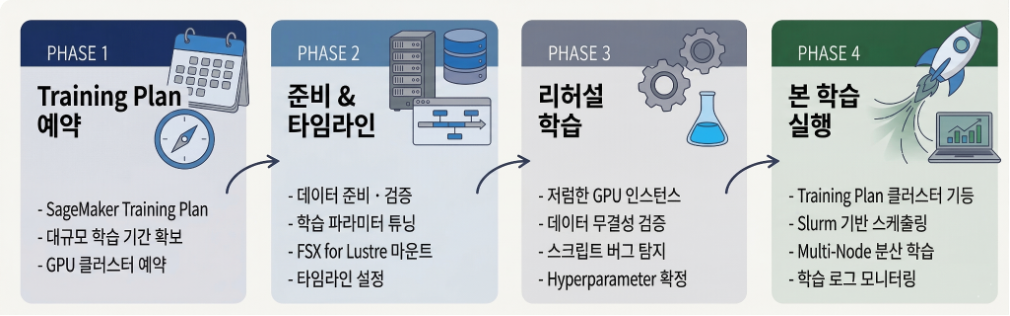
슈퍼브에이아이의 개발 사이클은 ‘데이터 정제 → 학습 파라미터 개선 → 학습 → 결과 분석’의 단계로 구성됩니다. 전체적인 워크플로우는 다음과 같습니다.
- Training Plan 예약: 먼저 Amazon SageMaker Training Plan을 예약하여 대규모 학습 기간을 확보합니다.
- 준비 단계 타임라인 설정: 데이터 준비, 학습 파라미터 튜닝 등의 타임라인을 설정합니다.
- 학습 파라미터 튜닝 및 리허설: 저렴한 GPU 인스턴스를 활용하여 트레이닝을 진행하며, 데이터 무결성 검증 및 트레이닝 스크립트의 버그를 파악합니다.
- 본 학습 진행: 학습 파라미터를 결정하고 리허설을 마치면, 저렴한 인스턴스를 해제하고 Training Plan으로 예약한 고성능 GPU 클러스터를 띄워 실제 학습을 진행합니다.
Training Plan을 통한 GPU 클러스터 예약
Training Plan 기능을 통해 고성능 네트워크로 연결된 대형 클러스터의 사용을 예약할 수 있습니다. 다만, 수요가 높기 때문에 개발 일정에 맞춰 Training Plan을 예약하기보다는, Training Plan 예약에 맞춰 개발 일정을 조정해야 합니다. 슈퍼브에이아이는 단일 노드 트레이닝 소요 시간을 바탕으로 예산을 고려하여 최대한의 기간을 예약했습니다.
데이터 준비: Amazon S3 업로드 및 최적화
실제 배포 성능은 트레이닝 데이터 분포(training distribution)에 의해 결정된다는 경험적 사실에 따라, 저희는 훈련 준비 기간의 대부분을 여러 상황을 세심하게 고려하여 광범위한 데이터를 선별하는 데 할애했습니다. 또한, 트레이닝 중 예외(Exception) 발생으로 학습이 중단되는 것을 방지하기 위해, 너무 크거나 라벨이 과도하게 많은 이미지 등 학습에 문제가 될 수 있는 데이터는 사전에 제거하거나 변경했습니다.
Amazon FSx for Lustre와 같은 고성능 파일 시스템은 처리량(throughput)은 매우 높지만, 파일 수가 수백만 개 이상이 되면 성능이 저하될 수 있습니다. 특히 Hugging Face Datasets과 같은 오픈 소스 라이브러리는 데이터셋 종류를 판단하기 위해 glob과 같은 패키지를 여러 번 호출하며 이 과정에서 파일 시스템 메타데이터를 반복적으로 읽습니다. FSx는 메타데이터 관리 서버 증설을 통해 성능을 높일 수 있지만, 관리 효율성 측면에서 여러 이미지를 단일 데이터셋 형식으로 병합하여 관리하는 것이 더 효과적입니다.
슈퍼브에이아이는 Hugging Face Datasets 라이브러리가 지원하는 Arrow 파일 기반의 데이터셋 포맷을 사용하여 4백만 장 규모의 데이터셋을 1G 단위의 샤드(shard) 약 1200개로 미리 분할한 뒤 Amazon S3에 업로드했습니다. 이처럼 데이터를 사전 변환하지 않고 개별 파일 상태의 데이터셋을 Huggingface Datasets으로 열게 되면, 필수적으로 30시간가량의 Arrow file 변환 과정을 거쳐야 합니다. 반면, 변환을 마친 데이터셋을 사용하면 단 몇 분 만에 데이터셋을 읽을 준비가 완료됩니다.
데이터를 S3로 업로드하기 위해 AWS CLI v2의 s3 sync 명령어를 사용했습니다. s3 sync 명령어와 S3 서비스는 네트워크 측면에서 매우 최적화되어 있어 내부 GPU 서버 회선의 최대 속도로 전송이 가능했습니다.
HyperPod 클러스터 생성과 FSx for Lustre 연동
Training Plan 시기가 다가오면서 트레이닝 리허설을 준비했습니다. HyperPod UI를 활용하여 클러스터를 간편하게 구성할 수 있었습니다. 멀티 노드 트레이닝의 정상 작동을 확인하기 위해 EFA를 통한 RDMA(Remote Direct Memory Access) 읽기/쓰기가 가능한 가장 저렴한 인스턴스인 g6e.8xlarge 2대를 컴퓨트 노드로 등록했습니다. 이 설정으로 클러스터와 FSx가 자동으로 생성되었습니다.
FSx가 생성되면 FSx 메뉴에서 해당 리소스를 확인할 수 있으며, ‘data repository’에 데이터가 있는 S3 버킷을 등록해야 합니다. 여기서 ‘file system path’ 값과 인스턴스 내의 경로, 그리고 ‘data repository path’ 값의 관계에 유의해야 합니다.
- FSx는 Slurm 클러스터 내의 모든 인스턴스에서 기본적으로
/fsx아래에 마운트됩니다. 홈 폴더는/fsx/ubuntu에 생성됩니다. - 예시 시나리오:
- Data Repository Path:
s3://mybucket/depth1/ - File System Path:
/s3_mapped - 이 경우, S3의
s3://mybucket/depth1/depth2/file.txt파일은 인스턴스 내/fsx/s3_mapped/depth2/file.txt에 매핑됩니다.
- Data Repository Path:
file system path는 지정한data repository path내의 파일들이/fsx폴더의 어디에 매핑될지를 결정하는 값입니다. Lustre 파일 시스템에서 파일 목록을 표시하기 위해서는 S3 서비스로부터 메타데이터를 복사해와야 하므로, 데이터의 크기가 클 경우 이 과정이 오래 걸릴 수 있습니다. 따라서 초기 설정 시 신중하게 결정해야 합니다. 또한, 기본으로 생성되는/fsx/ubuntu,/fsx/enroot등의 폴더도 고려해야 합니다.
리허설 단계: 저렴한 인스턴스로 사전 준비
#!/bin/bash
#SBATCH --job-name=zero_hyperpod
###########################
## Environment Variables ##
###########################
# NCCL configuration for distributed training
# References:
# - https://discuss.pytorch.org/t/nccl-network-is-unreachable-connection-refused-when-initializing-ddp/137352
# - https://github.com/pytorch/pytorch/issues/68893
export NCCL_SOCKET_IFNAME=ens # 필수적인 항목은 아닙니다.
export NCCL_ASYNC_ERROR_HANDLING=1
export NCCL_DEBUG=INFO # nccl 로드 과정을 상세히 볼 수 있습니다.
# Prevent CUDA async runtime errors
export CUDA_DEVICE_MAX_CONNECTIONS=1
# Set GPUs per node from environment variable or use default
: "${GPUS_PER_NODE:=8}"
export GPUS_PER_NODE
# Set batch size per device
: "${DEVICE_BATCH_SIZE:=8}"
export DEVICE_BATCH_SIZE
# Set gradient accumulation
: "${GRAD_ACCUM:=1}"
export GRAD_ACCUM
######################
#### Network Setup ####
######################
# Set master address to first node in the job
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
# Use random port between 30000 and 50000 to avoid conflicts
export MASTER_PORT=$(( RANDOM % (50000 - 30000 + 1 ) + 30000 ))
export NUM_PROCESSES=$(expr $NUM_NODES \* $GPUS_PER_NODE)
#########################
## Command and Options ##
#########################
# Container configuration
export DATA_DIR="$DATA_DIR"
export IMAGE_PATH="/fsx/PATH_TO_TRAINING_IMAGE"
# srun의 option (--container-image 등)은 pyxis slurm 플러그인이 설치돼 있어야 사용 가능합니다.
# --container-env에 등록된 env var들만 accelerate에서 읽을 수 있습니다.
srun --container-image=$IMAGE_PATH \
--container-env MASTER_ADDR,MASTER_PORT,NUM_NODES,NUM_PROCESSES,WANDB_API_KEY,DEVICE_BATCH_SIZE,GRAD_ACCUM \
--container-mounts=/fsx:/fsx:rw \
--no-container-remap-root \
--container-writable \
/bin/bash -c 'echo "** nodeid: $SLURM_NODEID n_procs: $NUM_PROCESSES n_machines: $NUM_NODES batch_size: $DEVICE_BATCH_SIZE **"; \
env ; \
accelerate launch \
--config_file config/default_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank $SLURM_NODEID \
--num_processes $NUM_PROCESSES \
--num_machines $NUM_NODES \
--rdzv_backend c10d \
./train.py \
...Fig1. 트레이닝에 사용한 sbatch 파일의 예시
S3에 업로드한 데이터를 FSx에 매핑한 후, 추가한 g6e.8xlarge 인스턴스 2대를 활용하여 멀티 노드 트레이닝 리허설을 진행했습니다. FSx의 Data Repository에 등록하더라도 기본적으로 지연 로딩(lazy loading)을 하기 때문에 메타데이터만 가져오고 실제 데이터는 즉시 Import하지 않습니다. 데이터 양이 많으면 실제 데이터 복사 과정도 오래 걸립니다. 트레이닝 리허설을 진행함으로써 본 트레이닝에 앞서 FSx에 데이터를 미리 로드할 수 있으며, 이로 인해 수 시간을 절약할 수 있습니다.
또한, 트레이닝 리허설을 진행함으로써 실제 트레이닝 시 발생할 수 있는 다양한 문제를 조기에 발견하고 시정할 수 있었습니다. 예를 들어, sbatch 파일에서 WandB API key 환경변수 설정 오류로 인해 wandb login 과정에서 트레이닝 스크립트가 멈추거나, 체크포인트 저장 디렉토리 소유자가 root로 설정되어 체크포인트 저장 시 exception이 발생해서 스크립트가 중단되는 등등의 경우가 있었습니다. 이렇게 사소하지만 트레이닝을 예상치 못하게 중단시켜 비용을 초래할 수 있는 문제들을 사전에 파악하고 해결할 수 있었습니다.
인스턴스 교체: 리허설 → 본 학습 전환
Training Plan 시작 시각이 다가오면, 다음과 같은 절차를 거쳐 인스턴스를 교체합니다.
1. 리허설 인스턴스 제거: 저렴한 리허설 인스턴스(g6e.8xlarge)를 클러스터에서 제거합니다.
2. provisioning_parameters.json 편집: HyperPod 생성 시 자동 생성된 라이프사이클 스크립트를 사용했다면, 새로 생성된 S3 버킷에 라이프사이클 스크립트 내용이 등록됩니다. 새 인스턴스 그룹을 추가하기 전에 provisioning_parameters.json 파일을 편집해야 합니다.
아래는 예시입니다.
3. 새 인스턴스 그룹 추가: HyperPod 클러스터 페이지에서 ‘Edit’을 클릭하고, provisioning_parameter.json에 새로 추가한 instance_group_name과 동일한 이름으로 Training Plan으로 예약한 인스턴스들을 포함할 그룹을 추가한 후 ‘Save’를 클릭합니다.
4. Target Instance Count 업데이트: Training Plan 시작 전에는 Target Instance Count가 0으로 설정되어 있습니다. Training Plan이 시작되면 예약한 인스턴스의 수로 업데이트하고 ‘Save’를 클릭합니다. 약 20분 후 새 인스턴스가 동작하기 시작합니다.
5. Slurm 노드 등록 확인 및 재구성: sinfo 명령 등으로 Slurm에 노드들이 정상적으로 등록되었는지 확인합니다. 새로 뜬 인스턴스의 Slurm 데몬이 Pyxis 플러그인을 일시적으로 인식하지 못하는 문제를 해결하기 위해 sudo scontrol reconfigure 명령을 한 번 실행합니다.
- 파티션 수동 변경: 별도로 라이프사이클 스크립트를 수정하지 않았다면 Slurm 파티션은 예전 설정 그대로 남아있을 수 있습니다.
sudo vi /opt/slurm/etc/slurm.conf를 실행하여 최근에 추가된 인스턴스 목록을 확인하고, 노드 이름들을 쉼표(,)로 구분하여 아래와 같이 새 파티션으로 등록합니다.
sudo scontrol reconfigure를 실행하여 설정을 적용합니다.
본 학습 실행
리허설과 동일한 방식으로 트레이닝 스크립트를 실행하여 학습을 진행합니다. 슈퍼브에이아이는 인스턴스 생성 대기 시간 등을 모두 포함하여 Training Plan 시작 후 약 30분 정도 뒤에 실제 트레이닝을 시작할 수 있었습니다. 특히, 리허설 과정에서 이미 S3 데이터가 FSx로 모두 복사되었기 때문에 추가적인 데이터 로드 대기 시간이 필요하지 않았습니다.
WandB를 사용해서 loss/GPU 사용률의 변화를 기록했고, WandB API와 telegram 봇을 활용해서 간단한 알람 시스템을 구성했습니다. 리허설 트레이닝 덕택에 미리 에러를 수정한 결과, Training Plan 기간을 거의 손실 없이 학습에 활용할 수 있었습니다.
비용 분석 및 효과 정리
Amazon SageMaker HyperPod의 유연성 덕분에 저렴한 비용으로 트레이닝 리허설을 진행할 수 있었고, 이 과정에서 다양한 버그를 사전에 수정할 기회를 얻었습니다. 만약 고성능 인스턴스 예약 기간에 이러한 버그를 수정했다면, 예약 기간의 상당 부분을 불필요하게 낭비했을 것입니다. 또한, 리허설 과정에서 S3에서 FSx로 데이터를 미리 로드하여 수 시간을 절약할 수 있었습니다.
| 구분 | 효과 |
| 개발 생산성 | 인프라 구성 및 튜닝 리소스 크게 절감 |
| 비용 효율성 | 저렴한 인스턴스로 사전 리허설 진행, 고성능 인스턴스 유휴 시간 최소화 |
| 학습 시간 단축 | S3에서 FSx로의 데이터 사전 로드 (수 시간 절약) |
| 안정성 확보 | 리허설을 통한 치명적인 트레이닝 스크립트 버그 사전 파악 |
결론 및 팁
이 워크플로우는 데이터 규모가 크고, 고성능 노드 예약 기간이 길어 시간당 비용이 비싼 대규모 모델 학습 시 특히 유용합니다. Amazon SageMaker HyperPod의 유연한 인프라 구성과 고성능 네트워크, 손쉬운 데이터 통합 기능을 통해 슈퍼브에이아이는 인프라 운영 부담을 최소화하고 모델 성능 고도화에 집중할 수 있었습니다.
ZERO를 직접 사용해 보세요
ZERO 모델은 AWS Marketplace에서 바로 구독하고 배포할 수 있습니다. SageMaker 엔드포인트 하나로 수 분 내 추론 환경을 구성할 수 있으며, ml.g4dn.xlarge 인스턴스만으로도 운영이 가능합니다.
SageMaker HyperPod에 대해 더 자세히 알아보기 위해서는, AI on SageMaker HyperPod 가이드, lifecycle 스크립트에 대한 best practice와 FSx 성능 튜닝 가이드를 참고하시기 바랍니다.