AWS 기술 블로그
Config의 Amazon EKS Spot 기반 대규모 RFM 데이터 파이프라인 구축
소개
Config는 General-Purpose Robot Foundation Model을 실현하기 위한 데이터 인프라와 기술을 구축하는 기업입니다. 다양한 실제 환경에서 로봇이 양손 조작 작업을 안정적으로 수행할 수 있도록, 대규모 학습 데이터의 수집부터 전처리, 모델 학습, 실환경 검증까지 이어지는 end-to-end 파이프라인을 운영하고 있습니다. 현재까지 약 10만 시간 규모의 액션 데이터를 구축했으며, 월 약 2만 시간의 데이터를 지속적으로 수집하고 있습니다.
이미지 1. About Config
특히 Config는 사람이 수행한 조작 영상으로부터 로봇 정렬 액션(robot-aligned action)을 추정하는 독자적인 파이프라인을 보유하고 있습니다. 이를 통해 로봇 데이터 수집 비용과 운영 부담을 줄이면서도 대규모의 다양한 학습 데이터를 효율적으로 확보할 수 있으며, 이렇게 학습된 Robot Foundation Model(RFM)은 소량의 작업별 데이터만으로도 약 48시간 내에 특정 작업에 대한 정책 모델을 효과적으로 학습하여 배포할 수 있습니다.

GIF 1. 사람 조작 데이터와 추정된 7-DoF 로봇 정렬 액션
이 글에서는 이러한 대규모 데이터 전처리 파이프라인을 기존 Amazon SQS + AWS Lambda 기반에서 Amazon EKS + Amazon EC2 Spot Instances + RabbitMQ + KEDA 기반으로 마이그레이션하여, 처리 비용을 70~90% 절감하고 처리 시간을 수 일에서 수 시간으로 단축한 과정을 공유합니다.
데이터 전처리 파이프라인의 역할
RFM 학습을 위해서는 수집된 원시 데이터를 모델이 학습할 수 있는 형태로 변환하는 전처리 과정이 필수적입니다. Config의 데이터 파이프라인은 크게 두 가지 유형의 데이터 처리 작업을 수행합니다.
(1) 사람 조작 영상 데이터로부터 로봇 정렬 액션 표현(robot-aligned action representation)을 추정하는 액션 라벨링 과정
(2) 데이터를 세그먼트 단위로 분할하고, 각 프레임에 대응하는 상태 데이터를 시간 축으로 정렬하여 학습에 적합한 형태로 변환하는 과정
하나의 에피소드는 평균적으로 3개의 카메라 뷰 영상(평균 25~50MB, 약 1~2분 분량)과 상태 데이터, 메타데이터로 구성됩니다. 개별 에피소드당 총 데이터 용량은 평균 75~150MB에 달하며, 수십만 개의 에피소드를 처리할 경우 전체 데이터셋은 수십 TB 규모에 이릅니다.
각 에피소드의 전처리 과정은 영상 디코딩, 프레임 추출, 상태 정렬, 모델 추론 등 다단계 처리를 필요로 합니다. 따라서 수만~수십만 개 에피소드를 대규모로 병렬 처리하기 위해서, CPU 전처리–GPU 추론–CPU 후처리 파이프라인을 효율적으로 활용할 수 있는 컴퓨팅 인프라가 필수적입니다.
기존 아키텍처와 한계
SQS + Lambda 기반 파이프라인
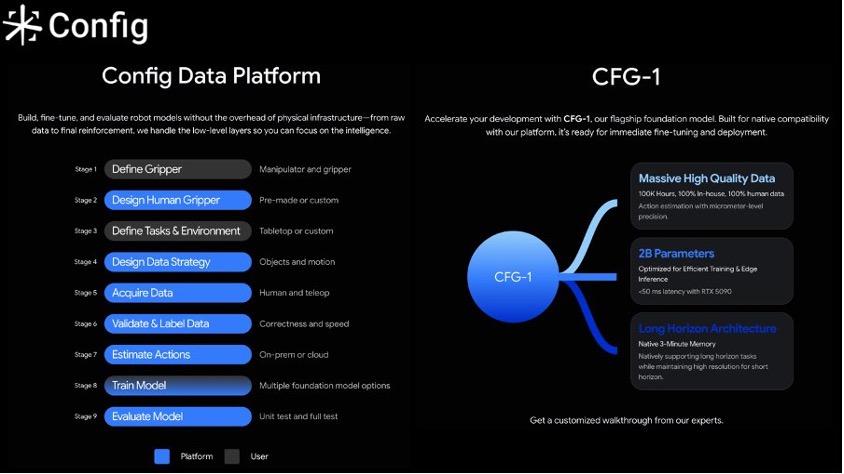
초기 데이터 전처리 파이프라인은 Amazon SQS와 AWS Lambda를 활용한 서버리스 아키텍처로 구성되어 있었습니다. Amazon S3에 저장된 원시 데이터의 경로를 SQS 메시지로 발행하면, Lambda 함수가 개별 에피소드를 처리하여 결과를 S3에 저장하는 단순한 구조였습니다.
이미지 2. 기존 아키텍처 다이어그램
한계점
데이터 규모와 사용자 수가 급격히 증가하면서 다음과 같은 한계에 직면했습니다.
- 단일 큐(Single Queue)로 인한 순차 대기 병목: 기존 아키텍처에서 서비스별로 하나의 SQS 큐만 운영하는 구조였기 때문에, 여러 사용자가 동시에 작업을 요청하면 하나의 큐에서 순차적으로 대기해야 했습니다. 사용자가 늘어날수록 대기 시간이 길어지고, 대규모 배치 작업이 큐를 점유하면 다른 사용자의 소규모 작업까지 지연되었습니다.
- AWS Lambda의 기본 제약: Lambda에는 계정 수준의 동시 실행 기본 할당량과 최대 실행 시간 제한(15분)이 존재합니다. 할당량 상향 요청이 가능하지만, 수만 개의 에피소드를 동시에 처리해야 하는 대규모 배치 워크로드에는 구조적으로 적합하지 않았습니다.
- 높은 비용: Lambda는 On-Demand 가격으로만 실행되므로, 대규모 배치 처리 시 Spot Instance 활용 대비 상당히 높은 비용이 발생했습니다.
- 제한된 운영 가시성: 개별 작업의 진행 상태를 실시간으로 파악하기 어려웠습니다. 어떤 에피소드가 처리 중이고, 어떤 것이 실패했는지를 즉시 확인할 수 있는 모니터링 환경이 부족했습니다.
새로운 아키텍처 개요
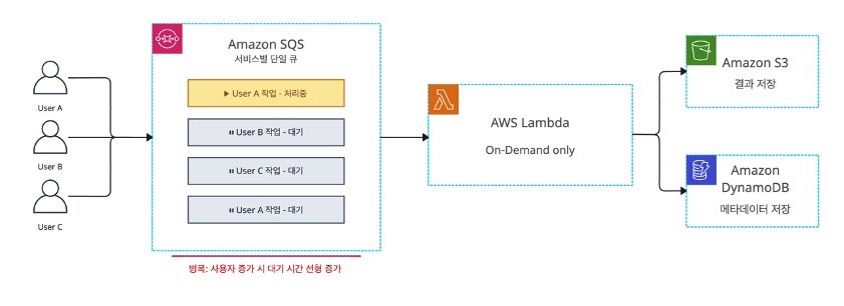
이러한 한계를 해결하기 위해, Amazon EKS 클러스터 위에 RabbitMQ, KEDA, Karpenter를 결합한 새로운 아키텍처를 설계했습니다.
이미지 3. 새로운 EKS 기반 아키텍처 다이어그램
핵심 구성요소
| 구성요소 | 역할 | |
|---|---|---|
| 1 | Amazon EKS | 컨테이너 오케스트레이션 플랫폼 |
| 2 | RabbitMQ (EKS 내 배포) | Job별 독립 큐 관리, Quorum Queue로 메시지 안정성 보장 |
| 3 | KEDA | RabbitMQ 큐 깊이 기반 Pod 자동 스케일링 |
| 4 | Karpenter | Pending Pod 감지 시 Spot/On-Demand 노드 자동 프로비저닝 |
| 5 | Amazon EC2 Spot Instances | CPU/GPU 워커 노드, On-Demand 대비 70~90% 비용 절감 |
핵심 변화: 단일 큐에서 Job별 동적 큐로
기존 아키텍처에서 가장 큰 병목이었던 단일 큐 문제를 해결하기 위해, RabbitMQ 기반의 Job별 동적 큐 생성 패턴을 도입했습니다. 각 배치 작업이 시작되면 해당 작업 전용의 큐와 워커가 동적으로 생성되고, 작업이 완료되면 자동으로 정리됩니다. 이를 통해 여러 사용자가 동시에 독립적인 작업을 병렬로 실행할 수 있고, 한 사용자의 대규모 작업이 다른 사용자에게 영향을 주지 않으며, 각 작업별로 독립적인 스케일링과 진행률 모니터링이 가능합니다.
Karpenter 기반 노드 관리
Amazon EKS Auto Mode에도 Karpenter가 내장되어 있지만, GPU Spot NodePool의 인스턴스 타입 세밀 지정, taint 설정, disruption 정책 등 워크로드별 세밀한 제어가 필요하여 Karpenter를 직접 배포했습니다. Karpenter를 사용하여 워크로드 특성에 맞는 여러 종류의 노드 풀(NodePool)을 구성했습니다.
- On-Demand 노드: RabbitMQ 클러스터, KEDA 등 안정성이 중요한 인프라 컴포넌트 배치. Spot 중단의 영향을 받지 않아야 하는 핵심 서비스용.
- CPU Spot 노드: 영상 전처리, 후처리 등 CPU 기반 워커 실행. 다양한 인스턴스 패밀리를 지정하여 Spot 용량 확보 가능성을 극대화.
- GPU Spot 노드: 액션 라벨링 추론 등 GPU 워커 실행. GPU taint를 설정하여 CPU 워크로드가 GPU 노드에 스케줄링되지 않도록 방지.
Spot 용량 확보를 위해 특히 신경 쓴 부분은 인스턴스 다양성입니다. 단일 패밀리에 의존하면 Spot 용량 부족 시 노드 프로비저닝이 지연될 수 있으므로, 아래와 같이 다양한 인스턴스 패밀리를 지정하여 가용 용량 풀을 넓혔습니다. Karpenter는 기본적으로 price-capacity-optimized 할당 전략을 사용하므로, 가격과 중단 가능성을 함께 고려하여 최적의 인스턴스를 선택합니다.
# CPU Spot NodePool 예시
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: cpu-spot
spec:
template:
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["t", "c", "m", "r"] # 다양한 패밀리로 Spot 용량 극대화
minValues: 3 # 최소 3개 패밀리 이상에서 선택하도록 설정
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"] # 3세대 이상
limits:
cpu: "4500" # 비용 폭주 방지를 위한 클러스터 레벨 제한
memory: "8000Gi"
disruption:
consolidationPolicy: WhenEmpty # Pod가 남아있으면 처리 중이므로 consolidation하지 않음
consolidateAfter: 30mRabbitMQ 클러스터 및 큐 아키텍처
클러스터 구성
RabbitMQ Cluster Operator를 사용하여 EKS 클러스터 내에 고가용성 RabbitMQ 클러스터를 배포했습니다. Amazon MQ for RabbitMQ(관리형 서비스)도 고려했으나, 동일 수준의 관리형 서비스 비용 대비 EKS 내에 직접 배포하는 것이 더 경제적이었고, Quorum Queue 세부 설정을 직접 제어할 수 있다는 장점이 있어 직접 배포 방식을 선택했습니다. RabbitMQ는 안정성이 최우선이므로 Spot이 아닌 On-Demand 노드에 배치하고, Pod Anti-Affinity를 설정하여 각 replica가 서로 다른 물리 노드에 분산되도록 구성했습니다.
모든 큐는 기본적으로 Quorum Queue로 생성됩니다. Quorum Queue는 Raft 합의 알고리즘을 사용하여 메시지를 여러 노드에 복제하므로, 단일 노드 장애 시에도 메시지가 유실되지 않습니다. Consumer timeout은 20분으로 설정했는데, 이는 워커의 에피소드당 최대 처리 시간(15분)에 5분의 여유를 더한 값입니다. 이를 통해 비정상 종료된 워커의 메시지가 너무 오래 잠기지 않으면서도, 정상 처리 중인 워커의 연결이 조기 종료되지 않도록 합니다. 또한 PodDisruptionBudget(PDB)을 설정하여, 노드 업그레이드 등의 상황에서도 최소 replica 수가 유지되도록 합니다.
# RabbitMQ Cluster 구성 예시
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: rabbitmq
spec:
replicas: 3
image: rabbitmq:4.2.2-management
resources:
requests:
cpu: "1"
memory: 4Gi
limits:
cpu: "2"
memory: 8Gi
persistence:
storageClassName: gp3
storage: 50Gi
rabbitmq:
additionalConfig: |
default_queue_type = quorum
consumer_timeout = 1200000 # 20분: 워커 타임아웃(15분) + 5분 버퍼Job별 동적 큐 패턴
이 아키텍처의 핵심은 Job별 동적 큐 패턴입니다. 각 배치 작업이 시작되면 해당 Job 전용의 작업 큐와 Dead Letter Queue(DLQ)가 동적으로 생성됩니다.
job_{job_id}_{task_type} ← 작업 큐 (Quorum Queue)
├─ x-delivery-limit: 3 ← 최대 3회 재시도
├─ x-dead-letter-routing-key ← 실패 시 DLQ로 라우팅
└─ x-consumer-timeout: 20min ← 워커 무응답 시 자동 재분배
↓ (3회 실패 후)
dlq_job_{job_id}_{task_type} ← Dead Letter Queue
├─ x-message-ttl: 24시간 ← 메시지 자동 삭제
└─ x-expires: 25시간 ← 큐 자체 자동 삭제# Job별 Quorum Queue 동적 생성 예시
def create_job_queue(self, job_id, task_type, max_retries=3):
queue_name = f"job_{job_id}_{task_type}"
dlq_name = f"dlq_{queue_name}"
# Job별 DLQ 생성 (24시간 TTL, 이후 자동 삭제)
self.channel.queue_declare(
queue=dlq_name, durable=True,
arguments={
"x-queue-type": "quorum",
"x-message-ttl": 86400000,
"x-expires": 86400000 + 3600000,
},
)
# 작업 큐 생성 (Quorum Queue + DLQ 연결)
self.channel.queue_declare(
queue=queue_name, durable=True,
arguments={
"x-queue-type": "quorum",
"x-delivery-limit": max_retries,
"x-dead-letter-exchange": "",
"x-dead-letter-routing-key": dlq_name,
"x-consumer-timeout": 1200000,
},
)
return queue_name이 패턴은 세 가지 면에서 운영을 단순화합니다. 첫째, 각 Job이 독립적인 큐를 가지므로 여러 사용자가 서로 간섭 없이 동시에 작업을 실행할 수 있어, 한 사용자의 대규모 배치가 다른 사용자의 작업을 지연시키는 문제가 근본적으로 해결됩니다. 둘째, x-delivery-limit을 통해 RabbitMQ가 재시도 횟수를 자체 관리하므로, 워커 코드에 별도의 재시도 로직을 구현할 필요 없이 ACK/NACK만 전송하면 됩니다. 셋째, DLQ 메시지는 24시간 후, 빈 DLQ는 25시간 후 자동 삭제되므로, Job이 완료된 이후 별도의 정리 작업 없이 큐가 자동으로 소멸됩니다.
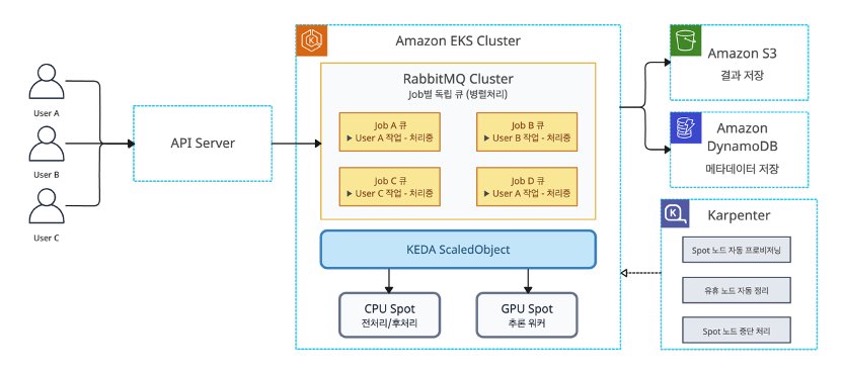
KEDA 기반 자동 스케일링
KEDA(Kubernetes Event-Driven Autoscaling)는 RabbitMQ 큐의 메시지 수를 주기적으로 모니터링하여 워커 Pod의 replica 수를 자동으로 조절합니다. 큐에 메시지가 쌓이면 Pod를 늘리고, 큐가 비면 Pod를 0개까지 줄입니다. KEDA가 Pod 수를 늘리면 Karpenter가 Pending 상태의 Pod를 감지하고 Spot 노드를 자동으로 프로비저닝하는 연쇄 스케일링 구조입니다.
이미지 4. KEDA + Karpenter 기반 자동 스케일링 시퀀스 다이어그램
각 배치 작업이 시작되면 Deployment(replicas=0)와 KEDA ScaledObject가 동적으로 생성됩니다. minReplicaCount: 0으로 설정되어 큐가 비어 있으면 워커 Pod가 0개로 스케일다운되어 컴퓨팅 비용이 발생하지 않고, 메시지가 들어오면 10초 내에 스케일업이 시작됩니다.
# KEDA ScaledObject 동적 생성 예시
scaled_object = {
"apiVersion": "keda.sh/v1alpha1",
"kind": "ScaledObject",
"spec": {
"scaleTargetRef": {"name": deployment_name},
"minReplicaCount": 0,
"maxReplicaCount": max_replicas,
"cooldownPeriod": 30,
"pollingInterval": 10,
"triggers": [{
"type": "rabbitmq",
"metadata": {
"queueName": queue_name,
"mode": "QueueLength",
"value": "1", # 메시지 1개당 Pod 1개, maxReplicaCount로 상한 제어
},
"authenticationRef": {"name": "<your-auth-secret-name>"},
}],
},
}Spot 인스턴스 중단 처리
Spot Instance는 On-Demand 대비 최대 90%의 비용을 절감할 수 있지만, 필요 시 언제든지 회수될 수 있으며 중단 2분 전 알림만 제공됩니다. 이와 같은 상황에서 데이터 손실 없이 작업을 안전하게 처리하기 위해, 다층 보호 전략을 설계했습니다.
인프라 레이어 (Karpenter + EventBridge): Karpenter v1에서는 Spot 중단 처리가 내장되어 있으므로, 별도의 AWS Node Termination Handler(NTH)를 설치할 필요가 없습니다. Karpenter가 Amazon EventBridge와 Amazon SQS를 통해 EC2 Spot 중단 경고를 수신하며, Spot 중단뿐 아니라 EC2 Rebalance Recommendation이나 Instance State Change 이벤트도 동일하게 처리합니다. 중단이 감지되면 영향받는 노드를 즉시 drain하고, 앞서 다양한 인스턴스 패밀리를 지정해 둔 덕분에 용량이 부족한 패밀리 대신 가용한 다른 패밀리로 새 Spot 노드를 프로비저닝합니다.
애플리케이션 레이어 (SIGTERM 핸들러): 워커 Pod의 terminationGracePeriodSeconds를 충분히 길게 설정하여, SIGTERM 수신 후 현재 처리 중인 작업을 안전하게 NACK할 수 있는 시간을 확보합니다. NACK된 메시지는 RabbitMQ가 큐에 다시 넣어 다른 워커가 재처리하며, x-delivery-limit에 따라 재시도 횟수가 관리됩니다.
# 워커의 SIGTERM 핸들러 예시
def _handle_signal(self, signum, frame):
self._should_stop = True
if self._current_delivery_tag is not None:
self._current_channel.basic_nack(
delivery_tag=self._current_delivery_tag,
requeue=True # 큐에 반환하여 다른 워커가 재처리
)
self._current_delivery_tag = None메시지 큐 레이어 (Quorum Queue): 메시지는 여러 노드에 복제되어 유실되지 않으며, 워커가 비정상 종료하여 ACK을 보내지 못하더라도 consumer timeout(20분) 이후 자동으로 메시지가 재분배됩니다.
이 다층 보호를 통해, Spot 인스턴스 중단 시에도 데이터 손실 없이 작업의 완료를 보장합니다.
데이터 처리 워크로드
사람이 작업을 수행한 영상에는 로봇의 구조화된 상태 데이터가 존재하지 않으므로, 영상으로부터 7-DoF 로봇 정렬 액션을 추정하는 라벨링 과정이 필요합니다. 이 과정은 CPU와 GPU를 혼합 활용하는 3단계 파이프라인으로 구성됩니다.
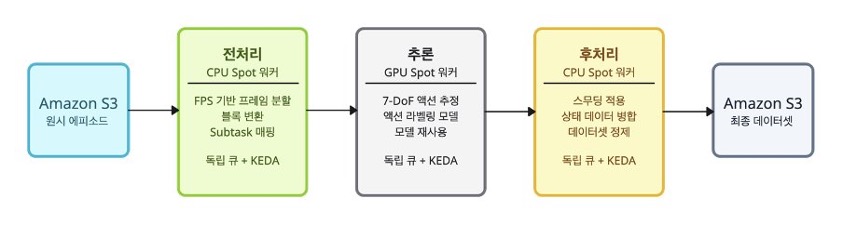
이미지 5. 액션 라벨링 3단계 파이프라인 다이어그램
- 전처리 (CPU): 각 에피소드의 영상 프레임을 일정 크기의 블록 단위로 분할하고, 추론 모델의 입력에 맞는 형태로 변환합니다. 시간적 맥락을 위한 전후 프레임도 함께 포함시킵니다.
- 추론 (GPU): Config에서 개발한 액션 라벨링 모델을 사용하여 각 프레임에서 7-DoF 로봇 정렬 액션을 추정합니다. GPU 워커는 모델을 한 번 로드한 후 동일한 설정의 모든 에피소드에 재사용하여, 모델 로딩 오버헤드를 최소화합니다.
- 후처리 (CPU): 추론 결과에 선택적으로 스무딩을 적용하여 노이즈를 완화하고, 기존 상태 데이터와 병합하여 최종 학습 데이터셋 형태로 정제합니다.
각 단계는 독립적인 RabbitMQ 큐와 KEDA ScaledObject를 가지므로, 단계별로 독립적으로 스케일링됩니다.
도입 결과
| 항목 | SQS + Lambda (기존) | RabbitMQ + EKS Spot (신규) | |
|---|---|---|---|
| 1 | 작업 병렬성 | 단일 큐 순차 대기 | Job별 독립 큐, 완전 병렬 |
| 2 | 컴퓨팅 비용 | On-Demand 100% | 10~30% (70~90% 절감) |
| 3 | 처리 시간 (대규모 배치) | 수 일 | 수 시간 |
| 4 | 최대 동시 처리 | Lambda 동시 실행 제한 | 1,000+ Pod |
| 5 | 다중 사용자 | 순차 대기 | 동시 독립 실행 |
| 6 | 장애 복구 | 수동 재처리 | 자동 NACK + 재시도 |
| 7 | 큐 모니터링 | 제한적 | RabbitMQ Management UI |
| 8 | 작업 없을 때 | 서버리스 | Scale-to-Zero |
가장 의미 있는 변화는 순차 대기에서 완전 병렬 처리로의 전환이었습니다. 기존에는 단일 큐 구조 특성상 사용자가 몰릴 경우 병목이 불가피한 구조였지만, Job별 동적 큐 패턴으로 전환하면서 1,000개 이상의 Pod를 동시에 운영하며 여러 사용자의 작업이 서로 간섭 없이 처리될 수 있게 되었습니다. 비용 면에서는 Spot Instance 활용으로 On-Demand 대비 70~90%를 절감했습니다. 운영 가시성 면에서도 크게 개선되었습니다. RabbitMQ Management UI를 통해 각 큐의 메시지 수, 처리율, consumer 연결 수를 실시간으로 확인할 수 있으며, Job별 독립 큐 구조 덕분에 각 작업의 진행률을 처리된 메시지 수 / 전체 메시지 수로 간단히 추적할 수 있습니다.
결론
Config는 Amazon EKS, EC2 Spot Instances, RabbitMQ, KEDA, Karpenter를 결합하여, RFM 학습을 위한 대규모 비디오 및 액션 데이터 전처리 파이프라인을 구축했습니다. 기존 SQS + Lambda 기반의 단일 큐 순차 처리에서, Job별 동적 큐를 통한 완전 병렬 처리로 전환하여 다수의 사용자가 동시에 독립적으로 작업을 실행할 수 있게 되었습니다.
이를 통해 On-Demand 대비 비용을 70~90% 절감하고, 처리 시간을 수 일에서 수 시간으로 단축했으며, Spot 인스턴스 중단 시에도 데이터 손실 없이 작업의 완료를 보장하는 안정성을 확보했습니다. 이 아키텍처는 로봇 데이터 전처리에 한정되지 않으며, 영상 인코딩, ML 추론 파이프라인, 대규모 ETL 등 대규모 배치 처리가 필요한 다양한 워크로드에도 동일하게 적용할 수 있습니다.
이러한 효율적인 데이터 인프라를 기반으로, Config는 다양한 실제 환경에서 적용 가능한 General-Purpose Robot Foundation Model의 실현을 향해 나아가고 있습니다.
Amazon EKS와 Spot Instances를 활용한 비용 효율적인 데이터 파이프라인 구축에 대해 더 알아보려면 다음 리소스를 참고하세요:
- Amazon EKS 시작하기: https://aws.amazon.com/eks/getting-started/
- Amazon EC2 Spot Instances 모범 사례: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-best-practices.html
- Karpenter 공식 문서: https://karpenter.sh/docs/
- KEDA를 활용한 Kubernetes 이벤트 기반 오토스케일링: https://keda.sh/docs/
- Amazon EKS 모범 사례 가이드