AWS 기술 블로그
Amazon RDS for PostgreSQL에서 고성능 시계열 데이터 테이블 설계
이 글은 AWS Database Blog에 게시된 Designing high-performance time series data tables on Amazon RDS for PostgreSQL by Jim Mlodgenski and Andy Katz을 한국어 번역 및 편집하였습니다.
시계열 데이터(Time series)를 저장해야 하는 많은 조직들이 있습니다. 일부 조직은 사물 인터넷(IoT, Internet of Things) 디바이스에서 메트릭을 수집하는 것과 같은 대량의 시계열 데이터를 저장하고 쿼리하도록 설계된 애플리케이션을 가지고 있습니다. 또다른 경우에는 OLTP 데이터베이스의 트랜잭션 히스토리 테이블과 같은 단일 시계열 데이터 테이블을 가지고 있을 수도 있습니다. 시계열 데이터를 Amazon Relational Database Service (Amazon RDS) for PostgreSQL에 저장하는 것은 PostgresSQL에 이미 있는 트랜잭션 데이터와 조인해야 하는 경우 올바른 선택입니다. 수집할 데이터를 배치 처리하여 더 큰 그룹으로 로드할 수 있는 경우에도 올바른 선택이 될 수 있습니다. 시계열 데이터를 독립형 애플리케이션에서 사용하거나 여러 위치 또는 센서에서 직접 로드될 경우, Amazon Timestream처럼 특정 목적에 맞게 설계된 데이터베이스가 더 적합한 선택일 수 있습니다. 이 글에서는 PostgreSQL에 적합한 워크로드에 초점을 맞춰 살펴보겠습니다.
그 특성상 시계열 테이블은 지속적으로 크기가 커집니다. 이러한 테이블이 너무 커질 경우, 여러 개의 작은 테이블로 분할하면 데이터베이스 성능을 향상시키고 훨씬 쉽게 유지 관리할 수 있습니다. 테이블을 여러 테이블로 분할하는 것을 파티셔닝이라고 합니다. 파티셔닝을 올바르게 수행하면, 파티셔닝된 테이블에 액세스하는 애플리케이션은 요청한 데이터에 더 빠르게 액세스하는 것 외에는 어떠한 차이도 느끼지 못합니다.
PostgreSQL은 버전 10부터 테이블 파티셔닝을 지원합니다. 최근 버전의 PostgreSQL에는 시계열 데이터 성능을 향상시키는 인덱싱 및 파티셔닝 개선 사항이 추가됐습니다. PostgreSQL 12에서는 부모 테이블에 대한 배타적 잠금(Exclusive lock)을 걸지 않고 파티션을 추가할 수 있는 기능을 도입했으며, 플랜 알고리즘(Planning algorithm)을 변경하여 수천 개의 파티션을 지원할 수 있게 되었습니다. PostgreSQL 13은 이러한 기능을 기반으로 구축되었습니다. 이러한 확장을 가능하게 하는 PostgreSQL 13의 주요 기능 중 하나는 파티션 프루닝(Partition pruning)의 개선입니다. 파티션 프루닝은 쿼리와 관련없는 데이터를 포함하는 파티션을 무시할 수 있는 기능입니다. 이전 버전의 PostgreSQL은 효과적으로 파티션 프루닝을 할 수 없어, 많은 쿼리들이 모든 파티션들을 스캔해야 했습니다. Amazon RDS for PostgreSQL는 여러 파티션을 사용하여 시계열 데이터를 훨씬 쉽게 유지 관리할 수 있는 도구를 제공합니다. 이 블로그에서는 고도로 파티셔닝된 시계열 테이블을 관리하는데 유용한 pg_partman 및 pg_cron 확장(Extension)에 대해 설명합니다. 대부분의 경우 PostgreSQL은 연간 백만 개의 메트릭부터 초당 백만 개 이상의 메트릭에 이르는 조직의 시계열 데이터를 처리할 수 있습니다. 하지만 모든 테이블에서 파티셔닝이 유용한 것은 아니며, 필요하지 않은 경우 데이터베이스 성능을 저하시킬 수 있습니다. 파티셔닝을 통해 성능을 향상시키려면 시계열 데이터를 잘 처리하는 테이블을 설계하기 위해 몇 가지 사전에 고려해야 할 사항이 있습니다.
데이터베이스 관점에서 시계열 데이터는 몇 가지 주요 특징을 보입니다. 첫째, 시계열 데이터는 변경 불가능한 추가 전용(Append-only) 로그로 취급됩니다. 즉, 데이터는 업데이트되지 않고 삽입됩니다. 행이 정기적으로 업데이트되는 재고 관리 시스템 같은 비즈니스 애플리케이션 데이터와는 달리, 시계열 데이터는 변경 사항이 발생하면 테이블에 새로운 행이 추가됩니다. 기존 행은 불변으로 취급되며, 새로운 정보가 테이블에 추가됩니다. 데이터 정리가 필요한 경우 오래된 행은 삭제될 수 있지만, 변경되지는 않습니다. 또한 데이터는 시간순으로 삽입됩니다. 센서가 일정 기간 오프라인 상태가 되어 오래된 데이터가 수집되는 경우와 같은 예외는 있지만, 그런 경우에도 누락된 기간 동안의 데이터는 순서대로 저장됩니다. 데이터 접근은 일반적인 OLTP 데이터베이스에서처럼 랜덤하지 않습니다. 즉, 데이터에 어느 정도 자연스러운 순서가 있다는 것을 의미합니다. 대부분의 최신 데이터가 삽입되는 동안, 오래된 데이터는 이미 테이블에 저장되어 있는 경향이 있습니다.
이 블로그는 PostgreSQL에서 시계열 데이터를 처리하는 방법을 자세히 다루는 시리즈의 첫 번째 글입니다. 이 글에서는 시계열 데이터를 저장하는 데이터 모델을 설계할 때 고려해야 할 사항들을 살펴봅니다. 먼저 시계열 테이블에 적합한 데이터 타입 선택에 대해 논의할 것입니다. 다음으로 시계열 테이블의 인덱싱 고려 사항을 살펴보겠습니다. 마지막으로 시계열 테이블의 파티셔닝을 검토할 것입니다. 이 글에서 설명하는 원칙을 따르면 시계열 테이블을 일반 테이블처럼 취급하는 것보다 훨씬 큰 성능 향상을 얻을 수 있습니다. 간단한 벤치마크 도구를 사용하여 메트릭 수집을 시뮬레이션하고 PostgreSQL이 기본적으로 시계열 데이터를 처리하는 방법을 설명합니다. 이 벤치마크는 트럭 운송 차량의 메트릭을 추적하는 가상의 회사를 가정합니다.
테이블 개요
트럭 메트릭을 저장하는 메인 테이블은 readings 테이블입니다. 이 테이블은 측정값이 수집되는 시간 외에도 트럭의 위도, 경도, 고도, 속도와 같은 데이터 포인트를 저장합니다. 다음 테이블 정의를 참조하세요:
트럭 상태의 진단 정보(Diagnostics)를 저장하는 유사한 구조의 테이블들도 있습니다. 예를 들어, 연료 레벨, 트럭의 상태(이동 중인지 정지 중인지를 나타냄), 그리고 트럭의 모델 번호 및 적재 용량과 같은 메타데이터를 저장하는 태그들 등입니다.
메트릭 수집을 시뮬레이션하기 위해 벤치마크는 PostgreSQL의 COPY 명령을 사용하여 병렬 스레드로 미리 생성된 데이터를 로드합니다. 이 글에서는 트럭 100대에 대한 1년이 조금 넘는 기간의 데이터를 사용합니다. 데이터는 2020년 1월 1일부터 2021년 1월 12일까지의 기간을 포함하며, 이는 총 5억 8,600만 행, 133GB 용량에 해당합니다.
다음은 테이블과 인덱스별 데이터베이스 크기 분포를 보여줍니다:
메트릭을 수집할 때 Amazon RDS for PostgreSQL db.r6g.2xlarge DB 인스턴스를 사용하며, 20,000 IOPS로 프로비저닝된 io1 storage와 단 4개의 worker만 사용합니다. 적은 수의 worker를 사용하는 이유는 데이터베이스 서버의 과부하를 방지하기 위함입니다. 실제 운영 환경에서는 데이터 수집 외에도 쿼리 처리를 위해 데이터베이스가 항상 가용상태여야 합니다. 이 구성으로 데이터 로딩은 5,609초(93.5분)가 소요되었으며, 초당 522,832개의 메트릭을 처리했습니다.
데이터 타입 고려 사항
테이블 구조를 설계할 때는 가능한 값의 범위를 이해하고 가장 크거나 작은 값을 허용하는 데이터 타입을 선택하는 것이 중요합니다. 필요 이상으로 큰 데이터 타입을 선택하여 과도하게 할당하지 않는 것도 중요합니다. 데이터 타입을 과도하게 할당하면 전체 행 크기가 커지고, 이는 전체 테이블을 상당히 크게 만들어 데이터베이스 성능에 영향을 미칩니다.
먼저 tags 테이블의 id 열을 살펴보겠습니다. 이 테이블은 트럭의 메타데이터를 추적하며, 각 행은 실제 트럭과 운전자의 조합을 나타냅니다. 현재 트럭이 100대이므로, id 열의 데이터 유형은 2바이트 공간만 사용하는 smallint로 설정할 수 있습니다. 하지만 데이터 모델의 수명 기간 동안 현재 및 미래의 트럭을 운전할 수 있는 잠재적 운전자의 수를 고려하면, 가능한 조합의 수는 smallint의 최대값인 32,767을 쉽게 초과할 수 있습니다. 다른 정수형 데이터 타입의 최대값을 보면, int는 최대 2,147,483,647이고 bigint는 최대 9.22E+18까지 가능합니다. id열이 나타내는 비즈니스 맥락, 즉 차량 대수 증가 가능성이 제한적이라는 점을 고려할 때, 20억 개의 값을 저장할 수 있는 4바이트 정수형 데이터 타입이 적합합니다. 만약 해당 열이 대형 트럭이 아닌 휴대폰과 같은 소비자 기반 값을 나타낸다면, bigint 데이터 형식이 더 적합합니다.
이제 메트릭의 데이터 타입을 살펴보겠습니다. 이들은 모두 원래 double precision으로 생성되었으며, 8바이트의 물리적 공간에서 소수점 이하 최대 15자리까지 정밀도를 표현할 수 있습니다. 속도나 고도 같은 지표가 정수라는 점을 고려하면, 소수점 이하 15자리 정밀도는 필요 이상입니다. 트럭의 속도는 최대 3자리, 고도는 최대 5자까지의 정수로 표현하면 충분합니다. 정확도가 높아질 미래의 센서를 고려하더라도, 작은 정수에서 소수점 15자리까지 요구하는 수준으로 변화할 가능성은 매우 낮습니다. 수집되는 메트릭을 고려할 때 더 최적의 데이터 타입은 real이며, 이는 4바이트만 사용하면서도 소수점 6자리 정밀도를 제공합니다.
다음 명령문을 사용하면 소수점 이하 15자리 정밀도가 필요하지 않은 메트릭을 저장하는 readings 테이블 열의 데이터 형식을 변경할 수 있습니다:
15자리 소수점이 필요하지 않은 메트릭을 저장하는 readings 테이블의 열 데이터 타입을 변경한 결과, 데이터베이스 크기가 133GB에서 126GB로 약 5.2% 줄어들었습니다. 데이터베이스 크기가 줄어들면서 스토리지에 저장되는 데이터의 양이 감소할 뿐 아니라 더 많은 행을 캐시에 저장할 수 있게 되므로, 성능이 향상됩니다. 새로운 데이터 타입을 사용하여 데이터 수집 프로세스를 실행하면 로드 시간이 5,609초에서 5,487초로 2분 이상 단축되고, 수집 속도는 초당 522,832개에서 초당 534,517개로 증가합니다.
인덱스 고려사항
데이터 수집에서 가장 리소스 집약적인 부분 중 하나는 인덱스를 유지 관리하는 것입니다. 인덱스가 데이터 수집에 필수적인 것은 아니지만, 인덱스가 없으면 데이터 쿼리 속도가 엄청나게 느려집니다. 인덱스 수를 필요한 수로만 제한하면 적재 속도와 쿼리 성능 간의 균형을 잘 맞출 수 있지만, 어떠한 인덱스를 선택할 지는 쿼리에 대한 비즈니스 요구 사항에 따라 달라집니다. 시계열 테이블에도 필요에 따라 여러 인덱스를 추가할 수 있지만, 시계열 데이터 특성상 time 열에는 인덱스가 있습니다. 많은 쿼리가 특정 시간 구간 동안의 기록을 분석하므로 해당 행에 빠르게 액세스해야 합니다.
PostgreSQL에서 사용하는 기본 인덱스는 B-Tree 인덱스입니다. B-Tree 인덱스는 범용 인덱스 유형으로 훌륭한 선택이지만, 유지 관리에 상당한 리소스가 필요하며 테이블의 행 수가 늘어날 수록 인덱스의 크기도 크게 증가할 수 있습니다. PostgreSQL에서 B-Tree 인덱스는 시계열 데이터에 적합한 우측 편향 트리(Right-learning tree)에 대해 일부 성능 최적화를 제공합니다. time 열은 항상 증가하는 값을 가지므로 최신 행은 항상 트리 오른쪽에 배치됩니다.
B-Tree 인덱스의 장점 중 하나는 기본 키(Primary key)로 사용되는 정수나 이메일 주소와 같은 단일 값을 빠르게 반환할 수 있다는 것입니다. 이를 위해서는 인덱스가 테이블의 모든 행에 대한 항목을 유지해야 합니다. 이는 OLTP 유형의 워크로드에는 이상적이지만, 시계열 데이터에 대한 쿼리는 일반적으로 지난 5분의 모든 행을 반환하거나 어제의 값을 집계하는 것과 같이 시간 범위에 걸쳐 있습니다. 일반적인 쿼리는 정확한 시간을 기준으로 행을 조회하지 않습니다. 시계열 데이터의 경우 모든 행의 정확한 시간 값을 추적할 필요는 없지만, 해당 행이 특정 시간 범위 내에 속하는지 추적해야 합니다.
PostgreSQL의 유연성 덕분에 시계열 사용 사례에 매우 적합한 인덱스 유형이 있습니다. Block Range Index(BRIN)는 시계열 워크로드 같은 액세스 패턴을 위해 설계되었습니다. BRIN은 개별 시간 값을 추적하는 대신 테이블 페이지 범위의 최소 및 최대 시간 값을 추적합니다. 시계열 테이블은 물리적 페이지와 시간 값 사이에 자연스러운 상관관계가 있기 때문에(새 행이 테이블 끝에 추가되기 때문) BRIN이 매우 효율적입니다.
다음 명령문은 readings 테이블의 time 열에 BRIN 방식을 사용하여 인덱스를 생성합니다. 또한 pages_per_range 값을 기본값인 128 대신 32로 설정합니다. 이 설정은 최소값과 최대값을 추적하는 범위 크기를 제어합니다. 우리가 사용하는 100대와 같이 적은 수의 장치의 경우, 128페이지는 거의 20분 분량의 데이터를 담을 수 있습니다. 이처럼 넓은 범위는 정기적으로 실행하는 일반적인 쿼리에 대해 충분히 선택적이지 않아 쿼리에서 필요한 데이터를 효과적으로 좁혀주지 못하기 때문에, 범위를 32 페이지로 축소하여 더 세밀한 단위로 최소/최대값을 추적하게 함으로써, 쿼리가 필요한 범위만 더 정확하게 선택할 수 있게 되어 쿼리 성능 향상에 도움이 됩니다.
시간 열에 B-Tree 인덱스 대신 BRIN 인덱스를 사용함으로써 데이터베이스 크기가 126GB에서 101GB (-19.8%)로 감소했습니다. 두 BRIN 인덱스의 크기는 각각 24KB에 불과합니다. 이렇게 크게 줄어든 인덱스의 크기는 메트릭 수집 성능 향상으로 직접 이어집니다. BRIN 인덱스를 사용하여 메트릭을 로드하면 시간이 5,487초에서 4,761초로 12분 더 단축되며, 초당 616,002개의 속도로 메트릭을 수집할 수 있습니다.
BRIN을 사용하여 데이터 수집 속도를 높이는 것도 좋지만, 인덱스의 목적은 쿼리 성능 향상에 있습니다. time 열에서 인덱스를 활용하는 간단한 쿼리를 살펴보겠습니다. 다음 쿼리는 B-Tree 인덱스를 사용하여 하루 동안 readings 테이블에 입력된 행의 수를 카운트합니다. EXPLAIN plan을 보면 PostgreSQL이 인덱스 전용 스캔(Index Only Scan)을 사용하여 222 밀리초 만에 777,456개의 행을 카운트하는 것을 확인할 수 있습니다:
BRIN 인덱스를 사용한 동일 쿼리를 살펴보면, 실행 계획이 조금 다르다는 것을 확인할 수 있습니다. 다음 실행 계획에서는 먼저 readings_time_brin_idx 인덱스를 스캔하여 9,728개의 후보 블록을 반환합니다. PostgreSQL은 페이지의 모든 행이 쿼리 조건과 일치하는지 확인하기 위해 두번째 검사를 수행해야 하며, 이 두번째 단계에서 PostgreSQL은 결과에서 19,762개의 행을 제거했습니다. 두 번째 검사라는 추가 처리 과정이 포함되었음에도 불구하고, 쿼리는 176밀리초 만에 777,456개의 행을 모두 카운트할 수 있었습니다:
이 예시처럼 모든 쿼리가 BRIN 인덱스를 사용할 때 더 나은 성능을 보이는 것은 아니지만, 액세스 패턴이 BRIN의 장점에 맞으면 B-Tree 인덱스와 비슷한 성능을 발휘합니다.
파티셔닝 고려 사항
네이티브 PostgreSQL의 전반적인 메트릭 수집 속도는 인상적입니다. 하지만 부하 기간 동안의 세부 사항을 살펴 보면 전체 수치가 성능 저하 동작을 숨기고 있음을 알 수 있습니다. 다음 그래프는 부하 기간 동안 시간 경과에 따른 메트릭 수집 속도를 보여줍니다. 처음에 부하는 초당 150만 개 이상의 메트릭을 처리하지만, 최종적으로는 초당 40만 개의 메트릭 처리량으로 감소합니다.
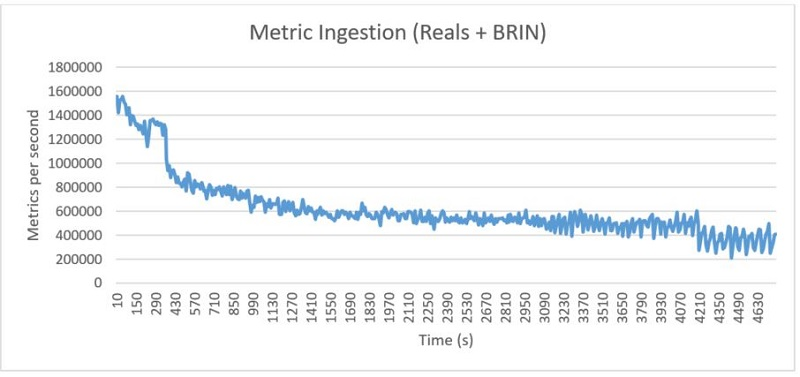
여기서 두 가지 동작 변화를 확인할 수 있습니다. 첫 번째는 약 300초 지점에서 수집 속도가 급격히 감소하는 것입니다. 두 번째는 약 4,200초 지점에서 속도의 변동폭이 더욱 커지는 것입니다. 초기 하락은 수집이 시작된 후 PostgreSQL이 첫 번째 체크포인트를 수행하는 것과 관련이 있습니다. 체크포인트 이후 페이지가 처음 수정될 때, PostgreSQL은 전체 페이지 쓰기(full-page writes)라는 프로세스를 통해 전체 페이지를 기록합니다. 이러한 전체 페이지 쓰기는 데이터 손상을 방지하기 위해 crash recovery 프로세스에서 사용됩니다. 이런 동작으로 인해 B-Tree 인덱스가 커지면 트리에 추가 레벨이 더해지며, 이는 인덱스의 리프 노드에 접근하기 위해 더 많은 페이지에 접근해야 한다는 것을 의미합니다. 추가로 접근하는 페이지는 체크포인트 이후 WAL(Write-Ahead Log)에 완전히 기록되어야 하므로, 스토리지에 저장해야 하는 전체 데이터 양이 증가하여 전반적인 처리량에 영향을 미칩니다. 두 번째 성능 저하는 데이터베이스의 크기가 인스턴스의 가용 메모리를 초과하는 지점에서 발생합니다. 그 시점부터는 메모리 대신 스토리지에서 페이지를 가져와야 하므로 처리량의 변동성이 커집니다.
두 가지 성능 저하 문제를 완화하기 위한 해결책은 활성 데이터세트(Active dataset)와 그에 해당하는 인덱스의 크기를 작게 유지하는 것입니다. 시계열 데이터의 특성상 이러한 방식은 적합하지 않지만, PostgreSQL에서는 데이터 파티셔닝을 통해 이 문제를 해결할 수 있습니다. PostgreSQL 버전 10부터 네이티브 파티셔닝을 지원하며, 이는 시계열 테이블에 특히 유용합니다. 파티셔닝을 사용하면 하나의 큰 테이블을 더 작은 단위로 나눌 수 있어, 애플리케이션 입장에서는 큰 테이블처럼 보이면서도 작은 테이블의 성능 특성을 유지할 수 있습니다. PostgreSQL 버전 10의 초기 파티셔닝 구현에는 일부 성능 문제가 있었지만, 이후 릴리스를 거듭할수록 기능이 개선되어 PostgreSQL 13에서는 수천 개의 파티션까지 안정적으로 확장되고 매우 뛰어난 성능을 보여줍니다.
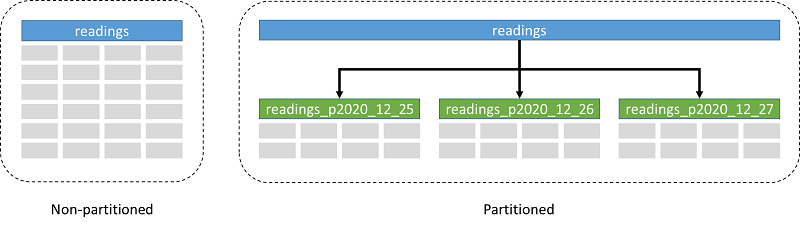
테이블을 파티셔닝할 때, 테이블을 분할하는 데 사용할 열을 자유롭게 결정할 수 있습니다. 시계열 테이블에서는 기본적으로 time 열을 사용합니다. 그 다음에 파티셔닝 방법을 결정할 수 있습니다. PostgreSQL은 해시, 리스트, 범위 파티셔닝을 지원합니다. 앞서 블록 범위 인덱스에 대한 설명에서 언급했듯이, 시계열 테이블은 일반적으로 시간 범위에 걸쳐 데이터를 처리하기 때문에 범위 파티셔닝이 적합합니다. 마지막으로 각 파티션에 포함될 데이터 범위의 크기를 결정해야 합니다. 이상적인 범위 크기는 데이터 수집 속도, 데이터에 접근하는 일반적인 쿼리 등 여러 요인에 따라 달라지지만, 파티션당 하루치 데이터를 기준으로 시작하는 것이 좋습니다.
파티션 테이블을 생성할 때 일반 테이블과 동일한 명령을 사용하지만, 파티션 세부 사항을 정의해야 합니다. 일반 테이블과 마찬가지로 인덱스 또한 정의합니다. 다음 명령은 time 별로 파티셔닝된 readings 테이블을 생성합니다.
테이블이 생성되었으므로 일별 파티션을 만들 수 있습니다. 다음 명령은 readings 테이블에 단일 일별 파티션을 생성합니다:
명령은 간단하지만, 1년 이상 거슬러 올라가는 일별 파티션을 생성하는 것은 매우 번거로운 작업입니다. 파티션 생성을 단순화하기 위해 pg_partman 확장(Extension)을 사용할 수 있습니다. pg_partman은 시계열 테이블의 파티션을 생성하고 관리하는 함수를 제공합니다. 다음 명령은 pg_partman을 사용하여 2020년 1월 1일부터 오늘까지 readings 테이블에 대한 일별 파티션을 생성합니다. 또한 시간이 지남에 따라 사용할 수 있도록, 미래 4일 분의 파티션도 미리 생성합니다. pg_partman에는 새로운 데이터를 위해 항상 파티션을 사용할 수 있도록 지속적으로 미래 파티션을 생성하는 함수도 포함되어 있습니다. pg_cron 확장을 사용하여 이러한 기능이 매일 실행되도록 스케줄링할 수 있습니다.
모든 시계열 테이블에 일별 파티션이 적용된 상태에서 데이터 수집 프로세스를 다시 실행했습니다. 파티션이 적용된 데이터베이스의 최종 크기는 101GB로 동일하지만, 부하 시간은 크게 개선되었습니다. 파티셔닝을 통해 데이터 수집 시간은 4,761초에서 1,774초로 약 50분 단축(-62.7% 시간 단축)되었으며, 초당 1,653,024개의 더 빠른 속도로 메트릭을 수집할 수 있었습니다.
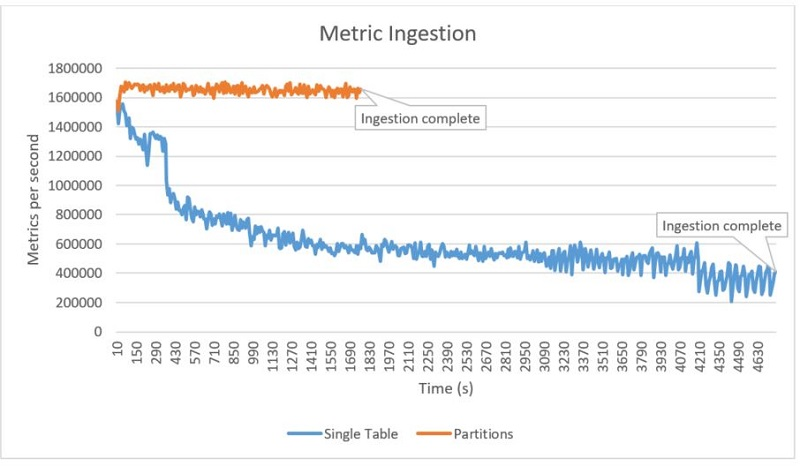
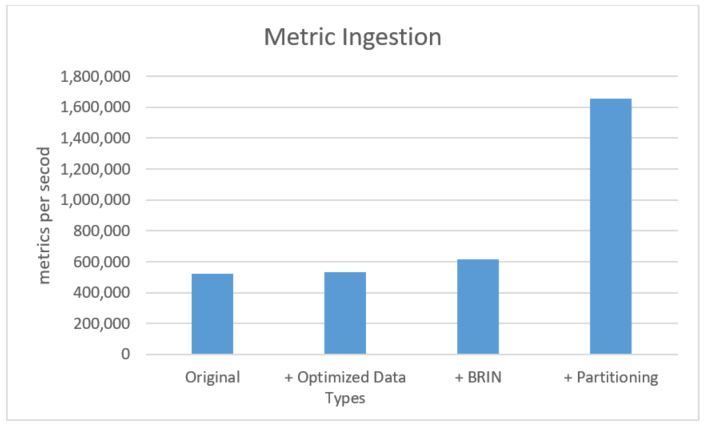 이전 그래프에서 보았듯이, 데이터 수집의 세부 사항은 결과에 큰 영향을 미칠 수 있습니다. 다음 그래프는 파티셔닝된 테이블을 사용한 수집과 대형 단일 테이블을 사용했을 때의 데이터 수집을 비교한 것입니다. 파티션 그래프가 훨씬 더 짧은데, 이는 작업이 훨씬 빠르게 완료되었기 때문입니다. 또한 부하가 지속되는 동안 초당 160만 개의 메트릭 처리량이 안정적으로 유지되는 것을 확인할 수 있습니다.
이전 그래프에서 보았듯이, 데이터 수집의 세부 사항은 결과에 큰 영향을 미칠 수 있습니다. 다음 그래프는 파티셔닝된 테이블을 사용한 수집과 대형 단일 테이블을 사용했을 때의 데이터 수집을 비교한 것입니다. 파티션 그래프가 훨씬 더 짧은데, 이는 작업이 훨씬 빠르게 완료되었기 때문입니다. 또한 부하가 지속되는 동안 초당 160만 개의 메트릭 처리량이 안정적으로 유지되는 것을 확인할 수 있습니다.
요약
이 글에서는 시계열 데이터에 유용한 PostgreSQL 기본 기능을 살펴보았습니다. 적당한 크기의 Amazon RDS for PostgreSQL 또는 Amazon Aurora PostgreSQL 인스턴스는 데이터 모델 설계에 대한 간단한 계획만으로도 초당 100만 개 이상의 메트릭을 쉽게 수집하면서 데이터 쿼리에 사용할 수 있는 리소스를 충분히 확보할 수 있습니다.
PostgreSQL의 기본 파티셔닝의 기능은 대용량 시계열 데이터 처리에 있어 혁신적인 변화를 가져왔습니다. Amazon RDS for PostgreSQL 13부터는 PostgreSQL이 수천 개의 파티션을 지원하므로, 테이블에 일별 또는 시간별 파티션을 생성하여 수년 간의 데이터를 관리할 수 있습니다. pg_partman 및 pg_cron 확장을 사용하면 이러한 파티션 관리를 간편하게 할 수 있습니다.
더 나아가 Amazon Forecast란 무엇인가요?를 참조하면 AWS에서 시계열 데이터에 예측 모델과 인사이트를 쉽게 추가하는 방법을 알아볼 수도 있습니다.