AWS 기술 블로그
대규모 환경에서의 MCP를 활용한 효율적인 EBS 모니터링
개요
Amazon EBS(Elastic Block Store)는 Amazon EC2(Elastic Compute Cloud)의 인스턴스에 영구 블록 스토리지를 제공하는 핵심 서비스입니다. 엔터프라이즈 환경에서 수백, 수천 개의 EBS 볼륨을 운영할 때, 각 볼륨의 성능을 실시간으로 모니터링하고 병목 지점을 신속하게 파악하는 것은 서비스 안정성과 직결되는 중요한 과제입니다.
Amazon CloudWatch는 EBS 볼륨에 대해 다양한 성능 지표를 제공하지만, 이를 종합적으로 분석하여 실질적인 인사이트를 얻기 위해서는 복잡한 계산과 여러 API 호출이 필요합니다. 또한 EBS 스냅샷의 실제 데이터 크기를 파악하려면 EBS Direct API를 별도로 호출해야 하는 번거로움이 있습니다. 이러한 제한으로 인해 대규모 운영 환경에서 블록 스토리지의 성능과 비용을 분석하는 데 상당한 시간이 소요됩니다.
본 글에서는 EBS Performance Monitoring MCP를 활용하여 자연어를 통해 대규모 환경에서의 EBS 성능 분석을 진행하는 방법에 대해 소개합니다. AWS의 AI 기반 IDE인 Kiro와 통합되어, 복잡한 CloudWatch 쿼리나 AWS CLI 명령어 대신 직관적인 자연어 명령만으로 여러 볼륨에 대한 성능 분석을 실시간으로 수행할 수 있습니다.
본 글은 단순히 전체 코드를 공유하기보다는, MCP 기반 인프라 자동화의 설계 철학과 실전 적용 전략에 초점을 맞춥니다. 실제 운영 환경에서 검증된 아키텍처 패턴과 구현 인사이트를 통해, 여러분의 조직에서 AI 기반 인프라 운영 체계를 구축하는 구체적인 로드맵을 제시합니다.
현대적 인프라 운영의 요구사항 – MCP로 EBS 성능 모니터링을 자동화해야 하는 이유
기존 EBS 모니터링 방식의 한계 및 개선 요구 사항
1. CloudWatch 지표 해석의 복잡성
AWS CloudWatch는 EBS 볼륨에 대해 VolumeReadOps, VolumeWriteOps, VolumeReadBytes, VolumeWriteBytes 등 다양한 지표를 제공합니다. 그러나 실질적인 성능 분석을 위해서는 다음과 같은 추가 작업이 필요합니다.
- 다중 지표 조합 계산: IOPS는
VolumeReadOps와VolumeWriteOps의 합을 시간으로 나눠야 하고, 처리량은 바이트를 MiB/s로 변환해야 합니다. - 버스팅 성능 계산: 실제 I/O가 발생한 시간(활성 시간) 기준의 성능을 계산하려면
VolumeIdleTime을 활용한 복잡한 계산이 필요합니다. - 사용률 계산: 프로비저닝된 IOPS/처리량 대비 실제 사용량 비율을 수동으로 계산해야 합니다.
- 지연 시간 계산:
VolumeTotalReadTime과VolumeReadOps를 조합하여 평균 지연 시간을 산출해야 합니다.
2. 스냅샷 크기 파악의 어려움
EBS 스냅샷은 증분(incremental) 방식으로 저장되어 실제 데이터 크기를 파악하기 어렵습니다.
- 볼륨 크기 ≠ 스냅샷 크기: 100GB 볼륨의 스냅샷이 실제로는 10GB만 차지할 수 있습니다.
- EBS Direct API 필요: 실제 정확한 스냅샷 크기를 조회하려면
ListSnapshotBlocks또는ListChangedBlocksAPI를 별도로 호출하여 모든 블록 크기를 직접 구해야 합니다.
3. 대규모 환경에서의 관리 복잡성
수백 개의 볼륨을 운영하는 환경에서는 시계열 데이터를 이용하여 모든 볼륨의 지표에 대한 가시성을 확보하기 어렵습니다.
- 개별 조회의 비효율성: 각 볼륨을 하나씩 조회하고 분석하는 것은 시간 소모적입니다.
- 비교 분석의 어려움: 여러 볼륨의 성능을 한눈에 비교하기 어렵습니다.
- 반복적인 CLI 작업: 동일한 분석을 반복할 때마다 복잡한 명령어 또는 스크립트를 다시 입력해야 합니다.
4. EBS 성능 모니터링이 필요한 주요 시나리오
대규모 운영 환경에서 EBS 성능 모니터링은 다양한 이점이 있습니다.
- 성능 병목 진단: 애플리케이션 지연 발생 시 EBS가 원인인지 신속하게 확인
- 용량 계획: 현재 IOPS/처리량 사용률 기반으로 볼륨 타입 변경 또는 크기 조정 결정
- 비용 최적화: 과도하게 프로비저닝된 볼륨 식별 및 다운사이징 (예: io2 → gp3)
- 스냅샷 관리: 실제 데이터 크기 기반의 스냅샷 보관 정책 수립 및 비용 예측
예를 들어, 트래픽이 급증하는 시간대에 애플리케이션 응답 속도가 느려진다면, 엔지니어는 EBS 볼륨의 IOPS 한계에 도달했는지 신속하게 확인해야 합니다. 또한 월간 인프라 비용 검토 시, 실제 사용률이 10%에 불과한 고성능 io2 볼륨을 발견한다면 gp3로 전환하여 상당한 비용 절감을 달성할 수 있습니다. 스냅샷의 경우, 볼륨 크기가 아닌 실제 데이터 크기를 파악함으로써 정확한 스토리지 비용 예측과 보관 정책 수립이 가능해집니다.
솔루션 개요
- 종합 성능 분석: IOPS, 처리량, 지연 시간, 사용률을 한 번의 요청으로 분석
- 버스팅 성능 측정: 활성 시간 기준의 실제 버스팅 성능 자동 계산
- EC2/EBS 병목 진단: 인스턴스 타입별 EBS 전용 대역폭과 볼륨 프로비저닝 성능을 비교하여 실제 병목 지점 식별
- 스냅샷 실제 크기: EBS Direct API를 활용한 정확한 데이터 크기 산출
- 다중 볼륨 병렬 분석: 여러 볼륨을 동시에 분석하여 비교
- 자연어 인터페이스: 복잡한 CLI 명령어 대신 직관적인 자연어 명령 지원
이러한 기능들은 단순히 데이터를 보여주는 것을 넘어, 실제 운영 의사결정을 지원합니다. 종합 성능 분석을 통해 여러 지표를 한눈에 파악하고, 버스팅 성능 측정으로 순간적인 부하 상황에서의 실제 성능을 이해할 수 있습니다. 특히 EC2/EBS 병목 진단 기능은 인스턴스 타입의 EBS 대역폭 제한과 볼륨 자체의 성능 제한 중 어느 것이 실제 병목인지 명확히 구분해주어, 정확한 최적화 방향을 제시합니다. 다중 볼륨 병렬 분석은 수십 개의 볼륨을 운영하는 환경에서 전체 인프라의 성능 상태를 빠르게 파악할 수 있게 해줍니다.
대규모 운영 환경에서 EBS 성능 모니터링은 복잡한 CloudWatch 지표 조합, EBS Direct API 호출, 수동 계산 등의 한계로 인해 신속한 의사결정이 어렵습니다. 이러한 문제를 해결하기 위해 MCP(Model Context Protocol) 기반의 자동화된 모니터링 솔루션을 구현하여, 자연어 명령만으로 성능 분석, 병목 진단, 비용 최적화 등 다음과 같은 인사이트를 즉시 얻을 수 있도록 접근성을 개선했습니다.
Model Context Protocol(MCP) 아키텍처 및 핵심 구현
MCP란?
Model Context Protocol(MCP)은 AI 모델과 외부 도구/데이터 소스 간의 표준화된 통신 프로토콜입니다. MCP를 통해 AI 에이전트는 다양한 외부 시스템과 상호작용할 수 있으며, 개발자는 AI가 활용할 수 있는 커스텀 도구를 쉽게 구축할 수 있습니다.
MCP 솔루션 아키텍처
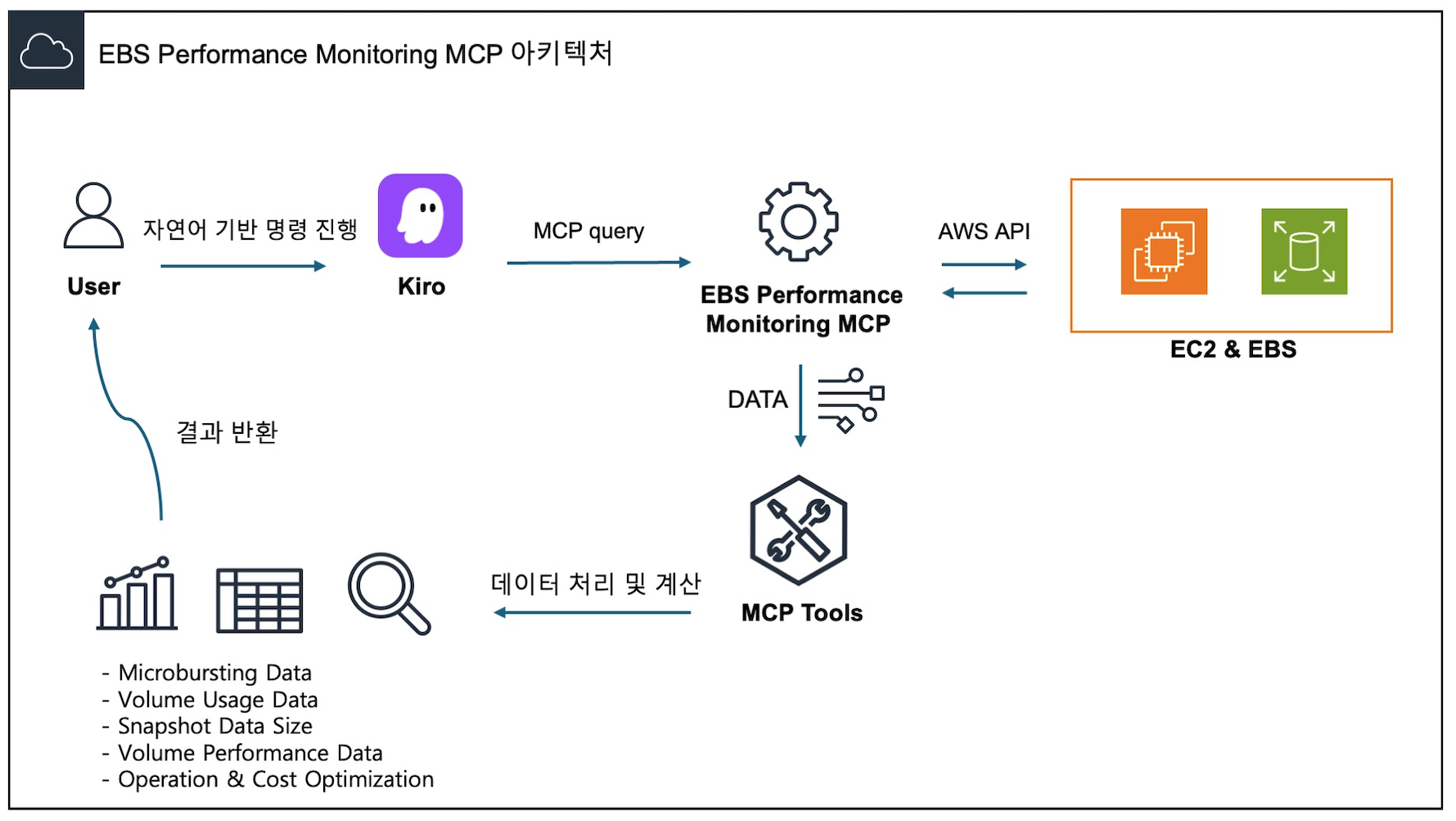
그림1 : EBS Performance Monitoring MCP 아키텍처
MCP 데이터 흐름
MCP 통신 흐름 상세
MCP 통신은 다음과 같은 흐름으로 진행됩니다. 사용자가 Kiro에 자연어로 요청하면, LLM이 의도를 파악하여 적절한 MCP 도구를 선택합니다. 그 후 JSON-RPC 프로토콜로 MCP 서버에 호출을 전달하고, 서버가 AWS API를 통해 데이터를 수집·가공하여 CLI 친화적인 형식으로 결과를 반환합니다.
- 사용자 요청: 사용자가 Kiro에 자연어로 요청 (예: “vol-xxx 볼륨의 지난 24시간 성능을 분석해줘”)
- 의도 파악 및 도구 선택: Kiro의 LLM이 사용자 의도를 파악하고, 등록된 MCP 도구 중 적절한 것을 선택
- MCP 프로토콜 통신: JSON-RPC 형식으로 MCP 서버에 도구 호출 요청
- AWS API 호출: MCP 서버가 필요한 AWS API들을 호출하여 데이터 수집
- 데이터 처리: 수집된 원시 데이터를 가공하여 의미 있는 지표로 변환
- 결과 반환: CLI 친화적인 테이블 형식과 자연어 설명으로 결과 반환
사용자가 “vol-xxx 볼륨의 지난 24시간 성능을 분석해줘”라고 요청하면, Kiro의 LLM은 이 요청에서 볼륨 ID(vol-xxx), 시간 범위(24시간), 분석 유형(성능 분석)을 추출하여 get_volume_performance 도구를 선택합니다. 이후 JSON-RPC 프로토콜을 통해 MCP 서버와 통신하며, 서버는 CloudWatch에서 VolumeReadOps, VolumeWriteOps, VolumeIdleTime 등 필요한 여러 지표를 병렬로 호출하여 데이터를 수집합니다. 수집된 원시 데이터는 IOPS, 처리량, 지연 시간, 사용률 등 의미 있는 지표로 가공되어 CLI 친화적인 테이블 형식과 자연어 설명으로 변환되어 사용자에게 반환됩니다. 이 모든 과정은 수 초 내에 완료되어, 사용자는 복잡한 명령어나 계산 없이 즉시 인사이트를 얻을 수 있습니다.
핵심 구현
전체 소스 코드는 GitHub 샘플 코드 저장소에서 확인하실 수 있습니다.
다음은 구현된 기능간의 흐름을 표현한 다이어그램입니다.
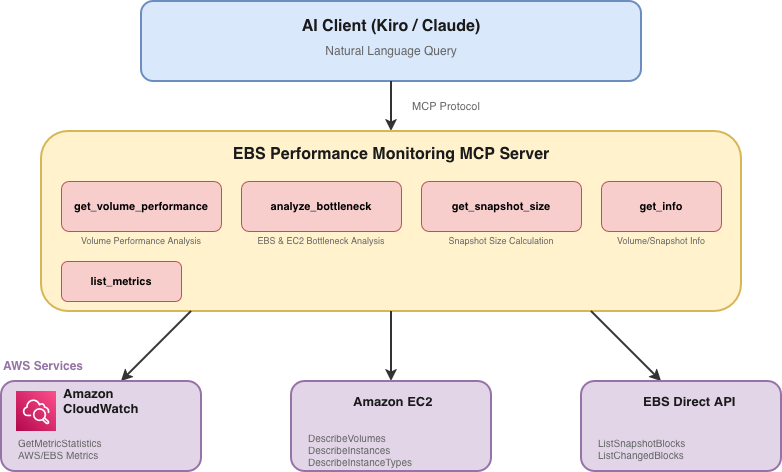
그림2 : EBS Performance Monitoring MCP 데이터 흐름
1. FastMCP 기반 서버 설정
FastMCP는 MCP 서버 개발을 위한 고수준 프레임워크로, 기존 MCP SDK의 복잡한 설정 과정을 대폭 간소화합니다. 가장 큰 장점은 데코레이터 기반의 도구 등록입니다. @mcp.tool() 데코레이터만 함수 위에 붙이면 해당 함수가 자동으로 MCP 도구로 등록됩니다. 기존 SDK에서는 도구 목록 반환 함수, 도구 호출 핸들러, JSON Schema 정의를 모두 수동으로 작성해야 했지만, FastMCP에서는 이 모든 과정이 자동화됩니다.
[코드 예제1 : Fast MCP 예제]
from mcp.server.fastmcp import FastMCP
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# FastMCP 서버 인스턴스 생성
mcp = FastMCP("ebs-performance-monitoring")
@mcp.tool()
async def get_volume_performance(
volume_ids: list[str],
hours: int = 24,
region: Optional[str] = None
) -> str:
"""EBS 볼륨의 성능을 분석합니다. 단일 또는 다중 볼륨을 지원합니다."""2. 버스팅 성능 계산 알고리즘
EBS 볼륨의 실제 버스팅 성능을 측정하기 위해 VolumeIdleTime을 활용합니다. 전체 분석 기간이 아닌 실제 I/O가 발생한 활성 시간 기준으로 IOPS와 처리량을 계산하여 워크로드의 실제 특성을 파악합니다.
[코드 예제2: 버스팅 성능 계산 알고리즘 예시]
class PerformanceAnalyzer:
def _calculate_summary(self, config, metrics, hours, period):
total_seconds = hours * 3600
# CloudWatch 지표에서 값 추출
read_ops = metrics.get("VolumeReadOps", {}).get("sum", 0)
write_ops = metrics.get("VolumeWriteOps", {}).get("sum", 0)
read_bytes = metrics.get("VolumeReadBytes", {}).get("sum", 0)
write_bytes = metrics.get("VolumeWriteBytes", {}).get("sum", 0)
idle_time = metrics.get("VolumeIdleTime", {}).get("sum", 0)
# 평균 성능 계산 (전체 시간 기준)
avg_read_iops = read_ops / total_seconds
avg_write_iops = write_ops / total_seconds
avg_total_iops = avg_read_iops + avg_write_iops
# 버스팅 성능 계산 (활성 시간 기준)
# 활성 시간 = 전체 시간 - 유휴 시간
active_time = total_seconds - idle_time
if active_time > 0:
# I/O가 실제로 발생한 시간 동안의 성능
bursting_read_iops = read_ops / active_time
bursting_write_iops = write_ops / active_time
bursting_total_iops = bursting_read_iops + bursting_write_iops
bursting_read_throughput = (read_bytes / active_time) / BYTES_PER_MIB
bursting_write_throughput = (write_bytes / active_time) / BYTES_PER_MIB
bursting_total_throughput = bursting_read_throughput + bursting_write_throughput
else:
# I/O가 전혀 없었던 경우
bursting_read_iops = bursting_write_iops = 0
bursting_total_iops = 0
bursting_read_throughput = bursting_write_throughput = 0
bursting_total_throughput = 0버스팅 성능 지표는 평균 성능만으로는 파악할 수 없는 중요한 인사이트를 제공합니다. 워크로드가 간헐적으로 발생하는 환경에서는 평균 IOPS가 낮게 나타나지만, 실제 부하가 발생하는 순간에는 훨씬 높은 성능이 필요합니다. 예를 들어, 배치 작업이나 백업 작업 중에는 짧은 시간 동안 집중적인 I/O가 발생하는데, 이때의 실제 성능이 프로비저닝된 한계에 근접한다면 작업 지연이나 타임아웃이 발생할 수 있습니다. 평균 성능만 보고 볼륨이 충분하다고 판단했다가, 실제 운영 중 피크 시간대에 성능 문제를 겪는 경우가 많습니다. 버스팅 성능 분석을 통해 이러한 숨겨진 병목을 사전에 발견하고 대응할 수 있습니다.
3. 인스턴스 연결 정보 및 EBS 대역폭 조회
인스턴스 타입별 EBS 전용 대역폭을 확인하여 EBS와 EC2 인스턴스 간의 병목 현상이 존재하는지 확인합니다.
[코드 예제3: 인스턴스에 연결된 볼륨 정보 및 전용 대역폭 조회 예시]
async def get_instance_ebs_bandwidth(instance_type: str, region: Optional[str] = None) -> Optional[EC2EbsBandwidth]:
client = boto3.client("ec2", region_name=region) if region else boto3.client("ec2")
loop = asyncio.get_event_loop()
...
...
return EC2EbsBandwidth(
instance_type=instance_type,
ebs_optimized=ebs_info.get("EbsOptimizedSupport") in ("default", "supported"),
baseline_iops=ebs_bandwidth.get("BaselineIops", 0),
maximum_iops=ebs_bandwidth.get("MaximumIops", 0),
baseline_throughput_mib_s=ebs_bandwidth.get("BaselineThroughputInMBps", 0),
maximum_throughput_mib_s=ebs_bandwidth.get("MaximumThroughputInMBps", 0),
baseline_bandwidth_mbps=ebs_bandwidth.get("BaselineBandwidthInMbps", 0),
maximum_bandwidth_mbps=ebs_bandwidth.get("MaximumBandwidthInMbps", 0),
...
...4. 스냅샷 실제 크기 계산
EBS Direct API를 사용하여 스냅샷에 저장된 실제 데이터 블록 수를 조회합니다. 이를 통해 볼륨 크기가 아닌 실제 사용된 데이터 크기를 정확히 파악할 수 있습니다.
[코드 예제4: 실제 스냅샷 크기 계산 예시]
@mcp.tool()
async def get_snapshot_size(
snapshot_id: str,
previous_snapshot_id: Optional[str] = None,
region: Optional[str] = None
) -> str:
"""스냅샷의 실제 블록 데이터 크기를 계산합니다."""
ebs_client = boto3.client("ebs", region_name=region)
ec2_client = boto3.client("ec2", region_name=region)
# 스냅샷 메타데이터 조회
snap_response = ec2_client.describe_snapshots(SnapshotIds=[snapshot_id])
snapshot_meta = snap_response["Snapshots"][0]
block_size = 512 * 1024 # 512 KiB (EBS 블록 크기)
total_blocks = 0
next_token = None스냅샷의 실제 크기를 정확히 파악하는 것은 스토리지 비용 관리의 핵심입니다. 많은 조직에서 볼륨 크기를 기준으로 스냅샷 비용을 추정하지만, 실제로는 사용된 데이터만 저장되므로 큰 차이가 발생합니다.
- 비용 예측: 실제 저장된 데이터 크기를 기반으로 스냅샷 저장 비용 산출
- 증분 크기 분석: 이전 스냅샷 대비 변경된 데이터량 파악
- 보관 정책 수립: 실제 데이터 크기를 기반으로 한 스냅샷 라이프사이클 관리
예를 들어, 500GiB 볼륨이라도 실제 데이터가 100GiB뿐이라면 스냅샷 저장 비용은 1/5 수준입니다. 또한 증분 스냅샷의 크기를 추적하면 일일 데이터 변경률을 파악하여 백업 주기를 최적화하고, 불필요한 스냅샷을 식별하여 정리할 수 있습니다. 실제 운영 환경에서는 수백 개의 스냅샷이 누적되는데, 각각의 실제 크기를 파악함으로써 월간 수백 달러의 비용 절감이 가능합니다.
설치 및 설정
필수 AWS IAM(Identity and Access Management) 권한
MCP를 이용하기 위해 사용하는 사용자 프로필이 다음과 같은 권한을 가지고 있는지 확인합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"ec2:DescribeSnapshots",
"ec2:DescribeVolumes",
"ebs:ListSnapshotBlocks",
"ebs:ListChangedBlocks"
],
"Resource": "*"
}
]
}Kiro MCP 설정
MCP 서버를 연결하기 위해서는 ~/.kiro/settings/mcp.json 파일을 설정합니다.
{
"mcpServers": {
"ebs-performance-monitoring": {
"command": "uvx",
"args": [
"run",
"--directory",
"/path/to/ebs-performance-monitoring-mcp",
"ebs-performance-monitoring"
],
"env": {
"AWS_PROFILE": "default",
"AWS_REGION": "ap-northeast-2",
"FASTMCP_LOG_LEVEL": "ERROR"
}
}
}
}일반적인 활용 예시
1. 단일 볼륨 성능 분석
단일 볼륨 성능 분석은 CloudWatch의 여러 지표를 개별적으로 확인하는 번거로움 없이, 한 번의 호출로 프로비저닝된 IOPS/처리량 대비 실제 사용률, 읽기/쓰기 지연 시간, 버스팅 성능, I/O 활용도를 종합적으로 파악할 수 있어 과잉 프로비저닝으로 인한 비용 낭비를 식별하거나, 사용률이 임계치에 근접할 때 성능 병목을 조기에 발견하여 볼륨 타입 변경이나 IOPS 조정 같은 최적화 의사결정을 신속하게 내릴 수 있습니다.
-출력 결과-
단일 볼륨 성능 분석 결과 1
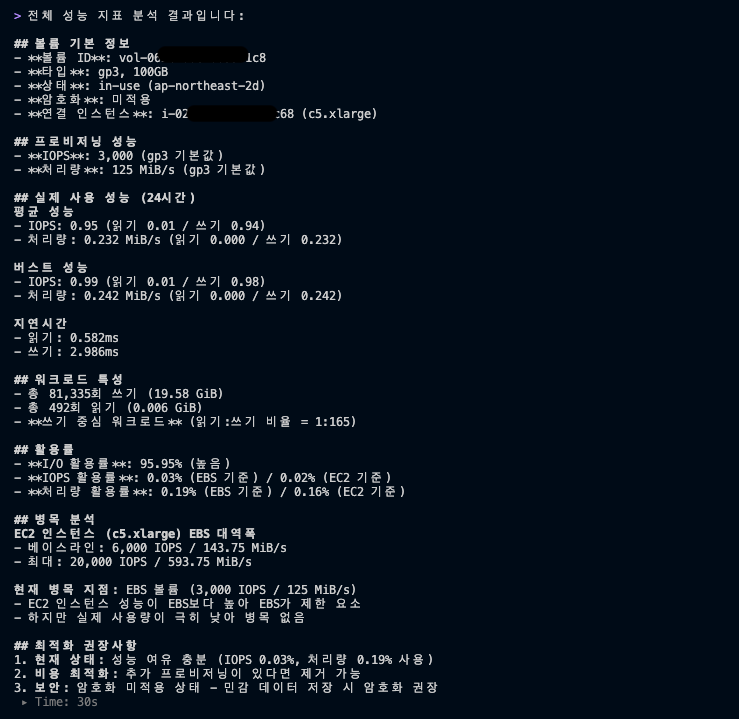
단일 볼륨 성능 분석 결과 2
2. 다중 볼륨 비교 분석
다중 볼륨 비교 분석은 여러 EBS 볼륨을 병렬로 분석하여 전체 IOPS/처리량 합계, 평균 사용률을 집계하고, 가장 사용률이 높은 볼륨과 낮은 볼륨을 자동으로 식별해주므로, 수십 개의 볼륨을 운영하는 환경에서 개별적으로 확인하는 시간을 절약하면서 성능 핫스팟이나 유휴 리소스를 한눈에 파악하여 리소스 재배치, 통합, 또는 다운사이징 같은 인프라 최적화 결정을 효율적으로 내릴 수 있습니다.
-출력 결과-
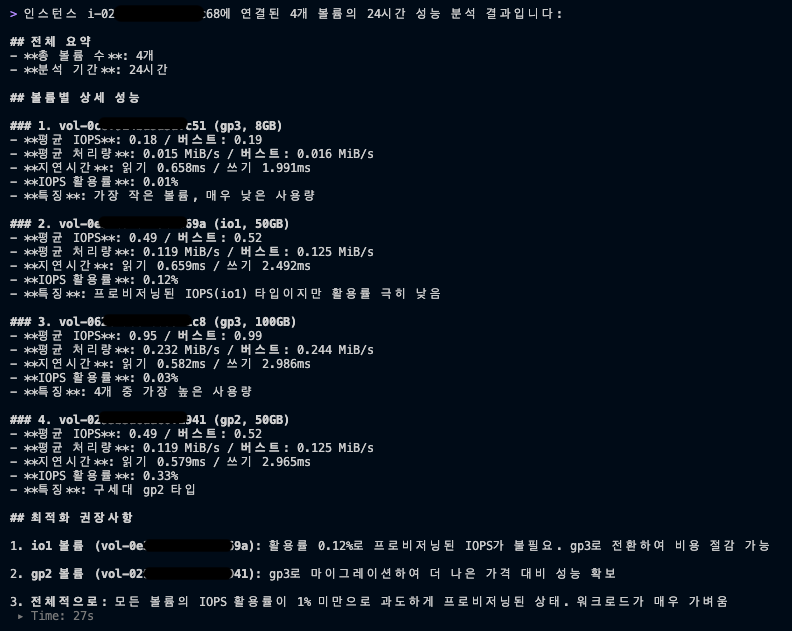
다중 볼륨 비교 분석 결과
3. 스냅샷 실제 크기 계산
EBS Direct API를 통해 스냅샷에 실제로 저장된 데이터 블록 수를 조회하여, 볼륨 크기가 아닌 실제 사용된 데이터 크기(GiB)를 정확히 계산하므로, 100GiB 볼륨이라도 실제 데이터가 20GiB뿐이라면 스냅샷 저장 비용이 20GiB 기준임을 파악하여 정확한 스토리지 비용 예측과 용량 계획이 가능합니다.
-출력 결과-
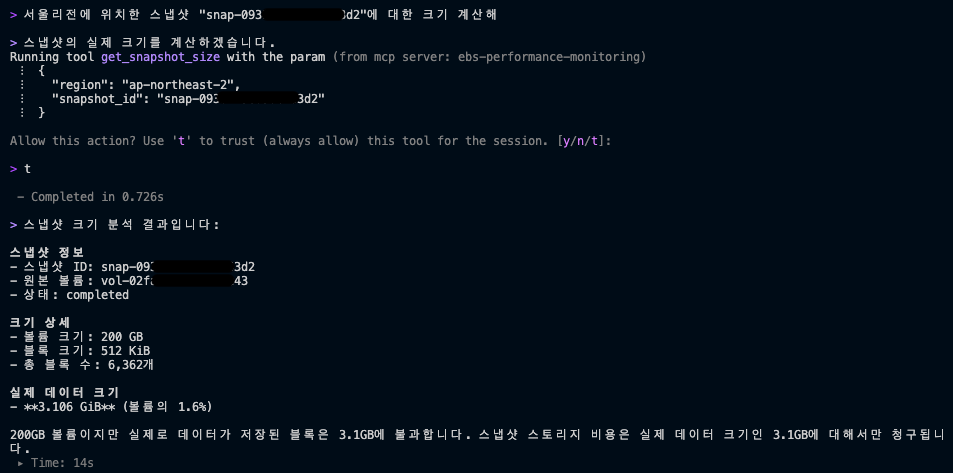
스냅샷 실제 크기 계산 결과
4. 증분 스냅샷 크기 비교
이전 스냅샷과 현재 스냅샷 간 변경된 블록만 조회(ListChangedBlocks)하여 증분 데이터 크기를 계산하므로, 일일 백업 시 실제로 얼마나 데이터가 변경되는지 파악하여 백업 주기 최적화, 스냅샷 보존 정책 수립, 그리고 데이터 변경률 기반의 정확한 월간 스냅샷 저장 비용을 산정할 수 있습니다.
-출력 결과-
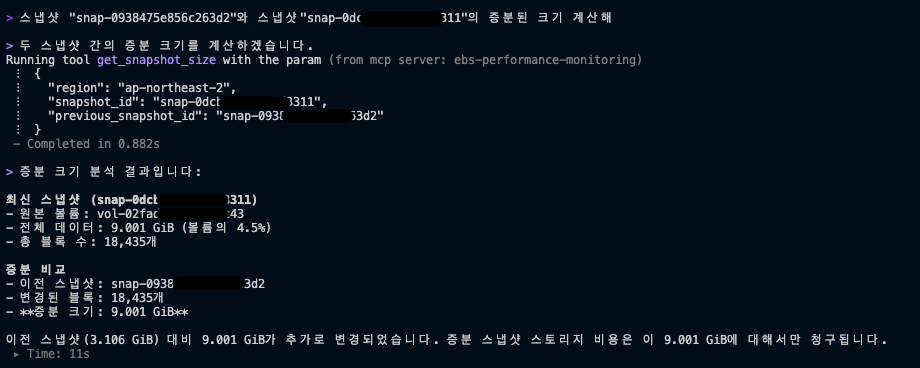
증분 스냅샷 크기 비교 결과
Large-Scale EBS 환경에서의 활용 예시
시나리오
운영 중인 AWS 계정에서 데이터베이스, 애플리케이션 서버, 배치 처리 등 다양한 워크로드에 100개 이상의 EBS 볼륨을 사용하고 있습니다. 운영팀은 다음 작업을 수행해야 합니다:
- 예제 1 : 대규모 볼륨의 전체 성능 현황 파악
- 예제 2 : EC2-EBS 간 병목 지점 식별
- 예제 3 : EC2-EBS 간 최적화가 필요한 부분 안내
예제 1 : 대규모 볼륨의 전체 성능 현황 파악
운영 중인 100개 이상의 EBS 볼륨에 대해 get_volume_performance 도구를 사용하여 지난 24시간의 성능 데이터를 일괄 수집합니다. 볼륨별 평균 IOPS, Throughput, Latency, 사용률 등을 한눈에 확인할 수 있으며, IOPS 사용률이 높은 순서로 정렬하여 주의가 필요한 볼륨을 빠르게 식별합니다.

대규모 볼륨 전체 성능 현황 1
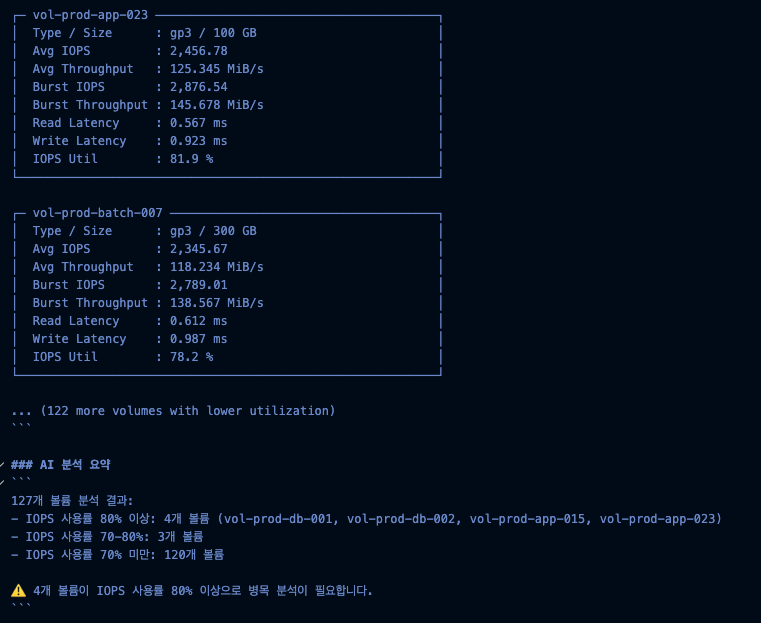
대규모 볼륨 전체 성능 현황 2
예제 2 : EC2-EBS 간 병목 지점 식별
[예제 1]에서 IOPS 사용률 80% 이상으로 식별된 볼륨에 대해 analyze_bottleneck 도구를 사용하여 EC2-EBS 간 병목 분석을 수행합니다. EBS 볼륨의 Provisioned IOPS/Throughput과 연결된 EC2 인스턴스의 EBS Baseline 대역폭을 비교하여, 실제 병목이 EBS 볼륨 측인지 EC2 인스턴스 측인지 정확히 진단합니다.

EC2-EBS 병목 분석 결과 1

EC2-EBS 병목 분석 결과 2
예제 3 : EC2 & EBS 최적화 안내
[예제 2]의 병목 분석 결과를 바탕으로 성능 최적화가 필요한 볼륨과 개선 방향을 간단히 확인할 수 있습니다. EBS 병목인 경우 IOPS/Throughput 증설을, EC2 병목인 경우 인스턴스 타입 업그레이드를 권장하며, 각 볼륨별 현재 사용률과 권장 스펙을 한눈에 비교할 수 있습니다.

EC2 & EBS 최적화 안내
이렇듯, EBS Performance Monitoring MCP를 사용하여 100개 이상의 대규모 EBS 볼륨에 대해 단일 명령으로 일괄 분석하여 IOPS 사용률이 높은 볼륨을 즉시 식별하고, 복잡한 AWS CLI나 CloudWatch 쿼리 없이 “볼륨 성능 분석해줘”, “병목 분석해줘”와 같은 자연어 질의만으로 EBS와 EC2 간의 실제 병목 지점을 정확히 진단할 수 있습니다. 최종적으로, 병목이 발생하는 지점에 대해 EBS 또는 EC2 측면에서의 최적화 인사이트에 도달할 수 있습니다.
고급 활용 시나리오
시나리오 1: 성능 병목 진단
- 상황: 애플리케이션에서 간헐적인 지연이 발생하여 EBS가 원인인지 확인이 필요합니다.
- 자연어 명령: “이 볼륨의 지연 시간이 높은지 확인하고, IOPS 사용률이 100%에 가까우면 알려주세요”
- 분석 접근법:
- 1.
get_volume_performance로 지연 시간과 IOPS 사용률 확인 - 2. 버스트 IOPS가 프로비저닝 한계에 근접하면 순간적 병목 발생 가능
- 3. 지연 시간이 10ms 이상이면 I/O 대기로 인한 성능 저하 의심
- 1.
시나리오 2: 비용 최적화 분석
- 상황: 월간 EBS 비용이 증가하여 과도하게 프로비저닝된 볼륨을 식별해야 합니다.
- 자연어 명령: “IOPS 사용률이 10% 미만인 볼륨을 찾아서 gp3 기본 설정으로 다운그레이드 가능한지 분석해주세요”
- 분석 접근법:
- 1. 다중 볼륨 분석으로 전체 볼륨의 IOPS 사용률 비교
- 2. io2 볼륨 중 사용률이 낮은 경우 gp3로 전환 검토
- 3. gp3 볼륨 중 추가 IOPS가 프로비저닝된 경우 기본 설정으로 변경 검토
시나리오 3: 스냅샷 정리 및 비용 관리
- 상황: 스냅샷 저장 비용이 증가하여 실제 데이터 크기 기반으로 보관 정책을 수립해야 합니다.
- 자연어 명령: “이 볼륨의 모든 스냅샷의 실제 크기를 계산하고, 가장 큰 것부터 정렬해주세요”
- 분석 접근법:
- 1.
get_info로 볼륨의 스냅샷 목록 조회 - 2. 각 스냅샷에 대해
get_snapshot_size로 실제 크기 계산 - 3. 크기 기반으로 정렬하여 비용 영향이 큰 스냅샷 식별
- 1.
시나리오 4: 용량 계획
- 상황: 워크로드 증가에 대비하여 볼륨 업그레이드가 필요한지 판단해야 합니다.
- 자연어 명령: “지난 7일간 IOPS 사용률 추이를 보고 볼륨 업그레이드가 필요한지 판단해주세요”
- 분석 접근법:
- 1.
get_volume_performance에hours=168(7일/14일/21일 등)로 장기 추이 분석 - 2. 버스트 IOPS가 프로비저닝 한계의 80% 이상이면 업그레이드 권장
- 3. 지연 시간 증가 추세가 있다면 선제적 용량 확보 필요
- 1.
마무리
본 글에서는 MCP(Model Context Protocol)를 활용하여 EBS 성능 모니터링을 자동화하는 방법을 소개했습니다.
이 글을 통해 얻을 수 있는 핵심 가치는 아래와 같습니다.
- 복잡성 해소: CloudWatch 지표 조합, 버스팅 성능 계산, 스냅샷 크기 산출 등 복잡한 작업을 자동화
- 자연어 인터페이스: AWS CLI나 콘솔 대신 직관적인 자연어 명령으로 분석 수행
- 실질적 인사이트: 단순 지표 조회가 아닌 사용률, 버스팅 성능 등 의사결정에 필요한 정보 제공
- 재사용 가능한 패턴: 표준화된 MCP 프로토콜 기반으로 다른 AWS 서비스 모니터링에도 동일한 방식으로 적용 가능
이러한 가치들은 단순히 기술적 편의성을 넘어, 인프라 운영 패러다임의 변화를 의미합니다. 과거에는 엔지니어가 복잡한 CLI 명령어를 외우고, 여러 콘솔 화면을 오가며 데이터를 수집하고 수동으로 계산해야 했습니다. 하지만 MCP와 AI 에이전트의 결합으로, 이제는 자연어로 의도를 전달하면 AI가 모든 복잡한 작업을 처리하고 의사결정에 필요한 인사이트를 제공합니다. 이는 엔지니어가 반복적인 작업에서 벗어나 더 전략적이고 창의적인 업무에 집중할 수 있게 합니다.
또한 이 프로젝트에서 사용한 MCP 패턴을 사용하여 다른 AWS 서비스 모니터링에도 적용할 수 있습니다:
- Amazon RDS(Relational Database Service) 성능 모니터링 (CloudWatch Database Insights 통합)
- AWS Lambda 함수 분석 (콜드 스타트 및 실행 시간 분석)
- Amazon S3(Simple Storage Service) 비용 분석 (스토리지 클래스별 사용량)
AI 에이전트와 클라우드 인프라의 통합은 DevOps 업무의 효율성을 크게 향상시킬 수 있으며, MCP는 이러한 통합을 표준화된 방식으로 구현할 수 있는 강력한 프로토콜입니다. 반복적인 모니터링 작업에 시간을 소비하기보다, AI가 데이터를 수집하고 분석하는 동안 엔지니어는 더 가치 있는 아키텍처 설계와 최적화 의사결정에 집중할 수 있습니다. MCP 서버를 직접 구축해보면서 여러분의 운영 환경에 맞는 자동화 도구를 만들어보시기 바랍니다.