AWS 기술 블로그
Embodied AI 블로그 시리즈, 파트 1: AWS Batch에서 로봇 학습 시작하기
https://aws.amazon.com/ko/blogs/spatial/embodied-ai-blog-series-part-1/ 의 번역 글입니다.
우리는 고급 AI 모델을 통해 디지털 세계뿐만 아니라 물리적 세계까지 영향을 미칠 수 있는, 기술 진화의 중요한 이정표에 도달했습니다. 이제 텍스트를 생성하는 AI에서 원자를 움직이는 AI로 발전하고 있습니다 — 옷을 개고, 물류를 정리하고, 복잡한 물리적 작업을 스스로 판단하여 수행하는 등 일상생활 전반을 보조합니다. 하지만 구조화되지 않은 역동적인 물리적 세계와 성공적으로 상호작용하는 기술을 구현하려면 단순한 코드만으로는 부족합니다. 반복 가능성, 대규모 확장성, 그리고 엄격한 연구가 뒷받침되어야 합니다.
그 해결책은 로봇 학습에 있습니다. 기존의 모델 기반 제어에서 벗어나, 자율 시스템에서 전례 없는 역량을 실현하는 데이터 기반 패러다임으로의 전환입니다. 이는 물리적 및 시뮬레이션 하드웨어 통합, 원격 조작 및 제어, 데이터셋 수집과 증강, 정책 학습 및 평가, 추론 최적화에 이르는 다층적 라이프사이클을 포함합니다.

[TWIST2의 원격조작 인터페이스를 통해 인간 운영자와 로봇이 동기화된 목 움직임을 수행하며, 하드웨어 통합, 제어 및 데이터 수집 과정을 시연]
지난 2년간 로봇 학습 커뮤니티는 중요한 변곡점에 도달했습니다. Diffusion Policy, ACT(Action Chunking Transformers) 등의 모방 학습 프레임워크는 시연 데이터로부터 조작 작업을 효과적으로 학습할 수 있음을 입증했으며, π0(Pi Zero), NVIDIA Isaac GR00T, Molmo-Act 같은 범용 VLA(Vision-Language-Action) 모델은 시각적 인식과 자연어 이해를 결합하여 다양한 작업과 로봇 형태에 걸쳐 일반화 능력을 보여주고 있습니다. 이러한 방법론적 도약과 함께, NVIDIA Cosmos Predict 같은 월드 모델링 접근 방식은 로봇이 행동하기 전에 미래 상태를 시뮬레이션하고 예측할 수 있게 해주며, HIL-SERL 같은 강화 학습 방법은 인간 피드백과 강화 학습을 결합해 샘플 효율적인 학습을 달성하거나 현재 상태에 기반한 작업 보상을 모델링합니다. 특히 주목할 점은, Hugging Face의 LeRobot 같은 오픈소스 프로젝트가 이 기술 스택을 민주화하고 있다는 것입니다. 표준화된 데이터셋, 학습 파이프라인, 평가 벤치마크를 제공함으로써 누구나 이러한 발전에 기여할 수 있는 토대를 마련하고 있습니다.
NVIDIA Isaac GR00T은 로봇 학습을 위한 범용 기반 모델로서 독보적인 위치를 차지하고 있습니다. 오픈소스로 공개되어 있어 개발자가 자체 데이터로 사전 학습하거나 미세 조정할 수 있습니다. 특히 GR00T N1.5 3B는 실제 시연 데이터, Isaac Lab의 합성 데이터, 인터넷 규모의 비디오로 구성된 방대한 “데이터 피라미드”를 기반으로 학습되었으며, 다양한 작업과 로봇 형태에 걸쳐 뛰어난 일반화 성능을 보여줍니다. GR00T N1.5를 미세 조정하면 이러한 사전 학습 지식을 활용해 훨씬 적은 시연 데이터만으로도 높은 성능을 달성할 수 있으며, 학습 시간을 수개월에서 수시간으로 대폭 단축할 수 있습니다. 동시에 엣지와 클라우드 환경 모두에 유연하게 배포할 수 있다는 장점도 갖추고 있습니다. 사전 학습된 GR00T 기반 모델의 상업적 사용에 대해서는 NVIDIA의 최신 라이선스 요구 사항을 확인하시기 바랍니다.

[60개 미만의 시연으로 미세 조정된 GR00T N1.5 모델이 시뮬레이션된 SO-ARM101로 leisaac 주방 장면에서 비전 기반 조작을 보여주며, 오렌지를 성공적으로 잡아 그릇에 놓는 부드러운 움직임과 내결함성을 시연]
이 블로그 시리즈의 파트 1에서는 AWS에서 Isaac GR00T N1.5 3B를 쉽게 미세 조정할 수 있는 확장 가능한 인프라를 구축하는 방법을 시연합니다. 클라우드의 탄력성과 NVIDIA의 고급 로봇 학습 스택을 결합하여 개발 주기를 가속화할 수 있습니다 — 정책을 빠르게 반복하고, 대규모 데이터셋을 관리하고, 고충실도 시뮬레이션에서 성능을 검증합니다.
솔루션 개요
다음 아키텍처 다이어그램은 배포할 내용을 보여줍니다 — 보안 Amazon VPC 내의 확장 가능한 엔드투엔드 VLA 미세 조정 파이프라인입니다. 워크플로우는 Amazon S3, HuggingFace 또는 로컬 스토리지에 저장된 원시 데이터셋과 기본 모델로 시작합니다. 일관성을 보장하기 위해 AWS CodeBuild가 학습 환경을 컴파일하고, NVIDIA Isaac GR00T 종속성을 Docker 이미지로 캡슐화하여 Amazon ECR에 저장합니다.
미세 조정 작업이 제출되면 AWS Batch가 GPU가 있는 비용 효율적인 Amazon EC2 인스턴스를 동적으로 프로비저닝하고, 컨테이너를 가져와 학습 워크로드를 실행합니다. 이러한 인스턴스는 공유 Amazon Elastic File System (Amazon EFS) 볼륨을 마운트하여 모델 체크포인트와 로그를 실시간으로 유지합니다.
학습과 병행하여 Amazon DCV 지원 EC2 인스턴스가 시뮬레이션 및 평가를 위해 NVIDIA Isaac Lab을 실행합니다. 동일한 EFS 볼륨을 마운트함으로써 이 인스턴스는 학습 메트릭(TensorBoard를 통해)의 즉각적인 시각화와 최신 체크포인트를 사용한 정책 평가를 가능하게 하여 원활한 피드백 루프를 생성합니다.
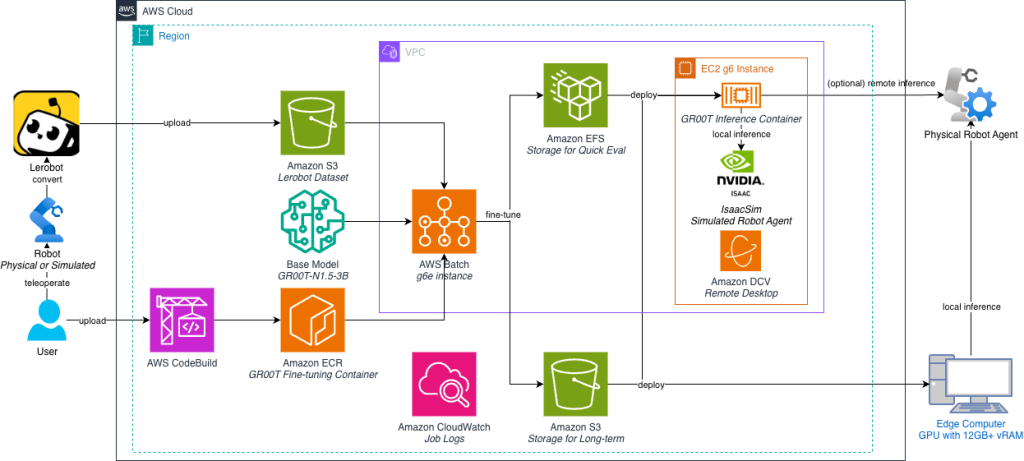
이 미세 조정 파이프라인을 배포한 다음 시뮬레이션에서 미세 조정된 정책을 학습하고 평가하는 단계를 살펴보겠습니다.
사전 요구 사항
이 게시물에서는 AWS CDK (AWS Cloud Development Kit, 익숙한 프로그래밍 언어를 사용하여 클라우드 인프라를 정의하는 프레임워크)를 사용하여 AWS Batch 리소스를 배포합니다.
- AWS CDK 설치
- 리포지토리 클론
git clone https://github.com/aws-samples/sample-embodied-ai-platform.git
cd sample-embodied-ai-platform- CDK 앱용 Python 종속성 설치:
cd training/gr00t/infra
pip install -r requirements.txt- CDK 부트스트랩 (이 계정/리전에서 이미 수행한 경우 건너뛸 수 있음)
참고:YOUR_AWS_PROFILE과YOUR_AWS_REGION을 자격 증명 프로필과 대상 리전으로 교체하십시오.
cdk bootstrap --profile YOUR_AWS_PROFILE --region YOUR_AWS_REGION1. 모방 학습을 위한 Lerobot 데이터셋 검토
시뮬레이션 환경에서 SO-ARM101을 원격 조작하여 오렌지를 집어 접시 위에 올려놓는 작업을 수행하며 수집한 데이터셋이 레포지토리에 제공되어 있습니다. Git LFS를 사용하여 해당 시뮬레이션 데이터셋을 다운로드하고 확인할 수 있습니다.
Git LFS를 설치하려면 이 웹사이트의 지침을 확인하십시오.
git lfs pull샘플 데이터셋은 training/sample_dataset 디렉토리에서 사용할 수 있습니다.
또는 다른 Lerobot 호환 데이터셋이 있는 경우 Lerobot 데이터셋 시각화 도구로 검토할 수 있습니다. 사용자 정의 구현체의 경우 데이터셋의 meta 폴더에 modality.json 파일이 있는지 확인하십시오. modality.json 요구 사항에 대한 자세한 내용은 Isaac GR00T 미세 조정 문서를 참조하십시오.
제공된 학습 스크립트에서 데이터셋에 modality.json 파일이 없는 경우 듀얼 카메라가 있는 SO-ARM 설정이 자동으로 적용됩니다.
2. 미세 조정 파이프라인 설정
기본적으로 다음 단계는 미세 조정을 위해 us-west-2 리전 사용을 가정하지만 G6e, P4d 또는 P5 인스턴스 패밀리가 있는 모든 리전이 지원됩니다.
이 섹션에서는 EC2기반의 AWS Batch를 사용하여 GR00T를 미세 조정하는 재사용 가능한 파이프라인을 생성하므로, 새로운 데이터셋이나 모델에 대한 향후 미세 조정 실행은 다른 환경 변수로 새 작업을 제출하는 것만큼 간단합니다.
일회성 학습 작업은 Jupyter 노트북에서 쉽게 시작할 수 있지만(예: Amazon SageMaker CodeEditor/JupyterLab을 사용하고 Hugging Face Lerobot × NVIDIA 가이드를 따름), 머신 러닝 엔지니어링 팀은 데이터셋이나 모델 업데이트가 빈번하기 때문에 신뢰할 수 있고 반복 가능하며 비용 효율적인 파이프라인을 요구하는 경우가 많습니다. 물리적 AI 모델 학습에는 일반적으로 멀티 컨테이너 설정이 있는 시뮬레이션도 포함됩니다. AWS Batch는 이를 수행하는 안전하고 확장 가능하며 구조화된 방법을 제공합니다.
g6e.2xlarge(또는 더 큰) 인스턴스를 시작할 충분한 할당량이 있는지 확인하십시오. AWS Service Quotas 콘솔을 통해 선택한 리전(예: us-west-2)에서 더 많은 컴퓨팅 리소스를 요청할 수 있습니다(“온디맨드 G인스턴스와 VT 인스턴스 운영”에 최소 8개의 vCPU 권장).
AWS CDK 스택 배포
빠르게 시작할 수 있도록 리포지토리에 AWS CDK 스택이 제공됩니다. 스택은 아래 표에 나열된 미세 조정 파이프라인에 필요한 리소스를 자동으로 생성합니다
| 리소스 | 이름 | 용도 |
|---|---|---|
| VPC | BatchVPC | 퍼블릭/프라이빗 서브넷과 NAT 게이트웨이가 있는 격리된 가상 네트워크 |
| 보안 그룹 | BatchEFSSecurityGroup | Batch 인스턴스와 EFS 간의 NFS 트래픽을 허용하는 보안 그룹 |
| Elastic File System | BatchEFS | 모델 체크포인트 및 학습 로그용 공유 스토리지 |
| (선택 사항) S3 버킷 | IsaacGr00tCheckpointBucket | 미세 조정 모델 체크포인트 저장용 S3 버킷 |
| (선택 사항) CodeBuild | Gr00tContainerBuild | 미세 조정 Docker 이미지를 빌드하고 ECR에 푸시하는 AWS CodeBuild 프로젝트 |
| Elastic Container Registry | gr00t-finetune | 미세 조정 Docker 이미지용 컨테이너 레지스트리 |
| EC2 시작 템플릿 | BatchLaunchTemplate | 대용량 컨테이너 이미지 실행을 위해 루트 볼륨이 증가된 EC2 구성 |
| Batch 컴퓨팅 환경 | IsaacGr00tComputeEnvironment | GPU 인스턴스용 AWS Batch 컴퓨팅 환경 |
| Batch 작업 대기열 | IsaacGr00tJobQueue | 미세 조정 작업 제출 및 관리용 AWS Batch 작업 대기열 |
| Batch 작업 정의 | IsaacGr00tJobDefinition | 컨테이너 사양용 AWS Batch 작업 정의 템플릿 |
| EC2 인스턴스 | DcvInstance | Amazon DCV로 시뮬레이션 시각화 및 미세 조정 정책 평가용 EC2 인스턴스 |
스택을 배포하려면 다음 명령을 실행합니다. (AWS 프로필 / IAM 역할이 위 리소스 생성을 허용하는지 확인)
# From the root directory of the repo
cd training/gr00t/infra
cdk deploy IsaacGr00tBatchStack IsaacLabDcvStack --profile YOUR_AWS_PROFILE --region YOUR_AWS_REGION
기본적으로 Batch 스택은 infra 폴더를 패키징하여 AWS CodeBuild에 업로드하고, Dockerfile에서 컨테이너 이미지를 빌드하여 Amazon ECR에 푸시합니다. 이는 일반적으로 완료하는 데 10-20분이 소요됩니다. 기존 컨테이너 이미지를 사용하려면 스택을 배포할 때 환경 변수로 사용자 정의 ECR 이미지 URI를 제공하여 CodeBuild를 건너뛸 수 있습니다
ECR_IMAGE_URI=<ECR_IMAGE_URI> cdk deploy IsaacGr00tBatchStack IsaacLabDcvStack기타 배포 경로
사용 환경과 선호도에 따라 인프라를 설정하는 여러 경로를 사용할 수 있습니다. 이 블로그에서는 로컬 머신에서 AWS CDK로 모든 것을 자동으로 배포합니다. 이 경로는 빠른 설정 또는 프로그래밍 방식 사용자 정의를 허용하도록 선택되었습니다. AWS 콘솔을 통해 단계별로 모든 리소스를 생성하여 AWS Batch 리소스 구성을 더 잘 이해하고 AWS 콘솔 탐색에 익숙해지려면 콘솔 연습 경로를 따를 수 있습니다.
3. 미세 조정 작업 제출 및 모니터링
AWS Batch 리소스가 준비되면 미세 조정 작업을 반복적으로 실행할 수 있습니다. 이제 새 데이터셋(예: 새 구현체 또는 작업용)을 수집/추가할 때마다 작업 환경 변수를 업데이트하고 작업 대기열에 새 작업을 제출하기만 하면 됩니다. AWS Batch는 필요에 따라 컴퓨팅 리소스를 자동으로 시작하고 중지합니다. 작업을 제출하려면 AWS Batch 콘솔 또는 AWS CLI를 사용할 수 있습니다.
- 옵션 A – AWS Batch 콘솔: 왼쪽 탐색 창에서 Jobs를 선택하고 오른쪽 상단에서 Submit new job을 선택합니다. Name에
IsaacGr00tFinetuning을 입력하고, Job definition에서IsaacGr00tJobDefinition을 선택하고, Job queue에서IsaacGr00tJobQueue를 선택한 다음 Next를 선택합니다. 나머지는 기본값으로 두고 Next를 다시 선택한 다음 Submit job을 선택합니다.
기본적으로 작업은 리포지토리에 제공된 샘플 데이터셋에서 GR00T를 미세 조정합니다. 특정 데이터셋에서 미세 조정하려면 Container overrides 아래의 Environment variables를 업데이트할 수 있습니다. 예를 들어 HF_DATASET_ID를 설정하여 사용자 정의 Lerobot 데이터셋에서 미세 조정할 수 있습니다. 구성 가능한 환경 변수 목록은 샘플 환경 변수 파일을 참조하십시오.
- 옵션 B – AWS CLI: AWS CLI가 설치되어 있고 올바른 프로필과 리전으로 구성되어 있는지 확인합니다. 그런 다음 다음 명령을 실행하여 작업을 제출합니다
aws batch submit-job \
--job-name "IsaacGr00tFinetuning" \
--job-queue "IsaacGr00tJobQueue" \
--job-definition "IsaacGr00tJobDefinition" \
--container-overrides "environment=[{name=HF_DATASET_ID,value=}]"선택적으로 다음을 추가하여 --region <REGION>으로 리전을 재정의하거나, --profile YOUR_AWS_PROFILE로 프로파일을 재정의하거나, --container-overrides "environment=[{name=HF_DATASET_ID,value=<YOUR_HF_DATASET_ID>}]"로 환경 변수를 재정의할 수 있습니다.
기본적으로 작업은 GR00T를 6000 스텝 동안 미세 조정하며, 2000 스텝마다 모델 체크포인트를 저장합니다. 이는 일반적으로 g6e.4xlarge 인스턴스에서 최대 2시간이 소요됩니다. 작업 제출 시 MAX_STEPS 및 SAVE_STEPS 환경 변수를 재정의하여 스텝 수와 저장 빈도를 변경할 수 있습니다. 모델을 더 빠르게 미세 조정하려면 GPU – optional 필드를 재정의하고 사용하려는 GPU 수와 함께 NUM_GPUS 환경 변수를 추가하여 작업에 더 많은 GPU를 요청할 수 있습니다. 자세한 내용은 GR00T 컴포넌트 문서를 참조하십시오.
작업 진행 상황 모니터링
콘솔 또는 CLI를 사용하여 상태를 추적하고 로그를 스트리밍할 수 있습니다.
- 옵션 A – AWS Batch 콘솔 1. Jobs로 이동하여
IsaacGr00tJobQueue작업 대기열을 선택하고 Search를 선택합니다. 2. 목록에서 제출한 작업과 해당 상태를 볼 수 있습니다. 제출한 작업을 클릭하고 Logging 탭을 선택합니다. 실시간으로 로그를 볼 수 있습니다. - 옵션 B – AWS CLI:
JOB_ID(예: 위의batch submit-job출력에서)를 제공하고 선택적으로REGION및PROFILE을 설정하여 다음 명령을 실행합니다.
작업 상태 확인:
REGION=<REGION> PROFILE=<PROFILE> JOB_ID=<JOB_ID>; aws batch describe-jobs --jobs "$JOB_ID" \
--query 'jobs[0].{status:status,statusReason:statusReason,createdAt:createdAt,startedAt:startedAt,stoppedAt:stoppedAt}' \
--output table --region "$REGION" --profile "$PROFILE"작업이 RUNNING 상태가 되면 실시간으로 로그를 스트리밍할 수 있습니다:
REGION=<REGION> PROFILE=<PROFILE> JOB_ID=<JOB_ID>; aws logs tail /aws/batch/job \
--log-stream-names "$(aws batch describe-jobs --jobs "$JOB_ID" --query 'jobs[0].container.logStreamName' --output text --region "$REGION" --profile "$PROFILE")" \
--follow --region "$REGION" --profile "$PROFILE"참고: 작업이 실행되는 동안 아래 섹션 4에 설명된 평가 환경을 사용하여 학습 진행 상황을 모니터링하고 메트릭을 실시간으로 시각화할 수도 있습니다. 이를 통해 전체 미세 조정 프로세스가 완료될 때까지 기다리지 않고 학습 성능을 추적하고 체크포인트를 사용할 수 있게 되면 검사할 수 있습니다.
4. 미세 조정된 정책 평가
학습 과정을 모니터링하고, 시뮬레이션 환경에서 또는 선택적으로 실제 SO-ARM101을 사용하여 파인튜닝된 정책을 평가할 수 있습니다. 또한 학습이 진행되는 동안 TensorBoard 로그를 시각화하여 확인할 수도 있습니다.
체크포인트가 사용 가능해지면 DcvInstance에서 GR00T 정책 서버를 시작하고 IsaacLab을 실행하여 시뮬레이션 환경에서 미세 조정된 정책을 시각화하고 평가할 수 있습니다.
섹션 2에서 CDK 스택을 배포하면 Amazon DCV EC2 인스턴스가 초기화되고 사용자 데이터 스크립트를 실행하는 데 몇 분이 소요됩니다. 인스턴스에 로그인한 후 터미널에서
sudo cat /var/log/dcv-bootstrap.summary를 실행하여 상태를 확인할 수 있습니다. 19개의STEP_OK와 마지막에STEP_OK:EFS mount가 표시되면 인스턴스가 준비된 것입니다. 이 스택은/mnt/efs에서 Batch 스택에 연결된 동일한 EFS를 마운트하므로 작업이 실행되는 동안 tensorboard 로그와 모델 체크포인트를 실시간으로 검사할 수 있습니다.
1. DCV 인스턴스에 로그인하여 TensorBoard를 시각화하고 체크포인트를 검사하세요. 배포된 IsaacLabDcvStack의 출력(CLI 또는 CloudFormation 콘솔에서)을 확인하여 DCV 인스턴스 퍼블릭 IP 주소(DCVWebURL)와 자격 증명(DCVCredentials)을 가져온 다음, IP 주소로 이동하여 DCV 세션에 로그인합니다.
참고: 브라우저에서 “연결이 비공개가 아닙니다” 경고가 있을 수 있습니다. 무시하고 다음 단계로 진행하거나 DCV 클라이언트를 사용하여 인스턴스에 연결할 수 있습니다. DCV 인터페이스가 로드되었지만 “no session found” 오류가 발생하면 10분 후에 다시 시도하십시오. 문제 해결 및 사용자 정의 옵션에 대해서는 사용자 데이터 스크립트를 참조하세요.
로그인하면 Ctrl + Alt + T (또는 macOS에서 Control + Option + T)를 사용하여 터미널을 열 수 있으며 /mnt/efs/gr00t/checkpoints/runs 디렉토리에 tensorboard 로그가 있어야 합니다.
ls -l /mnt/efs/gr00t/checkpoints/runs다음 명령을 실행하여 tensorboard 서버를 시작합니다:
# If the conda environment is not activated, run: conda activate isaac
tensorboard --logdir /mnt/efs/gr00t/checkpoints/runs --bind_alltensorboard 서버는 포트 6006에서 실행되어야 합니다. DCV 인스턴스에서 직접 자동 생성된 URL을 “Ctrl + 클릭”하거나 DcvInstance 퍼블릭 IP 주소를 사용하여 모든 클라이언트(예: 로컬 노트북 브라우저)에서 액세스할 수 있습니다.(예: http://<DCV_INSTANCE_PUBLIC_IP>:6006)
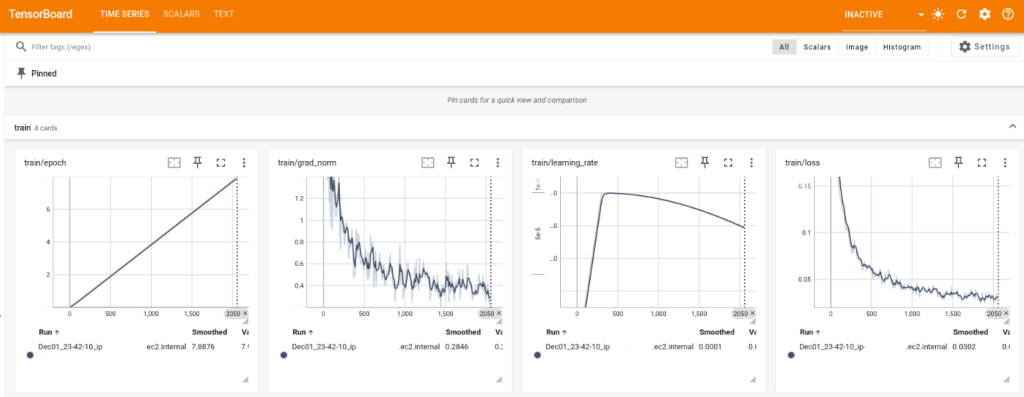
[GR00T 파인튜닝 진행 상황을 실시간으로 시각화한 그래프로, 네 가지 주요 학습 지표를 보여줍니다: 에포크 진행률(왼쪽), 그래디언트 노름 안정화(왼쪽 중앙), 학습률 스케줄(오른쪽 중앙), 손실 수렴(오른쪽)]
미세 조정 작업이 완료되면 /mnt/efs/gr00t/checkpoints 디렉토리에서 모델 체크포인트를 검사할 수 있습니다.
- Isaac GR00T 컨테이너 실행 및 정책 서버 시작하고 Amazon Elastic Container Registry 콘솔로 이동하여
gr00t-finetune컨테이너 리포지토리를 선택합니다. 오른쪽 상단의 View push commands를 클릭하여 ECR 인증을 위한 첫 번째 명령을 확인합니다. 명령은 다음과 같아야 합니다:
aws ecr get-login-password --region <REGION> | docker login --username AWS --password-stdin <ECR_PREFIX>
최신 이미지 태그의 URI를 복사하여 <ECR_IMAGE_URI>를 가져오고(예: 1234567890.dkr.ecr.us-west-2.amazonaws.com/gr00t-finetune:latest), 다음 명령을 실행하여 이미지를 가져오고 EFS를 읽기 전용으로 마운트한 대화형 셸을 시작합니다:
docker run -it --rm --gpus all --network host -v /mnt/efs:/mnt/efs:ro --entrypoint /bin/bash <ECR_IMAGE_URI>
컨테이너에서 <STEP>(예: 6000)으로 체크포인트를 선택하고 서버를 시작합니다:
MODEL_STEP=<STEP> # e.g. 6000
MODEL_DIR="/mnt/efs/gr00t/checkpoints/checkpoint-$MODEL_STEP"
python scripts/inference_service.py --server \
--model_path "$MODEL_DIR" \
--embodiment_tag new_embodiment \
--data_config so100_dualcam \
--denoising_steps 4서버가 준비되면 다음 출력이 표시됩니다:
Server is ready and listening on tcp://0.0.0.0:5555
3. leisaac 주방 장면 오렌지 집기 작업 실행
DCV 인스턴스에서 다른 터미널을 열고 다음 스크립트를 실행하여 leisaac 주방 장면 오렌지 집기 작업을 시작합니다. 이렇게 하면 시뮬레이션된 SO-ARM101이 컨테이너에서 실행 중인 GR00T 정책 서버에 연결됩니다:
# conda 환경이 활성화되지 않은 경우 실행, run: conda activate isaac
cd /home/ubuntu/leisaac
OMNI_KIT_ACCEPT_EULA=YES python scripts/evaluation/policy_inference.py \
--task=LeIsaac-SO101-PickOrange-v0 \
--policy_type=gr00tn1.5 \
--policy_host=localhost \
--policy_port=5555 \
--policy_timeout_ms=5000 \
--policy_action_horizon=16 \
--policy_language_instruction="Pick up an orange and place it on the plate" \
--device=cuda \
--enable_camerasIsaacSim은 처음 초기화하는 데 몇 분이 걸릴 수 있습니다.
이 스크립트를 실행하기 전에 컨테이너에서 추론 서버가 실행 중인지 확인하십시오. 장면이 로드되고 터미널에 [INFO]: Completed setting up the environment...가 표시되기까지 3-5분이 소요될 수 있으며, 이는 장면이 재생할 준비가 되었음을 나타냅니다. 노란색으로 표시되는 [Warning] 메시지와 빨간색으로 표시되는 [Error] 메시지는 무시해도 됩니다.
장면이 로드되면 시뮬레이션된 SO-ARM101이 오렌지를 집어 접시에 놓는 것을 볼 수 있습니다. IsaacSim 애플리케이션 창을 선택하고 r 을 눌러 장면을 재설정하고 무작위화하거나 터미널에서 Ctrl+C를 눌러 시뮬레이션을 중지할 수 있습니다.
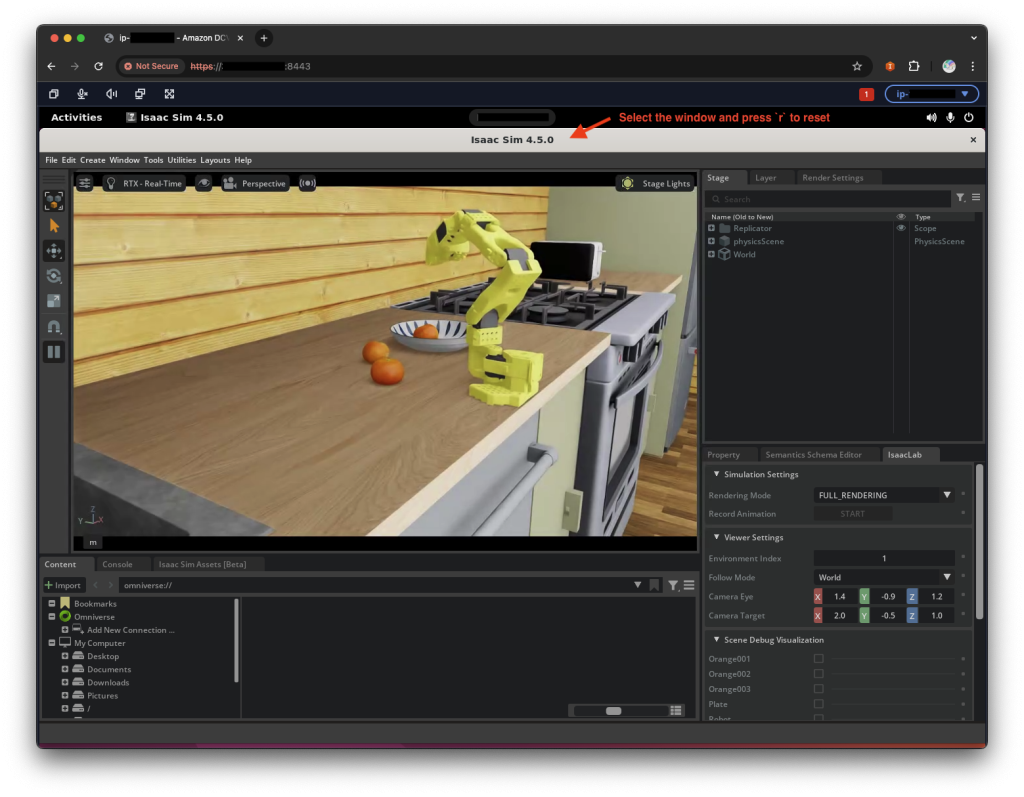
축하합니다! GR00T를 성공적으로 미세 조정하고 시뮬레이션에서 미세 조정된 정책을 평가했습니다. 손목 및 전면 카메라가 있는 물리적 SO-ARM101이 있는 경우 로컬 클라이언트를 원격 GR00T 정책 서버에 연결하여 로컬 물리적 SO-ARM101로 정책을 평가할 수도 있습니다. 다음 단계를 계속 진행하십시오:
- Lerobot 가이드에 따라 듀얼 카메라가 있는 SO-ARM101을 조립하고 캘리브레이션합니다
- Isaac GR00T 공식 가이드에 따라 로컬 머신에 종속성을 설치하고 Isaac GR00T 예제 클라이언트를 실행하여 물리적 SO-ARM101을 제어합니다
로컬 GPU 머신이 있는 경우 GR00T 정책 서버와 예제 클라이언트를 모두 로컬에서 실행할 수 있습니다. 자세한 내용은 Isaac-GR00T 가이드를 참조하십시오.
정리
진행 중인 요금을 피하려면 cdk destroy 명령으로 생성한 리소스를 해제합니다.
# 리포지토리 루트에서
cd training/gr00t/infra
# DCV 스택 먼저 삭제 (EC2 인스턴스 종료 및 EIP 해제)
cdk destroy IsaacLabDcvStack --force
# Batch 스택 삭제 (Batch 리소스, EFS, CDK로 생성된 경우 VPC 제거)
cdk destroy IsaacGr00tBatchStack --force결론
이 게시물에서는 AWS Batch, Amazon ECR, Amazon EFS를 사용하여 AWS에서 확장 가능하고 반복 가능한 로봇 학습 파이프라인을 구축하고, Amazon DCV로 구동되는 대화형 평가 환경과 결합했습니다. 인프라 프로비저닝과 컨테이너 관리를 자동화함으로써 가장 중요한 것에 집중할 수 있습니다: 복잡한 물리적 작업을 해결하기 위해 데이터셋과 정책을 반복하는 것입니다.
이 아키텍처는 로봇 학습 워크플로우를 확장하기 위한 견고한 기반을 제공합니다. NVIDIA Isaac GR00T와 같은 기반 모델을 미세 조정하든 LeRobot과 같은 오픈소스 프레임워크로 처음부터 정책을 학습하든, 탄력적 컴퓨팅과 공유 스토리지의 조합은 빠른 실험과 학습과 시뮬레이션 간의 원활한 피드백 루프를 가능하게 합니다.
유용한 리소스
- Robotics Fundamentals Learning Path | NVIDIA
- Robot Learning: A Tutorial – a Hugging Face Space by lerobot
- Enhance Robot Learning with Synthetic Trajectory Data Generated by World Foundation Models | NVIDIA Technical Blog
- NVIDIA Isaac GR00T in LeRobot
- Amazon FAR – TWIST2: 확장 가능하고 이식 가능한 통합 휴머노이드 데이터 수집 시스템
- LightwheelAI/leisaac: LeIsaac은 SO101Leader(LeRobot)를 사용하여 IsaacLab에서 텔레오퍼레이션 기능을 제공하며, 여기에는 데이터 수집, 데이터 변환 및 후속 정책 훈련이 포함됩니다.