AWS 기술 블로그
GloZ의 Amazon OpenSearch Service를 기반으로 한 자연어 이력서 검색 시스템 구축 사례 — Part 2: 하이브리드 검색과 자연어 쿼리 변환
1. Part 1 요약
Part 1: 데이터 파이프라인과 인덱싱에서는 검색 정확도의 기반이 되는 데이터 파이프라인을 다루었습니다. 글로지(GloZ Inc.)는 약 10만 명의 번역가 이력서를 검색 가능한 형태로 구조화하기 위해, 문서 유형별 파싱 → LLM 기반 메타데이터 추출 → 동의어·표기 변형 정규화 → 환각 검증 → 임베딩 입력 전략 최적화로 이어지는 데이터 정제 파이프라인을 구축했습니다. Amazon OpenSearch Ingest Pipeline과 ML Connector를 활용하여 인덱싱 단계에서 Amazon Bedrock Cohere 임베딩을 자동 생성하도록 구성했으며, “요약 + 메타데이터 키워드 평탄화” 방식이 가장 높은 검색 정확도를 보임을 실험으로 확인했습니다.
Part 2에서는 이렇게 준비된 데이터를 기반으로, 하이브리드 검색 가중치 최적화, 자연어의 DSL(Domain-Specific Language) 변환, 그리고 최종 비즈니스 성과를 다룹니다.
2. 프로젝트 배경
검색 단계의 한계
Part 1에서 다룬 데이터 파이프라인 한계 외에, 검색 단계에서도 다음과 같은 문제가 있었습니다.
자연어 쿼리 처리의 정확도 한계
번역가 검색에 사용되는 조건은 매우 다양합니다. 실제로 번역가 온보딩·소싱을 담당하는 프로젝트 PM이 입력하는 쿼리는 다음과 같이 한 문장에 여러 조건이 자유롭게 얽혀있는 경우가 많습니다.
- “더빙 경력이 있는 영어 또는 스페인어 원어민”
- “한영 자막 번역 경력이 5년 이상이면서 Aegisub 또는 Subtitle Edit을 사용해본 번역가”
- “의료·법률·금융 같은 전문 도메인 번역 경험이 없는 번역가 (일반 독자 시각의 평가자 후보 발굴용)”
이러한 자연어 쿼리를 정확한 검색 조건으로 변환하기 위해 단순 키워드 매칭이나 규칙 기반 파싱을 적용했으나, 다음과 같은 정확도 문제가 빈번하게 발생했습니다.
- “원어민 수준 영어”를 language_pairs=[“en-ko”]로 잘못 추론 — “원어민 수준”은 단순한 언어 능숙도를 의미하는데, 한국 기반 플랫폼 특성상 LLM이 타겟 언어를 한국어(ko)로 임의 추론
- “더빙 전문가”를 content_types=[“dubbing”]과 project_types=[“dubbing”]에 동시 추출하여 결과가 급감
- 단일 언어 표현(“독일어 번역가”)에서 임의 방향을 추론하여 잘못된 언어쌍 생성
분리된 메타데이터 필터링과 벡터 검색으로 인한 정확도 저하
메타데이터 필터링과 벡터 검색이 서로 다른 단계에서 수행되어, AND/OR/NOT 복합 조건을 정확히 반영하기 어려웠습니다. AND·OR·NOT이 동시에 얽힌 조건의 경우, 메타데이터 단계에서 일부 후보를 과도하게 걸러내거나 벡터 검색 단계에서 제외 조건이 무시되는 등 두 단계가 일관성 없이 결합되어 결과의 정확도가 저하되었습니다.
해결하고자 한 과제
- 복합 조건 처리: AND/OR/NOT 조건을 정확히 반영합니다.
- 자연어 → DSL 변환 정확도: 자연어 쿼리를 일관되고 정확한 검색 조건으로 변환합니다.
- 하이브리드 검색 최적화: BM25와 Vector 검색의 최적 결합 방식을 찾습니다.
3. 솔루션 구현 — 하이브리드 검색과 자연어 쿼리 변환
핵심 설계 원칙
- 하이브리드 검색 정규화·결합 전략 탐색: BM25 점수(0~∞)와 Vector 점수(0~2 범위, L2 거리 기반)는 스케일이 달라 단순 합산이 어렵습니다. OpenSearch의 normalization-processor와 search-pipeline을 활용하여 두 점수를 정규화·결합하고, 정규화 방식·결합 방식·가중치 조합을 Grid Search하여 워크로드에 적합한 최적값을 도출했습니다.
- Function Calling 기반 NL→DSL 변환: Bedrock Claude Haiku 4.5의 Tool Use (Function Calling)을 활용하여 자연어 쿼리를 OpenSearch DSL로 변환합니다. 여기서는 두 가지 핵심 원칙을 따릅니다.
- 결정론적 DSL 생성: LLM이 DSL 전체를 생성하지 않고 검색 파라미터만 추출하도록 설계하고, DSL 조립은 백엔드 코드가 담당하도록 책임을 분리했습니다. 이를 통해 쿼리의 일관성과 가중치 제어를 확보할 수 있습니다.
- RAG 패턴으로 변환 정확도 보강: 과거 변환 예시를 OpenSearch의 별도 인덱스로 저장하여, 새 쿼리가 들어올 때 유사한 예시를 Few-shot으로 동적 주입합니다.
모델 선택 근거
LLM (Bedrock Claude Haiku 4.5): 자연어에서 검색 파라미터를 추출하는 것은 입출력 토큰이 짧고 정형화된 단순 추출 작업이라 고성능 모델이 불필요합니다. 빠른 응답·낮은 비용·Function Calling 지원이 검증된 Haiku 계열을 선택하여 초당 수 회의 검색 요청에도 안정적으로 대응합니다
검색 아키텍처
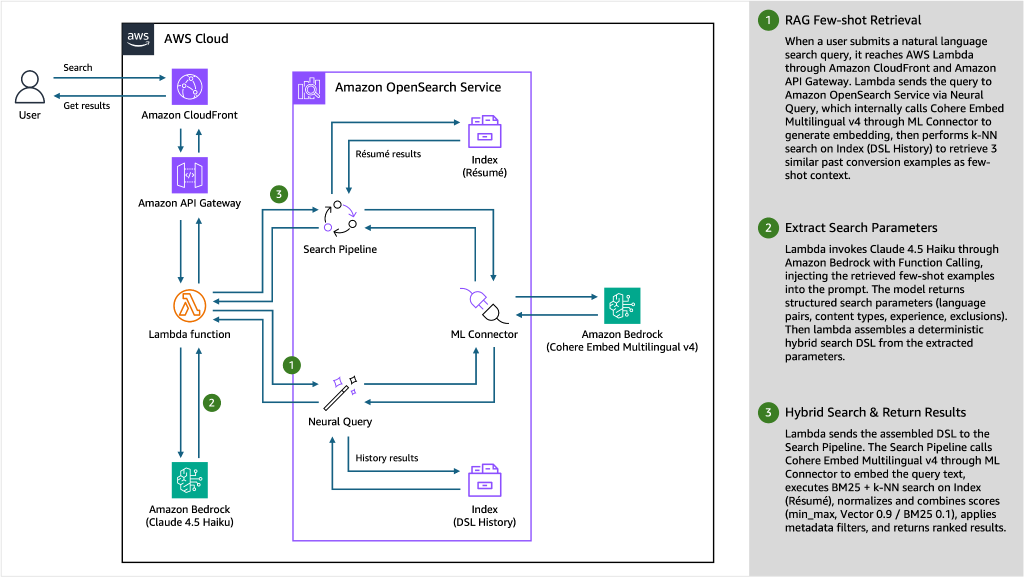
1. RAG Few-shot 조회 (RAG Few-shot Retrieval)
사용자가 자연어로 검색 쿼리를 입력하면, Amazon CloudFront와 Amazon API Gateway를 거쳐 AWS Lambda에 도달합니다. Lambda는 OpenSearch에 Neural Query를 전달하고, ML Connector를 통해 Amazon Bedrock의 Cohere Embed Multilingual v4로 쿼리를 임베딩한 뒤, Index(DSL History)에서 유사한 과거 변환 예시 3개를 k-NN 검색으로 조회합니다.
2. 검색 파라미터 추출 (Extract Search Parameters)
Lambda가 Bedrock의 Claude Haiku 4.5를 Function Calling으로 호출합니다. 앞서 조회한 Few-shot 예시를 프롬프트에 주입하여 구조화된 검색 파라미터(언어 쌍, 콘텐츠 도메인, 경력, 제외 조건 등)을 추출하고, 이를 기반으로 하이브리드 검색 DSL을 결정론적으로 조립합니다.
3. 하이브리드 검색 및 결과 반환 (Hybrid Search & Return Results)
Lambda가 조립된 DSL을 Search Pipeline으로 전달합니다. Search Pipeline은 ML Connector를 통해 Bedrock Cohere 모델로 쿼리 텍스트를 임베딩하고, BM25 + k-NN 검색을 실행한 뒤 점수를 정규화 및 결합(min_max, Vector 0.9 / BM25 0.1)하여 메타데이터 필터를 적용하고 최종 랭킹된 결과를 반환합니다.
하이브리드 검색 가중치 최적화
Grid Search
OpenSearch의 Search Pipeline을 활용하여 BM25 점수와 Vector 점수를 정규화하고 결합하는 하이브리드 검색을 구현했습니다. 워크로드 특성에 맞는 조합을 찾기 위해 정규화 방식 2종과 결합 방식 3종, 가중치 11단계를 이용해 총 66개 조합에 대한 Grid Search를 수행했습니다.
실험 결과
min_max 정규화 + harmonic_mean 결함 + Vector 0.9 / BM25 0.1 조합이 가장 우수한 정확도를 보여주었습니다. 이는 이력서 검색 도메인이 키워드 일치보다 의미 유사도(예: “현지화 전문가” ↔ “localization specialist”)가 더 중요하다는 점을 정량적으로 입증합니다.
운영 환경 적용
데이터 규모가 커질수록(497건 → 5,000건) semantic-heavy와 균형 가중치의 정확도 차이가 약 70%에서 1.5%로 급격하게 감소하였고, 일부 키워드 의존적 쿼리에서는 semantic-heavy가 오히려 랭킹을 저해하는 사례로 관찰되었습니다. 이를 종합하여 운영 환경에서는 균형 가중치(0.4:0.6, arithmetic_mean)를 기본값으로 두고, 세 가지 프리셋(keyword_heavy, balanced, semantic_heavy)을 사전 정의하여 LLM이 쿼리 특성에 따라 자동 선택할 수 있는 구조로 운영하게 되었습니다.
한국어 처리
한국어 이력서의 검색 품질을 확보하기 위해 Nori 형태소 분석기를 OpenSearch 패키지로 설치하고 인덱스 매핑에 적용했습니다. 복합어 분해(nori_tokenizer mixed decompound 모드로 복합어를 원형과 분해형 양쪽으로 색인), 읽기형 변환(nori_readingform 필터로 한자 표기를 한글 읽기로 정규화), 품사 기반 필터링(lowercase 등 필터 체인을 통해 검색 노이즈 토큰 정리)을 함께 설정하여 “게임 로컬라이제이션”, “K-드라마 자막”과 같은 한국어 복합어 검색이 정확하게 동작하도록 했습니다.
Function Calling + RAG 패턴
자연어 쿼리를 OpenSearch DSL로 변환하기 위해 두 가지 접근을 비교했습니다.
- OpenSearch Agentic Search: LLM이 자연어로부터 OpenSearch DSL 자체를 생성하는 방식
- Function Calling(Tool Use): LLM은 검색 파라미터만 추출하고 DSL 조립은 결정론적 코드가 담당
두 방식을 약 150건의 평가 쿼리(LLM 자동 생성 + 실무자 인터뷰 기반 결합)로 동일 운영 데이터 기준에서 직접 비교했습니다.
Agentic Search: 검토 배경과 한계
NL→DSL 변환을 설계하던 초기, OpenSearch의 Agentic Search를 고려한 이유는 다음과 같습니다:
- 엔드투엔드 단순화: 자연어 입력 → DSL 생성 → 검색까지 OpenSearch 내부에서 처리되므로, 별도의 파라미터 추출·DSL 조립 코드를 줄일 수 있을 것으로 기대했습니다.
- 유연한 쿼리 구조: 정해진 스키마에 얽매이지 않고, LLM이 인덱스 매핑을 참조하여 쿼리 구조를 자유롭게 구성할 수 있습니다.
- OpenSearch 네이티브 기능 활용: 검색 엔진에 통합된 기능을 그대로 사용하여 운영 구성요소를 단순화할 수 있습니다.
이에 따라 Agentic Search를 두 가지 형태로 구현·테스트했습니다:
- 기본형(Flow Agent + QueryPlanningTool): LLM이 인덱스 매핑을 참조해 DSL을 직접 생성
- 템플릿형(Flow Agent + Search Templates): LLM이 사전 정의된 Mustache 검색 템플릿을 선택하고 파라미터만 채움
테스트에서 확인한 구조적 한계
- 하이브리드 검색 불가: Agentic Search가 생성한 Neural(벡터) 쿼리를 일반 텍스트 필드에 적용하면 오류가 발생했습니다. 결국 프롬프트 단계에서 Neural·k-NN 쿼리 생성을 차단하고 BM25(키워드) 검색만 허용해야 했습니다. 이력서 검색은 의미 유사도 비중이 큰 도메인입니다. 예를 들어 “게임 번역가”라는 쿼리가 이력서에 “video game localization”으로 표현돼 있어도 매칭되어야 합니다. 하지만 벡터 검색이 빠지면서 검색 품질이 크게 하락했습니다.
- 필터 값 검증 단계 부재: Agentic Search는 LLM이 생성한 필터 값을 그대로 DSL에 삽입합니다. LLM이 인덱스의 실제 필드 값 분포를 알지 못하므로, 존재하지 않거나 과도하게 확장된 필터 값을 생성하는 경우가 잦았습니다(예: 하나의 도메인만 필요한 쿼리에 연관 도메인 값까지 함께 추출). Function Calling 방식에서는 LLM이 추출한 값을 표준 어휘 사전(VALID_VALUES)·별칭·퍼지 매칭으로 검증·정규화하는 레이어를 삽입할 수 있지만, Agentic Search 파이프라인에는 이러한 중간 검증을 삽입하기 어려웠습니다.
- 비결정성: 동일한 자연어 쿼리에도 매번 다른 구조의 DSL이 생성될 수 있어, 디버깅과 운영 측면에서 일관성을 확보하기 어려웠습니다.
이러한 한계를 확인한 뒤, LLM의 역할을 “파라미터 추출”로 한정하고 DSL 조립은 결정론적 코드가 담당하는 Function Calling 패턴을 최종 채택했습니다.
Function Calling 스키마
자연어 검색 쿼리를 OpenSearch DSL의 필터 구조로 변환하기 위해, Bedrock Claude Haiku 4.5의 Tool Use(Function Calling) 기능을 사용했습니다.
parse_search_query라는 tool을 정의하고, LLM이 자연어 입력에서 추출해야 할 필드(언어쌍, 콘텐츠 도메인, 도구, 경력, 제외 조건 등)를 구조화된 스키마로 명세했습니다.
Tool 스키마 예시
{
"type": "function",
"function": {
"name": "parse_search_query",
"description": "Extract structured search parameters from a natural language query about finding translators, interpreters, or language professionals.",
"parameters": {
"type": "object",
"properties": {
"query_text": {
"type": "string",
"description": "Concise English keyword query for BM25/vector search. Translate Korean input to English. Focus on skills, experience, and domain expertise."
},
"language_pairs": {
"type": "array",
"items": {"type": "string"},
"description": "Language pairs in source-target format (e.g., 'ko-en' for Korean to English). Use ISO 639-1 codes."
},
"content_types": {
"type": "array",
"items": {"type": "string"},
"description": "Content domains. Valid: entertainment, subtitling, education, business, literary, marketing, gaming, medical, culture, technical, legal, webtoon, dubbing, press, tourism."
},
"tools": {
"type": "array",
"items": {"type": "string"},
"description": "CAT tools or software. Valid: trados, memoq, subtitle edit, aegisub, memsource, smartcat, wordfast, ooona, eztitles, etc."
},
"min_experience_months": {
"type": "integer",
"description": "Minimum experience in months. Convert years to months (e.g., '3 years' = 36)."
},
"exclude_language_pairs": {
"type": "array",
"items": {"type": "string"},
"description": "Language pairs to EXCLUDE from results."
},
"exclude_content_types": {
"type": "array",
"items": {"type": "string"},
"description": "Content domains to EXCLUDE."
}
},
"required": ["query_text"]
}
}
}주요 설계 포인트
- Tool Use 활용: 단순 텍스트 응답이 아닌 구조화된 JSON을 강제로 받아내어, LLM 출력의 일관성·파싱 안정성 확보.
- 표준 어휘 강제: description 필드에 valid한 값들을 명시하여 LLM이 임의 표현을 생성하지 않도록 유도.
- 제외 조건 분리 (exclude_*): “의료 분야 제외” 같은 NOT 조건을 별도 필드로 분리하여 BM25/k-NN 본 쿼리와 분리 처리.
비교 결과
Function Calling 방식이 동일 데이터 기준 랭킹 품질에서 큰 폭으로 우수했고, 응답 속도도 35% 빨랐습니다. 이러한 차이는 Agentic Search의 다음과 같은 구조적 한계에서 기인합니다.
- BM25 기반 키워드 검색 전용: Neural 쿼리를 텍스트 필드에 적용할 수 없어, 하이브리드 검색 자체가 불가능합니다.
- 가중치 제어 불가: BM25:Vector 가중치 조절 자체가 의미 없어, 도메인 특성에 맞춘 튜닝이 어렵습니다.
- 데이터 분포 미인지: LLM이 실제 인덱스의 필드 값 분포를 모르기 때문에, 존재하지 않는 필터 값을 생성하는 경우가 빈번합니다.
- 비결정성: 동일한 자연어 쿼리에도 매번 다른 DSL이 생성될 수 있어 디버깅과 운영이 어렵습니다.
이 결과를 바탕으로 파라미터 추출은 LLM, DSL 조립은 결정론적 코드로 책임을 분리하는 아키텍처를 채택했습니다. LLM 출력은 사전에 정의한 표준 어휘 사전(VALID_VALUES)과 별칭/퍼지 매칭으로 검증·정규화하여, 존재하지 않는 필터 값이 생성되지 않도록 안전망을 구축했습니다.
실행 예시
사내 PM (검색 사용자)가 입력한 자연어 쿼리가 OpenSearch DSL로 변환되어 실행되는 전체 흐름의 구체적인 예시입니다.
Step 1: 사용자 자연어 입력
- “Netflix 자막 번역 5년 이상 경력의 한영 번역가, 의료 분야 제외, Trados 사용 가능”
Step 2: Bedrock Claude Haiku 4.5 (Function Calling) 호출
구조화 결과
{
"query_text": "Netflix subtitle translation experienced Korean to English translator with Trados",
"language_pairs": ["ko-en"],
"content_types": ["subtitling", "entertainment"],
"tools": ["trados"],
"min_experience_months": 60,
"exclude_content_types": ["medical"]
}Step 3: 백엔드 Lambda가 OpenSearch Hybrid Query DSL로 조립
GET resumes-v01/_search?search_pipeline=resume-hybrid-search-pipeline
{
"size": 20,
"query": {
"hybrid": {
"queries": [
{
"multi_match": {
"query": "Netflix subtitle translation experienced Korean to English translator with Trados",
"fields": ["summary^2", "search_text", "summary.korean"]
}
},
{
"neural": {
"embedding": {
"query_text": "Netflix subtitle translation experienced Korean to English translator with Trados",
"model_id": "<ml-connector-model-id>",
"k": 100
}
}
}
]
}
},
"post_filter": {
"bool": {
"must": [
{ "term": { "language_pairs": "ko-en" } },
{ "terms": { "content_types": ["subtitling", "entertainment"] } },
{ "term": { "tools": "trados" } },
{ "range": { "total_experience_months": { "gte": 60 } } }
],
"must_not": [
{ "term": { "content_types": "medical" } }
]
}
}
}Step 4: Search Pipeline에서 BM25/k-NN 점수 정규화 + 결합 → 최종 랭킹
- Normalization: min_max로 BM25와 k-NN 점수를 0~1로 정규화
- Combination: arithmetic_mean으로 가중 평균 (BM25 0.1 / Vector 0.9, semantic-heavy preset)
- Filters (must / must_not): 정확 매칭 필터를 post_filter로 적용하여 랭킹 품질 보존
- 최종 결과: 조건을 만족하는 상위 20명의 번역가 후보 반환
RAG(Retrieval-Augmented Generation) 패턴 도입
Function Calling 단독 변환만으로는 정확도에 한계가 있어 RAG 패턴을 추가했습니다.
- 과거 변환 예시 약 40여 건을 별도의 OpenSearch 인덱스에 임베딩 형태로 저장
- 새 쿼리가 들어오면 OpenSearch가 Neural Query를 통해 ML Connector로 임베딩을 생성하고, k-NN 검색으로 유사한 예시 3개를 가져와 LLM 프롬프트에 few-shot 예시로 동적 주입
- 평가 시에는 데이터 누수를 방지하기 위해 leave-one-out 프로토콜을 적용
이 접근만으로 Function Calling 베이스라인(nDCG@10 0.847) 대비 약 +4%p 추가 개선되어 0.882에 도달했으며, 특히 자연어 표현이 모호한 쿼리(예: “원어민 수준”, “전문가 우대”)에서 변환 정확도가 크게 향상되었습니다.
평가 데이터셋 구축 — LLM 생성 + 실무자 질문 결합
RAG의 성능은 학습 예시·평가 데이터의 품질에 크게 좌우됩니다. 평가 데이터를 구성할 때 단순히 LLM이 합성한 쿼리만 사용하면 실제 사용자 패턴과 괴리가 생기므로, 두 가지 출처를 결합하여 약 150건의 평가 쿼리 셋을 구축했습니다.
- LLM 기반 자동 생성: 다양한 조합(언어쌍·도메인·도구·경력)을 변형하며 LLM이 합성한 다수의 테스트 쿼리
- 실무자 인터뷰 기반 실제 쿼리: 번역가 온보딩·소싱을 담당하는 프로젝트 PM에게 직접 받은 실제 사용 패턴의 쿼리
AND 필터 누적 효과 발견 및 해결
OpenSearch에서 모든 필터는 AND 조건으로 적용되므로, 필터가 하나 추가될 때마다 결과가 곱셈적으로 감소합니다. LLM이 자연어로부터 너무 많은 필터를 추출할 경우 검색 결과가 급격히 감소하는 문제를 발견했습니다. 실무자 쿼리의 경우, LLM이 “원어민 수준”을 language_pairs=[“en-ko”, “es-ko”]로 잘못 추론하면서 결과가 271건에서 12건으로 약 95% 감소했습니다. 이를 해결하기 위해 다음과 같은 2단계 접근을 적용했습니다.
- 시스템 프롬프트에 “필터 최소화 원칙”을 명시하여, 확실한 조건만 필터로 사용하고 모호한 표현(원어민 수준, 능숙, 우대 등)은 query_text에 두어 의미 검색이 처리하도록 분리
- RAG 예시 데이터 자체를 정제하여, 동시 다중 필터를 사용하는 예시 약 30건을 단일 필터 기준으로 수정
이를 통해 실무 사용 쿼리(REAL) 기준 필터 정확도를 36.4% → 90.9%로 개선할 수 있었습니다. 결과적으로 확실한 조건만 필터로 두고, 나머지는 의미 검색이 처리하도록 분리하는 방향으로 정리되었습니다.
결과 스트리밍을 통한 체감 응답 속도 개선
검색 파이프라인 전체 응답 시간(NL→DSL 변환·임베딩·OpenSearch 하이브리드 검색·결과 조립)은 평균 2~3초 수준입니다. 사용자가 결과를 더 빠르게 인지할 수 있도록 WebSocket보다 가볍게 관리할 수 있는 SSE(Server-Sent Events) 기반의 점진적 스트리밍을 구현하여, 진행 상태와 결과를 단계적으로 브라우저에 전달함으로써 체감 응답 속도를 개선했습니다.
4. 비즈니스 효과 (Customer Benefits)
자연어 검색 정확도 nDCG@10 0.901, 자연어 → DSL 변환 정확도 91.7%를 달성했으며, 번역가 온보딩·소싱을 담당하는 프로젝트 PM의 인력 탐색·검토 시간을 단축했습니다.
| 지표 | 값 | 의미 |
|---|---|---|
| nDCG@10 | 0.901 | 상위 10개 결과의 검색 관련도 |
| Precision@5 | 0.912 | 상위 5개 결과 중 91.2%가 적합한 후보 |
| MRR | 0.944 | 평균 정답 위치 (1.06번째에 정답이 등장) |
| Filter Accuracy | 94% | 필터 조건(언어쌍·도메인·경력 등) 정확도 |
| NL→DSL 변환 정확도 | 91.7% | 자연어 쿼리의 의도 추출 정확도 |
정량적 성과
아래 수치는 LLM 기반 자동 채점 파이프라인으로 구축한 약 150건의 평가 데이터셋 기준입니다. 각 후보 문서에 대해 LLM이 관련성 점수를 판정하고, 데이터 규모 확장 시 신규 문서에 대한 판정을 추가해 평가에 대한 일관성을 유지하였습니다.
응답 시간
- 평균 검색 응답 시간: 2.3~3.3초 (NL→DSL 변환 포함)
검색 정확도 (운영 데이터)
베이스라인은 OpenSearch + Function Calling 변환만 적용한 시점(RAG·가중치 최적화 미적용)이며, 비교 대상인 최적 파이프라인은 RAG few-shot과 가중치 최적화까지 모두 적용한 최종 구성입니다.
자연어 → DSL 변환 정확도
- 전체 정확도: 91.7% (약 150건 평가 쿼리 기준)
- 필드별: 도구 100%, 언어쌍 94.4%, 도메인 93.6%, 경력 수준 100% 등
개선 단계별 누적 효과
각 개선 요소의 기여도를 분리 측정하기 위해 4가지 파이프라인을 동일 평가 기준으로 비교했습니다. 각 단계의 개선이 누적되어 최종 nDCG@10 0.901을 달성했습니다.
| 파이프라인 | 구성 | nDCG@10 | 베이스라인 대비 |
|---|---|---|---|
| A (베이스라인) | Function Calling | 0.819 | – |
| B (프롬프트 정교화) | A + 프롬프트 개선 | 0.847 | +3.4% |
| C (RAG few-shot) | B + RAG few-shot 주입 | 0.882 | +7.7% |
| D (가중치 최적화) | C + semantic-heavy 가중치 적용 | 0.901 | +10.0% |
확장성
데이터 규모별 정확도를 검증하기 위해 PoC부터 운영 환경까지 데이터를 점진적으로 확장하며 동일 평가 기준으로 검증했습니다. 데이터가 풍부해질수록 모든 파이프라인이 nDCG@10 0.85 이상으로 수렴하며, 이는 알고리즘 차이보다 데이터 품질·규모가 검색 정확도를 결정한다는 점을 시사합니다. 약 10만 명의 번역가 풀 대상 검색을 안정적으로 운영하고 있으며, 향후 전체 이력서 인덱싱 확대 시에도 OpenSearch 매니지드 환경에서 노드 스케일업만으로 대응할 수 있게 되었습니다.
정성적 성과·비즈니스 영향
- 후보 발굴 효율 향상: 번역가 온보딩·소싱을 담당하는 프로젝트 PM이 자연어로 직접 후보를 검색할 수 있게 되어, 기존 수작업 필터링 대비 인력 탐색 및 검토 시간이 단축되었습니다.
- 사내 품질 관리 시스템(Linguist Leaderboard)과의 통합: 본 검색 시스템은 사내 번역과 품질 관리 대시보드에 쉽게 통합되었습니다. 이를 통해 작업 이력 기반 필터와 이력서 기반 자연어 검색을 동시에 활용할 수 있게 되었습니다.
- 운영 부담 감소: Part 1에서 다룬 OpenSearch 매니지드 서비스 전환을 통해 인덱스 갱신 · 모니터링이 표준화되었습니다.
- 데이터 품질 가시성 확보: 환각 데이터 자동 검출·제거 파이프라인을 통해 지속적인 품질 개선이 가능해졌습니다.
5. 마무리
본 블로그 시리즈에서는 GloZ의 약 10만 명 번역가 이력서를 대상으로, Amazon OpenSearch Service 기반 자연어 검색 시스템을 설계·구축한 전 과정을 두 편에 걸쳐 다뤘습니다.
Part 1에서는 검색 정확도의 기반이 되는 데이터 파이프라인을 다루었습니다. 이력서 원문을 구조화하고, 정규화하고, 환각을 검증하고, 최적의 임베딩 입력 전략을 선택하는 과정이 검색 품질을 결정하는 가장 중요한 요소임을 확인했습니다.
Part 2에서는 BM25 + 벡터 하이브리드 검색 가중치 최적화와 Function Calling + RAG 패턴의 자연어 쿼리 변환을 구현했습니다. LLM의 역할을 파라미터 추출로 한정하고, 필터 최소화 원칙과 RAG Few-shot을 결합하여 최종 nDCG@10 0.901, NL→DSL 변환 정확도 91.7%를 달성했습니다.
적합한 번역가와 프로젝트가 더 빠르게 연결될수록, 창작자의 콘텐츠는 언어를 넘어 더 빨리 전 세계 곳곳의 사용자에게 전달 될 수 있습니다. GloZ는 이번 자연어 기반 이력서 검색 시스템 구축 사례를 통해 이 연결의 속도를 높여가고 있습니다. 이 사례가 비정형 문서에 자연어 검색을 적용하고자 하는 기업에게 실질적인 레퍼런스가 되기를 기대합니다.