AWS 기술 블로그
PostgreSQL 성능 개선: 락 매니저 경합 진단 및 완화
이 글은 AWS Database Blog에 게시된 Improve PostgreSQL performance: Diagnose and mitigate lock manager contention by Sumit Kumar, Devinder Singh, and Ramesh Kumar Venkatraman 을 한국어 번역 및 편집하였습니다.
워크로드가 증가하면서 데이터베이스 읽기 작업이 예상치 못하게 느려지고 있나요? PostgreSQL 기반 시스템을 운영하는 많은 조직은 즉각적으로 파악하기 어려운 성능 병목 현상을 겪게 됩니다. 여러 개의 파티션이나 인덱스가 있는 테이블에 많은 읽기 작업이 동시에 수행되는 경우, PostgreSQL의 빠른 경로 잠금 메커니즘(PostgreSQL’s fast path locking mechanism) 제한을 초과하여, 시스템이 공유 메모리 락을 사용하게 될 수 있습니다. 빠른 경로 락에서 공유 메모리 락으로 전환하면 락 매니저에서 경량 락(LWLock) 경합이 발생하므로, 읽기 전용 작업을 수행하는 도중에도 데이터베이스 성능에 영향을 미칩니다.
이 글에서는 읽기 위주의 워크로드가 빠른 경로 잠금 제한을 초과하여 LWLock 경합을 유발하는 방식을 살펴봅니다. 이는 PostgreSQL 엔진과 그 잠금 메커니즘을 기반으로 하는 모든 시스템에서 발생할 수 있는 문제입니다. 이 글에서는 시연을 위해 Amazon Aurora PostgreSQL 호환 버전을 사용하며, 실제 예시를 통해 파티션 스캔, 인덱스 사용, 복잡한 조인이 락에 미치는 영향을 보여줍니다. 또한 워크로드가 느린 경로 잠금(slow path locking)으로 전환되는 시점을 파악하고, 더 나은 성능을 위해 쿼리 설계와 스키마 구조를 최적화하는 구체적인 기법도 소개합니다.
읽기 위주의 워크로드가 증가함에 따라, DBA는 데이터베이스의 안정성을 유지하기 위해 LWLock 경합을 모니터링하고 해결해야 합니다. 마찬가지로 개발자 또한 과도한 경합을 유발하는 패턴을 피해야 합니다. 데이터베이스가 빠른 경로 잠금에서 느린 경로 잠금으로 전환될 때 처리량이 크게 저하될 수 있기 때문입니다. 이 글에서 보여주는 테스트를 통해, 최대 34%의 성능 차이를 확인할 수 있습니다. LWLock:lock_manager와 같은 대기 이벤트를 모니터링하고, pg_locks 뷰를 검토하여 워크로드를 실행하는 백엔드 프로세스의 빠른 경로 슬롯이 소진되고 있는지 확인함으로써, 처리량 감소를 식별할 수 있습니다. 이러한 병목을 해결하기 위해서는 파티션 프루닝을 효과적으로 수행하고, 인덱스를 주의 깊게 관리하며, 백엔드 프로세스당 PostgreSQL의 빠른 경로 잠금 슬롯 16개 제한 내에서 워크로드를 유지하도록 조인 패턴을 단순화하는 등의 전략이 필요합니다.
LWLock 경합 이해하기
LWLock은 PostgreSQL에서 공유 메모리 구조에 대한 접근을 제어하는 데 사용하는 동기화 기법입니다. 사용자에 의한 데이터베이스 객체 수준 잠금에 사용되는 무거운 락(heavyweight locks)과는 달리, LWLock은 가볍고 고성능을 위해 최적화되어 있어 적은 오버헤드로 공유 자원에 대한 동시 접근을 관리할 수 있습니다.
LWLock 경합은 여러 프로세스들이 공유 메모리의 락 데이터 구조 상에서 동일한 LWLock을 획득하려고 경쟁할 때 발생하며, 이는 지연을 초래합니다. 이러한 경합은 일반적으로 많은 백엔드 프로세스들이 다음과 같은 공유 자원에 접근해야 할 때 발생합니다.
- 버퍼 매니저 – 읽기/쓰기 작업 중 공유 버퍼(shared buffer)를 보호합니다.
- 락 매니저 – 락과 관련된 데이터 구조에 대한 접근을 조정합니다.
- WAL 관리 – 미리 쓰기 로그(WAL)에 대한 쓰기를 동기화합니다.
LWLock 경합은 데이터베이스에 대한 동시 연결이 증가함에 따라 함께 증가할 수 있습니다. 이는 특히 높은 처리량을 보이는 환경에서 두드러지는데, Aurora PostgreSQL-Compatible Edition과 같이 높은 병렬 처리, 다수의 파티션이 있는 테이블, 또는 많은 인덱스가 있는 테이블을 포함하는 워크로드를 지원할 수 있는 상황에서 특히 그렇습니다.
테이블에 대해 SQL 쿼리를 실행하는 동안, PostgreSQL은 테이블과 관련 인덱스에 대한 락을 획득하려 합니다. 파티션된 테이블의 경우, SQL 쿼리가 접근하려는 테이블 파티션에 대한 락이 획득됩니다. 잠금을 더 빠르고 효율적으로 수행하기 위해, 시스템이 다른 락과의 충돌이 없다는 것을 신속하게 확인할 수 있는 경우, AccessShareLock, RowShareLock, RowExclusiveLock과 같은 덜 제한적인 약한 락에 대해 빠른 경로 잠금이 사용됩니다.
Fast Path 잠금: 작동 메커니즘
PostgreSQL에서 빠른 경로 잠금 메커니즘은 작업간 충돌이 없다면 공유 메모리 락 해시 테이블과 관련 LWLock을 우회할 수 있게 합니다. 빠른 경로 잠금은 가장 일반적인 사용 사례를 위해 설계되었으며, 동일한 릴레이션에 충돌하는 강력한 락이 없는 한, 약한 락을 획득하는 빈번한 동시 쿼리를 처리합니다.
빠른 경로 잠금의 작동 방식은 다음과 같습니다.
- 세션별 캐시 – 각 백엔드 프로세스는 빠른 경로 락을 저장하기 위해 개인 PGPROC 구조에 최대 16개의 슬롯(기본값
FP_LOCK_SLOTS_PER_BACKEND = 16)을 할당합니다. - 빠른 경로 적격성 확인 – SELECT * FROM my_table;을 실행할 때, PostgreSQL은 작은 백엔드별 LWLock(MyProc→fpInfoLock)을 획득하여 현재 SQL 쿼리에 빠른 경로 잠금 메커니즘을 사용할 수 있는지 확인합니다. 다음 사항들을 검증합니다:
- 락 모드가 적격한 약한 모드인지
- 다른 세션이 충돌하는 락을 보유하고 있지 않은지
- 백엔드가 이미 로컬 백엔드 메모리 배열의 16개 슬롯을 모두 사용하지 않았는지
- 로컬 부여 – 위의 빠른 경로 적격성 확인을 통과하면, FastPathGrantRelationLock()이 백엔드의 로컬 캐시에 락을 저장합니다. 공유 메모리 락 해시 테이블을 보호하는 공유 메모리 기반 LWLock은 획득되지 않으며, 함수는 즉시 성공을 반환합니다.
실제로, 이는 트랜잭션이 처음 접근하는 16개의 고유 테이블(또는 인덱스)에 대해 거의 0에 가까운 락 관리자 오버헤드가 발생한다는 것을 의미합니다.
빠른 경로 캐시는 작으며, 16개의 락을 초과하거나 더 강한 락 모드를 요청할 때 PostgreSQL은 느린 경로로 전환해야 합니다:
- 이미 획득한 16개의 빠른 경로 락을 초과하는 모든 빠른 경로 락 요청은 FastPathTransferRelationLocks()를 사용하여 공유 락 테이블로 마이그레이션됩니다.
- 락 태그(릴레이션 OID와 락 모드 포함)는 공유 메모리 락 해시 테이블의 16개 락 파티션 중 하나로 해시됩니다.
- PostgreSQL은 파티션 LWLock(LWLockAcquire(partitionLock, LW_EXCLUSIVE))을 획득하고, 공유 해시 테이블을 업데이트한 다음, LWLock을 해제합니다.
- 그 시점부터 테이블부터 인덱스까지 추가적인 락 획득은 락 관리자를 통해 이루어지며, 동시성 상황에서 LWLock:LockManager 대기 이벤트가 발생합니다.
빠른 경로 최적화에서 느린 경로 경합으로의 전환을 이해함으로써, 락 관리자 병목 현상을 완전히 피하면서 빠른 경로 제한 내에서 유지되는 쿼리와 스키마를 설계할 수 있습니다.
솔루션 개요
다음 섹션에서는 세 가지 실험을 통해 LWLock 경합을 자세히 설명합니다.
- 파티션된 테이블에서의 락 관찰
- 사용하지 않거나 불필요한 여러 인덱스가 있는 비파티션 테이블에서의 락 관찰
- 다중 조인 쿼리에서의 잠금 동작 관찰
각각의 실험은 스키마 설정, 워크로드 실행, PostgreSQL 시스템 뷰를 통한 락 모니터링, 그리고 pgbench를 통한 동시성 영향 분석 방법을 보여줍니다. 모든 예제는 Aurora PostgreSQL-Compatible(PostgreSQL 16.6와 호환) db.r7g.4xlarge 인스턴스에서 수행되었습니다.
전제 조건
시작하기 전에 다음 사항들이 준비되어 있는지 확인하세요.
- Aurora PostgreSQL-Compatible 데이터베이스에 접근 가능한 AWS 계정
- AWS Management Console에 대한 접근 권한
- Aurora PostgreSQL 인스턴스에 연결 가능한 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스
- Amazon EC2 인스턴스에 설치된 PostgreSQL 클라이언트(예. psql)
- Amazon EC2 인스턴스에 설치된 pgbench
- Aurora PostgreSQL 클러스터를 생성하고 관리할 수 있는 AWS Identity and Access Management(IAM) 권한
실험 1: 파티션된 테이블에서의 락 관찰
이 실험에서는 파티션된 테이블 작업 시 PostgreSQL의 잠금 동작을 세 가지 주요 테스트 시나리오를 통해 조사합니다.
- 먼저, PostgreSQL이 전체 파티션 세트에 걸쳐 락을 어떻게 처리하는지 관찰하기 위해
orders테이블의 모든 파티션을 쿼리합니다. - 그런 다음, 특정 파티션에 접근하기 위해 파티션 프루닝을 사용하는 더 타겟팅된 접근 방식을 검토합니다.
- 마지막으로, pgbench를 사용하여 실제 워크로드를 시뮬레이션하면서 높은 동시성 하에서 두 접근 방식 모두를 스트레스 테스트합니다.
이러한 쿼리들을 통해, PostgreSQL의 빠른 경로 락 최적화가 어떻게 동작하는지, 빠른 경로 슬롯이 소진되었을 때 어떤 일이 발생하는지, 그리고 파티션 프루닝이 동시성이 높은 워크로드에서 성능을 어떻게 크게 향상시킬 수 있는지 보여줍니다. 여기서는 order_ts 타임스탬프 컬럼을 사용하여 월별로 데이터가 파티션된 orders 테이블을 사용합니다.
이 실험은 다음에 대한 중요한 통찰력을 보여줄 것입니다.
- PostgreSQL이 읽기 전용 작업 중에 락을 관리하는 방법
- 빠른 경로 vs 느린 경로 락의 영향
- 파티션 프루닝을 통해 락 경합을 줄이는 방법
- 높은 동시성 환경에서의 성능 영향
스키마 준비하기
12개의 월별 자식 파티션이 있는 파티션된 orders 테이블을 생성합니다. 다음 SQL 코드를 실행하세요.
-- Create the schema
CREATE SCHEMA experiment_1;
SET search_path TO experiment_1;
-- Create the partitioned parent table
CREATE TABLE orders (
id int NOT NULL,
order_ts timestamp NOT NULL,
customer_id int,
amount numeric,
PRIMARY KEY (id, order_ts)
) PARTITION BY RANGE (order_ts);
-- Create child partitions (example: Jan 2025 - Jun 2025)
DO $
DECLARE
month int := 1;
partition_name text;
from_date date;
to_date date;
BEGIN
WHILE month <= 12 LOOP
partition_name := 'orders_2025_' || to_char(month, 'FM00');
from_date := make_date(2025, month, 1);
to_date := from_date + interval '1 month';
EXECUTE format(
'CREATE TABLE %I.%I PARTITION OF %I.%I FOR VALUES FROM (%L) TO (%L)',
'experiment_1', partition_name,
'experiment_1', 'orders',
from_date, to_date
);
month := month + 1;
END LOOP;
END $;
Test 1: orders 테이블의 모든 파티션을 쿼리하여 잠금 동작 관찰하기
이제 트랜잭션을 시작하고 파티션된 orders 테이블의 모든 파티션(프루닝되지 않은 파티션)을 쿼리합니다. 파티션 프루닝 없이 쿼리할 때 PostgreSQL은 모든 파티션에 접근해야 하며, 이는 락 오버헤드를 크게 증가시킵니다. 이 테스트를 시작하려면, Aurora PostgreSQL 데이터베이스에 새로운 커넥션을 열고 다음 명령어를 실행하세요(이를 세션 1이라고 부르겠습니다).
postgres=> set search_path to experiment_1;
SET
postgres=> begin;
BEGIN
postgres=*=> select count(*) from orders;
count
-------
0
(1 row)
위의 SQL 문은 12개의 모든 파티션을 스캔하는 트랜잭션을 시작할 것입니다. COMMIT, ROLLBACK 또는 End 명령어를 실행하지 않고, 락을 유지하기 위해 트랜잭션을 열어두겠습니다.
세션 1의 트랜잭션이 열려있는 동안, 두 번째 세션을 열고(이를 세션 2라고 부르겠습니다) 데이터베이스의 락 상태를 확인하기 위해 다음 SQL 쿼리를 실행하세요.
postgres=> SELECT
n.nspname AS schema,
c.relname AS table,
l.locktype,
l.mode,
l.fastpath
FROM pg_locks l
JOIN pg_class c ON l.relation = c.oid
JOIN pg_namespace n ON c.relnamespace = n.oid
AND n.nspname 'pg_catalog';
schema | table | locktype | mode | fastpath
--------------+---------------------+----------+-----------------+----------
experiment_1 | orders_2025_07_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_07 | relation | AccessShareLock | t
experiment_1 | orders_2025_06_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_06 | relation | AccessShareLock | t
experiment_1 | orders_2025_05_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_05 | relation | AccessShareLock | t
experiment_1 | orders_2025_04_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_04 | relation | AccessShareLock | t
experiment_1 | orders_2025_03_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_03 | relation | AccessShareLock | t
experiment_1 | orders_2025_02_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_02 | relation | AccessShareLock | t
experiment_1 | orders_2025_01_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_01 | relation | AccessShareLock | t
experiment_1 | orders_pkey | relation | AccessShareLock | t
experiment_1 | orders | relation | AccessShareLock | t
experiment_1 | orders_2025_11 | relation | AccessShareLock | f
experiment_1 | orders_2025_09 | relation | AccessShareLock | f
experiment_1 | orders_2025_09_pkey | relation | AccessShareLock | f
experiment_1 | orders_2025_11_pkey | relation | AccessShareLock | f
experiment_1 | orders_2025_08_pkey | relation | AccessShareLock | f
experiment_1 | orders_2025_10 | relation | AccessShareLock | f
experiment_1 | orders_2025_08 | relation | AccessShareLock | f
experiment_1 | orders_2025_10_pkey | relation | AccessShareLock | f
experiment_1 | orders_2025_12_pkey | relation | AccessShareLock | f
experiment_1 | orders_2025_12 | relation | AccessShareLock | f
(26 rows)
위의 결과에서 fastpath 컬럼의 값 t(True)와 f(False)를 보면, 반환된 총 행 수는 26개 중 마지막 10개 행의 값이 f인 것에 주목하세요. 값 t가 16개 행으로 나타난 것은 16개의 빠른 경로 슬롯이 소진되었음을 의미하며, 나머지 10개의 파티션/인덱스 AccessShareLock은 공유 메모리 락 해시 테이블(느린 경로)로 이전되었음을 의미합니다. 트랜잭션이 완료되면 락들은 해제될 것입니다.
Test 2: 파티션 프루닝을 사용하여 orders 테이블의 특정 파티션 쿼리하고 잠금 동작의 변화 관찰하기
이전 테스트(Test 1)의 세션 1에서 아래와 같이 새로운 트랜잭션 내에서 파티션 프루닝 접근 방식을 사용하는 쿼리를 실행하세요. 더 많은 파티션을 터치하면, 연속적으로 빠른 경로 락이 획득될 것입니다.
postgres=> set search_path to experiment_1;
SET
postgres=> begin;
BEGIN
postgres=*> SELECT * FROM orders WHERE order_ts <= '2025-01-01';
id | order_ts | customer_id | amount
----+----------+-------------+--------
(0 rows)
postgres=*> SELECT * FROM orders WHERE order_ts <= '2025-02-01';
id | order_ts | customer_id | amount
----+----------+-------------+--------
(0 rows)
postgres=*> SELECT * FROM orders WHERE order_ts <= '2025-03-01';
id | order_ts | customer_id | amount
----+----------+-------------+--------
(0 rows)세션 1의 트랜잭션이 열려있는 동안, 이전 테스트에서 생성한 세션 2에서 다음 SQL 문을 실행하여 데이터베이스의 락 상태를 확인하세요.
postgres=> SELECT
n.nspname AS schema,
c.relname AS table,
l.locktype,
l.mode,
l.fastpath
FROM pg_locks l
JOIN pg_class c ON l.relation = c.oid
JOIN pg_namespace n ON c.relnamespace = n.oid
AND n.nspname <> 'pg_catalog';
schema | table | locktype | mode | fastpath
--------------+---------------------+----------+-----------------+----------
experiment_1 | orders_2025_03_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_03 | relation | AccessShareLock | t
experiment_1 | orders_2025_02_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_02 | relation | AccessShareLock | t
experiment_1 | orders_2025_01_pkey | relation | AccessShareLock | t
experiment_1 | orders_2025_01 | relation | AccessShareLock | t
experiment_1 | orders_pkey | relation | AccessShareLock | t
experiment_1 | orders | relation | AccessShareLock | t
(8 rows)위의 결과에서 모든 fastpath 컬럼의 값이 t(True)로 표시된 것을 통해 모든 락이 빠른 경로 락임을 알 수 있으며, 이는 느린 경로 락을 획득할 필요가 없었음을 보여줍니다.
이 테스트는 빠른 경로 최적화를 보여주지만, 각 백엔드 프로세스가 빠른 경로 슬롯을 모두 소진하거나 16개 슬롯 제한 내에 머무르는 동시성과 관련된 시나리오를 설명하지는 않습니다. 이 특정 시나리오를 자세히 살펴보겠습니다. 다중 사용자 워크로드를 시뮬레이션하기 위해 pgbench를 사용할 것입니다.
Test 3-1: 높은 동시성 하에서 orders 테이블의 모든 파티션을 쿼리하여 잠금 동작의 변화 관찰하기
프루닝되지 않은 파티션에 접근하는 높은 동시성 읽기 워크로드를 시뮬레이션하기 위해 다음 pgbench 명령을 사용하세요. 이 명령어는 여러 스레드에 걸쳐 SELECT count(*) FROM orders 쿼리를 지속적으로 실행합니다. 이 테스트에서는 트랜잭션이 빠른 경로 슬롯을 소진하여 메인 락 관리자를 통한 락 획득을 강제할 때(LWLock:LockManager 대기를 유발), 높은 동시성 하에서 PostgreSQL의 빠른 경로 락 최적화가 어떻게 동작하는지 보여줍니다.
pgbench -c 100 -j 10 -n -f transaction.sql -T 900
pgbench에서 -c와 -j 옵션은 벤치마크 워크로드의 동시성과 병렬성을 제어하는 데 사용됩니다. -c 옵션은 동시 클라이언트 수를 지정하며, 이는 얼마나 많은 사용자 세션 또는 데이터베이스 연결이 동시에 활성화될 것인지를 의미합니다. 이 숫자는 PostgreSQL 데이터베이스에 적용되는 부하 수준을 결정하게 됩니다. -j 옵션은 pgbench가 이러한 클라이언트 연결을 관리하는 데 사용하는 작업자 스레드(worker threads)의 수를 정의합니다. 각 스레드는 전체 클라이언트의 일부를 처리하며, 워크로드는 스레드 간에 균등하게 분산되어 pgbench가 멀티코어 시스템을 더 잘 활용하고 클라이언트 측의 병목 현상을 피할 수 있게 합니다.
런타임에 자격 증명을 입력하지 않고 pgbench 명령어를 실행하기 위해 다음과 같은 환경 변수를 설정할 수 있습니다.
- PGHOST: Aurora 클러스터 엔드포인트
- PGPORT: 포트 번호(예: 5432)
- PGDATABASE: 데이터베이스 이름(예: postgres)
- PGUSER: 데이터베이스 사용자
- PGPASSWORD: 데이터베이스 사용자 비밀번호
앞의 쿼리는 transaction.sql에 정의된 트랜잭션을 실행하는 100개의 동시 클라이언트(-c 100)를 15분 또는 900초(-T 900) 동안 시뮬레이션합니다.
transaction.sql 파일은 experiment_1 스키마로의 검색 경로 설정과 함께 다음 SQL을 포함합니다.
set search_path to experiment_1;
DO $$
DECLARE
random_date date;
last_day date;
sql text;
BEGIN
random_date := date '2025-01-01' + floor(random() * 365)::int;
last_day := (date_trunc('month', random_date) + interval '1 month - 1 day')::date;
sql := format('SELECT COUNT(*) FROM orders');
EXECUTE sql;
END $$;이전 테스트의 세션 1 터미널에서 다음 pgbench 명령어를 실행하십시오. 이 명령어는 15분 안에 테스트를 완료할 것입니다. 이 명령어가 실행되는 동안, Amazon CloudWatch Database Insights에서 데이터베이스 대기 이벤트를 모니터링할 수 있습니다.
sh-5.1$ pgbench -c 100 -j 10 -n -f transaction.sql -T 900
transaction type: transaction.sql
scaling factor: 1
query mode: simple
number of clients: 100
number of threads: 10
duration: 900 s
number of transactions actually processed: 42005251
latency average = 2.143 ms
tps = 46672.159856 (including connections establishing)
tps = 46672.894164 (excluding connections establishing)이 워크로드에서 달성한 평균 초당 트랜잭션(tps)은 46,672였으며, 15분의 테스트 시간 동안 4200만 건의 트랜잭션이 처리되었습니다.
다음 CloudWatch Database Insights의 스크린샷은 활성 세션이 인스턴스의 vCPU 용량을 초과하고, 상당한 락 경합이 발생하면서 데이터베이스가 높은 부하를 경험하고 있음을 보여줍니다.
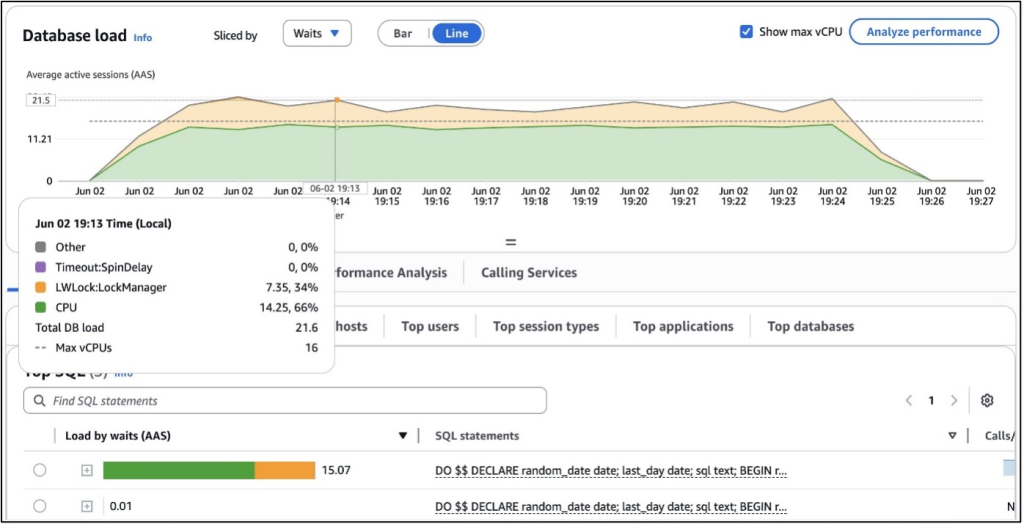
이 스크린샷은 db.r7g.4xlarge 인스턴스를 실행 중인 Aurora PostgreSQL 16.6 클러스터에서 CPU 사용률과 락 경합 모두에 의해 발생하는 높은 데이터베이스 부하를 보여줍니다. 평균 활성 세션(AAS)은 약 21로 유지되었는데, 이는 인스턴스의 16 vCPU 용량보다 높은 수치입니다. 부하의 66퍼센트가 CPU 사용률에 기인했지만, 상당한 비중인 34퍼센트가 LWLock:LockManager에서 대기하는 데 소요되었으며, 이는 PostgreSQL 내부 락 구조에 대한 경합이 있음을 나타냅니다.
다음으로, 파티션 프루닝 방식을 사용하여 성능을 평가해보겠습니다.
Test 3-2: 높은 동시성 하에서 파티션 프루닝을 통해 orders 테이블의 특정 파티션을 쿼리하기
프루닝되지 않은 파티션을 사용한 이전 테스트와의 대조를 위해, 파티션 프루닝이 어떻게 성능을 크게 향상시킬 수 있는지 살펴보겠습니다. 이 실험에 사용된 transaction.sql 파일은 PL/pgSQL을 포함하고 있는데, 이는 단순 SQL 쿼리 대신 파티션된 테이블과 런타임 생성 값을 다룰 때 PostgreSQL에서 효율적인 파티션 프루닝을 제공하기 위해 사용됩니다. 다음 쿼리와 같이 SQL을 사용할 수도 있지만, order_ts에 대한 필터가 공통 테이블 표현식(CTE) 내에서 무작위로 생성된 날짜에서 파생되므로, 최적의 실행 계획을 생성하는 쿼리 플래너가 쿼리 계획 시점에 order_ts 값을 결정할 수 없습니다. 결과적으로 PostgreSQL은 모든 파티션을 고려해야 하며, 이는 모든 파티션의 불필요한 잠금과 스캔으로 이어집니다. 하지만 무작위 날짜를 계산하고 EXECUTE를 사용하여 동적으로 쿼리를 구성하는 PL/pgSQL 블록으로 전환함으로써, 실제 날짜 값이 SQL 문자열에 직접 주입됩니다. 이는 쿼리 플래너의 관점에서 필터를 상수로 변환하여, 효과적인 파티션 프루닝을 가능하게 하고 관련된 파티션만 접근되고 잠기도록 보장합니다.
다음은 위에서 설명한 것과 같이 모든 파티션에 대한 락이 필요한 CTE 기반 SQL 쿼리입니다.
WITH rand_date AS (
SELECT (date '2025-01-01' + (floor(random() * 365))::int) AS dt
),
last_day AS (
SELECT
dt,
(date_trunc('month', dt) + interval '1 month - 1 day')::date AS last_day
FROM rand_date
)
SELECT
dt AS random_date,
last_day,
(
SELECT COUNT(*)
FROM orders
WHERE order_ts >= last_day.last_day
AND order_ts < last_day.last_day + interval '1 day'
) AS order_count
FROM last_day;위에서 설명한 대로, 효과적인 파티션 프루닝을 사용하기 위해서는 PL/pgSQL 접근 방식을 사용하는 다음 SQL을 수행하세요.
set search_path to experiment_1;
DO $$
DECLARE
random_date date;
last_day date;
sql text;
BEGIN
random_date := date '2025-01-01' + (floor(random() * 365))::int;
last_day := (date_trunc('month', random_date) + interval '1 month - 1 day')::date;
sql := format('SELECT count(*) FROM orders WHERE order_ts = %L', last_day);
EXECUTE sql;이전 테스트와 동일한 단계를 따라 세션 1 터미널에서 pgbench 명령어를 실행하세요. 이 명령어는 15분 안에 테스트를 완료할 것이며, 명령어가 실행되는 동안 CloudWatch Database Insights에서 데이터베이스 대기 이벤트를 모니터링할 수 있습니다.
sh-5.15 pgbench -c 100 -j 10 -n -f transaction.sql -T 900
transaction type: transaction.sql
scaling factor: 1
query mode: simple
number of clients: 100
number of threads: 10
duration: 900 s
number of transactions actually processed: 53240775
latency average = 1.690 ms
tps = 59255.673468 (including connections establishing)
tps = 59156.616479 (excluding connections establishing)pgbench 출력에서 볼 수 있듯, 워크로드는 초당 평균 59,255 트랜잭션을 달성했으며 15분의 테스트 기간 동안 약 5330만 건의 트랜잭션이 처리되었습니다. 락 경합이 없는 상태에서 시스템은 1100만 건의 추가 트랜잭션을 처리했습니다.
CloudWatch Database Insights의 스크린샷은 파티션 프루닝을 구현한 후 데이터베이스 성능이 향상되었음을 보여주며, 안정적인 부하 패턴과 락 경합이 없는 상태를 나타냅니다.
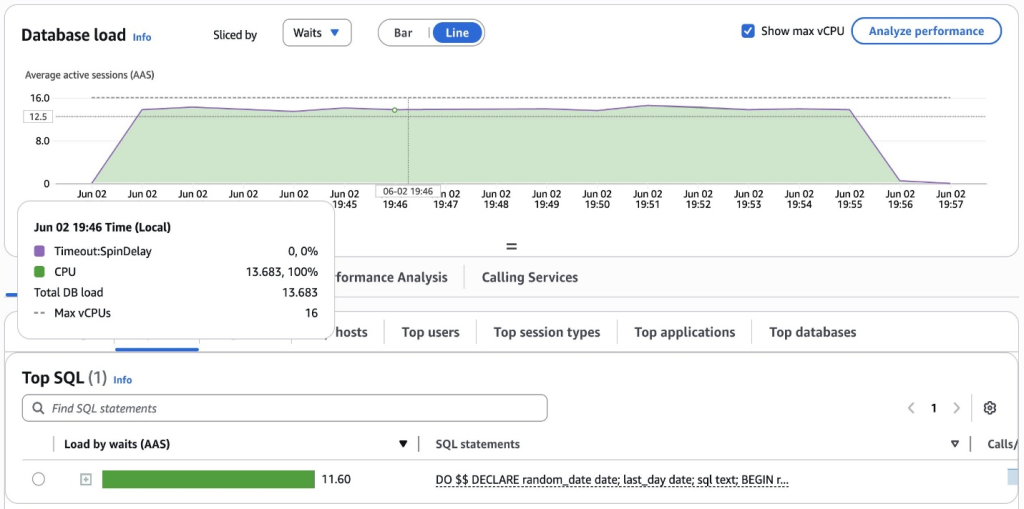
파티션 프루닝을 도입한 후, Aurora PostgreSQL 16.6 클러스터의 성능이 크게 개선되었습니다. 이전에는 워크로드가 CPU 사용률과 함께 LWLock:LockManager 대기 이벤트가 데이터베이스 부하의 거의 34%를 차지했습니다.
이전 테스트와는 대조적으로, 현재는 균형 잡힌 워크로드를 보여줍니다: 평균 활성 세션(AAS)이 Max vCPU 임계값(16) 아래로 유지되고 있으며, 대기는 최소화되어 있습니다 – Timeout:SpinDelay의 작은 부분만 관찰됩니다. 이제 최적화된 OLTP 시스템에서 볼 수 있는 것처럼 CPU가 부하의 주된 부분을 차지하며, 락 경합이 크게 감소했습니다. 이는 파티션 프루닝을 통해 획득이 필요한 락의 수를 성공적으로 줄였음을 의미하며, 각 세션이 관련 파티션에만 접근하고 세션당 빠른 경로 락을 제한하여 동시성을 크게 개선했음을 의미합니다. 파티션 프루닝을 통해 AAS는 Max vCPU 임계값(16) 아래로 유지되었습니다.
실험2: 여러 개의 사용되지 않거나 불필요한 인덱스가 있는 비파티션 테이블에서 락 관찰하기
이 실험에서는 PostgreSQL이 여러 B-tree 인덱스가 있는 비파티션 테이블에서 잠금 동작을 어떻게 처리하는지 검토합니다. 여기서는 사용되지 않거나 불필요한 인덱스가 존재할 때의 영향에 초점을 맞추기 위해 비파티션 테이블을 사용합니다. 전자상거래 또는 재고 시스템을 나타내는 items 테이블을 사용하여 두 가지 주요 테스트 시나리오를 살펴보겠습니다.
- 먼저, 인덱스 전용 스캔을 사용하는 간단한 쿼리를 수행하여 다음을 관찰합니다.
- PostgreSQL이 사용되지 않거나 불필요한 여러 인덱스에 걸쳐 락을 관리하는 방법
- 빠른 경로 슬롯이 소진되었을 때 발생하는 일
- 20개의 B-tree 인덱스를 가지는 것이 락 획득에 미치는 영향
- 그런 다음, 높은 동시성 하에서 시스템을 스트레스 테스트하여 다음을 보여줍니다.
- 과도한 인덱스가 락 관리자 동작에 미치는 영향
- 여러 인덱스가 있을 때 락 경합이 성능에 미치는 영향
- 인덱스 수와 LWLock:LockManager 대기 사이의 관계
이러한 테스트를 통해 인덱스 관련 락 오버헤드에 대한 중요한 통찰력을 얻고. 높은 동시성 환경에서의 인덱스 관리에 대한 실용적인 지침을 제공합니다.
스키마 준비하기
Aurora PostgreSQL 데이터베이스에서 items 테이블 스키마와 관련 인덱스를 생성하려면 다음 SQL 코드를 사용하세요.
-- Create Schema
CREATE SCHEMA IF NOT EXISTS experiment_2;
SET search_path TO experiment_2;
CREATE TABLE items (
item_id SERIAL PRIMARY KEY, sku TEXT NOT NULL, barcode TEXT, name TEXT NOT NULL,
description TEXT,category TEXT, subcategory TEXT, vendor_id INT,
vendor_region TEXT, brand TEXT, model TEXT,price NUMERIC(10,2),
cost NUMERIC(10,2), discount NUMERIC(5,2), margin NUMERIC(5,2),
quantity_in_stock INT, reorder_level INT, lead_time_days INT, rating NUMERIC(2,1)
,num_reviews INT, available BOOLEAN DEFAULT true, warehouse_location TEXT,
is_active BOOLEAN DEFAULT true,last_restocked TIMESTAMP,
created_at TIMESTAMP DEFAULT now(), updated_at TIMESTAMP DEFAULT now()
);
CREATE INDEX idx_items_sku ON items(sku);
CREATE INDEX idx_items_barcode ON items(barcode);
CREATE INDEX idx_items_name ON items(name);
CREATE INDEX idx_items_category ON items(category);
CREATE INDEX idx_items_vendor_id ON items(vendor_id);
CREATE INDEX idx_items_brand ON items(brand);
CREATE INDEX idx_items_model ON items(model);
CREATE INDEX idx_items_price ON items(price);
CREATE INDEX idx_items_cost ON items(cost);
CREATE INDEX idx_items_quantity ON items(quantity_in_stock);
CREATE INDEX idx_items_rating ON items(rating);
CREATE INDEX idx_items_num_reviews ON items(num_reviews);
CREATE INDEX idx_items_created_at ON items(created_at);
CREATE INDEX idx_items_updated_at ON items(updated_at);
CREATE INDEX idx_items_vendor_category ON items(vendor_id, category);
CREATE INDEX idx_items_sku_available ON items(sku, available);
CREATE INDEX idx_items_barcode_active ON items(barcode, is_active);
CREATE INDEX idx_items_category_subcategory_price ON items(category, subcategory,
price);
CREATE INDEX idx_items_vendor_region_brand ON items(vendor_region, brand);
CREATE INDEX idx_items_brand_model ON items(brand, model);위의 SQL 코드는 제품 세부 정보(예: SKU, 가격, 재고)를 위한 26개의 컬럼과 자주 조회되는 컬럼 및 컬럼 조합에 대한 20개의 B-tree 인덱스가 있는 전자상거래 items 테이블을 생성합니다.
Test 1: 여러 인덱스가 있는 비파티션 테이블 쿼리하기
과도한 인덱스가 PostgreSQL의 잠금 동작에 미치는 영향을 검토하기 위해, items 테이블을 쿼리하며 첫 번째 테스트를 수행해 보겠습니다. 대부분의 인덱스가 이 쿼리에 불필요함에도 PostgreSQL이 20개의 모든 인덱스에 걸쳐 락을 관리하는 방법을 관찰하기 위해, 이름을 조회하는 간단한 쿼리를 실행할 것입니다. 이는 과도한 인덱스로 인해 발생하는 기본적인 잠금 오버헤드를 이해하는 데 도움이 될 것입니다. 인덱스 접근 경로를 사용하여 items 테이블의 특정 컬럼을 쿼리하는 트랜잭션을 시작하세요.
postgres=> set search_path to experiment_2;
SET
postgres=> EXPLAIN SELECT name FROM items WHERE name = 'test';
QUERY PLAN
----------------------------------------------------------------
Index Only Scan using idx_items_name on items (cost=0.14..8.16 rows=1 width=32)
Index Cond: (name = 'test'::text)
(2 rows)
postgres=> BEGIN;
BEGIN
postgres=> SELECT name FROM items WHERE name = 'test';
name
------
(0 rows)위의 SQL 쿼리에서 쿼리 플래너는 Index Only Scan 경로를 선택했습니다. items 테이블에서 name 컬럼만 조회하고 있습니다. 이제 다른 세션에서 잠금 동작을 관찰하겠습니다.
다른 세션에서 SQL 쿼리를 실행한 후, 아래 출력에서 items 테이블, 기본 키, 그리고 쿼리 실행을 위해 플래너가 사용한 인덱스(idx_items_name) 외에, AccessShareLock을 획득한 다른 인덱스들을 주목하세요. 반환된 총 행 수는 22개이며, 빠른 경로 슬롯이 소진되었고, 6개의 락이 공유 메모리 락 테이블로 이동되었습니다. 이 테이블에 더 많은 인덱스가 있었다면 그 인덱스들도 AccessShareLock이 필요했을 것이며, 빠른 경로 슬롯이 소진되었기 때문에 공유 메모리 락 테이블에 배치되었을 것입니다. 이렇게 되면, 테이블에 대한 높은 동시성을 갖는 워크로드가 수행되는 동안 공유 메모리 락 테이블에서 생성된 경합으로 인해 성능이 저하될 것입니다.
postgres=> SELECT
n.nspname AS schema,
c.relname AS table,
l.locktype,
l.mode,
l.fastpath
FROM pg_locks l
JOIN pg_class c ON l.relation = c.oid
JOIN pg_namespace n ON c.relnamespace = n.oid
AND n.nspname <> 'pg_catalog';
schema | table | locktype | mode | fastpath
--------------+--------------------------------------+----------+-----------------+----------
experiment_2 | idx_items_updated_at | relation | AccessShareLock | t
experiment_2 | idx_items_created_at | relation | AccessShareLock | t
experiment_2 | idx_items_num_reviews | relation | AccessShareLock | t
experiment_2 | idx_items_rating | relation | AccessShareLock | t
experiment_2 | idx_items_quantity | relation | AccessShareLock | t
experiment_2 | idx_items_cost | relation | AccessShareLock | t
experiment_2 | idx_items_price | relation | AccessShareLock | t
experiment_2 | idx_items_model | relation | AccessShareLock | t
experiment_2 | idx_items_brand | relation | AccessShareLock | t
experiment_2 | idx_items_vendor_id | relation | AccessShareLock | t
experiment_2 | idx_items_category | relation | AccessShareLock | t
experiment_2 | idx_items_name | relation | AccessShareLock | t
experiment_2 | idx_items_barcode | relation | AccessShareLock | t
experiment_2 | idx_items_sku | relation | AccessShareLock | t
experiment_2 | items_pkey | relation | AccessShareLock | t
experiment_2 | items | relation | AccessShareLock | t
experiment_2 | idx_items_vendor_region_brand | relation | AccessShareLock | f
experiment_2 | idx_items_brand_model | relation | AccessShareLock | f
experiment_2 | idx_items_vendor_category | relation | AccessShareLock | f
experiment_2 | idx_items_barcode_active | relation | AccessShareLock | f
experiment_2 | idx_items_sku_available | relation | AccessShareLock | f
experiment_2 | idx_items_category_subcategory_price | relation | AccessShareLock | f
(22 rows)Test 2: 높은 동시성 하에서 여러 인덱스가 있는 비파티션 테이블 쿼리하기
불필요한 인덱스가 성능에 어떤 영향을 미치는지 이해하기 위해, 높은 동시성 하에서 비파티션 테이블 items 에 대한 스트레스 테스트를 해보겠습니다. 이전의 파티션된 테이블 실험(실험 1)과 마찬가지로, pgbench를 사용하여 여러 사용자가 테이블에 동시에 접근하는 것을 시뮬레이션합니다.
첫 번째 실험에서 사용한 것과 동일한 pgbench 명령어를 사용하여, 세션 1 터미널에서 다음을 실행하십시오. 이 테스트는 5분 동안 실행될 것입니다. 테스트가 실행되는 동안 CloudWatch Database Insights에서 데이터베이스 대기 이벤트를 모니터링할 수 있습니다.
pgbench -c 100 -j 10 -n -f transaction.sql -T 300transaction.sql 파일에는 위의 이전 테스트와 같이 items 테이블에서 이름을 조회하는 SQL 쿼리가 포함되어 있습니다.
CloudWatch Database Insights의 다음 스크린샷은 items 테이블의 과도한 인덱스가 어떻게 상당한 LWLock:LockManager 대기를 발생시키고, 이로 인해 데이터베이스 부하와 CPU 사용률이 증가하는지를 보여줍니다.
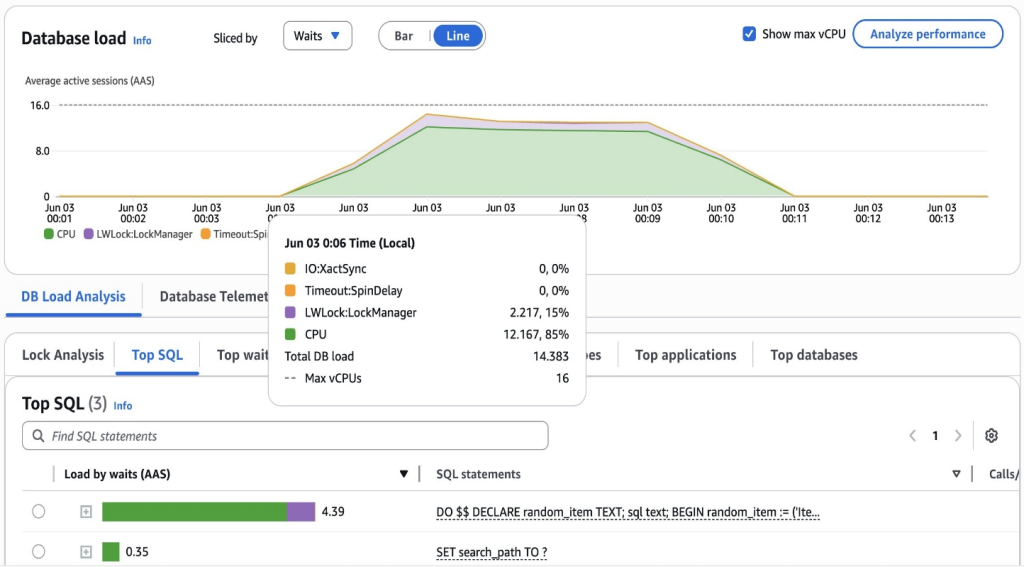
여기서 관찰된 LWLock:LockManager 대기는 주로 items 테이블에 있는 과도한 수의 인덱스로 인해 발생합니다. 데이터가 없더라도 PostgreSQL은 모든 20개의 인덱스를 검사하고, 관련 락을 획득하며, 카탈로그 메타데이터에 접근해야 하기 때문에 쿼리 계획 및 실행 중에 오버헤드가 발생합니다. 높은 동시성으로 인해 많은 수의 락이 관여되었고, 데이터베이스 세션이 빠른 경로 락을 소진하여 백엔드 프로세스가 메인 락 관리자로 대체되도록 강제되었으며, 이는 추가적인 경합을 초래했습니다. 반복적인 카탈로그 스캔으로 CPU 사용량이 증가했으며, 락 획득 오버헤드로 데이터베이스 부하가 증가했습니다. 불필요한 인덱스의 수를 줄이면 쿼리 계획 복잡성을 감소시킬 뿐만 아니라 빠른 경로 잠금을 유지하는 데 도움이 되어, 높은 동시성 워크로드에서 시스템 효율성이 향상될 것입니다.
실험3: 다중 조인이 있는 쿼리에서의 잠금 동작 관찰하기
이 실험에서는 PostgreSQL이 여러 관련 테이블에 걸친 복잡한 쿼리를 실행할 때 락을 어떻게 관리하는지 조사합니다. 두 가지 주요 테스트 시나리오를 탐구하기 위해 실제 전자상거래 데이터베이스 스키마를 사용할 것입니다.
1. 먼저, 다음과 같은 단일 다중 조인 쿼리를 검토합니다.
-
- 단일 읽기 전용 작업에서 사용자의 장바구니 내용, 상품 가격, 주문 상태 및 결제 세부 정보를 검색합니다.
- 6개의 상호 연관된 테이블(
users,carts,cart_items,items,orders,payments)에 연결합니다. - PostgreSQL이 여러 테이블과 그들의 인덱스에 걸쳐 락을 어떻게 처리하는지 확인합니다.
이 쿼리는 여러 테이블 조인이 누적된 락 공간에 어떤 영향을 미치는지 관찰할 수 있는 기회를 제공합니다. 각 테이블은 자체 기본 키와 외래 키 인덱스를 가지고 있기 때문에, PostgreSQL은 이러한 단순 읽기에 대해 빠른 경로 락을 사용할 수 있어 공유 메모리 락 테이블에 항목을 획득하는 오버헤드를 피할 수 있습니다.
2. 그런 다음, 높은 동시성 하에서 시스템을 스트레스 테스트하여 다음과 같은 내용을 확인합니다.
-
- 복잡한 조인을 실행하는 여러 세션이 락 관리에 어떤 영향을 미치는지 관찰합니다.
- 여러 인덱스된 테이블에 걸친 락 획득의 성능 영향을 측정합니다.
- 조인 복잡성이 CPU 사용률과 락 경합 모두에 어떤 영향을 미치는지 보여줍니다.
이러한 테스트를 통해 다음에 대한 중요한 통찰력을 얻을 수 있습니다.
- 복잡하고 상호 연결된 테이블 구조에서의 락 관리
- 테이블 조인, 인덱스, 락 오버헤드 간의 관계
- 높은 동시성 환경에서 다중 조인 쿼리에 대한 성능 고려 사항
스키마 준비하기
6개의 상호 연결된 테이블(users, carts, cart_items, items, orders, payments)과 관련 인덱스 및 외래 키 제약 조건을 포함하는 전자상거래 스키마를 생성하려면 다음 SQL 코드를 사용하십시오. 이 스키마는 테이블당 여러 인덱스와 적절한 참조 무결성 제약 조건을 포함하여 실제 전자상거래 데이터베이스를 시뮬레이션하기 위해 의도적으로 포괄적으로 유지됩니다.
-- Create Schema
CREATE SCHEMA IF NOT EXISTS experiment_3;
SET search_path TO experiment_3;
-- USERS table
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
phone TEXT,
role TEXT DEFAULT 'customer',
is_active BOOLEAN DEFAULT TRUE,
is_deleted BOOLEAN DEFAULT FALSE,
created_by INT,
updated_by INT,
created_at TIMESTAMP DEFAULT now(),
updated_at TIMESTAMP DEFAULT now(),
deleted_at TIMESTAMP
);
-- Indexes for USERS
CREATE INDEX idx_users_name_created_at ON users(name, created_at);
CREATE INDEX idx_users_email_active ON users(email, is_active);
CREATE INDEX idx_users_role_active ON users(role, is_active);
CREATE INDEX idx_users_created_at ON users(created_at);
-- ITEMS table
CREATE TABLE items (
item_id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
sku TEXT UNIQUE,
category TEXT,
price NUMERIC(10,2) NOT NULL,
discount NUMERIC(5,2) DEFAULT 0.00,
stock_quantity INT NOT NULL,
restock_threshold INT DEFAULT 10,
is_active BOOLEAN DEFAULT TRUE,
is_deleted BOOLEAN DEFAULT FALSE,
created_by INT,
updated_by INT,
created_at TIMESTAMP DEFAULT now(),
updated_at TIMESTAMP DEFAULT now(),
deleted_at TIMESTAMP
);
-- Indexes for ITEMS
CREATE INDEX idx_items_price_stock ON items(price, stock_quantity);
CREATE INDEX idx_items_category_active ON items(category, is_active);
CREATE INDEX idx_items_name_price ON items(name, price);
CREATE INDEX idx_items_created_at ON items(created_at);
-- CARTS table
CREATE TABLE carts (
cart_id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(user_id) ON DELETE CASCADE,
status TEXT DEFAULT 'open',
is_deleted BOOLEAN DEFAULT FALSE,
expires_at TIMESTAMP,
created_by INT,
updated_by INT,
created_at TIMESTAMP DEFAULT now(),
updated_at TIMESTAMP DEFAULT now(),
deleted_at TIMESTAMP
);
-- Indexes for CARTS
CREATE INDEX idx_carts_user_created ON carts(user_id, created_at);
CREATE INDEX idx_carts_user_status ON carts(user_id, status);
CREATE INDEX idx_carts_status_expires ON carts(status, expires_at);
CREATE INDEX idx_carts_created_at ON carts(created_at);
-- CART_ITEMS table
CREATE TABLE cart_items (
cart_item_id SERIAL PRIMARY KEY,
cart_id INT REFERENCES carts(cart_id) ON DELETE CASCADE,
item_id INT REFERENCES items(item_id) ON DELETE RESTRICT,
quantity INT NOT NULL CHECK (quantity > 0),
price_at_addition NUMERIC(10,2),
is_deleted BOOLEAN DEFAULT FALSE,
added_at TIMESTAMP DEFAULT now()
);
-- Indexes for CART_ITEMS
CREATE INDEX idx_cart_items_cart_item ON cart_items(cart_id, item_id);
CREATE INDEX idx_cart_items_item_deleted ON cart_items(item_id, is_deleted);
CREATE INDEX idx_cart_items_cart_added ON cart_items(cart_id, added_at);
CREATE INDEX idx_cart_items_added_at ON cart_items(added_at);
-- ORDERS table
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(user_id),
cart_id INT REFERENCES carts(cart_id),
status TEXT NOT NULL CHECK (status IN ('pending', 'paid', 'shipped', 'cancelled', 'refunded')),
shipping_address TEXT,
billing_address TEXT,
tracking_number TEXT,
payment_due_date TIMESTAMP,
is_deleted BOOLEAN DEFAULT FALSE,
total NUMERIC(10,2),
created_by INT,
updated_by INT,
created_at TIMESTAMP DEFAULT now(),
updated_at TIMESTAMP DEFAULT now(),
deleted_at TIMESTAMP
);
-- Indexes for ORDERS
CREATE INDEX idx_orders_status_created ON orders(status, created_at);
CREATE INDEX idx_orders_user_status ON orders(user_id, status);
CREATE INDEX idx_orders_user_created ON orders(user_id, created_at);
CREATE INDEX idx_orders_tracking ON orders(tracking_number);
-- PAYMENTS table
CREATE TABLE payments (
payment_id SERIAL PRIMARY KEY,
order_id INT REFERENCES orders(order_id) ON DELETE CASCADE,
payment_method TEXT NOT NULL,
payment_status TEXT DEFAULT 'initiated',
transaction_id TEXT UNIQUE,
currency TEXT DEFAULT 'USD',
amount NUMERIC(10,2) NOT NULL,
is_refundable BOOLEAN DEFAULT FALSE,
paid_at TIMESTAMP DEFAULT now(),
refunded_at TIMESTAMP
);
-- Indexes for PAYMENTS
CREATE INDEX idx_payments_method_paid_at ON payments(payment_method, paid_at);
CREATE INDEX idx_payments_method_status ON payments(payment_method, payment_status);
CREATE INDEX idx_payments_order_status ON payments(order_id, payment_status);
CREATE INDEX idx_payments_currency_paid ON payments(currency, paid_at);Test 1: 여러 인덱스된 테이블에 걸친 다중 조인 쿼리 실행하기
PostgreSQL이 복잡한 조인 작업 중에 락을 어떻게 처리하는지 검토하기 위해, 사용자의 전체 장바구니 정보를 검색하는 다중 조인 쿼리를 사용하여 첫 번째 테스트를 실행해 보겠습니다. 이 쿼리는 PostgreSQL이 여러 테이블과 관련 인덱스에 걸쳐 락을 어떻게 관리하는지 보여줍니다. 세션 1에서 트랜잭션을 시작하고 이 쿼리를 실행하세요.
postgres=> SET search_path TO experiment_3;
BEGIN;
SELECT
u.user_id,
u.name AS user_name,
c.cart_id,
i.name AS item_name,
ci.quantity,
i.price,
(i.price * ci.quantity) AS line_total,
o.order_id,
o.status,
p.payment_method,
p.amount
FROM users u
JOIN carts c ON c.user_id = u.user_id
JOIN cart_items ci ON ci.cart_id = c.cart_id
JOIN items i ON i.item_id = ci.item_id
LEFT JOIN orders o ON o.cart_id = c.cart_id
LEFT JOIN payments p ON p.order_id = o.order_id
WHERE u.user_id = (1 + floor(random() * 10))::int;
SET
BEGIN
user_id | user_name | cart_id | item_name | quantity | price | line_total | order_id | status | payment_method | amount
---------+-----------+---------+-----------+----------+-------+------------+----------+--------+----------------+--------
(0 rows)세션 1에서 위의 트랜잭션을 열어둔 상태에서, 다중 조인 쿼리에 관련된 모든 테이블과 인덱스에 걸쳐 PostgreSQL이 락을 어떻게 관리하는지 검토하기 위해 세션 2에서 다음 쿼리를 실행하세요.
postgres=> SELECT
n.nspname AS schema,
c.relname AS table,
l.locktype,
l.mode,
l.fastpath
FROM pg_locks l
JOIN pg_class c ON l.relation = c.oid
JOIN pg_namespace n ON c.relnamespace = n.oid
AND n.nspname <> 'pg_catalog';
schema | table | locktype | mode | fastpath
---------------+------------------------------+----------+----------------+----------
experiment_3 | idx_carts_status_expires | relation | AccessShareLock | t
experiment_3 | idx_carts_user_status | relation | AccessShareLock | t
experiment_3 | idx_carts_user_created | relation | AccessShareLock | t
experiment_3 | carts_pkey | relation | AccessShareLock | t
experiment_3 | idx_users_created_at | relation | AccessShareLock | t
experiment_3 | idx_users_role_active | relation | AccessShareLock | t
experiment_3 | idx_users_email_active | relation | AccessShareLock | t
experiment_3 | idx_users_name_created_at | relation | AccessShareLock | t
experiment_3 | users_email_key | relation | AccessShareLock | t
experiment_3 | users_pkey | relation | AccessShareLock | t
experiment_3 | payments | relation | AccessShareLock | t
experiment_3 | orders | relation | AccessShareLock | t
experiment_3 | items | relation | AccessShareLock | t
experiment_3 | cart_items | relation | AccessShareLock | t
experiment_3 | carts | relation | AccessShareLock | t
experiment_3 | users | relation | AccessShareLock | t
experiment_3 | idx_cart_items_item_deleted | relation | AccessShareLock | f
experiment_3 | idx_orders_user_status | relation | AccessShareLock | f
experiment_3 | idx_cart_items_cart_item | relation | AccessShareLock | f
experiment_3 | idx_payments_order_status | relation | AccessShareLock | f
experiment_3 | idx_carts_created_at | relation | AccessShareLock | f
experiment_3 | idx_cart_items_cart_added | relation | AccessShareLock | f
experiment_3 | idx_items_created_at | relation | AccessShareLock | f
experiment_3 | orders_pkey | relation | AccessShareLock | f
experiment_3 | payments_pkey | relation | AccessShareLock | f
experiment_3 | idx_items_name_price | relation | AccessShareLock | f
experiment_3 | idx_payments_method_status | relation | AccessShareLock | f
experiment_3 | payments_transaction_id_key | relation | AccessShareLock | f
experiment_3 | idx_items_category_active | relation | AccessShareLock | f
experiment_3 | items_pkey | relation | AccessShareLock | f
experiment_3 | idx_orders_status_created | relation | AccessShareLock | f
experiment_3 | idx_items_price_stock | relation | AccessShareLock | f
experiment_3 | idx_cart_items_added_at | relation | AccessShareLock | f
experiment_3 | idx_orders_tracking | relation | AccessShareLock | f
experiment_3 | idx_payments_currency_paid | relation | AccessShareLock | f
experiment_3 | cart_items_pkey | relation | AccessShareLock | f
experiment_3 | items_sku_key | relation | AccessShareLock | f
experiment_3 | idx_orders_user_created | relation | AccessShareLock | f
experiment_3 | idx_payments_method_paid_at | relation | AccessShareLock | f
(39 rows)위의 출력에서, PostgreSQL이 총 39개의 락을 획득했음을 볼 수 있습니다. fastpath 컬럼을 보면 23개 행이 f(false)로 나타나는데, 이는 이러한 락들이 빠른 경로 대신 공유 메모리 락 테이블을 통한 더 느린 경로를 사용해야 했음을 나타냅니다. 이는 겉보기에 단순한 중첩 조인 쿼리라도 빠른 경로 슬롯이 소진될 때 상당한 락 경합이 발생할 수 있음을 보여줍니다.
Test 2: 높은 동시성 하에서 다중 조인 쿼리 실행하기
위의 SQL 쿼리와 같은 이러한 복잡한 조인이 어떻게 수행되는지 이해하기 위해, 높은 동시성 하에서 전자상거래 스키마를 스트레스 테스트해 보겠습니다. 이전 실험들과 마찬가지로, pgbench를 사용하여 다중 조인 쿼리를 동시에 실행하는 여러 동시 사용자를 시뮬레이션합니다.
이전 실험들(실험 1과 2)에서 사용한 것과 동일한 pgbench 명령어를 사용하여, 세션 1 터미널에서 다음을 실행하십시오. 이 테스트는 5분 동안 실행될 것입니다.
pgbench -c 100 -j 10 -n -f transaction.sql -T 300transaction.sql 파일에는 이전 테스트와 동일한 다중 조인 SQL 쿼리가 포함되어 있습니다. 테스트가 실행되는 동안 CloudWatch Database Insights에서 데이터베이스 대기 이벤트를 모니터링할 수 있습니다.
CloudWatch Database Insights의 다음 스크린샷은 인덱스가 많은 테이블에 걸친 다중 조인 쿼리가 어떻게 이중 성능 영향을 만들어내는지 보여줍니다. LWLock:LockManager 경합이 활성 세션의 20퍼센트를 소비하고 CPU 사용률이 80퍼센트에 근접하여 포화 상태에 도달하고 있습니다.
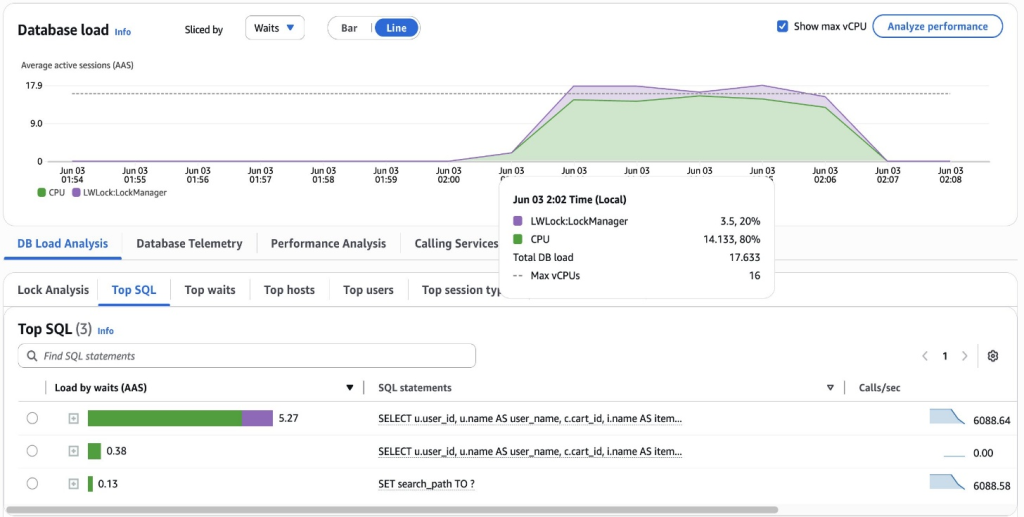
데이터베이스 부하 그래프는 여러 인덱스가 있는 테이블들에 걸친 다중 조인 쿼리로 인해 상당한 LWLock:LockManager 경합(AAS의 20퍼센트)과 높은 CPU 사용률(80퍼센트)을 보여줍니다. 각 조인은 PostgreSQL이 인덱스에 대한 AccessShareLock 락을 획득하도록 강제하여, 빠른 경로 락을 소진하고 더 느린 메인 락 관리자로 대체됩니다. 쿼리 계획 중의 반복적인 카탈로그 스캔은 CPU 사용률을 포화 상태에 가깝게 끌어올립니다. 이러한 락 관리자 병목 현상은 조인 계획 중에 여러 인덱스된 테이블에 걸쳐 락을 유지하는 데 따른 결합된 오버헤드에서 비롯됩니다. 중복된 인덱스를 줄이고 조인 패턴을 단순화하면 워크로드에서 볼 수 있는 락 경합과 CPU 부하가 모두 완화될 것입니다.
PostgreSQL 락 경합 관리를 위한 주요 완화 전략
PostgreSQL 락 경합을 줄이기 위한 다음 주요 완화 전략들을 고려하실 수 있습니다.
- 파티션 테이블에 대한 최적화된 접근
- 파티션 프루닝 활성화 – 풀 테이블 스캔 대신 명시적 날짜 범위(
WHERE order_ts BETWEEN X AND Y) 사용하세요. PostgreSQL 문서에서 파티션 프루닝에 대해 자세히 알아보세요. - 상수가 없는 동적 SQL 피하기 – 실험1과 같이 프루닝을 강제하기 위해, CTE를 PL/pgSQL 블록으로 대체하세요.
- 파티션 수 제한하기 – 빠른 경로 슬롯 제한을 넘지 않기 위해, 가능한 경우 파티션 수를 줄이세요. (예: 월별 대신 분기별 파티션 사용을 고려하세요)
- 파티션 프루닝 활성화 – 풀 테이블 스캔 대신 명시적 날짜 범위(
- 인덱스 조정
- 사용되지 않는 인덱스 감사 및 제거 –
pg_stat_user_indexes를 통해 사용 빈도가 낮은 인덱스를 식별하세요. - 중복 인덱스 통합 – 개별 컬럼 인덱스를 복합 인덱스로 대체하세요. (예: 세 개의 별도 인덱스 대신 (
category,subcategory,price)로 구성하기) - 과도한 인덱싱 피하기 – OLTP 시스템에 크리티컬한 경우가 아니라면, 테이블당 인덱스를 제한하세요. (예: 10개 이하)
- 사용되지 않는 인덱스 감사 및 제거 –
- 스키마 디자인 조정
- 불필요한 파티셔닝 피하기 – 100GB를 초과하거나 명확한 접근 패턴이 있는 테이블만 파티션화 하세요. 테이블 파티셔닝을 언제 어떻게 구현할지에 대한 자세한 지침은 Amazon Aurora 및 Amazon RDS에서 파티션된 테이블로 마이그레이션하여 대규모 PostgreSQL 테이블의 성능과 관리성 개선을 참조하세요.
- 커버링 인덱스 사용 – 테이블 접근을 피하기 위해
INCLUDE컬럼을 추가하세요.(relation 락 감소) PostgreSQL 문서에서 커버링 인덱스와 인덱스 전용 스캔 구현에 대해 자세히 알아보세요. - 높은 동시성 테이블 정규화 – 인덱스 확산(index sprawl)을 줄이기 위해 넓은 테이블(예:
items)은 분할하세요.
- 쿼리 최적화
- 조인 단순화 – 다중 조인 쿼리를 materialized view나 단계적 쿼리로 분할하세요. Materialized view 구현은 PostgreSQL 문서를 참조하세요.
- 작은 읽기 일괄 처리 – 락 빈도를 줄이기 위해, 작은 조회는 결합하세요. (예:
IN (...)절을 사용할 수 있습니다.)
- PostgreSQL 튜닝
- max_locks_per_transaction 조정 – 파티셔닝이 불가피하고(메모리 모니터링 필요) 빠른 경로 슬롯이 초과되어 락이 공유 메모리 락 해시 테이블로 이동되는 경우,
max_locks_per_transaction증가를 고려해 보세요. (예: 256에서 512로) - 빠른 경로 사용량 모니터링 – 슬롯 소진을 식별하기 위해
pg_locks를 추적하세요.
- max_locks_per_transaction 조정 – 파티셔닝이 불가피하고(메모리 모니터링 필요) 빠른 경로 슬롯이 초과되어 락이 공유 메모리 락 해시 테이블로 이동되는 경우,
리소스 정리하기
이 블로그 게시물의 솔루션 구현과 관련된 향후 비용 발생을 피하기 위해 생성한 리소스를 삭제하세요.
- 실험에서 생성한 테스트 스키마와 테이블을 삭제하세요.
- 테스트용으로 Aurora PostgreSQL 클러스터를 생성한 경우, 이를 삭제하세요.
- 더 이상 필요하지 않은 경우, 관련 스냅샷을 제거하세요.
결론
읽기 중심 워크로드에서의 PostgreSQL LWLock 경합은 프루닝되지 않은 파티션, 중복 인덱스, 복잡한 조인으로 인해 발생하는 빠른 경로 잠금 제한 초과에서 비롯됩니다. 이 게시물의 실험들은 다음을 보여주었습니다.
- 파티션 프루닝은 락을 빠른 경로 슬롯 개수 안에서 사용할 수 있게 함으로써, 락 오버헤드를 줄여 34퍼센트의 성능 향상(46,000 tps에서 59,000 tps로)을 달성했습니다.
- 사용되지 않는 각 인덱스는 빈 테이블에서도 느린 경로 대체를 강제하여 락 압박을 가중시켰습니다.
- 다중 조인 쿼리는 테스트된 시나리오에서 60퍼센트의 락이 느린 경로로 넘어가면서 경합을 증폭시켰습니다.
파티션 쿼리, 엄격한 인덱스 관리, 조인 단순화를 우선시함으로써 Amazon Aurora PostgreSQL과 Amazon RDS for PostgreSQL에서 빠른 경로 효율성을 유지하고 선형적인 읽기 확장성을 제공할 수 있습니다. 데이터베이스가 성장함에 따라, 이러한 최적화는 락 병목 현상 없이 AWS의 탄력성을 활용하는 데 기초가 됩니다.
Aurora에서 확장 가능한 PostgreSQL 워크로드의 성능 튜닝과 설계에 대한 자세한 내용은 Aurora PostgreSQL 튜닝을 위한 핵심 개념을 참조하십시오.